
C:\> tools\fdimage floppies\kern.flp A:FreeBSD 手册
如果发现翻译错误,请直接 发起PR修改.
Copyright © 1995-2023 The FreeBSD Documentation Project
trademarks
FreeBSD 是 FreeBSD 基金会的注册商标
IBM、 AIX、 OS/2、 PowerPC、 PS/2、 S/390 以及 ThinkPad 是国际商用机器公司在美国和其他国家的注册商标或商标。
IEEE, POSIX, 和 802 是 Institute of Electrical and Electronics Engineers, Inc. 在美国的注册商标。
Red Hat, RPM, 是 Red Hat, Inc. 在美国和其他国家的注册商标。
3Com 和 HomeConnect 是 3Com Corporation 的注册商标。
Adobe、 Acrobat、 Acrobat Reader、 Flash, 以及 PostScript 是 Adobe Systems Incorporated 在美国和/或其他国家的商标或注册商标。
Apple, AirPort, FireWire, iMac, iPhone, iPad, Mac, Macintosh, Mac OS, Quicktime, 以及 TrueType 是 Apple Inc. 在美国以及其他国家的注册商标。
Intel, Celeron, Centrino, Core, EtherExpress, i386, i486, Itanium, Pentium, 和 Xeon 是 Intel Corporation 及其分支机构在美国和其他国家的商标或注册商标。
Linux 是 Linus Torvalds 的注册商标。
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media, 和 Windows NT 是 Microsoft Corporation 在美国和/或其他国家的商标或注册商标。
Motif, OSF/1, 和 UNIX 是 The Open Group 在美国和其他国家的注册商标; IT DialTone 和 The Open Group 是其商标。
Sun、 Sun Microsystems、 Java、 Java Virtual Machine、 JDK、 JRE、 JSP、 JVM、 Netra、 OpenJDK、 Solaris、 StarOffice、 SunOS 以及 VirtualBox 是 Sun Microsystems, Inc. 在美国和其他国家的商标或注册商标。
RealNetworks, RealPlayer, 和 RealAudio 是 RealNetworks, Inc. 的注册商标。
Oracle 是 Oracle Corporation 的注册商标。
3ware 是 3ware Inc 的注册商标。
ARM 是 ARM Limited. 的注册商标。
Adaptec 是 Adaptec, Inc. 的注册商标。
Android 是 Google Inc 的注册商标。
Heidelberg、 Helvetica、 Palatino 以及 Times Roman 是 Heidelberger Druckmaschinen AG 在美国和其他国家的商标或注册商标。
Intuit 和 Quicken 是 Intuit Inc., 或其子公司在美国和其他国家的商标或注册商标。
LSI Logic, AcceleRAID, eXtremeRAID, MegaRAID 和 Mylex 是 LSI Logic Corp 的商标或注册商标。
MATLAB 是 The MathWorks, Inc. 的注册商标。
SpeedTouch 是 Thomson 的商标。
VMware 是 VMware, Inc. 的商标
Mathematica 是 Wolfram Research, Inc 的注册商标。
Ogg Vorbis 和 Xiph.Org 是 Xiph.Org 的商标。
XFree86 是 The XFree86 Project, Inc 的商标。.
许多制造商和经销商使用一些称为商标的图案或文字设计来彰显自己的产品。 本文档中出现的, 为 FreeBSD Project 所知晓的商标,后面将以 “™” 或 “®” 符号来标注。
目录
[ Split HTML / Single HTML ]
摘要
欢迎来到 FreeBSD !本手册涵盖了 FreeBSD 14.0-RELEASE, 13.2-RELEASE 和 FreeBSD 12.4-RELEASE 的安装和日常使用。本书是许多人持续工作的结果。某些部分可能已过时。有兴趣帮助更新和扩展本文档的人应该发送电子邮件至 FreeBSD documentation project mailing list。
这本书的最新版本可以从 FreeBSD 网站 获取。以前的版本可以从 https://docs.FreeBSD.org/doc/ 获取。该书可以从 FreeBSD 下载服务器 或众多 镜像站点 之一以多种格式和压缩选项下载。可以在手册和其他文档上进行搜索,链接在 搜索页面 上。
前言
预期读者
FreeBSD 新手会发现本书的第一部分指导用户完成 FreeBSD 安装过程,并轻松地介绍了 UNIX® 的概念和约定。阅读这一部分只需要有探索的愿望,以及接受新概念的能力。
一旦你走到这一步,手册的第二部分,也是更大的部分,是一个对 FreeBSD 系统管理员感兴趣的各种主题的全面参考。其中一些章节可能会建议你先阅读一些内容,在每个章节的简介中会有注明。
有关更多信息来源的列表,请参见 参考文献。
第四版
当前版本的手册代表了一个工作组的累积努力,该工作组一直在审查和更新所有手册内容。以下是自第四版手册以来的主要更新。
-
手册已从 Docbook 转换为 Hugo 和 AsciiDoctor。
-
FreeBSD 文档门户 已创建。
-
添加了 Wayland,其中包含在 FreeBSD 下安装和配置 Wayland 的信息。
-
参考文献 已经进行了广泛的更新。
第二版(2004 年)
第三版是 FreeBSD 文档项目专注成员超过两年工作的巅峰之作。印刷版的规模增长到了需要分为两卷出版的程度。以下是这个新版中的主要变化:
-
配置和调优 增加了关于 ACPI 电源和资源管理、
cron系统实用程序以及更多内核调优选项的新信息。 -
Security 增加了关于虚拟私有网络(VPN)、文件系统访问控制列表(ACLs)和安全公告的新信息。
-
Mandatory Access Control 是本版本的新章节。它解释了 MAC 是什么,以及如何使用这种机制来保护 FreeBSD 系统。
-
Storage 增加了关于 USB 存储设备、文件系统快照、文件系统配额、文件和网络支持的文件系统以及加密磁盘分区的新信息。
-
向 PPP 添加了故障排除部分。
-
电子邮件 扩展了关于使用替代传输代理、SMTP 身份验证、UUCP、fetchmail、procmail 和其他高级主题的新信息。
-
网络服务器 在本版中是全新的。本章包括有关设置 Apache HTTP 服务器、ftpd 以及使用 Samba 为 Microsoft® Windows® 客户端设置服务器的信息。为了改善呈现效果,一些来自 高级网络 的部分内容被移至此处。
-
高级网络 增加了关于在 FreeBSD 上使用蓝牙设备、设置无线网络和异步传输模式(ATM)网络的新信息。
-
添加术语表,以提供一个集中的位置,用于定义整本书中使用的技术术语。
-
对本书中的表格和图表进行了一些美观的改进。
第一版(2001 年)
第二版是 FreeBSD 文档项目专注成员两年多工作的巅峰之作。以下是本版的主要变化:
-
添加完整索引。
-
所有的 ASCII 图形都已被替换为图形化的图表。
-
每个章节都添加了一个标准的简介,以便快速概述该章节包含的信息以及读者应该了解的内容。
-
内容已经在逻辑上重新组织成三个部分:“入门指南”,“系统管理”和“附录”。
-
对 FreeBSD 基础知识 进行了扩展,包含了关于进程、守护进程和信号的额外信息。
-
对 安装应用程序:软件包和端口 进行了扩展,包含了关于二进制包管理的额外信息。
-
X Window 系统 章节完全重写,重点是使用现代桌面技术,如 KDE 和 GNOME 在 XFree86™ 4.X 上。
-
对 FreeBSD 引导过程 进行了扩展。
-
存储 一章是由原本分为"磁盘"和"备份"两个章节合并而成的。我们认为将这些主题作为一个单独的章节呈现更容易理解。同时,还添加了一个关于 RAID (硬件和软件)的部分。
-
Serial Communications 章节完全重新组织和更新,适用于 FreeBSD 4.X/5.X 。
-
PPP 章节进行了重大更新。
-
高级网络 中添加了许多新的部分。
-
对 电子邮件 进行扩展,包括更多关于配置 sendmail 的信息。
-
对 Linux® 二进制兼容性 进行了扩展,包括了安装 Oracle® 和 SAP® R/3® 的信息。
-
本第二版涵盖了以下新主题:
本书的组织结构
本书分为五个逻辑上独立的部分。第一部分是 入门,介绍了 FreeBSD 的安装和基本使用。预计读者会按照章节的顺序阅读,可能会跳过熟悉的主题章节。第二部分是 常见任务,介绍了 FreeBSD 的一些常用功能。这部分以及后续的部分可以按任意顺序阅读。每个章节都以简洁的摘要开始,描述了章节内容和读者所需的基础知识。这样可以让读者随意跳转到感兴趣的章节。第三部分是 系统管理,介绍了管理主题。第四部分是 网络通信,介绍了网络和服务器主题。第五部分包含参考信息的附录。
- 导言
-
本文向新用户介绍 FreeBSD 。它描述了 FreeBSD 项目的历史、目标和开发模型。
- 安装 FreeBSD
-
使用 bsdinstall,引导用户完成 FreeBSD 9._x_及更高版本的完整安装过程。
- FreeBSD 基础知识
-
介绍了 FreeBSD 操作系统的基本命令和功能。如果您熟悉 Linux® 或其他 UNIX® 的变种,那么您可能可以跳过本章。
- 安装应用程序:软件包和 Ports
-
本文介绍了使用 FreeBSD 创新的“Ports Collection”和标准二进制软件包安装第三方软件的方法。
- X Window 系统
-
描述了 X Window System 的一般情况,特别是在 FreeBSD 上使用 X11 的情况。还描述了常见的桌面环境,如 KDE 和 GNOME。
- Wayland
-
描述了 Wayland 显示服务器的一般情况,特别是在 FreeBSD 上使用 Wayland 的情况。还描述了常见的合成器,如 Wayfire、Hikari 和 Sway。
- 桌面应用程序
-
列举了一些常见的桌面应用程序,如网络浏览器和办公套件,并描述了如何在 FreeBSD 上安装它们。
- 多媒体
-
展示了如何为您的系统设置音频和视频播放支持。还介绍了一些示例音频和视频应用程序。
- 配置 FreeBSD 内核
-
解释了为什么您可能需要配置一个新的内核,并提供了详细的配置、构建和安装自定义内核的指令。
- 打印
-
描述了在 FreeBSD 上管理打印机的方法,包括有关横幅页面、打印机计费和初始设置的信息。
- Linux® 二进制兼容性
-
描述了 FreeBSD 的 Linux® 兼容功能。还提供了许多流行的 Linux® 应用程序(如 Oracle® 和 Mathematica®)的详细安装说明。
- WINE
-
描述了 WINE 并提供了详细的安装说明。还描述了 WINE 的操作方式,如何安装 GUI 助手,如何在 FreeBSD 上运行 Windows® 应用程序,并提供其他提示和解决方案。
- 配置和调优
-
描述了系统管理员可以调整 FreeBSD 系统以获得最佳性能的参数。还描述了在 FreeBSD 中使用的各种配置文件以及它们的位置。
- FreeBSD 引导过程
-
描述了 FreeBSD 的启动过程,并解释了如何通过配置选项来控制这个过程。
- 安全
-
描述了许多不同的工具,可用于帮助保护您的 FreeBSD 系统的安全性,包括 Kerberos、IPsec 和 OpenSSH。
- Jails
-
描述了 FreeBSD 中的 jails 框架以及 jails 相对于传统的 chroot 支持的改进。
- 强制访问控制
-
解释了强制访问控制(Mandatory Access Control,MAC)是什么,以及如何使用这种机制来保护 FreeBSD 系统。
- 安全事件审计
-
描述了什么是 FreeBSD 事件审计,如何安装、配置以及如何检查或监控审计日志。
- 存储
-
描述了如何使用 FreeBSD 管理存储介质和文件系统。这包括物理磁盘、RAID 阵列、光盘和磁带介质、内存支持的磁盘和网络文件系统。
- GEOM:模块化磁盘转换框架
-
描述了 FreeBSD 中的 GEOM 框架是什么以及如何配置各种支持的 RAID 级别。
- OpenZFS 存储平台
-
描述了 OpenZFS 存储平台,并提供了一个快速入门指南,以及关于在 FreeBSD 下运行 OpenZFS 的高级主题的信息。
- 其他文件系统
-
研究了 FreeBSD 对非本地文件系统(如 ext2、 ext3 和 ext4)的支持。
- 虚拟化
-
描述了虚拟化系统提供的功能以及如何在 FreeBSD 上使用它们。
- 本地化 - i18n/L10n 的使用和设置
-
描述了如何在非英语语言环境中使用 FreeBSD。涵盖了系统和应用程序级别的本地化。
- 更新和升级 FreeBSD
-
解释了 FreeBSD-STABLE、FreeBSD-CURRENT 和 FreeBSD 发布版之间的区别。描述了哪些用户会从跟踪开发系统中受益,并概述了该过程。介绍了用户可以采取的方法来更新系统到最新的安全发布版。
- DTrace
-
描述了如何在 FreeBSD 上配置和使用 Sun™ 的 DTrace 工具。通过进行实时系统分析,动态跟踪可帮助定位性能问题。
- USB 设备模式/USB OTG
-
解释了在 FreeBSD 上使用 USB 设备模式和 USB On The Go(USB OTG)的方法。
- PPP
-
描述了如何在 FreeBSD 中使用 PPP 连接到远程系统。
- 电子邮件
-
解释了电子邮件服务器的不同组件,并深入探讨了最流行的邮件服务器软件 sendmail 的简单配置主题。
- 网络服务器
-
提供详细的说明和示例配置文件,以将您的 FreeBSD 机器设置为网络文件系统服务器、域名服务器、网络信息系统服务器或时间同步服务器。
- Firewalls
-
解释了基于软件的防火墙背后的哲学,并提供有关可用于 FreeBSD 的不同防火墙的配置的详细信息。
- 高级网络
-
描述了许多网络主题,包括在局域网上与其他计算机共享互联网连接、高级路由主题、无线网络、蓝牙®、ATM、IPv6 等等。
- 获取 FreeBSD
-
列出了获取 FreeBSD 光盘或 DVD 的不同来源,以及允许您下载和安装 FreeBSD 的互联网上的不同网站。
- 参考文献
-
这本书涉及了许多不同的主题,可能会让你渴望更详细的解释。参考书目列出了文本中引用的许多优秀书籍。
- 互联网资源
-
描述了许多可供 FreeBSD 用户发布问题和参与有关 FreeBSD 的技术讨论的论坛。
- OpenPGP 密钥
-
列出了几位 FreeBSD 开发者的 PGP 指纹。
本书中使用的约定
为了提供一致且易于阅读的文本,本书遵循了几个约定。
排版约定
- 斜体
-
斜体字用于文件名、URL、强调的文本以及技术术语的首次使用。
等宽-
错误消息、命令、环境变量、端口名称、主机名、用户名、组名、设备名、变量和代码片段使用
等宽字体。 - 粗体
-
应用程序、命令和按键使用 粗体 字体。
用户输入
键以 粗体 显示,以突出显示与其他文本的区别。同时输入的键组合以 + 符号分隔键,例如:
Ctrl+Alt+Del
意思是用户应该同时按下 Ctrl、Alt 和 Del 键。
需要按顺序输入的键将用逗号分隔,例如:
Ctrl+X,Ctrl+S
这意味着用户需要同时按下键盘上的 Ctrl 和 X 键,然后再同时按下键盘上的 Ctrl 和 S 键。
示例
以 C:\> 开头的示例表示一个 MS-DOS® 命令。除非另有说明,这些命令可以在现代 Microsoft® Windows® 环境中的 "Command Prompt" 窗口中执行。
以 # 开头的示例表示在 FreeBSD 中必须以超级用户身份调用的命令。您可以登录为 root 来输入命令,或者登录为您的普通帐户并使用 su(1) 来获取超级用户权限。
# dd if=kern.flp of=/dev/fd0以 % 开头的示例表示应从普通用户帐户调用的命令。除非另有说明,设置环境变量和其他 shell 命令使用 C-shell 语法。
% top致谢
你手中的这本书代表了全球数百人的努力。无论他们是纠正错别字还是提交完整的章节,所有的贡献都是有用的。
几家公司通过支付作者全职工作、出版费用等方式支持了本文档的开发。特别是 BSDi(后来被 Wind River Systems 收购)支付了 FreeBSD 文档项目的成员全职工作,以改进这本书,直到 2000 年 3 月第一版印刷版的出版(ISBN 1-57176-241-8)。随后, Wind River Systems 支付了几位额外的作者,改进了印刷输出基础设施,并为文本添加了额外的章节。这项工作最终在 2001 年 11 月出版了第二版印刷版(ISBN 1-57176-303-1)。在 2003 年至 2004 年期间, FreeBSD Mall,Inc 支付了几位贡献者,改进了手册,为第三版印刷版做准备。第三版印刷版被分为两卷。两卷都已出版,分别是 The FreeBSD Handbook 3rd Edition Volume 1: User Guide(ISBN 1-57176-327-9)和The FreeBSD Handbook 3rd Edition Volume 2: Administrators Guide(ISBN 1-57176-328-7)。
Part I: 入门指南
本手册的这部分是为那些对FreeBSD新手用户和管理员准备的。这些章节包括:
-
介绍 FreeBSD。
-
引导读者完成安装过程。
-
教授 UNIX® 的基础知识和基本原理。
-
展示如何安装适用于 FreeBSD 的丰富第三方应用程序。
-
介绍 UNIX® 窗口系统 X,并详细说明如何配置一个能提高用户生产力的桌面环境。
-
介绍 Wayland,一种新的 UNIX® 显示服务器。
文本中的正向引用数量被尽量减少,以便这一部分可以从头到尾地阅读,最大程度地减少翻页。
Chapter 1. 介绍
1.1. 简介
感谢你对 FreeBSD 有所兴趣! 下面这一章涉及到了 FreeBSD 项目的各个方面,例如它的历史、目标、开发模式等等。
阅读本章后,您将了解:
-
FreeBSD 与其他计算机操作系统的关系。
-
FreeBSD 项目的历史。
-
FreeBSD 项目的目标。
-
FreeBSD 开源开发模型的基础知识。
-
当然,还有一个问题: FreeBSD 这个名字的由来。
1.2. 欢迎来到 FreeBSD !
FreeBSD 是一个开源的、符合标准的类 Unix 操作系统,适用于 x86(32 位和 64 位)、ARM、AArch64、RISC-V、POWER 和 PowerPC 计算机。它提供了现在被视为理所当然的所有功能,如抢占式多任务处理、内存保护、虚拟内存、多用户设施、 SMP 支持、各种语言和框架的开源开发工具,以及以 X Window System、KDE 或 GNOME 为中心的桌面功能。它的特点有:
-
自由开源许可证( Liberal Open Source license ) 赋予您自由修改和扩展其源代码的权利,并将其纳入开源项目和闭源产品中,而不会施加典型的强制共享许可证所具有的限制,同时避免潜在的许可证不兼容问题。
-
强大的 TCP/IP 网络 - FreeBSD 采用行业标准协议,具有越来越高的性能和可扩展性。这使得它在服务器和路由 / 防火墙角色中都能很好地匹配 - 实际上,许多公司和供应商正是出于这个目的使用它。
-
完全集成的 OpenZFS 支持,包括 root-on-ZFS 、 ZFS 引导环境、故障管理、管理委派、支持 jails 、 FreeBSD 特定文档和系统安装程序支持。
-
广泛的安全功能,从强制访问控制框架到 Capsicum 能力和沙盒机制。
-
超过30 , 000 个预构建软件包 支持所有架构,以及 Ports Collection ,使得构建自己定制的软件包变得容易。
-
文档 - 除了手册和涵盖从系统管理到内核内部的各种主题的不同作者的书籍之外,还有 man(1) 页面,不仅适用于用户空间的守护进程、实用程序和配置文件,还适用于内核驱动程序 API (第 9 节)和单个驱动程序(第 4 节)。
-
简单而一致的存储库结构和构建系统 - FreeBSD 使用一个存储库来管理所有组件,包括内核和用户空间。这个特点,加上统一且易于定制的构建系统以及经过深思熟虑的开发流程,使得将 FreeBSD 与自己产品的构建基础设施集成变得容易。
-
秉承 Unix 哲学,更倾向于可组合性,而不是硬编码行为的单体化“一体化”守护程序。
-
与 Linux 的二进制兼容性,使得在不需要虚拟化的情况下可以运行许多 Linux 二进制文件。
FreeBSD 基于加利福尼亚大学伯克利分校计算机系统研究组( CSRG )的 4.4BSD-Lite 发布版,并延续了 BSD 系统开发的卓越传统。除了 CSRG 提供的出色工作外, FreeBSD 项目还投入了数千小时的工作,扩展了功能并对系统进行了精细调整,以在实际负载情况下实现最大性能和可靠性。 FreeBSD 提供与其他开源和商业产品相当的性能和可靠性,同时结合了其他地方无法获得的尖端功能。
1.2.1. FreeBSD 可以做什么?
FreeBSD 的应用范围几乎只受你的想象力限制。从软件开发到工厂自动化,从库存控制到远程卫星天线的方位校正;如果可以用商业 UNIX® 产品完成,那么很有可能你也可以用 FreeBSD 来实现! FreeBSD 还受益于全球研究中心和大学开发的成千上万个高质量应用程序,通常可以以很低的或者零成本获得。
由于 FreeBSD 本身的源代码是免费提供的,因此该系统可以根据特定应用或项目的需求进行几乎无与伦比的定制,而这在大多数主要商业供应商的操作系统中通常是不可能的。以下是一些人们目前正在使用 FreeBSD 的应用程序的示例:
-
互联网服务:FreeBSD 内置的强大的 TCP/IP 网络使其成为各种互联网服务的理想平台,例如:
-
Web 服务器
-
IPv4 和 IPv6 路由
-
防火墙和 NAT ("IP 伪装")网关
-
FTP 服务器
-
电子邮件服务器
-
存储服务器
-
虚拟化服务器
-
还有更多 …
-
-
教育: 你是计算机科学或相关工程领域的学生吗?没有比 FreeBSD 提供的亲身实践、深入了解操作系统、计算机架构和网络更好的学习方式了。还有一些免费的 CAD 、数学和图形设计软件包,对于那些主要关注计算机用于完成其他工作的人来说,它们也非常有用!
-
研究: 由于整个系统的源代码可用, FreeBSD 是操作系统以及计算机科学其他领域研究的优秀平台。 FreeBSD 的自由可用性也使得远程团队能够在想法或共享开发上进行合作,而无需担心特殊许可协议或在公开论坛上讨论的限制。
-
网络: 需要一个新的路由器吗?一个域名服务器( DNS )?一个防火墙来阻止人们进入您的内部网络? FreeBSD 可以轻松地将闲置在角落的个人电脑转变为具有复杂数据包过滤功能的高级路由器。
-
嵌入式: FreeBSD 是构建嵌入式系统的优秀平台。它支持 ARM 、 AArch64 和 PowerPC 平台,配备强大的网络堆栈、尖端功能和宽松的 BSD 许可证,使 FreeBSD 成为构建嵌入式路由器、防火墙和其他设备的理想基础。
-
桌面: FreeBSD 是一个使用免费的 X11 服务器和 Wayland 显示服务器的廉价桌面解决方案的不错选择。 FreeBSD 提供了许多开源桌面环境的选择,包括标准的 GNOME 和 KDE 图形用户界面。 FreeBSD 甚至可以从中央服务器“无盘启动”,使得个人工作站更加便宜和易于管理。
-
软件开发: 基本的 FreeBSD 系统配备了一套完整的开发工具,包括完整的 C/C ++编译器和调试器套件。通过端口和软件包集合,还可以支持许多其他编程语言。
FreeBSD 可以免费下载,也可以通过 CD-ROM 或 DVD 获取。有关获取 FreeBSD 的更多信息,请参阅 Obtaining FreeBSD 。
1.2.2. 谁使用 FreeBSD ?
FreeBSD 以其 Web 服务器功能而闻名。可以在 FreeBSD 基金会的网站上找到一份 基于 FreeBSD 的产品和服务的公司的 testimonials 列表 。维基百科还维护着一个 基于 FreeBSD 的产品列表 。
1.3. 关于 FreeBSD 项目
下面的部分提供了关于项目的一些背景信息,包括简要历史、项目目标以及项目 开发模型。
1.3.1. FreeBSD 的简要历史
FreeBSD 项目诞生于 1993 年初,部分是由非官方的 386BSDPatchkit 的最后三位协调员 Nate Williams 、 Rod Grimes 和 Jordan Hubbard 共同构思而成。
最初的目标是生成 386BSD 的中间快照,以解决一些无法通过补丁机制解决的问题。该项目的早期工作标题是 386BSD 0.5 或 386BSD Interim ,以此为参考。
386BSD 是 Bill Jolitz 的操作系统,到那时为止,它已经遭受了将近一年的严重忽视。随着每一天过去,补丁包变得越来越不舒服,他们决定通过提供这个临时的“清理”快照来帮助 Bill 。然而,当 Bill Jolitz 突然决定撤回对该项目的支持,并没有明确表示将采取什么替代措施时,这些计划被粗暴地中止了。
即使没有 Bill 的支持,三人组仍然认为目标仍然值得追求,因此他们采用了 David Greenman 提出的“ FreeBSD ”这个名字。在与系统当前用户咨询后,确定了最初的目标。一旦清楚该项目可能成为现实, Jordan 便联系了 Walnut Creek CDROM ,以改善 FreeBSD 的发行渠道,以便那些没有便捷访问互联网的人。 Walnut Creek CDROM 不仅支持在光盘上分发 FreeBSD ,还提供了一台用于开发工作的机器和快速的互联网连接。如果没有 Walnut Creek CDROM 对当时一个完全未知的项目的几乎前所未有的信任, FreeBSD 很可能不会像今天这样迅速取得如此大的进展。
第一张 CD-ROM (以及整个网络范围内的)发行版是 FreeBSD 1.0 ,于 1993 年 12 月发布。它基于来自加州大学伯克利分校的 4.3BSD-Lite (“Net/2”)磁带,同时还借鉴了 386BSD 和自由软件基金会提供的许多组件。作为首次发布,它取得了相当不错的成功,并在 1994 年 5 月发布了备受好评的 FreeBSD 1.1 版本。
在这个时候,Novell 和加州大学伯克利分校( U.C. Berkeley )就有关伯克利 Net/2 磁带的法律地位的长期诉讼达成了意外的和解。和解的条件是 U.C. Berkeley 承认 Net/2 的三个文件是“受限制”的代码,必须予以删除,因为它们是诺维尔的财产,而 Novell 则是之前从 AT&T 收购的。作为回报,伯克利获得了 Novell 的“祝福”,即当 4.4BSD-Lite 版本最终发布时,将被宣布为无限制的,并强烈鼓励所有现有的 Net/2 用户切换过来。这包括 FreeBSD ,该项目被给予截止到 1994 年 7 月底停止发布基于 Net/2 的产品的时间。根据协议的条款,该项目在最后期限之前被允许发布最后一个版本,即 FreeBSD 1.1.5.1 。
FreeBSD 随后开始了一项艰巨的任务,从一个全新且相当不完整的 4.4BSD-Lite 代码库中重新塑造自己。虽然只有与 System V 共享内存和信号量相关的三个文件被删除,但在 BSD 发行版中进行了许多其他的更改和错误修复,因此将所有 FreeBSD 的开发工作合并到 4.4BSD-Lite 中是一项巨大的任务。该项目直到 1994 年 11 月才完成了这一过渡,并在 12 月向世界发布了 FreeBSD 2.0 版本。尽管在某种程度上仍然存在一些问题,但这个版本取得了重大的成功,并在 1995 年 6 月发布了更稳定、更易安装的 FreeBSD 2.0.5 版本。
从那时起,FreeBSD 发布了一系列版本,每次都会在前一版本的稳定性、速度和功能集上进行改进。
目前,长期发展项目仍在15.0-CURRENT (main) 分支中进行,并且随着工作的进行,15.0 的快照版本将持续从 快照服务器 发布。
1.3.2. FreeBSD 项目的目标
FreeBSD 项目的目标是提供可用于任何目的且无附加条件的软件。我们中的许多人在代码(和项目)上投入了大量资源,偶尔获得一些财务补偿并不介意,但我们绝对不会坚持要求。我们相信我们的首要任务是向任何人提供代码,无论出于何种目的,以便代码得到最广泛的使用并提供最广泛的利益。我们认为这是自由软件的最基本目标之一,我们对此表示热情支持。
我们源代码树中受 GNU 通用公共许可证( GPL )或库通用公共许可证( LGPL )约束的代码,附带了稍微更多的限制,尽管至少是在强制访问方面,而不是通常的相反情况。由于商业使用 GPL 软件可能出现的额外复杂性,我们更喜欢在合理的情况下选择以更宽松的 BSD 许可证提交的软件。
1.3.3. FreeBSD 开发模型
FreeBSD 的开发是一个非常开放和灵活的过程,从世界各地成千上万的人的贡献中构建而成,这一点可以从我们的 贡献者列表 中看出来。 FreeBSD 的开发基础设施允许这些成千上万的贡献者在互联网上进行合作。我们一直在寻找新的志愿者,有兴趣更深入参与的人应该参考有关 贡献 FreeBSD 的文章。
无论是独立工作还是密切合作,以下是关于 FreeBSD 项目及其开发过程的一些有用信息:
- Git 仓库
-
多年来, FreeBSD 的中央源代码树由免费可用的源代码控制工具 CVS ( Concurrent Versions System )维护。 2008 年 6 月,该项目转而使用 SVN ( Subversion )。由于源代码树的迅速扩展和已存储的历史记录量, CVS 所施加的技术限制变得明显,因此这次转换被认为是必要的。文档项目和 Ports 集合存储库也分别于 2012 年 5 月和 2012 年 7 月从 CVS 迁移到了 SVN 。 2020 年 12 月,该项目将源代码和文档存储库迁移到了 Git ,而 Ports 集合则在 2021 年 4 月跟随。有关获取 FreeBSD
src/存储库的更多信息,请参阅 Obtaining the Source 部分,有关获取 FreeBSD Ports 集合的详细信息,请参阅 Using the Ports Collection 。 - 贡献者列表
-
committers 是那些具有对 Git 仓库的 push 访问权限的人,他们被授权对 FreeBSD 源代码进行修改(术语“committer”来自于
commit,这是用于将新更改引入仓库的源代码控制命令)。任何人都可以提交一个 bug 到 Bug Database 。在提交 bug 报告之前,可以使用 FreeBSD 邮件列表、 IRC 频道或论坛来帮助验证一个问题是否真的是一个 bug 。 - FreeBSD 核心团队
-
如果 FreeBSD 项目是一家公司,那么 FreeBSD 核心团队 将相当于董事会。核心团队的主要任务是确保整个项目处于良好状态并朝着正确的方向发展。邀请专注和负责任的开发人员加入我们的提交者团队是核心团队的职责之一,招募新的核心团队成员也是核心团队的职责之一。当前的核心团队是在 2022 年 5 月从提交者候选人中选举产生的。选举每 2 年举行一次。
和大多数开发者一样, FreeBSD 核心团队的大多数成员在 FreeBSD 开发方面也是志愿者,并且没有从项目中获得经济利益,所以“承诺”也不应被误解为“有保证的支持”。上面提到的“董事会”类比并不十分准确,更适合说这些人是在违背自己更好判断的情况下选择了 FreeBSD 而放弃了自己的生活!
- FreeBSD 基金会
-
FreeBSD 基金会 是一个位于美国的 501(c)(3) 非营利组织,致力于支持和推广全球的 FreeBSD 项目和社区。基金会通过项目拨款资助软件开发,并提供员工立即响应紧急问题并实施新的特性和功能。基金会购买硬件以改善和维护 FreeBSD 基础设施,并资助人员提高测试覆盖率、持续集成和自动化。基金会通过在世界各地的技术会议和活动上推广 FreeBSD 来支持 FreeBSD 。基金会还提供研讨会、教育材料和演示,以吸引更多的 FreeBSD 用户和贡献者。基金会还代表 FreeBSD 项目执行合同、许可协议和其他需要认可法律实体的法律安排。
- 外部贡献者
-
最后,但绝对不是最不重要的,最大的开发者群体是用户自己,他们几乎一直向我们提供反馈和错误修复。与 FreeBSD 基本系统的开发保持联系的主要方式是订阅 FreeBSD technical discussions mailing list ,在这里讨论这些事情。对于移植第三方应用程序,可以使用 FreeBSD ports mailing list 。对于文档,可以使用 FreeBSD documentation project mailing list 。有关各种 FreeBSD 邮件列表的更多信息,请参见 互联网资源。
The FreeBSD 贡献者列表 是一个长期而不断增长的列表,为什么不通过 为 FreeBSD 做出贡献 加入其中呢?提供代码并不是唯一的方式!
总之,我们的开发模型是以一组松散的同心圆组织起来的。中心化模型是为了方便 FreeBSD 的用户,他们可以通过追踪一个中央代码库来获得便利,而不是为了排斥潜在的贡献者!我们的愿望是提供一个稳定的操作系统,配备一套大量的一致的应用程序,用户可以轻松安装和使用 - 这个模型在实现这一目标方面非常成功。
我们对那些希望加入我们成为 FreeBSD 开发者的人只有一个要求,那就是拥有与现有成员一样对其持续成功的奉献精神!
1.3.4. 第三方程序
除了基本发行版之外, FreeBSD 还提供了一个可移植软件集合,其中包含数千个常见的程序。ports 列表涵盖了从 HTTP 服务器到游戏、编程语言、编辑器等几乎所有领域的程序。大约有 36000 个 ports;整个 Ports 集合需要大约 3 GB 的空间。要编译一个 ports,只需切换到您想要安装的程序的目录,输入 make install,然后让系统完成剩下的工作。每个构建的 ports 都会动态地检索完整的原始发行版,因此您只需要足够的磁盘空间来构建所需的 ports。
几乎每个 ports 也都提供了预编译的“软件包”,不希望从源代码编译自己的 ports 的用户可以使用简单的命令( pkg install )进行安装。有关软件包和 ports 的更多信息,请参阅 安装应用程序:软件包和 ports 。
1.3.5. 附加文档
所有支持的 FreeBSD 版本在安装程序中提供了一个选项,在初始系统设置期间可以安装附加文档到 /usr/local/share/doc/freebsd。文档也可以在之后使用软件包进行安装:
# pkg install en-freebsd-doc对于本地化版本,请将“en”替换为所选语言的语言前缀。请注意,一些本地化版本可能已过时,可能包含不再正确或相关的信息。您可以使用以下 URL 在 Web 浏览器中查看本地安装的手册:
- FreeBSD 手册
-
/usr/local/share/doc/freebsd/en/books/handbook/handbook_en.pdf - FreeBSD 常见问题解答
-
/usr/local/share/doc/freebsd/en/books/faq/faq_en.pdf
您可以随时在 文档门户 找到最新的文档。
所有商标均为其各自所有者的财产。
Chapter 2. 安装 FreeBSD
2.1. 简介
FreeBSD 支持多种架构,包括 amd64 、 ARM® 、 RISC-V® 和 PowerPC® 。根据不同的架构和平台,可以 下载 不同的镜像来安装或直接运行 FreeBSD 。
镜像类型有:
-
虚拟机磁盘镜像,例如
qcow2、vmdk、vhd和原始设备镜像。这些不是安装镜像,而是已经预装了 FreeBSD 并准备好进行后安装任务的镜像。虚拟机镜像在云环境中也被广泛使用。 -
SD 卡镜像,用于树莓派等嵌入式系统。这些文件必须解压缩并以原始镜像的形式写入 SD 卡,主板将从 SD 卡启动。
-
安装镜像用于从 ISO 或 USB 设备引导,以在常见的台式机、笔记本电脑或服务器系统上安装 FreeBSD 到驱动器。
本章的其余部分描述了第三种情况,解释了如何使用名为 bsdinstall 的基于文本的安装程序安装 FreeBSD 。安装程序与此处显示的内容可能存在细微差异,因此请将本章作为一份通用指南,而不是一组字面指令。
阅读完本章后,您将了解:
-
如何获取 FreeBSD 镜像并创建 FreeBSD 安装介质。
-
如何启动 bsdinstall 。
-
bsdinstall 将会询问的问题,它们的含义以及如何回答。
-
如何排除安装失败的问题。
-
在进行安装之前,如何访问 FreeBSD 的活动版本。
2.2. 最低硬件要求
安装 FreeBSD 的硬件要求因架构和版本而异。支持 FreeBSD 发布的硬件架构和设备可以在 FreeBSD 发布信息 页面上找到。FreeBSD 下载页面 还提供了选择不同架构的正确镜像的建议。
2.3. 安装前的任务
一旦确定系统满足安装 FreeBSD 的最低硬件要求,就应该下载安装文件并准备安装介质。在此之前,请通过验证以下清单中的项目,确保系统已准备好进行安装:
-
备份重要数据
在安装任何操作系统之前, 一定要 首先备份所有重要数据。不要将备份存储在正在安装的系统上。而是将数据保存到可移动的磁盘,如 USB 驱动器、网络上的另一个系统或在线备份服务中。在开始安装之前,测试备份以确保它包含所有所需的文件。一旦安装程序格式化了系统的磁盘,该磁盘上存储的所有数据都将丢失。
-
决定在哪里安装 FreeBSD
如果只安装 FreeBSD 作为唯一的操作系统,可以跳过这一步。但如果 FreeBSD 将与其他操作系统共享磁盘,则需要决定哪个磁盘或分区将用于 FreeBSD 。
在 i386 和 amd64 架构中,可以使用两种分区方案将磁盘分成多个分区。传统的 主引导记录(MBR) 保存了一个包含最多四个 主分区 的分区表。出于历史原因,FreeBSD 将这些主分区称为 slices。其中一个主分区可以成为包含多个 逻辑分区 的 扩展分区。 GUID 分区表(GPT) 是一种较新且更简单的磁盘分区方法。常见的 GPT 实现允许每个磁盘最多有 128 个分区,消除了逻辑分区的需要。
FreeBSD 引导加载程序需要一个主分区或 GPT 分区。如果所有的主分区或 GPT 分区已经被使用,就必须释放一个分区给 FreeBSD 使用。为了在不删除现有数据的情况下创建一个分区,可以使用分区调整工具来缩小一个现有分区,并使用释放出的空间创建一个新的分区。
在 磁盘分区软件维基百科条目 中列出了各种免费和商业的分区调整工具。GParted Live 是一个免费的 Live CD,其中包含了 GParted 分区编辑器。
当正确使用时,磁盘收缩工具可以安全地为创建新分区腾出空间。由于选择错误分区的可能性存在,一定要在修改磁盘分区之前备份任何重要数据并验证备份的完整性。
包含不同操作系统的磁盘分区使得在一台计算机上安装多个操作系统成为可能。另一种选择是使用虚拟化技术,它允许多个操作系统同时运行,而无需修改任何磁盘分区。
-
收集网络信息
一些 FreeBSD 安装方法需要网络连接才能下载安装文件。在任何安装之后,安装程序将提供设置系统网络接口的选项。
如果网络有 DHCP 服务器,可以使用它来提供自动网络配置。如果没有 DHCP 可用,必须从本地网络管理员或互联网服务提供商获取系统的以下网络信息:
所需网络信息
-
IP 地址
-
子网掩码
-
默认网关的 IP 地址
-
网络的域名
-
网络的 DNS 服务器的 IP 地址
-
-
检查 FreeBSD 勘误表
尽管 FreeBSD 项目努力确保每个 FreeBSD 版本尽可能稳定,但偶尔会出现一些错误。在非常罕见的情况下,这些错误会影响安装过程。当这些问题被发现并修复时,它们会在每个版本的 FreeBSD 勘误页面中进行记录。在安装之前,请检查勘误页面,以确保没有可能影响安装的问题。
所有发布版本的信息和勘误表都可以在 FreeBSD Release Information 页面上找到。
2.3.1. 准备安装介质
FreeBSD 安装程序不是可以在另一个操作系统中运行的应用程序。相反,您需要下载一个 FreeBSD 安装文件,将其刻录到与其文件类型和大小(CD、DVD 或 USB)相关联的介质上,并从插入的介质启动系统以进行安装。
FreeBSD 安装文件可以在 FreeBSD 下载页面 上找到。每个安装文件的名称包括 FreeBSD 的发布版本、架构和文件类型。
安装文件有多种格式可供选择,可以使用 xz(1) 进行压缩或者不压缩。这些格式根据计算机架构和媒体类型而有所不同。
安装文件类型:
-
-bootonly.iso:这是最小的安装文件,只包含安装程序。在安装过程中需要一个可用的互联网连接,因为安装程序将下载完成 FreeBSD 安装所需的文件。这个文件应该被刻录到光盘介质上。 -
-disc1.iso:这个文件包含了安装 FreeBSD 所需的所有文件,包括其源代码和 Ports 集合。这个文件应该被刻录到光盘介质上。 -
-dvd1.iso:该文件包含安装 FreeBSD 所需的所有文件,包括其源代码和 Ports 集合。它还包含一组流行的二进制软件包,用于安装窗口管理器和一些应用程序,以便可以在没有连接到互联网的情况下从介质上安装完整的系统。该文件应该被刻录到光盘介质上。 -
-memstick.img:该文件包含安装 FreeBSD 所需的所有文件,包括其源代码和 Ports 集合。按照 将镜像文件写入 USB 中所示的方法将该文件写入 USB 存储设备。 -
-mini-memstick.img:与-bootonly.iso类似,不包含安装文件,但会在需要时进行下载。在安装过程中需要一个可用的互联网连接。请按照 将镜像文件写入 USB 中所示的方式将其写入 USB 存储设备。
在下载镜像文件后,从相同目录下载至少一个 checksum 文件。有两个 checksum 文件可用,分别以发布版本号和架构名称命名。例如:CHECKSUM.SHA256-FreeBSD-13.1-RELEASE-amd64 和 CHECKSUM.SHA512-FreeBSD-13.1-RELEASE-amd64。
在下载其中一个文件(或两个文件)之后,计算镜像文件的 校验和(checksum) 并将其与 checksum 文件中显示的 校验和 进行比较。请注意,您需要将计算出的 校验和 与正确的文件进行比较,因为它们对应于两种不同的算法: SHA256 和 SHA512。 FreeBSD 提供了可以用于计算 校验和 的 sha256(1) 和 sha512(1)。其他操作系统也有类似的程序。
在 FreeBSD 中,可以通过执行 sha256sum(1)(和 sha512sum(1))来自动验证 校验和。
% sha256sum -c CHECKSUM.SHA256-FreeBSD-13.1-RELEASE-amd64 FreeBSD-13.1-RELEASE-amd64-dvd1.iso
FreeBSD-13.1-RELEASE-amd64-dvd1.iso: OK校验和必须完全匹配。如果校验和不匹配,则图像文件损坏,必须重新下载。
2.3.1.1. 将镜像文件写入 USB
*memstick.img 文件是一个内存棒的完整内容的 镜像。它不能作为文件复制到目标设备上。有几个应用程序可用于将 *.img 写入 USB 内存棒。本节介绍其中两个实用程序。
|
在继续之前,请备份 U 盘上的任何重要数据。此操作将擦除 U 盘上的现有数据。 |
步骤 使用 dd 命令写入镜像
|
这个例子使用 |
-
命令行实用程序可在 BSD、Linux® 和 Mac OS® 系统上使用。要使用
dd烧录镜像,请插入 USB 闪存并确定其设备名称。然后,指定下载的安装文件的名称和 USB 闪存的设备名称。此示例将 amd64 安装镜像烧录到现有的 FreeBSD 系统上的第一个 USB 设备。# dd if=FreeBSD-13.1-RELEASE-amd64-memstick.img of=/dev/da0 bs=1M conv=sync如果此命令失败,请验证 USB 存储设备是否挂载,并且设备名称是磁盘而不是分区。
-
步骤。使用 Windows® 写入镜像 *
|
请务必提供正确的驱动器字母,因为指定驱动器上的现有数据将被覆盖和销毁。 |
-
获取 Windows® 的图像写入器
Image Writer for Windows® 是一个免费的应用程序,可以正确地将图像文件写入存储卡。从 win32diskimager 主页 下载并将其解压到一个文件夹中。
-
使用 Writing the Image 写入镜像
双击 Win32DiskImager 图标启动程序。确保在
Device下显示的驱动器字母是存储器的驱动器。点击文件夹图标并选择要写入存储器的镜像。点击 Save 接受镜像文件名。确认一切正确,并且存储器上没有其他窗口中打开的文件夹。当一切准备就绪时,点击 Write 将镜像文件写入存储器。
2.4. 开始安装
|
默认情况下,在以下消息之前,安装程序不会对磁盘进行任何更改: Your changes will now be written to disk. If you have chosen to overwrite existing data, it will be PERMANENTLY ERASED. Are you sure you want to commit your changes? 在出现此警告之前,可以随时退出安装。如果担心某些配置不正确,只需在此之前关闭计算机,系统磁盘将不会进行任何更改。 |
本节描述了如何从使用 准备安装介质 中的说明准备的安装介质引导系统。使用可启动的 USB 闪存驱动器时,在打开计算机之前插入 USB 闪存驱动器。从 CD 或 DVD 引导时,应在第一时间打开计算机并插入介质。如何配置系统以从插入的介质引导取决于体系结构。
2.4.1. FreeBSD 启动菜单
一旦系统从安装介质启动,将显示类似以下的菜单:
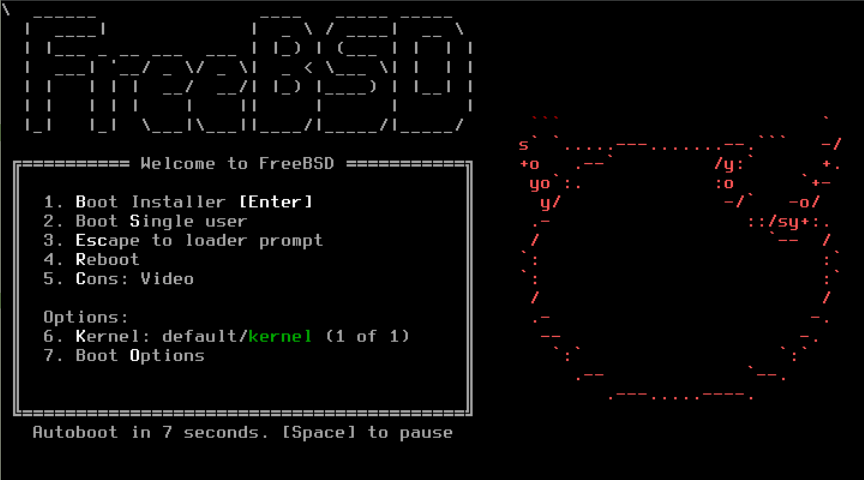
图 1. FreeBSD 引导加载程序菜单
默认情况下,菜单将在启动 FreeBSD 安装程序之前等待十秒钟以等待用户输入,或者如果 FreeBSD 已经安装,则在启动 FreeBSD 之前等待十秒钟。要暂停启动计时器以查看选择项,请按下空格键。要选择一个选项,请按下其突出显示的数字、字符或键。以下选项可用。
-
启动多用户模式(Boot Multi User):这将继续 FreeBSD 的启动过程。如果启动计时器已经暂停,请按下 1、大写或小写的 B 或 Enter 键。 -
单用户启动(Boot Single User): 这种模式可以用于修复已有的 FreeBSD 安装,如 ”单用户模式“ 中所述。按下键盘上的 2 或大写或小写的 S 进入此模式。 -
进入加载器提示符(Escape to loader prompt): 这将使系统启动到一个包含有限数量低级命令的修复提示符。该提示符在 “Stage Three” 中有描述。按下 3 或 Esc 键进入该提示符。 -
Reboot:重新启动系统。 -
Cons: 允许通过视频(video)、串口(serial)、双串口(串口为主)或双视频(视频为主)继续安装。 -
Kernel: 加载一个不同的内核。 -
引导选项(Boot Options):打开菜单,该菜单在 FreeBSD 启动选项菜单 中显示并描述。
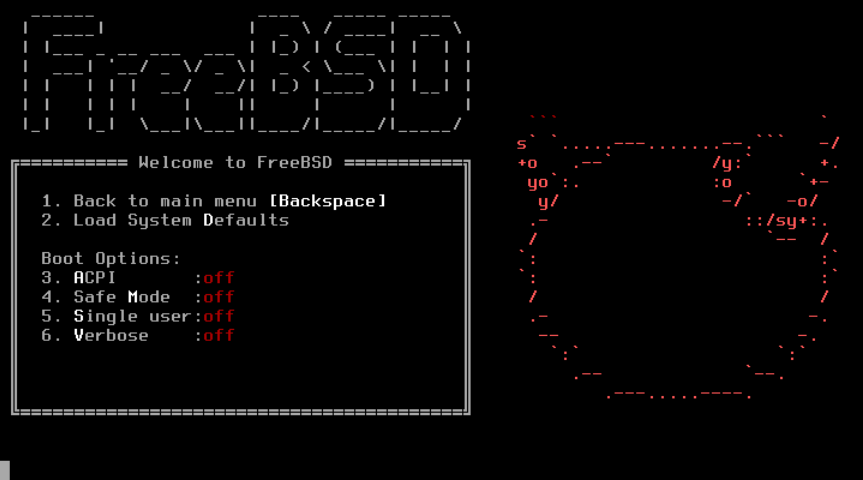
图 2. FreeBSD 启动选项菜单
启动选项菜单分为两个部分。第一部分可以用于返回主启动菜单或将任何切换选项重置为默认值。
下一节用于通过按下选项的突出显示的数字或字符来切换可用选项的状态为 On 或 Off。系统将始终使用这些选项的设置进行引导,直到它们被修改。可以使用此菜单切换多个选项的状态。
-
ACPI 支持(ACPI Support): 如果系统在启动过程中出现卡死的情况,请尝试将此选项切换为Off。 -
安全模式(Safe Mode):如果系统在启动时即使将ACPI Support设置为Off仍然出现卡顿的情况,请尝试将此选项设置为On。 -
单用户模式(Single User):将此选项切换为On,以修复现有的 FreeBSD 安装,如 “单用户模式” 中所述。一旦问题解决,将其设置为Off。 -
Verbose:将此选项切换为On以在启动过程中显示更详细的消息。在排除硬件问题时,这可能会很有用。
在进行所需的选择后,按下 1 或 Backspace 返回到主引导菜单,然后按下 Enter 继续引导进入 FreeBSD。FreeBSD 将执行其硬件设备探测和加载安装程序时,一系列引导消息将出现。引导完成后,将显示在 欢迎菜单 中显示的欢迎菜单。
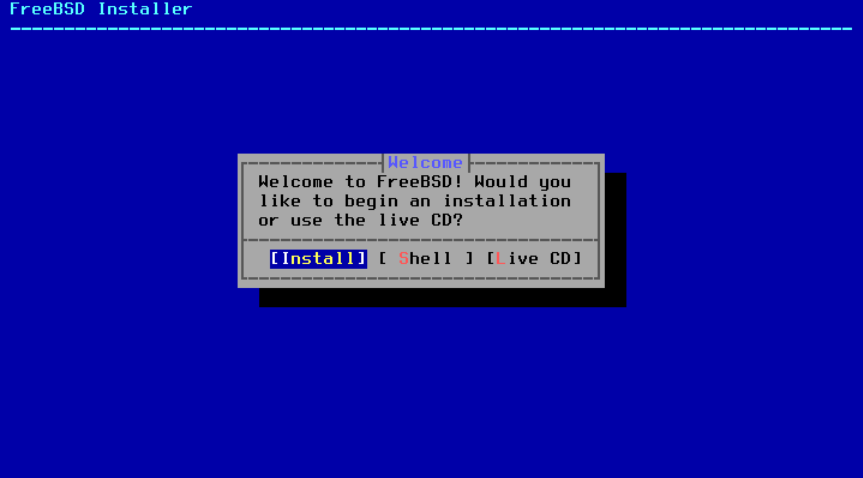
图 3. 欢迎菜单
按下 Enter 键选择默认的 Install 按钮进入安装程序。本章的其余部分将描述如何使用此安装程序。否则,使用右箭头、左箭头或带颜色的字母选择所需的菜单项。Shell 可用于访问 FreeBSD shell,以便在安装之前使用命令行实用程序准备磁盘。Live CD 选项可用于在安装之前尝试 FreeBSD。有关 live 版本的详细信息,请参阅 使用 Live CD 。
|
要查看启动消息,包括硬件设备探测,请按下大写或小写的 S,然后按下 Enter 以访问 shell。在 shell 提示符下,键入 |
2.5. 使用 bsdinstall
本节展示了 bsdinstall 菜单的顺序以及在系统安装之前将要询问的信息类型。使用箭头键来突出显示菜单选项,然后使用 Space 来选择或取消选择该菜单项。完成后,按下 Enter 保存选择并进入下一个屏幕。
2.5.1. 选择键映射菜单
在开始过程之前, bsdinstall 将加载键盘映射文件,如 按键映射加载中 所示。
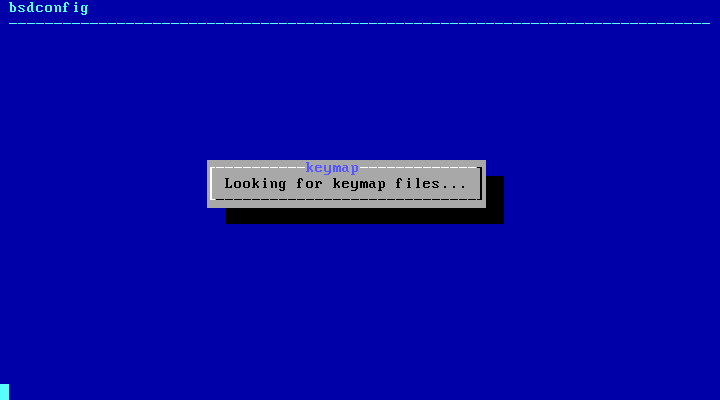
图 4. 按键映射加载中
在加载了键位映射之后, bsdinstall 会显示如 按键映射选择菜单 所示的菜单。使用上下箭头选择最接近系统连接的键盘映射的键位映射。按下 Enter 保存选择。
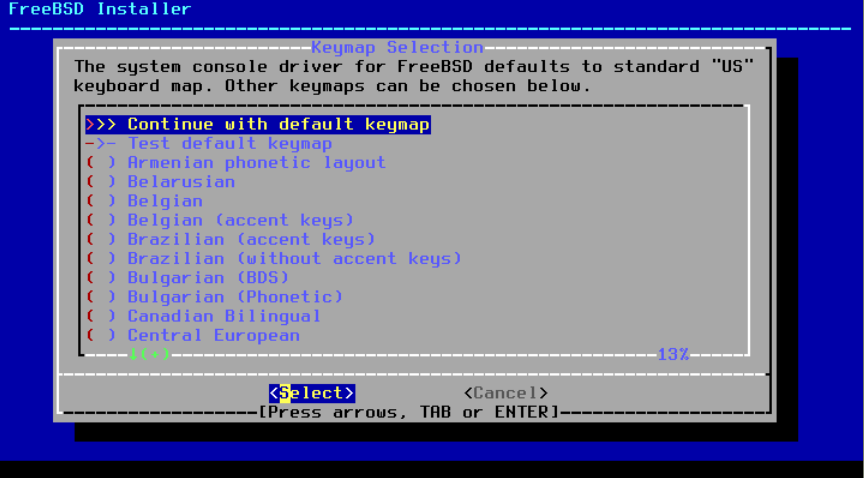
图 5. 按键映射选择菜单
|
按下 Esc 将退出此菜单并使用默认键映射。如果键映射的选择不明确, 也是一个安全的选项。 |
此外,在选择不同的键盘映射时,用户可以在继续之前尝试并确保它是正确的,如 按键映射测试菜单 所示。
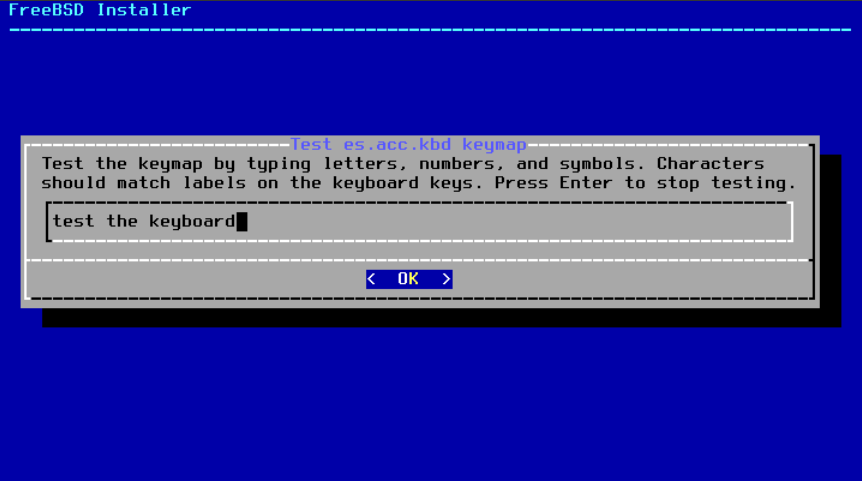
图 6. 按键映射测试菜单
2.5.2. 设置主机名
下一个 bsdinstall 菜单用于设置新安装系统的主机名。
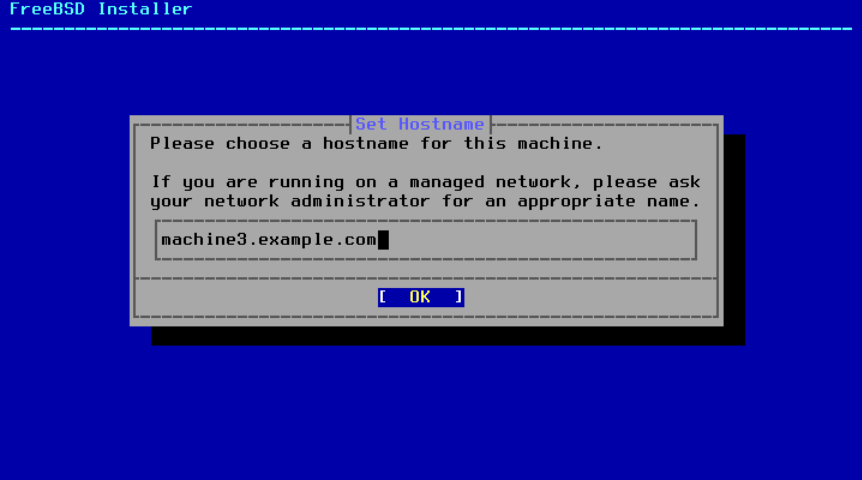
图 7. 设置主机名
输入一个在网络中唯一的主机名。它应该是一个完全合格的主机名,例如 machine3.example.com 。
2.5.3. 选择要安装的组件
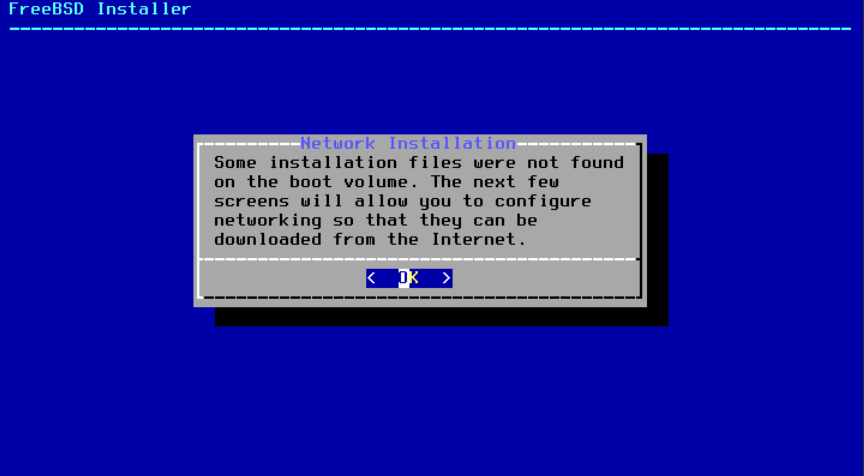
接下来, bsdinstall 将提示选择要安装的可选组件。
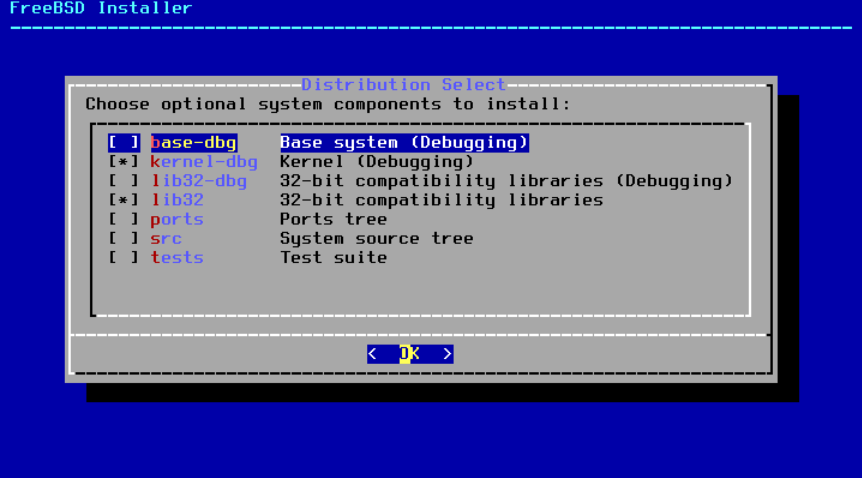
图 8. 选择要安装的组件
决定安装哪些组件将主要取决于系统的预期用途和可用的磁盘空间。 FreeBSD 内核和用户空间,统称为“基本系统”,始终会被安装。根据架构的不同,其中一些组件可能不会出现:
-
base-dbg- 基本工具,如 cat 和 ls 等,其中包含启用了调试符号的工具。 -
kernel-dbg- 启用了调试符号的内核和模块。 -
lib32-dbg- 在启用调试符号的 64 位 FreeBSD 版本上运行 32 位应用程序的兼容库。 -
lib32- 在 64 位版本的 FreeBSD 上运行 32 位应用程序的兼容性库。 -
ports- FreeBSD Ports Collection 是一组文件,用于自动下载、编译和安装第三方软件包。 安装应用程序:软件包和 Ports 讨论了如何使用 Ports Collection。安装程序不会检查磁盘空间是否足够。只有在有足够的硬盘空间时才选择此选项。 FreeBSD Ports 集合大约占用 3 GB 的磁盘空间。
-
src- 包含 FreeBSD 内核和用户空间的完整源代码。虽然大多数应用程序不需要它,但在构建设备驱动程序、内核模块或从 Ports Collection 中构建某些应用程序时可能需要它。它还用于开发 FreeBSD 本身。完整的源代码树需要 1 GB 的磁盘空间,重新编译整个 FreeBSD 系统需要额外的 5 GB 空间。 -
tests- FreeBSD 测试套件。
2.6. 分配磁盘空间
下一个菜单用于确定分配磁盘空间的方法。
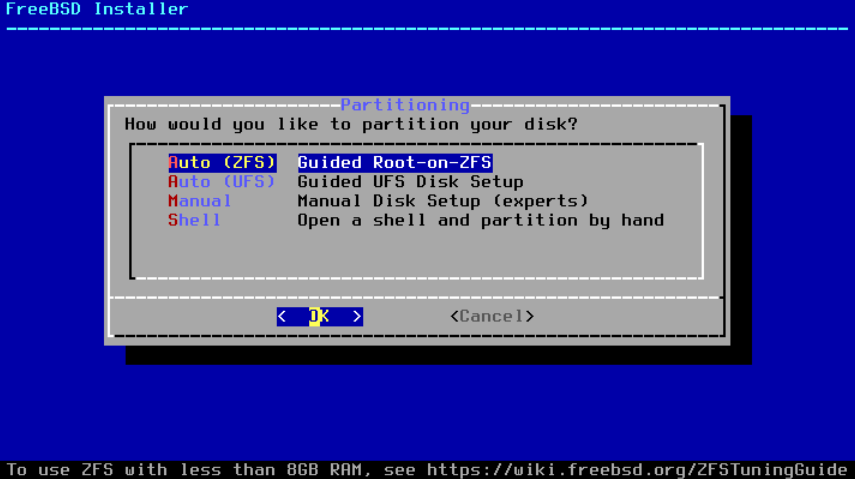
图 10. 分区选择
bsdinstall 为用户提供了四种分配磁盘空间的方法:
-
Auto (ZFS)分区创建一个基于 ZFS 的系统,可选择支持 GELI 加密用于 引导环境。 -
Auto (UFS)分区是使用UFS文件系统自动设置磁盘分区的功能。 -
Manual分区允许高级用户通过菜单选项创建自定义分区。 -
Shell打开一个 shell 提示符,高级用户可以使用命令行工具(如 gpart(8)、fdisk(8) 和 bsdlabel(8))创建自定义分区。
本节描述了在布置磁盘分区时需要考虑的事项。然后演示了如何使用不同的分区方法。
2.6.1. 设计分区布局
文件系统的默认分区布局包括一个用于整个系统的文件系统。当使用 UFS 时,如果您有足够的磁盘空间或多个磁盘,考虑使用多个文件系统可能是值得的。在布置文件系统时,请记住硬盘从外部轨道到内部传输数据速度更快。因此,较小且访问频率较高的文件系统应该靠近驱动器的外部,而像 /usr 这样的较大分区应该放置在磁盘的内部部分。按照类似的顺序创建分区是一个好主意: / 、交换空间、/var 和 /usr。
/var 分区的大小反映了预期机器的使用情况。该分区用于存储邮箱、日志文件和打印机队列。根据用户数量和日志文件保留时间的长短,邮箱和日志文件的大小可能会出乎意料地增长。通常情况下,大多数用户在 /var 分区中很少需要超过 1GB 的可用磁盘空间。
|
有时,在 |
/usr 分区存放着许多支持系统的文件,包括 FreeBSD Ports Collection 和系统源代码。建议为这个分区提供至少 2GB 的空间。此外,请注意,默认情况下,用户的家目录位于 /usr/home ,但也可以放在另一个分区上。默认情况下, /home 是指向 /usr/home 的符号链接。
在选择分区大小时,请考虑空间需求。在一个分区中空间不足,而另一个分区几乎未使用可能会带来麻烦。
作为一个经验法则,交换分区的大小应该是物理内存(RAM)的两倍左右。具有较小内存的系统(对于较大内存配置来说更少)可能在有更多交换空间时性能更好。配置过少的交换空间可能导致虚拟内存页面扫描代码的低效,并且如果添加更多内存后可能会引发问题。
在具有多个 SCSI 磁盘或多个在不同控制器上运行的 IDE 磁盘的较大系统上,建议在每个驱动器上配置交换空间,最多四个驱动器。交换分区的大小应该大致相同。内核可以处理任意大小,但内部数据结构会按照最大交换分区的 4 倍进行扩展。保持交换分区的大小接近相同,可以让内核以最佳方式在不同磁盘间条带化交换空间。较大的交换大小可能会引发有关总配置交换的内核警告消息。通过增加用于跟踪交换分配的内存量来提高限制,如警告消息所指示的那样。在被迫重新启动之前,从失控的程序中恢复可能更容易。
通过正确地分区系统,较小的写入密集分区引入的碎片不会波及到主要读取分区。将写入负载较重的分区保持在磁盘边缘附近,将提高在这些分区中发生的 I/O 性能。虽然可能需要较大分区的 I/O 性能,但将它们更靠近磁盘边缘不会比将 /var 移动到边缘带来显著的性能改善。
2.6.2. 使用 UFS 进行引导分区
当选择此方法时,菜单将显示可用的磁盘。如果连接了多个磁盘,请选择要安装 FreeBSD 的磁盘。
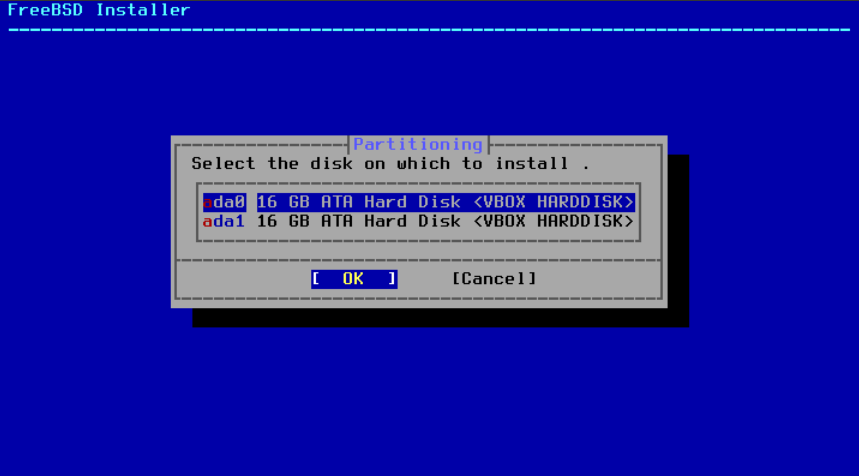
图 11. 从多个磁盘中进行选择
选择磁盘后,下一个菜单会提示选择是将整个磁盘安装,还是使用可用空间创建分区。如果选择 Entire Disk ,将自动创建一个填满整个磁盘的通用分区布局。选择 Partition 将从磁盘上未使用的空间创建一个分区布局。
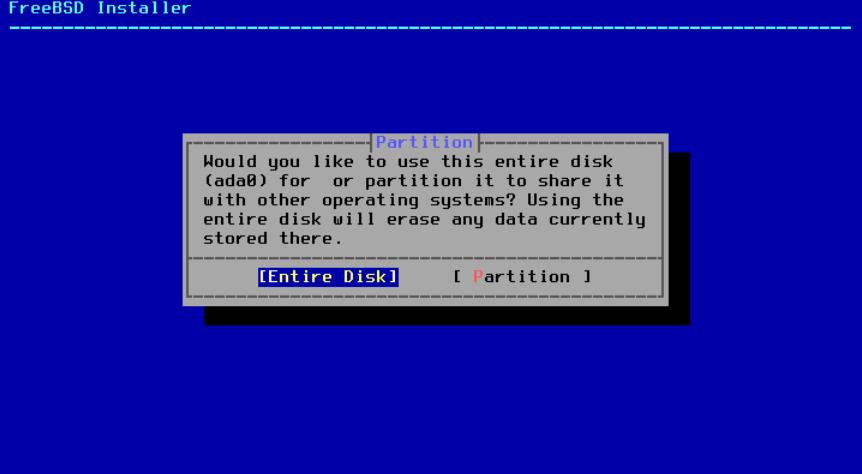
图 12. 选择整个磁盘或分区
选择 Entire Disk 选项后,bsdinstall 会显示一个对话框,指示将擦除磁盘。
图 13. 确认
下一个菜单显示了可用的分区方案类型列表。对于 amd64 计算机来说, GPT 通常是最合适的选择。不兼容 GPT 的旧计算机应该使用 MBR。其他分区方案通常用于不常见或较旧的计算机。有关更多信息,请参阅 分区方案 。
图 14. 选择分区方案
在创建分区布局之后,请进行审核以确保它满足安装的需求。选择 Revert 将重置分区为其原始值。按下 Auto 将重新创建自动的 FreeBSD 分区。分区也可以手动创建、修改或删除。当分区设置正确时,请选择 Finish 继续进行安装。
图 15. 审查已创建的分区
一旦磁盘配置完成,下一个菜单提供了在选择的驱动器格式化之前进行更改的最后机会。如果需要进行更改,请选择 返回 返回到主分区菜单。 还原和退出 退出安装程序,不对驱动器进行任何更改。否则,选择 提交 开始安装过程。
图 16. 最终确认
要继续安装过程,请转到 获取分发文件 。
2.6.3. 手动分区
选择此方法将打开分区编辑器:
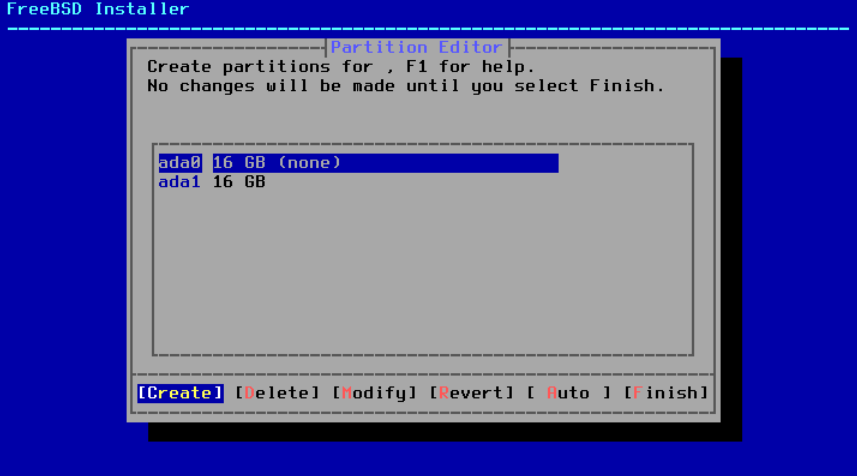
图 17. 手动创建分区
高亮显示安装驱动器(在此示例中为 ada0),然后选择 Create 以显示可用分区方案的菜单:
图 18. 手动创建分区
GPT 通常是 amd64 计算机的最合适选择。不兼容 GPT 的旧计算机应使用 MBR。其他分区方案通常用于不常见或较旧的计算机。
| 缩写 | 描述 |
|---|---|
APM |
Apple Partition Map,由 PowerPC® 使用。 |
BSD |
没有 MBR 的 BSD 标签,有时被称为 危险专用模式,因为非 BSD 磁盘工具可能无法识别它。 |
GPT |
GUID 分区表 。 |
MBR |
主引导记录 。 |
在选择和创建分区方案之后,再次选择 Create 来创建分区。使用 Tab 键将焦点放在字段上(在循环通过 <OK> 、 <Options> 和 <Cancel> 之后)。
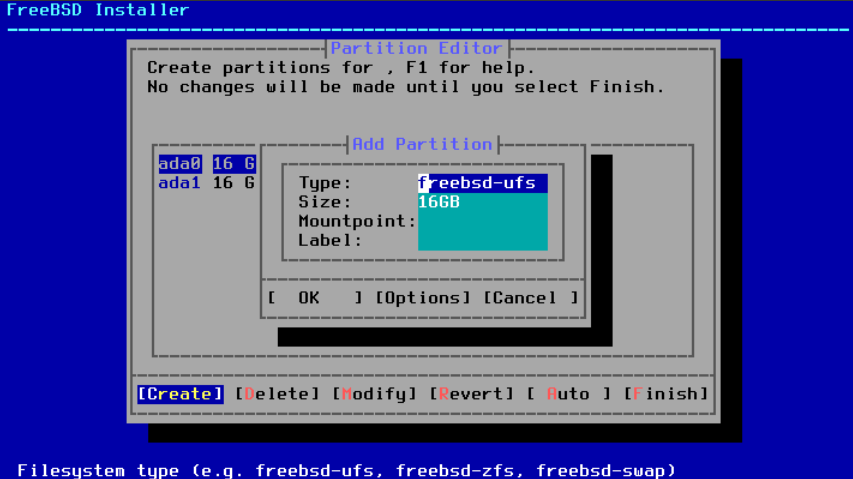
图 19. 手动创建分区
标准的 FreeBSD GPT 安装至少使用三个分区,其中包括 UFS 或 ZFS 之一:
-
freebsd-boot或efi- 存放着 FreeBSD 的引导代码。 -
freebsd-ufs- 一个 FreeBSD UFS 文件系统。 -
freebsd-zfs- 一个 FreeBSD 的 ZFS 文件系统。有关 ZFS 的更多信息,请参阅 Z 文件系统(ZFS) 。 -
freebsd-swap- FreeBSD 交换空间。
请参考 gpart(8),了解可用的 GPT 分区类型的描述。
可以创建多个文件系统分区。有些人喜欢传统的布局,将 /、/var、/tmp 和 /usr 分别放在不同的分区中。
|
请注意,在具有足够内存的系统上,可以将 |
请参考 创建传统的分割文件系统分区 中的示例。
Size 可以使用常见的缩写进行输入:K 表示千字节,M 表示兆字节,G 表示吉字节。
|
正确的扇区对齐可以提供最佳性能,将分区大小设置为 4K 字节的倍数有助于确保在具有 512 字节或 4K 字节扇区的驱动器上进行对齐。通常,使用 1M 或 1G 的倍数作为分区大小是确保每个分区从 4K 的倍数开始的最简单方法。有一个例外:由于当前引导代码的限制,freebsd-boot 分区的大小不应超过 512K 。 |
如果分区将包含文件系统,则需要一个 Mountpoint 。如果只创建一个 UFS 分区,则挂载点应为 /。
Label 是分区的名称。如果驱动器连接到不同的控制器或端口,驱动器名称或编号可能会发生变化,但分区标签不会改变。在像 /etc/fstab 这样的文件中使用标签而不是驱动器名称和分区编号,可以使系统更容忍硬件变化。当连接了磁盘时,GPT 标签会出现在 /dev/gpt/ 中。其他分区方案具有不同的标签功能,它们的标签会出现在 /dev/ 中的不同目录中。
|
在每个分区上使用唯一的标签,以避免相同标签引起的冲突。可以在标签中添加计算机名称、用途或位置的几个字母。例如,对于名为 |
例 1. 创建传统的分割文件系统分区
对于传统的分区布局,其中 /、/var、/tmp 和 /usr 目录是各自独立的文件系统,创建一个 GPT 分区方案,然后按照所示创建分区。所示的分区大小适用于 20G 目标磁盘。如果目标磁盘上有更多的空间,可以考虑使用更大的交换空间或 /var 分区。这里显示的标签以 ex 为前缀,表示"示例",但读者应根据上述说明使用其他唯一的标签值。
默认情况下,FreeBSD 的 gptboot 期望第一个 UFS 分区是 / 分区。
| 分区类型 | 大小 | 挂载点 | 标签 |
|---|---|---|---|
|
|
||
|
|
|
|
|
|
` |
|
|
|
|
|
|
|
|
|
|
接受默认选项(使用磁盘的剩余空间)。 |
|
|
在创建自定义分区后,选择 Finish 继续安装并转到 获取分发文件 。
2.6.4. 使用 Root-on-ZFS 进行引导分区
这种分区模式只适用于整个磁盘,并且会擦除整个磁盘的内容。主要的 ZFS 配置菜单提供了一些选项来控制池的创建。
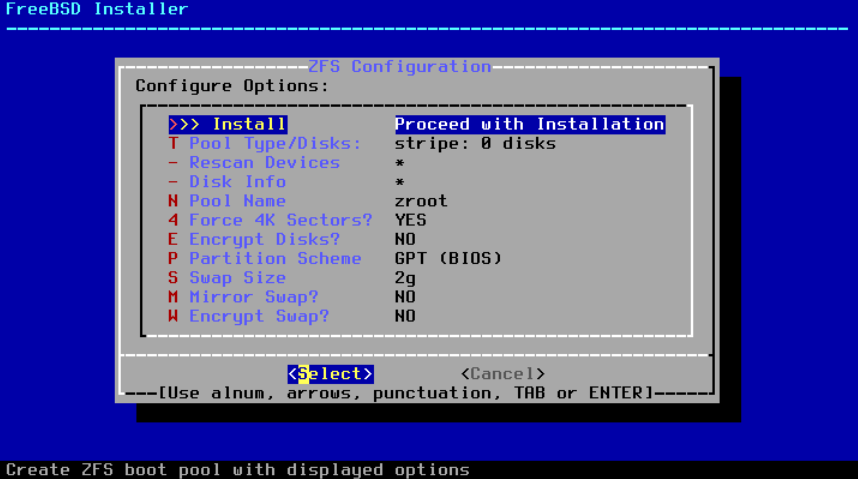
图 20. ZFS 分区菜单
这是该菜单中选项的摘要:
-
安装(Install)- 使用所选选项继续安装。 -
` 池类型及磁盘(Pool Type/Disks)` - 配置
池类型和组成池的磁盘。自动 ZFS 安装程序目前只支持创建单个顶级 vdev,除非是 stripe 模式。要创建更复杂的池,请使用 Shell 模式分区 中的说明来创建池。 -
重新扫描设备(Rescan Devices)- 重新填充可用磁盘列表。 -
磁盘信息(Disk Info)- 此菜单可用于检查每个磁盘,包括其分区表和其他各种信息,如设备型号和序列号(如果可用)。 -
池名称(Pool Name)- 设置池的名称。默认名称为 zroot。 -
强制使用 4K 扇区(Force 4K Sectors)?- 强制使用 4K 扇区。默认情况下,安装程序将自动创建与 4K 边界对齐的分区,并强制 ZFS 使用 4K 扇区。即使是 512 字节扇区的磁盘,这也是安全的,并且还有一个额外的好处,即确保在将来可以将 4K 扇区磁盘添加到在 512 字节磁盘上创建的池中,无论是作为额外的存储空间还是作为替换失败的磁盘。按下 Enter 键选择是否激活它。 -
加密磁盘(Encrypt Disks)?- 加密磁盘允许用户使用 GELI 对磁盘进行加密。有关磁盘加密的更多信息,请参阅 “使用 geli 进行磁盘加密”。按下 Enter 键选择是否激活它。 -
分区方案(Partition Scheme)- 选择分区方案。在大多数情况下,GPT 是推荐的选项。按下 Enter 键来在不同选项之间进行选择。 -
交换空间大小(Swap Size)- 设置交换空间的大小。 -
镜像交换分区(Mirror Swap)?- 是否在磁盘之间进行交换分区的镜像。请注意,启用镜像交换分区将会破坏崩溃转储。按下 Enter 键来激活或不激活。 -
加密交换空间(Encrypt Swap)?- 是否加密交换空间。这将在每次系统启动时使用临时密钥加密交换空间,并在重新启动时丢弃它。按下 Enter 键选择是否激活。有关加密交换空间的更多信息,请参阅 “加密交换空间” 。
选择 T 来配置 池类型 和组成池的磁盘。
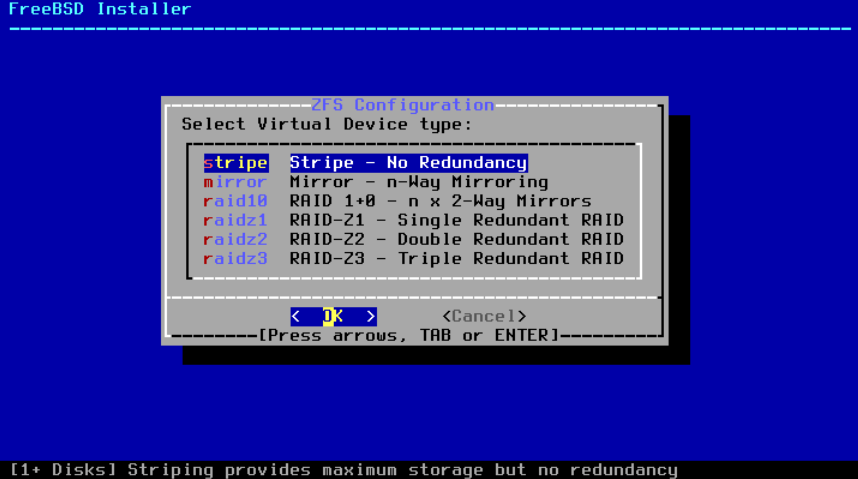
图 21. ZFS 池类型
这是一个关于此菜单中可选择的 池类型 的摘要:
-
stripe- 条带化提供了最大的存储空间,但没有冗余。如果只有一个磁盘故障,池中的数据将无法恢复。 -
镜像(mirror)- 镜像将所有数据完整地存储在每个磁盘上。镜像提供良好的读取性能,因为数据可以并行从所有磁盘中读取。写入性能较慢,因为数据必须写入池中的所有磁盘。允许除一个磁盘外的所有磁盘故障。此选项至少需要两个磁盘。 -
raid10- 镜像条带化。提供最佳性能,但存储空间最少。此选项至少需要偶数个磁盘和至少四个磁盘。 -
raidz1- 单冗余 RAID 。允许同时故障一个磁盘。此选项至少需要三个磁盘。 -
raidz2- 双冗余 RAID 。允许同时故障两个磁盘。此选项至少需要四个磁盘。 -
raidz3- 三重冗余 RAID 。允许同时故障三个磁盘。此选项至少需要五个磁盘。
一旦选择了 池类型,将显示可用磁盘列表,并提示用户选择一个或多个磁盘来组成池。然后,将验证配置以确保选择了足够的磁盘。如果验证失败,请选择 <Change Selection> 返回到磁盘列表,或选择 <Back> 更改 池类型。
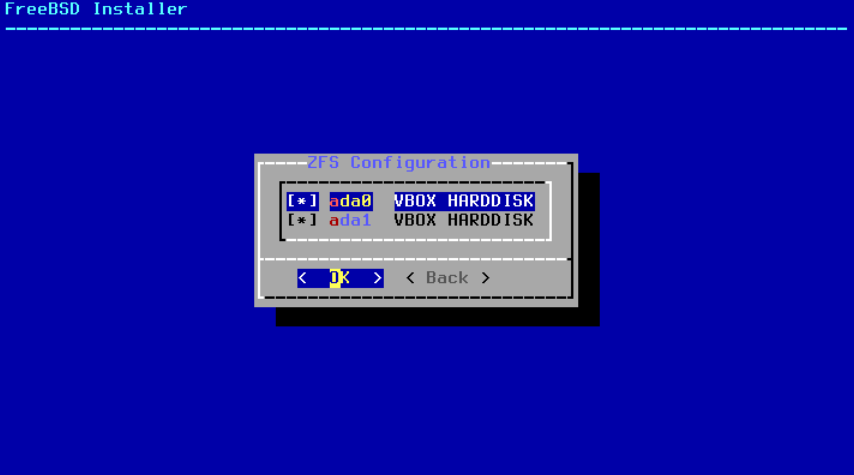
图 22. 磁盘选择
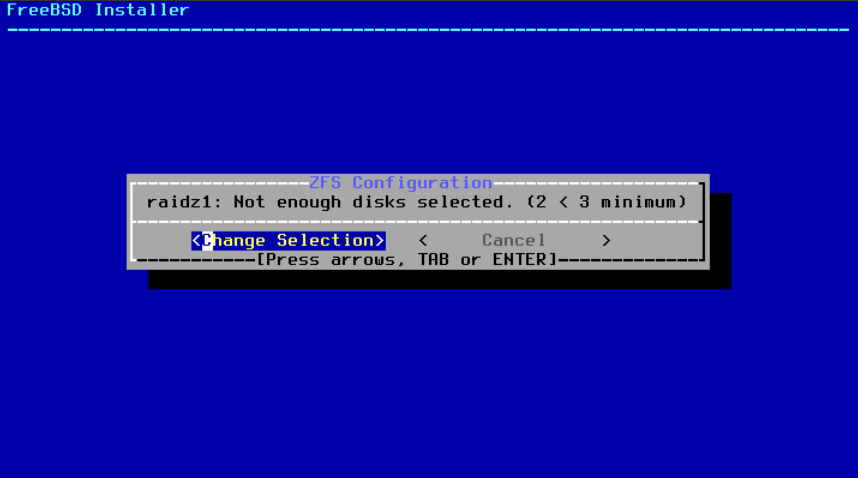
图 23. 无效选择
如果列表中缺少一个或多个磁盘,或者在启动安装程序后附加了磁盘,请选择 - Rescan Devices 以重新填充可用磁盘列表。
图 24. 重新扫描设备
为了避免意外擦除错误的磁盘,可以使用 - Disk Info 菜单来检查每个磁盘,包括其分区表和其他各种信息,如设备型号和序列号(如果有)。
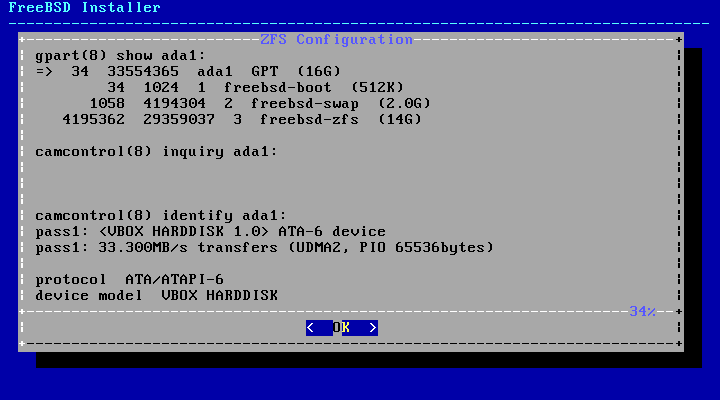
图 25. 分析磁盘
选择 N 来配置 池名称。输入所需的名称,然后选择 <OK> 来确认,或选择 <Cancel> 返回主菜单并保留默认名称。
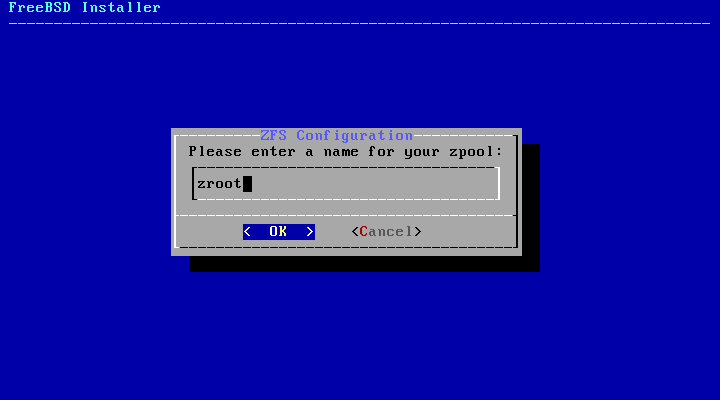
图 26. 池名称
选择 S 来设置交换空间的大小。输入所需的交换空间大小,然后选择 <OK> 来确认设置,或选择 <Cancel> 返回主菜单并使用默认大小。
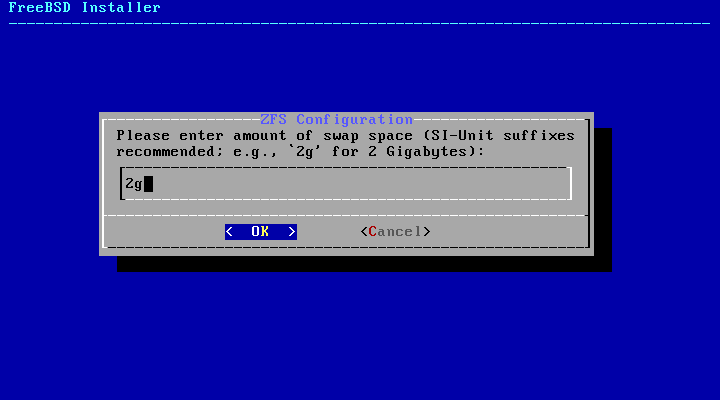
图 27. 交换空间大小
一旦所有选项都设置为所需的值,选择菜单顶部的 >>> Install 选项。然后安装程序会在销毁所选驱动器的内容以创建 ZFS 池之前,提供最后一次取消的机会。
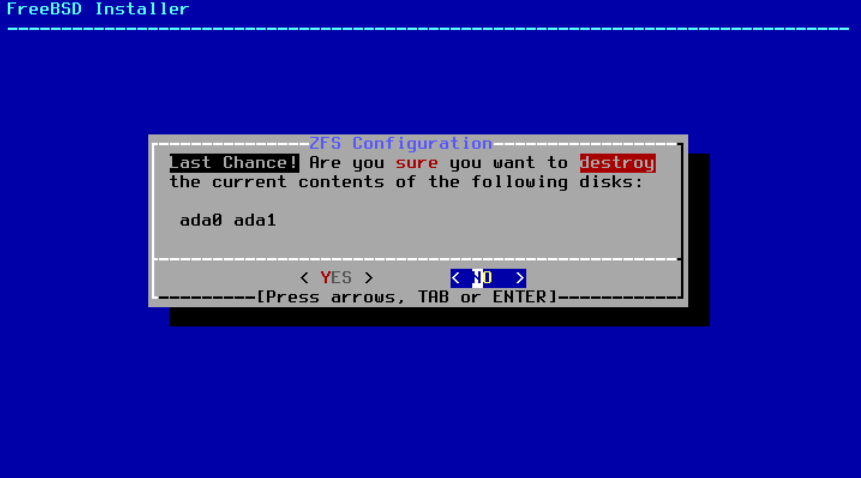
图 28. 最后机会
如果启用了 GELI 磁盘加密,安装程序将会两次提示输入用于加密磁盘的密码短语。然后,加密的初始化过程开始。
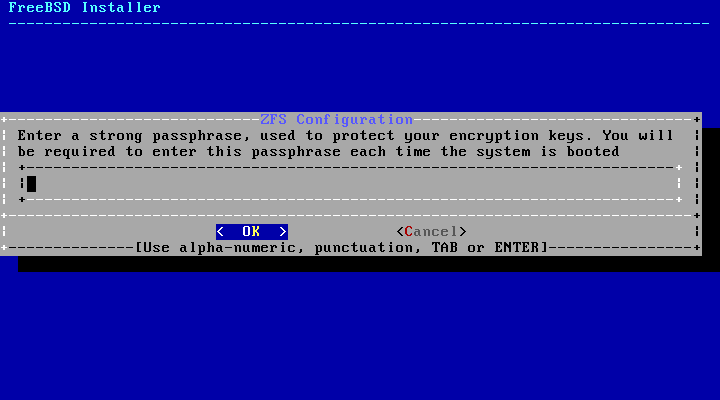
图 29. 磁盘加密密码
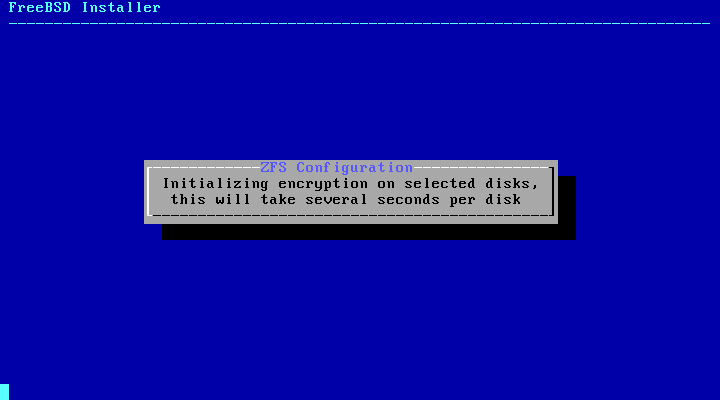
图 30. 初始化加密
安装然后正常进行。要继续安装,请转到 获取分发文件 。
2.7. 获取分发文件
安装时间将根据所选择的发行版、安装介质和计算机速度而有所不同。一系列的消息将指示安装的进度。
首先,安装程序会格式化所选磁盘并初始化分区。接下来,在选择了 仅引导媒体 或 迷你内存棒 的情况下,它会下载所选组件:
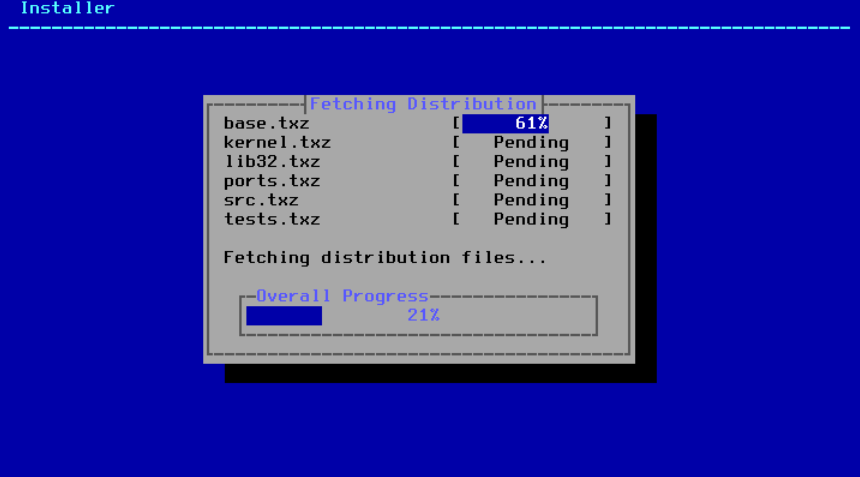
图 31. 获取分发文件
接下来,将验证分发文件的完整性,以确保在下载过程中没有损坏或在安装介质中读取错误:
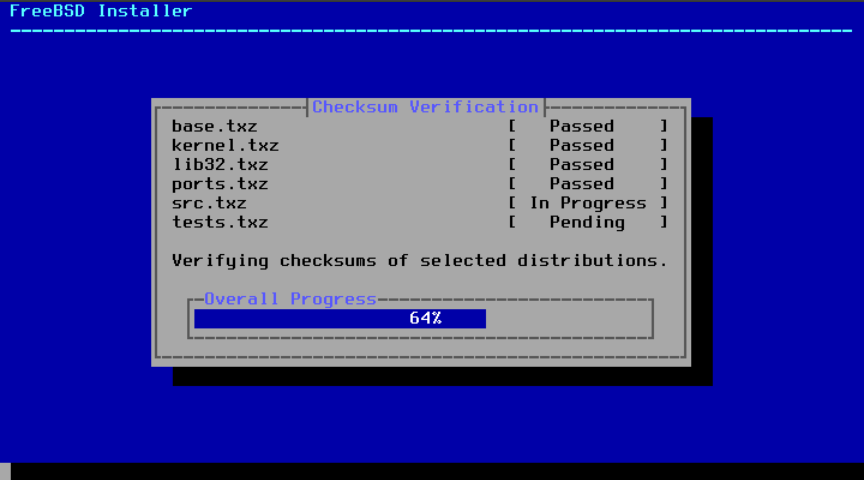
图 32. 验证分发文件
最后,验证过的分发文件被解压到磁盘上:
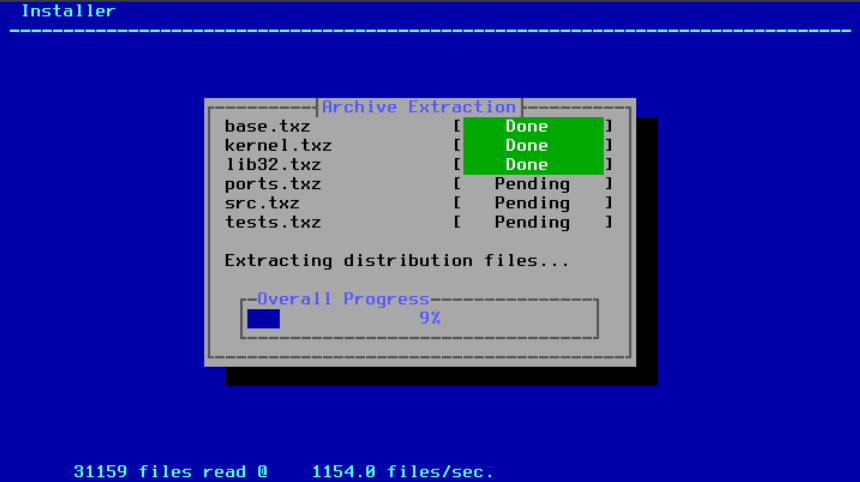
图 33. 提取分发文件
一旦提取了所有请求的分发文件, bsdinstall 将显示第一个安装后配置屏幕。下一节将介绍可用的后配置选项。
2.8. 网络接口,账户,时区,服务和加固
2.8.2. 配置网络接口
接下来,将显示计算机上找到的网络接口列表。请选择要配置的接口。
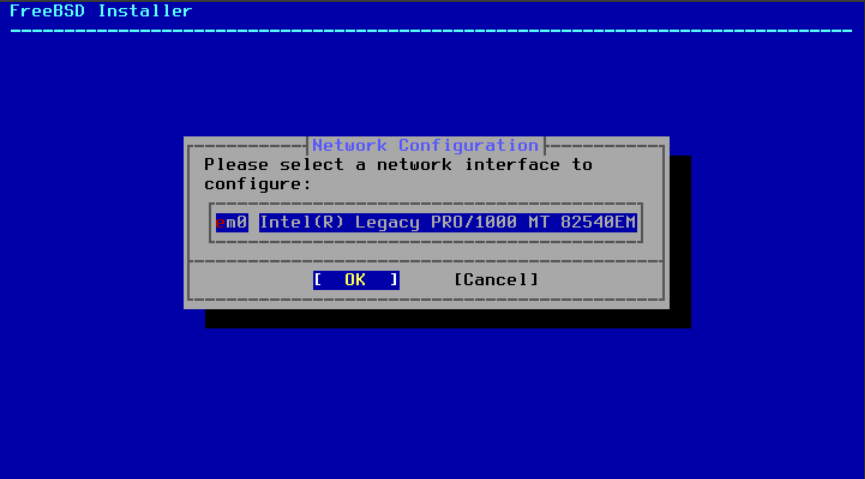
图 35. 选择一个网络接口
如果选择了以太网接口,安装程序将直接跳转到 选择 IPv4 网络 中显示的菜单。如果选择了无线网络接口,系统将会扫描无线接入点:
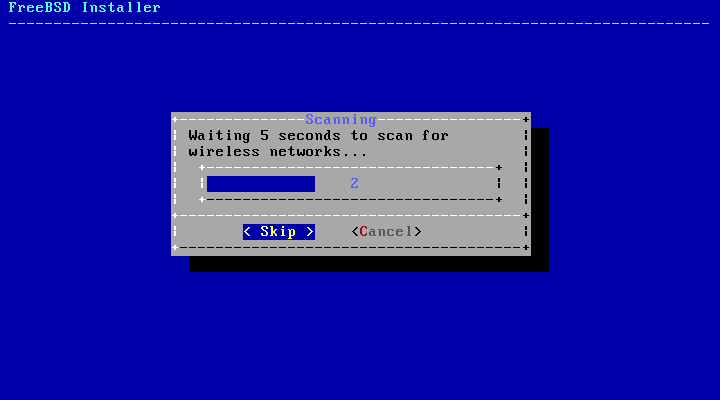
图 36. 扫描无线接入点
无线网络通过服务集标识符(SSID)进行识别,每个网络都有一个短而独特的名称。扫描期间找到的 SSID 将列出,然后是该网络可用的加密类型的描述。如果所需的 SSID 在列表中未出现,请选择 Rescan 进行再次扫描。如果所需的网络仍未出现,请检查天线连接是否有问题,或尝试将计算机移动到接入点附近。每次更改后都要重新扫描。
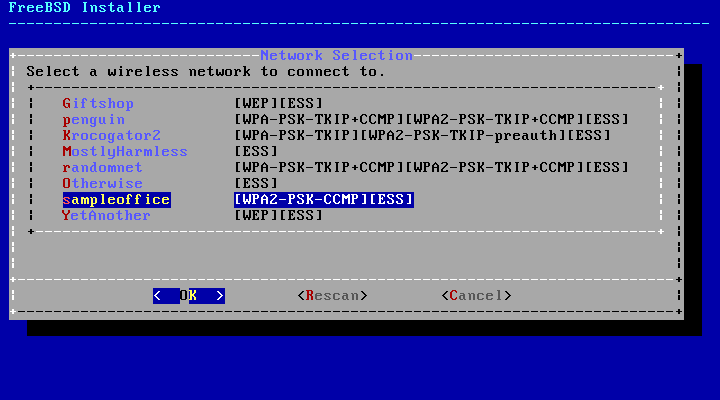
图 37. 选择无线网络
接下来,请输入连接到所选无线网络的加密信息。强烈建议使用 WPA2 加密,而不是较旧的加密类型,如 WEP ,因为 WEP 提供的安全性很低。如果网络使用 WPA2,请输入密码,也称为预共享密钥(PSK)。出于安全原因,输入框中键入的字符将显示为星号。
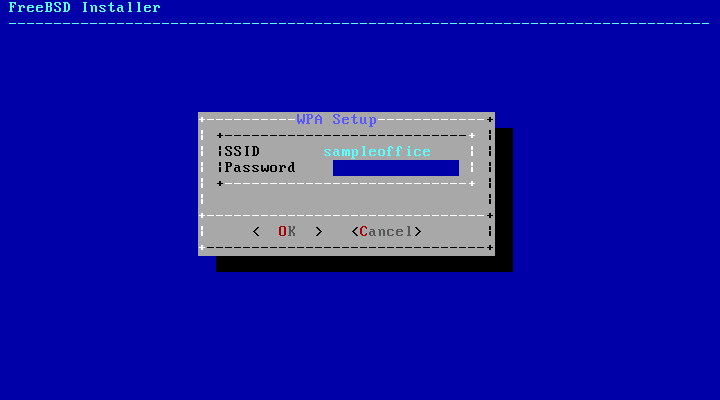
图 38. WPA2 设置
接下来,选择是否在以太网或无线接口上配置 IPv4 地址:
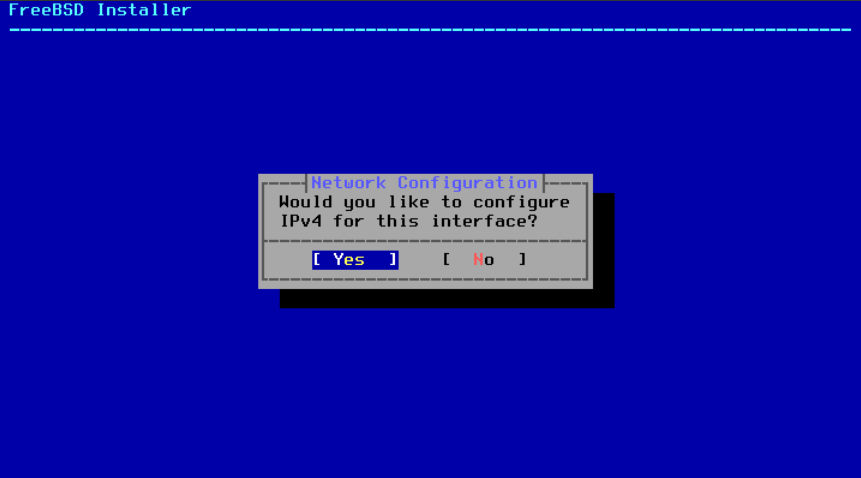
图 39. 选择 IPv4 网络
IPv4 配置有两种方法。如果网络提供了 DHCP 服务器,DHCP 将自动正确配置网络接口,并且应该使用 DHCP。否则,需要手动输入地址信息作为静态配置。
|
请不要输入随机的网络信息,因为它不会起作用。如果没有 DHCP 服务器可用,请向网络管理员或互联网服务提供商获取 所需网络信息 中列出的信息。 |
如果有 DHCP 服务器可用,请在下一个菜单中选择 Yes 以自动配置网络接口。安装程序将会暂停一分钟左右,以便找到 DHCP 服务器并获取系统的地址信息。
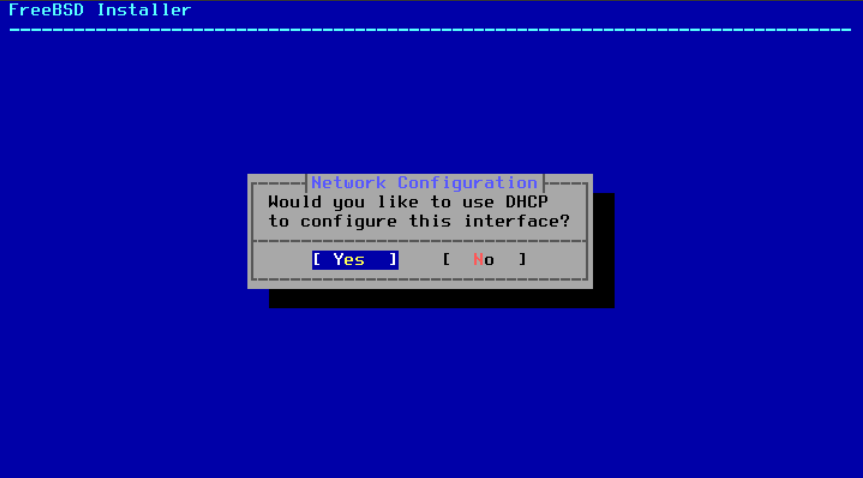
图 40. 选择 IPv4 DHCP 配置
如果没有可用的 DHCP 服务器,请选择 No,并在此菜单中输入以下寻址信息:
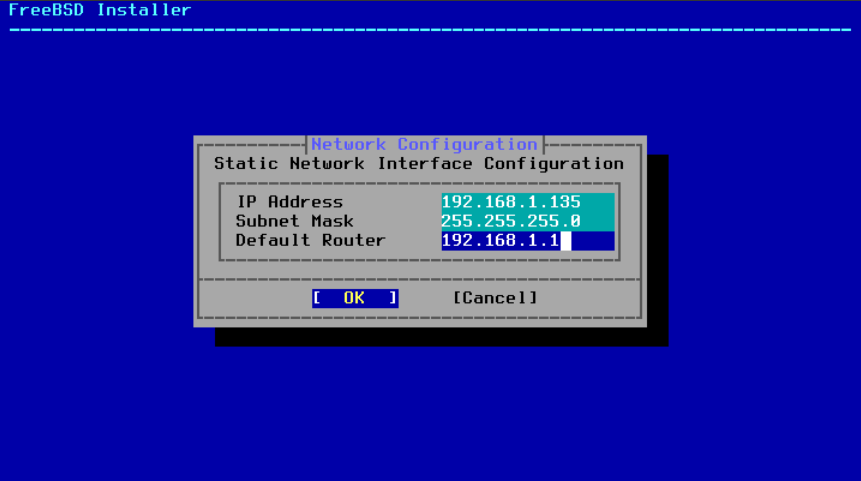
图 41. IPv4 静态配置
-
IP 地址(IP Address)- 分配给此计算机的 IPv4 地址。该地址必须是唯一的,并且在本地网络上没有被其他设备使用。 -
子网掩码(Subnet Mask)- 网络的子网掩码。 -
默认路由器(Default Router)- 网络的默认网关的 IP 地址。
下一个屏幕将询问是否应该为 IPv6 配置接口。如果 IPv6 可用且需要,请选择 Yes 来选择它。
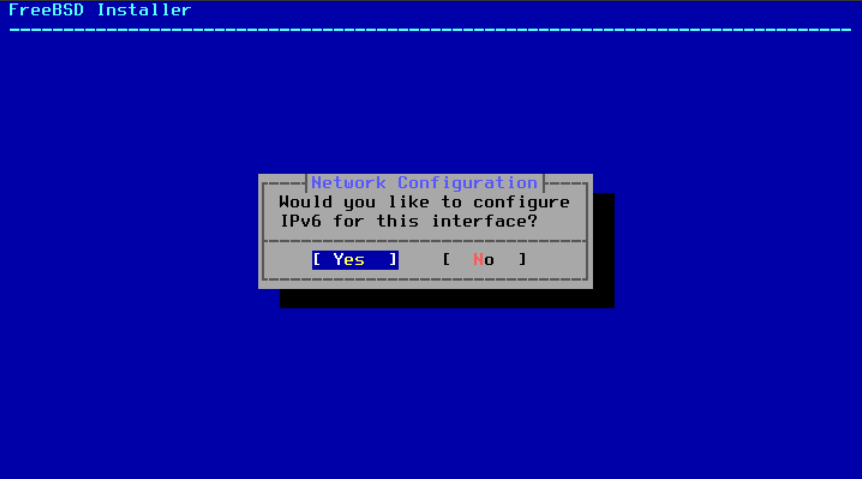
图 42. 选择 IPv6 网络
IPv6 还有两种配置方法。无状态地址自动配置(SLAAC)将自动从本地路由器请求正确的配置信息。有关更多信息,请参阅 rfc4862。静态配置需要手动输入网络信息。
如果有 IPv6 路由器可用,请在下一个菜单中选择 Yes 以自动配置网络接口。安装程序将会暂停一分钟左右,以查找路由器并获取系统的寻址信息。
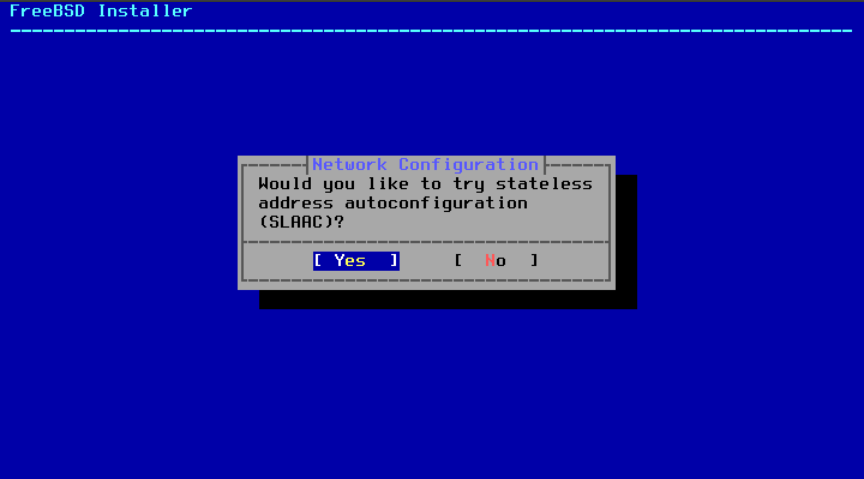
图 43. 选择 IPv6 SLAAC 配置
如果没有可用的 IPv6 路由器,请选择 No 并在此菜单中输入以下寻址信息:
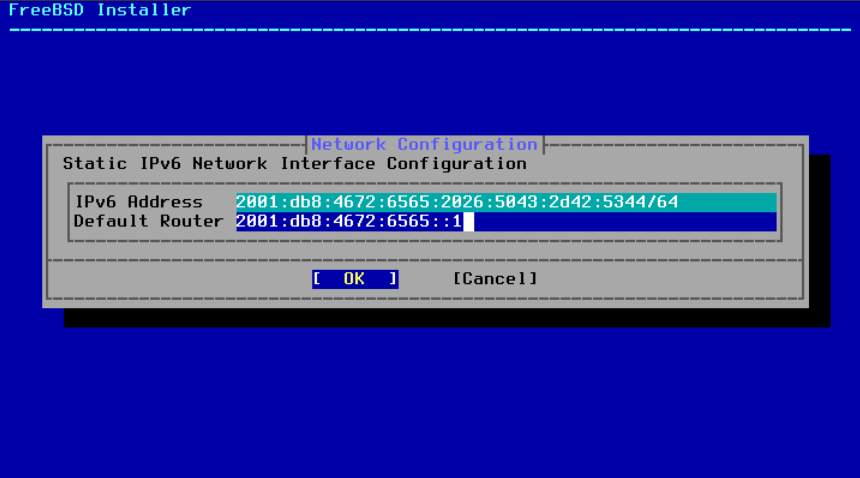
图 44. IPv6 静态配置
-
IPv6 地址(IPv6 Address)- 分配给此计算机的 IPv6 地址。该地址必须是唯一的,并且在本地网络中没有被其他设备使用。 -
默认路由器(Default Router)- 网络的默认网关的 IPv6 地址。
最后一个网络配置菜单用于配置域名系统(DNS)解析器,该解析器将主机名转换为网络地址,并且可以将网络地址转换为主机名。如果使用 DHCP 或 SLAAC 自动配置网络接口,则 解析器配置(Resolver Configuration) 值可能已经填写。否则,请在 搜索(Search) 字段中输入本地网络的域名。DNS #1 和 DNS #2 是 DNS 服务器的 IPv4 和 / 或 IPv6 地址。至少需要一个 DNS 服务器。
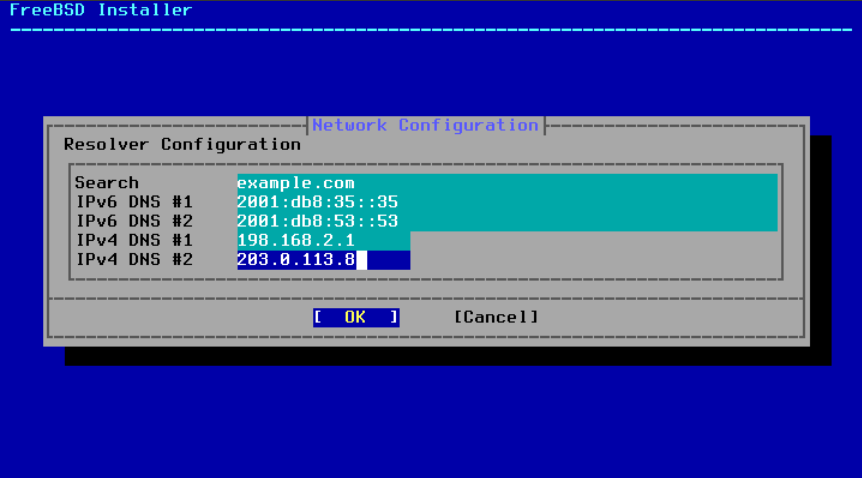
图 45. DNS 配置
一旦配置了接口,选择一个位于与安装 FreeBSD 的计算机相同地区的镜像站点。当镜像站点靠近目标计算机时,可以更快地检索文件,从而减少安装时间。
|
选择 |
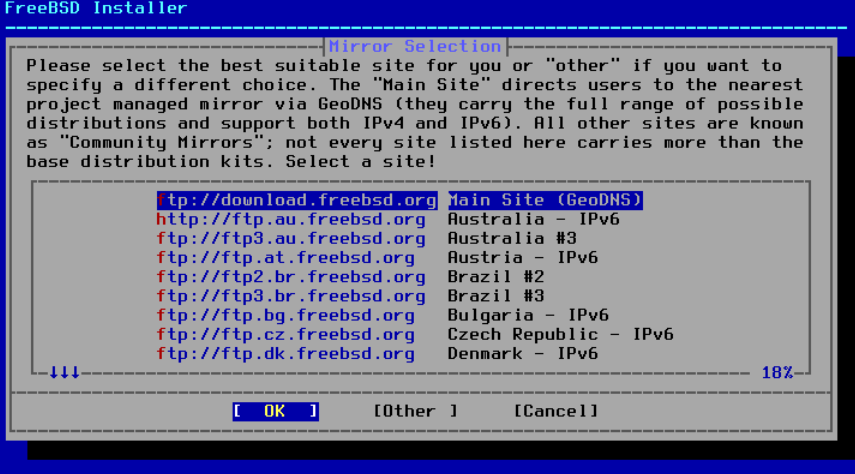
图 46. 选择镜像源
2.8.3. 设置时区
下一系列菜单用于通过选择地理区域、国家和时区来确定正确的本地时间。设置时区允许系统自动校正区域时间变化,如夏令时,并正确执行其他与时区相关的功能。
这里展示的示例适用于位于西班牙欧洲大陆时区的机器。根据地理位置的不同,选择项会有所变化。
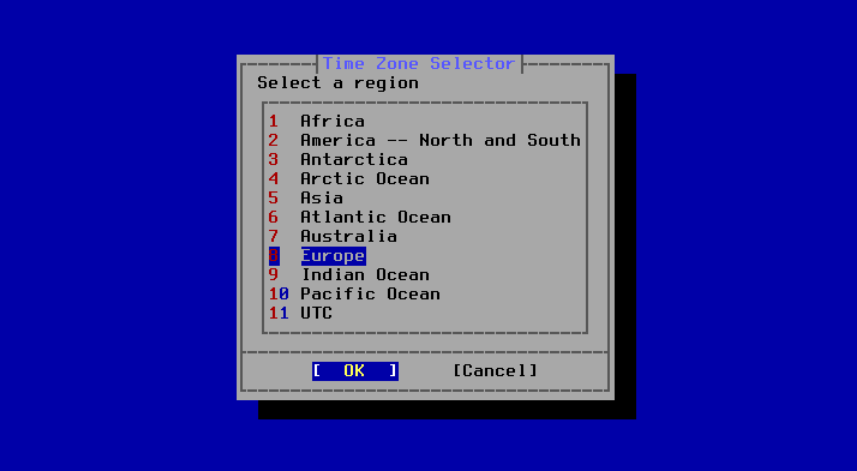
图 47. 选择一个地区
使用箭头键选择适当的区域,然后按下 Enter 键。
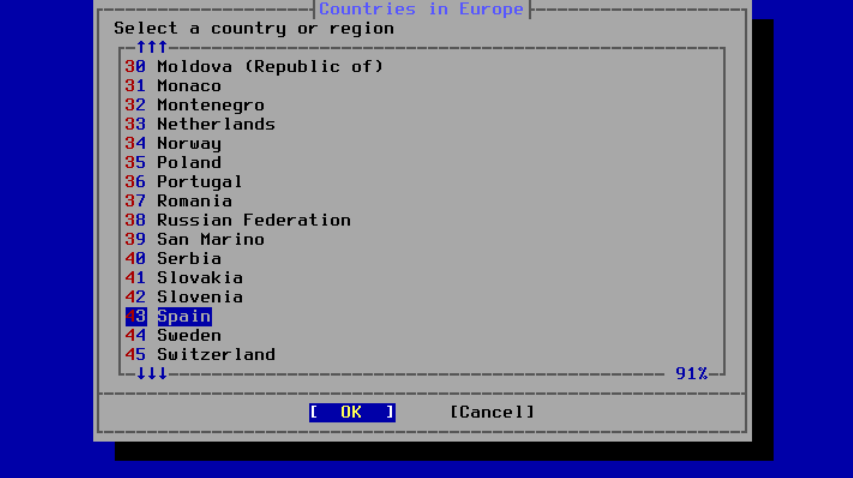
图 48. 选择一个国家
使用箭头键选择适当的国家,然后按下键盘上的 [Enter] 键。
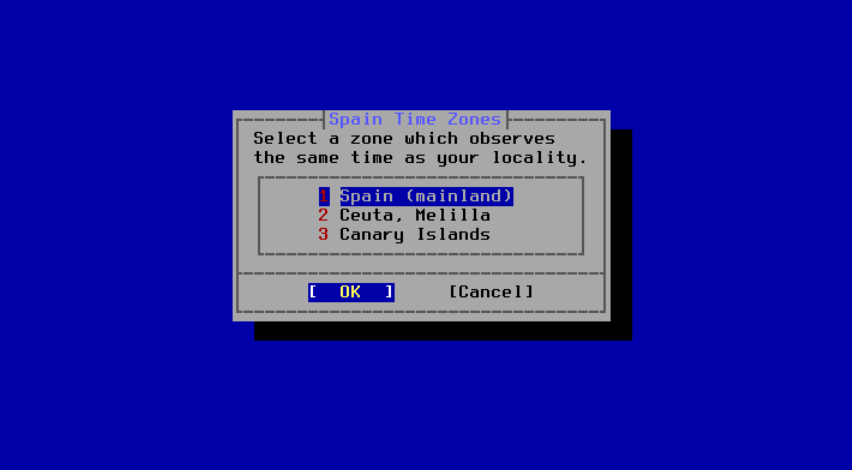
图 49. 选择一个时区
使用箭头键选择适当的时区,然后按下 Enter 键确认。
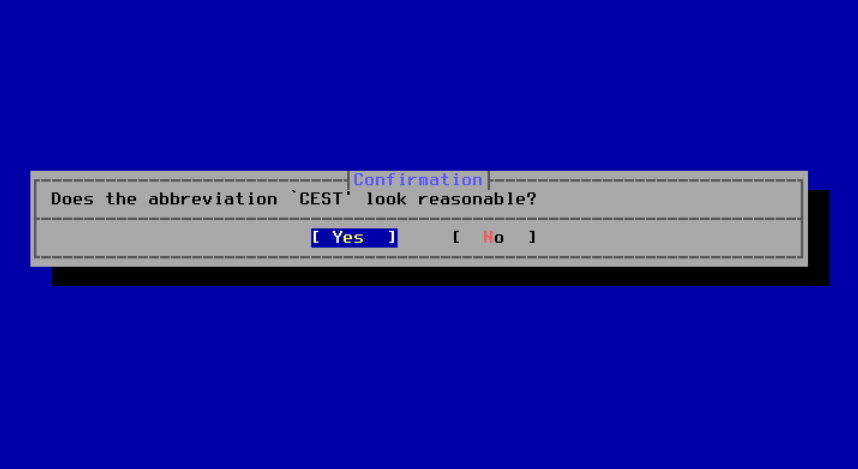
图 50. 确认时区
请确认时区的缩写是否正确。
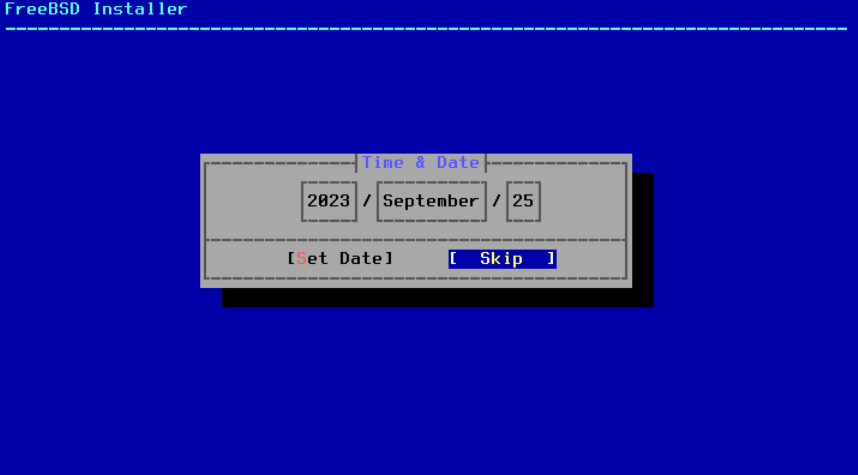
图 51. 选择日期
使用箭头键选择适当的日期,然后按下 Set Date 。否则,可以通过按下 Skip 来跳过日期选择。
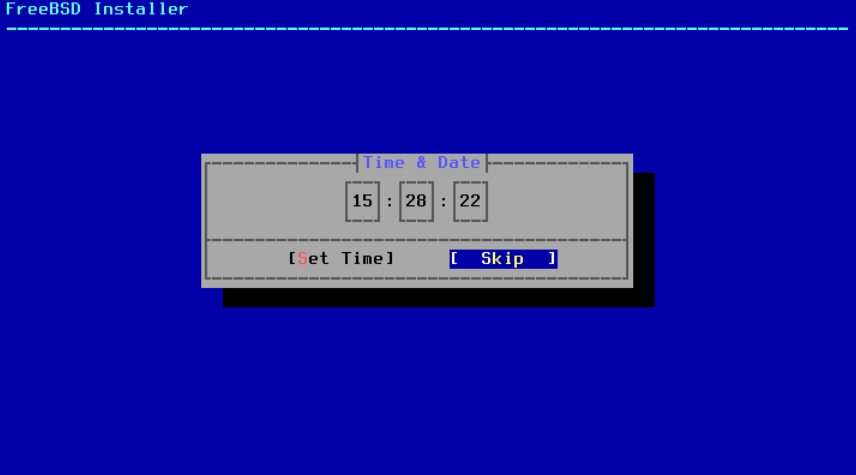
图 52. 选择时间
使用箭头键选择适当的时间,然后按下 Set Time 。否则,可以通过按下 Skip 来跳过时间选择。
2.8.4. 启用服务
下一个菜单用于配置系统启动时将启动哪些系统服务。所有这些服务都是可选的。只启动系统运行所需的服务。
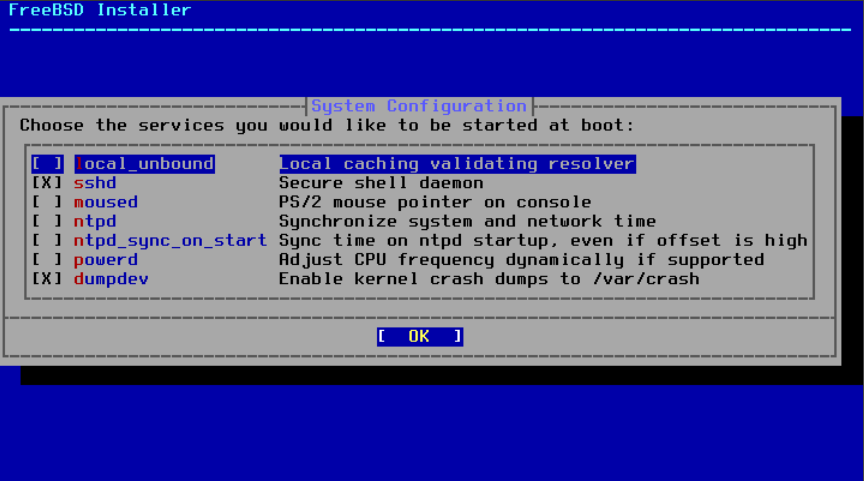
图 53. 选择启用附加服务
这里是可以在此菜单中启用的服务的摘要:
-
local_unbound- 启用本地 DNS 解析器 unbound 。需要注意的是,这个配置只适用于作为本地缓存转发解析器使用。如果目标是为整个网络设置解析器,请安装dns/unbound软件包。 -
sshd- 安全 Shell(SSH)守护进程用于通过加密连接远程访问系统。只有在系统需要提供远程登录时才启用此服务。 -
moused- 如果希望从命令行系统控制台使用鼠标,请启用此服务。 -
ntpdate- 在启动时启用自动时钟同步。请注意,该程序的功能现在已经整合到ntpd(8)守护进程中,ntpdate(8)实用程序将很快被弃用。 -
ntpd- 自动时钟同步的网络时间协议(NTP)守护进程。如果您希望将系统时钟与远程时间服务器或时间池同步,请启用此服务。 -
powerd- 用于系统电源控制和节能的实用程序。 -
dumpdev- 崩溃转储在调试系统问题时非常有用,因此鼓励用户启用它们。
2.8.5. 启用强化安全选项
下一个菜单用于配置启用的安全选项。所有这些选项都是可选的,但建议使用它们。
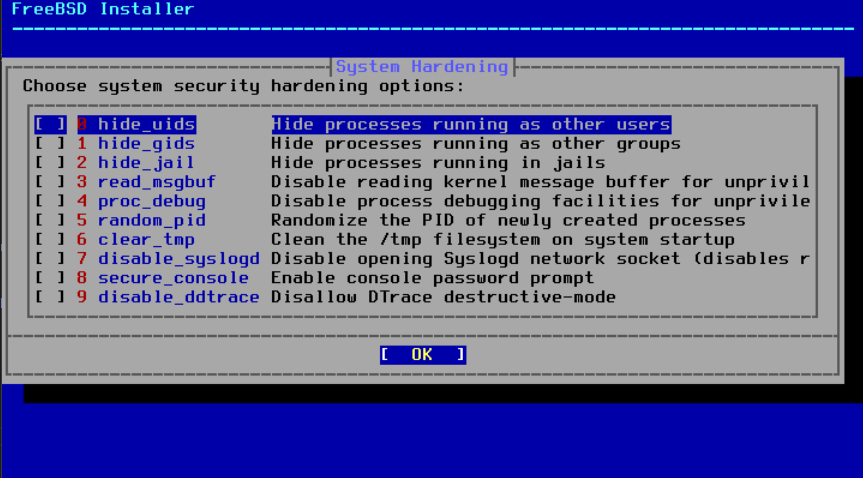
图 54. 选择加固安全选项
这里是可以在此菜单中启用的选项摘要:
-
hide_uids- 隐藏以其他用户(UID)身份运行的进程。这可以防止非特权用户看到其他用户正在运行的进程。 -
hide_gids- 隐藏以其他组(GID)身份运行的进程。这可以防止非特权用户看到来自其他组的运行进程。 -
hide_jail- 隐藏在 jail 中运行的进程。这可以防止非特权用户看到在 jail 内部运行的进程。 -
read_msgbuf- 禁止非特权用户读取内核消息缓冲区。防止非特权用户使用 dmesg(8) 命令查看内核日志缓冲区中的消息。 -
proc_debug- 禁用非特权用户的进程调试功能。禁用了各种非特权进程间调试服务,包括一些 procfs 功能,ptrace()和ktrace()。请注意,这也会阻止调试工具如 lldb(1)、truss(1) 和 procstat(1),以及某些脚本语言(如 PHP)中的一些内置调试功能。 -
random_pid- 随机化进程的 PID 。 -
clear_tmp- 在系统启动时清理/tmp目录。 -
disable_syslogd- 禁用打开 syslogd 网络套接字。默认情况下,FreeBSD 以安全方式运行 syslogd ,使用-s选项。这样可以防止守护进程在 514 端口上监听传入的 UDP 请求。启用此选项后, syslogd 将改为使用-ss运行,这将阻止 syslogd 打开任何端口。有关更多信息,请参阅 syslogd(8) 。 -
disable_sendmail- 禁用 sendmail 邮件传输代理。 -
secure_console- 在进入单用户模式时,使命令提示符要求输入root密码。 -
disable_ddtrace- DTrace 可以以影响运行中的内核的模式运行。除非显式启用,否则不得使用破坏性操作。在使用 DTrace 时,使用-w来启用此选项。有关更多信息,请参阅 dtrace(1) 。 -
enable_aslr- 启用地址空间布局随机化。有关地址空间布局随机化的更多信息,请参考 维基百科文章 。
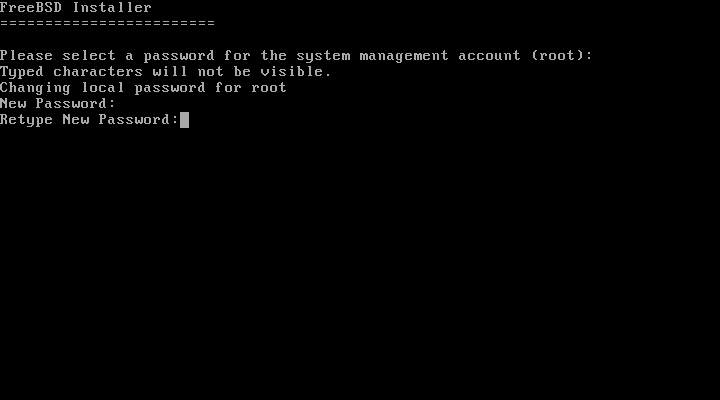
2.8.6. 添加用户
下一个菜单提示您创建至少一个用户帐户。建议使用用户帐户登录系统,而不是使用“ root ”用户。以 root 用户身份登录时,基本上没有限制或保护,可以做任何事情。以普通用户身份登录更安全、更可靠。
选择 Yes 来添加新用户。
图 55. 添加用户账户
按照提示输入用户账户所需的信息。在 输入用户信息 中的示例创建了 asample 用户账户。
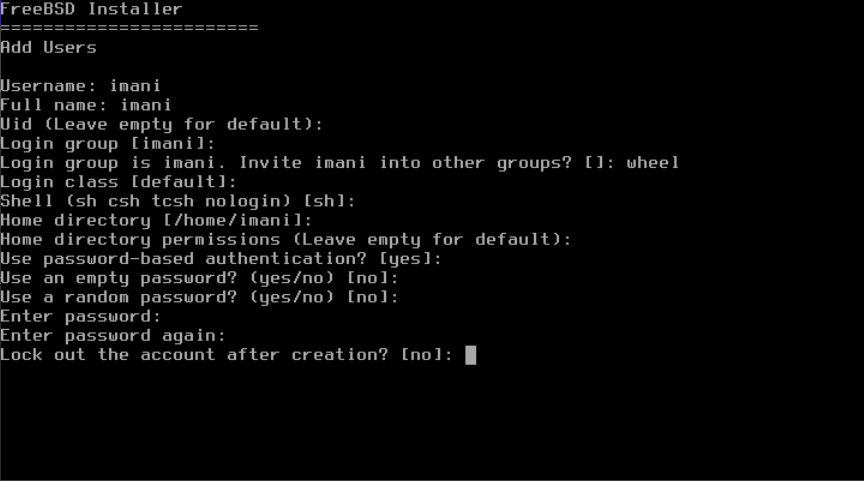
图 56. 输入用户信息
这是输入信息的摘要:
-
用户名(Username)- 用户登录时输入的名称。常见的约定是使用名字的首字母与姓氏结合,只要每个用户名在系统中是唯一的。用户名区分大小写,不应包含任何空格。 -
Full name- 用户的全名。可以包含空格,并且用作用户账户的描述。 -
Uid- 用户 ID 。通常留空,系统会自动分配一个值。 -
登录组(Login group)- 用户所属的组。通常留空以接受默认值。 -
将
用户邀请加入其他群组(Invite user into other groups)? - 用户将作为成员添加到其他群组。如果用户需要管理员访问权限,请在此处输入wheel。 -
登录类(Login class)- 通常留空以使用默认值。 -
Shell- 输入列表中的一个值来设置用户的交互式 shell 。有关 shell 的更多信息,请参考 Shells 。 -
Home directory- 用户的主目录。通常情况下,默认值是正确的。 -
主目录权限(Home directory permissions)- 用户主目录的权限。通常情况下,默认设置是正确的。 -
使用基于密码的身份验证(se password-based authentication)?- 通常选择yes,这样用户在登录时会被提示输入密码。 -
使用空密码(Use an empty password)?- 通常情况下,不建议使用空密码,因为空密码或空白密码是不安全的。 -
使用随机密码(Use a random password)?- 通常是no,这样用户可以在下一个提示中设置自己的密码。 -
输入密码(Enter password)- 此用户的密码。输入的字符不会显示在屏幕上。 -
再次输入密码(Enter password again)- 为了验证,必须再次输入密码。 -
创建后锁定账户(Lock out the account after creation)?- 通常是no,以便用户可以登录。
输入完所有细节后,会显示一个摘要供审核。如果有错误,请输入 no 进行更正。一切都正确无误后,请输入 yes 创建新用户。
图 57. 退出用户和组管理
如果还有更多用户需要添加,请用 yes 回答“是否添加另一个用户?”的问题。输入 no 以完成添加用户并继续安装。
有关添加用户和用户管理的更多信息,请参阅 用户和基本帐户管理 一节。
2.8.7. 最终配置
在安装和配置完成之后,提供了最后一次修改设置的机会。
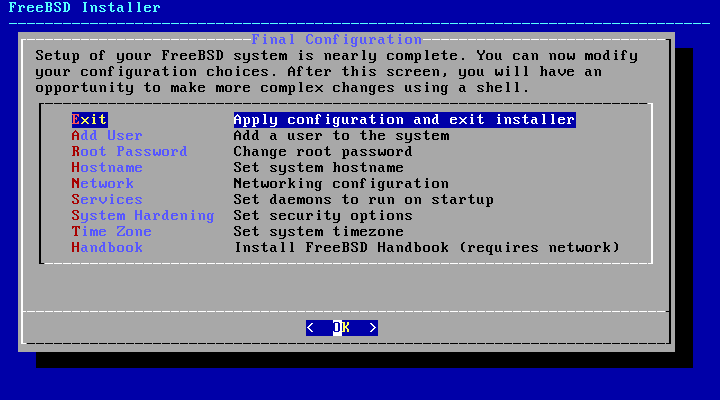
图 58. 最终配置
在完成安装之前,使用此菜单进行任何更改或进行任何额外的配置。
配置完成后,选择 Exit。
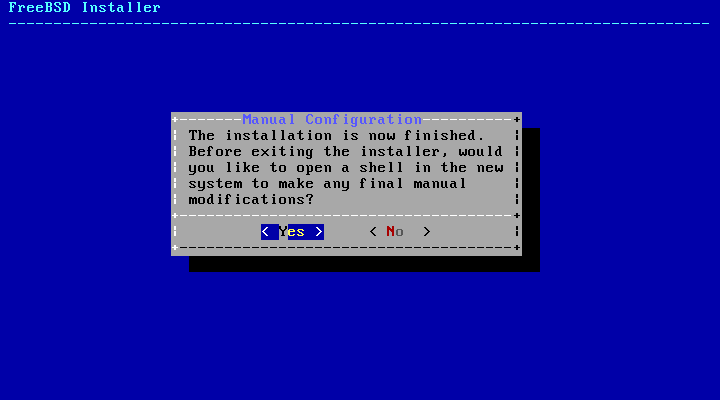
图 59. 手动配置
bsdinstall 将提示进行任何在重启进入新系统之前需要完成的额外配置。选择 Yes 退出到新系统中的 shell ,或选择 No 继续进行安装的最后一步。
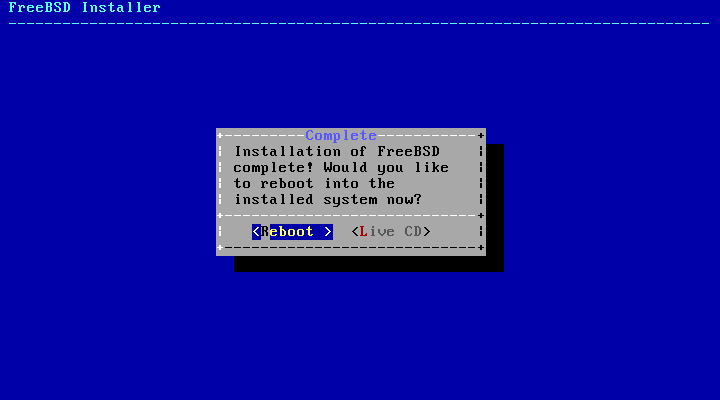
图 60. 完成安装
如果需要进一步配置或特殊设置,请选择 Live CD 以将安装介质引导到 Live CD 模式。
如果安装完成,请选择 Reboot 来重新启动计算机并启动新的 FreeBSD 系统。不要忘记移除 FreeBSD 安装介质,否则计算机可能会再次从它启动。
FreeBSD 启动时会显示信息性的消息。系统完成启动后,会显示一个登录提示符。在 login: 提示符下,输入在安装过程中添加的用户名。避免使用 root 登录。如需进行管理访问时,参考 超级用户账户 中的说明,了解如何成为超级用户。
按下 Scroll-Lock 键可以查看启动过程中出现的消息,以打开滚动缓冲区。使用 PgUp、PgDn 和箭头键可以向后滚动查看消息。完成后,再次按下 Scroll-Lock 键以解锁显示并返回到控制台。要在系统运行一段时间后查看这些消息,请在命令提示符下输入 less /var/run/dmesg.boot。查看完毕后,按下 q 键返回到命令行。
如果在 选择启用附加服务 中启用了 sshd,系统在第一次启动时可能会慢一些,因为系统会生成 SSH 主机密钥。随后的启动将会更快。然后,密钥的指纹将会显示如下示例:
Generating public/private rsa1 key pair.
Your identification has been saved in /etc/ssh/ssh_host_key.
Your public key has been saved in /etc/ssh/ssh_host_key.pub.
The key fingerprint is:
10:a0:f5:af:93:ae:a3:1a:b2:bb:3c:35:d9:5a:b3:f3 [email protected]
The key's randomart image is:
+--[RSA1 1024]----+
| o.. |
| o . . |
| . o |
| o |
| o S |
| + + o |
|o . + * |
|o+ ..+ . |
|==o..o+E |
+-----------------+
Generating public/private dsa key pair.
Your identification has been saved in /etc/ssh/ssh_host_dsa_key.
Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub.
The key fingerprint is:
7e:1c:ce:dc:8a:3a:18:13:5b:34:b5:cf:d9:d1:47:b2 [email protected]
The key's randomart image is:
+--[ DSA 1024]----+
| .. . .|
| o . . + |
| . .. . E .|
| . . o o . . |
| + S = . |
| + . = o |
| + . * . |
| . . o . |
| .o. . |
+-----------------+
Starting sshd.有关指纹和 SSH 的更多信息,请参考 OpenSSH 。
默认情况下,FreeBSD 不安装图形化环境。有关安装和配置图形窗口管理器的更多信息,请参考 X Window 系统 。
正确关闭 FreeBSD 计算机有助于保护数据和硬件免受损坏。在系统正确关闭之前,请不要关闭电源!如果用户是 wheel 组的成员,请在命令行中输入 su 并输入 root 密码以成为超级用户。然后,输入 shutdown -p now,系统将会干净地关闭,并且如果硬件支持的话,会自动关闭电源。
2.9. 故障排除
本节介绍基本的安装故障排除,例如人们常见的问题。
请查看 FreeBSD Release Information 页面上列出的硬件说明,以确保硬件得到支持。
|
通过更新各种硬件组件的固件,尤其是主板的固件,可以避免或减轻一些安装问题。主板固件通常被称为 BIOS。大多数主板和计算机制造商都有升级和升级信息的网站。 除非有充分的理由,如关键更新,否则制造商通常建议不要升级主板 BIOS。升级过程可能会出错,导致 BIOS 不完整,使计算机无法正常运行。 |
如果系统在启动过程中探测硬件时卡住或在安装过程中表现异常,ACPI 可能是罪魁祸首。FreeBSD 在 i386 和 amd64 平台上在启动过程中检测到 ACPI 后会广泛使用系统 ACPI 服务来帮助系统配置。不幸的是,ACPI 驱动程序和系统主板以及 BIOS 固件中仍然存在一些错误。可以通过在第三阶段引导加载程序中设置 hint.acpi.0.disabled 提示来禁用 ACPI。
set hint.acpi.0.disabled="1"每次系统启动时都会重置这个设置,因此需要将 hint.acpi.0.disabled ="1" 添加到文件 /boot/loader.conf 中。有关引导加载程序的更多信息可以在 “Synopsis” 中找到。
2.10. 使用 Live CD
bsdinstall 的欢迎菜单在 欢迎菜单 中显示,提供了 Live CD 选项。对于那些仍然在犹豫是否选择 FreeBSD 作为他们的操作系统,并且想在安装之前测试一些功能的人来说,这是非常有用的。
在使用 Live CD 之前,应注意以下几点:
-
要访问系统,需要进行身份验证。用户名为
root,密码为空。 -
由于系统直接从安装介质运行,因此性能将明显低于安装在硬盘上的系统。
-
该选项只提供命令提示符,而不提供图形界面。
Chapter 3. FreeBSD 基础知识
3.1. 简介
本章介绍了 FreeBSD 操作系统的基本命令和功能。其中很多内容对于任何类 UNIX 操作系统都是相关的。鼓励新的 FreeBSD 用户仔细阅读本章。
阅读完本章后,您将了解:
-
如何使用和配置虚拟控制台。
-
如何在 FreeBSD 上创建和管理用户和组。
-
UNIX® 文件权限和 FreeBSD 文件标志的工作原理。
-
默认的 FreeBSD 文件系统布局。
-
FreeBSD 磁盘组织。
-
如何挂载和卸载文件系统。
-
进程、守护进程和信号是什么。
-
什么是 shell ,以及如何更改默认的登录环境。
-
如何使用基本文本编辑器。
-
设备和设备节点是什么。
-
如何阅读手册页以获取更多信息。
3.2. 虚拟控制台和终端
除非 FreeBSD 已经配置为在启动时自动启动图形环境,否则系统将启动到一个命令行登录提示符,如下面的示例所示:
FreeBSD/amd64 (pc3.example.org) (ttyv0) login:
第一行包含了关于系统的一些信息。 amd64 表示 FreeBSD 运行在一个 64 位的 x86 系统上。主机名是 pc3.example.org ,而 ttyv0 表示这是“系统控制台”。第二行是登录提示符。
由于 FreeBSD 是一个多用户系统,它需要一种区分不同用户的方式。这通过要求每个用户在访问系统上的程序之前先登录系统来实现。每个用户都有一个唯一的“用户名”和个人的“密码”。
要登录系统控制台,请输入在系统安装过程中配置的用户名,如 Add Users 中所述,并按下 Enter 键。然后输入与用户名关联的密码并按下 Enter 键。出于安全原因,密码不会显示出来。
一旦输入正确的密码,将显示当天的消息( MOTD ),然后显示命令提示符。根据创建用户时选择的 shell 不同,该提示符可能是 # 、 $ 或 % 字符。提示符表示用户已成功登录到 FreeBSD 系统控制台,并准备尝试可用的命令。
3.2.1. 虚拟控制台
虽然系统控制台可以用于与系统进行交互,但在 FreeBSD 系统的键盘命令行上工作的用户通常会登录到虚拟控制台。这是因为系统消息默认配置为显示在系统控制台上。这些消息会出现在用户正在操作的命令或文件上,使得集中注意力于手头的工作变得困难。
默认情况下,FreeBSD 配置了多个虚拟控制台用于输入命令。每个虚拟控制台都有自己的登录提示符和 Shell ,并且可以轻松地在虚拟控制台之间切换。这基本上提供了在图形环境中同时打开多个窗口的命令行等效功能。
组合键 Alt+F1 到 Alt+F8 已被 FreeBSD 保留用于在虚拟控制台之间切换。使用 Alt+F1 切换到系统控制台( ttyv0 ),使用 Alt+F2 访问第一个虚拟控制台( ttyv1 ),使用 Alt+F3 访问第二个虚拟控制台( ttyv2 ),依此类推。当使用 Xorg 作为图形控制台时,组合键变为 Ctrl+Alt+F1 以返回到基于文本的虚拟控制台。
当从一个控制台切换到下一个控制台时,FreeBSD 会管理屏幕输出。结果是有多个虚拟屏幕和键盘可以用来键入命令以供 FreeBSD 运行。当用户切换到不同的虚拟控制台时,在一个虚拟控制台中启动的程序不会停止运行
请参考 kbdcontrol(1) 、 vidcontrol(1) 、 atkbd(4) 、 syscons(4) 和 vt(4) ,以获取更详细的 FreeBSD 控制台及其键盘驱动程序的技术描述。
在 FreeBSD 中,可用的虚拟控制台数量是在 /etc/ttys 文件的这个部分进行配置的:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" xterm on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" xterm on secure ttyv2 "/usr/libexec/getty Pc" xterm on secure ttyv3 "/usr/libexec/getty Pc" xterm on secure ttyv4 "/usr/libexec/getty Pc" xterm on secure ttyv5 "/usr/libexec/getty Pc" xterm on secure ttyv6 "/usr/libexec/getty Pc" xterm on secure ttyv7 "/usr/libexec/getty Pc" xterm on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
要禁用虚拟控制台,请在表示该虚拟控制台的行的开头放置一个注释符号( # )。例如,要将可用虚拟控制台的数量从八个减少到四个,请在表示虚拟控制台 ttyv5 到 ttyv8 的最后四行前面放置一个 # 。 不要 注释掉系统控制台 ttyv0 的行。请注意,如果已经安装并配置了 Xorg (如 X Window 系统 中所述),则最后一个虚拟控制台( ttyv8 )用于访问图形环境。
有关此文件中每个列的详细描述以及虚拟控制台的可用选项,请参阅 ttys(5) 。
3.2.2. 单用户模式
FreeBSD 引导菜单提供了一个标有“单用户启动”的选项。如果选择了这个选项,系统将启动到一个称为“单用户模式”的特殊模式。通常情况下,这个模式用于修复无法启动的系统或者在不知道 root 密码时重置密码。在单用户模式下,网络和其他虚拟控制台是不可用的。然而,系统完全支持 root 访问,并且默认情况下不需要 root 密码。因此,需要有对键盘的物理访问权限才能进入该模式,确定谁对键盘有物理访问权是保护 FreeBSD 系统安全时需要考虑的问题
控制单用户模式的设置位于 /etc/ttys 文件的这个部分。
# name getty type status comments # # If console is marked "insecure", then init will ask for the root password # when going to single-user mode. console none unknown off secure
默认情况下,状态被设置为 secure。这意味着对键盘具有物理访问权限的人要么不重要,要么受到物理安全策略的控制。如果将此设置更改为 insecure,则假设环境本身是不安全的,因为任何人都可以访问键盘。当将此行更改为 insecure 时, FreeBSD 将在用户选择进入单用户模式时提示输入 root 密码。
|
在更改此设置为 |
3.2.3. 更改控制台视频模式
FreeBSD 控制台的默认视频模式可以调整为 1024x768 、 1280x1024 或其他由图形芯片和显示器支持的尺寸。要使用不同的视频模式,请加载 VESA 模块:
# kldload vesa要确定硬件支持哪些视频模式,请使用 vidcontrol(1) 。要获取支持的视频模式列表,请执行以下操作:
# vidcontrol -i mode该命令的输出列出了硬件支持的视频模式。要选择一个新的视频模式,请使用 vidcontrol(1) 作为 root 用户指定该模式:
# vidcontrol MODE_279如果新的视频模式可接受,可以通过将其添加到 /etc/rc.conf 来在启动时永久设置。
allscreens_flags="MODE_279"
3.3. 用户和基本账户管理
FreeBSD 允许多个用户同时使用计算机。虽然一次只能有一个用户坐在屏幕前使用键盘,但任意数量的用户可以通过网络登录系统。为了使用系统,每个用户都应该有自己的用户账户。
本章描述了:
-
FreeBSD 系统上的不同类型的用户账户。
-
如何添加、删除和修改用户账户。
-
如何设置限制以控制用户和组可以访问的资源。
-
如何创建组并将用户添加为组的成员。
3.3.1. 账户类型
由于所有对 FreeBSD 系统的访问都是通过账户实现的,并且所有进程都是由用户运行的,因此用户和账户管理非常重要。
有三种主要类型的账户:系统账户、用户账户和超级用户账户。
3.3.1.1. 系统账户
系统账户用于运行诸如 DNS、邮件和 Web 服务器等服务。这样做的原因是出于安全考虑;如果所有服务都以超级用户身份运行,它们就可以无限制地执行操作。
系统账户的例子包括 daemon、operator、bind、news 和 www。
nobody 是一个通用的非特权系统账户。然而,使用 nobody 的服务越多,与该用户相关联的文件和进程也就越多,因此该用户的特权也就越高。
3.3.1.2. 用户账户
用户账户分配给真实的人,并用于登录和使用系统。每个访问系统的人都应该拥有一个唯一的用户账户。这使管理员能够查明谁在做什么,并防止用户破坏其他用户的设置。
每个用户都可以设置自己的环境以适应他们对系统的使用,通过配置他们的默认 shell 、编辑器、键绑定和语言设置。
在 FreeBSD 系统上,每个用户账户都有与之关联的特定信息:
- User name
-
用户名称是在
login:提示处输入的。每个用户必须有一个唯一的用户名。有一些创建有效用户名的规则,这些规则在 passwd(5) 中有详细说明。建议使用由八个或更少个小写字符组成的用户名,以保持与应用程序的向后兼容性。 - Password
-
每个账户都有一个关联的密码。
- User ID (UID)
-
用户 ID (UID) 是一个用于在 FreeBSD 系统中唯一标识用户的数字。允许指定用户名的命令将首先将其转换为 UID 。建议使用小于 65535 的 UID ,因为较高的值可能会导致某些软件的兼容性问题。
- Group ID (GID)
-
组 ID (GID) 是一个用于唯一标识用户所属的主要组的数字。组是一种基于用户的 GID 而不是 UID 来控制对资源访问的机制。这可以显著减小某些配置文件的大小,并允许用户成为多个组的成员。建议使用 65535 或更低的 GID ,因为较高的 GID 可能会破坏某些软件。
- Login class
-
登录分级是组机制的扩展,为定制系统以适应不同用户提供了额外的灵活性。有关登录类的详细讨论,请参阅 配置登录分级 。
- Password change time
-
默认情况下,密码不会过期。然而,可以根据每个用户的情况启用密码过期功能,强制一些或所有用户在一定时间后更改他们的密码。
- Account expiration time
-
默认情况下, FreeBSD 不会使账户过期。当创建需要有限生命周期的账户时,比如学校的学生账户,可以使用 pw(8) 命令指定账户的过期日期。在过期时间到达后,该账户将无法用于登录系统,但账户的目录和文件将保留。
- User’s full name
-
用户名在 FreeBSD 中唯一标识账户,但不一定反映用户的真实姓名。与注释类似,此信息可以包含空格、大写字符,并且可以超过 8 个字符的长度。
- Home directory
-
主目录是系统上一个目录的完整路径。这是用户登录时的起始目录。一个常见的约定是将所有用户的主目录放在
/home/username或/usr/home/username下。每个用户在自己的主目录中存储个人文件和子目录。 - User shell
-
Shell 提供了用户与系统进行交互的默认环境。有许多不同类型的 shell ,有经验的用户会根据自己的偏好进行设置,这些设置可以反映在他们的账户设置中。
3.3.1.3. 超级用户账户
超级用户账户通常被称为 root ,用于无限制地管理系统。因此,不应将其用于日常任务,如发送和接收邮件、系统的一般探索或编程。
与其他用户账户不同,超级用户可以无限制地操作,滥用超级用户账户可能导致灾难性后果。用户账户无法通过错误操作销毁操作系统,因此建议以用户账户登录,并且只在需要额外权限的命令时切换为超级用户。
作为超级用户,始终要仔细检查任何发出的命令,因为额外的空格或缺失的字符可能导致无法修复的数据丢失。
有几种方法可以获得超级用户权限。虽然可以使用 root 账户登录,但这是极不推荐的。
相反,使用 su(1) 命令成为超级用户。如果在运行此命令时指定了 - ,用户还将继承 root 用户的环境。运行此命令的用户必须属于 wheel 组,否则命令将失败。用户还必须知道 root 用户账户的密码。
在这个例子中,用户只是为了运行 make install 这个步骤需要超级用户权限,才成为超级用户。一旦命令完成,用户输入 exit 来退出超级用户账户,返回到他们的用户账户的权限。
例 2. 以超级用户身份安装程序
% configure
% make
% su -
Password:
# make install
# exit
%内置的 su(1) 框架适用于单个系统或只有一个系统管理员的小型网络。另一种选择是安装 security/sudo 软件包或 port。该软件提供活动日志记录,并允许管理员配置哪些用户可以以超级用户身份运行哪些命令。
3.3.2. 管理账户
FreeBSD 提供了多种不同的命令来管理用户账户。最常见的命令在 管理用户账户的实用工具 中进行了总结,并附有一些使用示例。有关每个实用程序的更多详细信息和使用示例,请参阅其手册页面。
命令 |
摘要 |
|---|---|
用于添加新用户的推荐命令行应用程序。 |
|
用于删除用户的推荐命令行应用程序。 |
|
用于更改用户数据库信息的灵活工具。 |
|
用于更改用户密码的命令行工具。 |
|
功能强大而灵活的工具,可对用户账户进行全方位修改。 |
|
具有账户管理支持的系统配置工具。 |
3.3.2.1. 添加用户
添加新用户的推荐程序是 adduser(8) 。当添加新用户时,该程序会自动更新 /etc/passwd 和 /etc/group 文件。它还会为新用户创建一个家目录,并从 /usr/share/skel 目录中复制默认配置文件,并可选择向新用户发送欢迎消息。此实用程序必须以超级用户身份运行。
adduser(8) 实用程序是交互式的,并且会引导用户完成创建新用户账户的步骤。如在 在 FreeBSD 上添加用户 中所示,可以输入所需信息,或按 Return 键接受方括号中显示的默认值。在本示例中,用户已被邀请加入 wheel 组,允许他们通过 su(1) 成为超级用户。完成后,实用程序将提示是否创建另一个用户或退出。
例 3. 在 FreeBSD 上添加用户
# adduser输出应该类似于以下内容:
Username: jru Full name: J. Random User Uid (Leave empty for default): Login group [jru]: Login group is jru. Invite jru into other groups? []: wheel Login class [default]: Shell (sh csh tcsh zsh nologin) [sh]: zsh Home directory [/home/jru]: Home directory permissions (Leave empty for default): Use password-based authentication? [yes]: Use an empty password? (yes/no) [no]: Use a random password? (yes/no) [no]: Enter password: Enter password again: Lock out the account after creation? [no]: Username : jru Password : **** Full Name : J. Random User Uid : 1001 Class : Groups : jru wheel Home : /home/jru Shell : /usr/local/bin/zsh Locked : no OK? (yes/no): yes adduser: INFO: Successfully added (jru) to the user database. Add another user? (yes/no): no Goodbye!
|
由于密码在输入时不会显示出来,请在创建用户账户时小心不要输入错误的密码。 |
3.3.2.2. 删除用户
要完全从系统中删除用户,请以超级用户身份运行 rmuser(8) 。该命令执行以下步骤:
-
如果存在用户的 crontab(1) 条目,则删除它。
-
删除用户拥有的所有 at(1) 作业。
-
向用户拥有的所有进程发送 SIGKILL 信号。
-
从系统的本地密码文件中删除用户。
-
删除用户的主目录(如果该目录属于该用户),包括处理路径中符号链接指向实际主目录的情况。
-
从
/var/mail目录中删除属于用户的传入邮件文件。 -
从
/tmp、/var/tmp和/var/tmp/vi.recover中删除用户所有拥有的文件。 -
将用户名从
/etc/group中所属的所有组中删除。(如果一个组变为空,并且组名与用户名相同,则删除该组;这与 adduser(8) 的每个用户唯一组相对应。) -
删除用户拥有的所有消息队列、共享内存段和信号量。
rmuser(8) 不能用于删除超级用户账户,因为这几乎总是意味着大规模破坏的迹象。
默认情况下,使用交互模式,如下例所示。
例 4.
rmuser 交互式账户删除# rmuser jru输出应该类似于以下内容:
Matching password entry: jru:*:1001:1001::0:0:J. Random User:/home/jru:/usr/local/bin/zsh Is this the entry you wish to remove? y Remove user's home directory (/home/jru)? y Removing user (jru): mailspool home passwd.
3.3.2.3. 更改用户信息
任何用户都可以使用 chpass(1) 命令来更改其默认 shell 和与其用户账户关联的个人信息。超级用户可以使用此实用程序来更改任何用户的其他账户信息。
当没有传递任何选项时,除了可选的用户名外, chpass(1) 会显示一个包含用户信息的编辑器。当用户从编辑器退出时,用户数据库将会更新为新的信息。
|
该实用程序在退出编辑器时会提示用户输入密码,除非以超级用户身份运行该实用程序。 |
在 以超级用户身份使用 chpass 命令 中,超级用户输入了 chpass jru ,现在正在查看可以更改该用户的字段。如果 jru 运行此命令,只有最后六个字段将被显示并可供编辑。这在 以普通用户身份使用 chpass 命令 中显示。
例 5. 以超级用户身份使用
chpass 命令# chpass输出应该类似于以下内容:
# Changing user database information for jru. Login: jru Password: * Uid [#]: 1001 Gid [# or name]: 1001 Change [month day year]: Expire [month day year]: Class: Home directory: /home/jru Shell: /usr/local/bin/zsh Full Name: J. Random User Office Location: Office Phone: Home Phone: Other information:
例 6. 以普通用户身份使用
chpass 命令#Changing user database information for jru.
Shell: /usr/local/bin/zsh
Full Name: J. Random User
Office Location:
Office Phone:
Home Phone:
Other information:3.3.2.4. 更改用户密码
任何用户都可以使用 passwd(1) 轻松更改他们的密码。为了防止意外或未经授权的更改,在设置新密码之前,该命令会提示用户输入原始密码:
例 7. 更改密码
% passwd输出应该类似于以下内容:
Changing local password for jru. Old password: New password: Retype new password: passwd: updating the database... passwd: done
超级用户可以通过在运行 passwd(1) 时指定用户名来更改任何用户的密码。当以超级用户身份运行此实用程序时,它不会提示用户输入当前密码。这允许在用户无法记住原始密码时更改密码。
例 8. 以超级用户身份更改另一个用户的密码
# passwd jru输出应该类似于以下内容:
Changing local password for jru. New password: Retype new password: passwd: updating the database... passwd: done
|
与 chpass(1) 一样, yppasswd(1) 是指向 passwd(1) 的链接,因此 NIS 可以与任一命令一起使用。 |
3.3.3. 管理群组
组是一个用户列表。组由组名称和 GID 标识。在 FreeBSD 中,内核使用进程的 UID 和其所属的组列表来确定该进程被允许做什么。大多数情况下,用户或进程的 GID 通常表示列表中的第一个组。
组名到 GID 的映射在 /etc/group 中列出。这是一个纯文本文件,包含四个由冒号分隔的字段。第一个字段是组名,第二个字段是加密密码,第三个字段是 GID ,第四个字段是逗号分隔的成员列表。有关语法的更完整描述,请参阅 group(5) 。
超级用户可以使用文本编辑器修改 /etc/group 文件,尽管使用 vigr(8) 编辑组文件更为推荐,因为它可以捕捉一些常见的错误。另外,也可以使用 pw(8) 来添加和编辑组。例如,要添加一个名为 teamtwo 的组,并确认它是否存在:
|
在使用操作员组时必须小心,因为可能会授予意外的类似超级用户的访问权限,包括但不限于关闭、重启以及访问组中 |
例 9. 使用 pw(8) 添加一个组
# pw groupadd teamtwo
# pw groupshow teamtwo输出应该类似于以下内容:
teamtwo:*:1100:
在这个例子中,1100 是 teamtwo 的 GID 。目前,teamtwo 没有成员。这个命令将会把 jru 添加为 teamtwo 的成员。
例 10. 使用 pw(8) 将用户账户添加到新组中
# pw groupmod teamtwo -M jru
# pw groupshow teamtwo输出应该类似于以下内容:
teamtwo:*:1100:jru
-M 参数后面是一个逗号分隔的用户列表,用于将这些用户添加到一个新的(空的)组中,或者替换现有组的成员。对于用户来说,这个组成员身份与密码文件中列出的用户的主组不同,而且是额外的。这意味着当使用 groupshow 和 pw(8) 一起查看用户时,用户不会显示为组成员,但是当使用 id(1) 或类似的工具查询信息时,用户会显示为组成员。当使用 pw(8) 将用户添加到组时,它只操作 /etc/group 文件,并不尝试从 /etc/passwd 中读取额外的数据。
例 11. 使用 pw(8) 添加新成员到一个组中
# pw groupmod teamtwo -m db
# pw groupshow teamtwo输出应该类似于以下内容:
teamtwo:*:1100:jru,db
在这个例子中, -m 参数后面是一个逗号分隔的用户列表,这些用户将被添加到该组中。与前一个例子不同的是,这些用户会被追加到该组中,而不会替换掉组中已有的用户。
例 12. 使用 id(1) 来确定组成员身份
% id jru输出应该类似于以下内容:
uid=1001(jru) gid=1001(jru) groups=1001(jru), 1100(teamtwo)
在这个例子中,jru 是 jru 和 teamtwo 组的成员。
3.4. 权限
在 FreeBSD 中,每个文件和目录都有一组关联的权限,并且有几个实用程序可用于查看和修改这些权限。要确保用户能够访问所需的文件,并且不能不正当地访问操作系统使用的文件或其他用户拥有的文件,就必须了解权限的工作原理。
本节讨论了在 FreeBSD 中使用的传统 UNIX® 权限。要进行更精细的文件系统访问控制,请参考 访问控制列表 。
在 UNIX® 中,基本权限使用三种类型的访问进行分配:读取、写入和执行。这些访问类型用于确定文件的所有者、组和其他人(其他所有人)对文件的访问。读取、写入和执行权限可以用字母 r、w 和 x 表示。它们也可以表示为二进制数字,因为每个权限都是打开或关闭的(0)。当表示为数字时,顺序总是按照 rwx 读取,其中 r 的打开值为 4 , w 的打开值为 2 , x 的打开值为 1 。
表 4.1 总结了可能的数字和字母组合。在阅读“目录列表”列时,使用 - 表示权限关闭。
| 值 | 权限 | 目录列表 |
|---|---|---|
0 |
禁止读取,禁止写入,禁止执行 |
|
1 |
禁止读取,禁止写入,可执行 |
|
2 |
禁止读取,可写入,禁止执行 |
|
3 |
禁止读取,可写入,可执行 |
|
4 |
可读取,禁止写入,禁止执行 |
|
5 |
可读取,禁止写入,可执行 |
|
6 |
可读取、可写入,禁止执行 |
|
7 |
可读取,可写入,可执行 |
|
使用 -l 参数与 ls(1) 一起,可以查看一个包含有关文件所有者、组和其他人权限的列的长目录列表。例如,在任意目录中使用 ls -l 可能会显示:
% ls -l输出应该类似于以下内容:
total 530 -rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile -rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile -rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
关注 myfile 这一行,第一个(最左边的)字符表示该文件是普通文件、目录、特殊字符设备、套接字还是其他特殊伪文件设备。在这个例子中, - 表示普通文件。接下来的三个字符 rw- 表示文件所有者的权限。再接下来的三个字符 r-- 表示文件所属组的权限。最后三个字符 r-- 表示其他用户的权限。破折号表示权限被关闭。在这个例子中,权限被设置为文件所有者可以读写文件,文件所属组可以读取文件,其他用户只能读取文件。根据上面的表格,该文件的权限将是 644 ,其中每个数字代表文件权限的三个部分。
系统如何控制设备的权限? FreeBSD 将大多数硬件设备视为程序可以打开、读取和写入数据的文件。这些特殊设备文件存储在 /dev/ 目录中。
目录也被视为文件。它们具有读取、写入和执行权限。目录的可执行位与文件的可执行位略有不同。当一个目录被标记为可执行时,意味着可以使用 cd(1) 命令进入该目录。这也意味着可以访问该目录中的文件,但受文件本身权限的限制。
为了执行目录列表,必须在目录上设置读取权限。为了删除一个已知文件名的文件,必须对包含该文件的目录具有写入和执行权限。
还有更多的权限位,但它们主要用于特殊情况,比如 setuid 二进制文件和粘滞目录。有关文件权限及如何设置它们的更多信息,请参考 chmod(1) 。
3.4.1. 符号权限
符号权限使用字符而不是八进制值来为文件或目录分配权限。符号权限使用以下语法: (用户) (动作) (权限) ,可用的值如下:
| 选项 | 参数 | 意义 |
|---|---|---|
(用户) |
u |
用户 |
(用户) |
g |
组所有者 |
(用户) |
o |
其他 |
(用户) |
a |
所有("全部") |
(动作) |
+ |
添加权限 |
(动作) |
- |
移除权限 |
(动作) |
= |
指定权限 |
(权限) |
r |
读 |
(权限) |
w |
写 |
(权限) |
x |
执行 |
(权限) |
t |
粘性位 |
(权限) |
s |
设置用户 ID 或组 ID |
这些值与 chmod(1) 一起使用,但使用字母而不是数字。例如,以下命令将阻止与 FILE 关联的组的所有成员以及所有其他用户访问 FILE。
% chmod go= FILE当需要对文件进行多组更改时,可以提供逗号分隔的列表。例如,以下命令会移除文件 FILE 的组和 "world" 的写权限,并为所有人添加执行权限:
% chmod go-w,a+x FILE3.4.2. FreeBSD 文件标志
除了文件权限之外,FreeBSD 还支持使用“文件标志”。这些标志为文件提供了额外的安全性和控制,但不适用于目录。通过文件标志,即使是 root 也可以被阻止删除或更改文件。
使用 chflags(1) 命令可以修改文件标志。例如,要在文件 file1 上启用系统不可删除标志,执行以下命令:
# chflags sunlink file1要禁用系统不可删除标志,请在 sunlink 前面加上 "no" :
# chflags nosunlink file1要查看文件的标志,可以使用 -lo 与 ls(1) 一起使用:
# ls -lo file1-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
只有 root 用户才能添加或删除一些文件标志。在其他情况下,文件所有者可以设置其文件标志。有关更多信息,请参阅 chflags(1) 和 chflags(2)。
3.4.3. setuid 、setgid 和 sticky 权限
除了已经讨论过的权限之外,还有三个其他特定的设置,所有管理员都应该了解。它们是 setuid、setgid 和 sticky 权限。
这些设置对于某些 UNIX® 操作非常重要,因为它们提供了通常不授予普通用户的功能。要理解它们,必须注意实际用户 ID 和有效用户 ID 之间的区别。
真实用户 ID 是拥有或启动进程的 UID 。有效 UID 是进程运行的用户 ID 。例如,当用户更改密码时, passwd(1) 以真实用户 ID 运行。然而,为了更新密码数据库,该命令以 root 用户的有效 ID 运行。这使得用户可以在不看到 权限被拒绝 错误的情况下更改密码。
可以通过为用户添加 s 权限来以符号方式添加 setuid 权限,示例如下:
# chmod u+s suidexample.sh在下面的示例中,也可以通过在权限集前加上数字四(4)来设置 setuid 权限:
# chmod 4755 suidexample.shsuidexample.sh 的权限现在如下所示:
-rwsr-xr-x 1 trhodes trhodes 63 Aug 29 06:36 suidexample.sh
请注意,现在文件所有者的权限集中包含了一个 s,取代了可执行位。这允许使用需要提升权限的实用程序,例如 passwd(1) 。
|
|
要实时查看此内容,请打开两个终端。在其中一个终端上,以普通用户身份输入 passwd 。在等待新密码时,检查进程表并查看 passwd(1) 的用户信息。
在终端 A 中:
Changing local password for trhodes
Old Password:在终端 B 中:
# ps aux | grep passwdtrhodes 5232 0.0 0.2 3420 1608 0 R+ 2:10AM 0:00.00 grep passwd
root 5211 0.0 0.2 3620 1724 2 I+ 2:09AM 0:00.01 passwd尽管 passwd(1) 以普通用户身份运行,但它使用的是 root 的有效 UID 。
setgid 权限与 setuid 权限执行相同的功能,只是它改变的是组的设置。当一个应用程序或实用工具以此设置运行时,它将根据拥有文件的组而不是启动进程的用户被授予权限。
要在文件上以符号方式设置 setgid 权限,请使用 chmod(1) 命令为组添加 s 权限。
# chmod g+s sgidexample.sh或者,给 chmod(1) 命令提供一个前缀的数字 2 :
# chmod 2755 sgidexample.sh在下面的清单中,请注意 s 现在位于用于组权限设置的字段中:
-rwxr-sr-x 1 trhodes trhodes 44 Aug 31 01:49 sgidexample.sh|
在这些示例中,尽管所讨论的 shell 脚本是一个可执行文件,但它不会以不同的 EUID 或有效用户 ID 运行。这是因为 shell 脚本可能无法访问 setuid(2) 系统调用。 |
setuid 和 setgid 权限位可能会降低系统安全性,因为它们允许提升权限。而第三个特殊权限位,即 sticky bit ,可以增强系统的安全性。
当目录上设置了 粘着位(sticky bit) 时,只允许文件所有者删除文件。这对于防止非文件所有者在公共目录(如 /tmp)中删除文件非常有用。要使用此权限,请将 t 模式添加到文件中:
# chmod +t /tmp或者,将权限集以数字 1 作为前缀:
# chmod 1777 /tmpsticky bit 权限将显示为权限集的最后一个字符 t 。
# ls -al / | grep tmpdrwxrwxrwt 10 root wheel 512 Aug 31 01:49 tmp3.5. 目录结构
FreeBSD 目录层次结构对于全面了解系统至关重要。最重要的目录是根目录或者“/”。这个目录是在启动时首先挂载的,它包含了准备操作系统进行多用户操作所需的基本系统。根目录还包含其他文件系统的挂载点,在切换到多用户操作时会挂载这些文件系统。
挂载点是一个目录,可以将额外的文件系统嵌入到父文件系统(通常是根文件系统)上。这在 磁盘组织 中有进一步描述。标准的挂载点包括 /usr/、/var/、/tmp/、/mnt/ 和 /cdrom/ 。这些目录通常在 /etc/fstab 中引用。这个文件是一个包含各种文件系统和挂载点的表格,并由系统读取。除非它们的条目包含 noauto,否则 /etc/fstab 中的大多数文件系统会在启动时自动从脚本 rc(8) 挂载。详细信息可以在 fstab 文件 中找到。
文件系统层次结构的完整描述可以在 hier(7) 中找到。下表提供了最常见目录的简要概述。
目录 |
描述 |
|---|---|
|
文件系统的根目录。 |
|
单用户和多用户环境的基本用户实用程序。 |
|
操作系统引导过程中使用的程序和配置文件。 |
|
默认的启动配置文件。有关详细信息,请参阅 loader.conf(5) 。 |
|
由 devfs(5) 管理的设备特殊文件。 |
|
系统配置文件和脚本。 |
|
默认系统配置文件。有关详细信息,请参阅 rc(8) 。 |
|
通过 cron(8) 每天、每周和每月运行的脚本。有关详细信息,请参阅 periodic(8) 。 |
|
|
|
关键系统文件 |
|
包含用作可移动介质(如 CD、USB 驱动器和软盘)的挂载点的子目录。 |
|
空目录通常被系统管理员用作临时挂载点。 |
|
自动挂载的 NFS 共享;请参阅 auto_master(5) 。 |
|
进程文件系统。有关详细信息,请参阅 procfs(5) 和 mount_procfs(8) 。 |
|
用于紧急恢复的静态链接程序,如 rescue(8) 中所述。 |
|
|
|
单用户和多用户环境的基本系统程序和管理工具。 |
|
通常在系统重新启动后不会保留的临时文件。基于内存的文件系统通常会挂载在 |
|
大多数用户工具和应用程序。 |
|
常用工具、编程工具和应用程序。 |
|
标准的 C 头文件。 |
|
库文件 |
|
杂项实用数据文件。 |
|
系统守护进程和由其他程序执行的系统实用工具。 |
|
本地可执行文件和库。也被用作 FreeBSD ports 框架的默认目的地。在 |
|
FreeBSD Ports 集合(可选)。 |
|
系统守护进程和由用户执行的系统实用程序。 |
|
与体系结构无关的文件。 |
|
BSD 或本地源文件。 |
|
多用途日志、临时、暂存和溢出文件。 |
|
杂项系统日志文件。 |
|
通常在系统重启后保留的临时文件。 |
3.6. 磁盘组织
FreeBSD 使用的最小组织单位是文件名。文件名区分大小写,这意味着 readme.txt 和 README.TXT 是两个不同的文件。 FreeBSD 不使用文件的扩展名来确定文件是程序、文档还是其他形式的数据。
文件存储在目录中。一个目录可以不包含任何文件,也可以包含数百个文件。一个目录还可以包含其他目录,从而允许在彼此之间建立目录层次结构以组织数据。
文件和目录的引用是通过给出文件或目录名称,后跟一个斜杠 / ,再跟上其他必要的目录名称来完成的。例如,如果目录 foo 包含一个目录 bar,该目录又包含文件 readme.txt ,那么文件的完整名称,或者路径,就是 foo/bar/readme.txt。请注意,这与 Windows® 不同,Windows 使用反斜杠 \ 来分隔文件和目录名称。 FreeBSD 在路径中不使用驱动器号或其他驱动器名称。例如,在 FreeBSD 上,不会输入 c:\foo\bar\readme.txt。
3.6.1. 文件系统
目录和文件存储在文件系统中。每个文件系统在最顶层都包含一个目录,称为该文件系统的根目录。这个根目录可以包含其他目录。一个文件系统被指定为根文件系统或 / 。其他所有文件系统都被挂载在根文件系统下。无论 FreeBSD 系统上有多少个磁盘,每个目录都看起来是同一个磁盘的一部分。
考虑三个文件系统,分别称为 A、B 和 C。每个文件系统都有一个根目录,其中包含两个其他目录,分别称为 A1、A2 (同样也有 B1、B2 和 C1、C2)。
将 A 称为根文件系统。如果使用 ls(1) 命令查看该目录的内容,将显示两个子目录,A1 和 A2。目录树如下所示:
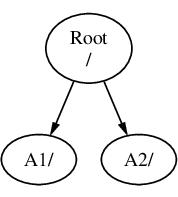
一个文件系统必须被挂载到另一个文件系统的目录上。当将文件系统 B 挂载到目录 A1 上时,B 的根目录将替换 A1,并且 B 中的目录会相应地显示出来:
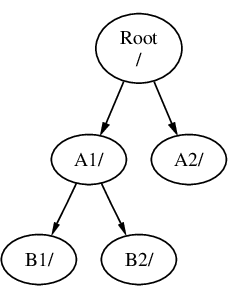
任何位于 B1 或 B2 目录中的文件可以通过路径 /A1/B1 或 /A1/B2 访问。任何位于 /A1 中的文件都被临时隐藏了。如果从 A 卸载 B,它们将重新出现。
如果 B 被安装在 A2 上,那么图表将如下所示:
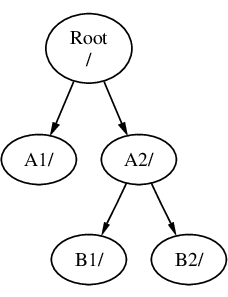
路径分别为 /A2/B1 和 /A2/B2。
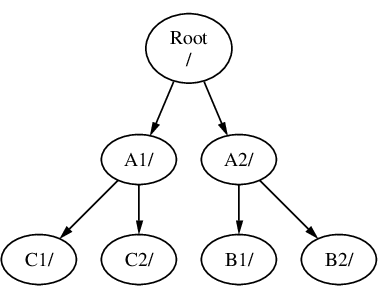
文件系统可以相互叠加挂载。继续上一个例子,C 文件系统可以被挂载在 B 文件系统中的 B1 目录上方,形成以下的安排:
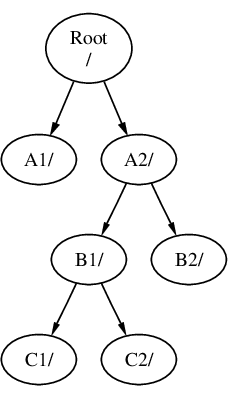
或者 C 可以直接挂载到 A 文件系统下的 A1 目录中:
完全可以只有一个大的根文件系统,而不需要创建其他文件系统。这种方法有一些缺点和一个优点。
多个文件系统的好处
-
不同的文件系统可以有不同的挂载选项。例如,根文件系统可以以只读方式挂载,这样用户就无法意外删除或编辑关键文件。将可由用户写入的文件系统(如
/home)与其他文件系统分离,可以将它们挂载为 nosuid 。此选项可以防止文件系统上存储的可执行文件的_ suid_/guid 位生效,从而可能提高安全性。 -
FreeBSD 会根据文件系统的使用情况自动优化文件的布局。因此,包含许多频繁写入的小文件的文件系统将与包含较少且较大的文件的文件系统有所不同的优化方式。如果只有一个大文件系统,这种优化将失效。
-
如果断电,FreeBSD 的文件系统是健壮的。然而,在关键时刻断电仍然可能损坏文件系统的结构。通过将数据分散在多个文件系统上,系统更有可能重新启动,从而更容易根据需要进行备份恢复。
3.6.2. 磁盘分区
文件系统包含在 分区 中。使用多种分区方案将磁盘划分为分区;参见 手动分区。较新的方案是 GPT ;旧的基于 BIOS 的计算机使用 MBR。GPT 支持将磁盘划分为具有大小、偏移和类型的分区。它支持大量的分区和分区类型,并且在可能的情况下推荐使用。GPT 分区使用磁盘名称加后缀,后缀为 p1 表示第一个分区,p2 表示第二个分区,依此类推。然而,MBR 仅支持少量的分区。在 FreeBSD 中,MBR 分区被称为 slices。 Slices 可以用于不同的操作系统。 FreeBSD slices 使用 BSD 标签进行分区细分(参见 bsdlabel(8))。
Slice 号码遵循设备名称,以 s 为前缀,从 1 开始。因此,“da0s1”是第一个 SCSI 驱动器上的第一个 slice。一个磁盘上只能有四个物理 slice,但是在适当类型的物理切片内可以有逻辑 slice。这些扩展 slice 从 5 开始编号,因此“ada0s5”是第一个 SATA 磁盘上的第一个扩展 slice。这些设备由希望占用一个 slice 的文件系统使用。
每个 GPT 或 BSD 分区只能包含一个文件系统,这意味着文件系统通常通过其在文件系统层次结构中的典型挂载点或它们所包含的分区的名称来描述。
FreeBSD 还使用磁盘空间作为 交换空间 来提供 虚拟内存。这使得您的计算机可以表现得好像它拥有比实际更多的内存。当 FreeBSD 内存不足时,它将一些当前未使用的数据移动到交换空间,并在需要时将其移回(将其他数据移出)。这被称为 分页。
一些 BSD 分区与特定的约定相关联。
分区 |
惯例 |
|---|---|
|
通常包含根文件系统。 |
|
通常包含交换空间。 |
|
通常与包含的 slice 大小相同。这样可以使需要在整个 slice 上工作的实用程序(例如坏块扫描器)能够在 |
|
分区 |
Slices 和“危险专用”物理驱动器包含 BSD 分区,这些分区用字母 a 到 h 表示。这个字母被附加到设备名称上,所以“ da0a”是第一个 da 驱动器上的 a 分区,该驱动器是“危险专用”的。“ada1s3e”是第二个 SATA 磁盘驱动器的第三个 slice 中的第五个分区。
最后,系统上的每个磁盘都有一个标识。磁盘名称以表示磁盘类型的代码开头,然后是一个数字,表示它是第几个磁盘。与分区和切片不同,磁盘编号从 0 开始。常见的代码列在 磁盘设备名称 中。
在引用 slice 中的分区时,请包括磁盘名称、s 、切片编号,然后是分区字母。示例见 示例磁盘、Slice 和分区名称 。 GPT 分区包括磁盘名称、p,然后是分区编号。
磁盘的概念模型 展示了使用 MBR 分区的磁盘布局的概念模型。
在安装 FreeBSD 时,如果使用 MBR,请配置磁盘 slice,并在 slice 内创建用于 FreeBSD 的分区。如果使用 GPT ,请为每个文件系统配置分区。无论哪种情况,都要在每个分区中创建文件系统或交换空间,并决定每个文件系统将被挂载到哪里。有关操作分区的信息,请参阅 gpart(8) 。
| 驱动类型 | 驱动设备名称 |
|---|---|
SATA 和 IDE 硬盘 |
|
SCSI 硬盘和 USB 存储设备 |
|
NVMe 存储 |
|
SATA 和 IDE CD-ROM 驱动器 |
|
SCSI CD-ROM 驱动器 |
|
软盘驱动器 |
|
SCSI 磁带驱动器 |
|
RAID 驱动器 |
例如,Adaptec® AdvancedRAID 的 |
| 名称 | 意义 |
|---|---|
|
第一个 SATA 磁盘( |
|
第二个 SCSI 磁盘( |
例 13. 磁盘的概念模型
这个图示展示了 FreeBSD 对系统上连接的第一个 SATA 硬盘的视图。假设该硬盘的容量为 250GB ,包含一个 80GB 的分区和一个 170GB 的分区(MS-DOS® 分区)。第一个分区包含一个 Windows® NTFS 文件系统,即 C:,而第二个分区包含一个 FreeBSD 安装。这个示例的 FreeBSD 安装有四个数据分区和一个交换分区。
四个分区分别持有一个文件系统。分区 a 用于根文件系统,d 用于 /var/,e 用于 /tmp/,f 用于 /usr/。分区字母 c 指的是整个 slice,因此不用于普通分区。

3.7. 挂载和卸载文件系统
文件系统最好被视为一棵树,以 / 作为根节点。根目录中的 /dev、/usr 和其他目录是分支,它们可能有自己的分支,比如 /usr/local 等等。
将一些目录放在单独的文件系统上有各种原因。/var 包含了 log/、spool/ 以及各种类型的临时文件,因此可能会被填满。填满根文件系统是不明智的,所以将 /var 与 / 分离通常是可取的。
将某些目录树包含在其他文件系统中的另一个常见原因是它们将被放置在单独的物理磁盘上,或者是单独的虚拟磁盘,例如网络文件系统挂载,如 “网络文件系统( NFS )” 描述的,或者 CDROM 驱动器。
3.7.1. fstab 文件
在引导过程中(FreeBSD 引导过程),除了包含 noauto 条目的条目外,/etc/fstab 中列出的文件系统会自动挂载。该文件以以下格式包含条目:
device /mount-point fstype options dumpfreq passno
device-
如 磁盘设备名称 中所解释的,现有设备名称。
mount-point-
一个现有的目录,用于挂载文件系统。
fstype-
传递给 mount(8) 的文件系统类型。默认的 FreeBSD 文件系统是
ufs。 options-
可以选择
rw表示读写文件系统,或者ro表示只读文件系统,后面可以添加其他可能需要的选项。常见的选项是noauto,用于在启动序列期间通常不挂载的文件系统。其他选项可以在 mount(8) 中找到。 dumpfreq-
dump(8) 使用此字段来确定哪些文件系统需要进行备份。如果该字段缺失,则默认为零值。
passno-
确定在重新启动后,fsck(8) 应该按照什么顺序检查 UFS 文件系统。应该跳过的文件系统应该将其
passno设置为零。根文件系统需要在其他所有文件系统之前进行检查,并且其passno应该设置为一。其他文件系统的passno应该设置为大于一的值。如果有多个文件系统具有相同的passno,fsck(8) 将尝试在可能的情况下并行检查文件系统。
请参考 fstab(5) 以获取有关 /etc/fstab 格式及其选项的更多信息。
3.7.2. 使用 mount(8)
文件系统使用 mount(8) 进行挂载。最基本的语法如下:
# mount device mountpoint在 /etc/fstab 中列出的文件系统也可以通过提供挂载点来挂载。
该命令提供了许多选项,这些选项在 mount(8) 中有描述。最常用的选项包括:
挂载选项
-a-
挂载
/etc/fstab中列出的所有文件系统,除了那些标记为“noauto”、被-t标志排除的文件系统,以及已经挂载的文件系统。 -d-
执行除实际挂载系统调用之外的所有操作。这个选项与
-v标志一起使用非常有用,可以确定 mount(8) 实际上正在尝试做什么。 -f-
强制挂载一个不干净的文件系统(危险操作),或者在将文件系统的挂载状态从读写改为只读时,撤销写访问权限。
-r-
将文件系统挂载为只读模式。这与使用
-o ro参数完全相同。 -t fstype-
如果包含
-a选项,则挂载指定的文件系统类型或仅挂载给定类型的文件系统。“ufs”是默认的文件系统类型。 -u-
更新文件系统的挂载选项。
-v-
提供详细信息。
-w-
将文件系统挂载为读写模式。
可以将以下选项作为逗号分隔的列表传递给 -o:
- nosuid
-
不要读取文件系统上的
setuid或setgid标志。这也是一个有用的安全选项。
3.8. 进程和守护进程
FreeBSD 是一个多任务操作系统。每个同时运行的程序被称为一个 进程。每个正在运行的命令都会启动至少一个新的进程,并且 FreeBSD 还会运行一些系统进程。
每个进程都由一个称为 进程 ID(PID)的数字唯一标识。与文件类似,每个进程都有一个所有者和组,并且所有者和组权限用于确定进程可以打开哪些文件和设备。大多数进程还有一个启动它们的父进程。例如,shell 是一个进程,shell 中启动的任何命令都是一个进程,其父进程是 shell 。例外情况是一个特殊的进程,称为 init(8),它始终是在启动时第一个启动的进程,其 PID 始终为 1。
有些程序并不是设计成需要连续的用户输入,也不能在第一时间与终端断开连接。例如,Web 服务器响应 Web 请求,而不是用户输入。邮件服务器是另一种这种类型的应用程序。这些类型的程序被称为 守护进程(daemon)。术语 daemon 来自希腊神话,代表着一个既不善良也不邪恶的实体,它在不可见的情况下执行有用的任务。这就是为什么 BSD 吉祥物是一个看起来开心的带着运动鞋和叉子的 daemon。
有一个约定,即通常作为守护进程运行的程序的命名方式是以字母"d"结尾的。例如,BIND 是 Berkeley Internet Name Domain 的缩写,但实际执行的程序是 named。Apache Web 服务器程序是 httpd ,线打印机排队守护进程是 lpd。这只是一种命名约定。例如,Sendmail 应用程序的主邮件守护进程是 sendmail,而不是 maild。
3.8.1. 查看进程
要查看系统上运行的进程,请使用 ps(1) 或 top(1)。要显示当前正在运行的进程的静态列表,包括它们的进程 ID 、使用的内存量以及启动它们的命令,请使用 ps(1) 。要显示所有正在运行的进程,并每隔几秒更新一次显示,以便交互式地查看计算机正在做什么,请使用 top(1)。
默认情况下,ps(1) 只显示正在运行且由用户拥有的命令。例如:
% ps输出应该类似于以下内容:
PID TT STAT TIME COMMAND 8203 0 Ss 0:00.59 /bin/csh 8895 0 R+ 0:00.00 ps
ps(1) 的输出被组织成多列。PID 列显示进程 ID。PID 从 1 开始分配,最大为 99999 ,然后重新从头开始分配。然而,如果 PID 已经被使用,它不会被重新分配。TT 列显示程序所在的 tty,STAT 列显示程序的状态。 TIME 是程序在 CPU 上运行的时间。这通常不是程序启动后经过的时间,因为大多数程序在需要在 CPU 上花费时间之前会花费很多时间等待事件发生。最后,COMMAND 是用于启动程序的命令。
有多种不同的选项可用于更改显示的信息。其中最有用的一组是 auxww,其中 a 显示有关所有用户的所有运行进程的信息,u 显示进程所有者的用户名和内存使用情况,x 显示有关守护进程的信息,ww 使 ps(1) 显示每个进程的完整命令行,而不是在屏幕上显示过长时截断它。
top(1) 的输出类似:
% top输出应该类似于以下内容:
last pid: 9609; load averages: 0.56, 0.45, 0.36 up 0+00:20:03 10:21:46 107 processes: 2 running, 104 sleeping, 1 zombie CPU: 6.2% user, 0.1% nice, 8.2% system, 0.4% interrupt, 85.1% idle Mem: 541M Active, 450M Inact, 1333M Wired, 4064K Cache, 1498M Free ARC: 992M Total, 377M MFU, 589M MRU, 250K Anon, 5280K Header, 21M Other Swap: 2048M Total, 2048M Free PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 557 root 1 -21 r31 136M 42296K select 0 2:20 9.96% Xorg 8198 dru 2 52 0 449M 82736K select 3 0:08 5.96% kdeinit4 8311 dru 27 30 0 1150M 187M uwait 1 1:37 0.98% firefox 431 root 1 20 0 14268K 1728K select 0 0:06 0.98% moused 9551 dru 1 21 0 16600K 2660K CPU3 3 0:01 0.98% top 2357 dru 4 37 0 718M 141M select 0 0:21 0.00% kdeinit4 8705 dru 4 35 0 480M 98M select 2 0:20 0.00% kdeinit4 8076 dru 6 20 0 552M 113M uwait 0 0:12 0.00% soffice.bin 2623 root 1 30 10 12088K 1636K select 3 0:09 0.00% powerd 2338 dru 1 20 0 440M 84532K select 1 0:06 0.00% kwin 1427 dru 5 22 0 605M 86412K select 1 0:05 0.00% kdeinit4
输出分为两个部分。标题部分(前五或六行)显示了最后一个运行的进程的 PID ,系统负载平均值(衡量系统繁忙程度的指标),系统运行时间(自上次重启以来的时间)和当前时间。标题中的其他数字与正在运行的进程数量、已使用的内存和交换空间以及系统在不同 CPU 状态下花费的时间有关。如果加载了 ZFS 文件系统模块,ARC 行将显示有多少数据是从内存缓存中读取而不是从磁盘中读取的。
在标题下面是一系列列,其中包含与 ps(1) 输出类似的信息,例如 PID、用户名、CPU 时间和启动进程的命令。默认情况下,top(1) 还会显示进程占用的内存空间。这被分为两列:总大小和常驻大小。总大小是应用程序所需的内存量,常驻大小是它当前实际使用的内存量。
top(1) 每两秒自动更新显示。可以使用 -s 指定不同的间隔。
3.8.2. 杀死进程
与任何正在运行的进程或守护进程进行通信的一种方法是使用 kill(1) 发送一个 信号(signal)。有许多不同的信号;一些具有特定的含义,而其他信号在应用程序的文档中有描述。用户只能向自己拥有的进程发送信号,向他人的进程发送信号将导致权限被拒绝的错误。例外情况是 root 用户,他可以向任何进程发送信号。
操作系统也可以向进程发送信号。如果一个应用程序编写得很糟糕,试图访问它不应该访问的内存, FreeBSD 将向该进程发送“分段违规(Segmentation Violation)”信号(SIGSEGV)。如果一个应用程序被编写成使用 alarm(3) 系统调用,在经过一段时间后被提醒,它将收到“闹钟(Alarm)”信号(SIGALRM)。
有两个信号可以用来停止一个进程:SIGTERM 和 SIGKILL。SIGTERM 是一种礼貌的方式来终止一个进程,因为进程可以读取该信号,关闭可能打开的任何日志文件,并尝试在关闭之前完成正在进行的操作。在某些情况下,如果进程正在执行无法中断的任务,它可能会忽略 SIGTERM 信号。
SIGKILL 无法被进程忽略。向一个进程发送 SIGKILL 通常会立即停止该进程。[1] 。
其他常用的信号包括 SIGHUP、SIGUSR1 和 SIGUSR2。由于这些是通用的信号,不同的应用程序会有不同的响应。
例如,在更改 Web 服务器的配置文件后,需要告诉 Web 服务器重新读取其配置。重新启动 httpd 将导致 Web 服务器短暂的停机时间。相反,发送 SIGHUP 信号给守护进程。请注意,不同的守护进程会有不同的行为,因此请参考守护进程的文档以确定是否使用 SIGHUP 可以达到所需的结果。
3.9. Shells
一个 shell 提供了一个命令行界面,用于与操作系统进行交互。 Shell 从输入通道接收命令并执行它们。许多 shell 提供了内置函数来帮助处理日常任务,如文件管理、文件通配符、命令行编辑、命令宏和环境变量。 FreeBSD 提供了几个 shell,包括 Bourne shell(sh(1))和扩展的 C shell(tcsh(1))。FreeBSD Ports Collection 中还提供了其他 shell,如 zsh 和 bash。
使用的 shell 实际上是个人口味的问题。 C 程序员可能更喜欢类似 C 的 shell ,比如 tcsh(1) 。 Linux® 用户可能更喜欢 bash。每个 shell 都有独特的特性,可能适用或不适用于用户首选的工作环境,这就是为什么可以选择使用哪个 shell 的原因。
一个常见的 shell 功能是文件名补全。当用户输入命令或文件名的前几个字母并按下 Tab 键时, shell 会自动完成命令或文件名的剩余部分。假设有两个文件名分别为 foobar 和 football。要删除 foobar,用户可以输入 rm foo 并按下 Tab 键来完成文件名的补全。
但是 Shell 只显示 rm foo 。由于 foobar 和 football 都以 foo 开头,它无法完成文件名。一些 Shell 会发出哔哔声或显示所有匹配的选项。用户必须输入更多字符来识别所需的文件名。输入一个 t 并再次按下 Tab 就足够让 Shell 确定所需的文件名并填充剩下的部分。
shell 的另一个特性是使用环境变量。环境变量是存储在 shell 环境中的键值对。任何由 shell 调用的程序都可以读取这个环境,并因此包含了许多程序配置。 常见的环境变量 提供了常见环境变量及其含义的列表。请注意,环境变量的名称始终为大写。
变量 |
描述 |
|---|---|
|
当前登录用户的名称。 |
|
以冒号分隔的目录列表,用于搜索二进制文件。 |
|
如果可用,连接到的 Xorg 显示器的网络名称。 |
|
当前的 Shell 。 |
|
用户终端的类型名称。用于确定终端的功能。 |
|
终端转义码的数据库条目,用于执行各种终端功能。 |
|
操作系统的类型。 |
|
系统的 CPU 架构。 |
|
用户首选的文本编辑器。 |
|
用户首选的逐页查看文本的实用工具。 |
|
以冒号分隔的目录列表,用于搜索手册页。 |
在不同的 shell 中设置环境变量的方法是不同的。在 tcsh(1) 和 csh(1) 中,使用 setenv 来设置环境变量。在 sh(1) 和 bash 中,使用 export 来设置当前的环境变量。以下示例将默认的 EDITOR 设置为 /usr/local/bin/emacs,适用于 tcsh(1) shell。
% setenv EDITOR /usr/local/bin/emacsbash 的等效命令是:
% export EDITOR="/usr/local/bin/emacs"为了展开环境变量以查看其当前设置,在命令行中在其名称前面键入 $ 字符。例如,echo $TERM 会显示当前的 $TERM 设置。
Shell 将特殊字符,称为元字符,视为数据的特殊表示。最常见的元字符是 * ,它表示文件名中的任意数量的字符。元字符可以用于执行文件名通配符匹配。例如,echo * 等同于 ls ,因为 shell 会将与 * 匹配的所有文件取出,并在命令行上列出它们。
为了防止 shell 解释特殊字符,可以通过在特殊字符前加上反斜杠(\)来将其从 shell 中转义。例如, echo $TERM 会打印终端设置,而 echo \$TERM 会直接打印字符串 $TERM。
3.9.1. 更改 Shell
永久更改默认 shell 的最简单方法是使用 chsh 命令。运行此命令将打开在 EDITOR 环境变量中配置的编辑器,默认设置为 vi(1)。将 Shell: 行更改为新 shell 的完整路径。
或者,使用 chsh -s 命令可以在不打开编辑器的情况下设置指定的 shell。例如,要将 shell 更改为 bash:
% chsh -s /usr/local/bin/bash在提示符处输入您的密码,然后按下 Return 键来更改您的 shell。注销并重新登录以开始使用新的 shell。
|
新的 shell 必须存在于 然后,重新运行 chsh(1)。 |
3.9.2. 高级 Shell 技巧
UNIX® shell 不仅仅是一个命令解释器,它还是一个强大的工具,允许用户执行命令、重定向输出、重定向输入以及链式组合命令,以提高最终命令的输出。当这种功能与内置命令结合使用时,用户可以获得一个可以最大化效率的环境。
Shell 重定向是将命令的输出或输入发送到另一个命令或文件的操作。例如,要将 ls(1) 命令的输出捕获到文件中,可以使用重定向操作:
% ls > directory_listing.txt目录内容现在将会列在 directory_listing.txt 中。一些命令可以用来读取输入,比如 sort(1) 。要对这个列表进行排序,可以重定向输入:
% sort < directory_listing.txt输入将被排序并显示在屏幕上。要将该输入重定向到另一个文件,可以通过混合方向来重定向 sort(1) 的输出。
% sort < directory_listing.txt > sorted.txt在所有之前的示例中,命令都是使用文件描述符进行重定向。每个 UNIX® 系统都有文件描述符,包括标准输入 (stdin)、标准输出 (stdout) 和标准错误 (stderr)。每个文件描述符都有其用途,其中输入可以是键盘或鼠标,提供输入的设备。输出可以是屏幕或打印机上的纸张。而错误则是用于诊断或错误消息的任何内容。这三个都被视为基于 I/O 的文件描述符,有时也被称为流。
通过使用这些描述符, Shell 允许输出和输入在各个命令之间传递,并可以重定向到文件或从文件中读取。另一种重定向的方法是管道操作符。
UNIX® 管道操作符“|”允许将一个命令的输出直接传递或定向到另一个程序。基本上,管道允许将一个命令的标准输出作为另一个命令的标准输入传递,例如:
% cat directory_listing.txt | sort | less在这个例子中,directory_listing.txt 的内容将被排序,并且输出将传递给 less(1) 。这使得用户可以按照自己的节奏滚动输出,并防止其滚动到屏幕外。
3.10. 文本编辑器
大多数 FreeBSD 的配置是通过编辑文本文件来完成的,因此熟悉文本编辑器是一个好主意。FreeBSD 自带了一些基本系统的文本编辑器,还有更多的编辑器可以在 Ports Collection 中找到。
一个简单的学习编辑器是 ee(1) ,它代表着 easy editor(简易编辑器)。要启动这个编辑器,输入 ee filename,其中 filename 是要编辑的文件名。一旦进入编辑器,所有用于操作编辑器功能的命令都列在显示屏的顶部。插入符号(^)代表 Ctrl,所以 ^e 扩展为 Ctrl+e。要离开 ee(1),按下 Esc,然后从主菜单中选择“离开编辑器”选项。如果文件已被修改,编辑器将提示保存任何更改。
FreeBSD 还配备了更强大的文本编辑器,例如 vi(1),作为基本系统的一部分。其他编辑器,如 editors/emacs 和 editors/vim,是 FreeBSD Ports Collection 的一部分。这些编辑器提供了更多的功能,但学习起来更加复杂。学习使用像 vim 或 Emacs 这样更强大的编辑器可以在长期来看节省更多的时间。
许多修改文件或需要输入文本的应用程序会自动打开一个文本编辑器。要更改默认的编辑器,请按照 Shells 中描述的方式设置 EDITOR 环境变量。
3.11. 设备和设备节点
设备是系统中主要用于硬件相关活动的术语,包括磁盘、打印机、显卡和键盘等。当 FreeBSD 启动时,大部分引导消息都是关于检测到的设备。引导消息的副本保存在 /var/run/dmesg.boot 中。
每个设备都有一个设备名称和编号。例如, ada0 表示第一个 SATA 硬盘,而 kbd0 表示键盘。
在 FreeBSD 中,大多数设备必须通过称为设备节点的特殊文件进行访问,这些文件位于 /dev 目录中。
3.12. 手册页
FreeBSD 上最全面的文档是以手册页的形式存在的。系统上几乎每个程序都附带有一个简短的参考手册,解释其基本操作和可用参数。可以使用 man 命令查看这些手册。
% man command其中 command 是要了解的命令的名称。例如,要了解有关 ls(1) 的更多信息,请输入:
% man ls手册页被分为不同的章节,代表不同的主题类型。在 FreeBSD 中,有以下几个章节可用:
-
用户命令。
-
系统调用和错误编号。
-
C 库中的函数。
-
设备驱动程序。
-
文件格式。
-
游戏和其他娱乐活动。
-
杂项信息。
-
系统维护和操作命令。
-
系统内核接口。
在某些情况下,同一个主题可能会出现在在线手册的多个部分中。例如,有一个 chmod 用户命令和一个 chmod() 系统调用。要告诉 man(1) 显示哪个部分,需要指定部分号码:
% man 1 chmod如果不知道手册页的名称,请使用 man -k 在手册页描述中搜索关键字:
% man -k mail该命令显示具有关键字“mail”在其描述中的命令列表。这相当于使用 apropos(1) 命令。
要阅读 /usr/sbin 目录下所有命令的描述,请输入:
% cd /usr/sbin
% man -f * | more或者
% cd /usr/sbin
% whatis * |more3.12.1. GNU Info 文件
FreeBSD 包含了由自由软件基金会(FSF)制作的多个应用程序和实用工具。除了手册页,这些程序还可能包括称为 info 文件的超文本文档。可以使用 info(1) 命令或者如果安装了 editors/emacs ,可以使用 emacs 的 info 模式来查看这些文件。
要使用 info(1),请输入:
% info要进行简要介绍,请输入 h。要查看快速命令参考,请输入 ?。
Chapter 4. 安装应用程序:软件包和 Ports
4.1. 简介
FreeBSD 捆绑了丰富的系统工具作为基本系统的一部分。此外,FreeBSD 还提供了两种互补的技术来安装第三方软件:FreeBSD Ports Collection 用于从源代码安装,而软件包则用于从预编译的二进制文件安装。可以使用任一方法从本地媒体或网络安装软件。
阅读完本章后,您将了解:
-
二进制包和 ports 之间的区别。
-
如何找到已经移植到 FreeBSD 的第三方软件。
-
如何使用 pkg 管理二进制软件包。
-
如何使用 Ports Collection 从源代码构建第三方软件。
-
如何找到应用程序安装后的文件,以进行后续配置。
-
如果软件安装失败,应该怎么办。
4.2. 软件安装概述
FreeBSD 的 ports 是一组文件,旨在自动化从源代码编译应用程序的过程。组成 ports 的文件包含了自动下载、提取、打补丁、编译和安装应用程序所需的所有必要信息。
如果软件尚未在 FreeBSD 上进行适配和测试,源代码可能需要进行编辑,以便正确安装和运行。
然而,在 36000 上已经有许多第三方应用程序被移植到了 FreeBSD。在可行的情况下,这些应用程序会以预编译的软件包形式提供下载。
可以使用 FreeBSD 软件包管理命令来操作软件包。
包和 ports 都能理解依赖关系。如果使用包或 ports 来安装一个应用程序,并且所依赖的库尚未安装,那么该库将会自动被先安装。
一个 FreeBSD 软件包包含了一个应用程序的预编译副本,以及任何配置文件和文档。可以使用 pkg(8) 命令来操作软件包,例如 pkg install。
虽然这两种技术相似,但软件包和 ports 各有各的优势。选择符合您安装特定应用程序需求的技术。
包的好处
-
通常,压缩的软件包 tarball 比包含应用程序源代码的压缩 tarball 要小。
-
包不需要编译时间。对于大型应用程序,如 Firefox 、KDE Plasma 或 GNOME,在慢速系统上这一点可能很重要。
-
在 FreeBSD 上编译软件的过程中,包不需要任何理解。
Port 的好处
-
通常情况下,软件包会使用保守的选项进行编译,因为它们需要在尽可能多的系统上运行。通过从 ports 进行编译,可以更改编译选项。
-
一些应用程序具有与安装的功能相关的编译时选项。例如,NGINX® 可以配置多种不同的内置选项。
在某些情况下,为了指定特定的设置,同一个应用程序可能会存在多个软件包。例如,NGINX® 有一个
nginx软件包和一个nginx-lite软件包,取决于是否安装了 Xorg。如果一个应用程序有超过一两个不同的编译选项,创建多个软件包将很快变得不可能。 -
一些软件的许可条件禁止二进制分发。这类软件必须以源代码的形式分发,并由最终用户进行编译。
-
有些人不信任二进制发行版,或者更喜欢阅读源代码以寻找潜在问题。
-
为了应用自定义补丁,需要提供源代码。
要跟踪更新的 ports ,请订阅 FreeBSD ports mailing list 和 FreeBSD ports bugs mailing list 。
|
在安装应用程序之前,请检查 https://vuxml.freebsd.org/ 是否存在相关的安全问题。 要对已安装的软件包进行已知漏洞的审计,请运行 |
本章的其余部分将解释如何使用软件包和 ports 在 FreeBSD 上安装和管理第三方软件。
4.3. 寻找软件
FreeBSD 的可用应用程序列表不断增长。有多种方法可以找到要安装的软件:
-
FreeBSD 网站维护着一个最新的可搜索的应用程序列表,位于 Ports Portal。可以通过应用程序名称或软件类别来搜索 ports。
-
Dan Langille 维护着 FreshPorts,该网站提供了一个全面的搜索工具,并跟踪 Ports Collection 中应用程序的变化。注册用户可以创建一个定制的监视列表,以便在所监视的 ports 更新时收到自动邮件通知。
-
如果找到一个特定的应用程序变得困难,可以尝试在 SourceForge 或者 GitHub 这样的网站上进行搜索,然后再回到 Ports Portal 查看该应用程序是否已经被移植。
-
使用 pkg(8) 命令在二进制软件包仓库中搜索一个应用程序
4.4. 使用 pkg 进行二进制包管理
pkg(8) 提供了一个用于操作软件包的接口:注册、添加、删除和升级软件包。
对于只希望使用 FreeBSD 镜像站点提供的预编译二进制包的网站,使用 pkg(8) 来管理软件包可能已经足够了。
然而,对于那些从源代码构建网站的用户,将需要使用单独的 ports 管理工具。
4.4.1. 开始使用 pkg
|
在引导过程中,需要一个互联网连接才能成功。 |
运行 pkg(8) 命令行:
# pkg输出应该类似于以下内容:
The package management tool is not yet installed on your system. Do you want to fetch and install it now? [y/N]
较新版本的 pkg(7) 可以理解 pkg -N 作为一种测试,用于检查是否安装了 pkg(8),而不触发安装操作。相反,pkg bootstrap[-f] 用于安装 pkg(8)(或强制重新安装),而不执行任何其他操作。
可以通过查看 pkg(8) 手册页面或者在运行 pkg 命令时不添加额外参数来获取 pkg 的使用信息。有关其他 pkg 配置选项的描述,请参阅 pkg.conf(5) 。
每个 pkg 命令参数都在特定命令的手册页中有详细说明。
例如,要阅读 pkg install 的手册页,请运行以下命令:
# pkg help install本节的其余部分演示了使用 pkg(8) 执行的常见二进制包管理任务。每个演示的命令都提供了许多开关来自定义其使用方式。有关详细信息和更多示例,请参阅命令的帮助或 man 页面。
4.4.2. 季度和最新的 ports 分支
Quarterly 分支为用户提供了更可预测和稳定的 ports 和软件包安装和升级体验。这主要通过只允许非功能性更新来实现。季度分支旨在接收安全修复(可能是版本更新或提交的回溯)、错误修复和 ports 合规性或框架更改。季度分支在每年的一月、四月、七月和十月的季度初从 HEAD 中切出。分支的命名方式根据它们创建的年份(YYYY)和季度(Q1-4)。例如, 2023 年 1 月创建的季度分支被命名为 2023Q1。而 Latest 分支为用户提供了软件包的最新版本。
要将 pkg(8) 从季度版切换到最新版,请运行以下命令:
# mkdir -p /usr/local/etc/pkg/repos
# echo 'FreeBSD: { url: "pkg+http://pkg.FreeBSD.org/${ABI}/latest" }' > /usr/local/etc/pkg/repos/FreeBSD.conf然后运行以下命令来更新本地软件包仓库目录,以获取最新分支的内容:
# pkg update -f4.4.3. 配置 pkg
pkg.conf(5) 是 pkg(8) 工具使用的系统级配置文件。该文件的默认位置是 /usr/local/etc/pkg.conf。
|
FreeBSD 不需要有 |
以"#"开头的行是注释,会被忽略。
该文件采用 UCL 格式。有关 libucl(3) 语法的更多信息,请访问 official UCL website 。
识别以下类型的选项 - 布尔型、字符串型和列表型选项。
如果在配置文件中指定了以下值之一 - YES 、TRUE 和 ON,则将布尔选项标记为已启用。
4.4.4. 搜索软件包
要搜索一个软件包,可以使用 pkg-search(8) 命令:
# pkg search nginx输出应该类似于以下内容:
modsecurity3-nginx-1.0.3 Instruction detection and prevention engine / nginx Wrapper nginx-1.22.1_2,3 Robust and small WWW server nginx-devel-1.23.2_4 Robust and small WWW server nginx-full-1.22.1_1,3 Robust and small WWW server (full package) nginx-lite-1.22.1,3 Robust and small WWW server (lite package) nginx-naxsi-1.22.1,3 Robust and small WWW server (plus NAXSI) nginx-prometheus-exporter-0.10.0_7 Prometheus exporter for NGINX and NGINX Plus stats nginx-ultimate-bad-bot-blocker-4.2020.03.2005_1 Nginx bad bot and other things blocker nginx-vts-exporter-0.10.7_7 Server that scraps NGINX vts stats and export them via HTTP p5-Nginx-ReadBody-0.07_1 Nginx embeded perl module to read and evaluate a request body p5-Nginx-Simple-0.07_1 Perl 5 module for easy to use interface for Nginx Perl Module p5-Test-Nginx-0.30 Testing modules for Nginx C module development py39-certbot-nginx-2.0.0 NGINX plugin for Certbot rubygem-passenger-nginx-6.0.15 Modules for running Ruby on Rails and Rack applications
4.4.5. 安装和获取软件包
要安装一个二进制软件包,可以使用 pkg-install(8) 命令。该命令使用存储库数据来确定要安装的软件的版本以及是否有未安装的依赖项。例如,要安装 curl :
# pkg install curl输出应该类似于以下内容:
Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
All repositories are up to date.
The following 9 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
ca_root_nss: 3.83
curl: 7.86.0
gettext-runtime: 0.21
indexinfo: 0.3.1
libidn2: 2.3.3
libnghttp2: 1.48.0
libpsl: 0.21.1_4
libssh2: 1.10.0.3
libunistring: 1.0
Number of packages to be installed: 9
The process will require 11 MiB more space.
3 MiB to be downloaded
Proceed with this action? [y/N]
新的软件包以及作为依赖项安装的任何其他软件包都可以在已安装软件包列表中看到:
# pkg info输出应该类似于以下内容:
ca_root_nss-3.83 Root certificate bundle from the Mozilla Project curl-7.86.0 Command line tool and library for transferring data with URLs gettext-runtime-0.21.1 GNU gettext runtime libraries and programs indexinfo-0.3.1 Utility to regenerate the GNU info page index libidn2-2.3.3 Implementation of IDNA2008 internationalized domain names libnghttp2-1.48.0 HTTP/2.0 C Library libpsl-0.21.1_6 C library to handle the Public Suffix List libssh2-1.10.0.3 Library implementing the SSH2 protocol libunistring-1.0 Unicode string library pkg-1.18.4 Package manager
要获取一个软件包并稍后安装它或在另一个地方安装,请使用 pkg-fetch(8)。例如,要下载 nginx-lite:
# pkg fetch -d -o /usr/home/user/packages/ nginx-lite-
-d:用于获取所有的依赖项 -
-o:用于指定下载目录
输出应该类似于以下内容:
Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
All repositories are up to date.
The following packages will be fetched:
New packages to be FETCHED:
nginx-lite: 1.22.1,3 (342 KiB: 22.20% of the 2 MiB to download)
pcre: 8.45_3 (1 MiB: 77.80% of the 2 MiB to download)
Number of packages to be fetched: 2
The process will require 2 MiB more space.
2 MiB to be downloaded.
Proceed with fetching packages? [y/N]:
要安装下载的软件包,可以使用 pkg-install(8) 命令,具体操作如下:
# cd /usr/home/user/packages/# pkg install nginx-lite-1.22.1,3.pkg4.4.6. 获取已安装软件包的信息
可以通过运行 pkg-info(8) 来查看系统上安装的软件包的信息。当不带任何开关运行时,它将列出所有已安装软件包或指定软件包的版本信息。
例如,要查看已安装的 pkg 版本,请运行:
# pkg info pkg输出应该类似于以下内容:
pkg-1.19.0 Name : pkg Version : 1.19.0 Installed on : Sat Dec 17 11:05:28 2022 CET Origin : ports-mgmt/pkg Architecture : FreeBSD:13:amd64 Prefix : /usr/local Categories : ports-mgmt Licenses : BSD2CLAUSE Maintainer : [email protected] WWW : https://github.com/freebsd/pkg Comment : Package manager Options : DOCS : on Shared Libs provided: libpkg.so.4 Annotations : FreeBSD_version: 1301000 repo_type : binary repository : FreeBSD Flat size : 33.2MiB Description : Package management tool WWW: https://github.com/freebsd/pkg
4.4.7. 升级已安装的软件包
已安装的软件包可以使用 pkg-upgrade(8) 命令升级到最新版本。
# pkg upgrade该命令将比较已安装的版本与存储库目录中可用的版本,并从存储库中升级它们。
4.4.8. 审核已安装的软件包
第三方应用程序经常会发现软件漏洞。为了解决这个问题,pkg 包含了一个内置的审计机制。要确定系统上安装的软件是否存在已知的漏洞,请使用 pkg-audit(8) 命令。
# pkg audit -F输出应该类似于以下内容:
Fetching vuln.xml.xz: 100% 976 KiB 499.5kB/s 00:02 chromium-108.0.5359.98 is vulnerable: chromium -- multiple vulnerabilities CVE: CVE-2022-4440 CVE: CVE-2022-4439 CVE: CVE-2022-4438 CVE: CVE-2022-4437 CVE: CVE-2022-4436 WWW: https://vuxml.FreeBSD.org/freebsd/83eb9374-7b97-11ed-be8f-3065ec8fd3ec.html
4.4.9. 移除软件包
不再需要的软件包可以使用 pkg-delete(8) 命令进行删除。
例如:
# pkg delete curl输出应该类似于以下内容:
Checking integrity... done (0 conflicting)
Deinstallation has been requested for the following 1 packages (of 0 packages in the universe):
Installed packages to be REMOVED:
curl :7.86.0
Number of packages to be removed: 1
The operation will free 4 MiB.
Proceed with deinstallation packages? [y/N]: y
[1/1] Deinstalling curl-7.86.0...
[1/1] Deleting files for curl-7.86.0: 100%
4.4.10. 自动删除未使用的软件包
删除一个软件包可能会留下不再需要的依赖项。可以使用 pkg-autoremove(8) 自动检测和删除作为依赖项安装的不需要的软件包(叶子软件包)。
# pkg autoremove输出应该类似于以下内容:
Checking integrity... done (0 conflicting)
Deinstallation has been requested for the following 1 packages:
Installed packages to be REMOVED:
ca_root_nss-3.83
Number of packages to be removed: 1
The operation will free 723 KiB.
Proceed with deinstalling packages? [y/N]:
作为依赖安装的软件包被称为 自动 软件包。非自动软件包,即明确安装而不是作为其他软件包的依赖项安装的软件包,可以使用以下命令列出:
# pkg prime-list输出应该类似于以下内容:
nginx openvpn sudo
pkg prime-list 是在 /usr/local/etc/pkg.conf 中声明的一个别名命令。系统中还有许多其他命令可以用来查询软件包数据库。例如,命令 pkg prime-origins 可以用来获取上述列表的源 ports 目录。
# pkg prime-origins输出应该类似于以下内容:
www/nginx security/openvpn security/sudo
这个列表可以用于使用构建工具(如 ports-mgmt/poudriere 或 ports-mgmt/synth)重新构建系统上安装的所有软件包。
将已安装的软件包标记为自动安装可以使用以下方法:
# pkg set -A 1 devel/cmake一旦一个包是一个叶子包并且被标记为自动安装,它将被 pkg autoremove 命令选择删除。
将已安装的软件包标记为 非 自动安装可以使用以下方法:
# pkg set -A 0 devel/cmake4.4.11. 移除过期的软件包
默认情况下,pkg 将二进制软件包存储在由 pkg.conf(5) 中的 PKG_CACHEDIR 定义的缓存目录中。只保留最新安装的软件包的副本。旧版本的 pkg 会保留所有先前的软件包。要删除这些过时的二进制软件包,请运行:
# pkg clean可以通过运行以下命令来清除整个缓存:
# pkg clean -a4.4.12. 锁定和解锁软件包
pkg-lock(8) 用于锁定包,防止重新安装、修改或删除。pkg-unlock(8) 用于解锁指定的包。无论哪种变体,都只对当前已安装的包产生影响。因此,除非安装新包意味着更新已锁定的包,否则无法通过此机制阻止新包的安装。
例如,要锁定 nginx-lite:
# pkg lock nginx-lite要解锁 nginx-lite:
# pkg unlock nginx-lite4.4.13. 修改软件包元数据
FreeBSD Ports Collection 中的软件可能会经历主版本号的更改。为了解决这个问题,pkg 有一个内置命令来更新软件包的来源。这在某些情况下非常有用,例如,如果 lang/python3 被重命名为 lang/python311 ,那么 lang/python3 现在可以表示版本 3.11。
要更改上面示例的软件包来源,请运行以下命令:
# pkg set -o lang/python3:lang/python311另一个例子是,要将 lang/ruby31 更新为 lang/ruby32,运行以下命令:
# pkg set -o lang/ruby31:lang/ruby32|
在更改软件包来源时,重要的是重新安装依赖于已修改来源的软件包。要强制重新安装依赖软件包,请运行: |
4.5. 使用 Ports 集合
Ports Collection 是一组 Makefiles、补丁和描述文件。每组这些文件用于在 FreeBSD 上编译和安装单个应用程序,被称为一个 ports。
默认情况下,Ports Collection 本身存储在 /usr/ports 的子目录中。
|
在安装和使用 Ports Collection 之前,请注意通常不建议使用 Ports Collection 与通过 pkg 提供的二进制软件包一起安装软件。 pkg 默认跟踪 ports 树的季度分支发布,而不是 HEAD 。与季度分支发布中的对应 ports 相比, HEAD 中的 ports 的依赖关系可能不同,这可能导致 pkg 安装的依赖关系与 Ports Collection 中的依赖关系发生冲突。如果必须同时使用 Ports Collection 和 pkg ,请确保您的 Ports Collection 和 pkg 位于相同的 ports 树分支发布上。 |
Ports 集合包含了软件类别的目录。每个类别中都有针对个别应用程序的子目录。每个应用程序子目录包含一组文件,告诉 FreeBSD 如何编译和安装该程序,称为 ports skeleton。每个 ports 骨架包括以下文件和目录:
-
Makefile:包含指定应用程序如何编译以及其组件应安装在何处的语句。
-
distinfo:包含构建 ports 所需下载的文件的名称和校验和。
-
files/:这个目录包含了在 FreeBSD 上编译和安装程序所需的补丁文件。这个目录也可能包含其他用于构建 ports 的文件。
-
pkg-descr:提供程序的更详细描述。
-
pkg-plist:一个包含所有将由 ports 安装的文件的列表。它还告诉 ports 系统在卸载时要删除哪些文件。
一些 ports 包括 pkg-message 或其他文件来处理特殊情况。有关这些文件以及 ports 的更多详细信息,请参考 FreeBSD Porter’s Handbook。
ports 不包含实际的源代码,也称为 `distfile` 。构建 ports 的提取部分将自动将下载的源代码保存到 `/usr/ports/distfiles`。
4.5.2. 安装 Ports
本节提供了使用 Ports Collection 安装或删除软件的基本说明。有关可用的 make 目标和环境变量的详细描述,请参阅 ports(7)。
|
在编译任何 ports 之前,请确保按照前一节中的描述更新 Ports Collection。由于安装任何第三方软件都可能引入安全漏洞,建议首先在 https://vuxml.freebsd.org/ 上检查与该 ports 相关的已知安全问题。或者,在安装新 ports 之前运行 |
使用 Ports 集合需要一个正常的互联网连接。它还需要超级用户权限。
要编译和安装 ports,请切换到要安装的 ports 的目录,然后在提示符下键入 make install。消息将指示进度:
# cd /usr/ports/sysutils/lsof
# make install
>> lsof_4.88D.freebsd.tar.gz doesn't seem to exist in /usr/ports/distfiles/.
>> Attempting to fetch from ftp://lsof.itap.purdue.edu/pub/tools/unix/lsof/.
===> Extracting for lsof-4.88
...
[extraction output snipped]
...
>> Checksum OK for lsof_4.88D.freebsd.tar.gz.
===> Patching for lsof-4.88.d,8
===> Applying FreeBSD patches for lsof-4.88.d,8
===> Configuring for lsof-4.88.d,8
...
[configure output snipped]
...
===> Building for lsof-4.88.d,8
...
[compilation output snipped]
...
===> Installing for lsof-4.88.d,8
...
[installation output snipped]
...
===> Generating temporary packing list
===> Compressing manual pages for lsof-4.88.d,8
===> Registering installation for lsof-4.88.d,8
===> SECURITY NOTE:
This port has installed the following binaries which execute with
increased privileges.
/usr/local/sbin/lsof
#由于 lsof 是一个以增加权限运行的程序,因此在安装时会显示一个安全警告。安装完成后,提示符将会返回。
一些 shell 会在 PATH 环境变量所列目录中保留一个命令缓存,以加快对这些命令可执行文件的查找操作。使用 tcsh shell 的用户应该输入 rehash 命令,以便可以在不指定完整路径的情况下使用新安装的命令。对于 sh shell,请使用 hash -r 命令。有关更多信息,请参阅 shell 的文档。
在安装过程中,会创建一个工作子目录,其中包含编译过程中使用的所有临时文件。删除此目录可以节省磁盘空间,并在以后升级到新版本的 ports 时最大程度地减少问题的可能性。
# make clean
===> Cleaning for lsof-88.d,8
#|
为了避免这个额外的步骤,编译 ports 时可以使用 |
4.5.2.1. 自定义 ports 安装
一些 ports 提供构建选项,可以用于启用或禁用应用程序组件,提供安全选项或允许其他自定义。示例包括 www/firefox 和 security/gpgme。如果该 ports 依赖于具有可配置选项的其他 ports,则默认行为是提示用户从菜单中选择选项,因此可能会多次暂停以进行用户交互。为了避免这种情况,并在一个批处理中进行所有配置,请在 ports 骨架中运行 make config-recursive。然后,运行 make install [clean] 来编译和安装该 ports。
|
当使用 |
在构建 ports 后,有几种方法可以重新访问 ports 的构建选项菜单,以添加、删除或更改这些选项。一种方法是进入包含 ports 的目录,然后输入 make config 命令。另一种选择是使用 make showconfig 命令。还可以执行 make rmconfig 命令,该命令将删除所有已选择的选项,并允许您重新开始。所有这些选项以及其他选项都在 ports(7) 中详细解释。
ports 系统使用 fetch(1) 来下载源文件,该工具支持各种环境变量。如果 FreeBSD 系统位于防火墙或 FTP/HTTP 代理后面,可能需要设置 FTP_PASSIVE_MODE、FTP_PROXY 和 FTP_PASSWORD 变量。有关支持的变量的完整列表,请参阅 fetch(3)。
对于不能始终连接到互联网的用户,可以在 /usr/ports 目录下运行 make fetch 命令,以获取所有的 distfiles,或者在某个分类目录(例如 /usr/ports/net)或特定的 ports 骨架中运行。请注意,如果一个 ports 有任何依赖项,那么在分类目录或 ports 骨架中运行此命令将不会获取来自其他分类的 ports 的 distfiles。相反,使用 make fetch-recursive 命令也可以获取 ports 的所有依赖项的 distfiles。
在极少数情况下,例如当组织拥有本地的 distfiles 仓库时,MASTER_SITES 变量可以用于覆盖 Makefile 中指定的下载位置。在使用时,请指定替代位置:
# cd /usr/ports/directory
# make MASTER_SITE_OVERRIDE= \
ftp://ftp.organization.org/pub/FreeBSD/ports/distfiles/ fetchWRKDIRPREFIX 和 PREFIX 变量可以覆盖默认的工作目录和目标目录。例如:
# make WRKDIRPREFIX=/usr/home/example/ports install将 ports 编译在 /usr/home/example/ports 目录下,并将所有内容安装在 /usr/local 目录下。
# make PREFIX=/usr/home/example/local install将 ports 编译在 /usr/ports 中,并将其安装在 /usr/home/example/local 中。并且:
# make WRKDIRPREFIX=../ports PREFIX=../local install将两者合并。
这些也可以设置为环境变量。请参考您所使用的 shell 的手册页面,了解如何设置环境变量的指令。
4.5.3. 移除已安装的 ports
使用 pkg delete 命令可以卸载已安装的 ports。有关使用此命令的示例,请参阅 pkg-delete(8) 手册页。
或者,可以在 ports 的目录中运行 make deinstall 命令:
# cd /usr/ports/sysutils/lsof
# make deinstall
===> Deinstalling for sysutils/lsof
===> Deinstalling
Deinstallation has been requested for the following 1 packages:
lsof-4.88.d,8
The deinstallation will free 229 kB
[1/1] Deleting lsof-4.88.d,8... done建议在卸载 ports 之前阅读消息。如果该 ports 有任何依赖于它的应用程序,这些信息将被显示,但卸载将继续进行。在这种情况下,重新安装应用程序可能更好,以防止依赖关系破裂。
4.5.4. 升级 ports
随着时间的推移,Ports Collection 中会有更新版本的软件可用。本节介绍了如何确定可以升级的软件以及如何执行升级操作。
要确定已安装的 ports 是否有更新版本可用,请确保安装了最新版本的 ports 树,使用在 "Git Method" 中描述的更新命令。以下命令将列出已过时的已安装 ports:
# pkg version -l "<"|
在尝试升级之前,请从文件顶部开始阅读 |
4.5.4.1. 升级和管理 ports 的工具
Ports Collection 包含多个实际执行升级的实用工具。每个工具都有其优点和缺点。
从历史上看,大多数安装使用的是 Portmaster 或 Portupgrade 。Synth 是一种较新的替代方案。
|
选择哪种工具最适合特定系统是由系统管理员决定的。在使用这些工具之前,建议先备份数据。 |
4.5.4.2. 使用 Portmaster 升级 Ports
ports-mgmt/portmaster 是一个非常小的工具,用于升级已安装的 ports。它旨在使用安装在 FreeBSD 基本系统中的工具,而不依赖其他 ports 或数据库。要将此实用程序安装为一个 ports:
# cd /usr/ports/ports-mgmt/portmaster
# make install cleanPortmaster 定义了四个 ports 的分类:
-
Root ports:没有依赖项,也不是任何其他 ports 的依赖项。
-
Trunk ports:没有依赖项,但其他 ports 依赖于它。
-
Branch ports:具有依赖关系,其他 ports 依赖于它。
-
Leaf ports:具有依赖关系,但没有其他 ports 依赖于它。
要列出这些类别并搜索更新:
# portmaster -L
===>>> Root ports (No dependencies, not depended on)
===>>> ispell-3.2.06_18
===>>> screen-4.0.3
===>>> New version available: screen-4.0.3_1
===>>> tcpflow-0.21_1
===>>> 7 root ports
...
===>>> Branch ports (Have dependencies, are depended on)
===>>> apache22-2.2.3
===>>> New version available: apache22-2.2.8
...
===>>> Leaf ports (Have dependencies, not depended on)
===>>> automake-1.9.6_2
===>>> bash-3.1.17
===>>> New version available: bash-3.2.33
...
===>>> 32 leaf ports
===>>> 137 total installed ports
===>>> 83 have new versions available这个命令用于升级所有过时的 ports:
# portmaster -a|
默认情况下,Portmaster 在删除现有 ports 之前会创建一个备份包。如果新版本的安装成功,Portmaster 会删除备份。使用 |
如果在升级过程中遇到错误,请在升级和重建所有 ports 时添加 -f。
# portmaster -afPortmaster 还可以用于在系统上安装新的 ports,在构建和安装新的 ports 之前升级所有依赖项。要使用此功能,请指定 Ports Collection 中 ports 的位置:
# portmaster shells/bash有关 ports-mgmt/portmaster 的更多信息可以在其 pkg-descr 中找到。
4.5.4.3. 使用 Portupgrade 升级 ports
ports-mgmt/portupgrade 是另一个可以用来升级 ports 的实用工具。它安装了一套可以用来管理 ports 的应用程序。然而,它依赖于 Ruby。要安装该 ports:
# cd /usr/ports/ports-mgmt/portupgrade
# make install clean在使用此工具进行升级之前,建议使用 pkgdb -F 扫描已安装的 ports 列表,并修复它报告的所有不一致性。
要升级系统上安装的所有过时 ports,请使用 portupgrade -a。或者,加入 -i 以便在每次单独升级时要求确认:
# portupgrade -ai要升级指定的应用程序而不是所有可用的 ports,请使用 portupgrade pkgname。非常重要的是要包括 -R 选项,以先升级给定应用程序所需的所有 ports:
# portupgrade -R firefox如果包含了 -P 选项,Portupgrade 会在 PKG_PATH 列出的本地目录中搜索可用的软件包。如果本地没有可用的软件包,它会从远程站点获取软件包。如果无法在本地或远程获取软件包,Portupgrade 将使用 ports。为了完全避免使用 ports,可以指定 -PP 选项。最后一组选项告诉 Portupgrade 如果没有可用的软件包则中止操作。
# portupgrade -PP gnome3如果指定了 -P,只需获取 ports distfiles 或软件包,而不需要构建或安装任何内容,请使用 -F 。有关所有可用开关的更多信息,请参阅 `portupgrade 的手册页。
有关 ports-mgmt/portupgrade 的更多信息可以在其 pkg-descr 中找到。
4.5.5. ports 和磁盘空间
使用 Ports Collection 会随着时间的推移占用磁盘空间。在构建和安装 ports 之后,在 ports 骨架中运行 make clean 将清理临时的 work 目录。如果使用 Portmaster 安装 ports,它会自动删除此目录,除非指定了 -K 选项。如果安装了 Portupgrade,此命令将删除在本地 Ports Collection 副本中找到的所有 work 目录:
# portsclean -C此外,随着时间的推移,过时的源代码分发文件会在 /usr/ports/distfiles 中累积。要使用 Portupgrade 删除所有不再被任何 ports 引用的分发文件:
# portsclean -DPortupgrade 可以删除系统上当前未安装任何 ports 引用的所有 distfiles 文件。
# portsclean -DD如果已安装 Portmaster,请使用:
# portmaster --clean-distfiles默认情况下,该命令是交互式的,并提示用户确认是否删除 distfile。
除了这些命令之外,ports-mgmt/pkg_cutleaves 还可以自动化删除不再需要的已安装 ports 的任务。
4.6. 使用 poudriere 构建软件包
poudriere 是一个使用 BSD 许可证的实用工具,用于创建和测试 FreeBSD 软件包。它使用 FreeBSD jails 来设置隔离的编译环境。这些 jails 可以用于为与安装它的系统不同的 FreeBSD 版本构建软件包,也可以用于在主机是 amd64 系统的情况下构建 i386 的软件包。一旦软件包构建完成,它们的布局与官方镜像完全相同。这些软件包可以被 pkg(8) 和其他软件包管理工具使用。
poudriere 是使用 ports-mgmt/poudriere 包或 ports 进行安装的。安装过程中包含一个示例配置文件 /usr/local/etc/poudriere.conf.sample。将此文件复制到 /usr/local/etc/poudriere.conf。编辑复制的文件以适应本地配置。
虽然在运行 poudriere 的系统上不需要 ZFS,但它是有益的。当使用 ZFS 时,必须在 /usr/local/etc/poudriere.conf 中指定 ZPOOL,并将 FREEBSD_HOST 设置为附近的镜像。定义 CCACHE_DIR 可以启用 devel/ccache 来缓存编译并减少频繁编译代码的构建时间。将 poudriere 数据集放在挂载在 /poudriere 的隔离树中可能很方便。其他配置值的默认设置是足够的。
检测到的处理器核心数量用于定义并行运行的构建数量。请提供足够的虚拟内存,可以是 RAM 或者交换空间。如果虚拟内存耗尽,编译环境将停止并被销毁,导致出现奇怪的错误信息。
4.6.1. 初始化 Jails 和 Port Trees
配置完成后,初始化 poudriere,以便安装一个包含所需 FreeBSD 树和 ports 树的 jail。使用 -j 指定 jail 的名称,并使用 -v 指定 FreeBSD 版本。在运行 FreeBSD/amd64 的系统上,可以使用 -a 将架构设置为 i386 或 amd64。默认架构为 uname 显示的架构。
# poudriere jail -c -j 13amd64 -v 13.1-RELEASE
[00:00:00] Creating 13amd64 fs at /poudriere/jails/13amd64... done
[00:00:00] Using pre-distributed MANIFEST for FreeBSD 13.1-RELEASE amd64
[00:00:00] Fetching base for FreeBSD 13.1-RELEASE amd64
/poudriere/jails/13amd64/fromftp/base.txz 125 MB 4110 kBps 31s
[00:00:33] Extracting base... done
[00:00:54] Fetching src for FreeBSD 13.1-RELEASE amd64
/poudriere/jails/13amd64/fromftp/src.txz 154 MB 4178 kBps 38s
[00:01:33] Extracting src... done
[00:02:31] Fetching lib32 for FreeBSD 13.1-RELEASE amd64
/poudriere/jails/13amd64/fromftp/lib32.txz 24 MB 3969 kBps 06s
[00:02:38] Extracting lib32... done
[00:02:42] Cleaning up... done
[00:02:42] Recording filesystem state for clean... done
[00:02:42] Upgrading using ftp
/etc/resolv.conf -> /poudriere/jails/13amd64/etc/resolv.conf
Looking up update.FreeBSD.org mirrors... 3 mirrors found.
Fetching public key from update4.freebsd.org... done.
Fetching metadata signature for 13.1-RELEASE from update4.freebsd.org... done.
Fetching metadata index... done.
Fetching 2 metadata files... done.
Inspecting system... done.
Preparing to download files... done.
Fetching 124 patches.....10....20....30....40....50....60....70....80....90....100....110....120.. done.
Applying patches... done.
Fetching 6 files... done.
The following files will be added as part of updating to
13.1-RELEASE-p1:
/usr/src/contrib/unbound/.github
/usr/src/contrib/unbound/.github/FUNDING.yml
/usr/src/contrib/unbound/contrib/drop2rpz
/usr/src/contrib/unbound/contrib/unbound_portable.service.in
/usr/src/contrib/unbound/services/rpz.c
/usr/src/contrib/unbound/services/rpz.h
/usr/src/lib/libc/tests/gen/spawnp_enoexec.sh
The following files will be updated as part of updating to
13.1-RELEASE-p1:
[…]
Installing updates...Scanning //usr/share/certs/blacklisted for certificates...
Scanning //usr/share/certs/trusted for certificates...
done.
13.1-RELEASE-p1
[00:04:06] Recording filesystem state for clean... done
[00:04:07] Jail 13amd64 13.1-RELEASE-p1 amd64 is ready to be used# poudriere ports -c -p local -m git+https
[00:00:00] Creating local fs at /poudriere/ports/local... done
[00:00:00] Checking out the ports tree... done在一台计算机上,poudriere 可以使用多个配置,在多个 jail 中,从不同的 ports 树构建 ports。这些组合的自定义配置被称为 集合。在安装了 ports-mgmt/poudriere 或 ports-mgmt/poudriere-devel 之后,可以查看 poudriere(8) 的 CUSTOMIZATION 部分获取详细信息。
这里显示的基本配置将一个单独的 jail、 port 和 set 特定的 make.conf 放置在 /usr/local/etc/poudriere.d 目录下。在这个示例中,文件名是通过组合 jail 名称、 port 名称和 set 名称创建的:13amd64-local-workstation-make.conf。系统的 make.conf 和这个新文件在构建时会合并,以创建构建 jail 使用的 make.conf 文件。
要构建的软件包应该在 13amd64-local-workstation-pkglist 文件中输入(具有 @FLAVOR 的 FLAVORS 的 ports 可以定义)。
editors/emacs devel/git devel/php-composer2@php82 ports-mgmt/pkg ...
已配置指定 ports 的选项和依赖项:
# poudriere options -j 13amd64 -p local -z workstation -f 13amd64-local-workstation-pkglist最后,构建软件包并创建软件包仓库:
# poudriere bulk -j 13amd64 -p local -z workstation -f 13amd64-local-workstation-pkglist在运行过程中,按下 Ctrl+t 键可以显示构建的当前状态。poudriere 还会在 /poudriere/logs/bulk/jailname 目录中构建文件,可以与 Web 服务器一起使用以显示构建信息。
完成后,新的软件包现在可以从 poudriere 仓库进行安装。
有关使用 poudriere 的更多信息,请参阅 poudriere(8) 和主要网站 https://github.com/freebsd/poudriere/wiki。
4.6.2. 配置 pkg 客户端以使用 poudriere 仓库
虽然可以同时使用自定义仓库和官方仓库,但有时禁用官方仓库是有用的。这可以通过创建一个配置文件来覆盖和禁用官方配置文件来实现。创建 /usr/local/etc/pkg/repos/FreeBSD.conf 文件,其中包含以下内容:
FreeBSD: {
enabled: no
}
通常,通过 HTTP 将 poudriere 仓库提供给客户机最为简单。设置一个 web 服务器来提供软件包目录,例如: /usr/local/poudriere/data/packages/13amd64,其中 13amd64 是构建的名称。
如果软件包仓库的 URL 是:http://pkg.example.com/13amd64,那么位于 /usr/local/etc/pkg/repos/custom.conf 的仓库配置文件将如下所示:
custom: {
url: "http://pkg.example.com/13amd64",
enabled: yes,
}
如果不希望将软件包仓库暴露在互联网上,可以使用 file:// 协议直接指向仓库:
custom: {
url: "file:///usr/local/poudriere/data/packages/11amd64",
enabled: yes,
}
4.7. 安装后的考虑事项
无论软件是从二进制包还是 ports 安装的,大多数第三方应用程序在安装后都需要进行一定程度的配置。以下命令和位置可用于帮助确定应用程序安装了什么。
-
大多数应用程序都会在
/usr/local/etc目录下安装至少一个默认配置文件。在应用程序有大量配置文件的情况下,会创建一个子目录来存放它们。通常,会安装一些以.sample后缀结尾的示例配置文件。应该审查并可能编辑这些配置文件以满足系统的需求。要编辑示例文件,首先将其复制并去掉.sample扩展名。 -
提供文档的应用程序会将文档安装到
/usr/local/share/doc目录下,许多应用程序还会安装手册页。在继续之前,应该先查阅这些文档。 -
一些应用程序运行的服务在启动应用程序之前必须添加到
/etc/rc.conf中。这些应用程序通常会在/usr/local/etc/rc.d中安装一个启动脚本。有关更多信息,请参阅 启动服务。根据设计,应用程序在安装时不会运行启动脚本,也不会在卸载或升级时运行停止脚本。这个决定留给了个别系统管理员来决定。
-
使用 csh(1) 的用户应该运行
rehash命令来重新构建 shell 的PATH中已知的二进制文件列表。 -
使用
pkg info命令来确定应用程序安装了哪些文件、man 页面和二进制文件。
4.8. 处理损坏的 ports
当 ports 无法构建或安装时,请尝试以下操作:
-
搜索一下 Problem Report database 中的 ports 是否有待修复的问题报告。如果有的话,实施建议的修复可能会解决这个问题。
-
向 ports 的维护者寻求帮助。在 ports 骨架中键入
make maintainer,或者阅读 ports 的Makefile以找到维护者的电子邮件地址。记得在发送给维护者的电子邮件中包含错误之前的输出。一些 ports 不是由个人维护,而是由一个由邮件列表表示的团队维护者维护。其中许多(但不是全部)地址看起来像 [email protected]。在发送电子邮件时,请考虑这一点。
特别是,由 [email protected] 维护的 ports 不由特定个人维护。相反,任何修复和支持都来自订阅该邮件列表的广大社区。我们始终需要更多的志愿者!
如果没有收到邮件回复,请按照 Writing FreeBSD Problem Reports 中的说明,使用 Bugzilla 提交错误报告。
-
修复它! Porter’s Handbook 包含了有关 ports 基础设施的详细信息,以便您可以修复偶尔出现的损坏 ports,甚至提交您自己的 ports!
-
按照 使用 pkg 进行二进制包管理 中的说明安装软件包,而不是使用 ports。
Chapter 5. X Window System (X Window系统)
5.1. 简介
使用 bsdinstall 安装 FreeBSD 时,不会自动安装图形用户界面。本章介绍了如何安装和配置 Xorg,它提供了用于提供图形环境的开源 X Window 系统。然后,它描述了如何查找和安装桌面环境或窗口管理器。
在阅读本章之前,您应该:
-
根据 安装应用程序:软件包和 Ports 中描述的方法,了解如何安装额外的第三方软件。
阅读完本章后,您将了解:
-
X Window 系统的各个组件以及它们之间的相互操作。
-
如何安装和配置 Xorg。
-
如何在 Xorg 中使用 TrueType® 字体。
-
如何设置系统以进行图形登录(XDM)。
5.2. 安装 Xorg
在 FreeBSD 上,Xorg 可以作为一个软件包或者端口进行安装。
二进制元包可以快速安装,但自定义选项较少:
# pkg install xorg任何一种安装方式都会导致完整的 Xorg 系统被安装。
当前用户必须是 video 组的成员。要将用户添加到 video 组中,请执行以下命令:
# pw groupmod video -m username|
适用于有经验的用户的 X 系统的较小版本可在包: x11/xorg-minimal[] 中获得。大多数文档、库和应用程序将不会被安装。某些应用程序需要这些额外的组件才能正常运行。 |
|
视频卡、显示器和输入设备会被自动检测,不需要任何手动配置。除非自动配置失败,否则不要创建 |
5.3. 显卡驱动程序
下表显示了 FreeBSD 支持的不同图形卡,应安装的软件包及其对应的模块。
| 品牌 | 类型 | 包 | 模块 |
|---|---|---|---|
Intel® |
开源 |
drm-kmod |
|
AMD® |
开源 |
drm-kmod |
|
NVIDIA® |
专有的 |
nvidia-driver |
|
VESA |
开源 |
xf86-video-vesa |
vesa |
SCFB |
开源 |
xf86-video-scfb |
scfb |
VirtualBox® |
开源 |
virtualbox-ose-additions |
VirtualBox® OSE 增加了 |
VMware® |
开源 |
xf86-video-vmware |
vmwgfx |
可以使用以下命令来识别系统中安装的图形卡:
% pciconf -lv|grep -B4 VGA输出应该类似于以下内容:
vgapci0@pci0:0:2:0: class=0x030000 rev=0x07 hdr=0x00 vendor=0x8086 device=0x2a42 subvendor=0x17aa subdevice=0x20e4
vendor = 'Intel Corporation'
device = 'Mobile 4 Series Chipset Integrated Graphics Controller'
class = display
subclass = VGA
|
如果显卡不受 Intel®、AMD® 或 NVIDIA® 驱动程序支持,则应使用 VESA 或 SCFB 模块。在 BIOS 模式下启动时必须使用 VESA 模块,在 UEFI 模式下启动时必须使用 SCFB 模块。 这个命令可以用来检查启动模式: 输出应该类似于以下内容: machdep.bootmethod: BIOS |
5.3.1. Intel®
Intel® Graphics 指的是与 Intel® CPU 集成在同一芯片上的图形芯片类别。维基百科提供了 一个关于 Intel HD Graphics 各个世代的变体和命名的良好概述 。
graphics/drm-kmod 包间接提供了一系列用于 Intel® 图形卡的内核模块。可以通过执行以下命令来安装 Intel® 驱动程序:
# pkg install drm-kmod然后将该模块添加到 /etc/rc.conf 文件中,执行以下命令:
# sysrc kld_list+=i915kms|
如果注意到高 CPU 使用率或高清视频出现过多的撕裂现象,安装 multimedia/libva-intel-driver 可能会有所帮助。要安装该软件包,请执行以下命令: |
5.3.2. AMD®
graphics/drm-kmod 包间接提供了一系列用于 AMD® 图形卡的内核模块。根据硬件的代数,可以使用 amdgpu 和 radeonkms 模块。FreeBSD 项目维护了一个 AMD 图形支持矩阵,以确定必须使用哪个驱动程序。
可以通过执行以下命令来安装 AMD® 驱动程序:
# pkg install drm-kmod对于 HD7000 系列或 Tahiti 显卡,请将模块添加到 /etc/rc.conf 文件中,执行以下命令:
# sysrc kld_list+=amdgpu对于较旧的图形卡(HD7000 之前或 Tahiti 之前,请将模块添加到 /etc/rc.conf 文件中,执行以下命令:
# sysrc kld_list+=radeonkms5.3.3. NVIDIA®
FreeBSD 支持不同版本的专有 NVIDIA® 驱动程序。使用较新的显卡的用户应安装包: x11/nvidia-driver[]。那些使用较旧显卡的用户需要查看下面支持它们的版本。
| 包 | 支持的硬件 |
|---|---|
x11/nvidia-driver-304 |
|
x11/nvidia-driver-340 |
|
x11/nvidia-driver-390 |
|
x11/nvidia-driver-470 |
|
x11/nvidia-driver |
|
NVIDIA® 图形驱动程序的 304 版本(nvidia-driver-304)不支持 xorg-server 1.20 或更高版本。 |
最新的 NVIDIA® 驱动程序可以通过运行以下命令进行安装:
# pkg install nvidia-driver然后将该模块添加到 /etc/rc.conf 文件中,执行以下命令:
# sysrc kld_list+=nvidia-modeset|
如果安装了 x11/nvidia-driver-304 或 x11/nvidia-driver-340 软件包,则必须使用 |
5.4. Xorg 配置
Xorg 支持大多数常见的视频卡、键盘和指针设备。
|
视频卡、显示器和输入设备会被自动检测,不需要任何手动配置。除非自动配置失败,否则不要创建 xorg.conf 文件或运行 |
5.4.1. 配置文件
Xorg 在多个目录中查找配置文件。在 FreeBSD 上,推荐使用目录 /usr/local/etc/X11/ 来存放这些文件。使用这个目录可以将应用程序文件与操作系统文件分开。
5.4.2. 单个文件或多个文件
使用多个文件来配置特定设置比传统的单个 xorg.conf 文件更容易。这些文件存储在 /usr/local/etc/X11/xorg.conf.d/ 子目录中。
|
传统的单一 xorg.conf 仍然有效,但是与位于 /usr/local/etc/X11/xorg.conf.d/ 子目录中的多个文件相比,既不清晰也不灵活。 |
5.4.3. 视频卡
图形卡的驱动程序可以在 /usr/local/etc/X11/xorg.conf.d/ 目录中指定。
要在配置文件中配置 Intel® 驱动程序:
例 14. 在文件中选择 Intel® 视频驱动程序
/usr/local/etc/X11/xorg.conf.d/20-intel.conf
Section "Device" Identifier "Card0" Driver "intel" EndSection
要在配置文件中配置 AMD® 驱动程序:
例 15. 在文件中选择 AMD® 视频驱动程序
/usr/local/etc/X11/xorg.conf.d/20-radeon.conf
Section "Device" Identifier "Card0" Driver "radeon" EndSection
要在配置文件中配置 NVIDIA® 驱动程序:
例 16. 在文件中选择 NVIDIA® 视频驱动程序
/usr/local/etc/X11/xorg.conf.d/20-nvidia.conf
Section "Device" Identifier "Card0" Driver "nvidia" EndSection
|
x11/nvidia-xconfig 也可以用来对 NVIDIA 驱动程序中可用的配置选项进行基本控制。 |
要在配置文件中配置 VESA 驱动程序:
例 17. 在文件中选择 VESA 视频驱动程序
/usr/local/etc/X11/xorg.conf.d/20-vesa.conf
Section "Device" Identifier "Card0" Driver "vesa" EndSection
要在配置文件中配置 SCFB 驱动程序:
例 18. 在文件中选择 SCFB 视频驱动程序
/usr/local/etc/X11/xorg.conf.d/20-scfb.conf
Section "Device" Identifier "Card0" Driver "scfb" EndSection
要配置多个视频卡,可以添加 BusID。执行以下命令可以显示视频卡总线 ID 的列表:
% pciconf -lv | grep -B3 display输出应该类似于以下内容:
vgapci0@pci0:0:2:0: class=0x030000 rev=0x07 hdr=0x00 vendor=0x8086 device=0x2a42 subvendor=0x17aa subdevice=0x20e4
vendor = 'Intel Corporation'
device = 'Mobile 4 Series Chipset Integrated Graphics Controller'
class = display
--
vgapci1@pci0:0:2:1: class=0x038000 rev=0x07 hdr=0x00 vendor=0x8086 device=0x2a43 subvendor=0x17aa subdevice=0x20e4
vendor = 'Intel Corporation'
device = 'Mobile 4 Series Chipset Integrated Graphics Controller'
class = display
例 19. 在一个文件中选择 Intel® 视频驱动程序和 NVIDIA® 视频驱动程序。
/usr/local/etc/X11/xorg.conf.d/20-drivers.conf
Section "Device" Identifier "Card0" Driver "intel" BusID "pci0:0:2:0" EndSection Section "Device" Identifier "Card0" Driver "nvidia" BusID "pci0:0:2:1" EndSection
5.4.4. 显示器
几乎所有的显示器都支持扩展显示识别数据标准(EDID)。Xorg 使用 EDID 与显示器进行通信,检测支持的分辨率和刷新率,然后选择最合适的设置组合来与该显示器配合使用。
可以通过在配置文件中设置所需的分辨率,或在启动 X 服务器后使用 xrandr(1) 来选择显示器支持的其他分辨率。
5.4.4.1. 使用 RandR (Resize and Rotate)
运行 xrandr(1) 命令,不带任何参数,可以查看视频输出和检测到的显示器模式列表:
% xrandr输出应该类似于以下内容:
Screen 0: minimum 320 x 200, current 2560 x 960, maximum 8192 x 8192 LVDS-1 connected 1280x800+0+0 (normal left inverted right x axis y axis) 261mm x 163mm 1280x800 59.99*+ 59.81 59.91 50.00 1280x720 59.86 59.74 1024x768 60.00 1024x576 59.90 59.82 960x540 59.63 59.82 800x600 60.32 56.25 864x486 59.92 59.57 640x480 59.94 720x405 59.51 58.99 640x360 59.84 59.32 VGA-1 connected primary 1280x960+1280+0 (normal left inverted right x axis y axis) 410mm x 257mm 1280x1024 75.02 60.02 1440x900 74.98 60.07 1280x960 60.00* 1280x800 74.93 59.81 1152x864 75.00 1024x768 75.03 70.07 60.00 832x624 74.55 800x600 72.19 75.00 60.32 56.25 640x480 75.00 72.81 66.67 59.94 720x400 70.08 HDMI-1 disconnected (normal left inverted right x axis y axis) DP-1 disconnected (normal left inverted right x axis y axis) HDMI-2 disconnected (normal left inverted right x axis y axis) DP-2 disconnected (normal left inverted right x axis y axis) DP-3 disconnected (normal left inverted right x axis y axis)
这表明 VGA-1 输出正在用于显示分辨率为 1280x960 像素、刷新率约为 60 Hz 的屏幕。LVDS-1 被用作辅助显示器,显示分辨率为 1280x800 像素、刷新率约为 60 Hz 的屏幕。HDMI-1、HDMI-2、DP-1、DP-2 和 DP-3 连接器上没有连接显示器。
可以使用 xrandr(1) 选择任何其他的显示模式。例如,要切换到 1280x1024 分辨率,刷新率为 60 Hz :
% xrandr --output LVDS-1 --mode 1280x720 --rate 605.4.5. 输入设备
Xorg 通过 x11/libinput 支持绝大部分输入设备。
|
一些桌面环境(如 KDE Plasma)提供了用于设置这些参数的图形界面。在尝试手动配置编辑之前,请检查是否有这样的界面。 |
例如,要配置键盘布局:
例 21. 设置键盘布局
/usr/local/etc/X11/xorg.conf.d/00-keyboard.conf
Section "InputClass"
Identifier "Keyboard1"
MatchIsKeyboard "on"
Option "XkbLayout" "es, fr"
Option "XkbModel" "pc104"
Option "XkbVariant" ",qwerty"
Option "XkbOptions" "grp:win_space_toggle"
EndSection
5.5. 在 Xorg 中使用字体
Xorg 默认提供的字体对于典型的桌面出版应用来说并不理想。大号演示字体显示出来会有锯齿状,不够专业,而小号字体几乎完全无法辨认。然而,有几种免费的高质量 Type1 (PostScript®) 字体可供在 Xorg 中方便地使用。
5.5.1. Type1 字体
URW 字体集合 (x11-fonts/urwfonts) 包括标准 Type1 字体 (Times Roman™,Helvetica™,Palatino™ 等)的高质量版本。Freefonts 集合 (x11-fonts/freefonts) 包括更多字体,但大部分是为图形软件(如 Gimp)使用的,并不完整,不能用作屏幕字体。此外,Xorg 可以配置为轻松使用 TrueType® 字体。有关详细信息,请参阅 X(7) 手册页面或 TrueType® 字体。
要安装上述的 Type1 字体集合,可以运行以下命令来安装二进制包:
# pkg install urwfonts同样,对于 freefont 或其他字体集合也是如此。要让 X 服务器检测这些字体,需要在 X 服务器配置文件 (/usr/local/etc/X11/xorg.conf.d/90-fonts.conf) 中添加一行适当的内容,如下所示:
Section "Files" FontPath "/usr/local/share/fonts/urwfonts/" EndSection
或者,在 X 会话的命令行中运行:
% xset fp+ /usr/local/share/fonts/urwfonts
% xset fp rehash这将起作用,但在 X 会话关闭时将丢失,除非将其添加到启动文件(对于普通的 startx 会话,为 ~/.xinitrc,或者对于通过图形登录管理器(如 XDM)登录的情况,为 ~/.xsession)。第三种方法是使用新的 /usr/local/etc/fonts/local.conf,如 抗锯齿字体 中所示。
5.5.2. TrueType® 字体
Xorg 内置了对 TrueType® 字体的渲染支持。有两个不同的模块可以启用这个功能。在这个例子中使用 freetype 模块,因为它与其他字体渲染后端更加一致。要启用 freetype 模块,只需将以下行添加到 /usr/local/etc/X11/xorg.conf.d/90-fonts.conf 文件的 "Module" 部分。
Load "freetype"
现在创建一个用于 TrueType® 字体的目录(例如,/usr/local/share/fonts/TrueType),并将所有的 TrueType® 字体复制到该目录中。请记住,TrueType® 字体不能直接从 Apple® Mac® 中获取;它们必须以 UNIX®/MS-DOS®/Windows® 格式存在,以供 Xorg 使用。一旦文件被复制到该目录中,使用 mkfontscale 创建一个 fonts.dir 文件,以便 X 字体渲染器知道这些新文件已经安装。mkfontscale 可以作为一个软件包进行安装:
# pkg install mkfontscale然后在一个目录中创建 X 字体文件的索引:
# cd /usr/local/share/fonts/TrueType
# mkfontscale现在将 TrueType® 目录添加到字体路径中。这与 Type1 字体 中描述的方式完全相同。
% xset fp+ /usr/local/share/fonts/TrueType
% xset fp rehash或者在 xorg.conf 文件中添加一个 FontPath 行。
现在,Gimp、LibreOffice 和所有其他 X 应用程序应该能够识别已安装的 TrueType® 字体。现在,在高分辨率显示器上的网页文本中的极小字体以及 LibreOffice 中的极大字体将会看起来更好。
5.5.3. 抗锯齿字体
在 Xorg 中,所有在 /usr/local/share/fonts/ 和 ~/.fonts/ 目录中找到的字体都会自动提供给支持 Xft-aware 的应用程序进行反锯齿处理。大多数最新的应用程序都支持 Xft-aware,包括 KDE、GNOME 和 Firefox。
要控制反锯齿的字体或配置反锯齿属性,请创建(或编辑,如果已存在)文件 /usr/local/etc/fonts/local.conf。可以使用此文件调整 Xft 字体系统的几个高级功能;本节仅描述了一些简单的可能性。有关更多详细信息,请参阅 fonts-conf(5)。
这个文件必须是 XML 格式的。请注意大小写,并确保所有标签都正确闭合。文件以通常的 XML 头部开始,接着是 DOCTYPE 定义,然后是 <fontconfig> 标签。
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
如前所述,位于 /usr/local/share/fonts/ 和 ~/.fonts/ 目录中的所有字体已经可以在支持 Xft-aware 的应用程序中使用。如果要添加一个位于这两个目录树之外的目录,可以在 /usr/local/etc/fonts/local.conf 文件中添加如下一行:
<dir>/path/to/my/fonts</dir>
在添加新字体,尤其是新的字体目录后,重新构建字体缓存:
# fc-cache -f抗锯齿会使边界略微模糊,这使得非常小的文本更易读,并消除了大文本上的“阶梯状”效果,但如果应用于普通文本,可能会导致眼部疲劳。要排除小于 14 点字号的字体应用抗锯齿,包括以下几行代码:
<match target="font"> <test name="size" compare="less"> <double>14</double> </test> <edit name="antialias" mode="assign"> <bool>false</bool> </edit> </match> <match target="font"> <test name="pixelsize" compare="less" qual="any"> <double>14</double> </test> <edit mode="assign" name="antialias"> <bool>false</bool> </edit> </match>
对于某些等宽字体,使用反锯齿可能会导致间距不合适。这似乎是 KDE 特别存在的问题。一个可能的解决方法是强制将这些字体的间距设置为 100 。添加以下行:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>fixed</string> </test> <edit name="family" mode="assign"> <string>mono</string> </edit> </match> <match target="pattern" name="family"> <test qual="any" name="family"> <string>console</string> </test> <edit name="family" mode="assign"> <string>mono</string> </edit> </match>
(这将其他常见的固定字体名称别名为 "mono"),然后添加:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>mono</string> </test> <edit name="spacing" mode="assign"> <int>100</int> </edit> </match>
某些字体,比如 Helvetica,在反锯齿处理时可能会出现问题。通常表现为字体在垂直方向上被切割了一半。最糟糕的情况下,可能会导致应用程序崩溃。为了避免这种情况,考虑将以下内容添加到 .local.conf 文件中:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>Helvetica</string> </test> <edit name="family" mode="assign"> <string>sans-serif</string> </edit> </match>
在编辑 local.conf 后,确保用 </fontconfig> 标签结束文件。如果不这样做,将会忽略所做的更改。
用户可以通过创建自己的 ~/.config/fontconfig/fonts.conf 文件来添加个性化设置。该文件使用上述描述的相同的 XML 格式。
最后一个要点:对于 LCD 屏幕,可能需要进行亚像素采样。这基本上是将(水平分离的)红色、绿色和蓝色分量分别处理,以提高水平分辨率;结果可能非常显著。要启用此功能,请在 local.conf 中的某个位置添加以下行:
<match target="font"> <test qual="all" name="rgba"> <const>unknown</const> </test> <edit name="rgba" mode="assign"> <const>rgb</const> </edit> </match>
|
根据显示器的类型,可能需要将 |
有关在 FreeBSD 上安装和配置字体的更多信息,请阅读文章 字体和 FreeBSD。
Chapter 6. 在 FreeBSD 上的 Wayland
6.1. Wayland 概述
Wayland 是一个新的显示服务器,但它与 Xorg 在几个重要方面有所不同。首先,Wayland 只是一个协议,充当客户端之间的中介,使用不同的机制来消除对 X 服务器的依赖。Xorg 既包括用于运行远程显示的 X11 协议,也包括 X 服务器将接受连接和显示窗口。在 Wayland 下,合成器或窗口管理器提供显示服务器,而不是传统的 X 服务器。
由于 Wayland 不是一个 X 服务器,传统的 X 屏幕连接需要使用其他方法,如 VNC 或 RDP 来进行远程桌面管理。其次,Wayland 可以作为一个独立实体来管理客户端和合成器之间的复合通信,而不需要支持 X 协议。
Wayland 相对较新,不是所有的软件都已经更新以在没有 Xwayland 支持的情况下本地运行。因为 Wayland 不提供 X 服务器,并且期望合成器提供该支持,尚不支持 Wayland 的 X11 窗口管理器将要求不使用 -rootless 参数启动 Xwayland 。移除 -rootless 参数后,将恢复 X11 窗口管理器的支持。
|
当前的 NVIDIA® 驱动程序应该能够与大多数 wlroots 合成器配合使用,但可能会有一些不稳定性,并且在此时可能不支持所有功能。我们请求志愿者帮助改进 NVIDIA® DRM 。 |
目前,许多软件在 Wayland 上可以正常运行,包括 Firefox。还有一些可用的桌面环境,比如 Compiz Fusion 的替代品 Wayfire,以及 i3 窗口管理器的替代品 Sway 。
|
截至 2021 年 5 月, plasma5-kwin 在 FreeBSD 上支持 Wayland。要在 Wayland 下使用 Plasma,请使用 |
对于合成器来说,必须存在支持 evdev(4) 驱动程序的内核才能利用按键绑定功能。这在默认情况下已经内置在 GENERIC 内核中;然而,如果内核被定制并且去除了 evdev(4) 支持,那么就需要加载 evdev(4) 模块。此外,使用 Wayland 的用户还需要是 video 组的成员。要快速进行此更改,请使用 pw 命令:
pw groupmod video -m user安装 Wayland 很简单;协议本身没有太多的配置。大部分的组合将取决于所选择的合成器。通过现在安装 seatd,可以跳过合成器安装和配置一部分的步骤,因为 seatd 需要提供对某些设备的非 root 访问权限。
这里描述的所有合成器都应该与 graphics/drm-kmod 开源驱动程序配合使用;然而,使用专有驱动程序时, NVIDIA® 显卡可能会出现问题。首先安装以下软件包:
# pkg install wayland seatd一旦协议和支持包被安装,合成器必须创建用户界面。接下来的几节将介绍几种合成器。所有使用 Wayland 的合成器都需要在环境中定义一个运行时目录,可以通过在 Bourne shell 中使用以下命令来实现:
% export XDG_RUNTIME_DIR=/var/run/user/`id -u`需要注意的是,大多数合成器会在 XDG_RUNTIME_DIR 目录中搜索配置文件。在这里包含的示例中,将使用一个参数来指定一个配置文件在 [.filename]# ~ /.config# 中,以便将临时文件和配置文件分开存放。建议为每个合成器配置一个别名,以加载指定的配置文件。
|
据报道,ZFS 用户可能会在某些 Wayland 客户端上遇到问题,因为它们需要在运行时目录中访问 |
seatd 守护进程帮助在合成器中管理非 root 用户对共享系统设备的访问,包括图形卡。对于传统的 X11 管理器,如 Plasma 和 GNOME,不需要使用 seatd,但对于这里讨论的 Wayland 合成器,在启动合成器环境之前,需要在系统上启用并运行它。要立即启用和启动 seatd 守护进程,并在系统初始化时启动:
# sysrc seatd_enable=”YES”
# service seatd start之后,需要安装一个类似于 X11 桌面的合成器 (compositor) 来创建 GUI 环境。这里讨论了三种合成器,包括基本配置选项、设置屏幕锁定以及获取更多信息的建议。
6.2. Wayfire 合成器
Wayfire 是一个旨在轻量化和可定制化的合成器。它提供了多种功能,并且还恢复了之前发布的 Compiz Fusion 桌面的一些元素。所有的部分在现代硬件上看起来都很漂亮。要启动和运行 Wayfire,请先安装所需的软件包:
# pkg install wayfire wf-shell alacritty swaylock-effects swayidle wlogout kanshi mako wlsunsetalacritty 软件包提供了一个终端仿真器。然而,并不完全需要它,因为其他终端仿真器如 kitty 和 XFCE-4 Terminal 已经在 Wayfire 合成器下进行了测试和验证。 Wayfire 的配置相对简单;它使用一个文件,应该对其中的任何自定义进行审查。要开始,将示例文件复制到运行时环境配置目录,然后编辑该文件:
% mkdir ~/.config/wayfire
% cp /usr/local/share/examples/wayfire/wayfire.ini ~/.config/wayfire对于大多数用户来说,默认设置应该是可以的。在配置文件中,像著名的 cube 这样的项目已经预先配置好了,并且有说明来帮助设置可用的选项。一些值得注意的主要设置包括:
[output] mode = 1920x1080@60000 position = 0,0 transform = normal scale = 1.000000
在这个例子中,从配置文件中,屏幕的输出应该是列表中列出的模式和列表中列出的赫兹。例如,模式应该设置为 widthxheight@refresh_rate。位置将输出放置在指定的像素位置上。默认值对大多数用户来说应该是可以接受的。最后, transform 设置了背景变换, scale 将输出按指定的比例因子进行缩放。这些选项的默认值通常是可以接受的;有关更多信息,请参阅文档。
如前所述,Wayland 是一种新的协议,还不是所有的应用程序都能与之兼容。目前,sddm 似乎不支持在 Wayland 中启动和管理合成器。在这些示例中,使用了 swaylock 实用程序。配置文件中包含了运行 swayidle 和 swaylock 来处理屏幕空闲和锁定的选项。
当系统处于空闲状态时,可以使用此选项来定义要执行的操作。
idle = swaylock
锁定超时是通过以下行进行配置的:
[idle] toggle = <super> KEY_Z screensaver_timeout = 300 dpms_timeout = 600
第一个选项将在 300 秒后锁定屏幕,再过 300 秒后,屏幕将通过 dpms_timeout 选项关闭。
需要注意的最后一件事是 <super> 键。大多数配置都提到了这个键,它是键盘上的传统 Windows 键。大多数键盘都有这个超级键可用;然而,如果该键不可用,应在此配置文件中重新映射它。例如,要锁定屏幕,请按住超级键,shift 键,然后按下 escape 键。除非映射已更改,否则这将执行 swaylock 应用程序。 swaylock 的默认配置将显示一个灰色屏幕;然而,该应用程序可以高度自定义,并且有很好的文档。此外,由于安装的是 swaylock-effects 版本,因此有几个可用的选项,例如模糊效果,可以使用以下命令查看:
% swaylock --effect-blur 7x5还有一个 --clock 参数,它会在锁屏界面上显示一个带有日期和时间的时钟。当安装了 x11/swaylock-effects 软件包时,会包含一个默认的 pam.d 配置文件。它提供了适用于大多数用户的默认选项。还有更高级的选项可用;有关更多信息,请参阅 PAM 文档。
此时,是时候测试 Wayfire 并查看它是否能在系统上启动了。只需输入以下命令:
% wayfire -c ~/.config/wayfire/wayfire.ini现在,合成器应该开始运行,并在屏幕顶部显示一个背景图像和一个菜单栏。 Wayfire 将尝试列出已安装的兼容应用程序,并在此下拉菜单中呈现它们;例如,如果安装了 XFCE-4 文件管理器,它将显示在此下拉菜单中。如果特定应用程序与键盘快捷键兼容且足够有价值,可以使用 wayfire.ini 配置文件将其映射到键盘序列。 Wayfire 还有一个名为 Wayfire Config Manager 的配置工具。它位于下拉菜单栏中,但也可以通过终端发出以下命令来启动:
% wcm通过这个应用程序,可以启用、禁用或配置各种 Wayfire 配置选项,包括合成特效。此外,为了提供更用户友好的体验,可以在配置文件中启用背景管理器、面板和停靠应用程序。
panel = wf-panel dock = wf-dock background = wf-background
|
通过 |
最后,在 wayfire.ini 中列出的默认启动器是 x11/wf-shell ,用户可以根据需要替换为其他面板。
6.3. Hikari 合成器
Hikari 合成器使用了几个以提高生产力为中心的概念,例如工作表(sheets)、工作区(workspaces)等等。从这个角度来看,它类似于平铺式窗口管理器。具体来说,合成器从一个单一的工作区开始,类似于虚拟桌面。 Hikari 使用一个单一的工作区或虚拟桌面进行用户交互。工作区由多个视图组成,这些视图是合成器中的工作窗口,分组为工作表或组(groups)。工作表和组都由一组视图组成,即被分组在一起的窗口。在工作表或之间切换时,活动的工作表或组将被统称为工作区。手册将详细介绍每个功能,但在本文档中,只需考虑一个使用单个 工作表的工作区。 Hikari 的安装将包括一个单一的软件包 x11-wm/hikari 和一个终端模拟器 alacritty 。
# pkg install hikari alacritty|
其他终端,如 |
Hikari 使用一个配置文件 hikari.conf,可以放置在 XDG_RUNTIME_DIR 目录中,也可以在启动时使用 -c 参数指定。不需要自动启动配置文件,但是可能会使迁移到这个合成器更容易一些。开始配置是创建 Hikari 配置目录并复制配置文件进行编辑:
% mkdir ~/.config/hikari
% cp /usr/local/etc/hikari/hikari.conf ~/.config/hikari配置被分解为各种部分,如 ui、outputs、layouts 等等。对于大多数用户来说,默认设置应该可以正常运行;但是还需要进行一些重要的更改。例如,$TERMINAL 变量通常在用户的环境中没有设置。可以更改这个变量或者修改 hikari.conf 文件以进行读取。
terminal = "/usr/local/bin/alacritty"
将使用绑定的按键启动 alacritty 终端。在浏览配置文件时,应注意大写字母用于为用户映射键。例如,用于启动终端的 L 键 L+Return 实际上是前面讨论过的超级键或 Windows 徽标键。因此,按住 L/super/Windows 键并按下 Enter 键将使用默认配置打开指定的终端仿真器。将其他键映射到应用程序需要创建一个动作定义。为此,动作项应列在动作段中,例如:
actions {
terminal = "/usr/local/bin/alacritty"
browser = "/usr/local/bin/firefox"
}
然后,可以将一个动作映射到键盘部分,该部分在绑定部分中定义:
bindings {
keyboard {
SNIP
"L+Return" = action-terminal
"L+b" = action-browser
SNIP
在 Hikari 重新启动后,按住 Windows 徽标按钮并在键盘上按下 b 键将启动网页浏览器。合成器没有菜单栏,建议用户在迁移之前至少设置一个终端仿真器。手册中包含大量的文档,应在进行完整迁移之前阅读。Hikari 的另一个积极方面是,在迁移到合成器时,可以在 Plasma 和 GNOME 桌面环境中启动 Hikari,以便在完全迁移之前进行试用。
在 Hikari 中锁定屏幕很容易,因为默认的 pam.d 配置文件和解锁工具已经与软件包捆绑在一起。锁定屏幕的键绑定是 L(Windows 徽标键)+ Shift + Backspace。需要注意的是,所有未标记为公共的视图将被隐藏。当屏幕锁定时,这些视图将不接受输入,但要注意敏感信息可能可见。对于一些用户来说,可能更容易迁移到其他屏幕锁定工具,比如在本节中讨论的 swaylock-effects。要启动 Hikari,请使用以下命令:
% hikari -c ~/.config/hikari/hikari.conf6.4. Sway 合成器
Sway 合成器是一种平铺式合成器,旨在取代 i3 窗口管理器。它应该与用户当前的 i3 配置兼容;但是,新功能可能需要一些额外的设置。在接下来的示例中,假设进行了全新安装,没有迁移任何 i3 配置。要安装 Sway 和有价值的组件,请以 root 用户身份执行以下命令:
# pkg install sway swayidle swaylock-effects alacritty dmenu-wayland dmenu对于一个基本的配置文件,执行以下命令,然后在复制完成后编辑配置文件:
% mkdir ~/.config/sway
% cp /usr/local/etc/sway/config ~/.config/sway基本配置文件有许多默认值,对于大多数用户来说这是可以的。但是还需要进行一些重要的更改,如下所示:
# Logo key. Use Mod1 for Alt.
input * xkb_rules evdev
set $mod Mod4
# Your preferred terminal emulator
set $term alacritty
set $lock swaylock -f -c 000000
output "My Workstation" mode 1366x786@60Hz position 1366 0
output * bg ~/wallpapers/mywallpaper.png stretch
### Idle configuration
exec swayidle -w \
timeout 300 'swaylock -f -c 000000' \
timeout 600 'swaymsg "output * dpms off"' resume 'swaymsg "output * dpms on"' \
before-sleep 'swaylock -f -c 000000'
在前面的示例中,加载了 xkb 规则以处理 evdev(4) 事件,并将 $mod 键设置为 Windows 徽标键以进行键绑定。接下来,终端仿真器被设置为 alacritty,并定义了一个屏幕锁定命令;稍后会详细介绍。输出关键字、模式、位置、背景壁纸以及 Sway 还被告知将该壁纸拉伸以填满屏幕。最后,设置 swaylock 在 300 秒超时后将屏幕或监视器锁定并进入睡眠模式。在这里还定义了锁定的背景颜色为 000000,即黑色。使用 swaylock-effects,还可以使用 --clock 参数显示时钟。有关更多选项,请参阅手册页。还应该查看 sway-output(5) 手册页;它包含了大量关于自定义输出选项的信息。
在 Sway 中,要打开应用程序菜单,请按住 Windows 徽标键(mod 键)并按下 d 键。可以使用键盘上的箭头键来导航菜单。还有一种方法可以操作栏的布局并添加一个托盘;请阅读 sway-bar(5) 手册页面获取更多信息。默认配置在右上角添加了日期和时间。在配置文件的 Bar 部分中可以找到一个示例。默认情况下,配置不包括在上面的示例之外锁定屏幕,启用锁定计时器。创建一个锁定键绑定需要在 Key bindings 部分添加以下行:
# Lock the screen manually bindsym $mod+Shift+Return exec $lock
现在可以使用按住 Windows 徽标键、按住 Shift 键,最后按下回车键的组合来锁定屏幕。当安装了 Sway,无论是从软件包还是 FreeBSD Ports Collection 安装的,都会安装一个默认的 pam.d 文件。默认配置对大多数用户来说应该是可接受的,但也提供了更高级的选项。请阅读 PAM 文档以获取更多信息。
最后,要退出 Sway 并返回到 shell,请按住 Windows 徽标键和 Shift 键,然后按下键盘上的 [e] 键。会显示一个提示,其中有一个选项可以退出 Sway。在迁移期间,可以通过在诸如 Plasma 之类的 X11 桌面上的终端模拟器中启动 Sway 。这使得在完全迁移到这个合成器之前,测试不同的更改和键绑定变得更加容易。要启动 Sway ,请执行以下命令:
% sway -c ~/.config/sway/config6.5. 使用 Xwayland
在安装 Wayland 时,除非 Wayland 是没有构建 X11 支持的,否则应该已经安装了 Xwayland 二进制文件。如果 /usr/local/bin/Xwayland 文件不存在,请使用以下命令进行安装:
# pkg install xwayland-devel|
推荐使用 Xwayland 的开发版本,并且很可能已经随 Wayland 软件包一起安装。每个合成器都有一种启用或禁用此功能的方法。 |
一旦安装了 Xwayland,请在所选的合成器中进行配置。对于 Wayfire 来说,在 wayfire.ini 文件中需要添加以下行:
xwayland = true
对于 Sway 合成器,默认情况下应启用 Xwayland。即便如此,建议在 ~/.config/sway/config 中手动添加以下配置行:
启用 XWayland
最后,对于 Hikari 来说,不需要进行任何更改。默认情况下,已经内置了对 Xwayland 的支持。要禁用该支持,可以从 ports 集合中重新构建该软件包,并在那时禁用 Xwayland 支持。
在进行这些更改后,通过命令行启动合成器,并从键绑定中执行一个终端。在这个终端中,输入 env 命令并搜索 DISPLAY 变量。如果合成器能够正确启动 Xwayland X 服务器,这些环境变量应该类似于以下内容:
% env | grep DISPLAYWAYLAND_DISPLAY=wayland-1 DISPLAY=:0
在这个输出中,有一个默认的 Wayland 显示器和一个为 Xwayland 服务器设置的显示器。验证 Xwayland 是否正常工作的另一种方法是安装和测试一个小包 package:[x11/eyes],并检查输出。如果 xeyes 应用程序启动并且眼睛跟随鼠标指针移动,那么 Xwayland 正常工作。如果显示了以下错误或类似错误,则在 Xwayland 初始化过程中发生了某些问题,可能需要重新安装:
Error: Cannot open display wayland-0
|
Wayland 的一个安全特性是,在没有运行 X 服务器的情况下,没有其他网络监听器。一旦启用了 |
对于一些复合器,比如 Wayfire,Xwayland 可能无法正常启动。因此,env 将显示 DISPLAY 环境变量的以下信息:
% env | grep DISPLAYDISPLAY=wayland-1 WAYLAND_DISPLAY=wayland-1
尽管已经安装和配置了 Xwayfire,但 X11 应用程序无法启动,出现显示问题。为了解决这个问题,可以通过以下两种方法验证是否已经存在一个使用 UNIX 套接字的 Xwayland 实例。首先,检查 sockstat 的输出,并搜索 X11-unix:
% sockstat | grep x11应该有类似以下信息的内容:
trhodes Xwayland 2734 8 stream /tmp/.X11-unix/X0 trhodes Xwayland 2734 9 stream /tmp/.X11-unix/X0 trhodes Xwayland 2734 10 stream /tmp/.X11-unix/X0 trhodes Xwayland 2734 27 stream /tmp/.X11-unix/X0_ trhodes Xwayland 2734 28 stream /tmp/.X11-unix/X0
这表明存在一个 X11 套接字。可以通过在合成器下运行的终端模拟器中尝试手动执行 Xwayland 来进一步验证:
% Xwayland如果已经存在一个 X11 套接字,则应向用户显示以下错误:
(EE) Fatal server error: (EE) Server is already active for display 0 If this server is no longer running, remove /tmp/.X0-lock and start again. (EE)
由于存在一个可用的活动 X 显示器,使用显示器零,环境变量设置不正确,要修复这个问题,将 DISPLAY 环境变量更改为 :0,然后尝试再次执行应用程序。以下示例使用 mail/claws-mail 作为需要 Xwayland 服务的应用程序:
export DISPLAY=:0在这个改变之后,mail/claws-mail 应用程序现在应该开始使用 Xwayland 并正常工作。
6.6. 使用 VNC 进行远程桌面访问
在本文档中早些时候已经指出, Wayland 不像 Xorg 提供相同的 X 服务器样式访问。相反,用户可以自由选择远程桌面协议,如 RDP 或 VNC。FreeBSD Ports 集合中包括 wayvnc,它将支持基于 wlroots 的合成器,例如在这里讨论的合成器。可以使用以下命令安装此应用程序:
# pkg install wayvnc与其他一些软件包不同,wayvnc 不提供配置文件。幸运的是,手册页面记录了重要的选项,并且可以将它们推导成一个简单的配置文件:
address=0.0.0.0 enable_auth=true username=username password=password private_key_file=/path/to/key.pem certificate_file=/path/to/cert.pem
需要生成密钥文件,并强烈建议使用它们以增加连接的安全性。当调用时,wayvnc 将在 ~/.config/wayvnc/config 中搜索配置文件。可以使用 -C configuration_file 选项在启动服务器时覆盖该文件。因此,要启动 wayvnc 服务器,请执行以下命令:
% wayvnc -C ~/.config/wayvnc/config|
在撰写本文时,系统初始化时没有 rc.d 脚本来启动 |
6.7. Wayland 登录管理器
虽然存在多个登录管理器,并且正在逐渐迁移到 Wayland,但其中一个选择是 x11/ly 中的文本用户界面(TUI)管理器。ly 只需要最少的配置,它会在系统初始化时显示一个登录窗口来启动 Sway、Wayfire 等桌面环境。要安装 ly,请执行以下命令:
# pkg install ly将会提供一些配置提示,导入步骤是将以下行添加到 /etc/gettytab 文件中:
Ly:\ :lo=/usr/local/bin/ly:\ :al=root:
然后在 /etc/ttys 中修改 ttyv1 行,使其与以下行匹配:
ttyv1 "/usr/libexec/getty Ly" xterm onifexists secure
系统重新启动后,应该出现登录界面。要配置特定的设置,例如语言和编辑 /usr/local/etc/ly/config.ini 。至少,这个文件应该有之前在 /etc/ttys 中指定的终端。
|
如果将 ttyv0 设置为登录终端,可能需要按下 alt 和 F1 键才能正确显示登录窗口。 |
当登录窗口出现时,使用左右箭头可以在不同支持的窗口管理器之间切换。
6.8. 有用的工具
所有合成器都可以使用的一个有用的 Wayland 实用程序是 waybar。虽然 Wayfire 带有一个启动菜单,但一个易于使用和快速的任务栏对于任何合成器或桌面管理器来说都是一个很好的附件。一个快速且易于配置的 Wayland 兼容的任务栏是 waybar。要安装该软件包和一个支持音频控制的实用程序,请执行以下命令:
# pkg install pavucontrol waybar要创建配置目录并复制默认配置文件,请执行以下命令:
% mkdir ~/.config/waybar
% cp /usr/local/etc/xdg/waybar/config ~/.config/waybarlavalauncher 实用程序为各种应用程序提供了一个启动栏。软件包中没有提供示例配置文件,因此必须执行以下操作:
mkdir ~/.config/lavalauncher下面是一个只包含 Firefox 的示例配置文件,并且放置在右侧:
global-settings {
watch-config-file = true;
}
bar {
output = eDP-1;
position = bottom;
background-colour = "#202020";
# Condition for the default configuration set.
condition-resolution = wider-than-high;
config {
position = right;
}
button {
image-path = /usr/local/lib/firefox/browser/chrome/icons/default/default48.png;
command[mouse-left] = /usr/local/bin/firefox;
}
button {
image-path = /usr/local/share/pixmaps/thunderbird.png;
command[mouse-left] = /usr/local/bin/thunderbird;
}
Chapter 7. 网络
7.1. 简介
本章深入探讨了网络配置和性能的主题,展示了 FreeBSD 操作系统强大的网络能力。无论是使用有线网络还是无线网络,本章提供了一个全面的指南,帮助您在 FreeBSD 中配置和优化网络连接。
在深入了解细节之前,读者对网络概念如协议、网络接口和寻址有基本的了解是有益的。
本章内容包括:
-
在 FreeBSD 中配置有线网络的能力,包括网络接口设置、寻址和定制选项。
-
在 FreeBSD 中配置无线网络的技能,包括无线网络接口设置、安全协议和故障排除技术。
-
FreeBSD 的网络能力以及其在优秀网络性能方面的声誉。
-
对于 FreeBSD 支持的各种网络服务和协议的理解,包括 DNS、DHCP 等的配置说明。
有关如何进行高级网络配置的更多信息,请参阅 高级网络。
7.2. 设置网络
为 FreeBSD 用户设置有线或无线连接是一个常见的任务。本节将展示如何识别有线和无线网络适配器以及如何配置它们。
在开始配置之前,需要了解以下网络数据:
-
如果网络使用 DHCP
-
如果网络没有 DHCP,则使用静态 IP 。
-
子网掩码
-
默认网关的 IP 地址
|
网络连接可能在安装时由 bsdinstall(8) 进行配置。 |
7.2.1. 识别网络适配器
FreeBSD 支持各种有线和无线网络适配器。请查看所使用的 FreeBSD 版本的硬件兼容性列表 FreeBSD release,以查看网络适配器是否受支持。
要获取我们系统使用的网络适配器,请执行以下命令:
% pciconf -lv | grep -A1 -B3 network输出应该类似于以下内容:
em0@pci0:0:25:0: class=0x020000 rev=0x03 hdr=0x00 vendor=0x8086 device=0x10f5 subvendor=0x17aa subdevice=0x20ee
vendor = 'Intel Corporation' (1)
device = '82567LM Gigabit Network Connection' (2)
class = network
subclass = ethernet
--
iwn0@pci0:3:0:0: class=0x028000 rev=0x00 hdr=0x00 vendor=0x8086 device=0x4237 subvendor=0x8086 subdevice=0x1211
vendor = 'Intel Corporation' (1)
device = 'PRO/Wireless 5100 AGN [Shiloh] Network Connection' (2)
class = networ
| 1 | 显示供应商的名称 |
| 2 | 显示设备的名称 |
|
只有在 FreeBSD 没有正确检测到网络接口卡时,才需要加载该模块。 例如,要加载 alc(4) 模块,请执行以下命令: 或者,要在启动时将驱动程序加载为模块,请将以下行放置在 /boot/loader.conf 中: if_alc_load="YES" |
7.3. 有线网络
一旦正确的驱动程序加载完成,需要配置网络适配器。FreeBSD 使用驱动程序名称后跟一个单元号来命名网络接口适配器。单元号表示适配器在引导时被检测到的顺序,或者是稍后被发现的顺序。
例如,em0 是系统上使用 em(4) 驱动程序的第一个网络接口卡(NIC)。
要显示网络接口配置,请输入以下命令:
% ifconfig输出应该类似于以下内容:
em0: flags=8863<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=481249b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,LRO,WOL_MAGIC,VLAN_HWFILTER,NOMAP>
ether 00:1f:16:0f:27:5a
inet6 fe80::21f:16ff:fe0f:275a%em0 prefixlen 64 scopeid 0x1
inet 192.168.1.19 netmask 0xffffff00 broadcast 192.168.1.255
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=23<PERFORMNUD,ACCEPT_RTADV,AUTO_LINKLOCAL>
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> metric 0 mtu 16384
options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x2
inet 127.0.0.1 netmask 0xff000000
groups: lo
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
在这个例子中,显示了以下设备:
-
em0:以太网接口。 -
lo0:回环接口是一种软件环回机制,可用于性能分析、软件测试或本地通信。有关更多信息,请参阅 lo(4)。
这个例子显示 em0 已经启动并运行。
关键指标包括:
-
UP表示接口已配置并准备就绪。 -
该接口具有一个 IPv4 Internet(
inet)地址,192.168.1.19。 -
该接口具有一个 IPv6 Internet(
inet6)地址,fe80::21f:16ff:fe0f:275a%em0。 -
它具有有效的子网掩码(
netmask),其中0xffffff00与255.255.255.0相同。 -
它具有有效的广播地址,
192.168.1.255。 -
接口(
ether)的 MAC 地址是00:1f:16:0f:27:5a。 -
物理媒体选择处于自动选择模式(
media: Ethernet autoselect (1000baseT <full-duplex>))。 -
链接的状态(
status)为active,表示检测到载波信号。对于em0,当以太网电缆未插入接口时,status: no carrier状态是正常的。
如果 ifconfig(8) 命令的输出结果与下面的输出结果类似,那么说明接口尚未配置:
em0: flags=8822<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=481249b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,LRO,WOL_MAGIC,VLAN_HWFILTER,NOMAP>
ether 00:1f:16:0f:27:5a
media: Ethernet autoselect
status: no carrier
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
7.3.1. 配置静态 IPv4 地址
本节提供了在 FreeBSD 系统上配置静态 IPv4 地址的指南。
可以使用命令行的 ifconfig(8) 来配置网络接口卡,但是如果不将配置添加到 /etc/rc.conf 中,配置在重启后将不会保留。
|
如果网络在安装过程中由 bsdinstall(8) 进行配置,则可能已经存在一些网络接口卡(NIC)的条目。在执行 sysrc(8) 之前,请仔细检查 /etc/rc.conf。 |
可以通过执行以下命令来设置 IP 地址:
# ifconfig em0 inet 192.168.1.150/24要使更改在重新启动后保持生效,请执行以下命令:
# sysrc ifconfig_em0="inet 192.168.1.150 netmask 255.255.255.0"执行以下命令添加默认路由器:
# sysrc defaultrouter="192.168.1.1"将 DNS 记录添加到 [/etc/resolv.conf] 文件中:
nameserver 8.8.8.8 nameserver 8.8.4.4
然后执行以下命令重新启动 netif 和 routing:
# service netif restart && service routing restart可以使用 ping(8) 来测试连接。
% ping -c2 www.FreeBSD.org输出应该类似于以下内容:
PING web.geo.FreeBSD.org (147.28.184.45): 56 data bytes 64 bytes from 147.28.184.45: icmp_seq=0 ttl=51 time=55.173 ms 64 bytes from 147.28.184.45: icmp_seq=1 ttl=51 time=53.093 ms --- web.geo.FreeBSD.org ping statistics --- 2 packets transmitted, 2 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 53.093/54.133/55.173/1.040 ms
7.3.2. 配置动态 IPv4 地址
如果网络有一个 DHCP 服务器,配置网络接口使用 DHCP 非常简单。FreeBSD 使用 dhclient(8) 作为 DHCP 客户端。 dhclient(8) 会自动提供 IP 地址、子网掩码和默认路由器。
要使接口与 DHCP 配合工作,请执行以下命令:
# sysrc ifconfig_em0="DHCP"dhclient(8) 可以通过运行以下命令手动使用:
# dhclient em0输出应该类似于以下内容:
DHCPREQUEST on em0 to 255.255.255.255 port 67 DHCPACK from 192.168.1.1 unknown dhcp option value 0x7d bound to 192.168.1.19 -- renewal in 43200 seconds.
通过这种方式可以验证使用 DHCP 进行地址分配是否正常工作。
|
dhclient(8) 客户端可以在后台启动。这可能会对依赖于正常工作网络的应用程序造成麻烦,但在许多情况下,它将提供更快的启动速度。 要在后台执行 dhclient(8),请执行以下命令: |
然后执行以下命令重新启动 netif:
# service netif restart可以使用 ping(8) 来测试连接。
% ping -c2 www.FreeBSD.org输出应该类似于以下内容:
PING web.geo.FreeBSD.org (147.28.184.45): 56 data bytes 64 bytes from 147.28.184.45: icmp_seq=0 ttl=51 time=55.173 ms 64 bytes from 147.28.184.45: icmp_seq=1 ttl=51 time=53.093 ms --- web.geo.FreeBSD.org ping statistics --- 2 packets transmitted, 2 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 53.093/54.133/55.173/1.040 ms
7.3.3. IPv6
IPv6 是广为人知的 IP 协议的新版本,也被称为 IPv4。
IPv6 相比 IPv4 提供了几个优势,以及许多新的功能:
-
它的 128 位地址空间允许拥有 340,282,366,920,938,463,463,374,607,431,768,211,456 个地址。这解决了 IPv4 地址短缺和最终的 IPv4 地址耗尽问题。
-
路由器只在其路由表中存储网络聚合地址,从而将路由表的平均空间减少到 8192 个条目。这解决了与 IPv4 相关的可扩展性问题,因为 IPv4 要求每个分配的 IPv4 地址块在互联网路由器之间进行交换,导致它们的路由表变得过大,无法实现高效的路由。
-
地址自动配置 (RFC2462)
-
强制性多播地址。
-
内置 IPsec(IP security)。
-
简化的标题结构。
-
支持移动 IP。
-
IPv6 到 IPv4 的过渡机制。
FreeBSD 包含了 KAME 项目 IPv6 参考实现,并且提供了使用 IPv6 所需的一切。
本节重点介绍如何配置和运行 IPv6。
IPv6 地址有三种不同的类型:
- 单播
-
发送到单播地址的数据包到达与该地址相关的接口。
- 任播
-
这些地址在语法上与单播地址无法区分,但它们用于寻址一组接口。发送到任播地址的数据包将到达最近的路由器接口。任播地址只由路由器使用。
- 多播
-
这些地址标识了一组接口。发送到多播地址的数据包将到达属于多播组的所有接口。 IPv4 广播地址通常为
xxx.xxx.xxx.255,在 IPv6 中用多播地址表示。
在阅读 IPv6 地址时,规范形式表示为 x:x:x:x:x:x:x:x,其中每个 x 表示一个 16 位的十六进制值。一个例子是 FEBC:A574:382B:23C1:AA49:4592:4EFE:9982。
通常,一个地址会有很长的全零子串。一个 ::(双冒号)可以用来替换地址中的一个子串。此外,每个十六进制值前面的最多三个 0 可以省略。例如, fe80::1 对应的规范形式是 fe80:0000:0000:0000:0000:0000:0000:0001。
第三种形式是使用众所周知的 IPv4 表示法编写最后 32 位。例如,2002::10.0.0.1 对应于十六进制的规范表示 2002:0000:0000:0000:0000:0000:0a00:0001,而这又等同于 2002::a00:1。
要查看 FreeBSD 系统的 IPv6 地址,请执行以下命令:
# ifconfig输出应该类似于以下内容:
em0: flags=8863<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=481249b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,LRO,WOL_MAGIC,VLAN_HWFILTER,NOMAP>
ether 00:1f:16:0f:27:5a
inet 192.168.1.150 netmask 0xffffff00 broadcast 192.168.1.255
inet6 fe80::21f:16ff:fe0f:275a%em0 prefixlen 64 scopeid 0x1
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=23<PERFORMNUD,ACCEPT_RTADV,AUTO_LINKLOCAL>
在这个例子中,em0 接口正在使用 fe80::21f:16ff:fe0f:275a%em0,这是一个自动配置的链路本地地址,它是根据 MAC 地址自动生成的。
一些 IPv6 地址是保留地址。保留地址的列表可以在下表中查看:
| IPv6 地址 | 前缀长度(位) | 描述 | 注释 |
|---|---|---|---|
|
128 位 |
未指定的 |
IPv4 中等同于 |
|
128 位 |
环回地址 |
IPv4 中等同于 |
|
96 位 |
嵌入式 IPv4 |
低 32 位是兼容的 IPv4 地址。 |
|
96 位 |
IPv4 映射 IPv6 地址 |
低 32 位是不支持 IPv6 的主机的 IPv4 地址。 |
|
10 位 |
链路本地 |
在 IPv4 中,等同于 169.254.0.0/16 的地址。 |
|
7 位 |
唯一本地 |
唯一本地地址用于本地通信,只能在一组合作站点内进行路由。 |
|
8 位 |
多播 |
|
|
3 位 |
全局单播 |
所有全局单播地址都是从这个地址池中分配的。前 3 位是 |
有关 IPv6 地址结构的更多信息,请参考 RFC3513。
7.3.4. 配置静态 IPv6 地址
要将 FreeBSD 系统配置为具有静态 IPv6 地址的 IPv6 客户端,需要设置 IPv6 地址。
执行以下命令以满足要求:
# sysrc ifconfig_em0_ipv6="inet6 2001:db8:4672:6565:2026:5043:2d42:5344 prefixlen 64"要分配一个默认路由器,请执行以下命令指定其地址:
# sysrc ipv6_defaultrouter="2001:db8:4672:6565::1"7.3.5. 配置动态 IPv6 地址
如果网络有一个 DHCP 服务器,配置网络接口使用 DHCP 非常简单。dhclient(8) 会自动提供 IP 地址、子网掩码和默认路由器。
要使接口与 DHCP 配合工作,请执行以下命令:
# sysrc ifconfig_em0_ipv6="inet6 accept_rtadv"
# sysrc rtsold_enable="YES"7.3.6. 路由器通告和主机自动配置
本节演示了如何在 IPv6 路由器上设置 rtadvd(8),以广播 IPv6 网络前缀和默认路由。
要启用 rtadvd(8),执行以下命令:
# sysrc rtadvd_enable="YES"指定 IPv6 路由器通告的接口非常重要。例如,要告诉 rtadvd(8) 使用 em0:
# sysrc rtadvd_interfaces="em0"接下来,按照以下示例创建配置文件 /etc/rtadvd.conf :
em0:\ :addrs#1:addr="2001:db8:1f11:246::":prefixlen#64:tc=ether:
将 em0 替换为要使用的接口,将 2001:db8:1f11:246:: 替换为分配的前缀。
对于一个专用的 /64 子网,不需要做任何其他更改。否则,请将 prefixlen# 更改为正确的值。
7.4. 无线网络
大多数无线网络都基于 IEEE® 802.11 标准。
|
在 FreeBSD 上,目前正在开发对 802.11ac 的支持。 |
一个基本的无线网络由多个站点组成,这些站点使用广播在 2.4GHz 或 5GHz 频段进行通信,尽管这在不同地区可能有所不同,并且也在不断变化以实现在 2.3GHz 和 4.9GHz 范围内的通信。
配置无线网络有三个基本步骤:
-
扫描并选择一个接入点
-
验证该站点
-
配置 IP 地址或使用 DHCP。
下面的部分讨论了每个步骤。
7.4.1. 连接无线网络的快速入门指南
将 FreeBSD 连接到现有的无线网络是一种非常常见的情况。
该过程显示所需的步骤:
-
第一步是从网络管理员那里获取无线网络的 SSID (服务集标识)和 PSK (预共享密钥)。
-
第二步是将此网络添加到 /etc/wpa_supplicant.conf 的条目中。如果文件不存在,请创建它:
network={
ssid="myssid" (1)
psk="mypsk" (2)
}
| 1 | 是无线网络的 SSID 。请将其替换为无线网络的名称。 <.> 是无线网络的 PSK 。请将其替换为无线网络的密码。
|
# sysrc wlans_iwn0="wlan0"
# sysrc ifconfig_wlan0="WPA DHCP"-
最后一步将是重新启动
netif服务,执行以下命令:
# service netif restart7.4.2. 基本无线配置
第一步是将无线网络卡配置到一个接口上。要查看系统中有哪些无线网络卡,请参考 识别网络适配器 部分。
# ifconfig wlan0 create wlandevice iwm0要使更改在重新启动后保持生效,请执行以下命令:
# sysrc wlans_iwn0="wlan0"|
由于世界各地的监管情况不同,因此有必要正确设置适用于您所在地区的域名,以获取关于可以使用哪些频道的正确信息。 可用的区域定义可以在 /etc/regdomain.xml 中找到。要在运行时设置数据,请使用 要持久保存设置,请将其添加到 [/etc/rc.conf] 文件中: |
7.4.3. 扫描无线网络
可以使用 ifconfig(8) 命令扫描可用的无线网络。
要列出无线网络,请执行以下命令:
# ifconfig wlan0 up list scan输出应该类似于以下内容:
SSID/MESH ID BSSID CHAN RATE S:N INT CAPS FreeBSD e8:d1:1b:1b:58:ae 1 54M -47:-96 100 EP RSN BSSLOAD HTCAP WPS WME NetBSD d4:b9:2f:35:fe:08 1 54M -80:-96 100 EP RSN BSSLOAD HTCAP WPS WME OpenBSD fc:40:09:c6:31:bd 36 54M -94:-96 100 EPS VHTPWRENV APCHANREP RSN WPS BSSLOAD HTCAP VHTCAP VHTOPMODE WME GNU-Linux dc:f8:b9:a0:a8:e0 44 54M -95:-96 100 EP WPA RSN WPS HTCAP VHTCAP VHTOPMODE WME VHTPWRENV Windows 44:48:b9:b3:c3:ff 44 54M -84:-96 100 EP BSSLOAD VHTPWRENV HTCAP WME RSN VHTCAP VHTOPMODE WPS MacOS 46:48:b9:b3:c3:ff 44 54M -84:-96 100 EP BSSLOAD VHTPWRENV HTCAP WME RSN VHTCAP VHTOPMODE WPS
-
SSID/MESH ID 标识网络的名称。
-
BSSID 标识了接入点的 MAC 地址。
-
CAPS 字段标识了每个网络的类型以及在该网络上运行的站点的能力(有关详细信息,请参阅 ifconfig(8) 中
list scan的定义)。
7.4.4. 连接和认证无线网络
一旦从扫描到的网络列表中选择了一个无线网络,就需要进行连接和认证。在绝大多数无线网络中,认证是通过路由器中配置的密码来完成的。其他方案要求在数据流量可以流动之前完成加密握手,可以使用预共享密钥或密钥,也可以使用涉及后端服务(如 RADIUS)的更复杂的方案。
7.4.4.1. 使用 WPA2/WPA/Personal
无线网络中的身份验证过程由 wpa_supplicant(8) 管理。
wpa_supplicant(8) 配置将在 /etc/wpa_supplicant.conf 文件中进行。有关更多信息,请参阅 wpa_supplicant.conf(5)。
一旦完成了对无线网络的扫描,选择了一个网络并获得了密码(PSK),那么这些信息将被添加到文件 /etc/wpa_supplicant.conf 中,如下所示的示例:
network={
scan_ssid=1 (1)
ssid="FreeBSD" (2)
psk="12345678" (3)
}
| 1 | SSID 扫描技术。只有在网络隐藏时才需要使用此选项。 <.> 网络名称。 <.> 无线网络的密码。 |
下一步将是在文件 /etc/rc.conf 中配置无线连接。
要使用静态地址,需要执行以下命令:
# sysrc ifconfig_wlan0="inet 192.168.1.20 netmask 255.255.255.0"要使用动态地址,需要执行以下命令:
# ifconfig_wlan0="WPA DHCP"然后执行以下命令重新启动网络:
# service netif restart|
可以在 “无线高级认证” 获取有关如何执行更高级身份验证方法的更多信息。 |
7.4.4.2. 使用开放网络进行身份验证
|
当用户连接到没有任何身份验证方式的开放网络时,非常重要的是用户要非常小心。 |
完成无线网络扫描并选择无线网络的 SSID 后,执行以下命令:
# ifconfig wlan0 ssid SSID然后执行 dhclient(8) 来获取配置的地址:
# dhclient wlan07.4.5. 同时使用有线和无线连接
有线连接提供更好的性能和可靠性,而无线连接提供灵活性和移动性。笔记本电脑用户通常希望在这两种连接类型之间无缝切换。
在 FreeBSD 上,可以以“故障转移(failover)”的方式将两个甚至更多的网络接口组合在一起。这种配置类型使用一组网络接口中最优先和可用的连接,并且当链路状态发生变化时,操作系统会自动切换。
链路聚合和故障转移在 “链路聚合和故障转移” 中有详细介绍,并且在 “以太网和无线接口之间的故障转移模式” 中提供了同时使用有线和无线连接的示例。
7.6. DNS
DNS 可以被理解为一个 电话簿,其中将 IP 地址与主机名进行互相识别。
有三个文件处理 FreeBSD 系统与 DNS 的交互。这三个文件是 hosts(5)、resolv.conf(5) 和 nsswitch.conf(5)。
除非在 /etc/nsswitch.conf 文件中另有说明,否则 FreeBSD 将首先查看 /etc/hosts 文件中的地址,然后再查看 /etc/resolv.conf 文件中的 DNS 信息。
|
nsswitch.conf(5) 文件指定了 nsdispatch(名称服务切换调度程序)的操作方式。 默认情况下,/etc/nsswitch.conf 文件的 hosts 部分将如下所示: hosts: files dns 例如,在使用 nscd(8) 服务的情况下,可以通过将该行保持如下来更改优先顺序: hosts: files cache dns |
7.6.1. 本地地址
/etc/hosts 文件是一个简单的文本数据库,用于提供主机名到 IP 地址的映射。可以将连接到局域网的本地计算机的条目添加到此文件中,以简化命名,而不是设置 DNS 服务器。此外, /etc/hosts 还可以用于提供互联网名称的本地记录,减少查询外部 DNS 服务器以获取常用名称的需求。
例如,在本地环境中有一个名为 www/gitlab-ce 的本地实例的情况下,可以将其添加到文件 /etc/hosts 中,如下所示:
192.168.1.150 git.example.com git
7.6.2. 配置域名服务器
FreeBSD 系统如何访问互联网域名系统(DNS)由 resolv.conf(5) 控制。
最常见的条目是 /etc/resolv.conf :
|
解析器应查询的名称服务器的 IP 地址。按照列出的顺序查询服务器,最多查询三个。 |
|
搜索列表用于主机名查找。通常由本地主机名的域确定。 |
|
本地域名。 |
一个典型的 /etc/resolv.conf 文件如下所示:
search example.com nameserver 147.11.1.11 nameserver 147.11.100.30
|
只能使用 |
在使用 DHCP 时,dhclient(8) 通常会使用从 DHCP 服务器接收到的信息重写 .filename#/etc/resolv.conf# 文件。
|
如果进行配置的机器 不是 DNS 服务器,可以使用 local-unbound(8) 来提高 DNS 查找性能。 要在启动时启用它,请执行以下命令: 要启动 local-unbound(8) 服务,请执行以下命令: |
7.7. 故障排除
在排除硬件和软件配置问题时,首先检查简单的事情。
-
网络电缆已插好吗?
-
网络服务是否已正确配置?
-
防火墙配置正确吗?
-
FreeBSD 是否支持该网卡?
-
路由器是否正常工作?
|
在发送错误报告之前,始终要在 FreeBSD 发布页面 检查硬件说明 ,将 FreeBSD 版本更新到最新的 STABLE 版本,检查邮件列表存档,并在互联网上进行搜索。 |
7.7.1. 有线网络故障排除
如果卡可以正常工作,但性能较差,请阅读 tuning(7)。此外,请检查网络配置,因为不正确的网络设置可能会导致连接变慢。
如果系统无法将数据包路由到目标主机,则会出现“无法到达主机”的消息。如果没有指定默认路由或者电缆未插好,就会发生这种情况。检查 netstat -rn 的输出,并确保存在到目标主机的有效路由。如果不存在有效路由,请阅读 “网关和路由”.
7.7.2. 无线网络故障排除
本节描述了一些步骤,以帮助解决常见的无线网络问题。
-
如果在扫描时未列出访问点,请检查配置是否限制了无线设备的频道范围。
-
如果设备无法与接入点关联,请验证配置是否与接入点上的设置匹配。这包括认证方案和任何安全协议。尽量简化配置。如果使用 WPA2 或 WPA 等安全协议,请将接入点配置为开放认证和无安全性,以查看是否可以传输流量。
-
一旦系统能够与接入点建立关联,可以使用诸如 ping(8) 之类的工具来诊断网络配置。
-
有许多低级调试工具。可以使用 wlandebug(8) 在 802.11 协议支持层启用调试消息。
Part II: 常见任务
现在基础知识已经介绍完毕,本书的这一部分将讨论 FreeBSD 的一些常用功能。这些章节包括:
-
介绍流行且实用的桌面应用程序:浏览器、办公工具、文档查看器等等。
-
介绍一些适用于 FreeBSD 的多媒体工具。
-
解释构建自定义 FreeBSD 内核以启用额外功能的过程。
-
详细描述桌面和网络连接打印机设置中的打印系统。
-
展示如何在 FreeBSD 系统上运行 Linux 应用程序。
其中一些章节建议先阅读,这在每个章节开头的简介中有注明。
Chapter 8. 桌面环境
8.1. 简介
尽管 FreeBSD 因其性能和稳定性而在服务器领域很受欢迎,但它也非常适合作为日常桌面使用。在 FreeBSD ports 树中有超过 36000 个应用程序可用,可以轻松构建一个定制的桌面环境,可以运行各种各样的桌面应用程序。本章介绍了如何安装流行的桌面环境以及诸如网络浏览器、办公软件、文档查看器和财务软件等桌面应用程序。
先决条件:
-
阅读本章的读者应该已经了解如何在 FreeBSD 上安装 X Window System 或 Wayland 。
-
在本章中,读者被指示安装官方软件包。请参考 使用 ports 集合 部分,以从 ports 构建定制软件包。
8.2. 桌面环境
本节介绍了如何在 FreeBSD 系统上安装和配置一些流行的桌面环境。桌面环境可以是一个简单的窗口管理器,也可以是一个完整的桌面应用套件。
| 名称 | 许可证 | 包 |
|---|---|---|
KDE Plasma |
GPL 2.0 or later |
x11/kde5 |
GNOME |
GPL 2.0 or later |
x11/gnome |
XFCE |
GPL, LGPL, BSD |
x11-wm/xfce4 |
MATE |
GPL 2.0, LGPL 2.0 |
x11/mate |
Cinnamon |
GPL 2.0 or later |
x11/cinnamon |
LXQT |
GPL, LGPL |
x11-wm/lxqt |
8.2.1. KDE Plasma
KDE Plasma 是一个易于使用的桌面环境。该桌面提供了一套应用程序,具有一致的外观和感觉,标准化的菜单和工具栏,键绑定,配色方案,国际化以及集中式、对话框驱动的桌面配置。有关 KDE 的更多信息,请访问 KDE 主页 。有关 FreeBSD 特定信息,请参阅 KDE 上的 FreeBSD 主页 。
8.2.1.2. 最小化的 KDE Plasma 安装
要安装最小化的 KDE Plasma ,请执行以下操作:
# pkg install plasma5-plasma|
这个安装非常简洁。必须单独安装 Konsole,执行以下操作: |
8.2.1.3. 配置 KDE Plasma
KDE Plasma 使用 dbus-daemon(1) 作为消息总线和硬件抽象层。这个应用程序会自动作为 KDE Plasma 的依赖项安装。
在 /etc/rc.conf 中启用 D-BUS 服务以在系统启动时启动:
# sysrc dbus_enable="YES"要增加消息大小,请执行以下操作:
sysctl net.local.stream.recvspace=65536
sysctl net.local.stream.sendspace=655368.2.1.4. 启动 KDE Plasma
# pkg install sddm在 /etc/rc.conf 中启用 SDDM 服务以在系统启动时启动:
# sysrc sddm_enable="YES"可以通过运行以下命令在 SDDM 中设置键盘语言(例如,对于西班牙语):
# sysrc sddm_lang="es_ES"启动 KDE Plasma 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo "exec ck-launch-session startplasma-x11" > ~/.xinitrc8.2.2. GNOME
GNOME 是一个用户友好的桌面环境。它包括一个用于启动应用程序和显示状态的面板,一个桌面,一套工具和应用程序,以及一套使应用程序能够合作并保持一致的约定。
8.2.2.2. 最小化的 GNOME 安装
要安装 GNOME-lite 元包,其中包含了经过精简的 GNOME 桌面,仅包含基本功能,请执行以下操作:
# pkg install gnome-lite8.2.2.3. 配置 GNOME
GNOME 需要挂载 /proc。在系统启动时自动挂载此文件系统,请将以下行添加到 /etc/fstab 文件中:
# Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
GNOME 使用 dbus-daemon(1) 作为消息总线和硬件抽象的工具。这个应用程序会作为 GNOME 的依赖自动安装。
在 /etc/rc.conf 中启用 D-BUS 服务以在系统启动时启动:
# sysrc dbus_enable="YES"8.2.2.4. 启动 GNOME
GNOME Display Manager(简称 GDM )是 GNOME 首选的显示管理器。GDM 作为 GNOME 软件包的一部分进行安装。
在 /etc/rc.conf 中启用 GDM 以在系统启动时启动:
# sysrc gdm_enable="YES"启动 GNOME 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo "exec gnome-session" > ~/.xinitrc8.2.3. XFCE
XFCE 是一个基于 GTK+ 的桌面环境,它轻量级并提供了一个简单、高效、易于使用的桌面。它可以完全配置,有一个带有菜单、小部件和应用程序启动器的主面板,提供文件管理器和声音管理器,并且支持主题定制。由于它快速、轻量级和高效,非常适合内存有限的老旧或较慢的计算机。
8.2.3.2. 配置 XFCE
XFCE 需要挂载 /proc。在系统启动时自动挂载此文件系统,请将以下行添加到 /etc/fstab 中:
# Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
XFCE 使用 dbus-daemon(1) 作为消息总线和硬件抽象的工具。这个应用程序会作为 XFCE 的依赖项自动安装。
在 /etc/rc.conf 中启用 D-BUS 以在系统启动时启动:
# sysrc dbus_enable="YES"8.2.3.3. 启动 XFCE
x11/lightdm 是一个支持不同显示技术的显示管理器,它非常轻量级,内存使用量少,并且性能快速,是一个很好的选择。
要安装它,请执行以下操作:
# pkg install lightdm lightdm-gtk-greeter在 /etc/rc.conf 中启用 lightdm 以在系统启动时启动:
# sysrc lightdm_enable="YES"启动 XFCE 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo '. /usr/local/etc/xdg/xfce4/xinitrc' > ~/.xinitrc8.2.4. MATE
MATE 桌面环境是 GNOME 2 的延续。它使用传统的样式,提供直观和吸引人的桌面环境。
8.2.4.3. 配置 MATE
MATE 需要挂载 /proc。在系统启动时自动挂载该文件系统,请将以下行添加到 /etc/fstab 文件中:
# Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
MATE 使用 dbus-daemon(1) 作为消息总线和硬件抽象层。这个应用程序会自动作为 MATE 的依赖项安装。在 /etc/rc.conf 中启用 D-BUS 以在系统启动时启动。
# sysrc dbus_enable="YES"8.2.4.4. 启动 MATE
x11/lightdm 是一个支持不同显示技术的显示管理器,它非常轻量级,内存使用量少,并且性能快速,是一个很好的选择。
要安装它,请执行以下操作:
# pkg install lightdm lightdm-gtk-greeter在 /etc/rc.conf 中启用 lightdm 以在系统启动时启动:
# sysrc lightdm_enable="YES"启动 MATE 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo "exec ck-launch-session mate-session" > ~/.xinitrc8.2.5. Cinnamon
Cinnamon 是一个 UNIX® 桌面环境,提供先进的创新功能和传统的用户体验。桌面布局类似于 Gnome 2。底层技术是从 Gnome Shell 分叉出来的。重点是让用户感到宾至如归,并为他们提供易于使用和舒适的桌面体验。
8.2.5.2. 配置 Cinnamon
Cinnamon 需要挂载 /proc。在系统启动时自动挂载该文件系统,请将以下行添加到 /etc/fstab 文件中:
# Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
Cinnamon 使用 dbus-daemon(1) 作为消息总线和硬件抽象层。这个应用程序会自动作为 Cinnamon 的依赖项安装。在 /etc/rc.conf 中启用 D-BUS 以在系统启动时启动它:
# sysrc dbus_enable="YES"8.2.5.3. 启动 Cinnamon
x11/lightdm 是一个支持不同显示技术的显示管理器,它非常轻量级,内存使用量少,并且性能快速,是一个很好的选择。
要安装它,请执行以下操作:
# pkg install lightdm lightdm-gtk-greeter在 /etc/rc.conf 中启用 lightdm 以在系统启动时启动:
# sysrc lightdm_enable="YES"启动 Cinnamon 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo "exec ck-launch-session cinnamon-session" > ~/.xinitrc8.2.6. LXQT
LXQt 是一个基于 Qt 技术的先进、易于使用和快速的桌面环境。它专为那些重视简洁、速度和直观界面的用户量身定制。与大多数桌面环境不同,LXQt 在性能较低的机器上也能良好运行。
8.2.6.2. 配置 LXQT
LXQT 需要挂载 /proc 。在系统启动时自动挂载该文件系统,请将以下行添加到 /etc/fstab 文件中:
# Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
LXQT 使用 dbus-daemon(1) 作为消息总线和硬件抽象的工具。这个应用程序会自动作为 LXQT 的依赖项进行安装。
在 /etc/rc.conf 中启用 D-BUS 以在系统启动时启动:
# sysrc dbus_enable="YES"8.2.6.3. 启动 LXQT
# pkg install sddm在 /etc/rc.conf 中启用 SDDM 服务以在系统启动时启动:
# sysrc sddm_enable="YES"在 SDDM 中,可以通过运行以下命令来设置键盘语言(例如,对于西班牙语):
# sysrc sddm_lang="es_ES"启动 LXQT 的第二种方法是手动调用 startx(1)。为了使其工作,需要在 ~/.xinitrc 中添加以下行:
% echo "exec ck-launch-session startlxqt" > ~/.xinitrc8.3. 浏览器
本节介绍了如何在 FreeBSD 系统上安装和配置一些流行的网络浏览器,从资源消耗较高的完整网络浏览器到资源使用较少的命令行网络浏览器。
| 名称 | 许可证 | 包 | 所需资源 |
|---|---|---|---|
Firefox |
MPL 2.0 |
Heavy |
|
Chromium |
BSD-3 and others |
Heavy |
|
Iridium browser |
BSD-3 and others |
Heavy |
|
Falkon |
MPL 2.0 |
Heavy |
|
Konqueror |
GPL 2.0 or later |
Medium |
|
Gnome Web (Epiphany) |
GPL 3.0 or later |
Medium |
|
qutebrowser |
GPL 3.0 or later |
Medium |
|
Dillo |
GPL 3.0 or later |
Light |
|
Links |
GPL 2.0 or later |
Light |
|
w3m |
MIT |
Light |
8.3.1. Firefox
Firefox 是一个开源浏览器,具有符合标准的 HTML 显示引擎、选项卡浏览、弹窗阻止、扩展功能、增强的安全性等特点。Firefox 基于 Mozilla 代码库开发。
要安装最新发布版本的 Firefox 软件包,请执行以下操作:
# pkg install firefox要安装 Firefox Extended Support Release (ESR) 版本,执行以下操作:
# pkg install firefox-esr8.3.2. Chromium
Chromium 是一个开源的浏览器项目,旨在构建更安全、更快速、更稳定的网络浏览体验。Chromium 具有标签式浏览、弹窗拦截、扩展等功能。 Chromium 是 Google Chrome 浏览器基于的开源项目。
要安装 Chromium ,请执行以下操作:
# pkg install chromium|
Chromium 的可执行文件是 /usr/local/bin/chrome ,而不是 [.filename]/usr/local/bin/chromium#。 |
8.3.3. Iridium browser
Iridium 是一个免费、开放和自由的浏览器修改版本,基于 Chromium 代码库,通过增强隐私保护在几个关键领域进行改进。禁止自动传输部分查询、关键词和指标到中央服务,只有在获得同意的情况下才会发生传输。
要安装 Iridium ,请执行以下操作:
# pkg install iridium-browser8.3.4. Falkon
Falkon 是一个新近推出的非常快速的 QtWebEngine 浏览器。它旨在成为一款轻量级的适用于所有主要平台的网络浏览器。 Falkon 具备您从一个网络浏览器所期望的所有标准功能。它包括书签、历史记录(两者都在侧边栏中)和选项卡。除此之外,您还可以使用内置的 AdBlock 插件屏蔽广告,使用 Click2Flash 屏蔽 Flash 内容,并使用 SSL 管理器编辑本地 CA 证书数据库。
要安装 Falkon ,请执行以下操作:
# pkg install falkon8.3.5. Konqueror
Konqueror 不仅是一个网页浏览器,还是一个文件管理器和多媒体查看器。它支持 WebKit ,这是许多现代浏览器(包括 Chromium )使用的渲染引擎,同时也支持自己的 KHTML 引擎。
要安装 Konqueror ,请执行以下操作:
# pkg install konqueror8.3.6. Gnome Web (Epiphany)
Gnome Web (Epiphany)是一个旨在尽可能轻量和快速的网络浏览器,但牺牲了其他浏览器中的许多功能。
要安装 Gnome Web(Epiphany),执行以下操作:
# pkg install epiphany8.3.7. qutebrowser
Qutebrowser 是一个以键盘为重点的浏览器,具有简洁的图形用户界面。它基于 Python 和 PyQt5,是一款自由软件,根据 GPL 许可证发布。
要安装 qutebrowser ,请执行以下操作:
# pkg install qutebrowser8.3.8. Dillo
Dillo 旨在成为一个跨平台的替代浏览器,它小巧、稳定、开发者友好、易用、快速和可扩展。这个新的实验版本的 Dillo 基于 FLTK 工具包,而不是 GTK1,并且已经进行了大量的重写。
要安装 Dillo,请执行以下操作:
# pkg install dillo8.4. 开发工具
本节介绍了如何在 FreeBSD 系统上安装和配置一些流行的开发工具。
| 名称 | 许可证 | 包 | 所需资源 |
|---|---|---|---|
Visual Studio Code |
MIT |
Heavy |
|
Qt Creator |
QtGPL |
Heavy |
|
Kdevelop |
GPL 2.0 or later and LGPL 2.0 or later |
Heavy |
|
Eclipse IDE |
EPL |
Heavy |
|
Vim |
VIM |
Light |
|
Neovim |
Apache 2.0 |
Light |
|
GNU Emacs |
GPL 3.0 or later |
Light |
8.4.1. Visual Studio Code
Visual Studio Code 是一种工具,它将代码编辑器的简洁性与开发人员在 编辑-构建-调试 核心循环中所需的功能结合在一起。它提供全面的编辑和调试支持,可扩展性模型以及与现有工具的轻量级集成。
要安装 Visual Studio Code ,请执行以下操作:
# pkg install vscode8.4.2. Qt Creator
Qt Creator 是一个跨平台的集成开发环境(IDE),专为 Qt 开发人员的需求而设计。Qt Creator 包含的功能有:
-
支持 C ++、 QML 和 ECMAscript 的代码编辑器;
-
快速代码导航工具;
-
实时代码检查和样式提示;
-
上下文敏感帮助;
-
可视化调试器;
-
集成的 GUI 布局和表单设计工具。
要安装 Qt Creator ,请执行以下操作:
# pkg install qtcreator8.4.3. kdevelop
开源、功能丰富、可扩展插件的 C/C ++和其他编程语言的集成开发环境。它基于 KDevPlatform、KDE 和 Qt 库进行开发,并自 1998 年以来一直在不断发展。
要安装 kdevelop ,请执行以下操作:
# pkg install kdevelop8.4.4. Eclipse IDE
Eclipse 平台是一个开放的可扩展的集成开发环境(IDE),可以用于任何事情,但又没有特定的限制。Eclipse 平台提供了构建和运行集成软件开发工具的基础和组件。Eclipse 平台允许工具开发者独立地开发与其他人的工具集成的工具。
要安装 Eclipse IDE ,请执行以下操作:
# pkg install eclipse8.4.5. Vim
Vim 是一个高度可配置的文本编辑器,旨在实现高效的文本编辑。它是 vi 编辑器的改进版本,大多数 UNIX 系统都配备了 vi 编辑器。
Vim 通常被称为“程序员的编辑器”,对于编程非常有用,以至于许多人认为它是一个完整的集成开发环境(IDE)。然而, Vim 不仅适用于程序员。 Vim 非常适合各种文本编辑,从撰写电子邮件到编辑配置文件都可以。
要安装 Vim ,请执行以下命令:
# pkg install vim8.4.6. Neovim
Neovim 是编辑器 editors/vim 的一个积极的重构版本。它对代码库进行了彻底的改进,包括合理的默认设置、内置终端仿真器、异步插件架构和为速度和可扩展性而设计的强大 API 。它与几乎所有的 Vim 插件和脚本保持完全兼容。
要安装 Neovim ,请执行以下操作:
# pkg install neovim8.5. 桌面办公生产力
当谈到生产力时,用户通常会寻找一个办公套件或易于使用的文字处理软件。虽然一些桌面环境(如 KDE Plasma )提供了一个办公套件,但没有默认的生产力软件包。无论安装的桌面环境如何,FreeBSD 都提供了几个办公套件和图形化文字处理软件。
本节演示了如何安装以下流行的生产力软件,并指出应用程序是否资源密集型,从 ports 编译需要时间,或者是否有任何重要的依赖关系。
| 名称 | 许可证 | 包 | 所需资源 |
|---|---|---|---|
LibreOffice |
MPL 2.0 |
Heavy |
|
Calligra Suite |
LGPL and GPL |
Medium |
|
AbiWord |
GPL 2.0 or later |
Medium |
8.5.1. LibreOffice
LibreOffice 是由 The Document Foundation 开发的免费软件办公套件。它与其他主要办公套件兼容,并可在多种平台上使用。它是 Apache OpenOffice 的重新品牌分支,包括完整办公生产力套件中的应用程序:文字处理器、电子表格、演示文稿管理器、绘图程序、数据库管理程序以及用于创建和编辑数学公式的工具。它提供多种不同语言版本,并将国际化扩展到界面、拼写检查和字典。有关 LibreOffice 的更多信息,请访问 libreoffice.org 。
要安装 LibreOffice ,请执行以下操作:
# pkg install libreofficeLibreOffice 软件包默认只提供英文版本。要使用本地化的 LibreOffice 版本,需要安装语言包。例如,要安装西班牙语本地化版本,需要使用以下命令安装软件包:editors/libreoffice-es。
# pkg install libreoffice-es8.6. 文档查看器
自从 UNIX® 问世以来,一些新的文档格式已经变得流行起来,而这些格式所需的查看器可能在基本系统中不可用。本节介绍如何安装以下文档查看器:
| 名称 | 许可证 | 包 | 所需资源 |
|---|---|---|---|
Okular |
GPL 2.0 |
Heavy |
|
Evince |
GPL 2.0 |
Medium |
|
ePDFView |
GPL 2.0 |
Medium |
|
Xpdf |
GPL 2.0 |
light |
8.6.1. Okular
Okular 是一个通用的文档查看器,是 KDE Plasma 项目的一部分。
Okular 结合了出色的功能性和支持不同类型文档的多样性,如 PDF、Postscript、DjVu、CHM、XPS、ePub 等。
要安装 Okular,请执行以下操作:
# pkg install okular8.6.2. Evince
Evince 是一个支持多种文档格式的文档查看器,包括 PDF 和 Postscript。它是 GNOME 项目的一部分。Evince 的目标是用一个简单的应用程序取代 ggv 和 gpdf 等文档查看器。
要安装 Evince,请执行以下操作:
# pkg install evince8.7. 金融
在 FreeBSD 桌面上管理个人财务,可以安装一些强大且易于使用的应用程序。其中一些应用程序与广泛使用的文件格式兼容,例如 Quicken 和 Excel 使用的格式。
本节涵盖以下程序:
| 名称 | 许可证 | 包 | 所需资源 |
|---|---|---|---|
KMyMoney |
GPL 2.0 |
Heavy |
|
GnuCash |
GPL 2.0 and GPL 3.0 |
Heavy |
Chapter 9. 多媒体
9.1. 简介
多媒体章节提供了关于 FreeBSD 上多媒体支持的概述。多媒体应用和技术已成为现代计算的重要组成部分, FreeBSD 为各种多媒体硬件和软件提供了强大可靠的支持。本章介绍了各种多媒体组件,如音频、视频和图像处理。还讨论了各种媒体格式和编解码器,以及用于多媒体创建和播放的工具和应用程序。此外,本章还涵盖了多媒体系统配置、故障排除和优化。无论您是多媒体爱好者还是专业内容创作者, FreeBSD 都为多媒体工作提供了强大的平台。本章旨在帮助充分利用 FreeBSD 的多媒体功能,提供有用的信息和实际示例,以帮助入门。
9.2. 设置声卡
默认情况下, FreeBSD 会自动检测系统使用的声卡。 FreeBSD 支持各种各样的声卡。可以在 sound(4) 中查看支持的声卡列表。
|
只有在 FreeBSD 没有正确检测到声卡时才需要加载声卡模块。 |
当不知道系统使用哪个声卡或者使用哪个模块时,可以通过执行以下命令加载 snd_driver 元驱动程序:
# kldload snd_driver或者,要在启动时将驱动程序作为模块加载,将以下行放置在 /boot/loader.conf 中:
snd_driver_load="YES"
9.2.1. 测试声音
要确认声卡是否被检测到,可以执行以下命令:
% dmesg | grep pcm输出应该类似于以下内容:
pcm0: <Conexant CX20561 (Hermosa) (Analog 2.0+HP/2.0)> at nid 26,22 and 24 on hdaa0 pcm1: <Conexant CX20561 (Hermosa) (Internal Analog Mic)> at nid 29 on hdaa0
可以使用以下命令来检查声卡的状态:
# cat /dev/sndstat输出应该类似于以下内容:
Installed devices: pcm0: <Conexant CX20561 (Hermosa) (Analog 2.0+HP/2.0)> (play/rec) default pcm1: <Conexant CX20561 (Hermosa) (Internal Analog Mic)> (rec)
如果没有列出任何 pcm 设备,请再次检查是否加载了正确的设备驱动程序。如果一切顺利,声卡现在应该可以在 FreeBSD 中正常工作了。
beep(1) 可以用来产生一些声音,确认声卡是否正常工作:
% beep9.2.2. 搅拌器
FreeBSD 在 FreeBSD 声音系统上构建了不同的实用工具来设置和显示声卡混音值:
| 名称 | 许可证 | Package | 工具包 |
|---|---|---|---|
手册: mixer[8] |
BSD-2 是指 BSD 许可证的第二个版本。 |
包含在基本系统中 |
命令行界面( CLI ) |
dsbmixer 是一个用于混合和处理音频的开源软件。它提供了一系列功能,包括音频输入和输出设备的管理、音频信号的混合和处理、音频效果的应用等。 dsbmixer 可以通过命令行界面或图形界面进行操作,使用户能够方便地控制和调整音频的各个参数。它支持多种音频格式,并且具有高度可定制性,用户可以根据自己的需求进行配置和扩展。 dsbmixer 是一个功能强大且易于使用的音频处理工具,适用于各种音频应用场景。 |
BSD-2 是指 BSD 许可证的第二个版本。 |
包: audio/dsbmixer[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
KDE Plasma 音频小部件 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包: audio/plasma5-plasma-pa[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
mixertui 是一个用于创建和管理混音器的命令行工具。它提供了一种简单的方式来配置和控制混音器的各种参数,包括音频输入和输出、音量控制、效果器和信号路由等。使用 mixertui ,用户可以方便地调整和优化音频混合的设置,以满足个人或专业需求。 |
BSD-2 是指 BSD 许可证的第二个版本。 |
包:音频 / 混音器界面 [] |
TUI 是文本用户界面( Text User Interface )的缩写,是一种基于文本的用户界面,通常用于计算机终端或控制台应用程序。 TUI 提供了一种通过文本命令或菜单进行交互的方式,相比于图形用户界面( GUI ), TUI 更加轻量级和资源节约。 TUI 常用于命令行界面( CLI )工具、文本编辑器和终端模拟器等应用程序中。 |
9.2.3. 显卡声音
图形卡通常配备自己的集成声音设备,可能不清楚哪个设备被用作默认设备。要确认,请运行 dmesg 命令并查找 pcm 条目以确定系统如何枚举输出。执行以下命令:
% dmesg | grep pcm输出的结果看起来像这样:
pcm0: <HDA NVIDIA (Unknown) PCM #0 DisplayPort> at cad 0 nid 1 on hdac0 pcm1: <HDA NVIDIA (Unknown) PCM #0 DisplayPort> at cad 1 nid 1 on hdac0 pcm2: <HDA NVIDIA (Unknown) PCM #0 DisplayPort> at cad 2 nid 1 on hdac0 pcm3: <HDA NVIDIA (Unknown) PCM #0 DisplayPort> at cad 3 nid 1 on hdac0 hdac1: HDA Codec #2: Realtek ALC889 pcm4: <HDA Realtek ALC889 PCM #0 Analog> at cad 2 nid 1 on hdac1 pcm5: <HDA Realtek ALC889 PCM #1 Analog> at cad 2 nid 1 on hdac1 pcm6: <HDA Realtek ALC889 PCM #2 Digital> at cad 2 nid 1 on hdac1 pcm7: <HDA Realtek ALC889 PCM #3 Digital> at cad 2 nid 1 on hdac1
在图形卡( NVIDIA® )之前,声卡( Realtek® )已被枚举,声卡显示为 pcm4 。可以通过执行以下命令将声卡配置为默认设备:
# sysctl hw.snd.default_unit=4要使此更改永久生效,请将下一行添加到 /etc/sysctl.conf 文件中:
hw.snd.default_unit=4
9.2.4. 自动切换到耳机
有些系统在切换音频输出时可能会遇到困难,但幸运的是, FreeBSD 允许在 .device.hints 中配置自动切换。
通过执行以下命令来确定系统是如何枚举音频输出设备:
% dmesg | grep pcm输出的结果看起来像这样:
pcm0: <Realtek ALC892 Analog> at nid 23 and 26 on hdaa0 pcm1: <Realtek ALC892 Right Analog Headphones> at nid 22 on hdaa0
将以下行添加到 /boot/device.hints 文件中:
hint.hdac.0.cad0.nid22.config="as=1 seq=15 device=Headphones" hint.hdac.0.cad0.nid26.config="as=2 seq=0 device=speakers"
|
请记住,这些值是针对上述示例而言的。它们可能会因系统而异。 |
9.2.5. 音频故障排除
一些常见的错误消息及其解决方案:
常见错误消息
-
"File not found" - 文件未找到
-
"Access denied" - 拒绝访问
-
"Invalid username or password" - 用户名或密码无效
-
"Connection timed out" - 连接超时
-
"Invalid input" - 输入无效
-
"Out of memory" - 内存不足
-
"Permission denied" - 拒绝权限
-
"Invalid file format" - 文件格式无效
-
"Page not found" - 页面未找到
-
"Server error" - 服务器错误
错误 |
解决方案 |
`xxx: 无法打开 /dev/dsp ! ` |
输入 |
使用 |
使用 audio/pulseaudio 的程序可能需要重新启动 audio/pulseaudio 守护进程,以使 hw.snd.default_unit 的更改生效。或者,可以实时更改 audio/pulseaudio 的设置。 pacmd(1) 打开与 audio/pulseaudio 守护进程的命令行连接。
# pacmd
Welcome to PulseAudio 14.2! Use "help" for usage information.
>>>以下命令将默认的音频输出设备更改为卡号为 4 ,与之前的示例相同:
set-default-sink 4
|
不要使用 |
9.3. 音频播放器
本节介绍了一些可以用于音频播放的软件,这些软件可以从 FreeBSD Ports Collection 中获取。
| 名称 | 许可证 | Package | 工具包 |
|---|---|---|---|
Elisa |
LGPL 3.0 是 GNU Lesser General Public License ( GNU 宽松通用公共许可证)的第 3.0 版。 |
包:音频 /Elisa[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
GNOME 音乐 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包: audio/gnome-music[] |
GTK +是一个用于创建图形用户界面的开源工具包。它最初是为 GNU 计划开发的,现在已经成为许多 Linux 发行版的标准工具包。 GTK +提供了一套丰富的控件和功能,使开发者能够轻松地创建各种应用程序,包括桌面应用程序、移动应用程序和嵌入式系统应用程序。它使用 C 语言编写,并提供了多种编程语言的绑定,如 Python 、 C ++和 Java 。 GTK +还具有跨平台的特性,可以在不同的操作系统上运行,如 Linux 、 Windows 和 macOS 。 |
Audacious 是一个免费的音频播放器,可在多个平台上使用。它具有简洁的界面和丰富的功能,可以播放各种音频格式。 Audacious 还支持插件扩展,用户可以根据自己的需求添加额外的功能和特性。无论是在个人使用还是在专业环境中, Audacious 都是一个强大而可靠的音频播放器选择。 |
BSD-2 是指 BSD 许可证的第二个版本。 |
包:多媒体 /audacious[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
MOC (音乐控制台) |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包:音频 /moc[] |
TUI 是文本用户界面( Text User Interface )的缩写,是一种基于文本的用户界面,通常用于计算机终端或控制台应用程序。 TUI 提供了一种通过文本命令或菜单进行交互的方式,相比于图形用户界面( GUI ), TUI 更加轻量级和资源节约。 TUI 常用于命令行界面( CLI )工具、文本编辑器和终端模拟器等应用程序中。 |
9.3.2. GNOME 音乐
GNOME Music 是新的 GNOME 音乐播放应用程序。它旨在将优雅和沉浸式的浏览体验与简单直观的控制相结合。
要安装 GNOME 音乐,请执行以下操作:
# pkg install gnome-music9.3.3. Audacious 是一个免费的音频播放器,可在多个平台上使用。它具有简洁的界面和丰富的功能,可以播放各种音频格式。 Audacious 还支持插件扩展,用户可以根据自己的需求添加额外的功能和特性。无论是在个人使用还是在专业环境中, Audacious 都是一个强大而可靠的音频播放器选择。
Audacious 是一个开源音频播放器。它是 XMMS 的后代,可以按照您的要求播放音乐,而不会占用计算机的资源进行其他任务。
要安装 Audacious ,请执行以下操作:
# pkg install audacious-qt6 audacious-plugins-qt6|
Audacious 原生支持 OSS ,但必须在设置中的音频选项卡中进行配置。 |
9.4. 视频播放器
本节介绍了一些可以用于视频播放的软件,这些软件可以从 FreeBSD Ports Collection 中获取。
| 名称 | 许可证 | Package | 工具包 |
|---|---|---|---|
MPlayer 是一个开源的多媒体播放器,可以在多个平台上运行。它支持各种音频和视频格式,并具有强大的功能和灵活的配置选项。 MPlayer 是一个非常流行的播放器,被广泛用于电影、音乐和其他媒体的播放。它具有简单易用的界面和高质量的播放效果,是许多用户的首选播放器之一。 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包:多媒体 /mplayer[] |
命令行界面( CLI ) |
SMPlayer 是一个免费的多媒体播放器,可在 Windows 和 Linux 操作系统上使用。它支持各种音频和视频格式,并具有许多有用的功能,如字幕支持、音频和视频过滤器、播放列表和快捷键。 SMPlayer 还具有用户友好的界面和可自定义的外观。它是一个功能强大且易于使用的播放器,适用于各种媒体播放需求。 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包:多媒体 /SMPlayer[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
VLC 媒体播放器 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包:多媒体 /vlc[] |
Qt 是一个跨平台的应用程序开发框架,用于开发图形用户界面、网络应用、数据库连接和其他各种应用程序。它提供了丰富的类库和工具,使开发者能够快速构建高质量的应用程序。 Qt 使用 C ++编写,具有良好的可扩展性和可移植性。它被广泛应用于各种领域,包括桌面应用、移动应用和嵌入式系统。 |
Kodi ( XBMC ) |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
包:多媒体 /kodi[] |
X11 是一个用于图形用户界面的网络协议。它允许在远程计算机上运行的应用程序通过网络连接到显示设备,并在本地显示。 X11 是 UNIX 和类 UNIX 系统中最常用的图形系统。它提供了窗口管理、图形绘制和用户输入处理等功能。 X11 还支持客户端 - 服务器模型,允许多个应用程序同时连接到同一个显示设备。 |
9.4.1. MPlayer 是一个开源的多媒体播放器,可以在多个平台上运行。它支持各种音频和视频格式,并具有强大的功能和灵活的配置选项。 MPlayer 是一个非常流行的播放器,被广泛用于电影、音乐和其他媒体的播放。它具有简单易用的界面和高质量的播放效果,是许多用户的首选播放器之一。
MPlayer 是一个多媒体播放器和编码套件,可以在许多平台上运行,并且可以通过命令行操作。它可以播放大量不同的文件格式和编解码器,包括流行的 DivX 、 XviD 、 H.264 流以及 DVD 和 SVCD ,还支持许多流行的音频编解码器。
要安装 MPlayer ,请执行以下操作:
# pkg install mplayer有关 MPlayer 如何工作的示例,请参阅 mplayer(1) 。
9.4.2. SMPlayer 是一个免费的多媒体播放器,可在 Windows 和 Linux 操作系统上使用。它支持各种音频和视频格式,并具有许多有用的功能,如字幕支持、音频和视频过滤器、播放列表和快捷键。 SMPlayer 还具有用户友好的界面和可自定义的外观。它是一个功能强大且易于使用的播放器,适用于各种媒体播放需求。
SMPlayer 旨在成为 MPlayer 的完整前端,从播放视频、 DVD 和 VCD 等基本功能到支持 MPlayer 滤镜等更高级功能。
要安装 SMPlayer ,请执行以下操作:
# pkg install smplayer9.5. 会议和会议
FreeBSD 桌面环境可以用于参加视频会议。本节将介绍如何配置摄像头以及在 FreeBSD 上支持哪些视频会议应用程序。
9.5.1. 设置网络摄像头
为了让 FreeBSD 能够访问并配置摄像头,需要安装一些特定的工具:
-
multimedia/webcamd 是一个守护进程,可以使用数百种不同的基于 USB 的网络摄像头和 DVB USB 设备。
-
multimedia/pwcview 是一个可以用来查看网络摄像头视频流的应用程序。
要安装所需的工具,请执行以下操作:
# pkg install webcamd pwcview在 /etc/rc.conf 中启用 webcamd(8) 服务,以便在系统启动时启动它:
# sysrc webcamd_enable="YES"用户必须属于 webcamd 组。要将用户添加到 webcamd 组,请执行以下命令:
# pw groupmod webcamd -m username由于 multimedia/webcamd 需要 cuse(3) 模块,因此必须通过执行以下命令来加载该模块:
# kldload cuse要在系统启动时加载 cuse(3) ,执行以下命令:
# sysrc kld_list += "cuse"一旦安装了实用程序,可以使用 webcamd(8) 命令显示可用的网络摄像头列表。
# webcamd -l输出应该类似于以下内容:
webcamd [-d ugen0.2] -N SunplusIT-Inc-HP-TrueVision-HD-Camera -S unknown -M 0 (1) webcamd [-d ugen1.3] -N Realtek-802-11n-WLAN-Adapter -S 00e04c000001 -M 0
| 1 | 可用的网络摄像头 |
执行以下命令配置可用的网络摄像头:
# sysrc webcamd_0_flags="-d ugen0.2" (1)|
请注意,如果这是一个即插即用的 USB 摄像头,更改连接的 USB 端口将会改变 |
启动 webcamd[8] 服务,需要执行以下命令:
# service webcamd start输出应该类似于以下内容:
Starting webcamd. webcamd 1616 - - Attached to ugen0.2[0]
可以使用 multimedia/pwcview 来检查摄像头的正常工作。可以使用以下命令来执行 multimedia/pwcview :
% pwcview -f 30 -s vga然后,安装包 multimedia/pwcview[] 将显示网络摄像头:

9.5.2. 会议软件状态
FreeBSD 目前支持以下用于进行视频会议的工具。
| 名称 | Firefox 状态 | Chromium 状态 | 网站 |
|---|---|---|---|
微软团队 |
不起作用 |
工作 |
|
Google Meet 是一款由 Google 开发的在线视频会议工具。它允许用户通过互联网进行高清视频通话和实时屏幕共享。 Google Meet 可以用于个人和商业用途,支持多种设备和操作系统,包括计算机、手机和平板电脑。用户可以通过邀请链接或会议代码邀请他人参加会议,并可以在会议中进行文字聊天和文件共享。 Google Meet 还提供了一些高级功能,如会议录制和直播。 |
不起作用 |
工作 |
|
Zoom 是一种视频会议和在线沟通平台。它允许用户通过互联网进行高清视频和音频通话,以及实时屏幕共享和文件传输。 Zoom 在商业、教育和个人领域都得到了广泛应用,特别是在远程办公和远程学习方面。它提供了许多功能,如多人视频会议、聊天、虚拟背景等,使用户能够方便地进行远程协作和沟通。 |
工作 |
工作 |
链接: https://zoom.us |
Jitsi 是一个开源的视频会议和即时通讯平台。它提供了高质量的音视频通话、屏幕共享、文件传输等功能。 Jitsi 可以在多个平台上运行,包括 Windows 、 Mac 、 Linux 和移动设备。它还支持端到端加密,保护用户的通信安全。 Jitsi 易于使用和部署,可以用于个人使用、企业会议、在线教育等各种场景。 |
不起作用 |
工作 |
|
BigBlueButton 是一个开源的在线会议和协作平台。它提供了视频会议、音频通话、屏幕共享、聊天和白板等功能,适用于远程教育、在线培训和团队协作等场景。 BigBlueButton 支持多种操作系统和浏览器,并且可以与其他应用程序集成,如学习管理系统和视频流媒体服务器。它的设计目标是提供稳定、可靠和安全的在线会议体验。 |
不起作用 |
工作 |
9.6. 图像扫描仪
在 FreeBSD 中,可以通过 SANE (Scanner Access Now Easy) 来访问图像扫描仪,该软件可在 FreeBSD Ports Collection 中获取。
9.6.1. 检查扫描仪
在尝试任何配置之前,重要的是要检查扫描仪是否受到 SANE 的支持。
连接上扫描仪后,运行以下命令以获取所有连接的 USB 设备:
# usbconfig list输出应该类似于以下内容:
ugen4.2: <LITE-ON Technology USB NetVista Full Width Keyboard.> at usbus4, cfg=0 md=HOST spd=LOW (1.5Mbps) pwr=ON (70mA) ugen4.3: <Logitech USB Optical Mouse> at usbus4, cfg=0 md=HOST spd=LOW (1.5Mbps) pwr=ON (100mA) ugen3.2: <HP Deskjet 1050 J410 series> at usbus3, cfg=0 md=HOST spd=HIGH (480Mbps) pwr=ON (2mA)
运行以下命令以获取 idVendor 和 idProduct :
# usbconfig -d 3.2 dump_device_desc|
请注意,扫描仪是一种即插即用设备,更改连接的 USB 端口将会改变 |
输出应该类似于以下内容:
ugen3.2: <HP Deskjet 1050 J410 series> at usbus3, cfg=0 md=HOST spd=HIGH (480Mbps) pwr=ON (2mA) bLength = 0x0012 bDescriptorType = 0x0001 bcdUSB = 0x0200 bDeviceClass = 0x0000 <Probed by interface class> bDeviceSubClass = 0x0000 bDeviceProtocol = 0x0000 bMaxPacketSize0 = 0x0040 idVendor = 0x03f0 idProduct = 0x8911 bcdDevice = 0x0100 iManufacturer = 0x0001 <HP> iProduct = 0x0002 <Deskjet 1050 J410 series> bNumConfigurations = 0x0001
一旦获得了 idVendor 和 idProduct ,就需要在链接: SANE 支持设备列表 中检查扫描仪是否受支持,通过按照 idProduct 进行过滤。
9.6.2. SANE 配置
SANE 通过后端提供对扫描仪的访问。要在 FreeBSD 上进行扫描,必须通过运行以下命令安装 graphics/sane-backends[] 软件包:
# pkg install sane-backends|
一些 USB 扫描仪需要加载固件。就像上面示例中使用的 HP 扫描仪一样,它需要安装 print/hplip 软件包。 |
安装必要的软件包后,必须配置 devd(8) 以允许 FreeBSD 访问扫描仪。
将 saned.conf 文件添加到 /usr/local/etc/devd/saned.conf ,内容如下:
notify 100 {
match "system" "USB";
match "subsystem" "INTERFACE";
match "type" "ATTACH";
match "cdev" "ugen[0-9].[0-9]";
match "vendor" "0x03f0"; (1)
match "product" "0x8911"; (2)
action "chown -L cups:saned /dev/\$cdev && chmod -L 660 /dev/\$cdev";
};
| 1 | vendor: 是之前通过运行 usbconfig -d 3.2 dump_device_desc 命令获取的 idVendor 。 <.> product: 是之前通过运行 usbconfig -d 3.2 dump_device_desc 命令获取的 idProduct 。 |
在那之后,必须通过运行以下命令来重新启动 devd(8) :
# service devd restartSANE 后端包括 scanimage(1) ,可用于列出设备并执行图像获取。
使用 -L 参数执行 scanimage(1) 命令以列出扫描设备:
# scanimage -L输出应该类似于以下内容:
device `hpaio:/usb/Deskjet_1050_J410_series?serial=XXXXXXXXXXXXXX' is a Hewlett-Packard Deskjet_1050_J410_series all-in-one
如果 scanimage(1) 无法识别扫描仪,将显示以下消息:
No scanners were identified. If you were expecting something different, check that the scanner is plugged in, turned on and detected by the sane-find-scanner tool (if appropriate). Please read the documentation which came with this software (README, FAQ, manpages).
一旦 scanimage(1) 检测到扫描仪,配置就完成了,扫描仪现在可以使用了。
要激活该服务并使其在启动时运行,请执行以下命令:
# sysrc saned_enable="YES"虽然可以使用 scanimage(1) 命令行工具来进行图像采集,但通常更倾向于使用图形界面来进行图像扫描。
| 名称 | 许可证 | Package |
|---|---|---|
skanlite |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
图形 / 扫描仪 |
GNOME 简易扫描 |
GPL 3.0 是 GNU 通用公共许可证的第 3.0 版。 |
图形 / 简单扫描 |
XSANE 是一个用于扫描仪的开源图像扫描软件。它允许用户通过计算机控制扫描仪,从而将纸质文档转换为数字图像。 XSANE 提供了丰富的功能,包括调整扫描设置、图像预览、图像编辑和保存等。它支持多种图像格式,并且可以与其他图像处理软件集成使用。 XSANE 是一个功能强大且易于使用的工具,适用于个人用户和专业用户。 |
GPL 2.0 是 GNU 通用公共许可证的第 2.0 版。 |
图形 /xsane |
Chapter 10. 配置 FreeBSD 内核
10.1. 简介
内核是 FreeBSD 操作系统的核心。它负责管理内存、执行安全控制、网络、磁盘访问等等。尽管 FreeBSD 的许多部分是动态可配置的,但有时仍然需要配置和编译自定义内核。
阅读完本章后,您将了解:
-
何时构建自定义内核。
-
如何进行硬件清查。
-
如何自定义内核配置文件。
-
如何使用内核配置文件创建和构建新内核。
-
如何安装新内核。
-
如果出现问题,如何进行故障排除。
本章中示例中列出的所有命令都应以 root 用户身份执行。
10.2. 为什么要构建自定义内核?
传统上,FreeBSD 使用的是一个单内核。内核是一个庞大的程序,支持一组固定的设备,并且要改变内核的行为,需要编译并重新启动到一个新的内核。
如今,FreeBSD 内核中的大部分功能都包含在模块中,这些模块可以根据需要动态加载和卸载。这使得运行中的内核能够立即适应新的硬件,并将新的功能引入内核中。这被称为模块化内核。
偶尔,仍然有必要进行静态内核配置。有时所需功能与内核紧密相关,无法以动态加载的方式实现。某些安全环境禁止加载和卸载内核模块,并要求只将所需功能静态编译到内核中。
对于高级 BSD 用户来说,构建自定义内核通常是一种成年礼。尽管这个过程耗时,但可以为 FreeBSD 系统带来好处。与必须支持各种硬件的 GENERIC 内核不同,自定义内核可以精简为仅提供对该计算机硬件的支持。这有许多好处,例如:
-
更快的启动时间。由于内核只会探测系统上的硬件,系统启动所需的时间可以减少。
-
较低的内存使用量。自定义内核通常通过省略未使用的功能和设备驱动程序来使用较少的内存,相比于 GENERIC 内核。这很重要,因为内核代码始终驻留在物理内存中,防止该内存被应用程序使用。因此,在内存较小的系统上使用自定义内核非常有用。
-
额外的硬件支持。自定义内核可以为 GENERIC 内核中不存在的设备添加支持。
在构建自定义内核之前,请考虑进行此操作的原因。如果需要特定的硬件支持,可能已经存在相应的模块。
内核模块存在于 /boot/kernel 目录中,并且可以使用 kldload(8) 命令动态加载到运行中的内核中。大多数内核驱动程序都有可加载的模块和手册页。例如,ath(4) 无线网络驱动程序在其手册页中包含以下信息:
Alternatively, to load the driver as a module at boot time, place the
following line in loader.conf(5):
if_ath_load="YES"在 /boot/loader.conf 中添加 if_ath_load ="YES" 将会在启动时动态加载该模块。
在某些情况下,/boot/kernel 中没有关联的模块。这在某些子系统中是普遍存在的。
10.3. 查找系统硬件
在编辑内核配置文件之前,建议先对机器的硬件进行清查。在双启动系统上,可以从其他操作系统中创建清单。例如,Microsoft® 的设备管理器包含有关已安装设备的信息。
|
一些 Microsoft® Windows® 的版本中有一个系统图标,可以用来访问设备管理器。 |
如果 FreeBSD 是唯一安装的操作系统,请使用 dmesg(8) 命令来确定在启动探测期间找到和列出的硬件。FreeBSD 上的大多数设备驱动程序都有一个手册页面,列出了该驱动程序支持的硬件。例如,以下行表示 psm(4) 驱动程序找到了一个鼠标:
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: [GIANT-LOCKED]
psm0: [ITHREAD]
psm0: model Generic PS/2 mouse, device ID 0由于存在这个硬件,这个驱动程序不应从自定义内核配置文件中删除。
如果 dmesg 命令的输出没有显示引导探测的结果,可以读取文件 /var/run/dmesg.boot 的内容。
另一个用于查找硬件的工具是 pciconf(8),它提供更详细的输出。例如:
% pciconf -lv
ath0@pci0:3:0:0: class=0x020000 card=0x058a1014 chip=0x1014168c rev=0x01 hdr=0x00
vendor = 'Atheros Communications Inc.'
device = 'AR5212 Atheros AR5212 802.11abg wireless'
class = network
subclass = ethernet这个输出显示 ath 驱动程序找到了一个无线以太网设备。
man(1) 的 -k 标志可以用来提供有用的信息。例如,它可以用来显示包含特定设备品牌或名称的手册页面列表:
# man -k Atheros
ath(4) - Atheros IEEE 802.11 wireless network driver
ath_hal(4) - Atheros Hardware Access Layer (HAL)创建硬件清单后,参考该清单以确保在编辑自定义内核配置时不要删除已安装硬件的驱动程序。
10.4. 配置文件
为了创建一个自定义的内核配置文件并构建一个自定义的内核,首先必须安装完整的 FreeBSD 源代码树。
如果 /usr/src/ 不存在或为空,则表示源代码未安装。可以使用 Git 安装源代码,具体操作请参考 “使用 Git” 。
安装完成后,请查看 /usr/src/sys 目录的内容。该目录包含许多子目录,其中包括以下支持的架构:amd64,i386,powerpc 和 sparc64。特定架构目录中的所有内容仅与该架构相关,而其余代码是适用于所有平台的机器无关代码。每个支持的架构都有一个 conf 子目录,其中包含该架构的 GENERIC 内核配置文件。
不要对 GENERIC 进行编辑。相反,将文件复制到另一个名称并对副本进行编辑。惯例是使用全大写字母的名称。当维护具有不同硬件的多个 FreeBSD 机器时,最好使用机器的主机名来命名。此示例创建了一个名为 MYKERNEL 的副本,用于 amd64 架构的 GENERIC 配置文件。
# cd /usr/src/sys/amd64/conf
# cp GENERIC MYKERNELMYKERNEL 现在可以使用任何 ASCII 文本编辑器进行自定义。默认编辑器是 vi,尽管 FreeBSD 还安装了一个更适合初学者的简化编辑器,名为 ee 。
内核配置文件的格式很简单。每一行包含一个关键字,代表一个设备或子系统,一个参数和一个简短的描述。在 # 之后的任何文本都被视为注释并被忽略。要移除对设备或子系统的内核支持,请在表示该设备或子系统的行的开头加上 # 。对于任何你不理解的行,请不要添加或删除 #。
|
删除设备或选项的支持并最终导致内核损坏是很容易的。例如,如果从内核配置文件中删除了 ata(4) 驱动程序,使用 |
除了本文件中提供的简要描述外,其他描述还包含在与该架构的 GENERIC 文件位于同一目录中的 NOTES 文件中。对于与架构无关的选项,请参考 /usr/src/sys/conf/NOTES 。
|
在完成自定义内核配置文件后,将备份副本保存到位于 /usr/src 之外的位置。 或者,将内核配置文件保存在其他位置,并创建一个符号链接指向该文件: |
配置文件中可以使用 include 指令。这允许将另一个配置文件包含在当前文件中,从而方便地对现有文件进行小的修改。如果只需要少量的额外选项或驱动程序,这样可以相对于 GENERIC 保持增量,如下面的示例所示:
include GENERIC ident MYKERNEL options IPFIREWALL options DUMMYNET options IPFIREWALL_DEFAULT_TO_ACCEPT options IPDIVERT
使用这种方法,本地配置文件表达了与 GENERIC 内核的本地差异。随着升级的进行,添加到 GENERIC 的新功能也将添加到本地内核中,除非使用 nooptions 或 nodevice 明确禁止它们。有关配置指令及其描述的详细列表,请参阅 config(5) 。
|
要构建一个包含所有可用选项的文件,请以 |
10.5. 构建和安装自定义内核
一旦自定义配置文件的编辑保存完毕,可以按照以下步骤编译内核的源代码:
过程:构建内核
-
切换到这个目录:
# cd /usr/src -
通过指定自定义内核配置文件的名称来编译新的内核:
# make buildkernel KERNCONF=MYKERNEL -
安装与指定的内核配置文件相关联的新内核。此命令将新内核复制到 /boot/kernel/kernel 并将旧内核保存到 /boot/kernel.old/kernel 。
# make installkernel KERNCONF=MYKERNEL -
关闭系统并重新启动到新内核。如果出现问题,请参考 内核无法启动。
默认情况下,当编译自定义内核时,所有内核模块都会重新构建。为了更快地更新内核或仅构建自定义模块,在开始构建内核之前,请编辑 /etc/make.conf 文件。
例如,这个变量指定了要构建的模块列表,而不是使用默认的构建所有模块。
MODULES_OVERRIDE = linux acpi
另外,这个变量列出了在构建过程中要排除的模块。
WITHOUT_MODULES = linux acpi sound
还有其他可用的变量。有关详细信息,请参阅 make.conf(5) 。
10.6. 如果出现问题
构建自定义内核时可能出现的四种故障类别有:
config失败-
如果
config失败,它将打印出错误的行号。例如,对于以下消息,请通过将其与 GENERIC 或 NOTES 进行比较,确保第 17 行的输入正确。config: line 17: syntax error make失败-
如果
make失败,通常是由于内核配置文件中的错误,这种错误不严重到足以被config捕获。请检查配置,如果问题不明显,请发送一封包含内核配置文件的电子邮件到 FreeBSD general questions mailing list。
- 内核无法启动
-
如果新内核无法启动或无法识别设备,请不要惊慌!幸运的是,FreeBSD 有一个出色的机制可以从不兼容的内核中恢复。只需在 FreeBSD 引导加载程序中选择要引导的内核即可。当系统启动菜单出现时,可以通过选择“进入加载程序提示符(Escape to a loader prompt)”选项来访问它。在提示符下,输入
boot kernel.old,或者任何其他已知可以正确引导的内核的名称。在使用良好的内核启动后,检查配置文件并尝试重新构建。一个有用的资源是 /var/log/messages 文件,它记录了每次成功启动时的内核消息。此外,dmesg(8) 命令将打印当前启动的内核消息。
在排除内核问题时,请确保保留一个已知可正常工作的内核副本,例如 GENERIC。这很重要,因为每次安装新内核时, kernel.old 都会被上一个安装的内核覆盖,该内核可能无法启动。尽快将工作正常的内核移动,通过重命名包含良好内核的目录。
# mv /boot/kernel /boot/kernel.bad # mv /boot/kernel.good /boot/kernel - 内核工作正常,但是 ps(1) 命令不起作用。
-
如果内核版本与系统实用程序构建的版本不同,例如,在 -RELEASE 系统上安装了从 -CURRENT 源构建的内核,那么许多系统状态命令(如 ps(1) 和 vmstat(8))将无法工作。为了解决这个问题,应该使用与内核相同版本的源代码树重新编译和安装整个系统。在操作系统中使用与其余部分不同版本的内核从来都不是一个好主意。
Chapter 11. 打印
将信息记录在纸上是一项重要的功能,尽管有许多试图消除它的尝试。打印有两个基本组成部分。数据必须传递给打印机,并且必须以打印机能够理解的形式呈现。
11.1. 快速入门
基本的打印设置可以很快完成。打印机必须能够打印纯文本的 ASCII 字符。如需打印其他类型的文件,请参阅 过滤器 。
11.2. 打印机连接
打印机可以通过多种方式连接到计算机系统。小型台式打印机通常直接连接到计算机的 USB 端口。旧式打印机则连接到并行或“打印机”端口。有些打印机直接连接到网络,方便多台计算机共享使用。少数打印机使用罕见的串行端口连接。
FreeBSD 可以与所有这些类型的打印机进行通信。
USB是一种通用串行总线( Universal Serial Bus )的缩写,它是一种用于连接计算机和外部设备的标准接口。 USB 接口可以用于连接各种设备,包括打印机、键盘、鼠标、摄像头、移动存储设备等。 USB 接口具有热插拔功能,可以在计算机运行时插入或拔出设备,而无需重新启动计算机。 USB 接口还可以提供电力供应,使连接的设备可以通过 USB 接口获得电力。 USB 接口有多个版本,包括 USB 1.0 、 USB 2.0 、 USB 3.0 和 USB 4.0 ,每个版本都有不同的传输速度和功能。-
USB 打印机可以连接到计算机上的任何可用的 USB 端口。
当 FreeBSD 检测到一个
USB打印机时,会创建两个设备条目: /dev/ulpt0 和 /dev/unlpt0 。发送到任何一个设备的数据都会传递给打印机。在每个打印作业之后, ulpt0 会重置USB端口。重置端口可能会导致一些打印机出现问题,所以通常使用 unlpt0 设备代替。 unlpt0 根本不会重置 USB 端口。
- 并行( IEEE-1284 )
-
并行端口设备是 [/dev/lpt0] 。无论是否连接打印机,该设备都会出现,不会自动检测。
供应商们大多已经放弃了这些“传统”端口,许多计算机不再配备这些端口。可以使用适配器将并行打印机连接到
USB端口。通过这样的适配器,打印机可以被视为实际上是一台USB打印机。还可以使用称为“打印服务器”的设备将并行打印机直接连接到网络。
- 串行( RS-232 )
-
串口是另一种遗留端口,在某些特定的利基应用中除外,很少用于打印机。电缆、连接器和所需的布线各不相同。
对于集成在主板上的串口,串口设备名称是 [/dev/cuau0] 或 [/dev/cuau1] 。串口 USB 适配器也可以使用,它们将显示为 [/dev/cuaU0] 。
与串行打印机通信需要了解几个通信参数。其中最重要的是波特率( Baud Rate )或 BPS (每秒比特数)和奇偶校验( Parity )。具体数值可能有所不同,但典型的串行打印机使用波特率为 9600 ,无奇偶校验。
- 网络
-
网络打印机直接连接到本地计算机网络。
必须知道打印机的
DNS主机名。如果打印机通过DHCP分配动态地址,则应动态更新DNS,以便主机名始终具有正确的IP地址。为了避免这个问题,通常给网络打印机分配静态IP地址。大多数网络打印机都能理解使用 LPD 协议发送的打印作业。还可以指定打印队列名称。根据使用的队列不同,一些打印机会以不同的方式处理数据。例如,
raw队列会原样打印数据,而text队列会在纯文本中添加回车符。许多网络打印机还可以打印直接发送到端口 9100 的数据。
11.3. 常见的页面描述语言
发送给打印机的数据必须使用打印机能够理解的语言。这些语言被称为页面描述语言( Page Description Languages ,简称 PDLs )。
ASCII是一种用于表示文本字符的编码标准。它使用 7 位二进制数来表示 128 个字符,包括英文字母、数字、标点符号和一些特殊字符。 ASCII 编码是计算机系统中最常用的字符编码之一,它使得不同计算机之间可以互相交换和处理文本数据。-
纯文本是将数据发送到打印机的最简单方式。字符与将要打印的内容一一对应:数据中的一个“ A ”会在页面上打印出一个“ A ”。几乎没有可用的格式设置。无法选择字体或比例间距。纯文本的强制简洁性意味着文本可以直接从计算机打印,几乎不需要编码或翻译。打印输出与发送的内容直接对应。
一些廉价的打印机无法打印纯文本的
ASCII字符。这使得它们更难设置,但通常仍然是可能的。
- PostScript ( R )
-
PostScript® 几乎是
ASCII的反义词。与简单的文本不同, PostScript® 程序是一组绘制最终文档的指令。可以使用不同的字体和图形。然而,这种强大的功能是有代价的。绘制页面的程序必须编写。通常,这个程序是由应用软件生成的,所以对用户来说是不可见的。为了节省成本,廉价打印机有时会省略 PostScript® 兼容性。
PCL(打印机命令语言)-
PCL是ASCII的扩展,添加了用于格式化、字体选择和打印图形的转义序列。许多打印机支持PCL5。一些支持更新的PCL6或PCLXL。这些较新的版本是PCL5的超集,可以提供更快的打印速度。
- 基于主机的
-
制造商可以通过给打印机配备简单的处理器和很少的内存来降低成本。这些打印机无法打印纯文本。相反,文本和图形的位图由主机计算机上的驱动程序绘制,然后发送到打印机。这些被称为“基于主机”的打印机。
驱动程序与基于主机的打印机之间的通信通常通过专有或未记录的协议进行,这使它们只能在最常见的操作系统上运行。
11.3.1. 将 PostScript® 转换为其他 PDLs
Ports Collection 中的许多应用程序和 FreeBSD 实用程序会生成 PostScript® 输出。下表显示了可用于将其转换为其他常见 PDL 的实用程序:
| 输出 PDL | 生成者: | 注释 |
|---|---|---|
|
包: print/ghostscript9-base[] |
|
|
包: print/ghostscript9-base[] |
|
|
包: print/ghostscript9-base[] |
|
|
包: print/foo2zjs[] |
11.3.2. 摘要
为了实现最简单的打印,选择支持 PostScript® 的打印机是最好的选择。其次是支持 PCL 的打印机。使用 print/ghostscript9-base 软件包,这些打印机可以像本地支持 PostScript® 一样使用。几乎所有直接支持 PostScript® 或 PCL 的打印机也支持直接打印纯 ASCII 文本文件。
像典型的喷墨打印机一样,基于行的打印机通常不支持 PostScript® 或 PCL 。它们通常可以打印纯文本文件。 print/ghostscript9-base 支持一些这些打印机使用的页面描述语言( PDL )。然而,由于需要传输和打印的数据量很大,使用这些打印机打印整个基于图形的页面通常非常慢。
基于主机的打印机通常更难设置。由于专有的页面描述语言( PDL ),有些打印机根本无法使用。尽量避免使用这些打印机。
许多页面描述语言( PDL )的描述可以在 http://www.undocprint.org/formats/page_description_languages 找到。各种型号打印机使用的特定 PDL 可以在 http://www.openprinting.org/printers 找到。
11.4. 直接打印
对于偶尔打印的情况,可以直接将文件发送到打印机设备,无需进行任何设置。例如,可以将名为 sample.txt 的文件发送到一个 USB 打印机。
# cp sample.txt /dev/unlpt0直接打印到网络打印机取决于打印机的功能,但大多数打印机可以在端口 9100 上接受打印作业,可以使用 nc(1) 与它们一起使用。要将同一文件打印到名为_netlaser_的打印机上:
# nc netlaser 9100 < sample.txt11.5. LPD ( Line Printer Daemon )是一种用于打印机的网络协议。
在后台打印文件被称为“spooling”。一个打印机缓冲程序允许用户在打印作业慢慢完成的过程中继续使用计算机上的其他程序,而无需等待打印机完成。
11.5.1. 初始设置
创建了一个用于存储打印作业的目录,设置了所有权,并设置了权限,以防止其他用户查看这些文件的内容:
# mkdir -p /var/spool/lpd/lp
# chown daemon:daemon /var/spool/lpd/lp
# chmod 770 /var/spool/lpd/lp打印机在 /etc/printcap 中定义。每个打印机的条目包括名称、连接端口和其他各种设置。使用以下内容创建 /etc/printcap 文件:
lp:\ (1) :lp=/dev/unlpt0:\ (2) :sh:\ (3) :mx#0:\ (4) :sd=/var/spool/lpd/lp:\ (5) :lf=/var/log/lpd-errs: (6)
| 1 | 这台打印机的名称。 lpr(1) 命令将打印作业发送到 lp 打印机,除非使用 -P 指定了其他打印机,因此默认打印机应该被命名为 lp 。 |
| 2 | 打印机连接的设备。将此行替换为适用于此处显示的连接类型的正确行。 |
| 3 | 在打印作业开始时禁止打印页眉。 |
| 4 | 不要限制打印作业的最大大小。 |
| 5 | 这台打印机的排队目录路径。每台打印机都使用自己的排队目录。 |
| 6 | 这台打印机报告错误的日志文件。 |
创建 /etc/printcap 后,使用 chkprintcap(8) 来测试是否存在错误:
# chkprintcap在继续之前,请修复所有报告的问题。
在 /etc/rc.conf 文件中启用 lpd(8) 。
lpd_enable="YES"
启动服务:
# service lpd start11.5.2. 使用 lpr(1) 打印
使用 lpr 命令将文档发送到打印机。要打印的文件可以在命令行上指定名称,也可以通过管道传递给 lpr 。以下两个命令是等效的,将 doc.txt 的内容发送到默认打印机:
% lpr doc.txt
% cat doc.txt | lpr可以使用 -P 选项选择打印机。要打印到名为_laser_的打印机:
% lpr -Plaser doc.txt11.5.3. 过滤器
到目前为止展示的示例已经直接将文本文件的内容发送到打印机。只要打印机能理解这些文件的内容,输出就会正确打印。
有些打印机无法打印纯文本,而输入文件甚至可能不是纯文本。
过滤器 允许文件进行翻译或处理。典型的用法是将一种类型的输入(如纯文本)转换为打印机可以理解的形式,如 PostScript® 或 PCL 。过滤器还可以用于提供额外的功能,如添加页码或突出显示源代码以便更容易阅读。
这里讨论的过滤器是“输入过滤器”或“文本过滤器”。这些过滤器将输入的文件转换为不同的形式。在创建文件之前,使用 su(1) 命令切换为“ root ”用户。
过滤器在 /etc/printcap 中使用 `if = ` 标识符进行指定。要使用 /usr/local/libexec/lf2crlf 作为过滤器,修改 /etc/printcap 如下:
lp:\ :lp=/dev/unlpt0:\ :sh:\ :mx#0:\ :sd=/var/spool/lpd/lp:\ :if=/usr/local/libexec/lf2crlf:\ (1) :lf=/var/log/lpd-errs:
| 1 | `if = ` 标识了将用于处理传入文本的 输入过滤器。 |
|
在 printcap 条目的行尾处使用反斜杠 line continuation 字符,揭示了打印机条目实际上只是一行长字符串,其中条目由冒号字符分隔。一个早期的示例可以重写为一行不易读的字符串: lp:lp=/dev/unlpt0:sh:mx#0:sd=/var/spool/lpd/lp:if=/usr/local/libexec/lf2crlf:lf=/var/log/lpd-errs: |
11.5.3.1. 防止普通文本打印机上的阶梯状输出
典型的 FreeBSD 文本文件每行末尾只包含一个换行符。这些行在标准打印机上会呈“阶梯状”排列:
A printed file looks
like the steps of a staircase
scattered by the wind
一个过滤器可以将换行符转换为回车和换行符。回车使打印机在每行结束后返回到左侧。创建名为 /usr/local/libexec/lf2crlf 的文件,并将以下内容写入该文件:
#!/bin/sh
CR=$'\r'
/usr/bin/sed -e "s/$/${CR}/g"
设置权限并使其可执行:
# chmod 555 /usr/local/libexec/lf2crlf将 /etc/printcap 修改为使用新的过滤器:
:if=/usr/local/libexec/lf2crlf:\
通过打印相同的纯文本文件来测试过滤器。回车符将导致每行从页面的左侧开始。
11.5.3.2. 使用 print/enscript 在 PostScript® 打印机上打印时,可以得到漂亮的纯文本输出。
GNUEnscript 将纯文本文件转换为适合在 PostScript 打印机上打印的格式良好的 PostScript 文件。它添加页码,换行长行,并提供许多其他功能,使打印的文本文件更易于阅读。根据本地纸张尺寸,从 Ports Collection 安装 print/enscript-letter 或 print/enscript-a4 。
创建 /usr/local/libexec/enscript 文件,并使用以下内容:
#!/bin/sh /usr/local/bin/enscript -o -
设置权限并使其可执行:
# chmod 555 /usr/local/libexec/enscript将 /etc/printcap 修改为使用新的过滤器:
:if=/usr/local/libexec/enscript:\
通过打印一个纯文本文件来测试过滤器。
11.5.3.3. 将 PostScript® 打印到 PCL 打印机
许多程序生成 PostScript® 文档。然而,廉价打印机通常只能理解纯文本或 PCL 格式。该过滤器将 PostScript® 文件转换为 PCL 格式,然后发送给打印机。
从 Ports Collection 安装 Ghostscript PostScript® 解释器,包名为: print/ghostscript9-base[] 。
创建 /usr/local/libexec/ps2pcl 文件,并使用以下内容:
#!/bin/sh /usr/local/bin/gs -dSAFER -dNOPAUSE -dBATCH -q -sDEVICE=ljet4 -sOutputFile=- -
设置权限并使其可执行:
# chmod 555 /usr/local/libexec/ps2pcl将发送给此脚本的 PostScript® 输入将在发送到打印机之前被渲染并转换为 PCL 格式。
将 /etc/printcap 修改为使用这个新的输入过滤器:
:if=/usr/local/libexec/ps2pcl:\
通过向过滤器发送一个小的 PostScript® 程序来测试过滤器:
% printf "%%\!PS \n /Helvetica findfont 18 scalefont setfont \
72 432 moveto (PostScript printing successful.) show showpage \004" | lpr11.5.3.4. 智能过滤器
一个能够检测输入类型并自动将其转换为打印机正确格式的过滤器非常方便。 PostScript® 文件的前两个字符通常是 % ! ` 。过滤器可以检测到这两个字符。 PostScript® 文件可以直接发送到 PostScript® 打印机进行打印。文本文件可以使用之前展示的 Enscript 工具转换为 PostScript® 格式。请创建一个名为 `/usr/local/libexec/psif 的文件,并将以下内容添加到其中:
#!/bin/sh
#
# psif - Print PostScript or plain text on a PostScript printer
#
IFS="" read -r first_line
first_two_chars=`expr "$first_line" : '\(..\)'`
case "$first_two_chars" in
%!)
# %! : PostScript job, print it.
echo "$first_line" && cat && exit 0
exit 2
;;
*)
# otherwise, format with enscript
( echo "$first_line"; cat ) | /usr/local/bin/enscript -o - && exit 0
exit 2
;;
esac
设置权限并使其可执行:
# chmod 555 /usr/local/libexec/psif将 /etc/printcap 修改为使用这个新的输入过滤器:
:if=/usr/local/libexec/psif:\
通过打印 PostScript® 和纯文本文件来测试过滤器。
11.5.3.5. 其他智能过滤器
编写一个能够检测多种不同类型输入并正确格式化的过滤器是具有挑战性的。 Ports Collection 中的 print/apsfilter 是一个智能的“魔法”过滤器,它可以检测数十种文件类型,并自动将它们转换为打印机理解的 PDL 格式。更多详情请参考 http://www.apsfilter.org 。
11.5.4. 多个队列
/etc/printcap 中的条目实际上是对_队列_的定义。一个打印机可以有多个队列。与过滤器结合使用时,多个队列可以使用户更好地控制他们的作业如何打印。
以一个办公室中的网络化 PostScript® 激光打印机为例。大多数用户希望打印纯文本,但是少数高级用户希望能够直接打印 PostScript® 文件。可以在 [/etc/printcap] 中为同一台打印机创建两个条目:
textprinter:\ :lp=9100@officelaser:\ :sh:\ :mx#0:\ :sd=/var/spool/lpd/textprinter:\ :if=/usr/local/libexec/enscript:\ :lf=/var/log/lpd-errs: psprinter:\ :lp=9100@officelaser:\ :sh:\ :mx#0:\ :sd=/var/spool/lpd/psprinter:\ :lf=/var/log/lpd-errs:
发送给 textprinter 的文档将由之前示例中显示的 /usr/local/libexec/enscript 过滤器进行格式化。高级用户可以在 psprinter 上打印 PostScript® 文件,不进行任何过滤。
这种多队列技术可以用来提供对各种打印机功能的直接访问。具有双面打印功能的打印机可以使用两个队列,一个用于普通的单面打印,另一个使用过滤器发送命令序列以启用双面打印,然后发送传入的文件。
11.5.5. 监控和控制打印
有几种实用工具可用于监控打印作业、检查和控制打印机操作。
11.5.5.1. lpq(1) 是一个命令,用于查看打印队列的状态。
lpq(1) 显示用户打印作业的状态。不显示其他用户的打印作业。
显示当前用户在单个打印机上的待处理作业。
% lpq -Plp
Rank Owner Job Files Total Size
1st jsmith 0 (standard input) 12792 bytes显示当前用户在所有打印机上的待处理作业。
% lpq -a
lp:
Rank Owner Job Files Total Size
1st jsmith 1 (standard input) 27320 bytes
laser:
Rank Owner Job Files Total Size
1st jsmith 287 (standard input) 22443 bytes11.5.5.2. lprm(1)
lprm(1) 用于删除打印作业。普通用户只能删除自己的作业。 root 可以删除任何或所有作业。
从打印机中删除所有待处理作业。
# lprm -Plp -
dfA002smithy dequeued
cfA002smithy dequeued
dfA003smithy dequeued
cfA003smithy dequeued
dfA004smithy dequeued
cfA004smithy dequeued从打印机中删除一个作业。使用 lpq(1) 命令查找作业编号。
% lpq
Rank Owner Job Files Total Size
1st jsmith 5 (standard input) 12188 bytes
% lprm -Plp 5
dfA005smithy dequeued
cfA005smithy dequeued11.5.5.3. lpc(8)
lpc(8) 用于检查和修改打印机的状态。 lpc 后面跟着一个命令和一个可选的打印机名称。可以使用 all 代替特定的打印机名称,命令将应用于所有打印机。普通用户可以使用 lpc(8) 查看状态。只有 root 用户可以使用修改打印机状态的命令。
显示所有打印机的状态:
% lpc status all
lp:
queuing is enabled
printing is enabled
1 entry in spool area
printer idle
laser:
queuing is enabled
printing is enabled
1 entry in spool area
waiting for laser to come up阻止打印机接受新的任务,然后再次开始接受新的任务:
# lpc disable lp
lp:
queuing disabled
# lpc enable lp
lp:
queuing enabled停止打印,但继续接受新的任务。然后再次开始打印:
# lpc stop lp
lp:
printing disabled
# lpc start lp
lp:
printing enabled
daemon started在发生错误情况后重新启动打印机:
# lpc restart lp
lp:
no daemon to abort
printing enabled
daemon restarted关闭打印队列并禁用打印功能,并附带一条消息向用户解释问题原因:
# lpc down lp Repair parts will arrive on Monday
lp:
printer and queuing disabled
status message is now: Repair parts will arrive on Monday重新启用处于离线状态的打印机:
# lpc up lp
lp:
printing enabled
daemon started更多的命令和选项请参考 lpc(8) 。
11.5.6. 共享打印机
打印机在企业和学校中通常由多个用户共享。为了更方便地共享打印机,还提供了额外的功能。
11.5.6.1. 别名
打印机名称设置在 [/etc/printcap] 文件的第一行中。在该名称之后可以添加其他名称,也称为“别名”。别名之间和与名称之间用竖线分隔:
lp|repairsprinter|salesprinter:\
别名可以用来替代打印机名称。例如,销售部门的用户可以使用别名来打印到他们的打印机。
% lpr -Psalesprinter sales-report.txt维修部门的用户使用他们自己的打印机进行打印。
% lpr -Prepairsprinter repairs-report.txt所有的文件都打印在同一台打印机上。当销售部门发展到需要自己的打印机时,可以从共享打印机条目中删除别名,并将其用作新打印机的名称。两个部门的用户继续使用相同的命令,但销售文件将被发送到新的打印机。
11.5.6.2. 页眉页
对于用户来说,在繁忙的共享打印机产生的一堆页面中定位他们的文档可能很困难。为了解决这个问题,创建了“页眉页”。在每个打印作业之前,会打印一个包含用户姓名和文档名称的页眉页。这些页面有时也被称为“横幅”或“分隔符”页面。
启用页眉页面的方法取决于打印机是通过 USB 、并行或串行电缆直接连接到计算机,还是通过网络远程连接。
直接连接的打印机上的页眉页面可以通过从 /etc/printcap 文件中的条目中删除 :sh: \ ` ( Suppress Header )行来启用。这些页眉页面只使用换行字符作为换行符。一些打印机需要 /usr/share/examples/printing/hpif 过滤器来防止文本出现阶梯状。该过滤器配置 `PCL 打印机在接收到换行符时同时打印回车和换行符。
网络打印机的页眉页面必须在打印机本身上进行配置。 /etc/printcap 中的页眉页面条目将被忽略。通常可以通过打印机前面板或使用 Web 浏览器访问的配置网页来进行设置。
11.6. 其他打印系统
除了内置的 lpd(8) 之外,还有几个其他的打印系统可供选择。这些系统提供对其他协议或附加功能的支持。
11.6.1. CUPS ( Common UNIX® Printing System )
CUPS 是一个在许多操作系统上可用的流行打印系统。在 FreeBSD 上使用 CUPS 的方法在一个单独的文章中有详细说明: CUPS
11.6.2. HPLIP 是一种用于 Linux 操作系统的开源打印机和扫描仪驱动程序。它提供了与 HP 打印机和扫描仪的通信接口,使用户能够轻松地配置和使用这些设备。 HPLIP 支持各种 HP 打印机和扫描仪的功能,包括打印、扫描、复印和传真等。它还提供了一些额外的功能,如墨水和墨盒状态监测、打印机设置和网络打印等。 HPLIP 是一个非常有用的工具,可以帮助用户更好地管理和使用他们的 HP 打印机和扫描仪。
惠普公司提供了一个支持他们的喷墨和激光打印机的打印系统。该端口是 print/hplip 。主要网页位于 https://developers.hp.com/hp-linux-imaging-and-printing 。该端口在 FreeBSD 上处理所有安装细节。配置信息显示在 https://developers.hp.com/hp-linux-imaging-and-printing/install 。
11.6.3. LPRng 是一个用于打印管理的软件系统,它是 LPD ( Line Printer Daemon )的一个增强版本。 LPRng 提供了更多的功能和灵活性,可以在 UNIX 和类 UNIX 系统上运行。它支持多种打印机和打印队列,并提供了高级的打印作业控制和管理功能。 LPRng 还支持通过网络打印,并提供了安全性和权限控制机制。它是一个强大而可靠的打印管理解决方案。
LPRng 是作为 lpd(8) 的增强替代品开发的。该端口是 sysutils/LPRng 。有关详细信息和文档,请参阅 http://www.lprng.com/ 。
Chapter 12. Linux 二进制兼容性
12.1. 简介
FreeBSD 提供与 Linux® 的二进制兼容性,通常称为 Linuxulator,允许用户安装和运行未经修改的 Linux 二进制文件。它适用于 x86(32 位和 64 位)和 AArch64 架构。目前还不支持一些特定于 Linux 的操作系统功能,主要是与硬件相关或与系统管理相关的功能,例如 cgroups 或命名空间。
在阅读本章之前,你应该:
-
了解如何安装 其他第三方软件。
阅读完本章后,您将了解:
-
如何在 FreeBSD 系统上启用 Linux 二进制兼容性。
-
如何安装额外的 Linux 共享库。
-
如何在 FreeBSD 系统上安装 Linux 应用程序。
-
FreeBSD 中 Linux 兼容性的实现细节。
12.2. 配置 Linux 二进制兼容性
默认情况下,不启用 linux(4) 二进制兼容性。
要在启动时启用 Linux ABI,请执行以下命令:
# sysrc linux_enable="YES"
一旦启用,可以通过执行以下命令来启动,无需重新启动:
# service linux start这对于静态链接的 Linux 二进制文件来说已经足够了。
Linux 服务将加载 Linux 应用程序所需的内核模块并挂载文件系统,这些文件系统位于 /compat/linux 目录下。它们可以像本机 FreeBSD 二进制文件一样启动;它们的行为几乎与本机进程完全相同,并且可以按照通常的方式进行跟踪和调试。
可以通过执行以下命令来检查 /compat/linux 的当前内容:
# ls -l /compat/linux/输出应该类似于以下内容:
total 1 dr-xr-xr-x 13 root wheel 512 Apr 11 19:12 dev dr-xr-xr-x 1 root wheel 0 Apr 11 21:03 proc dr-xr-xr-x 1 root wheel 0 Apr 11 21:03 sys
12.3. Linux 用户空间
Linux 软件需要的不仅仅是一个 ABI 才能运行。为了运行 Linux 软件,首先必须安装 Linux 用户空间。
|
如果只是想运行已包含在 Ports 树中的一些软件,可以通过软件包管理器进行安装,并且 pkg(8) 将自动设置所需的 Linux 用户空间。 例如,要安装 Sublime Text 4 以及它所依赖的所有 Linux 库,请运行以下命令: |
12.3.1. 从 FreeBSD 软件包中获取的 CentOS 基本系统
要安装 CentOS 用户空间,请执行以下命令:
# pkg install linux_base-c7emulators/linux_base-c7 将基于 CentOS 7 的基本系统放置在 /compat/linux 中。
安装完软件包后,可以通过运行以下命令来验证 /compat/linux 的内容,以检查是否已安装 CentOS 用户空间:
# ls -l /compat/linux/输出应该类似于以下内容:
total 30 lrwxr-xr-x 1 root wheel 7 Apr 11 2018 bin -> usr/bin drwxr-xr-x 13 root wheel 512 Apr 11 21:10 dev drwxr-xr-x 25 root wheel 64 Apr 11 21:10 etc lrwxr-xr-x 1 root wheel 7 Apr 11 2018 lib -> usr/lib lrwxr-xr-x 1 root wheel 9 Apr 11 2018 lib64 -> usr/lib64 drwxr-xr-x 2 root wheel 2 Apr 11 21:10 opt dr-xr-xr-x 1 root wheel 0 Apr 11 21:25 proc lrwxr-xr-x 1 root wheel 8 Feb 18 02:10 run -> /var/run lrwxr-xr-x 1 root wheel 8 Apr 11 2018 sbin -> usr/sbin drwxr-xr-x 2 root wheel 2 Apr 11 21:10 srv dr-xr-xr-x 1 root wheel 0 Apr 11 21:25 sys drwxr-xr-x 8 root wheel 9 Apr 11 21:10 usr drwxr-xr-x 16 root wheel 17 Apr 11 21:10 var
12.3.2. 使用 debootstrap 创建 Debian/Ubuntu 基础系统
提供 Linux 共享库的另一种方式是使用 sysutils/debootstrap。这样做的优点是可以提供完整的 Debian 或 Ubuntu 发行版。
要安装 debootstrap,请执行以下命令:
# pkg install debootstrapdebootstrap(8) 需要启用 linux(4) ABI。启用后,执行以下命令在 /compat/ubuntu 中安装 Ubuntu 或 Debian :
# debootstrap focal /compat/ubuntu|
虽然从技术上讲可以安装到 /compat/linux 目录中,但由于可能与基于 CentOS 的软件包发生冲突,不建议这样做。相反,应根据发行版或版本名称派生目录名称,例如 /compat/ubuntu。 |
输出应该类似于以下内容:
I: Retrieving InRelease I: Checking Release signature I: Valid Release signature (key id F6ECB3762474EDA9D21B7022871920D1991BC93C) I: Retrieving Packages I: Validating Packages I: Resolving dependencies of required packages... I: Resolving dependencies of base packages... I: Checking component main on http://archive.ubuntu.com/ubuntu... [...] I: Configuring console-setup... I: Configuring kbd... I: Configuring ubuntu-minimal... I: Configuring libc-bin... I: Configuring ca-certificates... I: Base system installed successfully.
然后在 /etc/fstab 中设置挂载点。
|
如果要共享主目录的内容并且能够运行 X11 应用程序,应该使用 nullfs(5) 将 /home 和 /tmp 挂载到 Linux 兼容区域中,以实现回环。 以下示例可以添加到 /etc/fstab 文件中: # Device Mountpoint FStype Options Dump Pass# devfs /compat/ubuntu/dev devfs rw,late 0 0 tmpfs /compat/ubuntu/dev/shm tmpfs rw,late,size=1g,mode=1777 0 0 fdescfs /compat/ubuntu/dev/fd fdescfs rw,late,linrdlnk 0 0 linprocfs /compat/ubuntu/proc linprocfs rw,late 0 0 linsysfs /compat/ubuntu/sys linsysfs rw,late 0 0 /tmp /compat/ubuntu/tmp nullfs rw,late 0 0 /home /compat/ubuntu/home nullfs rw,late 0 0 然后执行 mount(8): |
要使用 chroot(8) 访问系统,请执行以下命令:
# chroot /compat/ubuntu /bin/bash然后可以执行 uname(1) 命令来检查 Linux 环境:
# uname -s -r -m输出应该类似于以下内容:
Linux 3.17.0 x86_64
一旦进入 chroot 环境,系统的行为就像在正常的 Ubuntu 安装中一样。虽然 systemd 不起作用,但 service(8) 命令仍然像往常一样工作。
|
要添加默认缺失的软件包仓库,请编辑文件 /compat/ubuntu/etc/apt/sources.list 。 对于 amd64 架构,可以使用以下示例: deb http://archive.ubuntu.com/ubuntu focal main universe restricted multiverse deb http://security.ubuntu.com/ubuntu/ focal-security universe multiverse restricted main deb http://archive.ubuntu.com/ubuntu focal-backports universe multiverse restricted main deb http://archive.ubuntu.com/ubuntu focal-updates universe multiverse restricted main 对于 arm64 架构,可以使用以下示例: deb http://ports.ubuntu.com/ubuntu-ports bionic main universe restricted multiverse |
12.4. 高级主题
有些应用程序需要挂载特定的文件系统。
这通常由 /etc/rc.d/linux 脚本处理,但可以通过执行以下命令在启动时禁用:
sysrc linux_mounts_enable="NO"
通过 rc 脚本挂载的文件系统在 chroots 或 jails 中的 Linux 进程中将无法工作;如果需要,在 /etc/fstab 中进行配置:
devfs /compat/linux/dev devfs rw,late 0 0 tmpfs /compat/linux/dev/shm tmpfs rw,late,size=1g,mode=1777 0 0 fdescfs /compat/linux/dev/fd fdescfs rw,late,linrdlnk 0 0 linprocfs /compat/linux/proc linprocfs rw,late 0 0 linsysfs /compat/linux/sys linsysfs rw,late 0 0
由于 Linux 二进制兼容层已经支持运行 32 位和 64 位 Linux 二进制文件,因此不再可能将仿真功能静态链接到自定义内核中。
12.4.1. 手动安装额外的库
|
对于使用 debootstrap(8) 创建的基本系统子目录,请使用上述说明。 |
如果在配置 Linux 二进制兼容性后,一个 Linux 应用程序抱怨缺少共享库,那么需要确定 Linux 二进制文件需要哪些共享库,并手动安装它们。
在使用相同的 CPU 架构的 Linux 系统上,可以使用 ldd 命令来确定应用程序需要哪些共享库。
例如,要检查 linuxdoom 需要哪些共享库,请从已安装 Doom 的 Linux 系统上运行以下命令:
% ldd linuxdoom输出应该类似于以下内容:
libXt.so.3 (DLL Jump 3.1) => /usr/X11/lib/libXt.so.3.1.0 libX11.so.3 (DLL Jump 3.1) => /usr/X11/lib/libX11.so.3.1.0 libc.so.4 (DLL Jump 4.5pl26) => /lib/libc.so.4.6.29
然后,将 Linux 系统输出的最后一列中的所有文件复制到 FreeBSD 系统的 /compat/linux 目录中。复制完成后,创建指向第一列中的文件名的符号链接。
这个例子将在 FreeBSD 系统上生成以下文件:
/compat/linux/usr/X11/lib/libXt.so.3.1.0 /compat/linux/usr/X11/lib/libXt.so.3 -> libXt.so.3.1.0 /compat/linux/usr/X11/lib/libX11.so.3.1.0 /compat/linux/usr/X11/lib/libX11.so.3 -> libX11.so.3.1.0 /compat/linux/lib/libc.so.4.6.29 /compat/linux/lib/libc.so.4 -> libc.so.4.6.29
如果在 ldd 输出的第一列中存在一个与 Linux 共享库的主要修订号匹配的库,则无需将其复制到最后一列中指定的文件中,因为现有库应该可以正常工作。但是,如果共享库是较新版本,则建议复制它。只要符号链接指向新的库,就可以删除旧的库。
例如,这些库已经存在于 FreeBSD 系统上:
/compat/linux/lib/libc.so.4.6.27 /compat/linux/lib/libc.so.4 -> libc.so.4.6.27
而 ldd 指示一个二进制文件需要一个较新的版本:
libc.so.4 (DLL Jump 4.5pl26) -> libc.so.4.6.29
由于现有的库只是在最后一位数字上过时了一到两个版本,所以程序应该仍然可以与稍旧的版本一起工作。然而,将现有的 libc.so 替换为更新的版本是安全的。
/compat/linux/lib/libc.so.4.6.29 /compat/linux/lib/libc.so.4 -> libc.so.4.6.29
通常情况下,在 FreeBSD 上首次安装 Linux 程序时,需要查找 Linux 二进制文件所依赖的共享库。然而,随着时间的推移,系统上会积累足够的 Linux 共享库,可以在安装新的 Linux 二进制文件时无需额外操作即可运行。
12.4.2. 标记 Linux ELF 可执行文件
FreeBSD 内核使用多种方法来确定要执行的二进制文件是否为 Linux 文件:它检查 ELF 文件头中的标记,查找已知的 ELF 解释器路径并检查 ELF 注释;最后,默认情况下,未标记的 ELF 可执行文件被认为是 Linux 文件。
如果所有这些方法都失败了,尝试执行二进制文件可能会导致错误消息:
% ./my-linux-elf-binary输出应该类似于以下内容:
ELF binary type not known Abort
为了帮助 FreeBSD 内核区分 FreeBSD ELF 二进制文件和 Linux 二进制文件,请使用 brandelf(1) 命令。
% brandelf -t Linux my-linux-elf-binary12.4.3. 安装基于 Linux RPM 的应用程序
要安装一个基于 Linux RPM 的应用程序,首先安装 archivers/rpm4 包或port。安装完成后,root 用户可以使用以下命令来安装 .rpm 文件:
# cd /compat/linux
# rpm2cpio < /path/to/linux.archive.rpm | cpio -id如果需要的话,对已安装的 ELF 二进制文件进行 brandelf 处理。请注意,这将阻止干净卸载。
12.4.4. 配置主机名解析器
如果 DNS 不工作或出现此错误:
resolv+: "bind" is an invalid keyword resolv+: "hosts" is an invalid keyword
将 /compat/linux/etc/host.conf 配置如下:
order hosts, bind multi on
这指定了首先搜索 /etc/hosts ,其次搜索 DNS。当 /compat/linux/etc/host.conf 不存在时,Linux 应用程序使用主机系统中的 /etc/host.conf,但它们会抱怨因为在 FreeBSD 中该文件不存在。如果没有配置名称服务器,请删除 bind,使用 /etc/resolv.conf。
12.4.5. 杂项
有关 Linux® 与二进制兼容性的更多信息,请参阅文章 FreeBSD 中的 Linux 模拟。
Chapter 13. WINE 是一个允许在 Linux 和其他类 Unix 操作系统上运行 Windows 应用程序的兼容层。它通过实现 Windows API 的替代实现来实现这一功能。 WINE 的名称是“ Wine Is Not an Emulator ”的缩写,这意味着它不是一个真正的模拟器,而是通过将 Windows API 调用转换为对底层操作系统的调用来实现兼容性。 WINE 对于那些需要在 Linux 环境中运行 Windows 应用程序的用户来说是非常有用的。
13.1. 简介
WINE ,全称为 Wine 不是模拟器,实际上是一种软件翻译层。它可以在 FreeBSD (和其他)系统上安装和运行一些为 Windows® 编写的软件。
它通过拦截系统调用或软件对操作系统的请求来运行,并将它们从 Windows® 调用转换为 FreeBSD 可以理解的调用。它还会根据需要将任何响应转换为 Windows® 软件所期望的格式。因此,在某种程度上,它模拟了 Windows® 环境,提供了许多 Windows® 应用程序所期望的资源。
然而,它并不是传统意义上的模拟器。许多解决方案通过使用软件进程构建一个完整的另一台计算机来运行。虚拟化(例如由 emulators/qemu 软件包提供的虚拟化)就是以这种方式运行的。这种方法的一个好处是能够在模拟器中安装完整版本的操作系统。这意味着对应用程序来说,环境看起来与真实机器没有任何区别,而且很有可能一切都能正常工作。这种方法的缺点是软件充当硬件的事实本质上比实际硬件慢。在软件中构建的计算机(称为“客户机”)需要来自真实机器(称为“主机”)的资源,并且在运行时会一直占用这些资源。
另一方面, WINE 项目对系统资源的消耗要小得多。它会实时翻译系统调用,因此虽然很难像真正的 Windows® 计算机一样快速,但它可以非常接近。另一方面, WINE 试图跟上不断变化的目标,以支持所有不同的系统调用和其他功能。因此,可能会有一些应用程序在 WINE 上无法按预期工作,根本无法工作,或者甚至无法安装。
在一天结束时, WINE 提供了另一种选择,可以尝试在 FreeBSD 上运行特定的 Windows® 软件程序。它始终可以作为第一选择,如果成功,可以提供良好的体验,而不会不必要地消耗主机 FreeBSD 系统的资源。
本章将描述:
-
在 FreeBSD 系统上安装 WINE 的方法。
-
WINE 是如何运作的,以及它与其他替代方案(如虚拟化)的区别。
-
如何根据特定应用程序的需求来调整 WINE 。
-
如何安装 WINE 的 GUI 助手。
-
FreeBSD 的常见提示和解决方案。
-
在多用户环境下,考虑在 FreeBSD 上使用 WINE 的问题。
在阅读本章之前,以下内容可能会有帮助:
-
了解如何交叉引用: bsdinstall[bsdinstall ,安装 FreeBSD] 。
-
了解如何交叉引用: advanced-networking[高级网络设置,建立网络连接] 。
-
了解如何交叉引用: ports[ports ,安装额外的第三方软件] 。
13.2. WINE 概述与概念
WINE 是一个复杂的系统,因此在在 FreeBSD 系统上运行之前,了解它是什么以及它是如何工作的是值得的。
13.2.1. WINE 是什么?
正如本章的 概述 中提到的, WINE 是一个兼容层,允许 Windows® 应用程序在其他操作系统上运行。理论上,这意味着这些程序应该可以在类似 FreeBSD 、 macOS 和 Android 的系统上运行。
当 WINE 运行 Windows® 可执行文件时,会发生两件事情:
-
首先, WINE 实现了一个模拟各个版本 Windows® 环境的环境。例如,如果一个应用程序请求访问诸如 RAM 之类的资源, WINE 有一个内存接口,它在应用程序看来看起来和行为都像 Windows® 。
-
然后,一旦该应用程序使用该接口, WINE 会将内存中的传入请求转换为与主机系统兼容的格式。同样,当应用程序检索数据时, WINE 会从主机系统中获取数据并将其传递回 Windows® 应用程序。
13.2.2. WINE 和 FreeBSD 系统
在 FreeBSD 系统上安装 WINE 将涉及几个不同的组件:
-
FreeBSD 提供了一些应用程序,用于运行 Windows® 可执行文件、配置 WINE 子系统或使用 WINE 支持编译程序的任务。
-
大量的库实现了 Windows® 的核心功能(例如 /lib/wine/api-ms-core-memory-l1-1-1.dll.so ,它是前述内存接口的一部分)。
-
一些 Windows® 可执行文件,它们是常见的实用工具(例如 /lib/wine/notepad.exe.so ,提供标准的 Windows® 文本编辑器)。
-
额外的 Windows® 资源,特别是字体(例如 Tahoma 字体,存储在安装根目录下的 .share/wine/fonts/tahoma.ttf 中)。
13.2.3. WINE 中的图形模式与文本模式 / 终端程序
作为一个将终端工具视为“一等公民”的操作系统,可以自然地假设 WINE 将包含对文本模式程序的广泛支持。然而,大多数 Windows® 应用程序,尤其是最受欢迎的应用程序,都是以图形用户界面( GUI )为设计目标的。因此,默认情况下, WINE 的工具被设计为启动图形程序。
然而,有三种方法可以运行这些所谓的控制台用户界面( CUI )程序:
-
Bare Streams 方法将直接将输出显示到标准输出。
-
wineconsole 实用程序可以与 user 或 curses 后端一起使用,以利用 WINE 系统为 CUI 应用程序提供的一些增强功能。
这些方法在 [WINE Wiki](https://wiki.winehq.org/Wine_User%27s_Guide#Text_mode_programs_.28CUI:_Console_User_Interface.29) 上有更详细的描述。
13.2.4. WINE 衍生项目
WINE 本身是一个成熟的开源项目,因此它被用作更复杂解决方案的基础并不令人意外。
13.2.4.1. 商业 WINE 实现
许多公司已经将 WINE 作为自己专有产品的核心( WINE 的 LGPL 许可证允许这样做)。其中最著名的两个如下所示:
-
Codeweavers CrossOver 是一款强大的软件,它允许用户在 Mac 和 Linux 操作系统上运行 Windows 应用程序。通过使用 CrossOver ,用户可以轻松地在非 Windows 平台上访问和使用他们喜爱的 Windows 软件。这个软件使用了一种独特的技术,使得 Windows 应用程序能够在其他操作系统上无缝运行,而无需安装 Windows 操作系统本身。 Codeweavers CrossOver 是一个非常有用的工具,为用户提供了更多的灵活性和选择,使他们能够在不同的操作系统之间无缝切换和使用他们需要的应用程序。
这个解决方案提供了一个简化的“一键式”安装 WINE 的方法,其中包含了额外的增强和优化(尽管该公司将其中许多贡献回馈给 WINE 项目)。 Codeweavers 的一个重点领域是使最受欢迎的应用程序能够顺利安装和运行。
虽然该公司曾经推出过适用于 FreeBSD 的 CrossOver 解决方案,但似乎已经被废弃很久了。虽然一些资源(如专门的论坛 https://www.codeweavers.com/compatibility/crossover/forum/freebsd )仍然存在,但它们也已经有一段时间没有活动了。
-
Steam Proton 是一个由 Valve 开发的兼容性工具,旨在使 Windows 上的游戏能够在 Linux 操作系统上运行。 Proton 基于 Wine 和其他开源技术,通过提供对 Windows API 的实现来实现这一目标。 Steam Proton 使得玩家可以在 Linux 上畅玩许多原本只能在 Windows 上运行的游戏,为 Linux 游戏生态系统的发展做出了重要贡献。
游戏公司 Steam 也使用 WINE 来使 Windows® 游戏能够在其他系统上安装和运行。它的主要目标是基于 Linux 的系统,尽管也有一些对 macOS 的支持。
虽然 Steam 没有提供原生的 FreeBSD 客户端,但可以使用 FreeBSD 的 Linux 兼容层来使用 Linux® 客户端的几种选项。
13.2.4.2. WINE 伴侣程序
除了专有的产品,其他项目还发布了与标准的开源版本 WINE 配合使用的应用程序。这些应用程序的目标可以从简化安装到提供简便的方式来安装流行软件。
这些解决方案在后面关于 GUI 前端 的章节中有更详细的介绍,包括以下内容:
-
winetricks 是一个用于在 Wine 环境中安装和配置 Windows 应用程序所需组件的实用工具。它提供了一系列预定义的安装选项,可以帮助用户轻松地安装常见的 Windows 库和运行时环境。通过使用 winetricks ,用户可以更方便地在 Linux 系统上运行 Windows 应用程序。
-
苏伊马祖
13.2.5. WINE 的替代方案
对于 FreeBSD 用户来说,使用 WINE 的替代方案如下:
-
双启动:一种简单的选择是在操作系统上直接运行所需的 Windows® 应用程序。当然,这意味着需要退出 FreeBSD 以启动 Windows® ,因此如果需要同时访问两个系统中的程序,则此方法不可行。
-
虚拟机:虚拟机( VM )是在本章前面提到的软件进程,它们模拟完整的硬件集合,可以在其上安装和运行其他操作系统(包括 Windows® )。现代工具使得创建和管理虚拟机变得容易,但这种方法是有代价的。主机系统的大部分资源必须分配给每个虚拟机,并且只要虚拟机在运行,这些资源就无法被主机回收。一些虚拟机管理器的例子包括开源解决方案 qemu 、 bhyve 和 VirtualBox 。有关更多详细信息,请参阅《虚拟化》章节。
-
远程访问:与许多其他类 UNIX® 系统一样, FreeBSD 可以运行各种应用程序,使用户能够远程访问 Windows® 计算机并使用其程序或数据。除了像 xrdp 这样连接到标准 Windows® 远程桌面协议的客户端之外,还可以使用其他开源标准,如 vnc (前提是在另一端存在兼容的服务器)。
13.3. 在 FreeBSD 上安装 WINE
可以通过 pkg 工具或编译端口来安装 WINE 。
13.3.1. WINE 的先决条件
在安装 WINE 本身之前,安装以下先决条件会很有用。
-
图形用户界面( GUI )
大多数 Windows® 程序都期望有一个可用的图形用户界面。如果安装 WINE 时没有安装图形用户界面,它的依赖项将包括 Wayland 合成器,因此将会安装一个图形用户界面。但在安装 WINE 之前,安装、配置和正确运行所选择的图形用户界面是很有用的。
-
Wine Gecko
Windows® 操作系统在很长一段时间内都预装了一个默认的网页浏览器: Internet Explorer 。因此,一些应用程序在工作时假设总会有能够显示网页的东西。为了提供这个功能, WINE 层包含了一个使用 Mozilla 项目的 Gecko 引擎的网页浏览器组件。当首次启动 WINE 时,它会提供下载和安装这个组件的选项,用户可能有理由这样做(这将在后面的章节中介绍)。但他们也可以在安装 WINE 之前或与 WINE 的安装同时安装这个组件。
使用以下命令安装此软件包:
# pkg install wine-gecko或者,使用以下方式编译端口:
# cd /usr/ports/emulator/wine-gecko
# make install-
Wine Mono 是一个用于在 Wine 环境中运行 .NET 应用程序的开源实现。它是一个替代 Microsoft .NET Framework 的组件,可以在 Linux 和其他类 Unix 系统上运行。 Wine Mono 提供了对 .NET 应用程序的兼容性,并且可以与 Wine 一起使用,使用户能够在非 Windows 操作系统上运行 .NET 应用程序。
此端口安装了 MONO 框架,它是微软 .NET 的开源实现。将其与 WINE 安装一起使用,可以增加任何使用 .NET 编写的应用程序在系统上安装和运行的可能性。
安装包的步骤如下:
# pkg install wine-mono从端口集合编译:
# cd /usr/ports/emulator/wine-mono
# make install13.3.2. 通过 FreeBSD 软件包仓库安装 WINE
在满足先决条件的情况下,使用以下命令通过软件包安装 WINE :
# pkg install wine使用以下方法从源代码编译 WINE 子系统:
# cd /usr/ports/emulator/wine
# make install13.3.3. WINE 安装中的 32 位与 64 位的问题
与大多数软件一样, Windows® 应用程序已经从旧的 32 位架构升级到 64 位。大多数最新的软件都是为 64 位操作系统编写的,尽管现代操作系统有时也可以继续运行旧的 32 位程序。 FreeBSD 也不例外,在 5.x 系列中就已经支持 64 位。
然而,使用默认不再支持的旧软件是模拟器的常见用途,用户通常会转向 WINE 来玩游戏和使用其他在现代硬件上无法正常运行的程序。幸运的是, FreeBSD 可以支持这三种情况:
-
在现代的 64 位机器上,如果想要运行 64 位的 Windows® 软件,只需安装上述部分提到的端口。端口系统将自动安装 64 位版本。
-
或者,用户可能拥有一台旧的 32 位机器,他们不想继续使用原始的、现在不再支持的软件。他们可以安装 32 位( i386 )版本的 FreeBSD ,然后在上述章节中安装端口。
13.4. 在 FreeBSD 上运行第一个 WINE 程序
现在 WINE 已经安装好了,下一步是通过运行一个简单的程序来尝试它。一个简单的方法是下载一个自包含的应用程序,即一个可以简单解压并运行而无需复杂安装过程的应用程序。
所谓的“便携式”应用程序版本是进行此测试的好选择,同样适用于只需一个可执行文件即可运行的程序。
13.4.1. 从命令行运行程序
有两种不同的方法可以从终端启动 Windows 程序。第一种,也是最直接的方法是导航到包含程序可执行文件( .EXE )的目录,并执行以下操作:
% wine program.exe对于需要使用命令行参数的应用程序,将它们像平常一样添加在可执行文件之后:
% wine program2.exe -file file.txt或者,在脚本中提供可执行文件的完整路径,以便使用它,例如:
% wine /home/user/bin/program.exe13.4.2. 从图形用户界面 (GUI) 运行程序
安装完成后,图形界面应该更新以适应 Windows 可执行文件( .EXE )的新关联。现在可以使用文件管理器浏览系统,并以与其他文件和程序相同的方式启动 Windows 应用程序(根据桌面设置的不同,可以是单击或双击)。
在大多数桌面上,通过右键单击文件并查找上下文菜单中的条目来确认此关联是否正确。其中一个选项(希望是默认选项)将是使用 *Wine Windows 程序加载器 * 打开文件,如下面的屏幕截图所示:
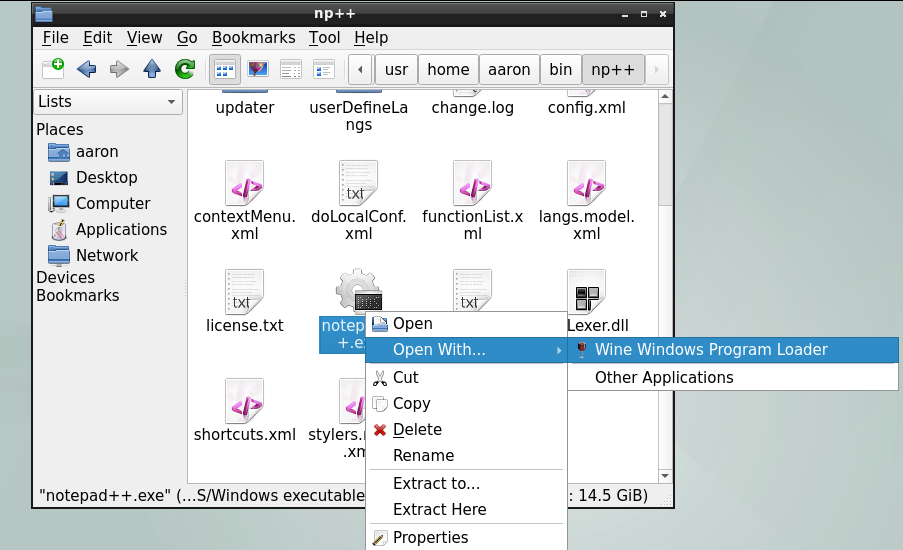
如果程序无法按预期运行,请尝试从命令行启动,并查看终端中显示的任何消息以进行故障排除。
如果在安装后, WINE 不是 .EXE 文件的默认应用程序,请检查当前桌面环境、图形界面或文件管理器中与该扩展名相关联的 MIME 类型。
13.5. 配置 WINE 安装
在了解了 WINE 是什么以及它的高级工作原理之后,下一步有效地在 FreeBSD 上使用它的关键是熟悉其配置。以下部分将描述_WINE 前缀_的关键概念,并说明如何使用它来控制通过 WINE 运行的应用程序的行为。
13.5.1. WINE 前缀
WINE 的“前缀”是一个目录,通常位于 [.filename]# $ HOME/.wine# 的默认位置下,但也可以位于其他位置。前缀是一组由 WINE 使用的配置和支持文件,用于配置和运行特定应用程序所需的 Windows® 环境。默认情况下,当用户首次启动全新的 WINE 安装时,将创建以下结构:
-
.update-timestamp: 包含了 [/usr/share/wine/wine.inf]# 文件的最后修改日期。它被 WINE 用来判断一个前缀是否过时,并在需要时自动更新它。
-
dosdevices/ :包含将 Windows® 资源映射到主机 FreeBSD 系统资源的信息。例如,在新的 WINE 安装之后,这里应该至少包含两个条目,以使用 Windows® 风格的驱动器字母访问 FreeBSD 文件系统:
-
c: @ #: 下面描述了一个指向 [.filename]#drive_c 的链接。
-
[.filename]#z: @ #: 指向系统根目录的链接。
-
-
drive_c/ :模拟 Windows® 系统的主要(即 C: )驱动器。它包含一个目录结构和相关文件,与标准的 Windows® 系统相同。一个新的 WINE 前缀将包含 Windows® 10 的目录,如_Users_和_Windows_,它们保存着操作系统本身。此外,安装在前缀中的应用程序将位于_Program Files_或_Program Files (x86)_中,具体取决于它们的架构。
-
system.reg: 这个注册表文件包含了关于 Windows® 安装的信息,对于 WINE 来说,这是位于 drive_c 的环境。
-
user.reg: 这个注册表文件包含当前用户的个人配置,可以通过各种软件或者注册表编辑器进行设置。
-
userdef.reg: 这个注册表文件是为新创建的用户提供的默认配置集合。
13.5.2. 创建和使用 WINE 前缀
虽然 WINE 会在用户的 [.filename]# $ HOME/.wine/# 目录下创建一个默认前缀,但也可以设置多个前缀。这样做有几个原因:
-
根据所涉及软件的兼容性需求,最常见的原因是模拟不同版本的 Windows® 。
-
此外,常常会遇到在默认环境下无法正常工作的软件,并且需要特殊配置。将这些软件隔离在自己的自定义前缀中是很有用的,这样的更改不会影响其他应用程序。
-
同样,将默认或“主”前缀复制到一个单独的“测试”前缀中,以评估应用程序的兼容性,可以减少损坏的机会。
在终端中创建前缀需要使用以下命令:
% WINEPREFIX="/home/username/.wine-new" winecfg这将运行 winecfg 程序,该程序可用于配置 Wine 前缀(稍后的章节将详细介绍)。但是,通过为 WINEPREFIX 环境变量提供一个目录路径值,如果该位置尚不存在前缀,则会在该位置创建一个新的前缀。
将相同的变量提供给 wine 程序也会导致所选程序以指定的前缀运行:
% WINEPREFIX="/home/username/.wine-new" wine program.exe13.5.3. 使用 winecfg 配置 WINE 前缀
如上所述, WINE 包含一个名为 winecfg 的工具,用于通过图形界面配置前缀。它包含多种功能,详细介绍在下面的章节中。当在前缀内运行 winecfg ,或者在 WINEPREFIX 变量中提供前缀的位置时,它可以配置所选前缀,具体描述在下面的章节中。
在“应用程序”选项卡上进行的选择将影响“库”和“图形”选项卡中所做更改的范围,这将仅限于所选的应用程序。有关更多详细信息,请参阅 WINE Wiki 中的 使用 Winecfg 部分。
13.5.3.1. 应用程序
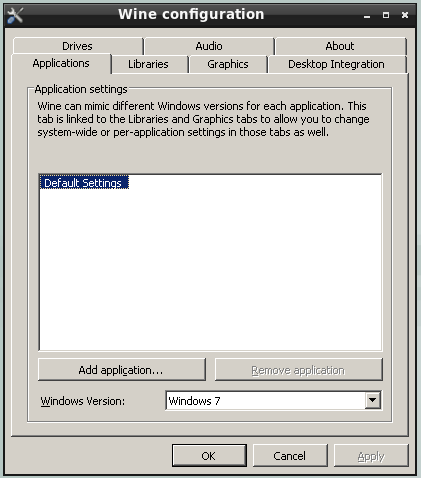
应用程序 包含控件,可以将程序与特定版本的 Windows® 关联起来。首次启动时,应用程序设置 部分将包含一个条目:默认设置。这对应于前缀的所有默认配置,即(如禁用的 删除应用程序 按钮所示)无法删除。
但是可以通过以下过程添加额外的应用程序:
-
点击“添加应用程序”按钮。
-
使用提供的对话框选择所需程序的可执行文件。
-
选择要与所选程序一起使用的 Windows® 版本。
13.5.3.2. 图书馆
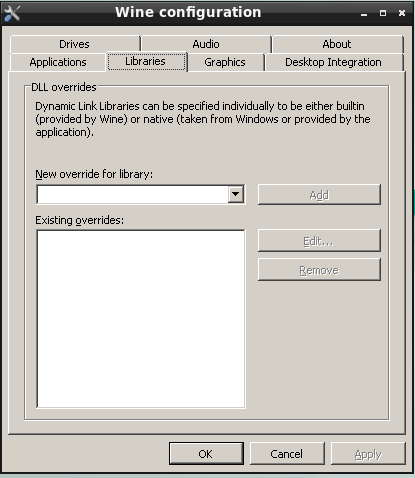
WINE 在其发行版中提供一组开源库文件,这些文件提供与 Windows® 对应的相同功能。然而,正如本章前面所提到的, WINE 项目始终试图跟上这些库的新更新。因此,随 WINE 一起发行的版本可能缺少最新的 Windows® 程序所期望的功能。
然而, winecfg 使得可以指定内置库的覆盖,特别是在与主机 FreeBSD 安装相同的机器上有一个 Windows® 版本可用的情况下。对于每个要覆盖的库,按照以下步骤进行:
-
打开“新的库覆盖”下拉菜单,并选择要替换的库。
-
点击“添加”按钮。
-
新的覆盖将出现在“现有覆盖”列表中,注意括号中的“本地,内置”标识。
-
点击以选择图书馆。
-
点击 编辑 按钮。
-
使用提供的对话框选择一个对应的库来替代内置的库。
请务必选择一个真正与内置版本对应的文件,否则可能会出现意外行为。
13.5.3.3. 图形
“图形”选项卡提供了一些选项,可以使通过 WINE 运行的程序在 FreeBSD 上平稳运行的窗口。
-
当窗口全屏时自动捕获鼠标。
-
允许 FreeBSD 窗口管理器为通过 WINE 运行的程序装饰窗口,例如它们的标题栏。
-
允许窗口管理器控制通过 WINE 运行的程序的窗口,例如对它们进行调整大小的操作。
-
创建一个模拟的虚拟桌面,在其中所有的 WINE 程序将运行。如果选择了此选项,可以使用“桌面尺寸”输入框指定虚拟桌面的大小。
-
设置通过 WINE 运行的程序的屏幕分辨率。
13.5.3.4. 桌面集成
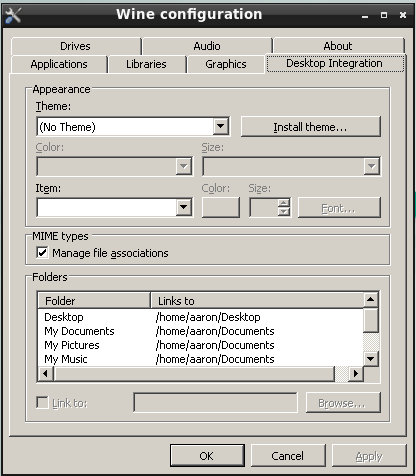
此选项卡允许配置以下项目:
-
用于通过 WINE 运行的程序的主题和相关视觉设置。
-
WINE 子系统是否应该在内部管理 MIME 类型(用于确定哪个应用程序打开特定文件类型)。
-
将主机 FreeBSD 系统中的目录映射到 Windows® 环境中的有用文件夹。要更改现有的关联,请选择所需的项目,然后点击“浏览”,然后使用提供的对话框选择一个目录。
13.5.3.5. 驱动器
“驱动器”选项卡允许将主机 FreeBSD 系统中的目录链接到 Windows® 环境中的驱动器字母。该选项卡中的默认值应该很熟悉,因为它们显示了当前 WINE 前缀中 dosdevices/ 目录的内容。通过此对话框进行的更改将反映在 dosdevices 中,并且在该目录中创建的格式正确的链接将显示在此选项卡中。
要创建一个新的条目,比如一个 CD-ROM (挂载在 /mnt/cdrom ),请按照以下步骤进行:
-
点击“添加”按钮。
-
在提供的对话框中,选择一个空闲的驱动器字母。
-
点击“确定”。
-
通过输入框填写“路径”字段,可以通过手动输入资源路径或者点击“浏览”按钮并使用提供的对话框进行选择。
默认情况下, WINE 会自动检测链接的资源类型,但也可以手动覆盖。有关高级选项的更多详细信息,请参阅 WINE Wiki 中的 部分 。
13.6. WINE 管理图形界面
虽然 WINE 的基本安装包含一个名为 winecfg 的图形界面配置工具,但它的主要目的仅限于配置现有的 WINE 前缀。然而,还有一些更高级的应用程序可以帮助初始安装应用程序,并优化它们的 WINE 环境。下面的章节包括一些最受欢迎的选择。
13.6.1. Winetricks 是一个用于在 Wine 环境中安装和配置 Windows 应用程序所需组件的实用工具。它提供了一个简单的命令行界面,使用户可以轻松地安装各种 Windows 库和运行时环境,以便在 Wine 中运行各种 Windows 软件。使用 Winetricks ,用户可以安装诸如 .NET Framework 、 DirectX 、 Visual C ++运行时库等常用的 Windows 组件,以便更好地支持和运行 Windows 应用程序。
winetricks 工具是一个跨平台的、通用的 WINE 辅助程序。它并非由 WINE 项目本身开发,而是由一群贡献者在 Github 上进行维护。它包含一些自动化的“配方”,可以通过优化设置和自动获取一些 DLL 库来使常见应用程序在 WINE 上运行。
13.6.1.1. 安装 winetricks
要在 FreeBSD 上使用二进制包安装 winetricks ,请使用以下命令(注意 winetricks 需要 i386-wine 或 i386-wine-devel 包之一,因此不会自动安装其他依赖项):
# pkg install i386-wine winetricks要从源代码编译它,请在终端中输入以下命令:
# cd /usr/ports/emulators/i386-wine
# make install
# cd /usr/ports/emulators/winetricks
# make install如果需要手动安装,请参考 Github 账户上的说明。
13.6.1.2. 使用 winetricks
使用以下命令运行 winetricks :
% winetricks注意:这应该在一个 32 位的前缀中运行 winetricks 。启动 winetricks 会显示一个窗口,其中包含一些选项,如下所示:
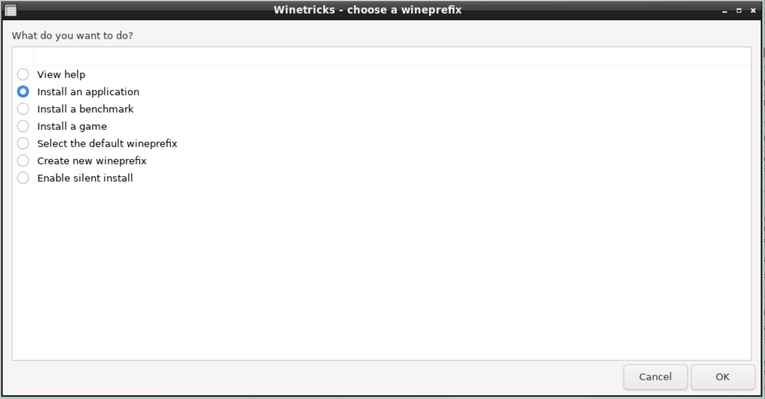
选择“安装应用程序”,“安装基准测试”或“安装游戏”中的任一选项,将显示一个支持的选项列表,例如下面的应用程序选项:
选择一个或多个项目并点击“确定”将开始它们的安装过程。最初,一些看起来像错误的消息可能会出现,但实际上它们是信息提示,因为 winetricks 正在配置 WINE 环境以解决应用程序的已知问题。
一旦这些被规避,应用程序的实际安装程序将被运行:
安装完成后,新的 Windows 应用程序应该可以从桌面环境的标准菜单中找到(如下面的 LXQT 桌面环境的截图所示):
要删除该应用程序,请再次运行 winetricks ,然后选择“运行卸载程序”。
将出现一个类似于 Windows® 风格的对话框,其中列出了安装的程序和组件的列表。选择要移除的应用程序,然后点击“修改 / 移除”按钮。
这将运行应用程序内置的安装程序,该程序还应该具有卸载选项。
13.6.2. 苏伊马祖
Suyimazu 是一个类似于 winetricks 的应用程序,但它受到了 Linux 游戏系统 Lutris 的启发。虽然它专注于游戏,但也可以通过 Suyimazu 安装非游戏应用程序。
13.6.2.1. 安装 Suyimazu
要安装 Suyimazu 的二进制包,请执行以下命令:
# pkg install suyimazuSuyimazu 在 FreeBSD Ports 系统中可用。然而,与其在 Ports 或二进制包的_emulators_部分中查找,不如在_games_部分中查找。
# cd /usr/ports/games/suyimazu
# make install13.6.2.2. 使用 Suyimazu
Suyimazu 的使用方法与 winetricks 非常相似。首次使用时,可以通过命令行(或桌面环境的运行程序)启动它:
% Suyimazu这应该会显示一个友好的欢迎消息。点击“确定”继续。
该程序还将提供在兼容环境的应用程序菜单中放置链接的选项:
根据 FreeBSD 机器的设置, Suyimazu 可能会显示一条消息,提示安装本机图形驱动程序。
然后应用程序的窗口将出现,相当于一个带有所有选项的“主菜单”。许多项目与 winetricks 相同,但 Suyimazu 提供了一些额外的有用选项,例如打开其数据文件夹(打开 Suyimazu 文件夹)或运行指定的程序(在前缀中运行可执行文件)。
要选择一个 Suyimazu 支持的应用程序进行安装,请选择“安装”,然后点击“确定”。这将显示 Homura 可以自动安装的应用程序列表。选择一个应用程序,然后点击“确定”开始安装过程。
作为第一步, Suyimazu 将下载所选的程序。在支持的桌面环境中可能会出现通知。
该程序还将为应用程序创建一个新的前缀。将显示一个带有此消息的标准 WINE 对话框。
接下来, Suyimazu 将安装所选程序的所有先决条件。这可能涉及下载和提取相当数量的文件,具体细节将显示在对话框中。
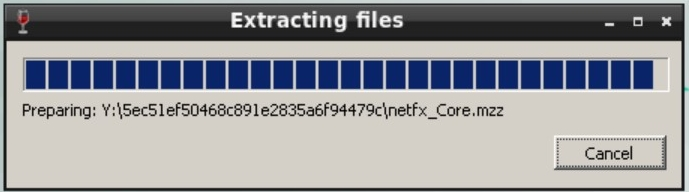
下载的软件包会自动打开并按需运行。
安装可能会以简单的桌面通知或终端中的消息结束,这取决于 Suyimazu 是如何启动的。但无论哪种情况, Suyimazu 都应返回到主屏幕。要确认安装成功,请选择“启动器”,然后点击“确定”。
这将显示已安装应用程序的列表。
要运行新程序,请从列表中选择它,然后点击“确定”。要卸载该应用程序,请从主屏幕选择“卸载”,这将显示一个类似的列表。选择要移除的程序,然后点击“确定”。
13.7. 在多用户的 FreeBSD 安装中使用 WINE
13.7.1. 使用共享的 WINE 前缀的问题
与大多数类 UNIX® 操作系统一样, FreeBSD 设计用于多个用户同时登录和工作。另一方面, Windows® 是多用户的,意味着可以在一个系统上设置多个用户账户。但是预期只有一个用户会在任何给定的时刻使用物理机器(台式机或笔记本电脑)。
最近的 Windows® 消费者版本在多用户场景下采取了一些措施来改善操作系统。但它仍然主要围绕单用户体验进行构建。此外, WINE 项目为创建兼容环境所采取的措施意味着,与 FreeBSD 应用程序(包括 WINE 本身)不同,它将类似于这种单用户环境。
因此,每个用户都需要维护自己的配置集,这可能是有益的。然而,安装应用程序,特别是像办公套件或游戏这样的大型应用程序,只需要一次安装是有优势的。这样做的两个原因的例子是维护(软件更新只需要应用一次)和存储效率(没有重复的文件)。
有两种策略可以最小化系统中多个 WINE 用户的影响。
13.7.2. 将应用程序安装到公共驱动器
在某些情况下,您可能希望将应用程序安装到一个公共驱动器,以便多个用户可以共享和访问这些应用程序。以下是安装应用程序到公共驱动器的步骤:
-
打开安装程序:双击应用程序的安装文件,以启动安装程序。
-
选择安装位置:在安装程序的界面上,选择您希望安装应用程序的位置。通常,您可以通过浏览按钮选择驱动器和文件夹。
-
选择公共驱动器:浏览您的计算机,找到一个公共驱动器,例如 D 盘或网络驱动器。选择该驱动器作为应用程序的安装位置。
-
完成安装:按照安装程序的指示完成安装过程。安装程序将应用程序文件复制到公共驱动器上。
安装完成后,其他用户可以通过访问公共驱动器上的应用程序文件来运行和使用这些应用程序。请注意,安装到公共驱动器的应用程序可能需要管理员权限才能运行。
如 WINE 配置部分所示, WINE 提供了将附加驱动器连接到给定前缀的功能。通过这种方式,应用程序可以安装到一个共享的位置,而每个用户仍然可以拥有一个前缀,其中可以保存个别设置(取决于程序)。如果要在用户之间共享相对较少的应用程序,并且这些程序需要对前缀进行少量自定义调整以正常运行,那么这是一个很好的设置。
按照以下步骤进行安装应用程序的方式:
一旦完成,应用程序可以安装到此位置,并且随后可以使用分配的驱动器号(或标准的 UNIX® 风格的目录路径)运行。然而,如上所述,同一时间只能有一个用户运行这些应用程序(可能会访问其安装目录中的文件)。一些应用程序在被非所有者用户运行时可能会表现出意外行为,尽管该用户是应该对整个目录具有完全的“读 / 写 / 执行”权限的组的成员。
13.7.3. 使用通用的 WINE 安装方法
另一方面,如果有许多需要共享的应用程序,或者它们需要特定的调整才能正常工作,可能需要采用不同的方法。在这种方法中,专门为存储 WINE 前缀及其所有已安装应用程序的目的创建一个完全独立的用户。然后,使用 sudo(8) 命令授予各个用户以该用户身份运行程序的权限。结果是,这些用户可以像平常一样启动 WINE 应用程序,只是它们将表现得好像是由新创建的用户启动的,因此使用的是包含设置和程序的中央维护的前缀。要实现这一点,请执行以下步骤:
使用以下命令(作为 root 用户)创建一个新用户,该命令将引导您完成所需的详细信息:
# adduser输入用户名(例如,windows)和全名(“ Microsoft Windows ”)。然后接受其余问题的默认值。接下来,使用以下命令使用二进制包安装 sudo 实用程序:
# pkg install sudo安装完成后,按照以下方式编辑 /etc/sudoers 文件:
# User alias specification # define which users can run the wine/windows programs User_Alias WINDOWS_USERS = user1,user2 # define which users can administrate (become root) User_Alias ADMIN = user1 # Cmnd alias specification # define which commands the WINDOWS_USERS may run Cmnd_Alias WINDOWS = /usr/bin/wine,/usr/bin/winecfg # Defaults Defaults:WINDOWS_USERS env_reset Defaults:WINDOWS_USERS env_keep += DISPLAY Defaults:WINDOWS_USERS env_keep += XAUTHORITY Defaults !lecture,tty_tickets,!fqdn # User privilege specification root ALL=(ALL) ALL # Members of the admin user_alias, defined above, may gain root privileges ADMIN ALL=(ALL) ALL # The WINDOWS_USERS may run WINDOWS programs as user windows without a password WINDOWS_USERS ALL = (windows) NOPASSWD: WINDOWS
这些更改的结果是,在_User_Alias_部分中列出的用户被允许以最后一行中列出的用户身份运行_Cmnd Alias_部分中列出的程序,使用_Defaults_部分中列出的资源(当前显示)。换句话说,被指定为_WINDOWS_USERS_的用户可以以_user windows_的身份运行 WINE 和 winecfg 应用程序。作为额外的好处,这里的配置意味着他们不需要为_windows_用户输入密码。
接下来,将显示器的访问权限提供给“ windows ”用户,这是 WINE 程序将要运行的用户。
% xhost +local:windows这应该添加到在登录时或默认图形环境启动时运行的命令列表中。完成上述所有步骤后,配置为 sudoers 文件中的 WINDOW_USERS 之一的用户可以使用以下命令使用共享前缀运行程序:
% sudo -u windows wine program.exe值得注意的是,多个用户同时访问这个共享环境仍然存在风险。然而,需要考虑的是,共享环境本身可以包含多个前缀。通过这种方式,管理员可以创建一个经过测试和验证的程序集,每个程序都有自己的前缀。同时,一个用户可以玩游戏,而另一个用户可以使用办公软件,而无需进行重复的软件安装。
13.8. 在 FreeBSD 上使用 WINE 的常见问题解答
下面的部分描述了在 FreeBSD 上运行 WINE 时的一些常见问题、技巧或常见问题,以及它们的相应答案。
13.8.1. 基本安装和使用
13.8.1.1. 如何在同一系统上安装 32 位和 64 位的 WINE ?
正如本节前面所述, wine 和 i386-wine 软件包彼此冲突,因此不能以正常方式在同一系统上安装。然而,可以使用 chroots/jails 等机制实现多个安装,或者通过从源代码构建 WINE 来实现(注意,这并不意味着构建端口)。
13.8.2. 安装优化
13.8.2.1. 如何处理 Windows® 硬件(例如,图形)驱动程序?
操作系统驱动程序在应用程序和硬件之间传输命令。 WINE 模拟了 Windows® 环境,包括驱动程序,这些驱动程序又使用 FreeBSD 的本地驱动程序进行传输。不建议安装 Windows® 驱动程序,因为 WINE 系统设计为使用主机系统的驱动程序。例如,如果有一块需要专用驱动程序的显卡,请使用标准的 FreeBSD 方法进行安装,而不是使用 Windows® 的安装程序。
13.8.2.2. 有没有办法让 Windows® 字体看起来更好?
一个在 FreeBSD 论坛上的用户建议使用以下配置来修复 WINE 字体的开箱即用外观,这可能会稍微出现像素化的问题。
根据 FreeBSD 论坛上的帖子( https://forums.freebsd.org/threads/make-wine-ui-fonts-look-good.68273/ ),将以下内容添加到 .config/fontconfig/fonts.conf 文件中将会添加反锯齿效果,并使文本更易读。
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd>"
<fontconfig>
<!-- antialias all fonts -->
<match target="font">
<edit name="antialias" mode="assign"><bool>true</bool></edit>>
<edit name="hinting" mode="assign"><bool>true</bool></edit>>
<edit name="hintstyle" mode="assign"><const>hintslight</const></edit>>
<edit name="rgba" mode="assign"><const>rgb</const></edit>>
</match>
</fontconfig>
13.8.3. 特定应用
13.8.3.1. 在哪里可以找到最好的地方来查看应用程序 X 在 WINE 上是否可用?
确定兼容性的第一步应该是查看 [WINE AppDB](https://appdb.winehq.org/) 。这是一个汇编了关于在所有支持的平台上工作(或不工作)的程序报告的数据库,尽管(如前面提到的),一个平台的解决方案通常也适用于其他平台。
13.8.3.2. 有什么可以帮助游戏运行更流畅的方法吗?
也许吧。许多 Windows® 游戏依赖于 DirectX ,这是微软的专有图形层。然而,在开源社区中有一些项目试图实现对这项技术的支持。
dxvk 项目是一个尝试使用兼容 FreeBSD 的 Vulkan 图形子系统来实现 DirectX 的项目之一。尽管其主要目标是在 Linux 上的 WINE ,但一些 FreeBSD 用户报告称他们成功编译并使用了 dxvk 。
此外, wine-proton 端口 的工作正在进行中。这将把 Steam 游戏平台开发者 Valve 的工作带到 FreeBSD 上。 Proton 是 WINE 的一个分发版本,旨在允许许多 Windows® 游戏在其他操作系统上以最小的设置运行。
13.8.3.3. 有没有任何地方, FreeBSD 的 WINE 用户可以聚集在一起交流技巧和窍门?
有很多地方可以让 FreeBSD 用户讨论与 WINE 相关的问题,并且可以搜索解决方案:
-
https://forums.freebsd.org/ [FreeBSD 论坛] ,特别是“安装和维护端口或软件包”或“仿真和虚拟化”论坛。
-
FreeBSD IRC 频道 包括 #freebsd (用于一般支持)、 #freebsd-games 等等。
-
BSD 世界 Discord 服务器 的频道包括_bsd-desktop_,bsd-gaming,_bsd-wine_和其他频道。
13.8.4. 其他操作系统资源
有许多针对其他操作系统的资源可能对 FreeBSD 用户有用:
-
https://wiki.winehq.org/ 【 WINE Wiki 】上有大量关于使用 WINE 的信息,其中很多适用于 WINE 支持的多个操作系统。
-
同样,其他操作系统项目提供的文档也可能非常有价值。 Arch Linux Wiki 上的 WINE 页面 是一个特别好的例子,尽管一些“第三方应用程序”(即“伴侣应用程序”)显然在 FreeBSD 上不可用。
-
最后, Codeweavers (一家商业版 WINE 的开发者)是一个积极的上游贡献者。在 他们的支持论坛 中,对于解决开源版本 WINE 的问题,经常可以找到有帮助的答案。
Part III: 系统管理
剩下的章节涵盖了 FreeBSD 系统管理的各个方面。每一章都以描述读完该章节后将学到的内容为开头,并详细说明读者在学习该章节之前应该具备的知识。
这些章节的设计是根据需要阅读的。它们不需要按照特定的顺序阅读,也不需要在开始使用 FreeBSD 之前全部阅读完毕。
Chapter 14. 配置、服务、日志和电源管理
14.1. 简介
FreeBSD 的一个重要方面是正确的系统配置。本章介绍了 FreeBSD 配置过程的许多内容,包括一些可以设置的参数,用于调整 FreeBSD 系统。
在阅读本章之前,您应该:
-
了解 UNIX® 和 FreeBSD FreeBSD 基础知识。
阅读本章后,您将了解:
-
如何使用 /etc 中的各种配置文件。
-
rc.conf 配置和 /usr/local/etc/rc.d 启动脚本的基础知识。
-
如何使用 sysctl(8) 变量来调整 FreeBSD。
-
如何在 FreeBSD 中配置电源管理。
14.2. 配置文件
FreeBSD 在基础系统和第三方应用程序之间保持了明确的分离,因此这影响了这些应用程序的配置文件的位置。
FreeBSD 基本系统配置位于 .filename]/etc 目录下,而 /usr/local/etc 目录包含通过 ports 集合和软件包安装在系统上的所有应用程序的配置文件。
内核状态配置位于 /etc/sysctl.conf。在 sysctl 实用程序 部分,将更详细地解释 sysctl(8) 的操作。
有关 FreeBSD 文件系统结构的更多信息,请参阅 hier(7)。
通常情况下,配置文件没有遵循统一的语法规范。虽然使用 # 字符来注释一行是常见的做法,并且每行都包含一个配置变量。
|
一些应用程序,如 pkg(8),开始使用 通用配置语言(UCL) 。 |
14.2.1. /etc 目录
/etc 目录包含了所有负责配置 FreeBSD 的基本系统配置文件。
|
在修改 /etc 目录中的文件时,必须非常小心;配置错误可能会导致 FreeBSD 无法启动或出现故障。 |
/etc |
系统配置文件和脚本。 |
/etc/defaults |
默认的系统配置文件,请参阅 rc(8) 获取更多信息。 |
/etc/fstab |
fstab(5) 包含了关于各种文件系统的描述信息。 |
/etc/mail |
额外的 sendmail(8) 配置和其他 MTA 配置文件。 |
/etc/mtree |
mtree 配置文件,请参考 mtree(8) 了解更多信息。 |
/etc/pam.d |
Pluggable Authentication Modules(PAM)库的配置文件。 |
/etc/periodic |
通过 cron(8) 每天、每周和每月运行的脚本,请参阅 periodic(8) 获取更多信息。 |
/etc/rc.d |
系统和守护进程的启动/控制脚本,请参阅 rc(8) 获取更多信息。 |
/etc/rc.conf |
包含有关本地主机名称的描述性信息,潜在网络接口的配置细节以及应在系统初始启动时启动的服务。有关更多信息,请参见 管理系统特定配置。 |
/etc/security |
OpenBSM 审计配置文件,详见 audit(8) 获取更多信息。 |
/etc/ppp |
ppp 配置文件,请参考 ppp(8) 获取更多信息。 |
/etc/ssh |
OpenSSH 配置文件,更多信息请参见 ssh(1)。 |
/etc/ssl |
OpenSSL 配置文件。 |
/etc/sysctl.conf |
包含内核的设置。更多信息请参见 sysctl 实用程序。 |
14.2.2. sysctl 实用程序
sysctl(8) 实用程序用于对运行中的 FreeBSD 系统进行更改。
sysctl(8) 实用程序用于检索内核状态,并允许具有适当特权的进程设置内核状态。要检索或设置的状态使用“管理信息库(Management Information Base)”(“MIB”)样式的名称进行描述,该名称被描述为一组由点分隔的组件。
sysctl 是一个用于管理和配置 Linux 内核参数的命令行工具。它允许用户查看和修改内核的运行时参数,以及控制系统的行为。通过 sysctl 命令,用户可以查询和修改各种系统设置,如网络配置、文件系统参数、内存管理等。这个工具在调优系统性能、解决问题和进行系统管理时非常有用。 |
"魔术"数字 |
kern |
内核功能和特性 |
vm |
虚拟内存 |
vfs |
文件系统 |
net |
网络 |
debug |
调试参数 |
hw |
硬件 |
machdep |
机器依赖 |
user |
用户空间 |
p1003_1b |
POSIX 1003.1B |
在其核心,sysctl(8) 有两个功能:读取和修改系统设置。
查看所有可读取的变量:
% sysctl -a输出应该类似于以下内容:
kern.ostype: FreeBSD ... vm.swap_enabled: 1 vm.overcommit: 0 vm.domain.0.pidctrl.kdd: 8 vm.domain.0.pidctrl.kid: 4 vm.domain.0.pidctrl.kpd: 3 ... vfs.zfs.sync_pass_rewrite: 2 vfs.zfs.sync_pass_dont_compress: 8 vfs.zfs.sync_pass_deferred_free: 2
要读取特定的变量,请指定其名称:
% sysctl kern.maxproc输出应该类似于以下内容:
kern.maxproc: 1044
管理信息库(MIB)是分层的,因此,指定一个前缀将打印出所有挂在该前缀下的节点:
% sysctl net输出应该类似于以下内容:
net.local.stream.recvspace: 8192 net.local.stream.sendspace: 8192 net.local.dgram.recvspace: 16384 net.local.dgram.maxdgram: 2048 net.local.seqpacket.recvspace: 8192 net.local.seqpacket.maxseqpacket: 8192 net.local.sockcount: 60 net.local.taskcount: 25 net.local.recycled: 0 net.local.deferred: 0 net.local.inflight: 0 net.inet.ip.portrange.randomtime: 1 net.inet.ip.portrange.randomcps: 9999 [...]
要设置特定的变量,请使用 variable=value 的语法:
# sysctl kern.maxfiles=5000输出应该类似于以下内容:
kern.maxfiles: 2088 -> 5000
|
为了在重启后保留配置,需要按照下面的说明将这些变量添加到 /etc/sysctl.conf 文件中。 |
14.2.3. /etc/sysctl.conf 文件
sysctl(8) 的配置文件,/etc/sysctl.conf ,看起来很像 /etc/rc.conf。
使用 variable=value 语法来设置值。
|
系统进入多用户模式后,设置了指定的值。并非所有变量都可以在此模式下设置。 |
例如,要关闭致命信号退出的日志记录并防止用户看到其他用户启动的进程,可以在[.filename]/etc/sysctl.conf 中设置以下可调整项:
# Do not log fatal signal exits (e.g., sig 11) kern.logsigexit=0 # Prevent users from seeing information about processes that # are being run under another UID. security.bsd.see_other_uids=0
要获取关于特定 sysctl 函数的更多信息,可以执行以下命令:
% sysctl -d kern.dfldsiz输出应该类似于以下内容:
kern.dfldsiz: Initial data size limit
14.2.4. 管理系统特定配置
系统配置信息的主要位置是 /etc/rc.conf。
该文件包含了各种配置信息,并在系统启动时读取以配置系统。它为 rc* 文件提供配置信息。
/etc/rc.conf 中的条目会覆盖 /etc/defaults/rc.conf 中的默认设置。
|
不应编辑包含默认设置的文件 /etc/defaults/rc.conf 。相反,所有特定于系统的更改应该在 /etc/rc.conf 中进行。 |
在集群应用中,可以采用多种策略来将整个站点的配置与系统特定的配置分离,以减少管理开销。
推荐的方法是将系统特定的配置放置在 /etc/rc.conf.local 文件中。
例如,这些条目在 /etc/rc.conf 适用于所有系统:
sshd_enable="YES" keyrate="fast" defaultrouter="10.1.1.254"
而这些条目在 /etc/rc.conf.local 文件中仅适用于此系统:
hostname="node1.example.org" ifconfig_fxp0="inet 10.1.1.1/8"
使用诸如 rsync 或 puppet 的应用程序,将 /etc/rc.conf 分发到每个系统,同时保持 /etc/rc.conf.local 的唯一性。
升级系统不会覆盖 /etc/rc.conf 文件,因此系统配置信息不会丢失。
|
/etc/rc.conf 和 /etc/rc.conf.local 都由 sh(1) 解析。这使得系统操作员能够创建复杂的配置场景。有关此主题的更多信息,请参阅 rc.conf(5)。 |
14.3. 在 FreeBSD 中管理服务
FreeBSD 在系统初始化和服务管理过程中使用 rc(8) 系统的启动脚本。
/etc/rc.d 中列出的脚本提供基本服务,可以通过 start、stop 和 `restart`选项来控制,使用 service(8) 命令。
一个基本的脚本可能类似于以下内容:
#!/bin/sh
#
# PROVIDE: utility
# REQUIRE: DAEMON
# KEYWORD: shutdown
. /etc/rc.subr
name=utility
rcvar=utility_enable
command="/usr/local/sbin/utility"
load_rc_config $name
#
# DO NOT CHANGE THESE DEFAULT VALUES HERE
# SET THEM IN THE /etc/rc.conf FILE
#
utility_enable=${utility_enable-"NO"}
pidfile=${utility_pidfile-"/var/run/utility.pid"}
run_rc_command "$1"
14.3.1. 启动服务
许多用户在 FreeBSD 上从 Ports Collection 安装第三方软件,并要求在系统初始化时启动已安装的服务。
服务,例如 security/openssh-portable 或 www/nginx 只是许多软件包中的两个,这些软件包可能在系统初始化期间启动。本节介绍了启动服务的可用程序。
由于 rc(8) 系统主要用于在系统启动和关闭时启动和停止服务,因此只有在设置了适当的 /etc/rc.conf 变量时,start、stop 和 restart 选项才会执行其操作。
因此,启动服务的第一步,例如 www/nginx,是通过执行以下命令将其添加到 /etc/rc.conf 中:
# sysrc nginx_enable="YES"然后可以执行以下命令来启动 nginx :
# service nginx start|
无论 /etc/rc.conf 中的设置如何,要启动、停止或重新启动服务,这些命令都应以“one”为前缀。例如,要启动 www/nginx,无论当前 /etc/rc.conf 的设置如何,执行以下命令: |
14.3.2. 服务的状态
要确定服务是否正在运行,请使用 status 子命令。
例如,要验证 www/nginx 是否正在运行:
# service nginx status输出应该类似于以下内容:
nginx is running as pid 27871.
14.3.3. 重新加载服务
在某些情况下,也可以“重新加载(reload)”一个服务。这将尝试向一个单独的服务发送一个信号,强制该服务重新加载其配置文件。
在大多数情况下,这意味着向服务发送一个 SIGHUP 信号。
并非所有服务都支持此功能。
rc(8) 系统用于网络服务,并且它还贡献了大部分系统初始化工作。例如,当执行 /etc/rc.d/bgfsck 脚本时,它会打印出以下消息:
Starting background file system checks in 60 seconds.该脚本用于后台文件系统检查,仅在系统初始化期间进行。
许多系统服务依赖其他服务的正常运行。例如,yp(8) 和其他基于 RPC 的服务可能在 rpcbind(8) 服务启动之前无法启动。
可以在 rc(8) 和 rc.subr(8) 中找到更多的信息。
14.3.4. 使用服务启动服务
其他服务可以使用 inetd(8) 启动。有关使用 inetd(8) 及其配置的详细信息,请参阅 “inetd 超级服务器”。
在某些情况下,使用 cron(8) 来启动系统服务可能更合理。这种方法有许多优点,因为 cron(8) 以 crontab(5) 的所有者身份运行这些进程。这使得普通用户可以启动和维护自己的应用程序。
14.4. Cron 和周期性任务
在 FreeBSD 上,安排任务在特定的日期或时间运行是一项非常常见的任务。负责执行这项任务的工具是 cron(8)。
除了用户可以通过 cron(8) 进行调度的任务之外,FreeBSD 还执行由 periodic(8) 管理的常规后台任务。
14.4.1. Cron
cron(8) 实用程序在后台运行,并定期检查 /etc/crontab 中的任务以执行,并在 /var/cron/tabs 中搜索自定义的 crontab 文件。
这些文件用于安排任务,cron 会在指定的时间运行这些任务。
crontab 中的每个条目定义了一个要运行的任务,被称为 cron 作业。
使用了两种不同类型的配置文件:系统 crontab 和用户 crontab。系统 crontab 不应该被修改,而用户 crontab 可以根据需要创建和编辑。这些文件使用的格式在 crontab(5) 中有文档记录。系统 crontab 的格式(.filename]/etc/crontab)包括一个 who 列,在用户 crontab 中不存在。在系统 crontab 中,cron 根据该列中指定的用户运行命令。在用户 crontab 中,所有命令都以创建 crontab 的用户身份运行。
用户的 crontab 允许个别用户安排自己的任务。root 用户也可以拥有一个用户 crontab ,用于安排系统中不存在的任务。
这是系统 crontab 的一个示例条目,/etc/crontab:
# /etc/crontab - root's crontab for FreeBSD # # $FreeBSD$ (1) # SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin (2) # #minute hour mday month wday who command (3) # # Save some entropy so that /dev/random can re-seed on boot. */11 * * * * operator /usr/libexec/save-entropy (4) # # Rotate log files every hour, if necessary. 0 * * * * root newsyslog # # Perform daily/weekly/monthly maintenance. 1 3 * * * root periodic daily 15 4 * * 6 root periodic weekly 30 5 1 * * root periodic monthly # # Adjust the time zone if the CMOS clock keeps local time, as opposed to # UTC time. See adjkerntz(8) for details. 1,31 0-5 * * * root adjkerntz -a
| 1 | 以 # 字符开头的行是注释。注释可以放在文件中作为对所执行的操作的内容和原因的提醒。注释不能与命令在同一行,否则它们将被解释为命令的一部分;它们必须在新的一行上。空行会被忽略。 |
| 2 | 等号(=)字符用于定义任何环境设置。在这个例子中,它被用来定义 SHELL 和 PATH。如果省略了 SHELL, cron 将使用默认的 Bourne shell。如果省略了 PATH,则必须提供要运行的命令或脚本的完整路径。 |
| 3 | 这行定义了系统 crontab 中使用的七个字段:minute(分钟)、hour(小时)、mday(月中的某一天)、month(月份)、wday(星期几)、who(用户)和 command(命令)。minute 字段表示指定命令将运行的分钟数,hour 字段表示指定命令将运行的小时数,mday 字段表示月份中的某一天,month 字段表示月份,wday 字段表示星期几。这些字段必须是数字值,表示 24 小时制的时间,或者是 *,表示该字段的所有值。who 字段仅存在于系统 crontab 中,用于指定命令应该以哪个用户身份运行。最后一个字段是要执行的命令。 |
| 4 | 此条目定义了此 cron 作业的值。*/11 后面跟着几个 * 字符,指定了 /usr/libexec/save-entropy 在每小时的每十一分钟,每天的每小时,每周的每天,每月的每天都由 operator 调用。命令可以包含任意数量的开关。然而,跨多行的命令需要使用反斜杠 "\" 继续字符进行分割。 |
14.4.2. 创建用户的定时任务表
要创建一个用户的定时任务表,可以在编辑器模式下调用 crontab 命令:
% crontab -e这将使用默认的文本编辑器打开用户的 crontab。当用户第一次运行此命令时,它将打开一个空文件。一旦用户创建了一个 crontab,此命令将打开该文件以供编辑。
在 crontab 文件的顶部添加以下行是很有用的,这样可以设置环境变量并记住 crontab 中字段的含义:
SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin # Order of crontab fields # minute hour mday month wday command
然后为每个要运行的命令或脚本添加一行,指定运行命令的时间。此示例在每天下午两点运行指定的自定义 Bourne shell 脚本。由于脚本的路径没有在 PATH 中指定,因此给出了脚本的完整路径:
0 14 * * * /home/user/bin/mycustomscript.sh
|
在使用自定义脚本之前,请确保它是可执行的,并使用 cron 设置的有限环境变量集进行测试。要复制用于运行上述 cron 条目的环境,请使用: env -i SHELL=/bin/sh PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin HOME=/home/user LOGNAME=user /home/user/bin/mycustomscript.sh 在 crontab(5) 中讨论了由 cron 设置的环境。如果脚本中包含使用通配符删除文件的命令,那么在 cron 环境中检查脚本的正确运行尤为重要。 |
编辑完 crontab 后,保存文件。它将自动安装,并且 cron 将读取 crontab 并在指定的时间运行其 cron 作业。要列出 crontab 中的 cron 作业,请使用以下命令:
% crontab -l输出应该类似于以下内容:
0 14 * * * /home/user/bin/mycustomscript.sh
要删除用户 crontab 中的所有 cron 作业:
% crontab -r输出应该类似于以下内容:
remove crontab for user? y
14.4.3. Periodic
FreeBSD 提供了一组系统管理脚本,用于检查各种子系统的状态,执行与安全相关的检查,轮转日志文件等。这些脚本定期运行:每天、每周或每月。这些任务的管理由 periodic(8) 执行,并且其配置存储在 periodic.conf(5) 中。定期任务由系统 crontab 中的条目启动,如上所示。
periodic(8) 执行的脚本位于基本工具的 /etc/periodic/ 目录下,第三方软件的脚本位于 /usr/local/etc/periodic/ 目录下。
它们被组织在 4 个子目录中,分别是 daily(每日)、weekly(每周)、monthly(每月)和 security(安全)。
14.4.4. 启用或禁用定期任务
FreeBSD 默认启用了一些定期运行的脚本。
要启用或禁用任务,第一步是编辑 /etc/periodic.conf 文件,执行以下命令:
# ee /etc/periodic.conf然后,要启用 daily_status_zfs_enable,请将以下内容放入文件中:
daily_status_zfs_enable="YES"
要禁用默认情况下处于活动状态的任务,只需将 YES 更改为 NO 即可。
14.4.5. 配置定期任务的输出
在 /etc/periodic.conf 文件中,变量 daily_output、weekly_output 和 monthly_output 指定了脚本执行结果的发送位置。
默认情况下,周期性脚本的输出会发送到 root 的邮箱,因此最好阅读 root 的邮件或将 root 的别名设置为一个被监控的邮箱。
要将结果发送到另一个电子邮件或其他电子邮件,请将电子邮件地址以空格分隔添加到 /etc/periodic.conf 中:
daily_output="[email protected] [email protected]" weekly_output="[email protected] [email protected]" monthly_output="[email protected] [email protected]"
要将周期性的输出记录到日志文件而不是通过电子邮件接收,将以下行添加到 /etc/periodic.conf 文件中。 newsyslog(8) 会在适当的时间对这些文件进行轮转:
daily_output=/var/log/daily.log weekly_output=/var/log/weekly.log monthly_output=/var/log/monthly.log
14.5. 配置系统日志
生成和读取系统日志是系统管理的重要方面。系统日志中的信息可以用于检测硬件和软件问题,以及应用程序和系统配置错误。这些信息在安全审计和事件响应中也起着重要作用。大多数系统守护进程和应用程序都会生成日志条目。
FreeBSD 提供了一个系统日志记录器,syslogd(8),用于管理日志记录。默认情况下,系统启动时会启用和启动 syslogd。
本节介绍了如何配置 FreeBSD 系统日志记录器以进行本地和远程日志记录,以及如何执行日志轮转和日志管理。
14.5.1. 配置本地日志记录
配置文件 /etc/syslog.conf 控制着 syslogd 在接收到日志条目时的处理方式。有几个参数用于控制处理传入事件的方式。facility 描述了生成消息的子系统,例如内核或守护进程,而 level 描述了发生事件的严重程度。这使得可以根据 facility 和 level 配置是否以及在哪里记录日志消息。还可以根据发送消息的应用程序以及远程日志记录的情况下生成日志事件的机器的主机名来采取行动。
该配置文件每行包含一个操作,每行的语法是选择器字段后跟一个操作字段。选择器字段的语法是 facility.level,它将匹配 facility 在 level 或更高级别的日志消息。还可以在级别之前添加一个可选的比较标志,以更精确地指定记录的内容。可以为同一个操作使用多个选择器字段,并用分号 (;) 分隔。使用 * 将匹配所有内容。操作字段表示将日志消息发送到何处,例如文件或远程日志主机。
以下是 FreeBSD 的默认 /etc/syslog.conf 示例:
# $FreeBSD$ # # Spaces ARE valid field separators in this file. However, # other *nix-like systems still insist on using tabs as field # separators. If you are sharing this file between systems, you # may want to use only tabs as field separators here. # Consult the syslog.conf(5) manpage. *.err;kern.warning;auth.notice;mail.crit /dev/console (1) *.notice;authpriv.none;kern.debug;lpr.info;mail.crit;news.err /var/log/messages security.* /var/log/security auth.info;authpriv.info /var/log/auth.log mail.info /var/log/maillog (2) cron.* /var/log/cron !-devd *.=debug /var/log/debug.log (3) *.emerg * daemon.info /var/log/daemon.log # uncomment this to log all writes to /dev/console to /var/log/console.log # touch /var/log/console.log and chmod it to mode 600 before it will work #console.info /var/log/console.log # uncomment this to enable logging of all log messages to /var/log/all.log # touch /var/log/all.log and chmod it to mode 600 before it will work #*.* /var/log/all.log # uncomment this to enable logging to a remote loghost named loghost #*.* @loghost # uncomment these if you're running inn # news.crit /var/log/news/news.crit # news.err /var/log/news/news.err # news.notice /var/log/news/news.notice # Uncomment this if you wish to see messages produced by devd # !devd # *.>=notice /var/log/devd.log (4) !* include /etc/syslog.d include /usr/local/etc/syslog.d
| 1 | 匹配所有级别为 err 或更高的消息,以及 kern.warning、auth.notice 和 mail.crit ,并将这些日志消息发送到控制台(/dev/console)。 <.> 匹配所有级别为 info 或更高的 mail 设施的消息,并将这些消息记录到 /var/log/maillog 。 <.> 使用比较标志(=)仅匹配级别为 debug 的消息,并将其记录到 /var/log/debug.log 。 <.> 是程序规范的示例用法。这使得其后的规则仅对指定的程序有效。在这种情况下,只有由 devd(8) 生成的消息被记录到 /var/log/devd.log 。 |
有关 /etc/syslog.conf 的更多信息,包括其语法和更高级的用法示例,请参阅 syslog.conf(5)。
14.5.2. 日志记录设施
设施描述了系统生成消息的部分。设施是一种将不同的消息分开的方式,以便用户更容易查阅日志。
| 名称 | 描述 |
|---|---|
认证 |
|
authpriv |
与 auth 相同,但日志记录到一个只有 root 用户可读的文件中。 |
console |
由内核控制台输出驱动程序写入到 /dev/console 的消息。 |
cron |
由 cron(8) 守护进程编写的消息。 |
daemon |
系统守护进程,例如 routed(8),这些进程不是由其他设施明确提供的。 |
ftp |
|
kern |
由内核生成的消息。这些消息不能由任何用户进程生成。 |
lpr |
|
邮件系统。 |
|
mark |
该设施每 20 分钟添加一条记录。 |
news |
网络新闻系统。 |
ntp |
网络时间协议系统。 |
security |
安全子系统,如 ipfw(4)。 |
syslog |
man:syslogd(8) 内部生成的消息。 |
user |
由随机用户进程生成的消息。如果未指定,则为默认的设施标识符。 |
uucp |
Unix 到 Unix 复制系统。一个古老的协议。真的很奇怪看到来自这个设施的消息。 |
local0 through local7 |
保留供本地使用。 |
14.5.3. 日志级别
级别描述了消息的严重程度,并且是以下有序列表中的关键字(从高到低):
| 名称 | 描述 |
|---|---|
emerg |
一种恐慌的情况。通常会向所有用户广播。 |
alert |
应立即纠正的条件,例如系统数据库损坏。 |
crit |
关键条件,例如硬件设备错误。 |
err |
错误。 |
warning |
警告信息。 |
notice |
不是错误条件,但可能需要特殊处理的条件。 |
info |
信息性消息。 |
debug |
包含通常仅在调试程序时有用的信息的消息。 |
none |
这个特殊级别禁用了一个特定的功能。 |
14.5.4. 阅读日志消息
通常日志具有以下语法:
date time hostname program[pid]: the message
将使用 /var/log/cron 文件的输出作为示例:
[...] Jul 16 12:40:00 FreeBSD /usr/sbin/cron[81519]: (root) CMD (/usr/libexec/atrun) Jul 16 12:44:00 FreeBSD /usr/sbin/cron[83072]: (operator) CMD (/usr/libexec/save-entropy) [...]
可以通过运行以下命令在 syslog(8) 中启用详细日志记录,这样每条消息的设施和级别都会被添加:
# sysrc syslogd_flags="-vv"一旦函数被激活,设施和级别将会在日志中显示,如下面的示例所示:
[...] Jul 16 17:40:00 <cron.info> FreeBSD /usr/sbin/cron[1016]: (root) CMD (/usr/libexec/atrun) Jul 16 17:44:00 <cron.info> FreeBSD /usr/sbin/cron[1030]: (operator) CMD (/usr/libexec/save-entropy) [...]
14.5.5. 日志管理和轮转
日志文件可以快速增长,占用磁盘空间,并且使得查找有用信息变得更加困难。
在 FreeBSD 中,newsyslog(8) 用于管理日志文件并尝试减轻这个问题。
这个内置程序定期轮转和压缩日志文件,并可选择创建丢失的日志文件,并在日志文件移动时向程序发送信号。
以下是 FreeBSD 中的默认配置,在 newsyslog.conf(5) 中可以找到更多信息:
# configuration file for newsyslog # $FreeBSD$ # # Entries which do not specify the '/pid_file' field will cause the # syslogd process to be signalled when that log file is rotated. This # action is only appropriate for log files which are written to by the # syslogd process (ie, files listed in /etc/syslog.conf). If there # is no process which needs to be signalled when a given log file is # rotated, then the entry for that file should include the 'N' flag. # # Note: some sites will want to select more restrictive protections than the # defaults. In particular, it may be desirable to switch many of the 644 # entries to 640 or 600. For example, some sites will consider the # contents of maillog, messages, and lpd-errs to be confidential. In the # future, these defaults may change to more conservative ones. # # logfilename [owner:group] mode count size when flags [/pid_file] [sig_num] /var/log/all.log 600 7 * @T00 J /var/log/auth.log 600 7 1000 @0101T JC /var/log/console.log 600 5 1000 * J /var/log/cron 600 3 1000 * JC /var/log/daily.log 640 7 * @T00 JN /var/log/debug.log 600 7 1000 * JC /var/log/init.log 644 3 1000 * J /var/log/kerberos.log 600 7 1000 * J /var/log/maillog 640 7 * @T00 JC /var/log/messages 644 5 1000 @0101T JC /var/log/monthly.log 640 12 * $M1D0 JN /var/log/devd.log 644 3 1000 * JC /var/log/security 600 10 1000 * JC /var/log/utx.log 644 3 * @01T05 B /var/log/weekly.log 640 5 * $W6D0 JN /var/log/daemon.log 644 5 1000 @0101T JC <include> /etc/newsyslog.conf.d/[!.]*.conf <include> /usr/local/etc/newsyslog.conf.d/[!.]*.conf
-
logfilename- 要归档的系统日志文件的名称。 -
[owner:group]- 这个可选字段指定了存档文件的所有者和组。 -
mode- 指定日志文件和归档文件的文件模式。有效的模式位是 0666 (即,可以为所有者、组和其他用户指定旋转日志的读写权限)。 -
count- 指定允许存在的归档文件的最大数量。 -
size- 当日志文件的大小达到指定的大小(以千字节为单位)时,将按照上述描述进行修剪。如果该字段包含星号('*'),则不会根据大小来修剪日志文件。 -
when- 由一个时间间隔、一个特定时间或两者组成。在 newsyslog.conf(5) 中支持的选项。 -
flags- 表示 newsyslog 接受的标志,newsyslog.conf(5) 中支持的选项。 -
[/pid_file]- 这个可选字段指定包含守护进程的进程 ID 或查找进程组 ID 的文件名。 -
[sig_num]- 这个可选字段指定将发送给守护进程的信号。
|
最后两个字段是可选的,用于指定进程的进程 ID(PID)文件的名称以及在文件轮转时发送给该进程的信号编号。 |
14.5.6. 配置远程日志记录
随着系统数量的增加,监控多个主机的日志文件可能变得难以管理。配置集中式日志记录可以减轻一些日志文件管理的行政负担。
在 FreeBSD 中,可以使用 syslogd 和 newsyslog 来配置集中式日志文件聚合、合并和轮转。
本节演示了一个示例配置,其中主机 A,名为 logserv.example.com,将收集本地网络的日志信息。
主机 B,名为 logclient.example.com,将被配置为将日志信息传递给日志服务器。
14.5.6.1. 日志服务器配置
日志服务器是一个已配置好的系统,用于接收来自其他主机的日志信息。
在配置日志服务器之前,请检查以下内容:
-
如果在日志服务器和任何日志客户端之间存在防火墙,请确保防火墙规则集允许客户端和服务器的 UDP 端口 514。
-
日志服务器和所有客户端机器必须在本地 DNS 中具有正向和反向条目。如果网络没有 DNS 服务器,请在每个系统的 /etc/hosts 中创建条目。正确的名称解析是必需的,以便日志条目不会被日志服务器拒绝。
在日志服务器上,编辑 /etc/syslog.conf 文件,指定要接收日志条目的客户端名称,要使用的日志设施以及存储主机日志条目的日志名称。此示例将主机名 B 添加到日志中,记录所有设施,并将日志条目存储在 /var/log/logclient.log 文件中。
例 22. 示例日志服务器配置
+logclient.example.com *.* /var/log/logclient.log
当添加多个日志客户端时,为每个客户端添加类似的两行条目。有关可用设施的更多信息,请参阅 syslog.conf(5)。
接下来,执行以下命令:
# sysrc syslogd_enable="YES"
# sysrc syslogd_flags="-a logclient.example.com -v -v"第一条条目在系统启动时启动 syslogd 。第二条条目允许来自指定客户端的日志条目。 -v -v 增加了日志消息的详细程度。这对于调整设施非常有用,因为管理员可以看到每个设施下记录了什么类型的消息。
可以指定多个 -a 选项来允许从多个客户端进行日志记录。还可以指定 IP 地址和整个网络块。有关可能选项的完整列表,请参阅 syslogd(8)。
最后,创建日志文件:
# touch /var/log/logclient.log此时,应重新启动并验证 syslogd :
# service syslogd restart
# pgrep syslog如果返回了一个 PID,则表示服务器成功重启,可以开始客户端配置。如果服务器没有重启,请查看错误信息,请参考 /var/log/messages 文件。
14.5.6.2. 日志客户端配置
一个日志客户端将日志条目发送到网络上的日志服务器。客户端还保留了自己日志的本地副本。
一旦配置了日志服务器,就在日志客户端上执行以下命令:
# sysrc syslogd_enable="YES"
# sysrc syslogd_flags="-s -v -v"第一项启用了系统启动时的 syslogd。第二项阻止其他主机向此客户端接受日志(-s),并增加了日志消息的详细程度。
接下来,在客户端的 /etc/syslog.conf 文件中定义日志服务器。在这个例子中,所有记录的设施都会被发送到一个远程系统,用 @ 符号表示,并指定主机名:
*.* @logserv.example.com
保存编辑后,重新启动 syslogd 以使更改生效:
# service syslogd restart为了测试日志消息是否通过网络发送,可以在客户端使用 logger(1) 命令向 syslogd 发送一条消息。
# logger "Test message from logclient"此消息现在应该同时存在于客户端的 /var/log/messages 和日志服务器的 /var/log/logclient.log 中。
14.5.6.3. 调试日志服务器
如果日志服务器上没有接收到任何消息,原因很可能是网络连接问题、主机名解析问题或配置文件中的拼写错误。为了确定原因,确保日志服务器和日志客户端都能够使用它们在 /etc/rc.conf 中指定的主机名相互 ping。如果失败,请检查网络电缆、防火墙规则集以及 DNS 服务器或日志服务器和客户端上的 /etc/hosts 中的主机名条目。重复此过程,直到从两个主机都成功 ping。
如果在两台主机上都成功执行了 ping 命令,但仍然无法接收到日志消息,则可以暂时增加日志的详细程度以缩小配置问题的范围。在下面的示例中,日志服务器上的 /var/log/logclient.log 文件为空,而日志客户端上的 /var/log/messages 文件没有显示失败的原因。
为了增加调试输出,编辑日志服务器上的 syslogd_flags 条目并执行重启操作:
sysrc syslogd_flags="-d -a logclient.example.com -v -v"# service syslogd restart在重新启动后,类似以下的调试数据将立即在控制台上闪现:
logmsg: pri 56, flags 4, from logserv.example.com, msg syslogd: restart syslogd: restarted logmsg: pri 6, flags 4, from logserv.example.com, msg syslogd: kernel boot file is /boot/kernel/kernel Logging to FILE /var/log/messages syslogd: kernel boot file is /boot/kernel/kernel cvthname(192.168.1.10) validate: dgram from IP 192.168.1.10, port 514, name logclient.example.com; rejected in rule 0 due to name mismatch.
在这个例子中,由于一个拼写错误导致日志消息被拒绝,从而导致主机名不匹配。客户端的主机名应该是 logclient,而不是 logclien。修复拼写错误,重新启动,并验证结果。
# service syslogd restart输出应该类似于以下内容:
logmsg: pri 56, flags 4, from logserv.example.com, msg syslogd: restart syslogd: restarted logmsg: pri 6, flags 4, from logserv.example.com, msg syslogd: kernel boot file is /boot/kernel/kernel syslogd: kernel boot file is /boot/kernel/kernel logmsg: pri 166, flags 17, from logserv.example.com, msg Dec 10 20:55:02 <syslog.err> logserv.example.com syslogd: exiting on signal 2 cvthname(192.168.1.10) validate: dgram from IP 192.168.1.10, port 514, name logclient.example.com; accepted in rule 0. logmsg: pri 15, flags 0, from logclient.example.com, msg Dec 11 02:01:28 trhodes: Test message 2 Logging to FILE /var/log/logclient.log Logging to FILE /var/log/messages
目前,消息已经被正确接收并放置在正确的文件中。
14.5.6.4. 安全考虑
与任何网络服务一样,在实施日志服务器之前应考虑安全要求。日志文件可能包含有关本地主机上启用的服务、用户帐户和配置数据的敏感信息。从客户端发送到服务器的网络数据将不会进行加密或密码保护。如果需要加密,请考虑使用 security/stunnel,它将通过加密隧道传输日志数据。
本地安全性也是一个问题。日志文件在使用过程中或在日志轮换后都没有加密。本地用户可以访问日志文件以获取有关系统配置的更多信息。在日志文件上设置适当的权限至关重要。内置的日志轮换程序 newsyslog 支持在新创建和轮换的日志文件上设置权限。将日志文件设置为 600 模式应该可以防止本地用户的非法访问。有关更多信息,请参阅 newsyslog.conf(5) 。
14.6. 功耗和资源管理
高效利用硬件资源是非常重要的。功耗和资源管理使操作系统能够监控系统限制,并可能根据与这些限制相关的事件运行一些操作。
14.6.1. ACPI 配置
在 FreeBSD 上,这些资源的管理由 acpi(4) 内核设备管理。
|
在 FreeBSD 中,默认情况下,在系统启动时加载 acpi(4) 驱动程序。 由于系统总线在各种硬件交互中使用该驱动程序,因此此驱动程序在引导后 无法卸载。 |
除了 acpi(4) 之外,FreeBSD 还有几个专门的内核模块用于各种 ACPI 供应商子系统。这些模块将添加一些额外的功能,如风扇速度、键盘背光或屏幕亮度。
可以通过运行以下命令获取列表:
% ls /boot/kernel | grep acpi输出应该类似于以下内容:
acpi_asus.ko acpi_asus_wmi.ko acpi_dock.ko acpi_fujitsu.ko acpi_hp.ko acpi_ibm.ko acpi_panasonic.ko acpi_sony.ko acpi_toshiba.ko acpi_video.ko acpi_wmi.ko sdhci_acpi.ko uacpi.ko
例如,如果使用 IBM/Lenovo 笔记本电脑,则需要通过执行以下命令加载模块 acpi_ibm(4):
# kldload acpi_ibm并将以下行添加到 /boot/loader.conf 文件中,以在启动时加载它:
acpi_ibm_load="YES"
acpi_video(4) 模块的替代方案是 backlight(9) 驱动程序。它提供了一种通用的处理面板背光的方式。默认的 GENERIC 内核包含了这个驱动程序。backlight(8) 实用程序可用于查询和调整面板背光的亮度。在这个示例中,亮度减少了 10% :
% backlight decr 1014.6.2. CPU 功耗管理
CPU 是系统中最消耗资源的部分。了解如何提高 CPU 效率是我们系统中节省能源的基本部分。
为了正确地充分利用机器的资源,FreeBSD 通过使用 powerd(8) 和 cpufreq[4] 等技术来支持诸如 Intel Turbo Boost、AMD Turbo Core、Intel Speed Shift 等技术。
第一步是通过执行以下命令来获取 CPU 信息:
% sysctl dev.cpu.0 (1)在这种情况下,数字 0 代表 CPU 的第一个核心。
输出应该类似于以下内容:
dev.cpu.0.cx_method: C1/mwait/hwc C2/mwait/hwc C3/mwait/hwc/bma dev.cpu.0.cx_usage_counters: 3507294 0 0 dev.cpu.0.cx_usage: 100.00% 0.00% 0.00% last 3804us dev.cpu.0.cx_lowest: C3 (1) dev.cpu.0.cx_supported: C1/1/1 C2/2/1 C3/3/57 (2) dev.cpu.0.freq_levels: 2267/35000 2266/35000 1600/15000 800/12000 (3) dev.cpu.0.freq: 1600 (4) dev.cpu.0.temperature: 40.0C (5) dev.cpu.0.coretemp.throttle_log: 0 dev.cpu.0.coretemp.tjmax: 105.0C dev.cpu.0.coretemp.resolution: 1 dev.cpu.0.coretemp.delta: 65 dev.cpu.0.%parent: acpi0 dev.cpu.0.%pnpinfo: _HID=none _UID=0 _CID=none dev.cpu.0.%location: handle=\_PR_.CPU0 dev.cpu.0.%driver: cpu dev.cpu.0.%desc: ACPI CPU
| 1 | 用于使 CPU 处于空闲状态的最低 Cx 状态。 |
| 2 | CPU 支持的 Cx 状态。 |
| 3 | 当前可用的 CPU 级别(频率 / 功耗)。 |
| 4 | 当前活动的 CPU 频率(以 MHz 为单位)。 |
| 5 | CPU 的当前温度。 |
|
如果温度信息未显示,请加载 coretemp(4) 模块。如果使用 AMD CPU,请加载 amdtemp(4) 模块。 |
一旦 CPU 信息可用,配置节能的最简单方法是让 powerd(8) 接管。
在 /etc/rc.conf 中启用 powerd(8) 服务,使其在系统启动时启动:
# sysrc powerd_enable=YES还需要向 powerd(8) 指定一些参数,以告诉它如何管理执行以下命令的 CPU 的状态:
# sysrc powerd_flags="-a hiadaptive -i 25 -r 85 -N"-
-a:选择在交流电源下使用的模式。 -
hiadaptive:操作模式。更多信息请参考 powerd(8)。 -
-i:指定当自适应模式开始降低性能以节省电力时的 CPU 负载百分比水平。 -
-r:指定自适应模式应该考虑 CPU 运行并提高性能的 CPU 负载百分比水平。 -
-N:将“nice”时间视为空闲时间,用于负载计算;即,如果 CPU 仅忙于“nice”进程,则不增加 CPU 频率。
然后执行以下命令启用服务:
# service powerd start14.6.3. CPU 频率控制
FreeBSD 包含一个通用的 cpufreq(4) 驱动程序,允许管理员或者像 powerd(8) 和 sysutils/powerdxx 这样的软件来管理 CPU 的频率,以实现性能和经济之间的理想平衡。降低设置可以节省电力,同时减少 CPU 产生的热量。提高设置可以增加性能,但会消耗额外的电力并产生更多的热量。
14.6.4. Intel® Enhanced Speed Step™
Intel® Enhanced Speed Step™ 驱动程序,est(4),用于替代提供此功能的 CPU 的通用 cpufreq(4) 驱动程序。可以使用 sysctl(8) 或 /etc/rc.d/power_profile 启动脚本静态调整 CPU 频率。还可以使用 powerd(8) 或 sysutils/powerdxx 等其他软件根据处理器利用率自动调整 CPU 频率。
可以通过检查 sysctl(3) 树来列出每个支持的频率及其预期的功耗。
# sysctl dev.cpufreq.0.freq_driver dev.cpu.0.freq_levels dev.cpu.0.freq输出应该类似于以下内容:
dev.cpufreq.0.freq_driver: est0 dev.cpu.0.freq_levels: 3001/53000 3000/53000 2900/50301 2700/46082 2600/43525 2400/39557 2300/37137 2100/33398 2000/31112 1800/27610 1700/25455 1500/22171 1400/20144 1200/17084 1100/15181 900/12329 800/10550 dev.cpu.0.freq: 800
CPU 的最大频率加 1 MHz 表示 Intel® Turbo Boost™ 功能。
14.6.5. Intel Speed Shift™
运行较新的 Intel® CPU 的用户在升级到 FreeBSD 13 时可能会发现动态频率控制方面存在一些差异。针对某些 SKU 可用的 Intel® Speed Shift™ 功能集,提供了一种新的驱动程序,可以使硬件能够动态地变化核心频率,包括每个核心的频率。FreeBSD 13 配备了 hwpstate_intel(4) 驱动程序,可以自动启用配备了 Speed Shift™ 控制功能的 CPU,取代了较旧的 Enhanced Speed Step™ est(4) 驱动程序。sysctl(8) dev.cpufreq.%d.freq_driver 将指示系统是否正在使用 Speed Shift。
要确定正在使用哪个频率控制驱动程序,请检查 dev.cpufreq.0.freq_driver oid 。
# sysctl dev.cpufreq.0.freq_driver输出应该类似于以下内容:
dev.cpufreq.0.freq_driver: hwpstate_intel0
这表示正在使用新的 hwpstate_intel(4) 驱动程序。在这种系统上,oid dev.cpu.%d.freq_levels 只会显示最大的 CPU 频率,并且会显示一个功耗级别为 -1。
可以通过检查 dev.cpu.%d.freq oid 来确定当前的 CPU 频率。
# sysctl dev.cpu.0.freq_levels dev.cpu.0.freq输出应该类似于以下内容:
dev.cpu.0.freq_levels: 3696/-1 dev.cpu.0.freq: 898
有关更多信息,包括如何平衡性能和能源使用,以及如何禁用此驱动程序,请参阅手册页面 hwpstate_intel(4)。
|
习惯使用 powerd(8) 或 sysutils/powerdxx 的用户会发现这些实用程序已被 hwpstate_intel(4) 驱动程序取代,并且不再按预期工作。 |
14.6.6. 图形卡功耗管理
近年来,显卡已成为计算机的基本组成部分。一些显卡可能具有过高的功耗。FreeBSD 允许进行某些配置以改善功耗。
如果使用 Intel® 显卡与 graphics/drm-kmod 驱动程序,可以将以下选项添加到 /boot/loader.conf 文件中:
compat.linuxkpi.fastboot=1 (1) compat.linuxkpi.enable_dc=2 (2) compat.linuxkpi.enable_fbc=1 (3)
| 1 | 尝试在启动时跳过不必要的模式设置。 <.> 启用省电显示 C 状态。 <.> 启用帧缓冲压缩以节省电量。 |
14.6.7. 挂起/恢复
挂起/恢复功能允许机器保持在低能耗状态,并且在不丢失运行程序状态的情况下恢复系统。
|
为了使挂起/恢复功能正常工作,必须在系统上加载图形驱动程序。在不支持 KMS 的图形卡上,必须使用 sc(4) 来避免破坏挂起/恢复功能。 有关使用哪个驱动程序以及如何配置它的更多信息,请参阅 X Window 系统章节。 |
acpi(4) 支持以下睡眠状态的列表:
| S1 | 快速挂起到 RAM。CPU 进入较低的功耗状态,但大多数外设仍然保持运行。 |
|---|---|
S2 |
比 S1 更低的功耗状态,但具有相同的基本特征。不被许多系统支持。 |
S3 (Sleep mode) |
挂起到 RAM。大多数设备都关闭电源,系统停止运行,只进行内存刷新。 |
S4 (Hibernation) |
磁盘挂起。所有设备都被关闭,系统停止运行。在恢复时,系统会像从冷启动一样启动。FreeBSD 尚不支持此功能。 |
S5 |
系统正常关闭并关闭电源。 |
14.6.7.1. 配置挂起/恢复
第一步是要知道我们正在使用的硬件支持哪种类型的睡眠状态,执行以下命令:
% sysctl hw.acpi.supported_sleep_state输出应该类似于以下内容:
hw.acpi.supported_sleep_state: S3 S4 S5
|
如上所述, FreeBSD 目前 不支持 |
acpiconf(8) 可以通过运行以下命令来检查 S3 状态是否正常工作,如果成功,屏幕应该变黑,机器将关闭:
# acpiconf -s 3在绝大多数情况下,挂起/恢复功能是用于笔记本电脑的。
在关闭笔记本盖子时,可以通过在 /etc/sysctl.conf 文件中添加以下行来配置 FreeBSD 进入 S3 状态。
hw.acpi.lid_switch_state=S3
14.6.7.2. 挂起/恢复的故障排除
为了使 FreeBSD 上的挂起和恢复功能正常工作并以最佳方式运行,已经付出了很多努力。但目前,挂起和恢复功能只在一些特定的笔记本电脑上正常工作。
如果它无法正常工作,可以进行一些检查。
在某些情况下,关闭蓝牙就足够了。在其他情况下,只需加载正确的显卡驱动程序等即可。
如果它不能正常工作,可以在 FreeBSD Wiki 的 Suspend/Resume 部分找到一些提示。
14.7. 添加交换空间
有时候 FreeBSD 系统需要更多的交换空间。本节介绍了两种增加交换空间的方法:在现有分区或新硬盘上添加交换空间,以及在现有文件系统上创建交换文件。
有关如何加密交换空间、存在哪些选项以及为什么应该这样做的信息,请参考 “加密交换空间”。
14.7.1. 在新硬盘或现有分区上进行交换
|
可以使用任何当前未挂载的分区,即使它已经包含数据。在包含数据的分区上使用 |
swapon(8) 可以用于向执行以下命令的系统添加交换分区:
# swapon /dev/ada1p2要在启动时自动添加此交换分区,请在 /etc/fstab 中添加一个条目:
/dev/ada1p2 none swap sw 0 0
请参阅 fstab(5),了解 /etc/fstab 中条目的解释。
14.7.2. 创建交换文件
这些示例创建一个名为 /usr/swap0 的 512M 交换文件。
|
强烈不建议在 ZFS 文件系统上使用交换文件,因为交换可能导致系统挂起。 |
第一步是创建交换文件:
# dd if=/dev/zero of=/usr/swap0 bs=1m count=512第二步是给新文件设置适当的权限:
# chmod 0600 /usr/swap0第三步是通过在 /etc/fstab 中添加一行来通知系统关于交换文件的信息:
md none swap sw,file=/usr/swap0,late 0 0
系统启动时将添加交换空间。要立即添加交换空间,请使用 swapon(8) 命令。
# swapon -aLChapter 15. FreeBSD 的引导过程
15.1. 简介
启动计算机并加载操作系统的过程被称为“引导过程”或“引导”。 FreeBSD 的引导过程提供了很大的灵活性,可以自定义系统启动时发生的事情,包括选择在同一台计算机上安装的不同操作系统、同一操作系统的不同版本或不同的内核。
本章详细介绍了可以设置的配置选项。它演示了如何自定义 FreeBSD 的启动过程,包括在 FreeBSD 内核启动、设备探测和 init(8) 启动之前发生的所有事情。这发生在启动消息的文本颜色从亮白色变为灰色时。
阅读完本章后,您将会认识到:
-
FreeBSD 引导系统的组件及其相互作用方式。
-
可以传递给 FreeBSD 引导程序中组件的选项,以控制引导过程。
-
设置设备提示的基础知识。
-
如何进入单用户模式和多用户模式,以及如何正确关闭 FreeBSD 系统。
|
本章仅描述在 x86 和 amd64 系统上运行的 FreeBSD 的引导过程。 |
15.2. FreeBSD 引导过程
打开计算机并启动操作系统会带来一个有趣的困境。根据定义,计算机在启动操作系统之前不知道如何执行任何操作,包括从磁盘运行程序。如果计算机没有操作系统就无法从磁盘运行程序,而操作系统的程序又存储在磁盘上,那么操作系统是如何启动的呢?
这个问题与《巴伦·门舒森的冒险》一书中的一个问题相似。一个角色在一个井盖上卡住了一半身子,他通过抓住自己的靴带并抬起来自救。在计算机的早期,术语 引导(bootstrap) 被用来指代加载操作系统的机制。后来,这个术语被缩短为“引导(booting)”。
在 x86 硬件上,基本输入/输出系统(BIOS)负责加载操作系统。BIOS 在硬盘上查找主引导记录(MBR),该记录必须位于硬盘的特定位置。BIOS 具有足够的知识来加载和运行 MBR,并假设 MBR 可以完成加载操作系统的其余任务,可能需要 BIOS 的帮助。
|
FreeBSD 支持从旧的 MBR 标准和新的 GUID 分区表(GPT)进行引导。GPT 分区通常在具有统一可扩展固件接口(UEFI)的计算机上找到。然而,即使在只有传统 BIOS 的机器上,FreeBSD 也可以从 GPT 分区引导,使用 gptboot(8) 。目前正在进行直接支持 UEFI 引导的工作。 |
MBR 中的代码通常被称为“引导管理器”,特别是当它与用户交互时。引导管理器通常在磁盘的第一个磁道或文件系统中有更多的代码。引导管理器的示例包括标准的 FreeBSD 引导管理器 boot0,也称为 Boot Easy,以及 GNU GRUB,它被许多 Linux® 发行版使用。
|
GRUB 的用户应参考 GNU 提供的文档。 |
如果只安装了一个操作系统,MBR 会搜索磁盘上第一个可引导(活动的)分区,并运行该分区上的代码来加载操作系统的其余部分。当存在多个操作系统时,可以安装不同的引导管理器来显示操作系统列表,以便用户可以选择要引导的操作系统。
FreeBSD 引导系统的剩余部分分为三个阶段。第一阶段只需知道让计算机进入特定状态并运行第二阶段即可。第二阶段可以做更多的事情,然后运行第三阶段。第三阶段完成加载操作系统的任务。将工作分为三个阶段是因为 MBR 对可以在第一和第二阶段运行的程序的大小有限制。将任务链接在一起使 FreeBSD 能够提供更灵活的加载程序。
然后启动内核,并开始探测设备并初始化它们以供使用。一旦内核引导过程完成,内核将控制权交给用户进程 init(8),该进程确保磁盘处于可用状态,启动用户级资源配置以挂载文件系统,设置网络卡以进行网络通信,并启动已配置为在启动时运行的进程。
本节将更详细地描述这些阶段,并演示如何与 FreeBSD 引导过程进行交互。
15.2.1. 引导管理器
MBR 中的引导管理器代码有时被称为引导过程的 零阶段。默认情况下,FreeBSD 使用 boot0 引导管理器。
FreeBSD 安装程序安装的 MBR 基于 /boot/boot0。由于 slice 表和 MBR 末尾的 0x55AA 标识符, boot0 的大小和功能被限制为 446 字节。如果安装了 boot0 和多个操作系统,则在启动时会显示类似于以下示例的消息:
例 23. boot0 截图
F1 Win
F2 FreeBSD
Default: F2如果在 FreeBSD 之后安装其他操作系统,它们将覆盖现有的 MBR。如果发生这种情况,或者要用 FreeBSD 的 MBR 替换现有的 MBR ,请使用以下命令:
# fdisk -B -b /boot/boot0 device其中 device 是引导磁盘,例如 ad0 表示第一个 IDE 磁盘,ad2 表示第二个 IDE 控制器上的第一个 IDE 磁盘,或者 da0 表示第一个 SCSI 磁盘。要创建自定义的 MBR 配置,请参考 boot0cfg(8)。
15.2.2. 第一阶段和第二阶段
从概念上讲,第一阶段和第二阶段是同一个程序在磁盘的同一个区域的一部分。由于空间限制,它们被分成两部分,但总是一起安装的。它们是由 FreeBSD 安装程序或 bsdlabel 从组合的 /boot/boot 复制而来。
这两个阶段位于文件系统之外,在引导 slice 的第一个磁道上,从第一个扇区开始。这是 boot0 或任何其他引导管理器期望找到一个程序来继续引导过程的位置。
第一阶段,boot1,非常简单,因为它的大小只能是 512 字节。它对 FreeBSD 的 bsdlabel 有一定了解,该标签存储有关分区的信息,以便找到并执行 boot2。
第二阶段,boot2,稍微复杂一些,足够理解 FreeBSD 文件系统以找到文件。它可以提供一个简单的界面来选择要运行的内核或加载程序。它运行加载程序,加载程序更加复杂,并提供一个引导配置文件。如果在第二阶段中断了引导过程,将显示以下交互式屏幕:
例 24. boot2 截图
>> FreeBSD/i386 BOOT
Default: 0:ad(0,a)/boot/loader
boot:要替换已安装的 boot1 和 boot2 ,请使用 bsdlabel 命令,其中 diskslice 是要从中引导的磁盘和分区,例如 ad0s1 表示第一个 IDE 磁盘上的第一个分区。
# bsdlabel -B diskslice|
如果只使用磁盘名称,例如 ad0, |
15.2.3. 第三阶段
加载器是三阶段引导过程的最后阶段。它位于文件系统上,通常是作为 /boot/loader 文件。
加载器旨在作为一种交互式的配置方法,使用内置的命令集,并由更强大的解释器支持,该解释器具有更复杂的命令集。
在初始化过程中,加载器将探测控制台和磁盘,并确定正在引导的磁盘。它将相应地设置变量,并启动一个解释器,用户可以通过脚本或交互方式传递命令。
然后,加载程序将读取 /boot/loader.rc 文件,默认情况下会读取 /boot/defaults/loader.conf 文件,该文件为变量设置了合理的默认值,并读取 /boot/loader.conf 文件以获取对这些变量的本地更改。loader.rc 文件会根据这些变量的设置加载所选的模块和内核。
最后,默认情况下,加载程序会等待 10 秒钟以等待按键操作,如果没有被中断,则启动内核。如果被中断,用户将会看到一个理解命令集的提示符,用户可以在其中调整变量、卸载所有模块、加载模块,最后进行启动或重新启动操作。 加载器内置命令 列出了最常用的加载程序命令。有关所有可用命令的完整讨论,请参阅 loader(8)。
| 变量 | 描述 |
|---|---|
autoboot seconds |
如果在给定的时间范围内(以秒为单位)没有被中断,将继续启动内核。它会显示一个倒计时,而默认的时间范围是 10 秒。 |
boot [ |
立即启动内核,使用指定的选项或内核名称。在执行 |
boot-conf |
根据指定的变量,自动配置模块,通常是 |
help [ |
显示从 /boot/loader.help 读取的帮助信息。如果给定的主题是 |
include |
读取指定的文件,并逐行解释。一旦出现错误, |
` |
加载给定类型的内核、内核模块或文件,使用指定的文件名。filename 后的任何参数都将传递给该文件。如果 filename 没有限定,将在 /boot/kernel 和 /boot/modules 下进行搜索。 |
ls [-l] [ |
显示给定路径中的文件列表,如果未指定路径,则显示根目录。如果指定了 |
lsdev [ |
列出所有可能加载模块的设备。如果指定了 |
lsmod [ |
显示已加载的模块。如果指定了 |
more |
显示指定的文件,在每个显示的 |
reboot |
立即重新启动系统。 |
set |
设置指定的环境变量。 |
unload |
移除所有已加载的模块。 |
以下是一些加载器使用的实际示例。要以单用户模式启动常规内核:
boot -s卸载常规的内核和模块,然后加载先前的或另一个指定的内核:
unload
load /path/to/kernelfile使用限定的 /boot/GENERIC/kernel 来引用安装时默认的内核,或者使用 /boot/kernel.old/kernel 来引用在系统升级或配置自定义内核之前先前安装的内核。
使用以下内容在另一个内核中加载常用模块。请注意,在这种情况下,不需要使用限定名称:
unload
set kernel="mykernel"
boot-conf加载自动化内核配置脚本的方法:
load -t userconfig_script /boot/kernel.conf15.2.4. 最后阶段
一旦内核被加载,无论是由引导程序还是由绕过引导程序的 boot2 加载,它都会检查任何引导标志并根据需要调整其行为。 引导过程中的内核交互 列出了常用的引导标志。有关其他引导标志的更多信息,请参阅 boot(8)。
| 选项 | 描述 |
|---|---|
|
在内核初始化期间,请求设备作为根文件系统进行挂载。 |
|
从 CDROM 引导根文件系统。 |
|
进入单用户模式。 |
|
在内核启动过程中增加更多的详细信息。 |
一旦内核启动完成,它将控制权交给用户进程 init(8),该进程位于 /sbin/init 或者在 loader 中的 init_path 变量指定的程序路径。这是引导过程的最后阶段。
引导序列确保系统上可用的文件系统是一致的。如果 UFS 文件系统不一致,并且 fsck 无法修复不一致性,init 会将系统切换到单用户模式,以便系统管理员可以直接解决问题。否则,系统将启动到多用户模式。
15.2.4.1. 单用户模式
用户可以通过使用 -s 参数启动或在引导程序中设置 boot_single 变量来指定此模式。也可以通过在多用户模式下运行 shutdown now 命令来进入此模式。单用户模式从以下消息开始:
Enter full pathname of shell or RETURN for /bin/sh:
如果用户按下 Enter 键,系统将进入默认的 Bourne shell 。要指定不同的 shell,请输入 shell 的完整路径。
单用户模式通常用于修复由于不一致的文件系统或引导配置文件错误而无法启动的系统。它还可以用于在未知情况下重置 root 密码。由于单用户模式提示符提供对系统及其配置文件的完全本地访问权限,因此可以执行这些操作。在此模式下没有网络连接。
单用户模式在修复系统时非常有用,但如果系统不在物理安全的位置,它会带来安全风险。默认情况下,任何能够物理访问系统的用户在进入单用户模式后将完全控制该系统。
如果在 /etc/ttys 文件中将系统的 console 设置为 insecure,系统将在启动单用户模式之前首先提示输入 root 密码。这样做可以增加一定的安全性,但也会移除在未知情况下重置 root 密码的能力。
例 25. 在 /etc/ttys 中配置一个不安全的控制台
# name getty type status comments # # If console is marked "insecure", then init will ask for the root password # when going to single-user mode. console none unknown off insecure
一个 不安全(insecure) 的控制台意味着控制台的物理安全被认为是不安全的,因此只有知道 root 密码的人才能使用单用户模式。
15.2.4.2. 多用户模式
如果 init 发现文件系统正常,或者用户在单用户模式下完成了他们的命令并输入 exit 退出单用户模式,系统将进入多用户模式,开始系统的资源配置。
资源配置系统从 /etc/defaults/rc.conf 读取配置的默认值,并从 /etc/rc.conf 读取系统特定的详细信息。然后,它会挂载 /etc/fstab 中列出的系统文件系统。它启动网络服务、杂项系统守护进程,然后启动本地安装软件包的启动脚本。
要了解更多关于资源配置系统的信息,请参考 rc(8),并检查位于 /etc/rc.d 的脚本。
15.3. 设备提示
在系统初始启动时,引导管理程序 boot loader(8) 会读取 device.hints(5) 文件。该文件存储了内核引导信息,也被称为 “设备提示(device hints)”。这些 “设备提示” 被设备驱动程序用于设备配置。
设备提示也可以在第三阶段的引导加载程序提示符中指定,如 第三阶段 中所示。可以使用 set 添加变量,使用 unset 删除变量,并使用 show 查看变量。在 /boot/device.hints 中设置的变量也可以被覆盖。在引导加载程序中输入的设备提示不是永久的,下次重启时不会应用。
一旦系统启动,可以使用 kenv(1) 命令来转储所有的变量。
/boot/device.hints 的语法是每行一个变量,使用井号 “#” 作为注释标记。行的构造如下:
hint.driver.unit.keyword="value"第三阶段引导加载程序的语法是:
set hint.driver.unit.keyword=value其中 driver 是设备驱动程序的名称,unit 是设备驱动程序的单元号,keyword 是提示关键字。关键字可以包含以下选项:
-
at:指定设备所连接的总线。 -
port:指定要使用的 I/O 的起始地址。 -
irq:指定要使用的中断请求号。 -
drq:指定 DMA 通道号。 -
maddr:指定设备占用的物理内存地址。 -
flags:为设备设置各种标志位。 -
disabled: 如果设置为1,则设备被禁用。
由于设备驱动程序可能接受或需要更多未在此处列出的提示,建议查看驱动程序的手册页。有关更多信息,请参阅 device.hints(5) 、 kenv(1)、loader.conf(5) 和 loader(8)。
15.4. 关机序列
在使用 shutdown(8) 进行控制关闭时, init(8) 将尝试运行脚本 /etc/rc.shutdown ,然后继续向所有进程发送 TERM 信号,随后对于未能及时终止的进程发送 KILL 信号。
在支持电源管理的架构和系统上,要关闭 FreeBSD 机器,可以使用 shutdown -p now 立即关闭电源。要重新启动 FreeBSD 系统,可以使用 shutdown -r now 。要运行 shutdown(8),必须是 root 用户或 operator 组的成员。还可以使用 halt(8) 和 reboot(8)。有关更多信息,请参考它们的手册页面和 shutdown(8)。
通过引用 “用户和基本账户管理” 来修改组成员身份。
|
电源管理需要将 acpi(4) 加载为模块或静态编译到自定义内核中。 |
Chapter 16. 安全
16.1. 简介
已经有数百种关于如何保护系统和网络的标准实践被撰写出来,作为 FreeBSD 的用户,了解如何防御攻击和入侵是必不可少的。
在本章中,将讨论几个基本原理和技术。FreeBSD 系统具有多层安全性,并且可以添加许多第三方工具来增强安全性。
本章内容包括:
-
基本的 FreeBSD 系统安全概念。
-
在 FreeBSD 中可用的各种加密机制。
-
如何配置 TCP Wrappers 以与 inetd(8) 一起使用。
-
在 FreeBSD 上设置 Kerberos 的方法。
-
如何在 FreeBSD 上配置和使用 OpenSSH。
-
在 FreeBSD 上如何使用 OpenSSL。
-
如何使用文件系统 ACL。
-
如何使用 pkg 来审计从 Ports 集合安装的第三方软件包。
-
如何利用 FreeBSD 安全公告。
-
进程账户是什么以及如何在 FreeBSD 上启用它。
-
如何使用登录类或资源限制数据库来控制用户资源。
-
什么是 Capsicum 和一个基本例子。
由于其复杂性,某些主题在专门的章节中进行讨论,例如 防火墙, 强制访问控制 以及像 VPN over IPsec 这样的文章。
16.2. 介绍
安全是每个人的责任。任何系统中的弱入口都可能使入侵者获得对关键信息的访问权限,并对整个网络造成混乱。信息安全的核心原则之一是 CIA 三元组,即信息系统的机密性、完整性和可用性。
CIA 三元组是计算机安全的基本概念,因为客户和用户期望他们的数据得到保护。例如,客户期望他们的信用卡信息被安全地存储(保密性),他们的订单在幕后不被更改(完整性),并且他们可以随时访问他们的订单信息(可用性)。
为了提供 CIA (机密性、完整性和可用性),安全专业人员采用了深度防御策略。深度防御的理念是在安全系统中添加多层安全措施,以防止单个层面的失败导致整个安全系统崩溃。例如,系统管理员不能仅仅打开防火墙就认为网络或系统是安全的。还必须审计账户、检查二进制文件的完整性,并确保没有安装恶意工具。要实施有效的安全策略,必须了解威胁及其防御方法。
在计算机安全领域,威胁是指不仅限于试图从远程位置未经许可访问系统的远程攻击者。威胁还包括员工、恶意软件、未经授权的网络设备、自然灾害、安全漏洞,甚至竞争对手。
系统和网络有时会在没有许可的情况下被访问,有时是出于意外,或者是被远程攻击者访问,而在某些情况下,可能是通过企业间谍活动或前员工的方式进行访问。作为用户,重要的是要为可能导致安全漏洞的错误做好准备,并向安全团队报告可能存在的问题。作为管理员,了解威胁并做好准备以减轻其影响是非常重要的。
在应用安全措施到系统时,建议首先保护基本账户和系统配置,然后保护网络层,使其符合系统策略和组织的安全程序。许多组织已经有了涵盖技术设备配置的安全策略。该策略应包括工作站、桌面电脑、移动设备、电话、生产服务器和开发服务器的安全配置。在许多情况下,标准操作规程(SOP)已经存在。如果有疑问,请咨询安全团队。
16.3. 保护账户安全
在 FreeBSD 中维护安全账户对于数据保密性、系统完整性和权限分离至关重要,它可以防止未经授权的访问、恶意软件和数据泄露,同时确保合规性并保护组织的声誉。
16.3.1. 防止登录
在保护系统时,一个很好的起点是对账户进行审计。禁用任何不需要登录访问的账户。
|
确保 |
拒绝登录账户有两种方法。
第一步是锁定账户,这个例子展示了如何锁定 imani 账户:
# pw lock imani第二种方法是通过将 shell 更改为 /usr/sbin/nologin 来阻止登录访问。 nologin(8) shell 在用户尝试登录时阻止系统为其分配 shell。
只有超级用户才能更改其他用户的 Shell。
# chsh -s /usr/sbin/nologin imani16.3.2. 密码哈希值
密码是技术中不可或缺的恶魔。当必须使用密码时,它们应该是复杂的,并且应该使用强大的哈希机制来加密存储在密码数据库中的版本。FreeBSD 支持多种算法,包括 SHA256、SHA512 和 Blowfish 哈希算法在其 crypt() 库中,详细信息请参阅 crypt(3)。
不应将 SHA512 的默认值更改为较不安全的哈希算法,但可以更改为更安全的 Blowfish 算法。
|
Blowfish 不是 AES 的一部分,也不被认为符合任何联邦信息处理标准(FIPS)。在某些环境中可能不允许使用。 |
为了确定用于加密用户密码的哈希算法,超级用户可以查看 FreeBSD 密码数据库中用户的哈希值。每个哈希值都以一个符号开头,该符号指示用于加密密码的哈希机制的类型。
如果使用 DES 加密算法,没有起始符号。对于 MD5 算法,起始符号是 $。对于 SHA256 和 SHA512 算法,起始符号是 $6$。对于 Blowfish 算法,起始符号是 $2a$。在这个例子中,用户 imani 的密码使用默认的 SHA512 算法进行哈希处理,因为哈希值以 $6$ 开头。请注意,存储在密码数据库中的是加密后的哈希值,而不是密码本身。
# grep imani /etc/master.passwd输出应该类似于以下内容:
imani:$6$pzIjSvCAn.PBYQBA$PXpSeWPx3g5kscj3IMiM7tUEUSPmGexxta.8Lt9TGSi2lNQqYGKszsBPuGME0:1001:1001::0:0:imani:/usr/home/imani:/bin/sh
哈希机制是设置在用户的登录类中的。
可以运行以下命令来检查当前使用的哈希机制:
# grep user /etc/master.passwd输出应该类似于以下内容:
:passwd_format=sha512:\
例如,要将算法更改为 Blowfish,将该行修改为以下内容:
:passwd_format=blf:\
然后,必须执行 cap_mkdb(1) 命令来升级 login.conf 数据库:
# cap_mkdb /etc/login.conf请注意,此更改不会影响任何现有的密码哈希值。这意味着所有密码都应通过要求用户运行 passwd 来重新哈希,以更改他们的密码。
16.3.3. 密码策略强制执行
对本地账户强制执行强密码策略是系统安全的基本方面。在 FreeBSD 中,可以使用内置的可插拔认证模块(PAM)来实现密码长度、密码强度和密码复杂性。
本节演示了如何使用 pam_passwdqc(8) 模块配置最小和最大密码长度以及强制使用混合字符。当用户更改密码时,将强制执行此模块。
要配置此模块,请成为超级用户,并取消注释包含 pam_passwdqc.so 的行,位于 /etc/pam.d/passwd 文件中。
然后,编辑该行以符合密码策略:
password requisite pam_passwdqc.so min=disabled,disabled,disabled,12,10 similar=deny retry=3 enforce=users
参数的解释可以在 pam_passwdqc(8) 中找到。
一旦保存了这个文件,用户更改密码时将看到类似以下的消息:
% passwd输出应该类似于以下内容:
Changing local password for user Old Password: You can now choose the new password. A valid password should be a mix of upper and lower case letters, digits and other characters. You can use a 12 character long password with characters from at least 3 of these 4 classes, or a 10 character long password containing characters from all the classes. Characters that form a common pattern are discarded by the check. Alternatively, if no one else can see your terminal now, you can pick this as your password: "trait-useful&knob". Enter new password:
如果输入的密码不符合策略要求,系统将拒绝并发出警告,用户将有机会再次尝试,最多可以重试配置的次数。
如果您的组织政策要求密码过期,FreeBSD 支持在用户的登录类中使用 passwordtime 选项,该选项可以在 /etc/login.conf 文件中设置。
default 登录类包含一个示例:
# :passwordtime=90d:\
因此,要为此登录类设置 90 天的到期时间,删除注释符号(#),保存编辑,并执行以下命令:
# cap_mkdb /etc/login.conf要为单个用户设置过期时间,请将过期日期或到期天数以及用户名传递给 pw 命令。
# pw usermod -p 30-apr-2025 -n user如图所示,过期日期以日、月和年的形式设置。有关更多信息,请参阅 pw(8)。
16.3.4. 使用 sudo 进行共享管理
系统管理员经常需要能够授予用户增强的权限,以便他们可以执行特权任务。团队成员被授予访问 FreeBSD 系统以执行他们的特定任务的想法,给每个管理员带来了独特的挑战。这些团队成员只需要超出普通用户级别的一部分访问权限;然而,他们几乎总是告诉管理层,如果没有超级用户访问权限,他们无法执行任务。幸运的是,没有必要为终端用户提供这样的访问权限,因为存在可以管理这个确切需求的工具。
|
即使是管理员,在不需要时也应该限制他们的权限。 |
到目前为止,安全章节已经涵盖了允许授权用户访问和防止未经授权访问的内容。一旦授权用户获得系统资源的访问权限,另一个问题就出现了。在许多情况下,一些用户可能需要访问应用程序启动脚本,或者一个管理员团队需要维护系统。传统上,标准用户和组、文件权限,甚至 su(1) 命令都可以管理这种访问权限。随着应用程序需要更多的访问权限,越来越多的用户需要使用系统资源,需要一个更好的解决方案。目前最常用的应用程序是 Sudo。
Sudo 允许管理员对系统命令进行更严格的访问配置,并提供一些高级日志记录功能。作为一个工具,可以通过 Ports Collection 中的 security/sudo 包或使用 pkg(8) 实用程序来获取。
执行以下命令进行安装:
# pkg install sudo安装完成后,安装的 visudo 将使用文本编辑器打开配置文件。强烈建议使用 visudo,因为它内置了语法检查器,可以在保存文件之前验证是否存在错误。
配置文件由几个小节组成,允许进行广泛的配置。在下面的示例中, Web 应用程序维护者 user1 需要启动、停止和重新启动名为 webservice 的 Web 应用程序。为了授予该用户执行这些任务的权限,请将以下行添加到 /usr/local/etc/sudoers 文件的末尾:
user1 ALL=(ALL) /usr/sbin/service webservice *
用户现在可以使用以下命令启动 webservice:
% sudo /usr/sbin/service webservice start虽然这个配置允许单个用户访问 webservice 服务;然而,在大多数组织中,有一个完整的网络团队负责管理该服务。一条单独的命令也可以给整个组提供访问权限。以下步骤将创建一个网络组,将用户添加到该组,并允许该组的所有成员管理该服务:
# pw groupadd -g 6001 -n webteam使用相同的 pw(8) 命令,将用户添加到 webteam 组中:
# pw groupmod -m user1 -n webteam最后,这行代码在文件 /usr/local/etc/sudoers 中允许 webteam 组的任何成员管理 webservice。
%webteam ALL=(ALL) /usr/sbin/service webservice *
只有被允许使用 sudo(8) 运行应用程序的用户需要输入自己的密码。这比使用 su(1) 更安全,并且提供了更好的控制,因为在 su(1) 中需要输入 root 密码,用户将获得所有 root 权限。
|
大多数组织正在转向或已经采用了双因素认证模型。在这些情况下,用户可能没有密码可输入。 sudo(8) 可以通过使用 %webteam ALL=(ALL) NOPASSWD: /usr/sbin/service webservice * |
16.3.5. 使用 Doas 进行共享管理
使用 doas,用户可以以提升的权限执行命令,通常是作为 root 用户,同时保持简化和注重安全的方法。与 sudo(8) 不同,doas 强调简单和极简主义,专注于简化的权限委派,而不是提供过多的配置选项。
执行以下命令进行安装:
# pkg install doas安装完成后,必须配置 /usr/local/etc/doas.conf,以授予用户对特定命令或角色的访问权限。
最简单的条目可以是以下内容,它在执行 doas 命令时授予用户 local_user 以 root 权限,而无需输入密码。
permit nopass local_user as root
在安装和配置 doas 实用程序之后,现在可以使用增强的权限执行命令,例如:
$ doas vi /etc/rc.conf要获取更多的配置示例,请阅读 doas.conf(5)。
16.4. 入侵检测系统(IDS)
验证系统文件和二进制文件的重要性在于为系统管理和安全团队提供有关系统变化的信息。监控系统变化的软件应用程序称为入侵检测系统(IDS)。
FreeBSD 提供了对一种名为 mtree(8) 的基本 IDS 系统的本地支持。虽然每晚的安全电子邮件会通知管理员有关系统变更的信息,但这些信息是存储在本地的,恶意用户有可能修改这些信息以隐藏对系统的更改。因此,建议创建一个单独的二进制签名集,并将其存储在只读、属于 root 的目录上,或者更好地,存储在可移动的 USB 磁盘或远程服务器上。
每次更新后,建议运行 freebsd-update IDS。
16.4.1. 生成规范文件
内置的 mtree(8) 实用程序可用于生成目录内容的规范。使用种子或数字常量生成规范,并且需要使用种子来检查规范是否发生了变化。这使得可以确定文件或二进制文件是否已被修改。由于攻击者不知道种子值,因此伪造或检查文件的校验和值将变得困难或几乎不可能。
|
建议为包含二进制文件和配置文件的目录以及包含敏感数据的目录创建规范。通常,会为 /bin、/sbin、/usr/bin、/usr/sbin、/usr/local/bin、/etc 和 /usr/local/etc 创建规范。 |
以下示例生成一组 sha512 哈希值,每个哈希值对应于 /bin 目录中的系统二进制文件,并将这些值保存到用户主目录下的隐藏文件 /home/user/.bin_chksum_mtree 中。
# mtree -s 123456789 -c -K cksum,sha512 -p /bin > /home/user/.bin_chksum_mtree输出应该类似于以下内容:
mtree: /bin checksum: 3427012225
|
将种子值和校验和输出对恶意用户保密是很重要的。 |
16.4.2. 规范文件结构
mtree 格式是一种描述文件系统对象集合的文本格式。这种文件通常用于创建或验证目录层次结构。
一个 mtree 文件由一系列行组成,每行提供有关单个文件系统对象的信息。前导空格始终被忽略。
上面创建的规范文件将用于解释格式和内容:
# user: root (1)
# machine: machinename (2)
# tree: /bin (3)
# date: Thu Aug 24 21:58:37 2023 (4)
# .
/set type=file uid=0 gid=0 mode=0555 nlink=1 flags=uarch (5)
. type=dir mode=0755 nlink=2 time=1681388848.239523000 (6)
\133 nlink=2 size=12520 time=1685991378.688509000 \
cksum=520880818 \
sha512=5c1374ce0e2ba1b3bc5a41b23f4bbdc1ec89ae82fa01237f376a5eeef41822e68f1d8f75ec46b7bceb65396c122a9d837d692740fdebdcc376a05275adbd3471
cat size=14600 time=1685991378.694601000 cksum=3672531848 \ (7)
sha512=b30b96d155fdc4795432b523989a6581d71cdf69ba5f0ccb45d9b9e354b55a665899b16aee21982fffe20c4680d11da4e3ed9611232a775c69f926e5385d53a2
chflags size=8920 time=1685991378.700385000 cksum=1629328991 \
sha512=289a088cbbcbeb436dd9c1f74521a89b66643976abda696b99b9cc1fbfe8b76107c5b54d4a6a9b65332386ada73fc1bbb10e43c4e3065fa2161e7be269eaf86a
chio size=20720 time=1685991378.706095000 cksum=1948751604 \
sha512=46f58277ff16c3495ea51e74129c73617f31351e250315c2b878a88708c2b8a7bb060e2dc8ff92f606450dbc7dd2816da4853e465ec61ee411723e8bf52709ee
chmod size=9616 time=1685991378.712546000 cksum=4244658911 \
sha512=1769313ce08cba84ecdc2b9c07ef86d2b70a4206420dd71343867be7ab59659956f6f5a458c64e2531a1c736277a8e419c633a31a8d3c7ccc43e99dd4d71d630
| 1 | 创建规范的用户。 <.> 机器的主机名。 <.> 目录路径。 <.> 规范创建的日期和时间。 <.> /set 特殊命令,定义从分析的文件中获取的一些设置。 <.> 指的是解析的目录,并指示其类型、模式、硬链接数量和自修改以来的 UNIX 格式时间。 <.> 指的是文件,显示大小、时间和一系列哈希值以验证完整性。 |
16.4.3. 验证规范文件
为了验证二进制签名是否发生了变化,将当前目录的内容与先前生成的规范进行比较,并将结果保存到文件中。
该命令需要用于生成原始规范的种子。
# mtree -s 123456789 -p /bin < /home/user/.bin_chksum_mtree >> /home/user/.bin_chksum_output这应该会为 /bin 生成与创建规范时相同的校验和。如果在此目录中的二进制文件没有发生任何更改, /home/user/.bin_chksum_output 输出文件将为空。
为了模拟一个变化,使用 touch(1) 命令更改 /bin/cat 的日期,然后再次运行验证命令:
# touch /bin/cat再次运行验证命令:
# mtree -s 123456789 -p /bin < /home/user/.bin_chksum_mtree >> /home/user/.bin_chksum_output然后检查输出文件的内容:
# cat /root/.bin_chksum_output输出应该类似于以下内容:
cat: modification time (Fri Aug 25 13:30:17 2023, Fri Aug 25 13:34:20 2023)
|
这只是一个示例,展示执行命令时将显示的元数据更改。 |
16.5. 安全级别
securelevel 是内核中实现的一种安全机制。当 securelevel 为正数时,内核会限制某些任务的执行;即使是超级用户(root)也不被允许执行这些任务。
securelevel 机制限制了以下能力:
-
取消特定文件标志,例如
schg(系统不可变标志)。 -
通过 /dev/mem 和 /dev/kmem 来写入内核内存。
-
加载内核模块。
-
修改防火墙规则。
16.5.1. 安全级别定义
内核运行在五个不同的安全级别下。任何超级用户进程都可以提升级别,但没有进程可以降低级别。
安全定义如下:
- -1
-
永久不安全模式 - 始终以不安全模式运行系统。 这是默认的初始值。
- 0
-
安全模式 - 可以关闭不可变和仅追加标志。 所有设备都可以根据其权限进行读取或写入。
- 1
-
安全模式 - 系统的不可变和系统的只追加标志不能被关闭; 挂载的文件系统的磁盘、/dev/mem 和 /dev/kmem 不能被打开以进行写操作; /dev/io (如果您的平台有的话)不能被打开; 内核模块(参见 kld(4))不能被加载或卸载。 不能使用 debug.kdb.enter sysctl 进入内核调试器。 不能使用 debug.kdb.panic、debug.kdb.panic_str 和其他 sysctl 来强制发生恐慌或陷阱。
- 2
-
高度安全模式 - 与安全模式相同,但是除了 mount(2) 之外,不允许打开磁盘进行写入操作,无论是否已挂载。 这个级别防止通过卸载文件系统来篡改它们,但同时也阻止在系统处于多用户状态下运行 newfs(8)。
- 3
-
网络安全模式 - 与高度安全模式相同,还包括无法更改 IP 数据包过滤规则(参见 ipfw(8),ipfirewall(4) 和 pfctl(8)),以及无法调整 dummynet(4) 或 pf(4) 配置。
|
总结一下,在 FreeBSD 安全级别中, |
16.6. 文件标志
文件标志允许用户在基本权限和所有权之外,为文件和目录附加额外的元数据或属性。这些标志提供了一种控制文件的各种行为和属性的方式,而无需创建特殊目录或使用扩展属性。
文件标志可以用于实现不同的目标,比如防止文件被删除,使文件只能追加,同步文件更新等等。在 FreeBSD 中,一些常用的文件标志包括“immutable”标志,它防止文件被修改或删除,以及“append-only”标志,它只允许在文件末尾添加数据,而不能修改或删除数据。
在 FreeBSD 中,可以使用 chflags(1) 命令来管理这些标志,为管理员和用户提供对其文件和目录的行为和特性具有更大的控制权。需要注意的是,文件标志通常由 root 用户或具有适当权限的用户管理,因为它们可以影响文件的访问和操作方式。一些标志可供文件所有者使用,详见 chflags(1)。
16.6.1. 处理文件标志
在这个例子中,用户的主目录中有一个名为 ~/important.txt 的文件,希望对其进行防删除保护。
执行以下命令来设置 schg 文件标志:
# chflags schg ~/important.txt当任何用户,包括 root 用户,尝试删除该文件时,系统将显示以下消息:
rm: important.txt: Operation not permitted
要删除该文件,需要执行以下命令来删除该文件的文件标志:
# chflags noschg ~/important.txt可以在 chflags(1) 中找到支持的文件标志及其功能的列表。
16.7. OpenSSH
OpenSSH 是一组网络连接工具,用于提供对远程机器的安全访问。此外,可以通过 SSH 连接安全地隧道或转发 TCP/IP 连接。OpenSSH 对所有流量进行加密,以消除窃听、连接劫持和其他网络级攻击。
OpenSSH 由 OpenBSD 项目维护,并且在 FreeBSD 中默认安装。
当数据以未加密的形式通过网络发送时,位于客户端和服务器之间的网络嗅探器可以窃取用户/密码信息或在会话期间传输的数据。OpenSSH 提供了各种身份验证和加密方法,以防止这种情况发生。
有关 OpenSSH 的更多信息,请访问 这个页面。
本节提供了内置的客户端工具的概述,用于安全地访问其他系统并从 FreeBSD 系统安全地传输文件。然后,它描述了如何在 FreeBSD 系统上配置 SSH 服务器。
|
如上所述,本章将介绍 OpenSSH 的基本系统版本。OpenSSH 的一个版本也可以在包 security/openssh-portable[] 中找到,该版本提供了额外的配置选项,并且定期更新。 |
16.7.1. 使用 SSH 客户端工具
要登录到 SSH 服务器,使用 ssh(1) 命令,并指定存在于该服务器上的用户名以及服务器的 IP 地址或主机名。如果这是第一次连接到指定的服务器,用户将被提示首先验证服务器的指纹:
# ssh [email protected]输出应该类似于以下内容:
The authenticity of host 'example.com (10.0.0.1)' can't be established. ECDSA key fingerprint is 25:cc:73:b5:b3:96:75:3d:56:19:49:d2:5c:1f:91:3b. Are you sure you want to continue connecting (yes/no)? yes Permanently added 'example.com' (ECDSA) to the list of known hosts. Password for [email protected]: user_password
SSH 利用密钥指纹系统来验证客户端连接时服务器的真实性。当用户在首次连接时通过输入 yes 接受密钥的指纹时,密钥的副本将保存在用户的主目录下的 ~/.ssh/known_hosts 文件中。将来的登录尝试将根据保存的密钥进行验证,如果服务器的密钥与保存的密钥不匹配, ssh(1) 将显示警告。如果发生这种情况,用户应该首先验证密钥为何发生变化,然后再继续连接。
|
如何执行此检查超出了本章的范围。 |
使用 scp(1) 命令可以安全地将文件从本地复制到远程机器,或者从远程机器复制到本地。
这个例子将远程系统上的 COPYRIGHT 文件复制到本地系统当前目录下同名的文件中:
# scp [email protected]:/COPYRIGHT COPYRIGHT输出应该类似于以下内容:
Password for [email protected]: ******* COPYRIGHT 100% |*****************************| 4735
由于该主机的指纹已经验证过,因此在提示用户输入密码之前,服务器的密钥会自动进行检查。
传递给 scp(1) 的参数与 cp(1) 类似。要复制的文件或文件是第一个参数,要复制到的目标是第二个参数。由于文件是通过网络获取的,因此一个或多个文件参数采用 user@host:<path_to_remote_file> 的形式。在递归复制目录时,请注意 scp(1) 使用 -r,而 cp(1) 使用 -R。
要打开一个用于复制文件的交互式会话,请使用 sftp(1)。
16.7.2. 基于密钥的身份验证
客户端可以配置为使用密钥连接到远程机器,而不是使用密码。出于安全原因,这是首选的方法。
ssh-keygen(1) 可以用来生成身份验证密钥。要生成公钥和私钥对,请指定密钥类型并按照提示操作。建议使用易于记住但难以猜测的密码来保护密钥。
% ssh-keygen -t rsa -b 4096输出应该类似于以下内容:
Generating public/private rsa key pair. Enter file in which to save the key (/home/user/.ssh/id_rsa): Created directory '/home/user/.ssh/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/user/.ssh/id_rsa. Your public key has been saved in /home/user/.ssh/id_rsa.pub. The key fingerprint is: SHA256:54Xm9Uvtv6H4NOo6yjP/YCfODryvUU7yWHzMqeXwhq8 [email protected] The key's randomart image is: +---[RSA 2048]----+ | | | | | | | . o.. | | .S*+*o | | . O=Oo . . | | = Oo= oo..| | .oB.* +.oo.| | =OE**.o..=| +----[SHA256]-----+
私钥存储在 ~/.ssh/id_rsa 中,公钥存储在 ~/.ssh/id_rsa.pub 中。为了使基于密钥的身份验证工作,必须将 公钥 复制到远程机器上的 ~/.ssh/authorized_keys。
|
为 OpenSSH 密钥使用密码短语是一种关键的安全实践,可以提供额外的保护层,防止未经授权的访问,并增强整体网络安全性。 在遗失或被盗的情况下,这增加了另一层安全保障。 |
16.7.3. SSH 隧道
OpenSSH 具有创建隧道的能力,可以在加密会话中封装另一种协议。
以下命令告诉 ssh(1) 创建一个隧道:
% ssh -D 8080 [email protected]这个例子使用了以下选项:
- -D
-
指定了一个本地的“动态(dynamic)”应用层端口转发。
- [email protected]
-
在指定的远程 SSH 服务器上使用的登录名。
SSH 隧道通过在指定的 localport 上在 localhost 上创建一个监听套接字来工作。
这种方法可以用来包装任意数量的不安全的 TCP 协议,如 SMTP、 POP3 和 FTP。
16.7.4. 启用 SSH 服务器
除了提供内置的 SSH 客户端工具外, FreeBSD 系统还可以配置为 SSH 服务器,接受来自其他 SSH 客户端的连接。
|
正如所述,本章将涵盖 OpenSSH 的基本系统版本。请 不要 与 security/openssh-portable 混淆,后者是随 FreeBSD ports 一起提供的 OpenSSH 版本。 |
为了在重新启动后启用 SSH 服务器,请执行以下命令:
# sysrc sshd_enable="YES"然后执行以下命令以启用该服务:
# service sshd start在 FreeBSD 系统上首次启动 sshd 时,系统的主机密钥将会自动创建,并且指纹将会显示在控制台上。提供用户指纹,以便他们在首次连接服务器时进行验证。
请参考 sshd(8) 以获取在启动 sshd 时可用的选项列表,以及有关身份验证、登录过程和各种配置文件的更完整的讨论。
在这一点上,sshd 应该对系统上所有具有用户名和密码的用户可用。
16.7.5. 配置公钥身份验证方法
通过配置 OpenSSH 使用公钥身份验证,可以通过利用非对称加密进行身份验证来增强安全性。这种方法消除了与密码相关的风险,例如弱密码或在传输过程中的拦截,同时阻止了各种基于密码的攻击。然而,确保私钥受到良好保护以防止未经授权的访问非常重要。
第一步是配置 sshd(8) 以使用所需的身份验证方法。
编辑 /etc/ssh/sshd_config 文件,并取消以下配置的注释:
PubkeyAuthentication yes
一旦配置完成,用户将需要将他们的 公钥 发送给系统管理员,这些密钥将被添加到 .ssh/authorized_keys 文件中。生成密钥的过程在 基于密钥的身份验证 中描述。
然后执行以下命令重新启动服务器:
# service sshd reload强烈建议按照 SSH 服务器安全选项 中指示的安全改进措施进行操作。
16.7.6. SSH 服务器安全选项
尽管 sshd 是 FreeBSD 最广泛使用的远程管理工具,但暴力破解和驱动攻击对于任何暴露在公共网络中的系统来说都是常见的。
本节将介绍几个可用的额外参数,以防止这些攻击的成功。所有配置都将在 /etc/ssh/sshd_config 文件中完成。
|
不要将 /etc/ssh/sshd_config 与 /etc/ssh/ssh_config 混淆(注意第一个文件名中多了一个 |
默认情况下,可以使用公钥和密码进行身份验证。为了 仅 允许公钥身份验证,强烈推荐,请更改变量:
PasswordAuthentication no
在 OpenSSH 服务器配置文件中使用 AllowUsers 关键字限制哪些用户可以登录 SSH 服务器以及从哪里登录是一个好主意。例如,要仅允许 user 从 192.168.1.32 登录,将以下行添加到 /etc/ssh/sshd_config 文件中:
AllowUsers [email protected]
为了允许 user 从任何地方登录,列出该用户而不指定 IP 地址:
AllowUsers user
多个用户应该在同一行上列出,如下所示:
AllowUsers [email protected] user
在进行所有更改之后,在重新启动服务之前,建议通过执行以下命令来验证所做的配置是否正确:
# sshd -t如果配置文件正确,将不会显示任何输出。如果配置文件不正确,将会显示类似以下内容:
/etc/ssh/sshd_config: line 3: Bad configuration option: sdadasdasdasads /etc/ssh/sshd_config: terminating, 1 bad configuration options
在进行更改并确认配置文件正确后,通过运行以下命令告诉 sshd 重新加载其配置文件:
# service sshd reload16.8. OpenSSL
OpenSSL 是一个实现安全套接字层(SSL)和传输层安全(TLS)网络协议以及许多密码学例程的密码学工具包。
openssl 程序是一个命令行工具,用于在 shell 中使用 OpenSSL 的加密库的各种加密功能。它可以用于
-
私钥、公钥和参数的创建和管理
-
公钥加密操作
-
创建 X.509 证书、证书签名请求(CSR)和证书撤销列表(CRL)
-
消息摘要的计算
-
使用密码进行加密和解密
-
SSL/TLS 客户端和服务器测试
-
处理 S/MIME 签名或加密邮件
-
时间戳请求、生成和验证
-
对加密算法进行基准测试
有关 OpenSSL 的更多信息,请阅读免费的 OpenSSL Cookbook。
16.8.1. 生成证书
OpenSSL 支持生成证书,既可以由证书颁发机构(CA)验证,也可以供自己使用。
运行命令 openssl(1) 以使用以下参数生成一个有效的证书,用于一个名为 CA 的证书颁发机构。该命令将在当前目录中创建两个文件。证书请求文件 req.pem 可以发送给 CA ,该机构将验证输入的凭据,签署请求并返回签署后的证书。第二个文件 cert.key 是证书的私钥,应存放在安全的位置。如果该私钥落入他人之手,可能被用来冒充用户或服务器。
执行以下命令以生成证书:
# openssl req -new -nodes -out req.pem -keyout cert.key -sha3-512 -newkey rsa:4096输出应该类似于以下内容:
Generating a RSA private key ..................................................................................................................................+++++ ......................................+++++ writing new private key to 'cert.key' ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:ES State or Province Name (full name) [Some-State]:Valencian Community Locality Name (eg, city) []:Valencia Organization Name (eg, company) [Internet Widgits Pty Ltd]:My Company Organizational Unit Name (eg, section) []:Systems Administrator Common Name (e.g. server FQDN or YOUR name) []:localhost.example.org Email Address []:[email protected] Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []:123456789 An optional company name []:Another name
或者,如果不需要来自 CA 的签名,可以创建自签名证书。这将在当前目录中创建两个新文件:私钥文件 cert.key 和证书本身 cert.crt。这些文件应该放在一个目录中,最好是在 /etc/ssl/ 下,该目录只能由 root 用户读取。对于这些文件,适当的权限是 0700 ,可以使用 chmod 命令设置。
执行以下命令以生成证书:
# openssl req -new -x509 -days 365 -sha3-512 -keyout /etc/ssl/private/cert.key -out /etc/ssl/certs/cert.crt输出应该类似于以下内容:
Generating a RSA private key ........................................+++++ ...........+++++ writing new private key to '/etc/ssl/private/cert.key' Enter PEM pass phrase: Verifying - Enter PEM pass phrase: ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:ES State or Province Name (full name) [Some-State]:Valencian Community Locality Name (eg, city) []:Valencia Organization Name (eg, company) [Internet Widgits Pty Ltd]:My Company Organizational Unit Name (eg, section) []:Systems Administrator Common Name (e.g. server FQDN or YOUR name) []:localhost.example.org Email Address []:[email protected]
16.8.2. 配置 FIPS 提供程序
随着 OpenSSL 3 进入基础系统(在 FreeBSD 14 及更高版本中),系统引入了其新的提供者模块概念。除了库中内置的默认提供者模块外,legacy 模块实现了现在可选的已弃用的密码算法,而 fips 模块将 OpenSSL 实现限制为链接中存在的密码算法: FIPS 标准集。OpenSSL 的这部分接受特别关注,包括一份相关安全问题的链接: 列表 ,并定期进行 FIPS 140 验证过程。还提供了 经 FIPS 验证的版本列表 。这使得用户可以确保在使用 OpenSSL 时符合 FIPS 标准。
重要的是,fips_module(7) 受到额外的安全措施保护,防止在未通过完整性检查的情况下使用。这个检查可以由本地系统管理员设置,允许 OpenSSL 3 的每个用户加载这个模块。当配置不正确时,预计 FIPS 模块将失败,如下所示:
# echo test | openssl aes-128-cbc -a -provider fips -pbkdf2输出应该类似于以下内容:
aes-128-cbc: unable to load provider fips Hint: use -provider-path option or OPENSSL_MODULES environment variable. 00206124D94D0000:error:1C8000D5:Provider routines:SELF_TEST_post:missing config data:crypto/openssl/providers/fips/self_test.c:275: 00206124D94D0000:error:1C8000E0:Provider routines:ossl_set_error_state:fips module entering error state:crypto/openssl/providers/fips/self_test.c:373: 00206124D94D0000:error:1C8000D8:Provider routines:OSSL_provider_init_int:self test post failure:crypto/openssl/providers/fips/fipsprov.c:707: 00206124D94D0000:error:078C0105:common libcrypto routines:provider_init:init fail:crypto/openssl/crypto/provider_core.c:932:name=fips
可以通过在 /etc/ssl/fipsmodule.cnf 中创建一个文件来配置检查,然后在 OpenSSL 的主配置文件 /etc/ssl/openssl.cnf 中引用该文件。OpenSSL 提供了 openssl-fipsinstall(1) 实用程序来帮助完成此过程,可以按照以下方式使用:
# openssl fipsinstall -module /usr/lib/ossl-modules/fips.so -out /etc/ssl/fipsmodule.cnf输出应该类似于以下内容:
INSTALL PASSED
然后应该修改 /etc/ssl/openssl.cnf 文件,以便:
-
包含上面生成的 /etc/ssl/fipsmodule.cnf 文件,
-
将 FIPS 模块暴露出来,以便可能的使用。
-
并显式激活默认模块。
[...] # For FIPS # Optionally include a file that is generated by the OpenSSL fipsinstall # application. This file contains configuration data required by the OpenSSL # fips provider. It contains a named section e.g. [fips_sect] which is # referenced from the [provider_sect] below. # Refer to the OpenSSL security policy for more information. .include /etc/ssl/fipsmodule.cnf [...] # List of providers to load [provider_sect] default = default_sect # The fips section name should match the section name inside the # included fipsmodule.cnf. fips = fips_sect # If no providers are activated explicitly, the default one is activated implicitly. # See man 7 OSSL_PROVIDER-default for more details. # # If you add a section explicitly activating any other provider(s), you most # probably need to explicitly activate the default provider, otherwise it # becomes unavailable in openssl. As a consequence applications depending on # OpenSSL may not work correctly which could lead to significant system # problems including inability to remotely access the system. [default_sect] activate = 1
完成这一步骤后,应该可以确认 FIPS 模块已经有效地可用并且正常工作:
# echo test | openssl aes-128-cbc -a -provider fips -pbkdf2输出应该类似于以下内容:
enter AES-128-CBC encryption password: Verifying - enter AES-128-CBC encryption password: U2FsdGVkX18idooW6e3LqWeeiKP76kufcOUClh57j8U=
每次修改 FIPS 模块时都必须重复执行此过程,例如在执行系统更新后或在应用影响基本系统中的 OpenSSL 的安全修复程序后。
16.9. Kerberos
Kerberos 是一种网络认证协议,最初由麻省理工学院(MIT)创建,用于在可能存在敌对网络的情况下提供安全认证。Kerberos 协议使用强加密技术,使得客户端和服务器可以在不发送任何未加密的秘密信息的情况下证明其身份。Kerberos 可以被描述为一个身份验证代理系统和一个可信第三方认证系统。用户在使用 Kerberos 进行身份验证后,他们的通信可以被加密以确保隐私和数据完整性。
Kerberos 的唯一功能是在网络上提供用户和服务器的安全认证。它不提供授权或审计功能。建议将 Kerberos 与其他提供授权和审计服务的安全方法一起使用。
协议的当前版本是版本 5,详细描述在 RFC 4120 中。有几个免费的实现该协议的软件可供选择,覆盖了广泛的操作系统。麻省理工学院(MIT)继续开发他们的 Kerberos 软件包。它在美国常被用作密码学产品,并且历史上受到美国出口管制的限制。在 FreeBSD 中, MITKerberos 可作为 security/krb5 软件包或端口使用。Heimdal Kerberos 实现是专门在美国以外开发的,以避免出口管制。Heimdal Kerberos 发行版已包含在基本的 FreeBSD 安装中,还有另一个具有更多可配置选项的发行版可在 Ports Collection 中使用,即 security/heimdal。
在 Kerberos 中,用户和服务被称为“主体”,并包含在一个管理组中,称为“领域”。一个典型的用户主体的形式为 user@REALM (领域通常是大写)。
本节提供了使用 FreeBSD 中包含的 Heimdal 发行版设置 Kerberos 的指南。
为了展示 Kerberos 安装的目的,命名空间将如下所示:
-
DNS 域(区域)将是
example.org。 -
Kerberos 领域将是
EXAMPLE.ORG。
|
在设置 Kerberos 时,请使用真实的域名,即使它将在内部运行。这样可以避免 DNS 问题,并确保与其他 Kerberos 领域的互操作性。 |
16.9.1. 设置 Heimdal KDC
密钥分发中心(KDC)是 Kerberos 提供的集中式认证服务,也是系统的“可信第三方”。它是发放 Kerberos 票据的计算机,用于客户端对服务器进行身份验证。由于 KDC 被 Kerberos 领域中的所有其他计算机视为可信任的,因此它具有更高的安全性要求。应该限制对 KDC 的直接访问。
运行 KDC 所需的计算资源很少,但出于安全原因,建议使用专用机器作为 KDC。
首先,按照以下方式安装 security/heimdal 软件包:
# pkg install heimdal接下来,使用 sysrc 按照以下方式更新 /etc/rc.conf 文件:
# sysrc kdc_enable=yes
# sysrc kadmind_enable=yes接下来,按照以下方式编辑 /etc/krb5.conf 文件:
[libdefaults]
default_realm = EXAMPLE.ORG
[realms]
EXAMPLE.ORG = {
kdc = kerberos.example.org
admin_server = kerberos.example.org
}
[domain_realm]
.example.org = EXAMPLE.ORG
在这个例子中,KDC 将使用完全限定的主机名 kerberos.example.org。KDC 的主机名必须能够在 DNS 中解析。
Kerberos 也可以使用 DNS 来定位 KDCs,而不是在 /etc/krb5.conf 文件的 [realms] 部分中。对于拥有自己 DNS 服务器的大型组织,上述示例可以简化为:
[libdefaults]
default_realm = EXAMPLE.ORG
[domain_realm]
.example.org = EXAMPLE.ORG
在 example.org 区域文件中包含以下行:
_kerberos._udp IN SRV 01 00 88 kerberos.example.org. _kerberos._tcp IN SRV 01 00 88 kerberos.example.org. _kpasswd._udp IN SRV 01 00 464 kerberos.example.org. _kerberos-adm._tcp IN SRV 01 00 749 kerberos.example.org. _kerberos IN TXT EXAMPLE.ORG
|
为了使客户端能够找到 Kerberos 服务,它们必须具有完全配置的 /etc/krb5.conf 文件或最小配置的 /etc/krb5.conf 文件和正确配置的 DNS 服务器。 |
接下来,创建 Kerberos 数据库,其中包含使用主密码加密的所有主体(用户和主机)的密钥。不需要记住此密码,因为它将存储在 /var/heimdal/m-key 中;为此目的使用一个 45 个字符的随机密码是合理的。要创建主密钥,请运行 kstash 并输入密码:
# kstash输出应该类似于以下内容:
Master key: xxxxxxxxxxxxxxxxxxxxxxx Verifying password - Master key: xxxxxxxxxxxxxxxxxxxxxxx
一旦主密钥被创建,就应该初始化数据库。可以在 KDC 上使用 Kerberos 管理工具 kadmin(8) 以 kadmin -l 的模式直接操作数据库,而不使用 kadmind(8) 网络服务。这解决了在创建数据库之前尝试连接数据库的鸡生蛋问题。在 kadmin 提示符下,使用 init 命令创建领域的初始数据库:
# kadmin -l
kadmin> init EXAMPLE.ORG
Realm max ticket life [unlimited]:最后,在 kadmin 中使用 add 命令创建第一个主体。暂时使用默认选项,因为这些选项可以在以后使用 modify 命令进行更改。在提示符处输入 ? 以查看可用选项。
kadmin> add tillman输出应该类似于以下内容:
Max ticket life [unlimited]: Max renewable life [unlimited]: Principal expiration time [never]: Password expiration time [never]: Attributes []: Password: xxxxxxxx Verifying password - Password: xxxxxxxx
接下来,通过运行以下命令启动 KDC 服务:
# service kdc start
# service kadmind start在这一点上,不会有任何运行的 Kerberized 守护程序,但可以通过获取刚刚创建的主体的票证来确认 KDC 是否正常运行:
% kinit tillman输出应该类似于以下内容:
[email protected]'s Password:
使用 klist 确认成功获取了一张票据。
% klist输出应该类似于以下内容:
Credentials cache: FILE:/tmp/krb5cc_1001 Principal: [email protected] Issued Expires Principal Aug 27 15:37:58 2013 Aug 28 01:37:58 2013 krbtgt/[email protected]
测试完成后,临时票据可以被销毁。
% kdestroy16.9.2. 配置服务器使用 Kerberos
配置服务器以使用 Kerberos 身份验证的第一步是确保它在 /etc/krb5.conf 中具有正确的配置。可以直接使用 KDC 提供的版本,或者可以在新系统上重新生成该文件。
接下来,在服务器上创建 /etc/krb5.keytab 文件。这是“Kerberizing”服务的主要部分 - 它对应于在服务和 KDC 之间生成一个共享密钥。这个密钥是一个加密密钥,存储在一个“keytab”文件中。 keytab 文件包含了服务器的主机密钥,它允许服务器和 KDC 验证彼此的身份。必须以安全的方式将它传输到服务器上,因为如果密钥被公开,服务器的安全性可能会被破坏。通常,keytab 文件是在管理员信任的机器上使用 kadmin 生成的,然后通过安全传输方式传输到服务器上,例如使用 scp(1) 命令;如果符合所需的安全策略,也可以直接在服务器上创建。非常重要的是,必须以安全的方式将 keytab 文件传输到服务器上:如果密钥被其他方知晓,该方可以冒充任何用户访问服务器!在服务器上直接使用 kadmin 非常方便,因为在 KDC 数据库中为主机主体创建条目也是使用 kadmin 完成的。
当然,kadmin 是一个使用 Kerberos 进行身份验证的服务;需要一个 Kerberos 票证来认证到网络服务,但为了确保运行 kadmin 的用户实际上存在(并且他们的会话没有被劫持),kadmin 会提示输入密码以获取一个新的票证。认证到 kadmin 服务的主体必须被允许使用 kadmin 接口,如 /var/heimdal/kadmind.acl 中所指定的。有关设计访问控制列表的详细信息,请参阅 info heimdal 中标题为“远程管理(Remote administration)”的部分。管理员可以通过本地控制台或 ssh(1) 安全地连接到 KDC,并使用 kadmin -l 在本地进行管理,而不是启用远程 kadmin 访问。
在安装完 /etc/krb5.conf 后,在 kadmin 中使用 add --random-key 命令。这将向数据库中添加服务器的主机主体,但不会将主机主体密钥提取到密钥表中。要生成密钥表,请使用 ext 命令将服务器的主机主体密钥提取到其自己的密钥表中:
# kadmin输出应该类似于以下内容:
kadmin> add --random-key host/myserver.example.org Max ticket life [unlimited]: Max renewable life [unlimited]: Principal expiration time [never]: Password expiration time [never]: Attributes []: kadmin> ext_keytab host/myserver.example.org kadmin> exit
请注意,默认情况下,ext_keytab 将提取的密钥存储在 /etc/krb5.keytab 中。当在进行 Kerberos 认证的服务器上运行时,这是很好的选择。但是,当密钥表在其他地方提取时,应使用 --keytab path/to/file 参数。
# kadmin输出应该类似于以下内容:
kadmin> ext_keytab --keytab=/tmp/example.keytab host/myserver.example.org kadmin> exit
然后,可以使用 scp(1) 或可移动介质将 keytab 安全地复制到服务器。请确保指定一个非默认的 keytab 名称,以避免将不必要的密钥插入系统的 keytab 中。
此时,服务器可以使用存储在 krb5.keytab 中的共享密钥从 KDC 读取加密消息。现在可以启用使用 Kerberos 的服务了。其中最常见的服务之一是 sshd(8),它通过 GSS-API 支持 Kerberos。在 /etc/ssh/sshd_config 中添加以下行:
GSSAPIAuthentication yes
在进行此更改后,必须重新启动 sshd(8) 以使新的配置生效:service sshd restart。
16.9.3. 配置客户端使用 Kerberos
与服务器一样,客户端需要在 /etc/krb5.conf 中进行配置。将文件复制到指定位置(安全地)或根据需要重新输入。
通过在客户端使用 kinit、klist 和 kdestroy 命令来获取、显示和删除现有主体的票证,来测试客户端。 Kerberos 应用程序也应该能够连接到启用了 Kerberos 的服务器。如果连接不起作用,但是获取票证可以,那么问题很可能是服务器而不是客户端或 KDC 的问题。在使用 kerberized ssh(1) 的情况下,默认情况下禁用了 GSS-API,因此请使用 ssh -o GSSAPIAuthentication = yes hostname 命令进行测试。
在测试 Kerberized 应用程序时,尝试使用诸如 tcpdump 之类的数据包嗅探器来确认没有明文发送敏感信息。
有各种不同的 Kerberos 客户端应用程序可供选择。随着桥接的出现,使用 SASL 进行身份验证的应用程序也可以使用 GSS-API 机制,因此大部分客户端应用程序都可以使用 Kerberos 进行身份验证,包括 Jabber 客户端和 IMAP 客户端。
在一个领域中,通常会将用户的 Kerberos 主体映射到本地用户账户。偶尔,需要将本地用户账户的访问权限授予没有匹配的 Kerberos 主体的人。例如,[email protected] 可能需要访问本地用户账户 webdevelopers。其他主体也可能需要访问该本地账户。
放置在用户的主目录中的 .k5login 和 .k5users 文件可以用来解决这个问题。例如,如果将以下 .k5login 文件放置在 webdevelopers 的主目录中,列出的两个主体都可以访问该帐户,而无需共享密码:
请参考 ksu(1) 获取有关 .k5users 的更多信息。
16.9.4. 与 MIT 的差异
MIT 和 Heimdal 实现之间的主要区别是 kadmin 具有不同但等效的命令集,并且使用不同的协议。如果 KDC 是 MIT 版本,则无法使用 Heimdal 版本的 kadmin 远程管理 KDC,反之亦然。
客户端应用程序也可以使用稍微不同的命令行选项来完成相同的任务。建议按照 http://web.mit.edu/Kerberos/www/ 上的说明进行操作。请注意路径问题:MIT 端口默认安装在 /usr/local/ 中,如果 PATH 列表中首先列出系统目录,则 FreeBSD 系统应用程序将代替 MIT 版本运行。
在 FreeBSD 上使用 MIT Kerberos 作为 KDC 时,执行以下命令将所需的配置添加到 /etc/rc.conf 文件中:
# sysrc kdc_program="/usr/local/sbin/kdc"
# sysrc kadmind_program="/usr/local/sbin/kadmind"
# sysrc kdc_flags=""
# sysrc kdc_enable="YES"
# sysrc kadmind_enable="YES"16.9.5. Kerberos 提示、技巧和故障排除
在配置和故障排除 Kerberos 时,请记住以下几点:
-
在使用来自 ports 的 Heimdal 或 MITKerberos 时,请确保
PATH中列出的是端口版本的客户端应用程序,而不是系统版本。 -
如果领域中的所有计算机没有同步的时间设置,认证可能会失败。 “使用 NTP 进行时钟同步” 描述了如何使用 NTP 同步时钟。
-
如果主机名发生变化,则必须更改
host/主体并更新 keytab。这也适用于特殊的 keytab 条目,比如用于 Apache 的HTTP/主体,例如 www/mod_auth_kerb。 -
领域中的所有主机必须在 DNS 中具有正向和反向解析的能力,或者至少存在于 /etc/hosts 文件中。CNAME 记录可以使用,但 A 记录和 PTR 记录必须正确并且存在。对于无法解析的主机,错误消息并不直观:
Kerberos5 refuses authenticatio because Read req failed: Key table entry not found -
一些作为 KDC 客户端的操作系统没有设置
ksu的权限为 setuidroot。这意味着ksu无法工作。这是一个权限问题,而不是 KDC 错误。 -
使用 MITKerberos,如果要允许一个主体拥有比默认的十小时更长的票据生命周期,可以在 kadmin(8) 提示符下使用
modify_principal命令来更改相关主体和krbtgt主体的maxlife属性。然后,该主体可以使用kinit -l命令来请求一个具有更长生命周期的票据。 -
在从工作站运行
kinit时,在 KDC 上运行数据包嗅探器以帮助故障排除时,票据授予票证(TGT)会立即发送,甚至在输入密码之前。这是因为 Kerberos 服务器会自由地向任何未经授权的请求传输 TGT。然而,每个 TGT 都是使用用户密码派生的密钥进行加密的。当用户输入密码时,它不会被发送到 KDC,而是用于解密kinit已经获取的 TGT。如果解密过程产生一个带有有效时间戳的有效票证,用户就拥有有效的 Kerberos 凭证。这些凭证包括用于与 Kerberos 服务器建立安全通信的会话密钥,以及使用 Kerberos 服务器自己的密钥加密的实际 TGT。这第二层加密允许 Kerberos 服务器验证每个 TGT 的真实性。 -
主机主体可以拥有更长的票据生命周期。如果用户主体的生命周期为一周,但连接的主机的生命周期为九小时,用户缓存将会有一个过期的主机主体,票据缓存将无法按预期工作。
-
在设置 krb5.dict 以防止特定的弱密码被使用,如 kadmind(8) 中所描述的那样,请记住它仅适用于已分配密码策略的主体。 krb5.dict 中使用的格式是每行一个字符串。创建一个符号链接到 /usr/share/dict/words 可能会很有用。
16.9.6. 缓解 Kerberos 的限制
由于 Kerberos 是一种全面的方法,网络上的每个启用的服务都必须要么被修改以与 Kerberos 一起工作,要么以其他方式进行网络攻击防护。这是为了防止用户凭据被窃取和重复使用。一个例子是当 Kerberos 在所有远程 shell 上启用时,非 Kerberos 化的 POP3 邮件服务器会以明文发送密码。
KDC 是一个单点故障。按设计,KDC 必须与其主密码数据库一样安全。KDC 上不应该运行任何其他服务,并且应该具有物理安全性。危险性很高,因为 Kerberos 将所有密码都使用相同的主密钥进行加密,该密钥存储在 KDC 上的文件中。
一个被破坏的主密钥并不像人们可能担心的那样糟糕。主密钥仅用于加密 Kerberos 数据库和作为随机数生成器的种子。只要 KDC 的访问是安全的,攻击者无法对主密钥做太多事情。
如果 KDC 不可用,网络服务将无法使用,因为无法进行身份验证。可以通过一个主 KDC 和一个或多个从 KDC 以及对 PAM 进行细致实施的次要或备用身份验证来缓解这个问题。
Kerberos 允许用户、主机和服务之间进行身份验证。它没有机制来对用户、主机或服务进行身份验证。这意味着一个被木马程序感染的 kinit 可以记录所有的用户名和密码。文件系统完整性检查工具,如 security/tripwire 可以缓解这个问题。
16.10. TCP Wrappers
TCP Wrappers 是一种基于主机的网络访问控制系统。通过在实际网络服务之前拦截传入的网络请求,TCP Wrappers 根据配置文件中预定义的规则评估源 IP 地址是否被允许或拒绝访问。
然而,尽管 TCP 包装器提供了基本的访问控制,但它们不应被视为更强大的安全措施的替代品。为了全面保护,建议使用像防火墙这样的先进技术,以及适当的用户身份验证实践和入侵检测系统。
16.10.1. 初始配置
# sysrc inetd_enable="YES"
# service inetd start然后,正确配置 /etc/hosts.allow 文件。
|
与其他 TCP Wrappers 的实现不同,在 FreeBSD 中使用 hosts.deny 已被弃用。所有配置选项应放置在 /etc/hosts.allow 中。 |
在最简单的配置中,守护进程连接策略根据 /etc/hosts.allow 中的选项设置为允许或阻止。在 FreeBSD 中,默认配置是允许所有与 inetd 启动的守护进程的连接。
基本配置通常采用 daemon : address : action 的形式,其中 daemon 是由 inetd 启动的守护进程, address 是有效的主机名、 IP 地址或用方括号([ ])括起来的 IPv6 地址,action 可以是 allow 或 deny。TCP Wrappers 使用首次匹配规则的语义,意味着配置文件从头开始扫描以寻找匹配的规则。当找到匹配时,规则被应用并且搜索过程停止。
例如,要允许通过 mail/qpopper 守护程序进行 POP3 连接,应将以下行追加到 /etc/hosts.allow 文件中:
# This line is required for POP3 connections: qpopper : ALL : allow
每当编辑此文件时,重新启动 inetd :
# service inetd restart16.10.2. 高级配置
TCP Wrappers 提供了高级选项,可以更好地控制连接的处理方式。在某些情况下,向特定的主机或守护进程连接返回注释可能是合适的。在其他情况下,应记录日志条目或向管理员发送电子邮件。其他情况可能需要仅用于本地连接的服务。通过使用通配符、扩展字符和外部命令执行的配置选项,所有这些都是可能的。要了解有关通配符及其相关功能的更多信息,请参阅 hosts_access(5) 。
16.11. 访问控制列表
访问控制列表(ACL)通过允许用户和组在每个文件或目录的基础上进行细粒度的访问控制,扩展了传统的 UNIX® 文件权限。每个 ACL 条目定义了一个用户或组以及相关的权限,如读取、写入和执行。 FreeBSD 提供了像 getfacl(1) 和 setfacl(1) 这样的命令来管理 ACL。
访问控制列表(ACL)在需要比标准权限更具体的访问控制的场景中非常有用,通常在多用户环境或共享托管中使用。然而,复杂性可能是不可避免的,但需要仔细规划,以确保提供所需的安全性质。
|
FreeBSD 支持在 UFS 和 OpenZFS 中实现 NFSv4 ACLs。请注意,setfacl(1) 命令的一些参数仅适用于 POSIX ACLs,而其他参数适用于 NFSv4 ACLs。 |
16.11.1. 在 UFS 中启用 ACL 支持
ACLs 是通过挂载时的管理标志 acls 启用的,可以将其添加到 /etc/fstab 文件中。
因此,需要访问 /etc/fstab 并在选项部分添加 acls 标志,如下所示:
# Device Mountpoint FStype Options Dump Pass# /dev/ada0s1a / ufs rw,acls 1 1
16.11.2. 获取 ACL 信息
可以使用 getfacl(1) 命令来检查文件或目录的 ACL 。
例如,要查看 ~/test 文件的 ACL 设置,请执行以下命令:
% getfacl test如果使用 NFSv4 ACLs ,输出应该类似于以下内容:
# file: test
# owner: freebsduser
# group: freebsduser
owner@:rw-p--aARWcCos:-------:allow
group@:r-----a-R-c--s:-------:allow
everyone@:r-----a-R-c--s:-------:allow
如果使用 POSIX.1e ACLs,输出应该类似于以下内容:
# file: test # owner: freebsduser # group: freebsduser user::rw- group::r-- other::r--
16.11.3. 使用 ACLs 进行工作
setfacl(1) 可以用于向文件或目录添加、修改或删除 ACL 。
如上所述,setfacl(1) 的一些参数与 NFSv4 ACLs 不兼容,反之亦然。本节介绍如何执行 POSIX ACLs 和 NFSv4 ACLs 的命令,并提供了两者的示例。
例如,要设置 POSIX.1e 默认 ACL 的强制元素:
% setfacl -d -m u::rwx,g::rx,o::rx,mask::rwx directory这个示例设置了文件所有者的 POSIX.1e ACL 条目的读取、写入和执行权限,并为文件上的邮件组设置了读取和写入权限。
% setfacl -m u::rwx,g:mail:rw file为了在 NFSv4 ACL 中执行与前一个示例相同的操作:
% setfacl -m owner@:rwxp::allow,g:mail:rwp::allow file从 POSIX.1e ACL 文件中删除除了三个必需的 ACL 条目之外的所有 ACL 条目。
% setfacl -bn file要删除 NFSv4 ACL 中的所有 ACL 条目:
% setfacl -b file有关这些命令可用选项的更多信息,请参考 getfacl(1) 和 setfacl(1)。
16.12. Capsicum
Capsicum 是一个轻量级的操作系统能力和沙箱框架,实现了混合能力系统模型。能力是不可伪造的授权令牌,可以委派,必须提交才能执行操作。 Capsicum 将文件描述符转换为能力。
Capsicum 可以用于应用程序和库的分隔,将较大的软件体分解为隔离(沙盒化)的组件,以实施安全策略并限制软件漏洞的影响。
16.13. 进程账户
进程账户是一种安全方法,管理员可以通过该方法跟踪系统资源的使用情况以及它们在用户之间的分配情况,提供系统监控,并最少程度地跟踪用户的命令。
进程账户有积极和消极的一面。其中一个积极的方面是可以将入侵事件追溯到入侵点。消极的一面是进程账户会生成大量的日志,并且可能需要大量的磁盘空间来存储这些日志。本节将向管理员介绍进程账户的基础知识。
|
如果需要更细粒度的会计记录,请参考 安全事件审计。 |
16.13.1. 启用和利用进程账户
在使用进程记账之前,必须使用以下命令启用它:
# sysrc accounting_enable=yes
# service accounting start记帐信息存储在位于 /var/account 的文件中,如果需要,记帐服务首次启动时会自动创建该文件。这些文件包含敏感信息,包括所有用户发出的所有命令。对文件的写访问权限仅限于 root ,读访问权限仅限于 root 和 wheel 组的成员。为了防止 wheel 组的成员也能读取这些文件,将 /var/account 目录的模式更改为仅允许 root 访问。
启用后,会计将开始跟踪诸如 CPU 统计和执行的命令等信息。所有的记账日志都以非人类可读的格式存储,可以使用 sa(8) 命令查看。如果不带任何选项使用 sa(8) 命令,将打印与每个用户调用次数、总经过时间(以分钟为单位)、总 CPU 和用户时间(以分钟为单位)以及平均 I/O 操作次数相关的信息。有关控制输出的可用选项列表,请参考 sa(8) 命令。
要显示用户发出的命令,请使用 lastcomm 命令。
例如,这个命令会打印出在 ttyp1 终端上由 trhodes 使用的 ls 的所有用法:
# lastcomm ls trhodes ttyp1还有许多其他有用的选项,可以在 lastcomm(1)、acct(5) 和 sa(8) 中找到解释。
16.14. 资源限制
在 FreeBSD 中,资源限制是指控制和管理将各种系统资源分配给进程和用户的机制。这些限制旨在防止单个进程或用户消耗过多的资源,从而可能导致性能下降或系统不稳定。资源限制有助于确保系统上所有活动进程和用户之间公平分配资源。
FreeBSD 提供了几种方法,供管理员限制个人使用系统资源的数量。
传统的方法是通过编辑 /etc/login.conf 来定义登录类。虽然这种方法仍然受支持,但任何更改都需要多个步骤:编辑该文件、重建资源数据库、对 /etc/master.passwd 进行必要的更改,并重新构建密码数据库。这可能会耗费时间,具体取决于要配置的用户数量。
rctl(8) 可以用于提供一种更精细的方法来控制资源限制。该命令不仅支持用户限制,还可以用于在进程和 jails 上设置资源约束。
本节展示了控制资源的两种方法,首先是传统方法。
16.14.1. 资源的类型
FreeBSD 提供了各种类型资源的限制,包括:
| 类型 | 描述 |
|---|---|
CPU 时间 |
限制进程可以消耗的 CPU 时间量 |
内存 |
控制进程可使用的物理内存量 |
打开文件 |
限制进程同时打开的文件数量。 |
进程 |
控制用户或进程可以创建的进程数量。 |
文件大小 |
限制进程可以创建的文件的最大大小。 |
核心转储 |
控制进程是否允许生成核心转储文件。 |
网络资源 |
限制进程可以使用的网络资源(例如,套接字)的数量 |
有关类型的完整列表,请参阅 login.conf(5) 和 rctl(8)。
16.14.2. 配置登录类
在传统的方法中,登录类和适用于登录类的资源限制在 /etc/login.conf 文件中定义。每个用户账户可以分配给一个登录类,其中 default 是默认的登录类。每个登录类都有一组与之关联的登录能力。登录能力是一个 name=value 对,其中 name 是一个众所周知的标识符,value 是一个任意字符串,根据 name 的不同进行相应的处理。
配置资源限制的第一步是通过执行以下命令打开 /etc/login.conf 文件:
# ee /etc/login.conf然后找到要修改的用户类的部分。在这个例子中,假设用户类的名称是 limited,如果不存在,则创建它。
limited:\ (1)
:maxproc=50:\ (2)
:tc=default: (3)
| 1 | 用户类的名称。 <.> 将 limited 类中的用户的最大进程数(maxproc)设置为 50。 <.> 表示该用户类继承了“default”类的默认设置。 |
在修改 /etc/login.conf 文件后,运行 cap_mkdb(1) 命令生成 FreeBSD 使用的数据库,以应用这些设置:
# cap_mkdb /etc/login.confchpass(1) 可以用于更改用户的类别,执行以下命令:
# chpass username这将打开一个文本编辑器,在其中添加新的 limited 类,如下所示:
#Changing user information for username. Login: username Password: $6$2H.419USdGaiJeqK$6kgcTnDadasdasd3YnlNZsOni5AMymibkAfRCPirc7ZFjjv DVsKyXx26daabdfqSdasdsmL/ZMUpdHiO0 Uid [#]: 1001 Gid [# or name]: 1001 Change [month day year]: Expire [month day year]: Class: limited Home directory: /home/username Shell: /bin/sh Full Name: User & Office Location: Office Phone: Home Phone: Other information:
现在,分配给 limited 类的用户将具有最大进程限制为 50。请记住,这只是使用 /etc/login.conf 文件设置资源限制的一个示例。
请记住,在对 /etc/login.conf 文件进行更改后,用户需要注销并重新登录以使更改生效。此外,在编辑系统配置文件时,特别是在使用特权访问时,始终要谨慎行事。
16.14.3. 启用和配置资源限制
rctl(8) 系统提供了一种更精细的方式来设置和管理单个进程和用户的资源限制。它允许您动态地为特定的进程或用户分配资源限制,而不考虑他们的用户类别。
使用 rctl(8) 的第一步是将以下行添加到 /boot/loader.conf 并重新启动系统,以启用它:
kern.racct.enable=1
然后激活 rctl(8) 服务并通过以下命令启用它执行:
# sysrc rctl_enable="YES"
# service rctl start然后可以使用 rctl(8) 来为系统设置规则。
规则语法(rctl.conf(5))通过使用主题、主题 ID 、资源和操作来进行控制,如下面的示例规则所示:
subject:subject-id:resource:action=amount/per
例如,要限制用户添加的进程数量不超过 10 个,请执行以下命令:
# rctl -a user:username:maxproc:deny=10/user要检查应用的资源限制,可以执行 rctl(8) 命令。
# rctl输出应该类似于以下内容:
user:username:maxproc:deny=10
如果将规则添加到 /etc/rctl.conf 文件中,规则将在重新启动后保持不变。格式是一个规则,没有前导命令。例如,可以将上述规则添加为:
user:username:maxproc:deny=10
16.15. 监控第三方安全问题
近年来,安全领域在漏洞评估的处理方面取得了许多改进。随着第三方工具在几乎所有现有操作系统上的安装和配置,系统入侵的威胁也在增加。
漏洞评估是安全性的关键因素。虽然 FreeBSD 为基本系统发布了安全公告,但对于每个第三方实用程序都这样做超出了 FreeBSD 项目的能力范围。有一种方法可以减轻第三方漏洞并警告管理员已知的安全问题。一个名为 pkg 的 FreeBSD 附加实用程序专门包含了这个目的的选项。
pkg 轮询数据库以查找安全问题。该数据库由 FreeBSD 安全团队和端口开发人员更新和维护。
安装提供了用于维护 pkg audit 数据库的 periodic(8) 配置文件,并提供了一种程序化的方法来保持其更新。
安装完成后,管理员可以选择更新数据库并查看已安装软件包的已知漏洞,以便随时审核第三方工具作为 Ports Collection 的一部分。
% pkg audit -F输出应该类似于以下内容:
vulnxml file up-to-date chromium-116.0.5845.96_1 is vulnerable: chromium -- multiple vulnerabilities CVE: CVE-2023-4431 CVE: CVE-2023-4427 CVE: CVE-2023-4428 CVE: CVE-2023-4429 CVE: CVE-2023-4430 WWW: https://vuxml.FreeBSD.org/freebsd/5fa332b9-4269-11ee-8290-a8a1599412c6.html samba413-4.13.17_5 is vulnerable: samba -- multiple vulnerabilities CVE: CVE-2023-3347 CVE: CVE-2023-34966 CVE: CVE-2023-34968 CVE: CVE-2022-2127 CVE: CVE-2023-34967 WWW: https://vuxml.FreeBSD.org/freebsd/441e1e1a-27a5-11ee-a156-080027f5fec9.html 2 problem(s) in 2 installed package(s) found.
通过将 Web 浏览器指向显示的 URL,管理员可以获取有关漏洞的更多信息。
这将包括受影响的版本,按照 FreeBSD port 版本列出,以及可能包含安全公告的其他网站。
16.16. FreeBSD 安全公告
像许多优质操作系统的生产者一样,FreeBSD 项目有一个安全团队,负责确定每个 FreeBSD 发布版本的生命周期结束(EoL)日期,并为尚未达到其 EoL 的受支持版本提供安全更新。有关 FreeBSD 安全团队和受支持版本的更多信息,请访问 FreeBSD 安全页面。
安全团队的一个任务是响应 FreeBSD 操作系统中报告的安全漏洞。一旦确认了漏洞,安全团队会验证修复漏洞所需的步骤,并更新源代码进行修复。然后,它将详细信息发布为“安全公告”。安全公告会发布在 FreeBSD 网站 上,并发送给 FreeBSD security notifications mailing list、https://lists.FreeBSD.org/subscription/freebsd-security[FreeBSD security mailing list] 和 FreeBSD announcements mailing list。
16.16.1. 安全公告的格式
这是一个 FreeBSD 安全公告的示例:
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
=============================================================================
FreeBSD-SA-23:07.bhyve Security Advisory
The FreeBSD Project
Topic: bhyve privileged guest escape via fwctl
Category: core
Module: bhyve
Announced: 2023-08-01
Credits: Omri Ben Bassat and Vladimir Eli Tokarev from Microsoft
Affects: FreeBSD 13.1 and 13.2
Corrected: 2023-08-01 19:48:53 UTC (stable/13, 13.2-STABLE)
2023-08-01 19:50:47 UTC (releng/13.2, 13.2-RELEASE-p2)
2023-08-01 19:48:26 UTC (releng/13.1, 13.1-RELEASE-p9)
CVE Name: CVE-2023-3494
For general information regarding FreeBSD Security Advisories,
including descriptions of the fields above, security branches, and the
following sections, please visit <URL:https://security.FreeBSD.org/>.
I. Background
bhyve(8)'s fwctl interface provides a mechanism through which guest
firmware can query the hypervisor for information about the virtual
machine. The fwctl interface is available to guests when bhyve is run
with the "-l bootrom" option, used for example when booting guests in
UEFI mode.
bhyve is currently only supported on the amd64 platform.
II. Problem Description
The fwctl driver implements a state machine which is executed when the
guest accesses certain x86 I/O ports. The interface lets the guest copy
a string into a buffer resident in the bhyve process' memory. A bug in
the state machine implementation can result in a buffer overflowing when
copying this string.
III. Impact
A malicious, privileged software running in a guest VM can exploit the
buffer overflow to achieve code execution on the host in the bhyve
userspace process, which typically runs as root. Note that bhyve runs
in a Capsicum sandbox, so malicious code is constrained by the
capabilities available to the bhyve process.
IV. Workaround
No workaround is available. bhyve guests that are executed without the
"-l bootrom" option are unaffected.
V. Solution
Upgrade your vulnerable system to a supported FreeBSD stable or
release / security branch (releng) dated after the correction date.
Perform one of the following:
1) To update your vulnerable system via a binary patch:
Systems running a RELEASE version of FreeBSD on the amd64, i386, or
(on FreeBSD 13 and later) arm64 platforms can be updated via the
freebsd-update(8) utility:
# freebsd-update fetch
# freebsd-update install
Restart all affected virtual machines.
2) To update your vulnerable system via a source code patch:
The following patches have been verified to apply to the applicable
FreeBSD release branches.
a) Download the relevant patch from the location below, and verify the
detached PGP signature using your PGP utility.
[FreeBSD 13.2]
# fetch https://security.FreeBSD.org/patches/SA-23:07/bhyve.13.2.patch
# fetch https://security.FreeBSD.org/patches/SA-23:07/bhyve.13.2.patch.asc
# gpg --verify bhyve.13.2.patch.asc
[FreeBSD 13.1]
# fetch https://security.FreeBSD.org/patches/SA-23:07/bhyve.13.1.patch
# fetch https://security.FreeBSD.org/patches/SA-23:07/bhyve.13.1.patch.asc
# gpg --verify bhyve.13.1.patch.asc
b) Apply the patch. Execute the following commands as root:
# cd /usr/src
# patch < /path/to/patch
c) Recompile the operating system using buildworld and installworld as
described in <URL:https://www.FreeBSD.org/handbook/makeworld.html>.
Restart all affected virtual machines.
VI. Correction details
This issue is corrected by the corresponding Git commit hash or Subversion
revision number in the following stable and release branches:
Branch/path Hash Revision
- -------------------------------------------------------------------------
stable/13/ 9fe302d78109 stable/13-n255918
releng/13.2/ 2bae613e0da3 releng/13.2-n254625
releng/13.1/ 87702e38a4b4 releng/13.1-n250190
- -------------------------------------------------------------------------
Run the following command to see which files were modified by a
particular commit:
# git show --stat <commit hash>
Or visit the following URL, replacing NNNNNN with the hash:
<URL:https://cgit.freebsd.org/src/commit/?id=NNNNNN>
To determine the commit count in a working tree (for comparison against
nNNNNNN in the table above), run:
# git rev-list --count --first-parent HEAD
VII. References
<URL:https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-3494>
The latest revision of this advisory is available at
<URL:https://security.FreeBSD.org/advisories/FreeBSD-SA-23:07.bhyve.asc>
-----BEGIN PGP SIGNATURE-----
iQIzBAEBCgAdFiEEthUnfoEIffdcgYM7bljekB8AGu8FAmTJdsIACgkQbljekB8A
Gu8Q1Q/7BFw5Aa0cFxBzbdz+O5NAImj58MvKS6xw61bXcYr12jchyT6ENC7yiR+K
qCqbe5TssRbtZ1gg/94gSGEXccz5OcJGxW+qozhcdPUh2L2nzBPkMCrclrYJfTtM
cnmQKjg/wFZLUVr71GEM95ZFaktlZdXyXx9Z8eBzow5rXexpl1TTHQQ2kZZ41K4K
KFhup91dzGCIj02cqbl+1h5BrXJe3s/oNJt5JKIh/GBh5THQu9n6AywQYl18HtjV
fMb1qRTAS9WbiEP5QV2eEuOG86ucuhytqnEN5MnXJ2rLSjfb9izs9HzLo3ggy7yb
hN3tlbfIPjMEwYexieuoyP3rzKkLeYfLXqJU4zKCRnIbBIkMRy4mcFkfcYmI+MhF
NPh2R9kccemppKXeDhKJurH0vsetr8ti+AwOZ3pgO21+9w+mjE+EfaedIi+JWhip
hwqeFv03bAQHJdacNYGV47NsJ91CY4ZgWC3ZOzBZ2Y5SDtKFjyc0bf83WTfU9A/0
drC0z3xaJribah9e6k5d7lmZ7L6aHCbQ70+aayuAEZQLr/N1doB0smNi0IHdrtY0
JdIqmVX+d1ihVhJ05prC460AS/Kolqiaysun1igxR+ZnctE9Xdo1BlLEbYu2KjT4
LpWvSuhRMSQaYkJU72SodQc0FM5mqqNN42Vx+X4EutOfvQuRGlI=
=MlAY
-----END PGP SIGNATURE-----
每个安全公告都使用以下格式:
-
每个安全公告都由安全官员的 PGP 密钥签名。可以在 OpenPGP Keys 上验证安全官员的公钥。
-
安全公告的名称始终以
FreeBSD-SA-(FreeBSD 安全公告)开头,后跟两位数格式的年份(23:),后跟该年份的公告编号(07.),后跟受影响的应用程序或子系统的名称(bhyve)。 -
Topic字段总结了漏洞的内容。 -
Category指的是系统中受影响的部分,可以是core、contrib或ports之一。core类别表示漏洞影响 FreeBSD 操作系统的核心组件。contrib类别表示漏洞影响 FreeBSD 中包含的软件,如 BIND。ports类别表示漏洞影响通过 Ports Collection 提供的软件。 -
Module字段指的是组件的位置。在这个例子中,bhyve模块受到影响;因此,这个漏洞会影响安装有操作系统的应用程序。 -
Announced字段反映了安全公告发布的日期。这意味着安全团队已经验证了问题的存在,并且已经提交了一个补丁到 FreeBSD 源代码仓库中。 -
Credits字段用于给发现并报告漏洞的个人或组织提供鸣谢。 -
Affects字段说明了哪些版本的 FreeBSD 受到此漏洞的影响。 -
Corrected字段表示修正的日期、时间、时间偏移和修正的发布版本。括号中的部分显示了已合并修复的每个分支,以及该分支对应发布的版本号。发布标识符本身包括版本号和(如果适用)补丁级别。补丁级别是字母p后跟一个数字,表示补丁的序列号,允许用户跟踪已应用到系统的补丁。 -
CVE Name字段列出了公共 cve.mitre.org 安全漏洞数据库中的咨询编号(如果存在)。 -
Background字段提供了受影响模块的描述。 -
Problem Description字段解释了漏洞的情况。这可能包括有关有缺陷的代码以及如何恶意使用该实用程序的信息。 -
Impact字段描述了问题对系统可能产生的影响类型。 -
Workaround字段指示系统管理员是否可以立即修补系统,以及是否有可用的解决方法。 -
Solution字段提供了修补受影响系统的指令。这是一个经过逐步测试和验证的方法,用于修补系统并确保其安全运行。 -
Correction Details字段显示了每个受影响的 Subversion 或 Git 分支以及包含修正代码的修订版本号。 -
References字段提供了有关漏洞的额外信息的来源。
Chapter 17. Jails 和容器
17.1. 简介
由于系统管理是一项困难的任务,因此开发了许多工具来简化管理员的工作。这些工具通常可以增强系统的安装、配置和维护方式。其中一个可以用来增强 FreeBSD 系统安全性的工具是 jails。自 FreeBSD 4.X 以来,Jails 一直在其有用性、性能、可靠性和安全性方面得到改进。
Jails 是基于 chroot(2) 概念构建的,该概念用于更改一组进程的根目录。这样可以创建一个与系统其余部分分离的安全环境。在 chroot 环境中创建的进程无法访问其外部的文件或资源。因此,入侵 chroot 环境中运行的服务不应允许攻击者危害整个系统。
然而,chroot 有一些限制。它适用于不需要太多灵活性或复杂高级功能的简单任务。随着时间的推移,人们发现了许多逃离 chroot 环境的方法,使其成为不太理想的保护服务的解决方案。
Jails 在多个方面改进了传统 chroot 环境的概念。
在传统的 chroot 环境中,进程只能访问文件系统的一部分。其余的系统资源、系统用户、运行中的进程和网络子系统由 chroot 进程和主机系统的进程共享。Jails 通过虚拟化对文件系统、用户集和网络子系统的访问来扩展这个模型。可以使用更精细的控制来调整被监禁环境的访问权限。Jails 可以被看作是一种操作系统级别的虚拟化。
本章内容包括:
-
在 FreeBSD 安装中,jail 是什么以及它可能起到的作用。
-
不同类型的 jail。
-
配置 jail 网络的不同方法。
-
jail 配置文件。
-
如何创建不同类型的 jail。
-
如何启动、停止和重启一个 jail。
-
jail 管理的基础知识,包括 jail 内部和外部的管理。
-
如何升级不同类型的 jail。
-
一个不完整的 FreeBSD jail 管理器列表。
17.2. Jail 类型
一些管理员将 jail 分为不同类型,尽管底层技术是相同的。每个管理员都必须根据他们需要解决的问题来评估在每种情况下创建哪种类型的 jail。
下面是不同类型的列表,包括它们的特点和使用时需要考虑的事项。
17.2.1. 厚(Thick)Jails
厚 jail 是 FreeBSD jail 的一种传统形式。在厚 jail 中,基本系统的完整副本被复制到 jail 的环境中。这意味着 jail 拥有自己独立的 FreeBSD 基本系统实例,包括库、可执行文件和配置文件。可以将 jail 视为一个几乎完整的独立 FreeBSD 安装,但在主机系统的限制下运行。这种隔离确保 jail 内的进程与主机和其他 jail 中的进程保持分离。
厚 Jails 的优势:
-
高度隔离性:jail 内的进程与主机系统和其他 jail 之间是隔离的。
-
独立性:厚 jail 可以拥有与主机系统或其他 jail 不同版本的库、配置和软件。
-
安全性:由于 jail 包含了自己的基本系统,影响 jail 环境的漏洞或问题不会直接影响主机或其他 jail。
厚 Jails 的缺点:
-
资源开销:由于每个 jail 都维护着自己独立的基础系统,相比于薄 jail,厚 jail 消耗更多的资源。
-
维护:每个 jail 都需要对其基本系统组件进行维护和更新。
17.2.2. 薄(Thin)Jails
薄 jail 使用 OpenZFS 快照或 NullFS 挂载从模板共享基础系统。每个薄 jail 仅复制基础系统的最小子集,与厚 jail 相比,资源消耗更少。然而,这也意味着薄 jail 与厚 jail 相比具有较少的隔离性和独立性。共享组件的更改可能会同时影响多个薄 jail。
简而言之,FreeBSD 薄 Jail 是一种 FreeBSD Jail,它在隔离环境中复制了基本系统的大部分内容,但并非全部。
薄 Jails 的优势:
-
资源效率:与厚 jail 相比,薄 jail 在资源利用上更高效。由于它们共享大部分基础系统,所以占用的磁盘空间和内存较少。这使得在同一硬件上运行更多的 jail 成为可能,而不会消耗过多的资源。
-
更快的部署:创建和启动薄 jail 通常比创建和启动厚 jail 更快。当您需要快速部署多个实例时,这可能特别有优势。
-
统一维护:由于薄 jail 与主机系统共享大部分基础系统(如库和二进制文件),因此只需要在主机上进行一次更新和维护常见的基础系统组件。与为每个厚 jail 维护单独的基础系统相比,这简化了维护过程。
-
共享资源:薄 jail 可以更轻松地与主机系统共享常见的资源,如库和二进制文件。这可能会导致更高效的磁盘缓存和 jail 内应用程序的性能改善。
薄 Jails 的缺点:
-
降低的隔离性:薄 jail 的主要缺点是相比于厚 jail,它们提供的隔离性较低。由于它们共享模板基础系统的大部分内容,可能会同时影响多个 jail 的漏洞或问题。
-
安全问题:薄 jail 中减少的隔离性可能会带来安全风险,因为一个 jail 的妥协可能对其他 jail 或主机系统产生更大的影响潜力。
-
依赖冲突:如果多个独立的容器需要不同版本的相同库或软件,管理依赖关系可能会变得复杂。在某些情况下,这可能需要额外的努力来确保兼容性。
-
兼容性挑战:在一个薄 jail 中,应用程序可能会遇到兼容性问题,如果它们假设某个基本系统环境与模板提供的共享组件不同。
17.3. 主机配置
在主机系统上创建任何 jail 之前,需要进行一些配置并从主机系统中获取一些信息。
需要配置 jail(8) 实用程序,创建必要的目录来配置和安装 jails,从主机的网络获取信息,并检查主机是否使用 OpenZFS 或 UFS 作为其文件系统。
|
在 jail 中运行的 FreeBSD 版本不能比主机中运行的版本更新。 |
17.3.1. Jail 实用工具
jail(8) 实用程序用于管理 jails。
要在系统启动时启动 jails,请运行以下命令:
# sysrc jail_enable="YES"
# sysrc jail_parallel_start="YES"|
使用 |
17.3.2. 网络
FreeBSD jails 的网络配置有多种不同的方式:
- 主机网络模式(IP 共享)
-
在主机网络模式下,一个 jail 与主机系统共享相同的网络堆栈。当一个 jail 在主机网络模式下创建时,它使用相同的网络接口和 IP 地址。这意味着 jail 没有单独的 IP 地址,它的网络流量与主机的 IP 地址相关联。
- 虚拟网络(VNET)
-
虚拟网络是 FreeBSD jails 的一个特性,提供比主机网络等基本网络模式更高级和灵活的网络解决方案。VNET 允许为每个 jail 创建隔离的网络堆栈,为它们提供独立的 IP 地址、路由表和网络接口。这提供了更高级别的网络隔离,并允许 jails 像运行在独立的虚拟机上一样运行。
- netgraph 系统
-
netgraph(4) 是一个多功能的内核框架,用于创建自定义的网络配置。它可以用于定义网络流量在 jails 和主机系统之间以及不同 jails 之间的流动方式。
17.3.3. 设置 jail 目录树
没有特定的位置来放置 jail 的文件。
一些管理员使用 /jail ,其他人使用 /usr/jail ,还有一些人使用 /usr/local/jails 。在本章中,将使用 /usr/local/jails 。
除了 /usr/local/jails 目录之外,还会创建其他目录:
-
media 将包含已下载用户空间的压缩文件。
-
在使用薄 Jails 时,templates 文件夹将包含模板。
-
containers 将包含 jail 。
在使用 OpenZFS 时,执行以下命令为这些目录创建数据集:
# zfs create -o mountpoint=/usr/local/jails zroot/jails
# zfs create zroot/jails/media
# zfs create zroot/jails/templates
# zfs create zroot/jails/containers|
在这种情况下, |
在使用 UFS 时,执行以下命令来创建目录:
# mkdir /usr/local/jails/
# mkdir /usr/local/jails/media
# mkdir /usr/local/jails/templates
# mkdir /usr/local/jails/containers17.3.4. Jail 配置文件
有两种方法来配置 jails 。
第一种方法是在文件 /etc/jail.conf 中为每个 jail 添加一个条目。另一种选项是在目录 /etc/jail.conf.d/ 中为每个 jail 创建一个文件。
没有正确或错误的选择。每个管理员必须选择最适合他们需求的选项。
如果主机系统只有几个 jail,可以在文件 /etc/jail.conf 中为每个 jail 添加一个条目。如果主机系统有很多 jail,最好在 /etc/jail.conf.d/ 目录中为每个 jail 拥有一个配置文件。
一个典型的 jail 入口会是这样的:
jailname { (1)
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc"; (2)
exec.stop = "/bin/sh /etc/rc.shutdown"; (3)
exec.consolelog = "/var/log/jail_console_${name}.log"; (4)
# PERMISSIONS
allow.raw_sockets; (5)
exec.clean; (6)
mount.devfs; (7)
# HOSTNAME/PATH
host.hostname = "${name}"; (8)
path = "/usr/local/jails/containers/${name}"; (9)
# NETWORK
ip4.addr = 192.168.1.151; (10)
ip6.addr = ::ffff:c0a8:197 (11)
interface = em0; (12)
}
| 1 | jailname - jail 的名称。 <.> exec.start - 创建 jail 时在 jail 环境中运行的命令。通常运行的命令是 "/bin/sh /etc/rc"。 <.> exec.stop - 删除 jail 之前在 jail 环境中运行的命令。通常运行的命令是 "/bin/sh /etc/rc.shutdown"。 <.> exec.consolelog - 将命令输出(stdout 和 stderr)重定向到的文件。 <.> allow.raw_sockets - 允许在 jail 内创建原始套接字。设置此参数允许像 ping(8) 和 traceroute(8) 这样的实用程序在 jail 内运行。 <.> exec.clean - 在一个干净的环境中运行命令。 <.> mount.devfs - 在 chrooted /dev 目录上挂载一个 devfs(5) 文件系统,并应用 devfs_ruleset 参数中的规则集来限制 jail 内可见的设备。 <.> host.hostname - jail 的主机名。 <.> path - jail 的根目录。在 jail 内运行的任何命令,无论是通过 jail 还是 jexec(8) 运行,都是从此目录开始的。 <.> ip4.addr - IPv4 地址。 IPv4 有两种配置可能性。第一种是像示例中所做的那样建立一个 IP 或 IP 列表。另一种是使用 ip4 替代,并将 inherit 值设置为继承主机的 IP 地址。 <.> ip6.addr - IPv6 地址。 IPv6 有两种配置可能性。第一种是像示例中所做的那样建立一个 IP 或 IP 列表。另一种是使用 ip6 替代,并将 inherit 值设置为继承主机的 IP 地址。 <.> interface - 添加 jail 的 IP 地址的网络接口。通常是主机接口。 |
有关配置变量的更多信息可以在 jail(8) 和 jail.conf(5) 中找到。
17.4. 经典 Jail(厚 Jail )
这些 jail 类似于真实的 FreeBSD 系统。它们可以像普通主机系统一样进行管理,并且可以独立更新。
17.4.1. 创建一个经典 Jail
原则上,一个 jail 只需要一个主机名、一个根目录、一个 IP 地址和一个用户空间。
可以从官方的 FreeBSD 下载服务器获取用于 jail 的用户空间。
执行以下命令以下载用户空间:
# fetch https://download.freebsd.org/ftp/releases/amd64/amd64/13.2-RELEASE/base.txz -o /usr/local/jails/media/13.2-RELEASE-base.txz下载完成后,需要将内容解压到 jail 目录中。
执行以下命令将用户空间提取到 jail 目录中:
# mkdir -p /usr/local/jails/containers/classic
# tar -xf /usr/local/jails/media/13.2-RELEASE-base.txz -C /usr/local/jails/containers/classic --unlink在 jail 目录中提取用户空间后,需要复制时区和 DNS 服务器文件:
# cp /etc/resolv.conf /usr/local/jails/containers/classic/etc/resolv.conf
# cp /etc/localtime /usr/local/jails/containers/classic/etc/localtime在复制文件后,下一步是通过执行以下命令更新到最新的补丁级别:
# freebsd-update -b /usr/local/jails/containers/classic/ fetch install最后一步是配置 jail。需要在配置文件 /etc/jail.conf 或 jail.conf.d 中添加一个条目,包含 jail 的参数。
一个例子如下:
classic {
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
# PERMISSIONS
allow.raw_sockets;
exec.clean;
mount.devfs;
# HOSTNAME/PATH
host.hostname = "${name}";
path = "/usr/local/jails/containers/${name}";
# NETWORK
ip4.addr = 192.168.1.151;
interface = em0;
}
执行以下命令以启动 jail :
# service jail start classic有关如何管理 jails 的更多信息可以在 Jail 管理 部分找到。
17.5. 薄(Thin)Jails
尽管瘦 Jails 使用与胖 Jails 相同的技术,但创建过程是不同的。可以使用 OpenZFS 快照或使用模板和 NullFS 来创建瘦 jails。使用 OpenZFS 快照和使用 NullFS 的模板相比传统的 jails 具有一定的优势,例如可以更快地从快照创建它们,或者可以使用 NullFS 更新多个 jails。
17.5.1. 使用 OpenZFS 快照创建一个瘦 Jail
由于 FreeBSD 和 OpenZFS 之间的良好集成,使用 OpenZFS 快照创建新的瘦 Jails 非常容易。
使用 OpenZFS 快照创建瘦 Jail 的第一步是创建一个模板。
模板只用于创建新的 jail。因此,它们以“只读”模式创建,以便 jail 以不可变的基础创建。
要为模板创建数据集,请执行以下命令:
# zfs create -p zroot/jails/templates/13.2-RELEASE然后执行以下命令来下载用户空间:
# fetch https://download.freebsd.org/ftp/releases/amd64/amd64/13.2-RELEASE/base.txz -o /usr/local/jails/media/13.2-RELEASE-base.txz下载完成后,需要执行以下命令将内容解压到模板目录中:
# tar -xf /usr/local/jails/media/13.2-RELEASE-base.txz -C /usr/local/jails/templates/13.2-RELEASE --unlink在模板目录中提取用户空间后,需要通过执行以下命令将时区和 DNS 服务器文件复制到模板目录中:
# cp /etc/resolv.conf /usr/local/jails/templates/13.2-RELEASE/etc/resolv.conf
# cp /etc/localtime /usr/local/jails/templates/13.2-RELEASE/etc/localtime下一步要做的是通过执行以下命令更新到最新的补丁级别:
# freebsd-update -b /usr/local/jails/templates/13.2-RELEASE/ fetch install一旦更新完成,模板就准备好了。
要从模板创建一个 OpenZFS 快照,请执行以下命令:
# zfs snapshot zroot/jails/templates/13.2-RELEASE@base一旦创建了 OpenZFS 快照,就可以使用 OpenZFS 克隆功能创建无限个 jail。
要创建一个名为 thinjail 的薄 Jail,请执行以下命令:
# zfs clone zroot/jails/templates/13.2-RELEASE@base zroot/jails/containers/thinjail最后一步是配置 jail。需要在配置文件 /etc/jail.conf 或 jail.conf.d 中添加一个条目,包含 jail 的参数。
一个例子如下:
thinjail {
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
# PERMISSIONS
allow.raw_sockets;
exec.clean;
mount.devfs;
# HOSTNAME/PATH
host.hostname = "${name}";
path = "/usr/local/jails/containers/${name}";
# NETWORK
ip4 = inherit;
interface = em0;
}
执行以下命令以启动 jail :
# service jail start thinjail有关如何管理 jails 的更多信息可以在 Jail 管理 部分找到。
17.5.2. 使用 NullFS 创建一个薄 Jail
使用薄 Jail 技术和使用 NullFS 将特定目录从主机系统选择性地共享到 jail 中,可以减少系统文件的重复创建。
第一步是创建数据集以保存模板,如果使用 OpenZFS,请执行以下命令:
# zfs create -p zroot/jails/templates/13.2-RELEASE-base如果使用 UFS,则使用以下命令:
# mkdir /usr/local/jails/templates/13.2-RELEASE-base然后执行以下命令来下载用户空间:
# fetch https://download.freebsd.org/ftp/releases/amd64/amd64/13.2-RELEASE/base.txz -o /usr/local/jails/media/13.2-RELEASE-base.txz下载完成后,需要执行以下命令将内容解压到模板目录中:
# tar -xf /usr/local/jails/media/13.2-RELEASE-base.txz -C /usr/local/jails/templates/13.2-RELEASE-base --unlink一旦用户空间在模板目录中被提取出来,就需要通过执行以下命令将时区和 DNS 服务器文件复制到模板目录中:
# cp /etc/resolv.conf /usr/local/jails/templates/13.2-RELEASE-base/etc/resolv.conf
# cp /etc/localtime /usr/local/jails/templates/13.2-RELEASE-base/etc/localtime将文件移动到模板后,下一步要做的是通过执行以下命令更新到最新的补丁级别:
# freebsd-update -b /usr/local/jails/templates/13.2-RELEASE-base/ fetch install除了基本模板之外,还需要创建一个目录,用于存放 skeleton。一些目录将从模板复制到 skeleton 中。
在使用 OpenZFS 的情况下,执行以下命令创建 skeleton 的数据集:
# zfs create -p zroot/jails/templates/13.2-RELEASE-skeleton如果使用 UFS,则使用以下命令:
# mkdir /usr/local/jails/templates/13.2-RELEASE-skeleton然后创建 skeleton 目录。 skeleton 目录将保存 jail 的本地目录。
执行以下命令创建目录:
# mkdir -p /usr/local/jails/templates/13.2-RELEASE-skeleton/home
# mkdir -p /usr/local/jails/templates/13.2-RELEASE-skeleton/usr
# mv /usr/local/jails/templates/13.2-RELEASE-base/etc /usr/local/jails/templates/13.2-RELEASE-skeleton/etc
# mv /usr/local/jails/templates/13.2-RELEASE-base/usr/local /usr/local/jails/templates/13.2-RELEASE-skeleton/usr/local
# mv /usr/local/jails/templates/13.2-RELEASE-base/tmp /usr/local/jails/templates/13.2-RELEASE-skeleton/tmp
# mv /usr/local/jails/templates/13.2-RELEASE-base/var /usr/local/jails/templates/13.2-RELEASE-skeleton/var
# mv /usr/local/jails/templates/13.2-RELEASE-base/root /usr/local/jails/templates/13.2-RELEASE-skeleton/root下一步是通过执行以下命令创建到 skeleton 的符号链接:
# cd /usr/local/jails/templates/13.2-RELEASE-base/
# mkdir skeleton
# ln -s skeleton/etc etc
# ln -s skeleton/home home
# ln -s skeleton/root root
# ln -s skeleton/usr/local usr/local
# ln -s skeleton/tmp tmp
# ln -s skeleton/var var准备好了 skeleton 之后,需要将数据复制到 jail 目录中。
如果使用 OpenZFS,可以使用 OpenZFS 快照通过执行以下命令轻松创建所需数量的 jails :
# zfs snapshot zroot/jails/templates/13.2-RELEASE-skeleton@base
# zfs clone zroot/jails/templates/13.2-RELEASE-skeleton@base zroot/jails/containers/thinjail如果使用 UFS 文件系统,可以通过执行以下命令来使用 cp(1) 程序:
# mkdir /usr/local/jails/containers/thinjail
# cp -R /usr/local/jails/templates/13.2-RELEASE-skeleton /usr/local/jails/containers/thinjail然后创建一个目录,用于挂载基本模板和 skeleton:
# mkdir -p /usr/local/jails/thinjail-nullfs-base在 /etc/jail.conf 中添加一个 jail 条目,或者在 jail.conf.d 目录中添加一个文件,内容如下:
thinjail {
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
# PERMISSIONS
allow.raw_sockets;
exec.clean;
mount.devfs;
# HOSTNAME/PATH
host.hostname = "${name}";
path = "/usr/local/jails/containers/${name}";
# NETWORK
ip4.addr = 192.168.1.153;
interface = em0;
# MOUNT
mount.fstab = "/usr/local/jails/thinjail-nullfs-base.fstab";
}
然后按照以下方式创建 /usr/local/jails/thinjail-nullfs-base.fstab 文件:
/usr/local/jails/templates/13.2-RELEASE-base /usr/local/jails/thinjail-nullfs-base/ nullfs ro 0 0 /usr/local/jails/containers/thinjail /usr/local/jails/thinjail-nullfs-base/skeleton nullfs rw 0 0
执行以下命令以启动 jail :
# service jail start thinjail17.5.3. 创建一个 VNET Jail
FreeBSD VNET Jails 拥有独立的网络堆栈,包括接口、 IP 地址、路由表和防火墙规则。
创建 VNET jail 的第一步是通过执行以下命令创建 bridge(4) 。
# ifconfig bridge create输出应该类似于以下内容:
bridge0
创建了 bridge 之后,需要通过执行以下命令将其附加到 em0 接口:
# ifconfig bridge0 addm em0要使此设置在重新启动后保持不变,请将以下行添加到 /etc/rc.conf 文件中:
defaultrouter="192.168.1.1" cloned_interfaces="bridge0" ifconfig_bridge0="inet 192.168.1.150/24 addm em0 up"
下一步是按照上述所示创建 jail 。
可以使用 经典 Jail(厚 Jail ) 过程和 薄(Thin)Jails 过程。唯一需要更改的是 /etc/jail.conf 文件中的配置。
路径 /usr/local/jails/containers/vnet 将被用作创建的 jail 的示例。
以下是一个 VNET jail 的配置示例:
vnet {
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
# PERMISSIONS
allow.raw_sockets;
exec.clean;
mount.devfs;
devfs_ruleset = 5;
# PATH/HOSTNAME
path = "/usr/local/jails/containers/${name}";
host.hostname = "${name}";
# VNET/VIMAGE
vnet;
vnet.interface = "${epair}b";
# NETWORKS/INTERFACES
$id = "154"; (1)
$ip = "192.168.1.${id}/24";
$gateway = "192.168.1.1";
$bridge = "bridge0"; (2)
$epair = "epair${id}";
# ADD TO bridge INTERFACE
exec.prestart += "ifconfig ${epair} create up";
exec.prestart += "ifconfig ${epair}a up descr jail:${name}";
exec.prestart += "ifconfig ${bridge} addm ${epair}a up";
exec.start += "ifconfig ${epair}b ${ip} up";
exec.start += "route add default ${gateway}";
exec.poststop = "ifconfig ${bridge} deletem ${epair}a";
exec.poststop += "ifconfig ${epair}a destroy";
}
| 1 | 表示 Jail 的 IP 地址,它必须是 唯一的 。 <.> 指的是之前创建的桥接。 |
17.5.4. 创建一个 Linux Jail
FreeBSD 可以使用 Linux 二进制兼容性 和 debootstrap(8) 在 jail 中运行 Linux。jail 没有内核,它们在主机的内核上运行。因此,在主机系统中启用 Linux 二进制兼容性是必要的。
要在启动时启用 Linux ABI,请执行以下命令:
# sysrc linux_enable="YES"一旦启用,可以通过执行以下命令来启动,无需重新启动:
# service linux start下一步将是按照上述所示创建一个 jail ,例如在 使用 OpenZFS 快照创建一个瘦 Jail 中,但 不要 执行配置。FreeBSD Linux jail 需要特定的配置,将在下面详细说明。
一旦按照上述说明创建了 jail,执行以下命令进行所需的 jail 配置并启动它:
# jail -cm \
name=ubuntu \
host.hostname="ubuntu.example.com" \
path="/usr/local/jails/ubuntu" \
interface="em0" \
ip4.addr="192.168.1.150" \
exec.start="/bin/sh /etc/rc" \
exec.stop="/bin/sh /etc/rc.shutdown" \
mount.devfs \
devfs_ruleset=4 \
allow.mount \
allow.mount.devfs \
allow.mount.fdescfs \
allow.mount.procfs \
allow.mount.linprocfs \
allow.mount.linsysfs \
allow.mount.tmpfs \
enforce_statfs=1要访问 jail ,需要安装 sysutils/debootstrap。
执行以下命令以访问 FreeBSD Linux jail:
# jexec -u root ubuntu在 jail 内执行以下命令来安装 sysutils/debootstrap 并准备 Ubuntu 环境:
# pkg install debootstrap
# debootstrap jammy /compat/ubuntu当进程完成并在控制台上显示 successfully 消息时,需要通过执行以下命令在主机系统上停止 jail:
# service jail ubuntu onestop然后在 [/etc/jail.conf] 文件中添加一个 Linux jail 的条目:
ubuntu {
# STARTUP/LOGGING
exec.start = "/bin/sh /etc/rc";
exec.stop = "/bin/sh /etc/rc.shutdown";
exec.consolelog = "/var/log/jail_console_${name}.log";
# PERMISSIONS
allow.raw_sockets;
exec.clean;
mount.devfs;
devfs_ruleset=4;
# HOSTNAME/PATH
host.hostname = "${name}";
path = "/usr/local/jails/containers/${name}";
# NETWORK
ip4.addr = 192.168.1.155;
interface = em0;
# MOUNT
mount += "devfs $path/compat/ubuntu/dev devfs rw 0 0";
mount += "tmpfs $path/compat/ubuntu/dev/shm tmpfs rw,size=1g,mode=1777 0 0";
mount += "fdescfs $path/compat/ubuntu/dev/fd fdescfs rw,linrdlnk 0 0";
mount += "linprocfs $path/compat/ubuntu/proc linprocfs rw 0 0";
mount += "linsysfs $path/compat/ubuntu/sys linsysfs rw 0 0";
mount += "/tmp $path/compat/ubuntu/tmp nullfs rw 0 0";
mount += "/home $path/compat/ubuntu/home nullfs rw 0 0";
}
然后可以使用以下命令正常启动 jail:
# service jail start ubuntu可以使用以下命令访问 Ubuntu 环境:
# jexec ubuntu chroot /compat/ubuntu /bin/bash更多信息可以在章节 Linux 二进制兼容性 中找到。
17.6. Jail 管理
一旦创建了 jail,就可以执行许多操作,比如启动、重启或删除 jail,安装软件等。本节将描述可以在主机上执行的不同 jail 操作。
17.6.1. 列出运行中的 Jails
要列出运行在主机系统上的 jails,可以使用命令 jls(8)。
# jls输出应该类似于以下内容:
JID IP Address Hostname Path
1 192.168.250.70 classic /usr/local/jails/containers/classic
例如,执行以下命令以获取 JSON 输出:
# jls --libxo=json输出应该类似于以下内容:
{"__version": "2", "jail-information": {"jail": [{"jid":1,"ipv4":"192.168.250.70","hostname":"classic","path":"/usr/local/jails/containers/classic"}]}}
17.6.2. 启动、重新启动和停止一个 Jail
service(8) 用于在主机上启动、重启或停止一个 jail。
例如,要启动一个 jail,请运行以下命令:
# service jail start jailname将 start 参数更改为 restart 或 stop 以执行其他对 jail 的操作。
17.6.3. 销毁一个 jail
销毁一个 jail 并不像使用 service(8) 停止 jail 和删除 jail 目录以及 /etc/jail.conf 条目那样简单。
FreeBSD 非常重视系统安全。因此,有一些文件即使是 root 用户也无法删除。这种功能被称为文件标志。
第一步是停止所需的 jail 执行以下命令:
# service jail stop jailname第二步是使用 chflags(1) 命令来移除这些标志,执行以下命令,其中 classic 是要移除的 jail 的名称:
# chflags -R 0 /usr/local/jails/classic第三步是删除 jail 所在的目录:
# rm -rf /usr/local/jails/classic最后,需要在 /etc/jail.conf 或 jail.conf.d 中删除 jail 条目。
17.6.4. 在 Jail 中处理软件包
pkg(8) 工具支持 -j 参数,以处理安装在 jail 内的软件包。
例如,在 jail 中安装 nginx-lite,可以从主机上执行以下命令:
# pkg -j classic install nginx-lite有关在 FreeBSD 中使用软件包的更多信息,请参阅 “安装应用程序:软件包和 Ports”。
17.6.5. 访问一个 Jail
虽然上面已经提到最好从主机系统管理 jail,但可以使用 jexec(8) 进入 jail。
可以通过在主机上运行 jexec(8) 来进入 jail。
# jexec -u root jailname当访问 jail 时,将显示在 motd(5) 中配置的消息。
17.6.6. 在 Jail 中执行命令
要在一个 jail 中从主机系统执行命令,可以使用 jexec(8) 命令。
例如,要停止在 jail 中运行的服务,将执行以下命令:
# jexec -l jailname service stop nginx17.7. Jail 升级
升级 FreeBSD Jails 可以确保隔离环境保持安全、最新,并与 FreeBSD 生态系统中的最新功能和改进保持一致。
17.7.1. 使用 OpenZFS 快照升级经典 Jail 或薄 Jail
Jails 必须从主机操作系统进行更新。在 FreeBSD 中,默认行为是禁止在 jail 中使用 chflags(1) 命令。这将阻止对某些文件的更新,因此在 jail 内部进行更新将失败。
要将 jail 更新到运行的 FreeBSD 版本的最新补丁版本,请在主机上执行以下命令:
# freebsd-update -j classic fetch install
# service jail restart classic要将 jail 升级到新的主要或次要版本,首先按照 “执行主要和次要版本升级” 中描述的方法升级主机系统。一旦主机升级并重新启动,就可以升级 jail。
|
如果从一个版本升级到另一个版本,创建一个新的 jail 比完全升级更容易。 |
例如,要从 13.1-RELEASE 升级到 13.2-RELEASE,请在主机上执行以下命令:
# freebsd-update -j classic -r 13.2-RELEASE upgrade
# freebsd-update -j classic install
# service jail restart classic
# freebsd-update -j classic install
# service jail restart classic|
需要执行两次 |
然后,如果是一个主要版本的升级,重新安装所有已安装的软件包并重新启动 jail。这是必需的,因为在 FreeBSD 的主要版本之间升级时,ABI 版本会发生变化。
来自主机:
# pkg -j jailname upgrade -f
# service jail restart jailname17.7.2. 使用 NullFS 升级薄 Jail
由于使用 NullFS 的薄 Jails 共享了大部分系统目录,因此它们非常容易更新。只需更新模板即可,这样可以同时更新多个 Jail。
要将模板更新到运行的 FreeBSD 版本的最新补丁版本,请在主机上执行以下命令:
# freebsd-update -b /usr/local/jails/templates/13.1-RELEASE-base/ fetch install
# service jail restart要将模板升级到新的主要或次要版本,首先按照 “执行主要和次要版本升级” 中描述的方式升级主机系统。一旦主机升级并重新启动,然后可以升级模板。
例如,要从 13.1-RELEASE 升级到 13.2-RELEASE ,请在主机上执行以下命令:
# freebsd-update -b /usr/local/jails/templates/13.1-RELEASE-base/ -r 13.2-RELEASE upgrade
# freebsd-update -b /usr/local/jails/templates/13.1-RELEASE-base/ install
# service jail restart
# freebsd-update -b /usr/local/jails/templates/13.1-RELEASE-base/ install
# service jail restart17.8. Jail 资源限制
系统管理员需要考虑从主机系统控制 jail 使用的资源的任务。
rctl(8) 允许您从主机系统管理 jail 可以使用的资源。
|
必须在 |
限制 jail 资源的语法如下:
rctl -a jail:<jailname>:resource:action=amount/percentage
例如,要限制一个 jail 可以访问的最大 RAM,运行以下命令:
# rctl -a jail:classic:memoryuse:deny=2G为了使限制在主机系统重新启动后仍然有效,需要将规则添加到 /etc/rctl.conf 文件中,如下所示:
jail:classic:memoryuse:deny=2G/jail
有关资源限制的更多信息可以在安全章节中找到,具体请参考 “资源限制部分” 。
17.9. Jail 管理器和容器
如前所述,每种类型的 FreeBSD Jail 都可以手动创建和配置,但 FreeBSD 还有第三方工具可以使配置和管理更加简便。
下面是一个不完整的不同 FreeBSD Jail 管理器的列表:
| 名称 | 许可证 | 包 | 文档 |
|---|---|---|---|
BastilleBSD |
BSD-3 |
||
pot |
BSD-3 |
||
cbsd |
BSD-2 |
||
AppJail |
BSD-3 |
sysutils/appjail, for devel sysutils/appjail-devel |
|
iocage |
BSD-2 |
||
ezjail |
Chapter 18. 强制访问控制
18.1. 简介
FreeBSD 支持基于 POSIX®.1e 草案的安全扩展。这些安全机制包括文件系统访问控制列表(“访问控制列表”)和强制访问控制(MAC)。MAC 允许加载访问控制模块以实施安全策略。一些模块为系统的一小部分提供保护,加固特定服务。其他模块提供全面的标记安全性,涵盖所有主体和对象。定义中的强制部分表示控制的执行由管理员和操作系统执行。这与默认的自主访问控制(DAC)安全机制形成对比,后者将执行权留给用户自行决定。
本章重点介绍 MAC 框架以及 FreeBSD 提供的一组可插拔安全策略模块,用于启用各种安全机制。
阅读完本章后,你将会了解:
-
与 MAC 框架相关的术语。
-
MAC 安全策略模块的功能以及标记和非标记策略之间的区别。
-
在配置系统使用 MAC 框架之前需要考虑的因素。
-
FreeBSD 中包含哪些 MAC 安全策略模块以及如何配置它们。
-
如何使用 MAC 框架实现更安全的环境。
-
如何测试 MAC 配置以确保框架已经正确实施。
在阅读本章之前,你应该:
-
了解 UNIX® 和 FreeBSD 基础知识。
-
对于安全性以及它与 FreeBSD 的相关性有一定的了解(安全性)。
|
不正确的 MAC 配置可能导致系统访问丢失,用户受到困扰,或无法访问 Xorg 提供的功能。更重要的是,不能仅依赖 MAC 来完全保护系统。 MAC 框架只是增强现有安全策略。如果没有健全的安全实践和定期的安全检查,系统将永远无法完全安全。 本章中包含的示例仅用于演示目的,示例设置 不应 在生产系统上实施。实施任何安全策略都需要充分理解、正确设计和彻底测试。 |
尽管本章涵盖了与 MAC 框架相关的广泛安全问题,但不包括开发新的 MAC 安全策略模块。 MAC 框架附带的一些安全策略模块具有特定特性,既用于测试,也用于新模块的开发。有关这些安全策略模块及其提供的各种机制的更多信息,请参阅 mac_test(4),mac_stub(4) 和 mac_none(4)。
18.2. 关键术语
在提到 MAC 框架时,使用以下关键术语:
-
隔离区(compartment):一组要进行分区或分离的程序和数据,用户被授予对系统特定组件的明确访问权限。隔离区表示一种分组,例如工作组、部门、项目或主题。隔离区使得实施需要知道的安全策略成为可能。
-
完整性(integrity):可以对数据放置的信任级别。随着数据的完整性提高,对该数据的信任能力也随之增强。
-
级别(level): 安全属性的增加或减少设置。随着级别的提高,其安全性也被认为提升。
-
标签(label):一个可以应用于系统中的文件、目录或其他项目的安全属性。它可以被视为一个机密性标记。当一个标签被放置在一个文件上时,它描述了该文件的安全属性,并且只允许具有相似安全设置的文件、用户和资源访问。标签值的含义和解释取决于策略配置。一些策略将标签视为表示对象的完整性或保密性,而其他策略可能使用标签来保存访问规则。
-
多标签(multilabel):这个属性是一个文件系统选项,可以在单用户模式下使用 tunefs(8) 设置,在启动时使用 fstab(5) 设置,或在创建新文件系统时设置。此选项允许管理员在不同的对象上应用不同的 MAC 标签。此选项仅适用于支持标签的安全策略模块。
-
单标签(single label):一种策略,整个文件系统使用一个标签来强制对数据流进行访问控制。只要未设置
多标签,所有文件都将符合相同的标签设置。 -
对象(object):在 主体 的指导下,信息流经过的实体。这包括目录、文件、字段、屏幕、键盘、内存、磁存储、打印机或任何其他数据存储或移动设备。对象是一个数据容器或系统资源。访问对象实际上意味着访问其数据。
-
主体(subject): 任何能够在对象之间传递信息的活动实体,例如用户、用户进程或系统进程。在 FreeBSD 上,这几乎总是一个代表用户的进程中的线程。
-
策略(policy):一系列规则的集合,定义了如何实现目标。策略通常记录了如何处理特定事项。本章将策略视为一系列控制数据和信息流动并定义谁可以访问这些数据和信息的规则。
-
高水位线(high-watermark):这种策略允许提高安全级别以访问更高级别的信息。在大多数情况下,完成进程后会恢复原始级别。目前,FreeBSD MAC 框架不包括这种类型的策略。
-
低水位线(low-watermark):这种类型的策略允许降低安全级别以访问较不安全的信息。在大多数情况下,完成过程后,用户的原始安全级别将恢复。在 FreeBSD 中,唯一使用此策略的安全策略模块是 mac_lomac(4)。
-
敏感性(sensitivity):通常在讨论多级安全性(MLS)时使用。敏感性级别描述了数据的重要性或机密性。随着敏感性级别的提高,数据的保密性或机密性的重要性也增加。
18.3. 理解 MAC 标签
MAC 标签是一种安全属性,可以应用于系统中的主体和对象。在设置标签时,管理员必须理解其影响,以防止系统出现意外或不希望的行为。对象上可用的属性取决于加载的策略模块,因为策略模块以不同的方式解释其属性。
对象上的安全标签是安全访问控制决策中的一部分。在某些策略中,标签包含了做出决策所需的所有信息。在其他策略中,标签可能作为一个更大的规则集的一部分进行处理。
有两种类型的标签策略:单标签和多标签。默认情况下,系统将使用单标签。管理员应该了解每种类型的优缺点,以便实施符合系统安全模型要求的策略。
单标签安全策略只允许每个主体或对象使用一个标签。由于单标签策略在整个系统上强制执行一组访问权限,因此它提供了较低的管理开销,但降低了支持标记的策略的灵活性。然而,在许多环境中,单标签策略可能就是所需的全部。
单标签策略在某种程度上类似于 DAC,因为 root 配置策略以便将用户放置在适当的类别和访问级别中。一个显著的区别是许多策略模块也可以限制 root。然后,对对象的基本控制将释放给组,但 root 可以随时撤销或修改设置。
在适当的情况下,可以通过将 multilabel 传递给 tunefs[8] 在 UFS 文件系统上设置多标签策略。多标签策略允许每个主体或对象拥有自己独立的 MAC 标签。对于实现标签功能的策略(如 biba、lomac 和 mls),只有在使用多标签或单标签策略时才需要做出决策。一些策略,如 seeotheruids、portacl 和 `partition ,根本不使用标签。
在分区上使用多标签策略并建立多标签安全模型可能会增加管理开销,因为文件系统中的所有内容都有标签,包括目录、文件甚至设备节点。
以下命令将在指定的 UFS 文件系统上设置 multilabel。这只能在单用户模式下执行,并且对于交换文件系统来说并不是必需的。
# tunefs -l enable /|
一些用户在设置根分区的 |
由于多标签策略是基于每个文件系统的设置,如果文件系统布局设计良好,则可能不需要多标签策略。以 FreeBSD Web 服务器为例,考虑一个安全的 MAC 模型。该机器在默认文件系统中使用单个标签 biba/high。如果 Web 服务器需要以 biba/low 运行以防止写入权限,可以将其安装到一个单独的 UFS /usr/local 文件系统,设置为 biba/low。
18.3.1. 标签配置
几乎所有标签策略模块配置的方面都可以使用基本系统工具来完成。这些命令提供了一个简单的界面,用于对象或主体的配置,或者用于配置的操作和验证。
所有的配置都可以使用 setfmac 来完成, setfmac 用于在系统对象上设置 MAC 标签,而 setpmac 用于在系统主体上设置标签。例如,要在 test 上将 biba MAC 标签设置为 high,可以使用以下命令:
# setfmac biba/high test如果配置成功,将返回无错误的提示。常见的错误是 Permission denied,通常发生在对受限对象设置或修改标签时。其他情况可能导致不同的失败。例如,文件可能不是尝试重新标记对象的用户拥有的,对象可能不存在,或者对象可能是只读的。强制策略将不允许进程重新标记文件,可能是因为文件的属性、进程的属性或建议的新标签值的属性。例如,如果以低完整性运行的用户尝试更改高完整性文件的标签,或者以低完整性运行的用户尝试将低完整性文件的标签更改为高完整性标签,这些操作将失败。
系统管理员可以使用 setpmac 命令通过为调用的进程分配不同的标签来覆盖策略模块的设置:
# setfmac biba/high test
Permission denied
# setpmac biba/low setfmac biba/high test
# getfmac test
test: biba/high对于当前正在运行的进程,例如 sendmail ,通常使用 getpmac 命令。该命令使用进程 ID(PID)代替命令名称。如果用户尝试操作不在其访问权限范围内的文件,根据加载的策略模块的规则,将显示 操作不允许(Operation not permitted) 的错误。
18.3.2. 预定义标签
一些支持标签功能的 FreeBSD 策略模块提供了三个预定义标签:low、equal 和 high,其中:
-
low被认为是对象或主体可能具有的最低标签设置。将其设置在对象或主体上会阻止它们访问被标记为高的对象或主体。 -
equal将主题或对象设置为禁用或不受影响,并且只应放置在被视为豁免政策的对象上。 -
high在 Biba 和 MLS 策略模块中为对象或主体授予最高的设置。
这些策略模块包括 mac_biba(4)、mac_mls(4) 和 mac_lomac(4)。每个预定义标签都建立了不同的信息流指令。请参考模块的手册页面以确定通用标签配置的特性。
18.3.3. 数字标签
Biba 和 MLS 策略模块支持一个数字标签,可以设置为指示精确的层次控制级别。这个数字级别用于将信息分区或分类到不同的分类组中,只允许访问该组或更高级别的组。例如:
biba/10:2+3+6(5:2+3-20:2+3+4+5+6)
可以解释为 “Biba 策略标签/等级 10:隔间 2,3 和 6:(等级 5 … )”
在这个例子中,第一等级被认为是具有有效隔间的有效等级,第二等级是低等级,最后一个是高等级。在大多数配置中,这样细粒度的设置是不需要的,因为它们被认为是高级配置。
系统对象只有当前等级和隔间。系统主体反映了系统中可用权限的范围,以及网络接口,它们用于访问控制。
在一个主体和对象对中,等级和隔间被用来构建一种被称为“优势”的关系,其中主体优势于对象,对象优势于主体,两者互不优势,或者两者互相优势。当两个标签相等时,会出现“两者互相优势”的情况。由于 Biba 的信息流特性,用户对一组可能对应于项目的隔间拥有权限,但对象也有一组隔间。用户可能需要使用 su 或 setpmac 来对其权限进行子集化,以便从受限制的隔间中访问对象。
18.3.4. 用户标签
用户需要具有标签,以便他们的文件和进程能够与系统上定义的安全策略正确交互。这是通过在 /etc/login.conf 中使用登录类进行配置的。每个使用标签的策略模块都会实现用户类设置。
要设置用户类的默认标签,该标签将由 MAC 强制执行,请添加一个 label 条目。下面显示了一个包含每个策略模块的示例 label 条目。请注意,在实际配置中,管理员永远不会启用每个策略模块。建议在实施任何配置之前先阅读本章的其余部分。
default:\ :copyright=/etc/COPYRIGHT:\ :welcome=/etc/motd:\ :setenv=MAIL=/var/mail/$,BLOCKSIZE=K:\ :path=~/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin:\ :manpath=/usr/share/man /usr/local/man:\ :nologin=/usr/sbin/nologin:\ :cputime=1h30m:\ :datasize=8M:\ :vmemoryuse=100M:\ :stacksize=2M:\ :memorylocked=4M:\ :memoryuse=8M:\ :filesize=8M:\ :coredumpsize=8M:\ :openfiles=24:\ :maxproc=32:\ :priority=0:\ :requirehome:\ :passwordtime=91d:\ :umask=022:\ :ignoretime@:\ :label=partition/13,mls/5,biba/10(5-15),lomac/10[2]:
用户无法修改默认值,但他们可以在登录后更改标签,但必须符合策略的限制。上面的示例告诉 Biba 策略,进程的最小完整性为 5,最大完整性为 15,默认有效标签为 10。进程将在 10 上运行,直到它选择更改标签,可能是由于用户使用 setpmac,该操作将受到 Biba 配置范围的限制。
对于 login.conf 的任何更改,必须使用 cap_mkdb 重新构建登录类能力数据库。
许多网站拥有大量用户,需要多个不同的用户类别。这需要进行深入的规划,因为这可能变得难以管理。
18.3.5. 网络接口标签
可以在网络接口上设置标签来帮助控制数据在网络中的流动。使用网络接口标签的策略与对象相关的策略的功能相同。例如,在 Biba 中设置为高级别的用户将不被允许访问标签为 低(low) 的网络接口。
在设置网络接口的 MAC 标签时,可以通过 ifconfig 传递 maclabel 参数:
# ifconfig bge0 maclabel biba/equal这个示例将在 bge0 接口上设置 biba/equal 的 MAC 标签。当使用类似于 biba/high(low-high) 的设置时,应该将整个标签用引号括起来,以防止返回错误。
每个支持标签的策略模块都有一个可调节项,可以用来禁用网络接口上的 MAC 标签。将标签设置为 equal 将产生类似的效果。请查看 sysctl 的输出、策略手册页面以及本章节中的其他信息,以获取有关这些可调节项的更多信息。
18.4. 规划安全配置
在实施任何 MAC 策略之前,建议先进行规划。在规划阶段,管理员应考虑实施要求和目标,例如:
-
如何对目标系统上的信息和资源进行分类。
-
应限制访问的信息或资源以及应该应用的限制类型。
-
为实现这个目标,将需要哪些 MAC 模块?
在将 MAC 实施到生产系统 之前,应进行可信系统及其配置的试运行。由于不同的环境具有不同的需求和要求,建立完整的安全配置文件将减少系统投入使用后的更改需求。
考虑 MAC 框架如何增强整个系统的安全性。MAC 框架提供的各种安全策略模块可以用于保护网络和文件系统,或者阻止用户访问特定的端口和套接字。也许最好的使用策略模块的方式是同时加载多个安全策略模块,以提供 MLS 环境。这种方法与硬化策略不同,硬化策略通常只针对系统中仅用于特定目的的元素进行硬化。 MLS 的缺点是增加了管理开销。
与提供选择特定配置所需的策略并降低性能开销的框架相比,开销是最小的。减少对不需要的策略的支持可以提高系统的整体性能,并提供选择的灵活性。一个良好的实现应该考虑整体安全要求,并有效地实施框架提供的各种安全策略模块。
使用 MAC 的系统可以确保用户不能随意更改安全属性。所有用户工具、程序和脚本必须在所选安全策略模块提供的访问规则约束下运行,而 MAC 访问规则的控制则由系统管理员负责。
系统管理员有责任仔细选择正确的安全策略模块。对于需要限制网络访问控制的环境,mac_portacl(4)、mac_ifoff(4) 和 mac_biba(4) 策略模块是很好的起点。对于需要严格保密文件系统对象的环境,可以考虑使用 mac_bsdextended(4) 和 mac_mls(4) 策略模块。
基于网络配置可以做出政策决策。如果只允许特定用户访问 ssh(1) ,那么 mac_portacl(4) 策略模块是一个不错的选择。在文件系统的情况下,对于某些用户来说,对对象的访问可能被视为机密,而对其他用户来说则不是。例如,一个大型开发团队可能会被分成较小的项目,项目 A 的开发人员可能不被允许访问项目 B 的开发人员编写的对象。然而,这两个项目可能需要访问项目 C 的开发人员创建的对象。使用 MAC 框架提供的不同安全策略模块,可以将用户分成这些组,并为其提供对应对象的访问权限。
每个安全策略模块都有一种独特的处理系统整体安全的方式。模块的选择应该基于经过深思熟虑的安全策略,可能需要进行修订和重新实施。了解 MAC 框架提供的不同安全策略模块将帮助管理员为他们的情况选择最佳策略。
本章的其余部分介绍了可用的模块,描述了它们的使用和配置,并在某些情况下提供了适用情况的见解。
|
实施 MAC 与实施防火墙非常相似,因为必须小心防止完全被系统锁定。应考虑能够恢复到先前的配置,并且在远程连接上实施 MAC 时应极度谨慎。 |
18.5. 可用的 MAC 策略
默认的 FreeBSD 内核包含 options MAC。这意味着 MAC 框架中包含的每个模块都可以作为运行时内核模块使用 kldload 加载。在测试完模块后,将模块名称添加到 /boot/loader.conf ,以便在启动时加载。对于那些选择编译自定义内核的管理员,每个模块还提供了一个内核选项。
FreeBSD 包含一组策略,可以满足大多数安全需求。下面对每个策略进行了总结。最后三个策略支持使用整数设置替代三个默认标签。
18.5.1. MAC 查看其他 UID 策略
模块名称:mac_seeotheruids.ko
内核配置行:options MAC_SEEOTHERUIDS
启动选项:mac_seeotheruids_load ="YES"
mac_seeotheruids(4) 模块扩展了 security.bsd.see_other_uids 和 security.bsd.see_other_gids sysctl 可调整参数。该选项在配置之前不需要设置任何标签,并且可以与其他模块透明地协同工作。
加载模块后,可以使用以下 sysctl 可调整项来控制其功能:
-
security.mac.seeotheruids.enabled启用该模块并实现默认设置,禁止用户查看其他用户拥有的进程和套接字。 -
security.mac.seeotheruids.specificgid_enabled允许指定的组免除此策略。要免除特定的组,请使用security.mac.seeotheruids.specificgid =XXX sysctl可调节参数,将 XXX 替换为要免除的数字组 ID。 -
security.mac.seeotheruids.primarygroup_enabled用于免除特定的主要组免受此策略的影响。当使用此可调整项时,不得设置security.mac.seeotheruids.specificgid_enabled。
18.5.2. MAC BSD 扩展策略
模块名称:mac_bsdextended.ko
内核配置行:options MAC_BSDEXTENDED
启动选项:mac_bsdextended_load ="YES"
mac_bsdextended(4) 模块实施了一个文件系统防火墙。它为标准文件系统权限模型提供了扩展,允许管理员创建类似防火墙的规则集来保护文件系统层次结构中的文件、实用程序和目录。当尝试访问文件系统对象时,将迭代规则列表,直到找到匹配的规则或到达末尾为止。可以使用 security.mac.bsdextended.firstmatch_enabled 来更改此行为。与 FreeBSD 中的其他防火墙模块类似,可以使用 rc.conf(5) 变量在系统启动时创建和读取包含访问控制规则的文件。
规则列表可以使用 ugidfw(8) 输入,其语法类似于 ipfw(8)。通过使用 libugidfw(3) 库中的函数,可以编写更多的工具。
在加载了 mac_bsdextended(4) 模块之后,可以使用以下命令列出当前的规则配置:
# ugidfw list
0 slots, 0 rules默认情况下,没有定义任何规则,所有内容都是完全可访问的。要创建一个规则,阻止用户的所有访问,但不影响 root 用户:
# ugidfw add subject not uid root new object not uid root mode n虽然这个规则很容易实现,但它是一个非常糟糕的想法,因为它会阻止所有用户发出任何命令。一个更现实的例子是阻止 user1 访问 user2 的主目录,包括目录列表。
# ugidfw set 2 subject uid user1 object uid user2 mode n
# ugidfw set 3 subject uid user1 object gid user2 mode n可以使用 not uid user2 来代替 user1,以便为所有用户强制相同的访问限制。然而,这些规则对 root 用户无效。
|
在使用该模块时应极度谨慎,因为错误的使用可能会阻止对文件系统的某些部分的访问。 |
18.5.3. MAC 接口禁止策略
模块名称:mac_ifoff.ko
内核配置行:options MAC_IFOFF
启动选项:mac_ifoff_load ="YES"
mac_ifoff(4) 模块用于动态禁用网络接口,并防止在系统启动期间启用网络接口。它不使用标签,也不依赖于任何其他 MAC 模块。
大部分该模块的控制是通过这些 sysctl 可调参数进行的:
mac_ifoff(4) 的最常见用途之一是在启动序列期间不允许网络流量的环境中进行网络监控。另一个用途是编写一个脚本,使用类似 security/aide 的应用程序,在受保护的目录中发现新文件或更改文件时自动阻止网络流量。
18.5.4. MAC 端口访问控制列表策略
模块名称:mac_portacl.ko
内核配置行:MAC_PORTACL
引导选项:mac_portacl_load ="YES"
mac_portacl(4) 模块用于限制绑定到本地 TCP 和 UDP 端口,使非 root 用户能够绑定到指定的特权端口(低于 1024)。
一旦加载,该模块将在所有套接字上启用 MAC 策略。以下可调整项可用:
-
security.mac.portacl.enabled用于启用或禁用该策略。 -
security.mac.portacl.port_high设置了 mac_portacl(4) 保护的最高端口号。 -
当
security.mac.portacl.suser_exempt设置为非零值时,免除root用户遵守此策略。 -
security.mac.portacl.rules指定了策略,其格式为rule[,rule,…]的文本字符串,可以包含多个规则,每个规则的格式为idtype:id:protocol:port。idtype可以是uid或gid。protocol参数可以是tcp或udp。port参数是允许指定的用户或组绑定的端口号。用户 ID、组 ID 和端口参数只能使用数字值。
默认情况下,只有以 root 身份运行的特权进程才能使用小于 1024 的端口。要允许非特权进程绑定到小于 1024 的端口,可以按照以下方式设置 mac_portacl(4) 中的可调整参数:
# sysctl security.mac.portacl.port_high=1023
# sysctl net.inet.ip.portrange.reservedlow=0
# sysctl net.inet.ip.portrange.reservedhigh=0为了防止 root 用户受到此策略的影响,请将 security.mac.portacl.suser_exempt 设置为非零值。
# sysctl security.mac.portacl.suser_exempt=1为了允许 UID 为 80 的 www 用户在不需要 root 权限的情况下绑定到端口 80:
# sysctl security.mac.portacl.rules=uid:80:tcp:80下面的示例允许具有 UID 为 1001 的用户绑定到 TCP 端口 110(POP3)和 995(POP3s):
# sysctl security.mac.portacl.rules=uid:1001:tcp:110,uid:1001:tcp:99518.5.5. MAC 分区策略
模块名称:mac_partition.ko
内核配置行:options MAC_PARTITION
启动选项:mac_partition_load ="YES"
mac_partition(4) 策略根据进程的 MAC 标签将其分配到特定的“分区”中。大部分该策略的配置都是使用 setpmac(8) 完成的。该策略有一个可调整的 sysctl 参数。
-
security.mac.partition.enabled启用了 MAC 进程分区的强制执行。
当启用此策略时,用户只能查看他们自己的进程以及其所在分区的其他进程,但不允许使用超出该分区范围的实用工具。例如,属于 不安全(insecure) 类别的用户将无法访问 top 以及许多其他需要生成进程的命令。
这个例子将 top 添加到 insecure 类别中的用户标签集合中。所有由 insecure 类别中的用户生成的进程都将保持在 partition/13 标签中。
# setpmac partition/13 top该命令显示分区标签和进程列表:
# ps Zax该命令显示另一个用户的进程分区标签以及该用户当前正在运行的进程:
# ps -ZU trhodes|
除非加载了 mac_seeotheruids(4) 策略,否则用户可以看到 |
18.5.6. MAC 多级安全模块
模块名称:mac_mls.ko
内核配置行:options MAC_MLS
启动选项:mac_mls_load ="YES"
mac_mls(4) 策略通过执行严格的信息流策略来控制系统中主体和对象之间的访问。
在 MLS 环境中,每个主体或对象的标签中都设置了一个“许可(clearance)”级别,以及隔间。由于这些许可级别可以达到几千以上的数字,彻底配置每个主体或对象将是一项艰巨的任务。为了减轻这种管理负担,该策略中包括了三个标签: mls/low,mls/equal 和 mls/high,其中:
-
任何标记为
mls/low的内容都具有低许可级别,不允许访问更高级别的信息。该标签还阻止高许可级别的对象向低级别写入或传递信息。 -
mls/equal应该被放置在应该被豁免政策的对象上。 -
mls/high是最高级别的许可级别。被分配此标签的对象将在系统中具有最高权限;然而,它们不会允许信息泄漏给较低级别的对象。
MLS 提供以下功能:
-
一个具有一组非层次化类别的分层安全级别。
-
固定的规则是
不可向上读取,不可向下写入。这意味着一个主体可以对其自身级别或以下级别的对象具有读取访问权限,但不能对以上级别的对象具有读取访问权限。同样地,一个主体可以对其自身级别或以上级别的对象具有写入访问权限,但不能对以下级别的对象具有写入访问权限。 -
保密性,或者说是防止数据不适当披露的措施。
-
设计能够同时处理多个敏感级别数据的系统基础,而不会在秘密和机密之间泄露信息。
以下是可用的 sysctl 可调整参数:
-
security.mac.mls.enabled用于启用或禁用 MLS 策略。 -
security.mac.mls.ptys_equal在创建过程中将所有pty(4)设备标记为mls/equal。 -
security.mac.mls.revocation_enabled在对象的标签变为较低等级的标签后,撤销对该对象的访问权限。 -
security.mac.mls.max_compartments设置系统允许的最大隔离级别数量。
要操作 MLS 标签,请使用 setfmac(8)。要为对象分配一个标签:
# setfmac mls/5 test获取文件 test 的 MLS 标签:
# getfmac test另一种方法是在 /etc/ 目录下创建一个主策略文件,该文件指定了 MLS 策略信息,并将该文件提供给 setfmac 命令。
当使用 MLS 策略模块时,管理员计划控制敏感信息的流动。默认的 block read up block write down 将所有内容设置为低状态。所有内容都是可访问的,管理员会逐渐增加信息的机密性。
除了三种基本的标签选项之外,管理员还可以根据需要将用户和组进行分组,以阻止它们之间的信息流动。使用描述性词语,如 机密、秘密 和 绝密 来查看清除级别的信息可能更容易。一些管理员根据项目级别创建不同的组。无论分类方法如何,都必须在实施限制性政策之前制定一个经过深思熟虑的计划。
MLS 策略模块的一些示例情况包括电子商务网站服务器、存储关键公司信息的文件服务器和金融机构环境。
18.5.7. MAC Biba 模块
模块名称:mac_biba.ko
内核配置行:options MAC_BIBA
启动选项:mac_biba_load ="YES"
mac_biba(4) 模块加载了 MAC Biba 策略。该策略与 MLS 策略类似,但信息流动规则略有不同。这是为了防止敏感信息的向下流动,而 MLS 策略则防止敏感信息的向上流动。
在 Biba 环境中,每个主体或对象都会设置一个“完整性(integrity)”标签。这些标签由层次等级和非层次组成。随着等级的提升,完整性也会提高。
支持的标签有 biba/low、biba/equal 和 biba/high,其中:
-
biba/low被认为是对象或主体可能具有的最低完整性。将其设置在对象或主体上会阻止它们对标记为biba/high的对象或主体的写访问,但不会阻止读访问。 -
biba/equal应该只被应用于被认为符合政策的对象上。 -
biba/high允许对设置在较低标签的对象进行写操作,但不允许读取该对象。建议将此标签放置在影响整个系统完整性的对象上。
Biba 提供:
-
具有一组非层次化完整性类别的层次完整性级别。
-
固定规则是
不可向上写入,不可向下读取,与 MLS 相反。主体可以对其自身级别或以下的对象具有写入访问权限,但不能对其以上的对象具有写入访问权限。同样地,主体可以对其自身级别或以上的对象具有读取访问权限,但不能对其以下的对象具有读取访问权限。 -
通过防止数据的不适当修改来保持完整性。
-
完整性级别而不是 MLS 敏感级别。
以下可调整项可用于操作 Biba 策略:
-
security.mac.biba.enabled用于在目标机器上启用或禁用 Biba 策略的执行。 -
security.mac.biba.ptys_equal用于禁用 Biba 策略对 pty(4) 设备的应用。 -
如果标签被更改为支配主体,则
security.mac.biba.revocation_enabled强制撤销对对象的访问权限。
要访问系统对象上的 Biba 策略设置,请使用 setfmac 和 getfmac 命令:
# setfmac biba/low test
# getfmac test
test: biba/low完整性与敏感性不同,用于确保信息不被不受信任的方进行篡改。这包括主体和对象之间传递的信息。它确保用户只能修改或访问他们被明确授权的信息。 mac_biba(4) 安全策略模块允许管理员配置用户可以查看和调用哪些文件和程序,同时确保这些程序和文件对该用户是可信的。
在初始规划阶段,管理员必须准备好将用户分成等级、级别和领域。一旦启用了该策略模块,系统将默认为高级别,并由管理员配置用户的不同等级和级别。与使用许可级别不同,一个好的规划方法可以包括主题。例如,只允许开发人员对源代码仓库、源代码编译器和其他开发工具进行修改访问。其他用户将被分组到其他类别,如测试人员、设计师或最终用户,并且只允许读取访问权限。
较低完整性的主体无法向较高完整性的主体写入,而较高完整性的主体无法列出或读取较低完整性的对象。将标签设置为最低等级可能会使主体无法访问。此安全策略模块的一些潜在环境包括受限的 Web 服务器、开发和测试机器以及源代码存储库。较少有用的实现可能是个人工作站、用作路由器的机器或网络防火墙。
18.5.8. MAC 低水位标记模块
模块名称:mac_lomac.ko
内核配置行:options MAC_LOMAC
启动选项:mac_lomac_load ="YES"
与 MAC Biba 策略不同, mac_lomac(4) 策略允许在降低完整性级别以不破坏任何完整性规则的情况下访问较低完整性对象。
低水位完整性策略与 Biba 几乎完全相同,唯一的区别是使用浮动标签来支持通过辅助等级隔离主体。这个辅助等级隔离采用 [auxgrade] 的形式。当分配一个带有辅助等级的策略时,使用语法 lomac/10[2],其中 2 是辅助等级。
该策略依赖于对所有系统对象进行普遍标记的完整性标签,允许主体从低完整性对象读取,并通过 [auxgrade] 将主体的标签降级,以防止将来对高完整性对象进行写入。与 Biba 相比,该策略可能提供更高的兼容性,并且需要较少的初始配置。
与 Biba 和 MLS 策略类似,setfmac 和 setpmac 用于给系统对象打上标签:
# setfmac /usr/home/trhodes lomac/high[low]
# getfmac /usr/home/trhodes lomac/high[low]辅助等级 low 是仅由 MACLOMAC 策略提供的一个特性。
18.6. 用户锁定
这个例子考虑了一个相对较小的存储系统,用户数量少于 50 人。用户将具有登录功能,并被允许存储数据和访问资源。
对于这种情况,mac_bsdextended(4) 和 mac_seeotheruids(4) 策略模块可以共存,并且可以阻止对系统对象的访问,同时隐藏用户进程。
首先,在 /boot/loader.conf 文件中添加以下行:
mac_seeotheruids_load="YES"
通过将以下行添加到 /etc/rc.conf,可以激活 mac_bsdextended(4) 安全策略模块:
ugidfw_enable="YES"
系统初始化时将加载存储在 /etc/rc.bsdextended 文件中的默认规则。然而,默认条目可能需要修改。由于此机器预计只为用户提供服务,因此除了最后两行外,可以将所有内容都注释掉,以便默认情况下强制加载用户拥有的系统对象。
将所需的用户添加到该机器并重新启动。为了测试目的,尝试在两个控制台上使用不同的用户登录。运行 ps aux 命令查看其他用户的进程是否可见。验证在另一个用户的主目录上运行 ls(1) 命令是否失败。
除非特定的 sysctl 已被修改以阻止超级用户访问,否则不要尝试使用 root 用户进行测试。
|
当添加一个新用户时,他们的 mac_bsdextended(4) 规则将不会出现在规则集列表中。为了快速更新规则集,可以使用 kldunload(8) 和 kldload(8) 命令卸载和重新加载安全策略模块。 |
18.7. 在 MAC Jail 中的 Nagios
本节演示了在 MAC 环境中实施 Nagios 网络监控系统所需的步骤。这仅作为一个示例,管理员在将该策略应用于生产环境之前需要测试其是否符合网络的安全要求。
在进行此示例之前,需要在每个文件系统上设置 multilabel。同时,还假设在将其集成到 MAC 框架之前,已经安装、配置并正确运行了 net-mgmt/nagios-plugins 、net-mgmt/nagios 和 www/apache22 。
18.7.1. 创建一个不安全的用户类
在 /etc/login.conf 中添加以下用户类别,开始该过程:
insecure:\ :copyright=/etc/COPYRIGHT:\ :welcome=/etc/motd:\ :setenv=MAIL=/var/mail/$,BLOCKSIZE=K:\ :path=~/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin :manpath=/usr/share/man /usr/local/man:\ :nologin=/usr/sbin/nologin:\ :cputime=1h30m:\ :datasize=8M:\ :vmemoryuse=100M:\ :stacksize=2M:\ :memorylocked=4M:\ :memoryuse=8M:\ :filesize=8M:\ :coredumpsize=8M:\ :openfiles=24:\ :maxproc=32:\ :priority=0:\ :requirehome:\ :passwordtime=91d:\ :umask=022:\ :ignoretime@:\ :label=biba/10(10-10):
然后,在默认用户类部分添加以下行:
:label=biba/high:
保存修改并执行以下命令以重建数据库:
# cap_mkdb /etc/login.conf18.7.2. 配置用户
使用以下命令将 root 用户设置为默认类:
# pw usermod root -L default所有不是 root 的用户帐户现在都需要一个登录类。否则,用户将被拒绝访问常用命令。下面的 sh 脚本应该能解决问题:
# for x in `awk -F: '($3 >= 1001) && ($3 != 65534) { print $1 }' \
/etc/passwd`; do pw usermod $x -L default; done;接下来,将 nagios 和 www 账户添加到不安全类别中:
# pw usermod nagios -L insecure
# pw usermod www -L insecure18.7.3. 创建上下文文件
现在应该创建一个上下文文件,路径为 /etc/policy.contexts 。
# This is the default BIBA policy for this system. # System: /var/run(/.*)? biba/equal /dev/(/.*)? biba/equal /var biba/equal /var/spool(/.*)? biba/equal /var/log(/.*)? biba/equal /tmp(/.*)? biba/equal /var/tmp(/.*)? biba/equal /var/spool/mqueue biba/equal /var/spool/clientmqueue biba/equal # For Nagios: /usr/local/etc/nagios(/.*)? biba/10 /var/spool/nagios(/.*)? biba/10 # For apache /usr/local/etc/apache(/.*)? biba/10
该策略通过对信息流动设置限制来强制执行安全性。在这个特定的配置中,包括 root 在内的用户不应该被允许访问 Nagios 。 Nagios 的配置文件和进程将完全自包含或被隔离。
在对每个文件系统运行 setfsmac 之后,将读取此文件。此示例设置了根文件系统的策略:
# setfsmac -ef /etc/policy.contexts /接下来,将这些编辑添加到主要部分的 /etc/mac.conf 中:
default_labels file ?biba default_labels ifnet ?biba default_labels process ?biba default_labels socket ?biba
18.7.4. 加载器配置
要完成配置,请将以下行添加到 /boot/loader.conf 中:
mac_biba_load="YES" mac_seeotheruids_load="YES" security.mac.biba.trust_all_interfaces=1
将以下行添加到存储在 /etc/rc.conf 中的网络卡配置中。如果主要网络配置是通过 DHCP 完成的,则可能需要在每次系统启动后手动配置此项:
maclabel biba/equal
18.7.5. 测试配置
首先,确保在系统初始化和重启时不会启动 Web 服务器和 Nagios 。确保 root 无法访问 Nagios 配置目录中的任何文件。如果 root 可以列出 .filename/var/spool/nagios 的内容,则表示出现了问题。相反,应返回“权限被拒绝(permission denied)”错误。
如果一切正常,现在可以启动 Nagios、Apache 和 Sendmail:
# cd /etc/mail && make stop && \
setpmac biba/equal make start && setpmac biba/10\(10-10\) apachectl start && \
setpmac biba/10\(10-10\) /usr/local/etc/rc.d/nagios.sh forcestart请仔细检查以确保一切正常运行。如果不正常,请检查日志文件以查找错误信息。如果需要,使用 sysctl(8) 命令禁用 mac_biba(4) 安全策略模块,然后尝试按照通常的方式重新启动所有内容。
|
为了阻止这种情况发生,可以使用 login.conf(5) 强制用户进入一个范围。如果 setpmac(8) 尝试在隔离区域范围之外运行命令,将返回错误并且不执行该命令。在这种情况下,将 root 设置为 |
18.8. 解决 MAC 框架的问题
本节讨论常见的配置错误以及如何解决它们。
multilabel标志在根(/ )分区上无法保持启用状态。-
以下步骤可能解决此临时错误:
-
编辑 /etc/fstab 文件,并将根分区设置为
ro,以实现只读模式。 -
重新启动进入单用户模式。
-
在 / 上运行
tunefs -l enable。 -
重启系统。
-
运行
mount -urw命令,并在/etc/fstab文件中将ro改回rw,然后再次重启系统。 -
请仔细检查
mount命令的输出,确保根文件系统上的multilabel已正确设置。
- 在使用 MAC 建立了安全环境之后,Xorg 不再启动。
-
这可能是由 MAC
分区策略或 MAC 标签策略中的一个标签错误引起的。为了调试,请尝试以下操作:
-
检查错误消息。如果用户在
insecure类中,partition策略可能是问题的原因。尝试将用户的类设置回default类,并使用cap_mkdb重新构建数据库。如果这不能解决问题,请进行第二步。 -
请仔细检查用户、Xorg 和 /dev 条目的标签策略是否设置正确。
-
如果以上两种方法都不能解决问题,请将错误信息和环境描述发送到 FreeBSD general questions mailing list 。
- 出现了
_secure_path: 无法统计 .login_conf错误。 -
当用户尝试从
root用户切换到系统中的另一个用户时,可能会出现此错误。当用户的标签设置比他们尝试成为的用户的标签设置更高时,通常会出现此消息。例如,如果joe的默认标签是“ biba/low ”,而root的标签是biba/high,则root无法查看joe的主目录。无论root是否使用su成为joe,都会发生这种情况,因为 Biba 完整性模型不允许root查看设置在较低完整性级别的对象。 - 系统不再识别
root。 -
当发生这种情况时,
whoami返回0,而su返回who are you?。如果一个标签策略被 sysctl(8) 禁用或者策略模块被卸载,就会发生这种情况。如果策略被禁用,登录能力数据库需要重新配置。请仔细检查 /etc/login.conf,确保所有的
label选项都已经被移除,并使用cap_mkdb重新构建数据库。如果策略限制对 master.passwd 的访问,也可能发生这种情况。这通常是由于管理员在与系统使用的通用策略冲突的标签下更改了文件而引起的。在这些情况下,系统会读取用户信息,并且由于文件继承了新的标签,访问将被阻止。使用 sysctl(8) 禁用该策略,一切应该恢复正常。
Chapter 19. 安全事件审计
19.1. 简介
FreeBSD 操作系统包含安全事件审计的支持。事件审计支持可靠、细粒度和可配置的记录各种与安全相关的系统事件,包括登录、配置更改以及文件和网络访问。这些日志记录对于实时系统监控、入侵检测和事后分析非常宝贵。 FreeBSD 实现了 Sun™ 发布的基本安全模块(BSM)应用程序编程接口(API)和文件格式,并与 Solaris™ 和 Mac OS® X 的审计实现互操作。
本章重点介绍事件审计的安装和配置。它解释了审计策略,并提供了一个示例审计配置。
阅读完本章后,您将了解:
-
什么是事件审计以及它是如何工作的。
-
如何在 FreeBSD 上配置用户和进程的事件审计。
-
如何使用审计缩减和审查工具来审查审计跟踪记录。
在阅读本章之前,你应该:
-
了解 UNIX® 和 FreeBSD 基础知识。
-
熟悉 内核配置/编译的基础知识。
-
对于安全性以及它与 FreeBSD 相关的内容有一定的了解(Security)。
|
审计功能有一些已知的限制。并非所有与安全相关的系统事件都可以进行审计,而某些登录机制(例如基于 Xorg 的显示管理器和第三方守护程序)未正确配置用户登录会话的审计功能。 安全事件审计功能能够生成系统活动的非常详细的日志。在繁忙的系统上,当配置为高详细级别时,跟踪文件数据可能非常大,在某些配置下每周超过几个千兆字节。管理员应考虑与高容量审计配置相关的磁盘空间需求。例如,可以将一个文件系统专门用于 /var/audit,这样如果审计文件系统变满,其他文件系统不会受到影响。 |
19.2. 关键术语
以下术语与安全事件审计相关:
-
事件(event):可审计事件是指可以使用审计子系统记录的任何事件。安全相关事件的示例包括文件的创建、网络连接的建立或用户登录。事件可以是“可归因”的,意味着可以追溯到经过身份验证的用户,也可以是“不可归因”的。不可归因事件的示例是在登录过程中身份验证之前发生的任何事件,例如密码错误尝试。
-
class:一组命名的相关事件,用于选择表达式中使用。常用的事件类包括“文件创建”(fc)、“执行”(ex)和“登录/注销”(lo)。
-
record:描述安全事件的审计日志条目。记录包含记录事件类型、执行操作的主体(用户)的信息、日期和时间信息、任何对象或参数的信息,以及成功或失败的条件。
-
trail:一个由一系列描述安全事件的审计记录组成的日志文件。Trail 的顺序大致按照事件完成的时间顺序排列。只有经过授权的进程才允许向审计轨迹提交记录。
-
选择表达式(selection expression):一个包含前缀和审计事件类名列表的字符串,用于匹配事件。
-
预选(preselection):系统识别哪些事件对管理员感兴趣的过程。预选配置使用一系列选择表达式来识别哪些事件类别适用于哪些用户进行审计,以及适用于已认证和未认证进程的全局设置。
-
reduction:从现有审计跟踪中选择记录以进行保留、打印或分析的过程。同样,也是从审计跟踪中删除不需要的审计记录的过程。通过使用减少,管理员可以实施有关保留审计数据的策略。例如,详细的审计跟踪可能会保留一个月,但之后,为了保留仅用于归档目的的登录信息,可能会进行减少。
19.3. 审计配置
用户空间对事件审计的支持是作为基本的 FreeBSD 操作系统的一部分安装的。内核支持默认情况下在 GENERIC 内核中可用,并且可以通过在 /etc/rc.conf 中添加以下行来启用 auditd(8)。
auditd_enable="YES"
然后,启动审计守护进程:
# service auditd start喜欢编译自定义内核的用户必须在其自定义内核配置文件中包含以下行:
options AUDIT
19.3.1. 事件选择表达式
选择表达式在审计配置中的许多地方用于确定应该审计哪些事件。表达式包含要匹配的事件类别列表。选择表达式从左到右进行评估,并通过将一个表达式附加到另一个来组合两个表达式。
默认的审计事件类别 总结了默认的审计事件类别:
| 类名 | 描述 | 行动 |
|---|---|---|
所有 |
所有 |
匹配所有事件类。 |
aa |
身份验证和授权 |
|
ad |
管理操作 |
对整个系统执行的管理操作。 |
ap |
应用程序 |
应用程序定义的操作。 |
cl |
关闭文件 |
审计对 |
ex |
执行 |
执行审计程序。通过 audit_control(5) 使用 |
fa |
文件属性访问 |
审计对象属性的访问,例如 stat(1) 和 pathconf(2)。 |
fc |
创建文件 |
审计事件:文件创建的结果。 |
fd |
删除文件 |
审计文件删除事件。 |
fm |
文件属性修改 |
审计文件属性修改的事件,例如通过 chown(8),chflags(1) 和 flock(2) 进行的修改。 |
fr |
文件读取 |
审计事件中涉及数据读取或打开文件进行读取的情况。 |
fw |
文件写入 |
审计事件中涉及数据写入、文件写入或修改的情况。 |
io |
ioctl |
审计对 |
ip |
ipc |
审计各种形式的进程间通信,包括 POSIX 管道和 System V IPC 操作。 |
lo |
登录_注销 |
|
na |
不可归因的 |
审计不可归属事件。 |
no |
无效的类 |
没有匹配的审计事件。 |
nt |
网络 |
与网络操作相关的审计事件,如 connect(2) 和 accept(2)。 |
ot |
其他 |
审计其他事件。 |
pc |
过程 |
这些审计事件类可以通过修改 audit_class 和 audit_event 配置文件进行自定义。
每个审计事件类别可以与前缀组合,以指示匹配成功/失败的操作,并指示添加或删除该类别和类型的匹配项。 审计事件类的前缀 总结了可用的前缀:
| 前缀 | 行动 |
|---|---|
+ |
审计此类中的成功事件。 |
- |
审计此类中的失败事件。 |
^ |
在这个类中,既不审计成功事件,也不审计失败事件。 |
^+ |
不要对这个类中的成功事件进行审计。 |
^- |
不要对该类中的失败事件进行审计。 |
如果没有前缀,则对事件的成功和失败实例都将进行审计。
以下示例选择字符串选择成功和失败的登录/注销事件,但仅选择成功的执行事件:
lo,+ex
19.3.2. 配置文件
安全事件审计的以下配置文件位于 /etc/security 目录中:
-
audit_class: 包含了审计类的定义。
-
audit_control: 控制审计子系统的各个方面,如默认审计类别、在审计日志卷上保留的最小磁盘空间以及最大审计跟踪大小。
-
audit_event: 系统审计事件的文本名称和描述,以及每个事件所属的类别列表。
-
audit_user: 用户特定的审计要求,在登录时与全局默认值结合使用。
-
audit_warn: 是一个可定制的 Shell 脚本,由 auditd(8) 使用,用于在异常情况下生成警告消息,例如当审计记录的空间不足或审计跟踪文件已经轮转时。
|
审计配置文件应该小心编辑和维护,因为配置错误可能导致事件记录不正确。 |
在大多数情况下,管理员只需要修改 audit_control 和 audit_user 这两个文件。第一个文件控制系统范围的审计属性和策略,而第二个文件可用于按用户进行细化调整审计。
19.3.2.1. audit_control 文件
在 audit_control 文件中指定了一些审计子系统的默认值:
dir:/var/audit dist:off flags:lo,aa minfree:5 naflags:lo,aa policy:cnt,argv filesz:2M expire-after:10M
dir 条目用于设置一个或多个目录,用于存储审计日志。如果出现多个 dir 条目,则按照它们出现的顺序进行填充。通常配置审计时,会将审计日志存储在专用的文件系统中,以防止文件系统填满时审计子系统与其他子系统之间的干扰。
如果 dist 字段设置为 on 或 yes ,将会在 /var/audit/dist 目录下创建所有审计文件的硬链接。
flags 字段设置了系统范围内可归属事件的默认预选掩码。在上面的示例中,成功和失败的登录/注销事件以及身份验证和授权将为所有用户进行审计。
minfree 条目定义了存储审计跟踪的文件系统的最小空闲空间百分比。
naflags 条目指定了要对非归因事件进行审计的审计类别,例如登录/注销过程以及身份验证和授权。
policy 条目指定了一个逗号分隔的策略标志列表,用于控制审计行为的各个方面。cnt 表示系统应该在审计失败的情况下继续运行(强烈推荐使用此标志)。另一个标志 argv 会导致命令行参数在执行命令时作为 execve(2) 系统调用的一部分进行审计。
filesz 条目指定了审计跟踪文件在自动终止和轮转之前的最大大小。值为 0 表示禁用自动日志轮转。如果请求的文件大小低于最小值 512k ,它将被忽略并生成一条日志消息。
expire-after 字段指定了审计日志文件何时过期并被删除。
19.4. 使用审计跟踪功能
由于审计跟踪是以 BSM 二进制格式存储的,因此有几个内置工具可用于修改或将这些跟踪转换为文本。要将跟踪文件转换为简单的文本格式,请使用 praudit。要缩小审计跟踪文件以进行分析、存档或打印,请使用 auditreduce。此实用程序支持各种选择参数,包括事件类型、事件类别、用户、事件的日期或时间,以及操作的文件路径或对象。
例如,要以纯文本形式转储指定审计日志的全部内容:
# praudit /var/audit/AUDITFILE其中 AUDITFILE 是要转储的审计日志文件。
审计追踪由一系列由令牌组成的审计记录组成,praudit 按顺序逐行打印这些记录,每行一个令牌。每个令牌都是特定类型的,例如 header (审计记录头)或 path(名称查找的文件路径)。以下是一个 execve 事件的示例:
header,133,10,execve(2),0,Mon Sep 25 15:58:03 2006, + 384 msec exec arg,finger,doug path,/usr/bin/finger attribute,555,root,wheel,90,24918,104944 subject,robert,root,wheel,root,wheel,38439,38032,42086,128.232.9.100 return,success,0 trailer,133
此审计记录表示一个成功的 execve 调用,其中运行了命令 finger doug。exec arg 令牌包含由 shell 传递给内核的处理过的命令行。path 令牌保存了内核查找到的可执行文件的路径。attribute 令牌描述了二进制文件,并包括文件模式。subject 令牌存储了审计用户 ID 、有效用户 ID 和组 ID 、真实用户 ID 和组 ID 、进程 ID 、会话 ID 、端口 ID 和登录地址。请注意,审计用户 ID 和真实用户 ID 不同,因为用户 robert 在运行此命令之前切换到了 root 账户,但是它是使用原始认证用户进行审计的。return 令牌表示成功执行,trailer 结束了记录。
还支持 XML 输出格式,可以通过包含 -x 来选择。
由于审计日志可能非常庞大,可以使用 auditreduce 选择记录的子集。此示例选择存储在 AUDITFILE 中的用户 trhodes 生成的所有审计记录。
# auditreduce -u trhodes /var/audit/AUDITFILE | prauditaudit 组的成员有权限读取位于 /var/audit 目录下的审计日志。默认情况下,该组为空,因此只有 root 用户可以读取审计日志。可以将用户添加到 audit 组中以委派审计审查权限。由于跟踪审计日志内容可以提供对用户和进程行为的重要见解,建议谨慎进行审计审查权限的委派。
19.4.1. 使用审计管道进行实时监控
审计管道是克隆伪设备,允许应用程序监听实时审计记录流。这主要对入侵检测和系统监控应用程序的作者感兴趣。然而,审计管道设备是管理员允许实时监控的便捷方式,可以避免审计跟踪文件所有权或日志轮换中断事件流的问题。要跟踪实时审计事件流:
# praudit /dev/auditpipe默认情况下,审计管道设备节点只对 root 用户可访问。要使其对 audit 组的成员可访问,需要在 /etc/devfs.rules 文件中添加一个 devfs 规则。
add path 'auditpipe*' mode 0440 group audit
请参阅 devfs.rules(5) 以获取有关配置 devfs 文件系统的更多信息。
|
很容易产生审计事件反馈循环,即每个审计事件的查看都会导致更多的审计事件生成。例如,如果对所有网络 I/O 进行审计,并且从一个 SSH 会话中运行 |
19.4.2. 旋转和压缩审计日志文件
审计日志由内核编写,并由审计守护程序(auditd(8))管理。管理员不应尝试使用 newsyslog.conf(5) 或其他工具直接轮转审计日志。相反,应使用 audit 来关闭审计、重新配置审计系统并执行日志轮转。以下命令会导致审计守护程序创建一个新的审计日志,并向内核发出信号以切换到使用新日志。旧日志将被终止和重命名,此时管理员可以对其进行操作。
# audit -n如果 auditd(8) 当前未运行,该命令将失败并产生错误消息。
将以下行添加到 /etc/crontab 将会每隔十二小时安排此轮换:
0 */12 * * * root /usr/sbin/audit -n
更改将在保存 /etc/crontab 后生效。
根据 audit_control 文件 中所述,可以使用 filesz 在 audit_control 中基于文件大小自动旋转审计跟踪文件。
由于审计跟踪文件可能变得非常大,因此通常希望在审计守护程序关闭它们后对跟踪进行压缩或归档。 audit_warn 脚本可用于执行各种与审计相关的事件的自定义操作,包括在轮换审计跟踪时对其进行清理终止。 例如,可以将以下内容添加到 /etc/security/audit_warn 中以在关闭时压缩审计跟踪:
#
# Compress audit trail files on close.
#
if [ "$1" = closefile ]; then
gzip -9 $2
fi
其他归档活动可能包括将轨迹文件复制到集中服务器,删除旧的轨迹文件,或者减少审计轨迹以删除不需要的记录。此脚本仅在审计轨迹文件被正确终止时运行。它不会在因不正确的关闭而导致未终止的轨迹上运行。
Chapter 20. 存储
20.1. 简介
本章介绍了在 FreeBSD 中使用磁盘和存储介质的方法。这包括 SCSI 和 IDE 磁盘、CD 和 DVD 媒体、内存支持的磁盘以及 USB 存储设备。
阅读完本章后,您将了解:
-
如何向 FreeBSD 系统添加额外的硬盘。
-
如何在 FreeBSD 上扩大磁盘分区的大小。
-
如何配置 FreeBSD 以使用 USB 存储设备。
-
如何在 FreeBSD 系统上使用 CD 和 DVD 媒体。
-
如何使用 FreeBSD 下可用的备份程序。
-
如何设置内存磁盘。
-
文件系统快照是什么以及如何高效使用它们。
-
如何使用配额限制磁盘空间使用。
-
如何加密磁盘和交换空间以防止攻击者的攻击。
-
如何配置高可用存储网络。
在阅读本章之前,您应该:
-
了解如何 配置和安装新的 FreeBSD 内核。
20.2. 添加磁盘
本节描述了如何将一个新的 SATA 硬盘添加到目前只有一个驱动器的计算机中。首先,关闭计算机,并按照计算机、控制器和硬盘制造商的说明将硬盘安装到计算机中。重新启动系统并成为 root 用户。
检查 /var/run/dmesg.boot 确保新的磁盘被找到。在这个例子中,新添加的 SATA 驱动器将会显示为 ada1。
对于这个示例,将在新磁盘上创建一个单独的大分区。优先使用 GPT 分区方案,而不是较旧且功能较少的 MBR 方案。
|
如果要添加的磁盘不是空白的,则可以使用 |
创建了分区方案,然后添加了一个单独的分区。为了提高在具有更大硬件块大小的新磁盘上的性能,该分区被对齐到每个一兆字节边界。
# gpart create -s GPT ada1
# gpart add -t freebsd-ufs -a 1M ada1根据使用情况,可能需要创建几个较小的分区。有关创建小于整个磁盘的分区的选项,请参阅 gpart(8)。
可以使用 gpart show 命令查看磁盘分区信息:
% gpart show ada1
=> 34 1465146988 ada1 GPT (699G)
34 2014 - free - (1.0M)
2048 1465143296 1 freebsd-ufs (699G)
1465145344 1678 - free - (839K)在新磁盘的新分区上创建了一个文件系统:
# newfs -U /dev/ada1p1一个空目录被创建为 mountpoint,用于在原始磁盘的文件系统中挂载新的磁盘:
# mkdir /newdisk最后,将一个条目添加到 /etc/fstab 文件中,以便新的磁盘在启动时自动挂载:
/dev/ada1p1 /newdisk ufs rw 2 2
新的磁盘可以手动挂载,无需重新启动系统:
# mount /newdisk20.3. 调整和扩展磁盘大小
磁盘的容量可以增加而不影响已有的数据。这在虚拟机中经常发生,当虚拟磁盘太小而需要扩大时。有时候,磁盘镜像被写入到 USB 存储设备中,但没有使用完整的容量。在这里,我们将描述如何调整或 增加 磁盘内容以利用增加的容量。
通过检查 /var/run/dmesg.boot 来确定要调整大小的磁盘的设备名称。在这个例子中,系统中只有一个 SATA 磁盘,所以该驱动器将显示为 ada0 。
列出磁盘上的分区以查看当前配置:
# gpart show ada0
=> 34 83886013 ada0 GPT (48G) [CORRUPT]
34 128 1 freebsd-boot (64k)
162 79691648 2 freebsd-ufs (38G)
79691810 4194236 3 freebsd-swap (2G)
83886046 1 - free - (512B)|
如果磁盘使用 GPT 分区方案进行格式化,可能会显示为 损坏(corrupted),因为 GPT 备份分区表不再位于驱动器的末尾。使用 |
现在,磁盘上的额外空间可供新分区使用,或者可以扩展现有分区:
# gpart show ada0
=> 34 102399933 ada0 GPT (48G)
34 128 1 freebsd-boot (64k)
162 79691648 2 freebsd-ufs (38G)
79691810 4194236 3 freebsd-swap (2G)
83886046 18513921 - free - (8.8G)分区只能调整为连续的空闲空间。在这里,磁盘上的最后一个分区是交换分区,但需要调整大小的是第二个分区。交换分区只包含临时数据,因此可以安全地卸载、删除,然后在调整第二个分区大小后重新创建第三个分区。
禁用交换分区:
# swapoff /dev/ada0p3从磁盘 ada0 中删除由 -i 标志指定的第三个分区。
# gpart delete -i 3 ada0
ada0p3 deleted
# gpart show ada0
=> 34 102399933 ada0 GPT (48G)
34 128 1 freebsd-boot (64k)
162 79691648 2 freebsd-ufs (38G)
79691810 22708157 - free - (10G)|
在修改挂载文件系统的分区表时存在数据丢失的风险。最好在从 Live CD-ROM 或 USB 设备运行时,对未挂载的文件系统执行以下步骤。然而,如果绝对必要,可以在禁用 GEOM 安全功能后调整挂载的文件系统的大小: |
调整分区大小,留出空间以重新创建所需大小的交换分区。使用 -i 指定要调整大小的分区,使用 -s 指定新的所需大小。可选地,使用 -a 控制分区的对齐方式。这仅修改分区的大小。分区中的文件系统将在单独的步骤中扩展。
# gpart resize -i 2 -s 47G -a 4k ada0
ada0p2 resized
# gpart show ada0
=> 34 102399933 ada0 GPT (48G)
34 128 1 freebsd-boot (64k)
162 98566144 2 freebsd-ufs (47G)
98566306 3833661 - free - (1.8G)重新创建交换分区并激活它。如果没有使用 -s 指定大小,则使用所有剩余空间。
# gpart add -t freebsd-swap -a 4k ada0
ada0p3 added
# gpart show ada0
=> 34 102399933 ada0 GPT (48G)
34 128 1 freebsd-boot (64k)
162 98566144 2 freebsd-ufs (47G)
98566306 3833661 3 freebsd-swap (1.8G)
# swapon /dev/ada0p3将 UFS 文件系统扩展到重新调整大小的分区的新容量。
# growfs /dev/ada0p2
Device is mounted read-write; resizing will result in temporary write suspension for /.
It's strongly recommended to make a backup before growing the file system.
OK to grow file system on /dev/ada0p2, mounted on /, from 38GB to 47GB? [Yes/No] Yes
super-block backups (for fsck -b #) at:
80781312, 82063552, 83345792, 84628032, 85910272, 87192512, 88474752,
89756992, 91039232, 92321472, 93603712, 94885952, 96168192, 97450432如果文件系统是 ZFS ,则通过运行带有 -e 选项的 online 子命令来触发调整大小:
# zpool online -e zroot /dev/ada0p2分区和其上的文件系统现在已经调整大小,以利用新可用的磁盘空间。
20.4. USB 存储设备
许多外部存储解决方案,如硬盘、USB 闪存驱动器以及 CD 和 DVD 刻录机,使用通用串行总线(USB)。FreeBSD 支持 USB 1.x、2.0 和 3.0 设备。
|
USB 3.0 支持不兼容一些硬件,包括 Haswell(Lynx Point)芯片组。如果 FreeBSD 启动时出现 |
对 USB 存储设备的支持已经集成到 GENERIC 内核中。对于自定义内核,请确保以下行在内核配置文件中存在:
device scbus # SCSI bus (required for ATA/SCSI) device da # Direct Access (disks) device pass # Passthrough device (direct ATA/SCSI access) device uhci # provides USB 1.x support device ohci # provides USB 1.x support device ehci # provides USB 2.0 support device xhci # provides USB 3.0 support device usb # USB Bus (required) device umass # Disks/Mass storage - Requires scbus and da device cd # needed for CD and DVD burners
FreeBSD 使用 umass(4) 驱动程序,该驱动程序使用 SCSI 子系统来访问 USB 存储设备。由于系统将任何 USB 设备视为 SCSI 设备,如果 USB 设备是 CD 或 DVD 刻录机,请在自定义内核配置文件中 不要 包含 device atapicam。
本节的其余部分演示了如何验证 FreeBSD 是否识别 USB 存储设备以及如何配置设备以便使用。
20.4.1. 设备配置
为了测试 USB 配置,请插入 USB 设备。使用 dmesg 命令确认驱动器是否出现在系统消息缓冲区中。它应该看起来像这样:
umass0: <STECH Simple Drive, class 0/0, rev 2.00/1.04, addr 3> on usbus0
umass0: SCSI over Bulk-Only; quirks = 0x0100
umass0:4:0:-1: Attached to scbus4
da0 at umass-sim0 bus 0 scbus4 target 0 lun 0
da0: <STECH Simple Drive 1.04> Fixed Direct Access SCSI-4 device
da0: Serial Number WD-WXE508CAN263
da0: 40.000MB/s transfers
da0: 152627MB (312581808 512 byte sectors: 255H 63S/T 19457C)
da0: quirks=0x2<NO_6_BYTE>品牌、设备节点(da0)、速度和大小将根据设备而异。
由于 USB 设备被视为 SCSI 设备,可以使用 camcontrol 命令列出连接到系统的 USB 存储设备:
# camcontrol devlist
<STECH Simple Drive 1.04> at scbus4 target 0 lun 0 (pass3,da0)另外,可以使用 usbconfig 命令列出设备。有关该命令的更多信息,请参阅 usbconfig(8)。
# usbconfig
ugen0.3: <Simple Drive STECH> at usbus0, cfg=0 md=HOST spd=HIGH (480Mbps) pwr=ON (2mA)如果设备尚未格式化,请参考 添加磁盘 中的说明,了解如何对 USB 驱动器进行格式化和创建分区的操作。如果驱动器已经带有文件系统,可以使用 “挂载和卸载文件系统” 中的指示,由 root 用户进行挂载。
|
从安全角度来看,不应该认为通过启用 |
为了使设备能够以普通用户的身份挂载,一种解决方案是使用 pw(8) 将设备的所有用户都添加到 operator 组中。接下来,通过将以下行添加到 /etc/devfs.rules 来确保 operator 能够读写设备:
[localrules=5] add path 'da*' mode 0660 group operator
|
如果系统中还安装了内部 SCSI 硬盘,请将第二行更改如下: add path 'da[3-9]*' mode 0660 group operator 这将排除前三个 SCSI 磁盘(da0 到 da2)不属于 |
接下来,在 /etc/rc.conf 文件中启用规则集:
devfs_system_ruleset="localrules"
然后,通过将以下行添加到 /etc/sysctl.conf,指示系统允许普通用户挂载文件系统:
vfs.usermount=1
由于此设置仅在下次重新启动后生效,请使用 sysctl 立即设置此变量:
# sysctl vfs.usermount=1
vfs.usermount: 0 -> 1最后一步是创建一个目录,用于挂载文件系统。这个目录需要由将要挂载文件系统的用户拥有。一种方法是让 root 用户创建一个由该用户拥有的子目录,例如 /mnt/username 。在下面的示例中,将 username 替换为用户的登录名,将 usergroup 替换为用户的主要组名:
# mkdir /mnt/username
# chown username:usergroup /mnt/username假设插入了一个 USB 闪存驱动器,并出现了一个设备 /dev/da0s1。如果该设备使用 FAT 文件系统格式化,用户可以使用以下命令挂载它:
% mount -t msdosfs -o -m=644,-M=755 /dev/da0s1 /mnt/username在设备被拔出之前,必须首先卸载设备:
% umount /mnt/username设备移除后,系统消息缓冲区将显示类似以下的消息:
umass0: at uhub3, port 2, addr 3 (disconnected)
da0 at umass-sim0 bus 0 scbus4 target 0 lun 0
da0: <STECH Simple Drive 1.04> s/n WD-WXE508CAN263 detached
(da0:umass-sim0:0:0:0): Periph destroyed20.4.2. 自动挂载可移动介质
取消注释 /etc/auto_master 中的这行代码可以自动挂载 USB 设备:
/media -media -nosuid然后将以下行添加到 /etc/devd.conf 文件中:
notify 100 {
match "system" "GEOM";
match "subsystem" "DEV";
action "/usr/sbin/automount -c";
};# service automount restart
# service devd restartautofs(5) 可以通过将以下行添加到 /etc/rc.conf 来设置在启动时启动:
autofs_enable="YES"
立即启动服务:
# service automount start
# service automountd start
# service autounmountd start
# service devd start每个可以自动挂载的文件系统都会在 /media/ 中以目录的形式显示。该目录的名称与文件系统的标签相同。如果标签缺失,则目录的名称与设备节点相同。
文件系统在第一次访问时透明地挂载,并在一段时间的不活动后卸载。自动挂载的驱动器也可以手动卸载:
# automount -fu这种机制通常用于存储卡和 USB 存储设备。它可以与任何块设备一起使用,包括光驱或 iSCSI 逻辑单元。
20.5. 创建和使用 CD 媒体
紧凑型光盘(CD)介质具有一些与传统磁盘不同的特点。它们被设计成可以连续读取,无需在轨道之间移动磁头造成延迟。虽然 CD 介质确实有轨道,但这些轨道指的是要连续读取的数据部分,而不是磁盘的物理属性。ISO 9660 文件系统是为处理这些差异而设计的。
FreeBSD Ports Collection 提供了几个用于刻录和复制音频和数据 CD 的实用工具。本章演示了几个命令行实用程序的使用方法。如果需要带有图形界面的 CD 刻录软件,请考虑安装 sysutils/xcdroast 或 sysutils/k3b 包或 ports。
20.5.1. 支持的设备
GENERIC 内核提供了对 SCSI、USB 和 ATAPICD 读写器的支持。如果使用自定义内核,则需要在内核配置文件中根据设备类型添加相应的选项。
对于 SCSI 刻录机,请确保以下选项存在:
device scbus # SCSI bus (required for ATA/SCSI) device da # Direct Access (disks) device pass # Passthrough device (direct ATA/SCSI access) device cd # needed for CD and DVD burners
对于一个 USB 刻录机,确保以下选项存在:
device scbus # SCSI bus (required for ATA/SCSI) device da # Direct Access (disks) device pass # Passthrough device (direct ATA/SCSI access) device cd # needed for CD and DVD burners device uhci # provides USB 1.x support device ohci # provides USB 1.x support device ehci # provides USB 2.0 support device xhci # provides USB 3.0 support device usb # USB Bus (required) device umass # Disks/Mass storage - Requires scbus and da
对于一个 ATAPI 刻录机,请确保以下选项存在:
device ata # Legacy ATA/SATA controllers device scbus # SCSI bus (required for ATA/SCSI) device pass # Passthrough device (direct ATA/SCSI access) device cd # needed for CD and DVD burners
|
在 FreeBSD 10.x 之前的版本中,如果刻录机是 ATAPI 设备,则还需要在内核配置文件中添加此行: device atapicam 或者,可以通过在 /boot/loader.conf 中添加以下行来在启动时加载此驱动程序: atapicam_load="YES" 这将需要系统重新启动,因为这个驱动程序只能在启动时加载。 |
要验证 FreeBSD 是否识别设备,请运行 dmesg 命令并查找设备的条目。在 10.x 之前的系统中,输出的第一行中设备名称将是 acd0,而不是 cd0。
% dmesg | grep cd
cd0 at ahcich1 bus 0 scbus1 target 0 lun 0
cd0: <HL-DT-ST DVDRAM GU70N LT20> Removable CD-ROM SCSI-0 device
cd0: Serial Number M3OD3S34152
cd0: 150.000MB/s transfers (SATA 1.x, UDMA6, ATAPI 12bytes, PIO 8192bytes)
cd0: Attempt to query device size failed: NOT READY, Medium not present - tray closed20.5.2. 刻录光盘
在 FreeBSD 中,可以使用 cdrecord 来刻录光盘。这个命令是通过 sysutils/cdrtools 包或端口安装的。
虽然 cdrecord 有很多选项,但基本用法很简单。只需指定要刻录的 ISO 文件的名称,如果系统有多个刻录设备,则还需指定要使用的设备的名称:
# cdrecord dev=device imagefile.iso要确定刻录机的设备名称,请使用 -scanbus 命令,可能会产生如下结果:
# cdrecord -scanbus
ProDVD-ProBD-Clone 3.00 (amd64-unknown-freebsd10.0) Copyright (C) 1995-2010 Jörg Schilling
Using libscg version 'schily-0.9'
scsibus0:
0,0,0 0) 'SEAGATE ' 'ST39236LW ' '0004' Disk
0,1,0 1) 'SEAGATE ' 'ST39173W ' '5958' Disk
0,2,0 2) *
0,3,0 3) 'iomega ' 'jaz 1GB ' 'J.86' Removable Disk
0,4,0 4) 'NEC ' 'CD-ROM DRIVE:466' '1.26' Removable CD-ROM
0,5,0 5) *
0,6,0 6) *
0,7,0 7) *
scsibus1:
1,0,0 100) *
1,1,0 101) *
1,2,0 102) *
1,3,0 103) *
1,4,0 104) *
1,5,0 105) 'YAMAHA ' 'CRW4260 ' '1.0q' Removable CD-ROM
1,6,0 106) 'ARTEC ' 'AM12S ' '1.06' Scanner
1,7,0 107) *找到 CD 刻录机的条目,并使用逗号分隔的三个数字作为 dev 的值。在这种情况下,Yamaha 刻录机设备是 1,5,0 ,因此指定该设备的适当输入是 dev = 1,5,0。请参考 cdrecord 的手册页面,了解其他指定该值的方法以及有关写入音轨和控制写入速度的信息。
或者,运行以下命令以获取刻录机的设备地址:
# camcontrol devlist
<MATSHITA CDRW/DVD UJDA740 1.00> at scbus1 target 0 lun 0 (cd0,pass0)使用 scbus、target 和 lun 的数值。对于这个例子,1,0,0 是要使用的设备名称。
20.5.3. 将数据写入 ISO 文件系统
为了制作数据光盘,必须在将数据文件刻录到光盘之前对其进行准备。在 FreeBSD 中,安装了 mkisofs 的 sysutils/cdrtools 可以用来生成一个 ISO 9660 文件系统,该文件系统是 UNIX® 文件系统中目录树的镜像。最简单的用法是指定要创建的 ISO 文件的名称和要放入 ISO 9660 文件系统的文件路径:
# mkisofs -o imagefile.iso /path/to/tree该命令将指定路径中的文件名映射为符合标准 ISO 9660 文件系统限制的名称,并且将排除不符合 ISO 文件系统标准的文件。
有多种选项可用于克服标准所施加的限制。特别地,-R 启用了在 UNIX® 系统中常见的 Rock Ridge 扩展,而 -J 启用了 Microsoft® 系统中使用的 Joliet 扩展。
对于仅在 FreeBSD 系统上使用的 CD,可以使用 -U 来禁用所有文件名限制。当与 -R 一起使用时,它会生成一个文件系统镜像,即使违反 ISO 9660 标准,也与指定的 FreeBSD 树完全相同。
通用用途的最后一个选项是 -b。它用于指定用于生成 “El Torito” 可引导 CD 的引导映像的位置。此选项接受一个参数,即从要写入 CD 的树的顶部到引导映像的路径。默认情况下,mkisofs 以“软盘仿真(floppy disk emulation)”模式创建 ISO 映像,因此期望引导映像的大小为 1200、1440 或 2880 KB。某些引导加载程序(如 FreeBSD 发行版媒体使用的加载程序)不使用仿真模式。在这种情况下,应使用 -no-emul-boot 选项。因此,如果 /tmp/myboot 中包含一个可引导的 FreeBSD 系统,并且引导映像位于 /tmp/myboot/boot/cdboot 中,此命令将生成 /tmp/bootable.iso:
# mkisofs -R -no-emul-boot -b boot/cdboot -o /tmp/bootable.iso /tmp/myboot生成的 ISO 镜像可以通过以下方式挂载为内存磁盘:
# mdconfig -a -t vnode -f /tmp/bootable.iso -u 0
# mount -t cd9660 /dev/md0 /mnt然后可以验证 /mnt 和 /tmp/myboot 是相同的。
有许多其他选项可用于细调 mkisofs 的行为。有关详细信息,请参阅 mkisofs(8)。
|
可以将数据光盘复制到一个与使用 生成的图像文件可以按照 刻录光盘 中描述的方式刻录到 CD 上。 |
20.5.4. 使用数据光盘
一旦 ISO 文件被刻录到光盘上,可以通过指定文件系统类型、包含光盘的设备名称和已存在的挂载点来挂载。
# mount -t cd9660 /dev/cd0 /mnt由于 mount 假设文件系统的类型是 ufs,如果在挂载数据光盘时没有包含 -t cd9660,将会出现 Incorrect super block 错误。
虽然任何数据 CD 都可以通过这种方式挂载,但带有特定 ISO 9660 扩展的光盘可能会表现出奇怪的行为。例如,Joliet 光盘将所有文件名存储为两个字节的 Unicode 字符。如果一些非英文字符显示为问号,请使用 -C 参数指定本地字符集。有关更多信息,请参考 mount_cd9660(8)。
|
为了使用 cd9660_iconv_load="YES" 然后重新启动机器,或通过使用 |
在尝试挂载数据光盘时,有时会显示 设备未配置(Device not configured)。这通常意味着光驱没有检测到托盘中的光盘,或者该驱动器在总线上不可见。光驱可能需要几秒钟的时间来检测媒体,请耐心等待。
有时候,SCSICD 驱动器可能会被忽略,因为它没有足够的时间来回应总线复位。为了解决这个问题,可以创建一个自定义内核,增加默认的 SCSI 延迟。将以下选项添加到自定义内核配置文件中,并按照 “构建和安装自定义内核” 中的说明重新构建内核。
options SCSI_DELAY=15000
这将在启动过程中告诉 SCSI 总线暂停 15 秒,以便给 CD 驱动器尽可能多的机会来响应总线复位。
|
可以直接将文件刻录到光盘上,而无需创建 ISO 9660 文件系统。这被称为刻录原始数据光盘,有些人出于备份目的这样做。 这种类型的光盘不能像普通数据光盘一样挂载。为了获取烧录到这种光盘上的数据,必须从原始设备节点读取数据。例如,以下命令将从第二个光盘设备中提取一个压缩的 tar 文件到当前工作目录: 为了挂载数据光盘,数据必须使用 |
20.5.5. 复制音频 CDs
要复制音频 CD,需要从 CD 中提取音频数据到一系列文件中,然后将这些文件写入空白 CD。
步骤:复制音频 CD 描述了如何复制和刻录音频 CD。如果 FreeBSD 版本小于 10.0 且设备为 ATAPI,必须首先使用 支持的设备 中的说明加载 atapicam 模块。
步骤:复制音频 CD
-
sysutils/cdrtools 包或 port 安装了
cdda2wav。此命令可用于提取所有音轨,每个音轨都会被写入当前工作目录中的单独的 WAV 文件中:% cdda2wav -vall -B -Owav如果系统上只有一个 CD 设备,则不需要指定设备名称。请参考
cdda2wav手册页面,了解如何指定设备以及了解此命令的其他可用选项。 -
使用
cdrecord命令来写入 .wav 文件:% cdrecord -v dev=2,0 -dao -useinfo *.wav请确保按照 刻录光盘 中描述的方式适当设置 2,0。
20.6. 创建和使用 DVD 媒体
与 CD 相比,DVD 是下一代光学媒体存储技术。DVD 可以容纳比任何 CD 更多的数据,并且是视频出版的标准。
可为可记录的 DVD 定义五种物理可记录格式:
-
DVD-R:这是第一个可用的 DVD 可记录格式。DVD-R 标准由 DVD 论坛定义。这种格式只能写入一次。
-
DVD-RW:这是 DVD-R 标准的可重写版本。一个 DVD-RW 可以重写约 1000 次。
-
DVD-RAM:这是一种可重写的格式,可以看作是可移动硬盘。然而,这种介质与大多数 DVD-ROM 驱动器和 DVD 视频播放器不兼容,因为只有少数 DVD 刻录机支持 DVD-RAM 格式。有关 DVD-RAM 使用的更多信息,请参阅 使用 DVD-RAM 。
-
DVD+RW :这是由 DVD+RW 联盟 定义的可重写格式。DVD+RW 可以重写约 1000 次。
-
DVD+R:这种格式是 DVD+RW 格式的一次写入变体。
一张单层可记录的 DVD 可以容纳高达 4,700,000,000 字节,实际上相当于 4.38 GB 或 4485 MB,因为 1 千字节等于 1024 字节。
|
必须区分物理介质和应用程序。例如,DVD-Video 是一种特定的文件布局,可以写入任何可记录的 DVD 物理介质,如 DVD-R、DVD+R 或 DVD-RW。在选择介质之前,请确保刻录机和 DVD-Video 播放器与所考虑的介质兼容。 |
20.6.1. 配置
要进行 DVD 录制,请使用 growisofs(1) 命令。该命令是 sysutils/dvd+rw-tools 工具包的一部分,支持所有 DVD 媒体类型。
这些工具使用 SCSI 子系统来访问设备,因此必须加载或静态编译 ATAPI/CAM support 到内核中。如果刻录机使用 USB 接口,则不需要此支持。有关 USB 设备配置的更多详细信息,请参阅 USB 存储设备。
还必须为 ATAPI 设备启用 DMA 访问,方法是在 /boot/loader.conf 中添加以下行:
hw.ata.atapi_dma="1"
在尝试使用 dvd+rw-tools 之前,请参考 硬件兼容性说明。
|
对于图形用户界面,请考虑使用 sysutils/k3b,它提供了一个用户友好的界面来使用 growisofs(1) 和许多其他刻录工具。 |
20.6.2. 刻录数据 DVD
由于 growisofs(1) 是 mkisofs 的前端,它将调用 mkisofs(8) 来创建文件系统布局并在 DVD 上执行写入操作。这意味着在刻录过程之前不需要创建数据的镜像。
要将位于 /path/to/data 的数据刻录到 DVD+R 或 DVD-R 上,请使用以下命令:
# growisofs -dvd-compat -Z /dev/cd0 -J -R /path/to/data在这个例子中,-J -R 被传递给 mkisofs(8) 以创建一个带有 Joliet 和 Rock Ridge 扩展的 ISO 9660 文件系统。更多详细信息请参考 mkisofs(8)。
对于初始会话录制,-Z 用于单个和多个会话。将 /dev/cd0 替换为 DVD 设备的名称。使用 -dvd-compat 表示光盘将被关闭,并且录制将无法追加。这还应该提供更好的与 DVD-ROM 驱动器的媒体兼容性。
要烧录预制的镜像,比如 imagefile.iso,请使用以下命令:
# growisofs -dvd-compat -Z /dev/cd0=imagefile.iso应该检测并根据使用的媒体和驱动器自动设置写入速度。要强制设置写入速度,请使用 -speed=。有关示例用法,请参考 growisofs(1)。
|
为了支持大于 4.38GB 的工作文件,必须通过在 mkisofs(8) 和所有相关程序(如 growisofs(1) )中传递 要创建这种类型的 ISO 文件: 直接将文件刻录到光盘: 当 ISO 镜像已经包含大文件时,growisofs(1) 在将该镜像刻录到光盘上时不需要额外的选项。 请确保使用最新版本的 sysutils/cdrtools,其中包含 mkisofs(8),因为旧版本可能不支持大文件。如果最新版本无法工作,请安装 sysutils/cdrtools-devel 并阅读其 mkisofs(8)。 |
20.6.3. 刻录 DVD 视频
DVD-Video 是基于 ISO 9660 和微型 UDF(M-UDF)规范的特定文件布局。由于 DVD-Video 呈现了特定的数据结构层次,因此需要使用特定的程序,如 multimedia/dvdauthor 来制作 DVD。
如果已经存在 DVD-Video 文件系统的镜像,可以像其他镜像一样进行刻录。如果使用了 dvdauthor 制作了 DVD,并且结果保存在 /path/to/video 中,应使用以下命令来刻录 DVD-Video:
# growisofs -Z /dev/cd0 -dvd-video /path/to/video-dvd-video 被传递给 mkisofs(8),用于指示它创建一个 DVD-Video 文件系统布局。此选项隐含了 -dvd-compat growisofs(1) 选项。
20.6.4. 使用 DVD+RW
与 CD-RW 不同,未使用过的 DVD+RW 需要在首次使用前进行格式化。强烈建议使用 growisofs(1) 在适当时自动处理此操作。然而,也可以使用 dvd+rw-format 来格式化 DVD+RW:
# dvd+rw-format /dev/cd0只需执行此操作一次,并记住只有全新的 DVD+RW 光盘需要进行格式化。一旦格式化完成,DVD+RW 光盘可以像往常一样进行刻录。
要烧录一个全新的文件系统,而不仅仅是将一些数据追加到 DVD+RW 上,媒体不需要先进行擦除。相反,可以像这样覆盖之前的记录:
# growisofs -Z /dev/cd0 -J -R /path/to/newdataDVD+RW 格式支持在之前的记录上追加数据。这个操作包括将新的会话合并到现有的会话中,因为它不被视为多会话写入。growisofs(1) 将会 增长 媒体上存在的 ISO 9660 文件系统。
例如,要将数据追加到 DVD+RW 上,请使用以下方法:
# growisofs -M /dev/cd0 -J -R /path/to/nextdata在进行下一次写入时,应使用与烧录初始会话时相同的 mkisofs[8] 选项。
|
使用 |
要清空媒体,请使用以下方法:
# growisofs -Z /dev/cd0=/dev/zero20.6.5. 使用 DVD-RW
DVD-RW 支持两种光盘格式:增量顺序和受限覆写。默认情况下,DVD-RW 光盘采用顺序格式。
一个全新的 DVD-RW 可以直接写入而无需进行格式化。然而,一个已经使用过的顺序格式的 DVD-RW 在写入新的初始会话之前需要进行擦除。
要以顺序模式擦除 DVD-RW:
# dvd+rw-format -blank=full /dev/cd0|
使用 由于 growisofs(1) 会自动尝试检测快速擦除的介质并启用 DAO 写入,因此不需要使用 对于任何 DVD-RW,应该使用受限覆盖模式,而不是默认的增量顺序模式,因为受限覆盖模式更加灵活。 |
要在顺序 DVD-RW 上写入数据,使用与其他 DVD 格式相同的指令:
# growisofs -Z /dev/cd0 -J -R /path/to/data要将一些数据追加到先前的录制中,请使用 -M 参数和 growisofs(1) 命令。然而,如果在增量顺序模式下在 DVD-RW 上追加数据,将会在光盘上创建一个新的会话,结果将是一个多会话光盘。
在受限覆写格式的 DVD-RW 上,不需要在开始新的初始会话之前将其擦除。相反,可以使用 -Z 来覆盖光盘。还可以使用 -M 来扩展已写入光盘上的现有 ISO 9660 文件系统。结果将是一个单会话的 DVD。
要将 DVD-RW 格式化为受限覆写格式,必须使用以下命令:
# dvd+rw-format /dev/cd0要切换回顺序格式,请使用:
# dvd+rw-format -blank=full /dev/cd020.6.6. 多会话
很少有 DVD-ROM 驱动器支持多会话 DVD,并且大多数情况下只能读取第一个会话。 DVD+R、DVD-R 和 DVD-RW 以顺序格式可以接受多个会话。对于 DVD+RW 和 DVD-RW 受限覆写格式,不存在多个会话的概念。
在使用 DVD+R、DVD-R 或 DVD-RW 顺序格式的初始非关闭会话后,使用以下命令将在光盘上添加一个新的会话:
# growisofs -M /dev/cd0 -J -R /path/to/nextdata在使用此命令时,如果使用 DVD+RW 或 DVD-RW 处于受限覆写模式,将会在将新会话合并到现有会话时追加数据。结果将是一个单会话光盘。使用此方法在这些类型的介质上进行初始写入后添加数据。
|
由于在每个会话之间使用了一些空间来标记会话的结束和开始,因此应该添加大量数据的会话以优化媒体空间。 DVD+R 的会话数量限制为 154 个, DVD-R 约为 2000 个,DVD + R 双层为 127 个。 |
20.6.7. 更多信息请参考
要获取有关 DVD 的更多信息,请在指定的驱动器中使用 dvd+rw-mediainfo /dev/cd0 命令,同时光盘在其中。
有关 dvd+rw-tools 的更多信息可以在 growisofs(1) 中找到,在 dvd+rw-tools 网站 上找到,并且在 cdwrite 邮件列表 的存档中也可以找到。
|
创建与使用 dvd+rw-tools 相关的问题报告时,始终包括 |
20.6.8. 使用 DVD-RAM
DVD-RAM 写入器可以使用 SCSI 或 ATAPI 接口。对于 ATAPI 设备,必须通过在 /boot/loader.conf 中添加以下行来启用 DMA 访问:
hw.ata.atapi_dma="1"
DVD-RAM 可以被视为可移动硬盘。与任何其他硬盘一样, DVD-RAM 在使用之前必须进行格式化。在这个例子中,整个磁盘空间将使用标准的 UFS2 文件系统进行格式化:
# dd if=/dev/zero of=/dev/acd0 bs=2k count=1
# bsdlabel -Bw acd0
# newfs /dev/acd0DVD 设备 acd0 必须根据配置进行更改。
一旦 DVD-RAM 被格式化,它可以被挂载为普通硬盘:
# mount /dev/acd0 /mnt一旦挂载,DVD-RAM 将可读可写。
20.7. 创建和使用软盘
本节介绍了如何在 FreeBSD 中格式化 3.5 英寸软盘。
步骤:格式化软盘的步骤
在使用软盘之前,需要进行低级格式化。通常由供应商完成,但格式化是检查介质完整性的好方法。在 FreeBSD 上进行软盘的低级格式化,可以使用 fdformat(1) 命令。在使用此实用程序时,请注意任何错误消息,因为它们可以帮助确定软盘是好的还是坏的。
-
要格式化软盘,请将一个新的 3.5 英寸软盘插入第一个软盘驱动器,并输入以下命令:
# /usr/sbin/fdformat -f 1440 /dev/fd0 -
在低级格式化磁盘之后,根据系统需要创建磁盘标签,以确定磁盘的大小和几何结构。支持的几何结构值在 /etc/disktab 中列出。
要编写磁盘标签,请使用 bsdlabel(8)。
# /sbin/bsdlabel -B -w /dev/fd0 fd1440 -
软盘现在可以进行高级格式化,并选择文件系统。软盘的文件系统可以是 UFS 或 FAT,其中 FAT 通常是软盘的更好选择。
要使用 FAT 格式化软盘,请执行以下操作:
# /sbin/newfs_msdos /dev/fd0
磁盘现在已经准备好供使用。要使用软盘,请使用 mount_msdosfs(8) 命令进行挂载。也可以从 Ports Collection 安装和使用 emulators/mtools。
20.8. 使用 NTFS 磁盘
本节介绍了如何在 FreeBSD 中挂载 NTFS 磁盘。
NTFS(新技术文件系统)是由微软开发的专有日志文件系统。多年来,它一直是微软 Windows 操作系统的默认文件系统。FreeBSD 可以使用 FUSE 文件系统挂载 NTFS 卷。这些文件系统是作为用户空间程序实现的,它们通过一个明确定义的接口与 fusefs(5) 内核模块进行交互。
过程:挂载 NTFS 磁盘的步骤
-
在使用 FUSE 文件系统之前,我们需要加载 fusefs(5) 内核模块:
# kldload fusefs使用 sysrc(8) 命令在启动时加载模块:
# sysrc kld_list+=fusefs -
按照示例中的方式(参见 使用 pkg 进行二进制包管理)或者从 ports(参见 使用 Ports Collection)安装实际的 NTFS 文件系统。
# pkg install fusefs-ntfs -
最后,我们需要创建一个目录,用于挂载文件系统:
# mkdir /mnt/usb -
假设插入了一个 USB 磁盘。可以使用 gpart(8) 命令查看磁盘分区信息。
# gpart show da0 => 63 1953525105 da0 MBR (932G) 63 1953525105 1 ntfs (932G) -
我们可以使用以下命令挂载磁盘:
# ntfs-3g /dev/da0s1 /mnt/usb/磁盘现已准备就绪,可以使用。
-
此外,还可以将条目添加到 /etc/fstab 文件中:
/dev/da0s1 /mnt/usb ntfs mountprog=/usr/local/bin/ntfs-3g,noauto,rw 0 0
现在可以使用以下命令挂载磁盘:
# mount /mnt/usb -
可以使用以下命令卸载磁盘:
# umount /mnt/usb/
20.9. 备份基础知识
实施备份计划是至关重要的,以便能够从磁盘故障、意外文件删除、随机文件损坏或完全机器破坏(包括现场备份的破坏)中恢复。
备份类型和计划将根据数据的重要性、文件恢复所需的粒度以及可接受的停机时间而有所不同。一些可能的备份技术包括:
-
整个系统的归档备份存储在永久的、离线的介质上。这种方式可以提供对上述所有问题的保护,但是恢复速度慢且不方便,特别是对于非特权用户来说。
-
文件系统快照,用于恢复已删除的文件或文件的先前版本。
-
使用计划 net/rsync,将整个文件系统或磁盘的副本与网络上的另一个系统进行同步。
-
硬件或软件 RAID,可以在磁盘故障时最小化或避免停机时间。
通常,会使用多种备份技术的组合。例如,可以创建一个定期计划,自动进行每周一次的完整系统备份,并将其存储在离线位置,并通过每小时的 ZFS 快照来补充此备份。此外,在进行文件编辑或删除之前,还可以对单个目录或文件进行手动备份。
本节介绍了一些可用于在 FreeBSD 系统上创建和管理备份的实用工具。
20.9.1. 文件系统备份
传统的 UNIX® 文件系统备份程序是 dump(8),用于创建备份,和 restore(8),用于恢复备份。这些工具在文件系统创建的文件、链接和目录的抽象层之下的磁盘块级别上工作。与其他备份软件不同,dump 备份整个文件系统,无法备份部分文件系统或跨多个文件系统的目录树的一部分。dump 不是写入文件和目录,而是写入组成文件和目录的原始数据块。
|
如果在根目录上使用 |
当用于恢复数据时,默认情况下,restore 将临时文件存储在 /tmp/ 中。如果使用具有较小 /tmp 的恢复磁盘,请将 TMPDIR 设置为具有更多可用空间的目录,以确保恢复成功。
在使用 dump 命令时,请注意一些来自 AT&T UNIX® 6 版本(约 1975 年)早期的怪异行为。默认参数假设备份是备份到 9 轨磁带,而不是备份到其他类型的介质或者今天可用的高密度磁带。这些默认值必须在命令行上进行覆盖。
可以通过网络将文件系统备份到另一个系统或连接到另一台计算机的磁带驱动器上。虽然可以使用 rdump(8) 和 rrestore(8) 工具来实现此目的,但它们被认为不安全。
相反,可以使用 dump 和 restore 以更安全的方式通过 SSH 连接进行操作。此示例创建了一个对 /usr 目录进行完整压缩备份的文件,并通过 SSH 连接将备份文件发送到指定的主机。
例 26. 通过 ssh 使用
dump 命令# /sbin/dump -0uan -f - /usr | gzip -2 | ssh -c blowfish \
[email protected] dd of=/mybigfiles/dump-usr-l0.gz这个示例设置 RSH,以便通过 SSH 连接将备份写入远程系统上的磁带驱动器:
例 27. 使用
RSH 设置通过 ssh 使用 dump 命令# env RSH=/usr/bin/ssh /sbin/dump -0uan -f [email protected]:/dev/sa0 /usr20.9.2. 目录备份
可以根据需要使用几个内置实用程序来备份和恢复指定的文件和目录。
备份目录中所有文件的一个好选择是 tar(1)。这个实用程序可以追溯到 AT&T UNIX® 的第 6 版,并且默认情况下假定对本地磁带设备进行递归备份。可以使用开关来指定备份文件的名称。
这个例子创建了一个压缩的备份文件,将当前目录的内容保存到 /tmp/mybackup.tgz 文件中。在创建备份文件时,请确保备份文件不要保存在被备份的目录中。
例 28. 使用
tar 备份当前目录# tar czvf /tmp/mybackup.tgz .要恢复整个备份,请进入要恢复的目录并指定备份的名称。请注意,这将覆盖恢复目录中的任何更新版本的文件。如果不确定,请恢复到一个临时目录或指定要恢复的备份中的文件名称。
例 29. 使用
tar 命令恢复当前目录# tar xzvf /tmp/mybackup.tgz有数十个可用的开关,这些开关在 tar(1) 中有描述。该实用程序还支持使用排除模式来指定在备份指定目录或从备份中恢复文件时不应包括哪些文件。
要使用指定的文件和目录列表创建备份,cpio(1) 是一个不错的选择。与 tar 不同,cpio 不知道如何遍历目录树,必须提供备份文件的列表。
例如,可以使用 ls 或 find 创建文件列表。此示例创建了当前目录的递归列表,然后将其通过管道传输给 cpio,以创建一个名为 /tmp/mybackup.cpio 的输出备份文件。
例 30. 使用
ls 和 cpio 来对当前目录进行递归备份# ls -R | cpio -ovF /tmp/mybackup.cpio一种备份工具,试图结合 tar 和 cpio 提供的功能是 pax(1)。多年来,各个版本的 tar 和 cpio 变得稍微不兼容。 POSIX® 创建了 pax,它尝试读取和写入许多不同的 cpio 和 tar 格式,以及自己的新格式。
前面示例的 pax 等效方式如下:
例 31. 使用
pax 备份当前目录# pax -wf /tmp/mybackup.pax .20.9.3. 使用数据磁带进行备份
尽管磁带技术不断发展,但现代备份系统往往将离线备份与本地可移动介质相结合。FreeBSD 支持使用 SCSI 的任何磁带驱动器,如 LTO 或 DAT。对于 SATA 和 USB 磁带驱动器的支持有限。
对于 SCSI 磁带设备,FreeBSD 使用 sa(4) 驱动程序和 /dev/sa0、/dev/nsa0 和 /dev/esa0 设备。物理设备名称是 /dev/sa0。当使用 /dev/nsa0 时,备份应用程序在写入文件后不会倒回磁带,这允许将多个文件写入磁带。使用 /dev/esa0 在设备关闭后弹出磁带。
在 FreeBSD 中,mt 用于控制磁带驱动器的操作,例如在磁带上寻找文件或向磁带写入磁带控制标记。例如,在写入新文件之前,可以通过跳过前三个文件来保留磁带上的文件。
# mt -f /dev/nsa0 fsf 3该实用程序支持许多操作。有关详细信息,请参阅 mt(1)。
使用 tar 将单个文件写入磁带,需要指定磁带设备的名称和要备份的文件:
# tar cvf /dev/sa0 file将文件从磁带上的 tar 归档恢复到当前目录:
# tar xvf /dev/sa0要备份 UFS 文件系统,请使用 dump 命令。以下示例备份了 /usr 目录,备份完成后不会倒回磁带:
# dump -0aL -b64 -f /dev/nsa0 /usr要从磁带上的 dump 文件交互式地恢复文件到当前目录:
# restore -i -f /dev/nsa020.9.4. 第三方备份工具
FreeBSD Ports Collection 提供了许多第三方工具,可以用于安排备份的创建、简化磁带备份,并使备份更加方便。其中许多应用程序是基于客户端/服务器的,可以用于自动化单个系统或网络中所有计算机的备份。
常用的工具包括 Amanda、Bacula、rsync 和 duplicity。
20.9.5. 紧急恢复
除了定期备份外,建议在紧急应急计划中执行以下步骤。
创建以下命令的输出的打印副本:
-
gpart show -
more /etc/fstab -
dmesg
将这份打印件和安装介质的副本存放在安全的地方。如果需要进行紧急恢复操作,启动安装介质并选择 Live CD 以访问救援 Shell。这个救援模式可以用来查看系统的当前状态,如果需要的话,还可以重新格式化磁盘并从备份中恢复数据。
接下来,测试救援 shell 和备份。记录下操作步骤,并将这些记录与介质、打印件和备份一起存储。这些记录可以防止在紧急恢复过程中因压力而意外破坏备份。
为了增加安全性,将最新的备份存储在与计算机和磁盘驱动器相隔一定距离的远程位置。
20.10. 内存磁盘
除了物理磁盘外,FreeBSD 还支持创建和使用内存磁盘。内存磁盘的一个可能用途是在不先将其刻录到 CD 或 DVD 上,然后挂载 CD/DVD 媒体的情况下访问 ISO 文件系统的内容。
在 FreeBSD 中,md(4) 驱动程序用于提供对内存磁盘的支持。GENERIC 内核包含了这个驱动程序。当使用自定义内核配置文件时,请确保包含以下行:
device md
20.10.1. 附加和分离现有镜像
要挂载现有的文件系统镜像,使用 mdconfig 命令指定 ISO 文件的名称和一个空闲的设备号。然后,使用该设备号将其挂载到现有的挂载点上。一旦挂载成功,ISO 中的文件将会出现在挂载点上。以下示例将 diskimage.iso 附加到内存设备 /dev/md0,然后将该内存设备挂载到 /mnt:
# mdconfig -f diskimage.iso -u 0
# mount -t cd9660 /dev/md0 /mnt请注意,使用 -t cd9660 来挂载 ISO 格式的文件。如果没有使用 -u 指定设备号,mdconfig 将自动分配一个未使用的内存设备,并输出分配的单元号的名称,例如 md4。有关此命令及其选项的更多详细信息,请参阅 mdconfig(8)。
当内存磁盘不再使用时,应该将其资源释放回系统。首先,卸载文件系统,然后使用 mdconfig 将磁盘从系统中分离并释放其资源。继续本示例:
# umount /mnt
# mdconfig -d -u 0要确定系统是否仍连接有任何内存磁盘,请输入 mdconfig -l。
20.10.2. 创建一个基于文件或内存的内存磁盘
FreeBSD 还支持内存磁盘,其中存储空间可以从硬盘或内存区域分配。第一种方法通常称为基于文件的文件系统,第二种方法称为基于内存的文件系统。可以使用 mdconfig 创建这两种类型的磁盘。
要创建一个新的基于内存的文件系统,需要指定 swap 类型和要创建的内存磁盘的大小。然后,像通常一样,对内存磁盘进行文件系统格式化和挂载。以下示例在单位 1 上创建了一个大小为 5M 的内存磁盘。然后,在挂载之前,该内存磁盘将被格式化为 UFS 文件系统:
# mdconfig -a -t swap -s 5m -u 1
# newfs -U md1
/dev/md1: 5.0MB (10240 sectors) block size 16384, fragment size 2048
using 4 cylinder groups of 1.27MB, 81 blks, 192 inodes.
with soft updates
super-block backups (for fsck -b #) at:
160, 2752, 5344, 7936
# mount /dev/md1 /mnt
# df /mnt
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/md1 4718 4 4338 0% /mnt要创建一个新的基于文件的内存磁盘,首先需要分配一个磁盘区域来使用。以下示例创建一个名为 newimage 的空白 5MB 文件:
# dd if=/dev/zero of=newimage bs=1k count=5k
5120+0 records in
5120+0 records out接下来,将该文件附加到一个内存磁盘上,为内存磁盘标记名称并使用 UFS 文件系统进行格式化,挂载内存磁盘,并验证文件支持的磁盘的大小。
# mdconfig -f newimage -u 0
# bsdlabel -w md0 auto
# newfs -U md0a
/dev/md0a: 5.0MB (10224 sectors) block size 16384, fragment size 2048
using 4 cylinder groups of 1.25MB, 80 blks, 192 inodes.
super-block backups (for fsck -b #) at:
160, 2720, 5280, 7840
# mount /dev/md0a /mnt
# df /mnt
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/md0a 4710 4 4330 0% /mnt使用 mdconfig 命令创建一个基于文件或内存的文件系统需要多个命令。FreeBSD 还提供了 mdmfs 命令,它可以自动配置一个内存磁盘,使用 UFS 文件系统进行格式化,并挂载它。例如,在使用 dd 命令创建了名为 newimage 的文件后,下面这个命令相当于运行上面显示的 bsdlabel、newfs 和 mount 命令:
# mdmfs -F newimage -s 5m md0 /mnt要使用 mdmfs 创建一个新的基于内存的内存磁盘,只需使用以下命令:
# mdmfs -s 5m md1 /mnt如果未指定设备号,mdmfs 将自动选择一个未使用的内存设备。有关 mdmfs 的更多详细信息,请参阅 mdmfs(8)。
20.11. 文件系统快照
FreeBSD 提供了一个与 Soft Updates 配合使用的功能:文件系统快照。
UFS 快照允许用户创建指定文件系统的镜像,并将其视为文件。快照文件必须在执行操作的文件系统中创建,并且用户每个文件系统最多可以创建 20 个快照。 活动快照在超级块中记录,因此它们在卸载和重新挂载操作以及系统重新启动时是持久的。当不再需要快照时,可以使用 rm(1) 命令将其删除。 尽管可以以任何顺序删除快照,但可能无法获取所有已释放块的使用空间,因为另一个快照可能会占用一些已释放的块。
在创建快照文件后,mksnap_ffs(8) 会设置不可更改的 snapshot 文件标志。unlink(1) 对于快照文件有一个例外,因为它允许将其删除。
使用 mount(8) 创建快照。要将 /var 的快照放置在文件 /var/snapshot/snap 中,请使用以下命令:
# mount -u -o snapshot /var/snapshot/snap /var或者,使用 mksnap_ffs(8) 命令来创建快照:
# mksnap_ffs /var /var/snapshot/snap可以使用 find(1) 命令在文件系统上找到快照文件,例如 /var。
# find /var -flags snapshot一旦创建了快照,它可以有多种用途:
-
一些管理员会使用快照文件进行备份,因为快照可以传输到光盘或磁带上。
-
文件系统完整性检查器 fsck(8) 可以在快照上运行。假设文件系统在挂载时是干净的,这应该始终提供一个干净且不变的结果。
-
在快照上运行 dump(8) 将生成一个与文件系统和快照的时间戳一致的转储文件。dump(8) 还可以使用
-L选项一次性拍摄快照、创建转储镜像并删除快照。 -
快照可以作为文件系统的冻结镜像进行挂载。要使用 mount(8) 挂载 /var/snapshot/snap 快照,请运行:
# mdconfig -a -t vnode -o readonly -f /var/snapshot/snap -u 4 # mount -r /dev/md4 /mnt
冻结的文件 /var 现在可以通过 /mnt 访问。一开始,所有内容都将保持与创建快照时相同的状态。唯一的例外是,任何早期的快照将显示为长度为零的文件。要卸载快照,请使用:
# umount /mnt
# mdconfig -d -u 4有关 softupdates 和文件系统快照的更多信息,包括技术论文,请访问 Marshall Kirk McKusick’s 的网站:http://www.mckusick.com/[http://www.mckusick.com/]。
20.12. 磁盘配额
磁盘配额可以用于限制用户或用户组在每个文件系统上分配的磁盘空间或文件数量。这可以防止某个用户或用户组占用所有可用的磁盘空间。
本节介绍了如何配置 UFS 文件系统的磁盘配额。要在 ZFS 文件系统上配置配额,请参考 “数据集、用户和组配额”。
20.12.1. 启用磁盘配额
要确定 FreeBSD 内核是否支持磁盘配额,请执行以下操作:
% sysctl kern.features.ufs_quota
kern.features.ufs_quota: 1在这个例子中,1 表示支持配额。如果值是 0,请将以下行添加到自定义内核配置文件中,并按照 配置 FreeBSD 内核 中的说明重新构建内核。
options QUOTA
接下来,在 /etc/rc.conf 中启用磁盘配额:
quota_enable="YES"
通常在启动时,使用 quotacheck(8) 检查每个文件系统的配额完整性。该程序确保配额数据库中的数据正确反映文件系统上的数据。这是一个耗时的过程,会显著影响系统启动所需的时间。要跳过此步骤,请将此变量添加到 /etc/rc.conf 中:
check_quotas="NO"
最后,编辑 /etc/fstab 文件以按文件系统启用磁盘配额。要在文件系统上启用每个用户的配额,请在 /etc/fstab 文件中的文件系统条目的选项字段中添加 userquota。例如:
/dev/da1s2g /home ufs rw,userquota 1 2
要启用组配额,请使用 groupquota。要同时启用用户和组配额,请使用逗号分隔选项:
/dev/da1s2g /home ufs rw,userquota,groupquota 1 2
默认情况下,配额文件存储在文件系统的根目录中,文件名为 quota.user 和 quota.group。有关更多信息,请参阅 fstab(5)。不建议指定配额文件的替代位置。
配置完成后,重新启动系统,/etc/rc 将自动运行适当的命令,为 /etc/fstab 中启用的所有配额创建初始配额文件。
在正常的操作过程中,通常不需要手动运行 quotacheck(8)、quotaon(8) 或 quotaoff(8)。然而,应该阅读这些手册页以熟悉它们的操作。
20.12.2. 设置配额限制
要验证配额是否已启用,请运行以下命令:
# quota -v对于每个启用了配额的文件系统,应该有一个关于磁盘使用情况和当前配额限制的一行摘要。
系统现在可以使用 edquota 来分配配额限制。
有几种选项可用于限制用户或组分配的磁盘空间量以及他们可以创建的文件数量。分配可以基于磁盘空间(块配额)、文件数量(inode 配额)或两者的组合进行限制。每个限制进一步分为两个类别:硬限制和软限制。
硬限制不能超过。一旦用户达到硬限制,该用户在该文件系统上将无法再进行进一步的分配。例如,如果用户在文件系统上的硬限制是 500 kbytes ,并且当前正在使用 490 kbytes,那么用户只能再分配额外的 10 kbytes。尝试分配额外的 11 kbytes 将失败。
软限制可以在有限的时间内超过,这被称为宽限期,默认为一周。如果用户超过限制的时间超过宽限期,软限制将变为硬限制,不再允许进一步的分配。当用户再次低于软限制时,宽限期将被重置。
在下面的示例中,正在编辑 test 账户的配额。当调用 edquota 时,会打开由 EDITOR 指定的编辑器,以便编辑配额限制。默认编辑器设置为 vi。
# edquota -u test
Quotas for user test:
/usr: kbytes in use: 65, limits (soft = 50, hard = 75)
inodes in use: 7, limits (soft = 50, hard = 60)
/usr/var: kbytes in use: 0, limits (soft = 50, hard = 75)
inodes in use: 0, limits (soft = 50, hard = 60)通常,每个启用了配额的文件系统通常有两行。一行表示块限制,另一行表示 inode 限制。更改值以修改配额限制。例如,要将 /usr 的块限制提高到软限制 500 和硬限制 600,请按照以下方式更改该行中的值:
/usr: kbytes in use: 65, limits (soft = 500, hard = 600)
新的配额限制在退出编辑器后生效。
有时候,对一系列用户设置配额限制是可取的。首先,将所需的配额限制分配给一个用户。然后,使用 -p 选项将该配额复制到指定范围的用户 ID(UID)。以下命令将复制 UID 为 10,000 到 19,999 的用户的配额限制:
# edquota -p test 10000-19999有关更多信息,请参考 edquota(8)。
20.12.3. 检查配额限制和磁盘使用情况
要检查单个用户或组的配额和磁盘使用情况,请使用 quota(1)。用户只能查看自己的配额和所属组的配额。只有超级用户才能查看所有用户和组的配额。要获取启用了配额的文件系统的所有配额和磁盘使用情况的摘要,请使用 repquota(8)。
通常情况下,用户没有使用任何磁盘空间的文件系统在 quota 命令的输出中不会显示,即使用户对该文件系统有配额限制。使用 -v 选项可以显示这些文件系统。以下是一个用户在两个文件系统上设置了配额限制时,使用 quota -v 命令的示例输出。
Disk quotas for user test (uid 1002):
Filesystem usage quota limit grace files quota limit grace
/usr 65* 50 75 5days 7 50 60
/usr/var 0 50 75 0 50 60
在这个例子中,用户当前超过了在 /usr 目录下的 50 kbytes 的软限制,超出了 15 kbytes,并且还剩下 5 天的宽限期。星号 * 表示用户当前超过了配额限制。
20.12.4. NFS 上的配额限制
配额由 NFS 服务器上的配额子系统强制执行。rpc.rquotad(8) 守护进程将配额信息提供给 NFS 客户端上的 quota 命令,使得这些机器上的用户可以查看他们的配额统计信息。
在 NFS 服务器上,通过从 /etc/inetd.conf 文件中的这一行中删除 # 来启用 rpc.rquotad。
rquotad/1 dgram rpc/udp wait root /usr/libexec/rpc.rquotad rpc.rquotad
然后,重新启动 inetd:
# service inetd restart20.13. 加密磁盘分区
FreeBSD 提供了出色的在线保护措施,防止未经授权的数据访问。文件权限和强制访问控制(MAC)可以在操作系统处于活动状态且计算机已经启动时,防止未经授权的用户访问数据。然而,如果攻击者可以物理访问计算机并将计算机的硬盘移动到另一个系统以复制和分析数据,操作系统强制执行的权限就变得无关紧要了。
无论攻击者如何获得硬盘或关闭电脑,FreeBSD 中内置的基于 GEOM 的加密子系统能够保护计算机文件系统上的数据,即使是对于拥有大量资源和高度动机的攻击者也是如此。与加密单个文件的加密方法不同,内置的 gbde 和 geli 实用程序可以用于透明地加密整个文件系统。明文永远不会接触到硬盘的盘片。
本章介绍了如何在 FreeBSD 上创建加密文件系统。首先使用 gbde 演示了该过程,然后使用 geli 演示了相同的示例。
20.13.1. 使用 gbde 进行磁盘加密
gbde(4) 设施的目标是为攻击者提供一个巨大的挑战,以防止其获取冷存储设备的内容。然而,如果计算机在运行时被入侵并且存储设备被主动连接,或者攻击者拥有有效的密码短语,那么它对存储设备的内容提供不了任何保护。因此,在系统运行时提供物理安全性并保护加密机制使用的密码短语非常重要。
该设施提供了几个屏障来保护存储在每个磁盘扇区中的数据。它使用 128 位 AES 在 CBC 模式下对磁盘扇区的内容进行加密。磁盘上的每个扇区都使用不同的 AES 密钥进行加密。有关加密设计的更多信息,包括如何从用户提供的密码短语派生扇区密钥,请参阅 gbde(4)。
FreeBSD 提供了一个用于 gbde 的内核模块,可以使用以下命令加载:
# kldload geom_bde如果使用自定义内核配置文件,请确保其中包含以下行:
options GEOM_BDE
下面的示例演示了向系统添加新的硬盘,该硬盘将容纳一个加密分区,并将其挂载为 /private。
过程:使用 gbde 加密分区
-
添加新的硬盘
按照 添加磁盘 中所述的方法将新驱动器安装到系统中。对于本示例,已添加了一个新的硬盘分区,表示为 /dev/ad4s1c,而 /dev/ad0s1* 表示现有的标准 FreeBSD 分区。
# ls /dev/ad* /dev/ad0 /dev/ad0s1b /dev/ad0s1e /dev/ad4s1 /dev/ad0s1 /dev/ad0s1c /dev/ad0s1f /dev/ad4s1c /dev/ad0s1a /dev/ad0s1d /dev/ad4 -
创建一个目录来存放
gbde锁文件。# mkdir /etc/gbdegbde 锁定文件包含了 gbde 访问加密分区所需的信息。如果没有访问锁定文件的权限,gbde 将无法解密加密分区中的数据,除非进行大量的手动干预,而该软件不支持此操作。每个加密分区都使用一个单独的锁定文件。
-
初始化
gbde分区在使用之前,必须初始化 gbde 分区。这个初始化只需要执行一次。该命令将打开默认编辑器,以便在模板中设置各种配置选项。对于与 UFS 文件系统一起使用,请将 sector_size 设置为 2048:
# gbde init /dev/ad4s1c -i -L /etc/gbde/ad4s1c.lock # $FreeBSD: src/sbin/gbde/template.txt,v 1.1.36.1 2009/08/03 08:13:06 kensmith Exp $ # # Sector size is the smallest unit of data which can be read or written. # Making it too small decreases performance and decreases available space. # Making it too large may prevent filesystems from working. 512 is the # minimum and always safe. For UFS, use the fragment size # sector_size = 2048 [...]编辑保存后,用户将被要求两次输入用于保护数据的密码短语。两次输入的密码短语必须相同。Gbde 保护数据的能力完全取决于密码短语的质量。有关如何选择既安全又容易记住的密码短语的提示,请参阅 http://world.std.com/~reinhold/diceware.htm。
这个初始化操作创建了一个用于 gbde 分区的锁文件。在这个例子中,它被存储为 /etc/gbde/ad4s1c.lock 。锁文件必须以 ".lock" 结尾,以便被 /etc/rc.d/gbde 启动脚本正确地检测到。
必须将锁定文件与任何加密分区的内容一起备份。如果没有锁定文件,合法的所有者将无法访问加密分区上的数据。
-
将加密分区附加到内核上
# gbde attach /dev/ad4s1c -l /etc/gbde/ad4s1c.lock这个命令会提示输入在加密分区初始化过程中选择的密码。新的加密设备将出现在 /dev 中,命名为 /dev/device_name.bde 。
# ls /dev/ad* /dev/ad0 /dev/ad0s1b /dev/ad0s1e /dev/ad4s1 /dev/ad0s1 /dev/ad0s1c /dev/ad0s1f /dev/ad4s1c /dev/ad0s1a /dev/ad0s1d /dev/ad4 /dev/ad4s1c.bde -
在加密设备上创建文件系统
一旦加密设备已经连接到内核,就可以在设备上创建文件系统。这个示例创建了一个启用了软更新的 UFS 文件系统。请确保指定具有 *.bde 扩展名的分区:
# newfs -U /dev/ad4s1c.bde -
挂载加密分区
创建一个挂载点并挂载加密文件系统:
# mkdir /private # mount /dev/ad4s1c.bde /private -
验证加密文件系统是否可用
加密文件系统现在应该可见并可供使用:
% df -H Filesystem Size Used Avail Capacity Mounted on /dev/ad0s1a 1037M 72M 883M 8% / /devfs 1.0K 1.0K 0B 100% /dev /dev/ad0s1f 8.1G 55K 7.5G 0% /home /dev/ad0s1e 1037M 1.1M 953M 0% /tmp /dev/ad0s1d 6.1G 1.9G 3.7G 35% /usr /dev/ad4s1c.bde 150G 4.1K 138G 0% /private
每次启动后,必须手动重新连接加密文件系统到内核,检查错误并挂载,然后才能使用这些文件系统。要配置这些步骤,请将以下行添加到 /etc/rc.conf 文件中:
gbde_autoattach_all="YES" gbde_devices="ad4s1c" gbde_lockdir="/etc/gbde"
这要求在启动时在控制台输入密码短语。输入正确的密码短语后,加密分区将自动挂载。还有其他可用的 gbde 启动选项,可以在 rc.conf(5) 中找到并列出。
|
sysinstall 与 gbde 加密设备不兼容。在启动 sysinstall 之前,必须将所有的 *.bde 设备从内核中分离,否则在设备的初始探测过程中,sysinstall 会崩溃。要分离示例中使用的加密设备,请使用以下命令: |
20.13.2. 使用 geli 进行磁盘加密
可以使用 geli 来使用另一种加密 GEOM 类。这个控制工具添加了一些功能,并使用了不同的加密方案来进行加密工作。它提供以下功能:
-
当可用时,利用 crypto(9) 框架并自动使用加密硬件。
-
支持多种加密算法,如 AES、Blowfish 和 3DES。
-
允许对根分区进行加密。在系统启动期间,将要求输入用于访问加密根分区的密码短语。
-
允许使用两个独立的键。
-
它之所以快速,是因为它执行简单的扇区级加密。
-
允许备份和恢复主密钥。如果用户销毁了他们的密钥,仍然可以通过从备份中恢复密钥来访问数据。
-
允许磁盘使用随机的一次性密钥进行连接,这对于交换分区和临时文件系统非常有用。
更多功能和使用示例可以在 geli(8) 中找到。
下面的示例描述了如何生成一个密钥文件,该文件将作为加密提供者在 /private 下挂载的主密钥的一部分。密钥文件将提供一些用于加密主密钥的随机数据。主密钥还将受到密码短语的保护。提供者的扇区大小将为 4kB 。该示例描述了如何连接到 geli 提供者,创建一个文件系统,挂载它,使用它,并最终如何卸载它。
过程:使用
geli 加密分区-
加载
geli支持支持
geli的功能作为可加载的内核模块提供。要配置系统在启动时自动加载该模块,请将以下行添加到 /boot/loader.conf 文件中:geom_eli_load="YES"
现在加载内核模块:
# kldload geom_eli对于自定义内核,请确保内核配置文件包含以下行:
options GEOM_ELI device crypto
-
生成主密钥
以下命令生成一个主密钥,所有数据都将使用该密钥进行加密。该密钥是不可更改的。与直接使用该密钥不同,它会被一个或多个用户密钥加密。用户密钥由来自文件 /root/da2.key 的可选随机字节或者口令组成。在这种情况下,密钥文件的数据源是 /dev/random。此命令还将提供者 (/dev/da2.eli) 的扇区大小配置为 4kB ,以提高性能。
# dd if=/dev/random of=/root/da2.key bs=64 count=1 # geli init -K /root/da2.key -s 4096 /dev/da2 Enter new passphrase: Reenter new passphrase:不强制同时使用密码短语和密钥文件,因为可以单独使用其中一种方法来保护主密钥。
如果密钥文件以"-"表示,则使用标准输入。例如,以下命令将生成三个密钥文件:
# cat keyfile1 keyfile2 keyfile3 | geli init -K - /dev/da2 -
将生成的密钥与提供者关联。
要附加提供者,请指定密钥文件、磁盘名称和密码短语:
# geli attach -k /root/da2.key /dev/da2 Enter passphrase:这将创建一个带有 .eli 扩展名的新设备:
# ls /dev/da2* /dev/da2 /dev/da2.eli -
创建新的文件系统
接下来,使用 UFS 文件系统对设备进行格式化,并将其挂载到现有的挂载点上:
# dd if=/dev/random of=/dev/da2.eli bs=1m # newfs /dev/da2.eli # mount /dev/da2.eli /private加密文件系统现在可以使用了。
# df -H Filesystem Size Used Avail Capacity Mounted on /dev/ad0s1a 248M 89M 139M 38% / /devfs 1.0K 1.0K 0B 100% /dev /dev/ad0s1f 7.7G 2.3G 4.9G 32% /usr /dev/ad0s1d 989M 1.5M 909M 0% /tmp /dev/ad0s1e 3.9G 1.3G 2.3G 35% /var /dev/da2.eli 150G 4.1K 138G 0% /private
一旦加密分区的工作完成,并且不再需要 /private 分区,为了安全起见,应该将设备放入冷存储中,即卸载并从内核中分离 geli 加密分区:
# umount /private
# geli detach da2.eli为了简化启动时 geli 加密设备的挂载,提供了一个 rc.d 脚本。对于这个示例,请将以下行添加到 /etc/rc.conf 文件中:
geli_devices="da2" geli_da2_flags="-k /root/da2.key"
这将 /dev/da2 配置为具有 /root/da2.key 作为主密钥的 geli 提供程序。系统将在关闭系统之前自动从内核中分离该提供程序。在启动过程中,脚本将在连接提供程序之前提示输入密码。在密码提示之前和之后可能会显示其他内核消息。如果启动过程似乎停滞不前,请仔细查找其他消息中的密码提示。一旦输入正确的密码,提供程序将被连接。然后文件系统通常会被挂载,通过 /etc/fstab 中的条目进行。有关如何配置文件系统在启动时挂载的说明,请参阅“挂载和卸载文件系统” 。
20.14. 加密交换分区
像磁盘分区的加密一样,交换空间的加密用于保护敏感信息。考虑一个处理密码的应用程序。只要这些密码保留在物理内存中,它们不会被写入磁盘,并且在重新启动后会被清除。然而,如果 FreeBSD 开始交换内存页面以释放空间,密码可能会以未加密的形式写入磁盘。对交换空间进行加密可以解决这种情况。
20.14.1. 配置加密交换空间
默认情况下,交换分区不会被加密,应在继续之前清除其中的任何敏感数据。要用随机垃圾覆盖当前的交换分区,请执行以下命令:
# dd if=/dev/random of=/dev/ada0s1b bs=1m要使用 gbde(8) 加密交换分区,请在 /etc/fstab 中的交换行上添加 .bde 后缀。
# Device Mountpoint FStype Options Dump Pass# /dev/ada0s1b.bde none swap sw 0 0
要使用 geli(8) 来加密交换分区,可以使用 .eli 后缀:
# Device Mountpoint FStype Options Dump Pass# /dev/ada0s1b.eli none swap sw 0 0
默认情况下,geli(8) 使用 128 位密钥长度的 AES 算法。通常情况下,默认设置就足够了。如果需要的话,可以在 /etc/fstab 中的选项字段中更改这些默认值。可能的标志有:
这个示例配置了一个使用 Blowfish 算法的加密交换分区,密钥长度为 128 位,扇区大小为 4 千字节。
# Device Mountpoint FStype Options Dump Pass# /dev/ada0s1b.eli none swap sw,ealgo=blowfish,keylen=128,sectorsize=4096 0 0
20.15. 高可用存储(Highly Available Storage,HAST)
高可用性是严肃的商业应用程序的主要要求之一,而高可用性存储是这种环境中的关键组成部分。在 FreeBSD 中,高可用性存储(HAST)框架允许通过 TCP/IP 网络在多个物理分离的机器上透明地存储相同的数据。HAST 可以理解为基于网络的 RAID1(镜像),类似于在 GNU/Linux 平台上使用的 DRBD® 存储系统。结合 FreeBSD 的其他高可用性功能(如 CARP),HAST 使得构建一个抵抗硬件故障的高可用性存储集群成为可能。
以下是 HAST 的主要特点:
-
可用于掩盖本地硬盘的 I/O 错误。
-
它与 FreeBSD 支持的任何文件系统兼容,与文件系统无关。
-
只有在节点宕机期间被修改的块才会进行同步,从而实现高效快速的重新同步。
-
可以在已部署的环境中使用,以增加额外的冗余性。
-
与 CARP、Heartbeat 或其他工具一起,它可以用于构建强大和耐用的存储系统。
阅读本节后,您将了解:
-
HAST 是什么,它是如何工作的,以及它提供了哪些功能。
-
如何在 FreeBSD 上设置和使用 HAST 。
-
如何集成 CARP 和 devd(8) 以构建一个强大的存储系统。
在阅读本节之前,您应该:
-
了解 UNIX® 和 FreeBSD 基础知识(FreeBSD Basics)。
-
了解如何配置网络接口和其他核心的 FreeBSD 子系统(Configuration and Tuning)。
-
对 FreeBSD 网络有很好的理解(“网络通信”)。
HAST 项目由 FreeBSD 基金会赞助,得到了 http://www.omc.net/ 和 http://www.transip.nl/ 的支持。
20.15.1. HAST 操作
HAST 提供了两台物理机之间的同步块级复制:主节点 和_ 备节点_。这两台机器一起被称为一个集群。
由于 HAST 以主-备配置工作,所以在任何给定的时间内只允许集群中的一个节点处于活动状态。主节点,也称为“活动节点”,负责处理所有对 HAST 管理设备的 I/O 请求。备节点会自动从主节点同步。
HAST 系统的物理组件包括主节点上的本地磁盘和远程次节点上的磁盘。
HAST 在块级别上同步操作,对文件系统和应用程序透明。 HAST 在 /dev/hast/ 目录下提供常规的 GEOM 提供程序,供其他工具或应用程序使用。使用 HAST 提供的设备和原始磁盘或分区之间没有区别。
每个写入、删除或刷新操作都会通过 TCP/IP 同时发送到本地磁盘和远程磁盘。每个读取操作都会从本地磁盘提供,除非本地磁盘不是最新的或发生了 I/O 错误。在这种情况下,读取操作会被发送到辅助节点。
HAST 试图提供快速的故障恢复。因此,在节点故障后减少同步时间非常重要。为了提供快速同步,HAST 管理一个磁盘上的脏扩展位图,并且只在定期同步期间同步这些扩展,初始同步除外。
处理同步的方法有很多种。HAST 实现了几种复制模式来处理不同的同步方法:
-
memsync:当本地写操作完成并且远程节点确认数据到达之后,但在实际存储数据之前,该模式将报告写操作已完成。在发送确认之后,远程节点上的数据将直接存储。该模式旨在减少延迟,但仍提供良好的可靠性。该模式是默认模式。
-
fullsync:当本地写操作和远程写操作都完成时,该模式将报告写操作已完成。这是最安全但也是最慢的复制模式。
-
async:此模式在本地写操作完成时报告写操作完成。这是最快速和最危险的复制模式。只有在复制到远程节点时延迟过高以至于其他模式无法使用时才应使用此模式。
20.15.2. HAST 配置
HAST 框架由几个组件组成:
-
hastd(8) 守护进程提供数据同步功能。当启动这个守护进程时,它会自动加载
geom_gate.ko模块。 -
用户空间管理实用程序,hastctl(8)。
-
hast.conf(5) 配置文件。在启动 hastd 之前,此文件必须存在。
如果用户希望静态地在内核中内置 GEOM_GATE 支持,应该将以下行添加到自定义内核配置文件中,然后按照 配置 FreeBSD 内核 中的说明重新构建内核。
options GEOM_GATE
以下示例描述了如何使用 HAST 在两个节点之间配置主备操作来复制数据。节点将被称为 hasta,IP 地址为 172.16.0.1,以及 hastb,IP 地址为 172.16.0.2。两个节点都将有一个专用硬盘 /dev/ad6,大小相同,用于 HAST 操作。HAST 池,有时也称为资源或 GEOM 提供者,在 /dev/hast/ 中将被称为 test。
HAST 的配置是通过使用 /etc/hast.conf 文件完成的。这个文件在两个节点上应该是相同的。最简单的配置如下:
resource test {
on hasta {
local /dev/ad6
remote 172.16.0.2
}
on hastb {
local /dev/ad6
remote 172.16.0.1
}
}
有关更高级的配置,请参考 hast.conf(5)。
|
如果主机是可解析的,并且在 /etc/hosts 或本地 DNS 中定义了,也可以在 |
一旦配置在两个节点上存在,就可以创建 HAST 池。在两个节点上运行以下命令,将初始元数据放置在本地磁盘上并启动 hastd(8):
# hastctl create test
# service hastd onestart|
无法使用 GEOM 提供程序与现有文件系统一起使用,也无法将现有存储转换为 HAST 管理的池。此过程需要在提供程序上存储一些元数据,而现有提供程序上没有足够的空间可用。 |
HAST 节点的 primary 或 secondary 角色由管理员或像 Heartbeat 这样的软件使用 hastctl(8) 选择。在主节点上,执行以下命令:
# hastctl role primary test在辅助节点上运行以下命令,hastb:
# hastctl role secondary test在每个节点上运行 hastctl 来验证结果:
# hastctl status test检查输出中的 status 行。如果它显示为 degraded,则配置文件存在问题。每个节点上应该显示为 complete,表示节点之间的同步已经开始。当 hastctl status 报告 0 字节的 dirty extents 时,同步完成。
下一步是在 GEOM 提供程序上创建文件系统并挂载它。这必须在 primary 节点上完成。根据硬盘的大小,创建文件系统可能需要几分钟的时间。此示例在 /dev/hast/test 上创建了一个 UFS 文件系统。
# newfs -U /dev/hast/test
# mkdir /hast/test
# mount /dev/hast/test /hast/test一旦 HAST 框架正确配置完成,最后一步是确保在系统启动时自动启动 HAST。将以下行添加到 /etc/rc.conf 文件中:
hastd_enable="YES"
20.15.2.1. 故障转移配置
这个示例的目标是构建一个强大的存储系统,能够抵抗任何给定节点的故障。如果主节点发生故障,备用节点将无缝接管,检查和挂载文件系统,并继续工作,不会丢失任何一位数据。
为了完成这个任务,使用 Common Address Redundancy Protocol (CARP) 来提供 IP 层的自动故障转移。CARP 允许同一网络段上的多个主机共享一个 IP 地址。根据 “通用地址冗余协议(CARP)” 中提供的文档,在集群的两个节点上设置 CARP 。在这个例子中,每个节点都有自己的管理 IP 地址和一个共享的 IP 地址为 172.16.0.254。集群的主要 HAST 节点必须是主要的 CARP 节点。
在前一节中创建的 HAST 池现在已经准备好导出到网络上的其他主机。可以通过 NFS 或 Samba 将其导出,使用共享的 IP 地址 172.16.0.254。唯一尚未解决的问题是主节点故障时的自动故障转移。
当 CARP 接口上下线时,FreeBSD 操作系统会生成一个 devd(8) 事件,这样就可以监视 CARP 接口的状态变化。CARP 接口的状态变化表示其中一个节点失败或重新上线。这些状态变化事件使得可以运行一个脚本来自动处理 HAST 故障切换。
要捕获 CARP 接口上的状态变化,请在每个节点的 /etc/devd.conf 配置文件中添加以下配置:
notify 30 {
match "system" "IFNET";
match "subsystem" "carp0";
match "type" "LINK_UP";
action "/usr/local/sbin/carp-hast-switch primary";
};
notify 30 {
match "system" "IFNET";
match "subsystem" "carp0";
match "type" "LINK_DOWN";
action "/usr/local/sbin/carp-hast-switch secondary";
};
|
如果系统运行的是 FreeBSD 10 或更高版本,请将 carp0 替换为 CARP 配置接口的名称。 |
在两个节点上重新启动 devd(8),以使新配置生效:
# service devd restart当指定的接口状态发生上升或下降变化时,系统会生成一个通知,允许 devd(8) 子系统运行指定的自动故障转移脚本 /usr/local/sbin/carp-hast-switch。有关此配置的进一步说明,请参考 devd.conf(5)。
这是一个自动故障转移脚本的示例:
#!/bin/sh # Original script by Freddie Cash <[email protected]> # Modified by Michael W. Lucas <[email protected]> # and Viktor Petersson <[email protected]> # The names of the HAST resources, as listed in /etc/hast.conf resources="test" # delay in mounting HAST resource after becoming primary # make your best guess delay=3 # logging log="local0.debug" name="carp-hast" # end of user configurable stuff case "$1" in primary) logger -p $log -t $name "Switching to primary provider for ${resources}." sleep ${delay} # Wait for any "hastd secondary" processes to stop for disk in ${resources}; do while $( pgrep -lf "hastd: ${disk} \(secondary\)" > /dev/null 2>&1 ); do sleep 1 done # Switch role for each disk hastctl role primary ${disk} if [ $? -ne 0 ]; then logger -p $log -t $name "Unable to change role to primary for resource ${disk}." exit 1 fi done # Wait for the /dev/hast/* devices to appear for disk in ${resources}; do for I in $( jot 60 ); do [ -c "/dev/hast/${disk}" ] && break sleep 0.5 done if [ ! -c "/dev/hast/${disk}" ]; then logger -p $log -t $name "GEOM provider /dev/hast/${disk} did not appear." exit 1 fi done logger -p $log -t $name "Role for HAST resources ${resources} switched to primary." logger -p $log -t $name "Mounting disks." for disk in ${resources}; do mkdir -p /hast/${disk} fsck -p -y -t ufs /dev/hast/${disk} mount /dev/hast/${disk} /hast/${disk} done ;; secondary) logger -p $log -t $name "Switching to secondary provider for ${resources}." # Switch roles for the HAST resources for disk in ${resources}; do if ! mount | grep -q "^/dev/hast/${disk} on " then else umount -f /hast/${disk} fi sleep $delay hastctl role secondary ${disk} 2>&1 if [ $? -ne 0 ]; then logger -p $log -t $name "Unable to switch role to secondary for resource ${disk}." exit 1 fi logger -p $log -t $name "Role switched to secondary for resource ${disk}." done ;; esac
简而言之,当一个节点成为主节点时,脚本会执行以下操作:
-
将 HAST 池提升为另一节点上的主节点。
-
检查 HAST 池下的文件系统。
-
挂载存储池。
当一个节点变为次要节点时:
-
卸载 HAST 池。
-
将 HAST 池降级为辅助池。
|
这只是一个作为概念验证的示例脚本。它并不能处理所有可能的情况,并且可以根据需要进行扩展或修改,例如启动或停止所需的服务。 |
|
对于这个示例,使用了标准的 UFS 文件系统。为了减少恢复所需的时间,可以使用启用了日志的 UFS 或 ZFS 文件系统。 |
更详细的信息和额外的示例可以在 http://wiki.FreeBSD.org/HAST 找到。
20.15.3. 故障排除
HAST 通常应该没有问题。然而,与任何其他软件产品一样,有时候它可能无法按照预期工作。问题的根源可能不同,但经验法则是确保集群节点之间的时间同步。
在排除 HAST 问题时,应通过使用 -d 参数启动 hastd 来增加 hastd(8) 的调试级别。可以多次指定此参数以进一步增加调试级别。还可以考虑使用 -F,它会在前台启动 hastd。
Chapter 21. GEOM :模块化磁盘转换框架
21.1. 简介
在 FreeBSD 中, GEOM 框架通过使用提供者(或者说是位于 /dev 目录下的磁盘设备)允许访问和控制类别,例如主引导记录和 BSD 标签。通过支持各种软件 RAID 配置, GEOM 可以透明地提供对操作系统和操作系统工具的访问。
本章介绍了在 FreeBSD 中使用 GEOM 框架下的磁盘。这包括使用该框架进行配置的主要 RAID 控制工具。本章不是关于 RAID 配置的权威指南,只讨论了 GEOM 支持的 RAID 分类。
阅读完本章后,您将会了解:
-
GEOM 提供哪种类型的 RAID 支持?
-
如何使用基本工具来配置、维护和操作各种 RAID 级别。
-
如何通过 GEOM 镜像、条带化、加密和远程连接磁盘设备。
-
如何排除与 GEOM 框架连接的磁盘问题。
在阅读本章之前,您应该:
-
了解 FreeBSD 如何处理磁盘设备(参考: disks[disks ,存储] )。
-
了解如何配置和安装新的内核(参考: kernelconfig[kernelconfig ,配置 FreeBSD 内核] )。
21.2. RAID0 - 条带化
条带化将多个磁盘驱动器合并为一个卷。可以通过使用硬件 RAID 控制器来执行条带化。 GEOM 磁盘子系统提供了对磁盘条带化的软件支持,也称为 RAID0 ,无需 RAID 磁盘控制器。
在 RAID0 中,数据被分割成块,并写入阵列中的所有驱动器。如下图所示, RAID0 可以同时将 64k 写入阵列中的四个驱动器,而不是等待系统将 256k 写入一个磁盘,从而提供更优异的 I/O 性能。通过使用多个磁盘控制器,可以进一步提升性能。
RAID0 条带中的每个磁盘必须具有相同的大小,因为 I/O 请求会交错地并行读取或写入多个磁盘。
|
RAID0 不提供任何冗余功能。这意味着如果阵列中的一个磁盘故障,所有磁盘上的数据都会丢失。如果数据很重要,请实施定期将备份保存到远程系统或设备的备份策略。 |
使用普通磁盘在 FreeBSD 系统上创建基于 GEOM 的 RAID0 软件的过程如下。创建条带后,可以参考 gstripe(8) 了解如何控制现有的条带的更多信息。
21.3. RAID1 - 镜像
RAID1 ,或者称为镜像,是一种将相同数据写入多个磁盘驱动器的技术。镜像通常用于防止由于驱动器故障而导致的数据丢失。镜像中的每个驱动器都包含数据的完全相同副本。当一个驱动器故障时,镜像仍然可以工作,从仍在运行的驱动器提供数据。计算机继续运行,管理员有时间替换故障的驱动器而不会中断用户。
这些示例中展示了两种常见情况。第一种情况是使用两个新的驱动器创建一个镜像,并将其作为现有单个驱动器的替代品。第二个示例是在一个新的驱动器上创建一个镜像,将旧驱动器的数据复制到其中,然后将旧驱动器插入到镜像中。虽然这个过程稍微复杂一些,但只需要一个新的驱动器。
传统上,镜像中的两个驱动器在型号和容量上是相同的,但是 gmirror(8) 并不要求如此。使用不同驱动器创建的镜像的容量将等于镜像中最小驱动器的容量。较大驱动器上的额外空间将不会被使用。后来插入镜像的驱动器必须至少具有与镜像中已有的最小驱动器相同的容量。
|
这里展示的镜像过程是非破坏性的,但是像任何重要的磁盘操作一样,请先进行完整备份。 |
21.3.1. 元数据问题
许多磁盘系统将元数据存储在每个磁盘的末尾。在将磁盘重新用于镜像之前,应该擦除旧的元数据。大多数问题是由两种特定类型的残留元数据引起的: GPT 分区表和来自先前镜像的旧元数据。
可以使用 gpart(8) 命令来擦除 GPT 元数据。这个例子会从磁盘 ada8 上擦除主 GPT 分区表和备份 GPT 分区表。
# gpart destroy -F ada8可以使用 gmirror(8) 命令一步完成从活动镜像中移除磁盘并擦除元数据。在这个例子中,磁盘 ada8 从活动镜像 gm4 中被移除。
# gmirror remove gm4 ada8如果镜像没有运行,但旧的镜像元数据仍然存在于磁盘上,请使用 gmirror clear 命令将其删除:
# gmirror clear ada8gmirror(8) 在磁盘的末尾存储一个块的元数据。由于 GPT 分区方案也在磁盘末尾存储元数据,因此不建议使用 gmirror(8) 来镜像整个 GPT 磁盘。这里使用 MBR 分区,因为它只在磁盘的开头存储分区表,不会与镜像的元数据冲突。
21.3.2. 使用两个新硬盘创建镜像
在这个例子中, FreeBSD 已经安装在一个单独的磁盘上, ada0 。系统已经连接了两个新的磁盘, ada1 和 ada2 。将在这两个磁盘上创建一个新的镜像,并用它来替换旧的单个磁盘。
内核模块 geom_mirror.ko 必须在内核中构建或在启动或运行时加载。现在手动加载内核模块:
# gmirror load使用两个新的硬盘创建镜像:
# gmirror label -v gm0 /dev/ada1 /dev/ada2gm0 是用户选择的设备名称,用于指定新镜像。在镜像启动后,该设备名称将出现在 /dev/mirror/ 中。
现在可以使用 gpart(8) 在镜像上创建 MBR 和 bsdlabel 分区表。这个例子使用传统的文件系统布局,包括用于 [/] 、交换空间、 [/var] 、 [/tmp] 和 [/usr] 的分区。也可以只使用一个 [/] 和一个交换空间分区。
镜像上的分区不必与现有磁盘上的分区大小相同,但必须足够大以容纳已经存在于 ada0 上的所有数据。
# gpart create -s MBR mirror/gm0
# gpart add -t freebsd -a 4k mirror/gm0
# gpart show mirror/gm0
=> 63 156301423 mirror/gm0 MBR (74G)
63 63 - free - (31k)
126 156301299 1 freebsd (74G)
156301425 61 - free - (30k)# gpart create -s BSD mirror/gm0s1
# gpart add -t freebsd-ufs -a 4k -s 2g mirror/gm0s1
# gpart add -t freebsd-swap -a 4k -s 4g mirror/gm0s1
# gpart add -t freebsd-ufs -a 4k -s 2g mirror/gm0s1
# gpart add -t freebsd-ufs -a 4k -s 1g mirror/gm0s1
# gpart add -t freebsd-ufs -a 4k mirror/gm0s1
# gpart show mirror/gm0s1
=> 0 156301299 mirror/gm0s1 BSD (74G)
0 2 - free - (1.0k)
2 4194304 1 freebsd-ufs (2.0G)
4194306 8388608 2 freebsd-swap (4.0G)
12582914 4194304 4 freebsd-ufs (2.0G)
16777218 2097152 5 freebsd-ufs (1.0G)
18874370 137426928 6 freebsd-ufs (65G)
156301298 1 - free - (512B)通过在 MBR 中安装引导代码和 bsdlabel ,并设置活动分区,使镜像可引导:
# gpart bootcode -b /boot/mbr mirror/gm0
# gpart set -a active -i 1 mirror/gm0
# gpart bootcode -b /boot/boot mirror/gm0s1在新的镜像上格式化文件系统,并启用软更新。
# newfs -U /dev/mirror/gm0s1a
# newfs -U /dev/mirror/gm0s1d
# newfs -U /dev/mirror/gm0s1e
# newfs -U /dev/mirror/gm0s1f现在可以使用 dump(8) 和 restore(8) 将原始的 ada0 磁盘上的文件系统复制到镜像中。
# mount /dev/mirror/gm0s1a /mnt
# dump -C16 -b64 -0aL -f - / | (cd /mnt && restore -rf -)
# mount /dev/mirror/gm0s1d /mnt/var
# mount /dev/mirror/gm0s1e /mnt/tmp
# mount /dev/mirror/gm0s1f /mnt/usr
# dump -C16 -b64 -0aL -f - /var | (cd /mnt/var && restore -rf -)
# dump -C16 -b64 -0aL -f - /tmp | (cd /mnt/tmp && restore -rf -)
# dump -C16 -b64 -0aL -f - /usr | (cd /mnt/usr && restore -rf -)编辑 /mnt/etc/fstab ,将其指向新的镜像文件系统:
# Device Mountpoint FStype Options Dump Pass# /dev/mirror/gm0s1a / ufs rw 1 1 /dev/mirror/gm0s1b none swap sw 0 0 /dev/mirror/gm0s1d /var ufs rw 2 2 /dev/mirror/gm0s1e /tmp ufs rw 2 2 /dev/mirror/gm0s1f /usr ufs rw 2 2
如果内核模块 geom_mirror.ko 没有被编译到内核中,需要编辑 /mnt/boot/loader.conf 文件,在启动时加载该模块:
geom_mirror_load="YES"
重新启动系统以测试新的镜像,并验证所有数据是否已复制。 BIOS 将把镜像视为两个独立的驱动器,而不是一个镜像。由于驱动器是相同的,选择哪个来启动并不重要。
如果启动时出现问题,请参阅 故障排除 。关闭电源并断开原始的 ada0 磁盘,可以将其保留为离线备份。
在使用中,镜像将表现得就像原始的单个驱动器一样。
21.3.3. 使用现有驱动器创建镜像
在这个例子中, FreeBSD 已经安装在一个单独的磁盘上, ada0 。一个新的磁盘, ada1 ,已经连接到系统上。将在新磁盘上创建一个单磁盘镜像,将现有系统复制到其中,然后将旧磁盘插入到镜像中。这个稍微复杂的过程是必需的,因为 gmirror 需要在每个磁盘的末尾放置一个 512 字节的元数据块,而现有的 ada0 通常已经分配了所有的空间。
加载 geom_mirror.ko 内核模块:
# gmirror load使用 diskinfo 命令检查原始磁盘的媒体大小:
# diskinfo -v ada0 | head -n3
/dev/ada0
512 # sectorsize
1000204821504 # mediasize in bytes (931G)在新的磁盘上创建一个镜像。为了确保镜像容量不大于原始的 ada0 驱动器,使用 gnop(8) 创建一个与原始驱动器大小完全相同的虚拟驱动器。这个驱动器不存储任何数据,只用于限制镜像的大小。当 gmirror(8) 创建镜像时,它将限制容量为 gzero.nop 的大小,即使新的 ada1 驱动器有更多的空间。请注意,第二行中的 1000204821504 等于 ada0 的媒体大小,如上面的 diskinfo 所示。
# geom zero load
# gnop create -s 1000204821504 gzero
# gmirror label -v gm0 gzero.nop ada1
# gmirror forget gm0由于 gzero.nop 不存储任何数据,因此镜像设备不会将其视为已连接。镜像设备被告知“忘记”未连接的组件,从而删除对 gzero.nop 的引用。结果是一个只包含一个磁盘 ada1 的镜像设备。
创建 gm0 后,查看 ada0 上的分区表。这个输出来自一个 1TB 的硬盘。如果驱动器末尾有一些未分配的空间,可以直接将内容从 ada0 复制到新的镜像中。
然而,如果输出显示磁盘上的所有空间都已分配,就像下面的列表中所示,那么在磁盘末尾没有可用于 512 字节镜像元数据的空间。
# gpart show ada0
=> 63 1953525105 ada0 MBR (931G)
63 1953525105 1 freebsd [active] (931G)在这种情况下,必须编辑分区表,将 mirror/gm0 的容量减少一个扇区。具体操作将在后面解释。
无论哪种情况,都应首先使用 gpart backup 和 gpart restore 命令来复制主硬盘上的分区表。
# gpart backup ada0 > table.ada0
# gpart backup ada0s1 > table.ada0s1这些命令创建了两个文件, table.ada0 和 table.ada0s1 。这个例子是来自一个 1 TB 的硬盘。
# cat table.ada0
MBR 4
1 freebsd 63 1953525105 [active]# cat table.ada0s1
BSD 8
1 freebsd-ufs 0 4194304
2 freebsd-swap 4194304 33554432
4 freebsd-ufs 37748736 50331648
5 freebsd-ufs 88080384 41943040
6 freebsd-ufs 130023424 838860800
7 freebsd-ufs 968884224 984640881如果磁盘末尾没有显示可用空间,则必须将分区和最后一个分区的大小都减小一个扇区。编辑这两个文件,将分区和最后一个分区的大小都减小一个。这些是每个列表中的最后一个数字。
# cat table.ada0
MBR 4
1 freebsd 63 1953525104 [active]# cat table.ada0s1
BSD 8
1 freebsd-ufs 0 4194304
2 freebsd-swap 4194304 33554432
4 freebsd-ufs 37748736 50331648
5 freebsd-ufs 88080384 41943040
6 freebsd-ufs 130023424 838860800
7 freebsd-ufs 968884224 984640880如果磁盘末尾至少有一个扇区未分配,这两个文件可以直接使用,无需修改。
现在将分区表恢复到 [mirror/gm0] 中:
# gpart restore mirror/gm0 < table.ada0
# gpart restore mirror/gm0s1 < table.ada0s1使用 gpart show 命令检查分区表。此示例中,分区表如下: gm0s1a 用于 / , gm0s1d 用于 /var , gm0s1e 用于 /usr , gm0s1f 用于 /data1 ,以及 gm0s1g 用于 /data2 。
# gpart show mirror/gm0
=> 63 1953525104 mirror/gm0 MBR (931G)
63 1953525042 1 freebsd [active] (931G)
1953525105 62 - free - (31k)
# gpart show mirror/gm0s1
=> 0 1953525042 mirror/gm0s1 BSD (931G)
0 2097152 1 freebsd-ufs (1.0G)
2097152 16777216 2 freebsd-swap (8.0G)
18874368 41943040 4 freebsd-ufs (20G)
60817408 20971520 5 freebsd-ufs (10G)
81788928 629145600 6 freebsd-ufs (300G)
710934528 1242590514 7 freebsd-ufs (592G)
1953525042 63 - free - (31k)切片和最后一个分区都必须在磁盘末尾至少有一个空闲块。
在这些新分区上创建文件系统。分区的数量将根据原始磁盘 ada0 而变化。
# newfs -U /dev/mirror/gm0s1a
# newfs -U /dev/mirror/gm0s1d
# newfs -U /dev/mirror/gm0s1e
# newfs -U /dev/mirror/gm0s1f
# newfs -U /dev/mirror/gm0s1g通过在 MBR 中安装引导代码和 bsdlabel ,并设置活动分区,使镜像可引导:
# gpart bootcode -b /boot/mbr mirror/gm0
# gpart set -a active -i 1 mirror/gm0
# gpart bootcode -b /boot/boot mirror/gm0s1将 /etc/fstab 调整为使用镜像上的新分区。首先通过将其复制到 /etc/fstab.orig 来备份此文件。
# cp /etc/fstab /etc/fstab.orig编辑 [/etc/fstab] 文件,将 [/dev/ada0] 替换为 [mirror/gm0] 。
# Device Mountpoint FStype Options Dump Pass# /dev/mirror/gm0s1a / ufs rw 1 1 /dev/mirror/gm0s1b none swap sw 0 0 /dev/mirror/gm0s1d /var ufs rw 2 2 /dev/mirror/gm0s1e /usr ufs rw 2 2 /dev/mirror/gm0s1f /data1 ufs rw 2 2 /dev/mirror/gm0s1g /data2 ufs rw 2 2
如果内核中没有构建 geom_mirror.ko 内核模块,请编辑 /boot/loader.conf 文件,在启动时加载它:
geom_mirror_load="YES"
现在可以使用 dump(8) 和 restore(8) 将原始磁盘上的文件系统复制到镜像上。使用 dump -L 转储的每个文件系统都会首先创建一个快照,这可能需要一些时间。
# mount /dev/mirror/gm0s1a /mnt
# dump -C16 -b64 -0aL -f - / | (cd /mnt && restore -rf -)
# mount /dev/mirror/gm0s1d /mnt/var
# mount /dev/mirror/gm0s1e /mnt/usr
# mount /dev/mirror/gm0s1f /mnt/data1
# mount /dev/mirror/gm0s1g /mnt/data2
# dump -C16 -b64 -0aL -f - /usr | (cd /mnt/usr && restore -rf -)
# dump -C16 -b64 -0aL -f - /var | (cd /mnt/var && restore -rf -)
# dump -C16 -b64 -0aL -f - /data1 | (cd /mnt/data1 && restore -rf -)
# dump -C16 -b64 -0aL -f - /data2 | (cd /mnt/data2 && restore -rf -)重新启动系统,从 ada1 引导。如果一切正常,系统将从 mirror/gm0 引导,该镜像现在包含与 ada0 之前相同的数据。如果启动时出现问题,请参考 故障排除 。
此时,镜像仍然只由单个 ada1 磁盘组成。
成功从 mirror/gm0 启动后,最后一步是将 ada0 插入到镜像中。
|
当 ada0 被插入到镜像中时,它的原始内容将被来自镜像的数据覆盖。在将 ada0 添加到镜像之前,请确保 mirror/gm0 的内容与 ada0 相同。如果之前使用 dump(8) 和 restore(8) 复制的内容与 ada0 上的内容不一致,请将 /etc/fstab 恢复为挂载 ada0 上的文件系统,重新启动,并重新开始整个过程。 |
# gmirror insert gm0 ada0
GEOM_MIRROR: Device gm0: rebuilding provider ada0两个磁盘之间的同步将立即开始。使用 gmirror status 命令查看进度。
# gmirror status
Name Status Components
mirror/gm0 DEGRADED ada1 (ACTIVE)
ada0 (SYNCHRONIZING, 64%)一段时间后,同步将完成。
GEOM_MIRROR: Device gm0: rebuilding provider ada0 finished.
# gmirror status
Name Status Components
mirror/gm0 COMPLETE ada1 (ACTIVE)
ada0 (ACTIVE)mirror/gm0 现在由两个磁盘 ada0 和 ada1 组成,并且它们的内容会自动同步。在使用中, mirror/gm0 的行为与原始的单个驱动器相同。
21.3.4. 故障排除
如果系统无法启动,可能需要更改 BIOS 设置以从新镜像驱动器中启动。可以使用任何一个镜像驱动器进行引导,因为它们包含相同的数据。
如果启动停在这个消息上,说明镜像设备出现了问题:
Mounting from ufs:/dev/mirror/gm0s1a failed with error 19.
Loader variables:
vfs.root.mountfrom=ufs:/dev/mirror/gm0s1a
vfs.root.mountfrom.options=rw
Manual root filesystem specification:
<fstype>:<device> [options]
Mount <device> using filesystem <fstype>
and with the specified (optional) option list.
e.g. ufs:/dev/da0s1a
zfs:tank
cd9660:/dev/acd0 ro
(which is equivalent to: mount -t cd9660 -o ro /dev/acd0 /)
? List valid disk boot devices
. Yield 1 second (for background tasks)
<empty line> Abort manual input
mountroot>忘记在 /boot/loader.conf 中加载 geom_mirror.ko 模块可能会导致这个问题。要修复它,从 FreeBSD 安装介质启动,并在第一个提示处选择 Shell 。然后加载镜像模块并挂载镜像设备:
# gmirror load
# mount /dev/mirror/gm0s1a /mnt编辑 [/mnt/boot/loader.conf] 文件,在其中添加一行代码以加载镜像模块:
geom_mirror_load="YES"
保存文件并重新启动。
导致“错误 19 ”的其他问题需要更多的努力来修复。虽然系统应该从 ada0 启动,但如果 /etc/fstab 不正确,将会出现选择 shell 的另一个提示。在引导加载程序提示符处输入 ufs:/dev/ada0s1a ,然后按下 Enter 。撤消 /etc/fstab 中的编辑,然后将文件系统从原始磁盘 (ada0) 挂载,而不是从镜像挂载。重新启动系统,然后再次尝试该过程。
Enter full pathname of shell or RETURN for /bin/sh:
# cp /etc/fstab.orig /etc/fstab
# reboot21.3.5. 从磁盘故障中恢复
磁盘镜像的好处是,即使一个磁盘发生故障,镜像也不会丢失任何数据。在上面的例子中,如果 ada0 失效,镜像将继续工作,并从剩余的工作驱动器 ada1 提供数据。
要替换故障的驱动器,请关闭系统并将故障的驱动器物理上替换为容量相等或更大的新驱动器。制造商在以千兆字节为单位评估驱动器时使用了一些任意的值,唯一真正确定的方法是比较 diskinfo -v 显示的扇区总数。比镜像容量更大的驱动器也可以工作,尽管新驱动器上的额外空间将不会被使用。
在计算机重新启动后,镜像将以“降级”模式运行,只有一个驱动器。镜像被告知忘记当前未连接的驱动器。
# gmirror forget gm0使用 元数据问题 中的说明清除替换磁盘上的任何旧元数据。然后将替换磁盘(此示例中为 ada4 )插入到镜像中。
# gmirror insert gm0 /dev/ada4当新驱动器插入到镜像中时,重新同步过程开始。将镜像数据复制到新驱动器可能需要一段时间。在复制过程中,镜像的性能将大大降低,因此最好在计算机需求较低时插入新驱动器。
可以使用 gmirror status 来监视进度,它会显示正在同步的驱动器以及完成的百分比。在重新同步期间,状态将显示为 DEGRADED ,当过程完成时,状态将变为 COMPLETE 。
21.4. RAID3 - 以字节为单位的条带化和专用奇偶校验
RAID3 是一种将多个磁盘驱动器组合成一个具有专用奇偶校验磁盘的卷的方法。在 RAID3 系统中,数据被分割成多个字节,这些字节被写入阵列中的所有磁盘,除了一个充当专用奇偶校验磁盘的磁盘。这意味着从 RAID3 实现中读取磁盘时,会访问阵列中的所有磁盘。通过使用多个磁盘控制器,可以提高性能。 RAID3 阵列提供了 1 个驱动器的容错能力,同时提供了总容量为所有磁盘的总容量的 1-1/n 倍的容量,其中 n 是阵列中的硬盘数量。这种配置主要适用于存储较大的数据,如多媒体文件。
构建 RAID3 阵列至少需要 3 个物理硬盘。每个硬盘的大小必须相同,因为 I/O 请求会交错地并行读取或写入多个硬盘。此外,由于 RAID3 的特性,驱动器的数量必须等于 3 、 5 、 9 、 17 等,即 2 ^ n + 1 。
本节演示了如何在 FreeBSD 系统上创建一个软件 RAID3 。
|
虽然理论上可以在 FreeBSD 上从 RAID3 阵列引导,但这种配置并不常见,也不建议使用。 |
21.4.1. 创建一个专用的 RAID3 阵列
在 FreeBSD 中,对 RAID3 的支持是通过 graid3(8) GEOM 类实现的。在 FreeBSD 上创建一个专用的 RAID3 阵列需要以下步骤。
-
首先,通过执行以下命令之一加载内核模块 geom_raid3.ko :
# graid3 load或者:
# kldload geom_raid3 -
确保存在一个合适的挂载点。此命令将创建一个新的目录作为挂载点使用:
# mkdir /multimedia -
确定要添加到阵列中的磁盘的设备名称,并创建新的 RAID3 设备。最后列出的设备将作为专用奇偶校验磁盘。此示例使用三个未分区的 ATA 驱动器: ada1 和 ada2 用于数据,以及 ada3 用于奇偶校验。
# graid3 label -v gr0 /dev/ada1 /dev/ada2 /dev/ada3 Metadata value stored on /dev/ada1. Metadata value stored on /dev/ada2. Metadata value stored on /dev/ada3. Done. -
将新创建的 gr0 设备进行分区,并在其上放置一个 UFS 文件系统:
# gpart create -s GPT /dev/raid3/gr0 # gpart add -t freebsd-ufs /dev/raid3/gr0 # newfs -j /dev/raid3/gr0p1许多数字将在屏幕上滑动,经过一段时间后,过程将完成。卷已创建并准备好挂载:
# mount /dev/raid3/gr0p1 /multimedia/RAID3 阵列现在可以使用了。
需要进行额外的配置才能在系统重新启动后保留此设置。
-
在挂载阵列之前,必须加载 geom_raid3.ko 模块。为了在系统初始化期间自动加载内核模块,请将以下行添加到 /boot/loader.conf 文件中:
geom_raid3_load="YES"
-
在系统启动过程中,必须将以下卷信息添加到 /etc/fstab 中,以便自动挂载阵列的文件系统:
/dev/raid3/gr0p1 /multimedia ufs rw 2 2
21.5. 软件 RAID 设备
一些主板和扩展卡会添加一些简单的硬件,通常只是一个 ROM ,使得计算机可以从 RAID 阵列启动。启动后,对 RAID 阵列的访问由运行在计算机主处理器上的软件处理。这种“硬件辅助软件 RAID ”提供了不依赖于任何特定操作系统的 RAID 阵列,并且在加载操作系统之前就可以正常工作。
根据所使用的硬件,支持多个级别的 RAID 。有关完整列表,请参阅 graid(8) 。
graid(8) 需要 geom_raid.ko 内核模块,该模块从 FreeBSD 9.1 开始包含在 GENERIC 内核中。如果需要,可以使用 graid load 命令手动加载该模块。
21.5.1. 创建一个数组
软件 RAID 设备通常在计算机启动时按下特殊键进入菜单。该菜单可用于创建和删除 RAID 阵列。 graid(8) 也可以直接从命令行创建阵列。
graid label 用于创建一个新的阵列。本例中使用的主板具有 Intel 软件 RAID 芯片组,因此指定了 Intel 元数据格式。新的阵列被赋予了一个标签 gm0 ,它是一个镜像( RAID1 ),并使用驱动器 ada0 和 ada1 。
|
当将驱动器制作成新的阵列时,一些空间将被覆盖。请先备份现有数据! |
# graid label Intel gm0 RAID1 ada0 ada1
GEOM_RAID: Intel-a29ea104: Array Intel-a29ea104 created.
GEOM_RAID: Intel-a29ea104: Disk ada0 state changed from NONE to ACTIVE.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:0-ada0 state changed from NONE to ACTIVE.
GEOM_RAID: Intel-a29ea104: Disk ada1 state changed from NONE to ACTIVE.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:1-ada1 state changed from NONE to ACTIVE.
GEOM_RAID: Intel-a29ea104: Array started.
GEOM_RAID: Intel-a29ea104: Volume gm0 state changed from STARTING to OPTIMAL.
Intel-a29ea104 created
GEOM_RAID: Intel-a29ea104: Provider raid/r0 for volume gm0 created.状态检查显示新的镜像已经准备就绪,可以使用了。
# graid status
Name Status Components
raid/r0 OPTIMAL ada0 (ACTIVE (ACTIVE))
ada1 (ACTIVE (ACTIVE))数组设备出现在 [/dev/raid/]# 目录中。第一个数组被称为 [r0]# 。如果存在其他数组,它们将被称为 [r1]# 、 [r2]# 等等。
某些设备上的 BIOS 菜单可以创建带有特殊字符的数组名称。为了避免这些特殊字符带来的问题,数组被赋予简单的编号名称,例如 r0 。要显示实际的标签,例如上面的示例中的 gm0 ,请使用 sysctl(8) 命令。
# sysctl kern.geom.raid.name_format=121.5.2. 多个卷
一些软件 RAID 设备支持在阵列上创建多个卷。卷的工作方式类似于分区,允许将物理驱动器上的空间分割并以不同的方式使用。例如, Intel 软件 RAID 设备支持两个卷。此示例创建一个 40G 的镜像卷,用于安全存储操作系统,然后是一个 20G 的 RAID0 (条带)卷,用于快速临时存储。
# graid label -S 40G Intel gm0 RAID1 ada0 ada1
# graid add -S 20G gm0 RAID0卷在 /dev/raid/ 目录下以额外的 .filenamerX 条目显示。一个包含两个卷的阵列将显示 .filenamer0 和 .filenamer1 。
请参阅 graid(8) ,了解不同软件 RAID 设备支持的卷数。
21.5.3. 将单个驱动器转换为镜像
在特定条件下,可以将现有的单个驱动器转换为 graid(8) 阵列而无需重新格式化。为了在转换过程中避免数据丢失,现有的驱动器必须满足以下最低要求:
如果驱动器符合这些要求,请先进行完整备份。然后使用该驱动器创建一个单驱动器镜像:
# graid label Intel gm0 RAID1 ada0 NONEgraid(8) 元数据被写入未使用空间的驱动器末尾。现在可以将第二个驱动器插入到镜像中:
# graid insert raid/r0 ada1原始驱动器的数据将立即开始复制到第二个驱动器。在复制完成之前,镜像将以降级状态运行。
21.5.4. 将新驱动器插入阵列中
可以将驱动器插入到阵列中,作为替换已经故障或丢失的驱动器。如果没有故障或丢失的驱动器,新的驱动器将成为备用驱动器。例如,将新的驱动器插入到工作中的两个驱动器的镜像中,将得到一个带有一个备用驱动器的两个驱动器的镜像,而不是一个三个驱动器的镜像。
在镜像阵列的示例中,数据立即开始复制到新插入的驱动器上。新驱动器上的任何现有信息都将被覆盖。
# graid insert raid/r0 ada1
GEOM_RAID: Intel-a29ea104: Disk ada1 state changed from NONE to ACTIVE.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:1-ada1 state changed from NONE to NEW.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:1-ada1 state changed from NEW to REBUILD.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:1-ada1 rebuild start at 0.21.5.5. 从阵列中移除驱动器
可以永久从阵列中移除单个驱动器,并擦除其元数据:
# graid remove raid/r0 ada1
GEOM_RAID: Intel-a29ea104: Disk ada1 state changed from ACTIVE to OFFLINE.
GEOM_RAID: Intel-a29ea104: Subdisk gm0:1-[unknown] state changed from ACTIVE to NONE.
GEOM_RAID: Intel-a29ea104: Volume gm0 state changed from OPTIMAL to DEGRADED.21.5.7. 检查数组状态
数组状态可以随时检查。在上面的示例中,当一个驱动器被添加到镜像中后,数据将从原始驱动器复制到新驱动器。
# graid status
Name Status Components
raid/r0 DEGRADED ada0 (ACTIVE (ACTIVE))
ada1 (ACTIVE (REBUILD 28%))某些类型的阵列,例如 RAID0 或 CONCAT ,如果磁盘故障,可能不会在状态报告中显示。要查看这些部分故障的阵列,请添加 -ga :
# graid status -ga
Name Status Components
Intel-e2d07d9a BROKEN ada6 (ACTIVE (ACTIVE))21.5.9. 删除意外的数组
-
启动系统。在启动菜单中,选择
2进入加载器提示符。输入:OK set kern.geom.raid.enable=0 OK boot系统将禁用 graid(8) 启动。
-
备份受影响驱动器上的所有数据。
-
作为一种解决方法,可以通过添加来禁用 graid(8) 阵列检测。
kern.geom.raid.enable=0
到 /boot/loader.conf 。
要永久删除受影响驱动器上的 graid(8) 元数据,请启动 FreeBSD 安装 CD-ROM 或内存棒,并选择
Shell。使用status命令找到阵列的名称,通常为raid/r0:# graid status Name Status Components raid/r0 OPTIMAL ada0 (ACTIVE (ACTIVE)) ada1 (ACTIVE (ACTIVE))按名称删除卷:
# graid delete raid/r0如果显示了多个卷,请为每个卷重复此过程。在删除最后一个阵列后,卷将被销毁。
重新启动并验证数据,如果需要的话,从备份中恢复。在元数据被删除后,还可以删除 /boot/loader.conf 中的
kern.geom.raid.enable = 0条目。
21.6. GEOM Gate Network 是一种计算机网络技术。
GEOM 提供了一种简单的机制,通过使用 GEOM Gate 网络守护进程 ggated ,可以远程访问诸如磁盘、 CD 和文件系统等设备。拥有设备的系统运行服务器守护进程,处理客户端使用 ggatec 发出的请求。设备不应包含任何敏感数据,因为客户端和服务器之间的连接没有加密。
与 NFS 类似, ggated 也使用 exports 文件进行配置。该文件指定了哪些系统被允许访问导出的资源以及它们所提供的访问级别。例如,要给客户端 192.168.1.5 对第一个 SCSI 磁盘的第四个分区进行读写访问权限,可以在 /etc/gg.exports 文件中添加以下行:
192.168.1.5 RW /dev/da0s4d
在导出设备之前,请确保它当前没有挂载。然后,启动 ggated :
# ggated有几个选项可用于指定备用的监听端口或更改 exports 文件的默认位置。有关详细信息,请参阅 ggated(8) 。
要在客户端机器上访问导出的设备,首先使用 ggatec 指定服务器的 IP 地址和导出设备的设备名称。如果成功,该命令将显示一个要挂载的 ggate 设备名称。将指定的设备名称挂载到一个空闲的挂载点上。此示例连接到 192.168.1.1 上的 /dev/da0s4d 分区,然后将 /dev/ggate0 挂载到 /mnt 上:
# ggatec create -o rw 192.168.1.1 /dev/da0s4d
ggate0
# mount /dev/ggate0 /mnt现在可以通过客户端上的 /mnt 访问服务器上的设备。有关 ggatec 的更多详细信息和一些使用示例,请参阅 ggatec(8) 。
|
如果设备当前已在服务器或网络上的任何其他客户端上挂载,则挂载将失败。如果需要同时访问网络资源,请使用 NFS 。 |
当设备不再需要时,使用 umount 命令卸载它,以便资源可以供其他客户端使用。
21.7. 标记磁盘设备
在系统初始化过程中, FreeBSD 内核会在发现设备时创建设备节点。这种探测设备的方法会引发一些问题。例如,如果通过 USB 添加了一个新的磁盘设备,那么很可能会将一个闪存设备分配为 da0 的设备名称,而原来的 da0 则会变成 da1 。这将导致挂载文件系统时出现问题,如果这些文件系统在 /etc/fstab 中列出,可能还会阻止系统启动。
一种解决方案是按顺序连接 SCSI 设备,这样添加到 SCSI 卡的新设备将被分配未使用的设备号。但是对于可能替换主要 SCSI 磁盘的 USB 设备怎么办?这是因为 USB 设备通常在 SCSI 卡之前进行探测。一种解决方案是在系统启动后再插入这些设备。另一种方法是只使用单个 ATA 驱动器,并且在 /etc/fstab 中不列出 SCSI 设备。
更好的解决方案是使用 glabel 为磁盘设备添加标签,并在 /etc/fstab 中使用这些标签。由于 glabel 将标签存储在给定提供者的最后一个扇区中,因此标签将在重新启动后保持持久。通过将此标签作为设备,文件系统可以始终被挂载,无论通过哪个设备节点进行访问。
|
|
21.7.1. 标签类型和示例
永久标签可以是通用标签或文件系统标签。可以使用 tunefs(8) 或 newfs(8) 创建永久文件系统标签。这些类型的标签将在 /dev 的子目录中创建,并根据文件系统类型进行命名。例如, UFS2 文件系统标签将在 /dev/ufs 中创建。可以使用 glabel label 创建通用永久标签。这些标签不特定于文件系统,并将在 /dev/label 中创建。
临时标签在下次重启时被销毁。这些标签是在 [/dev/label] 中创建的,适用于实验。可以使用 glabel create 命令创建临时标签。
要为 UFS2 文件系统创建一个永久标签而不破坏任何数据,请执行以下命令:
# tunefs -L home /dev/da3现在应该在 /dev/ufs 中存在一个标签,可以将其添加到 /etc/fstab 中:
/dev/ufs/home /home ufs rw 2 2
|
在尝试运行 |
现在可以挂载文件系统了:
# mount /home从这一点开始,只要在启动时加载了 geom_label.ko 内核模块,并且在 /boot/loader.conf 中或者存在 GEOM_LABEL 内核选项,设备节点可以在不对系统产生任何不良影响的情况下发生变化。
使用 newfs 命令和 -L 选项可以创建带有默认标签的文件系统。有关更多信息,请参阅 newfs(8) 。
可以使用以下命令来销毁标签:
# glabel destroy home下面的示例展示了如何为引导磁盘的分区添加标签。
例 32. 在引导磁盘上标记分区
通过对引导磁盘上的分区进行永久标记,即使将磁盘移动到另一个控制器或转移到不同的系统,系统也应能够继续正常引导。对于本示例,假设使用单个 ATA 磁盘,系统当前将其识别为 ad0 。还假设使用标准的 FreeBSD 分区方案,包括 / 、 /var 、 /usr 和 /tmp ,以及一个交换分区。
重新启动系统,在 loader(8) 提示符下,按下 4 键进入单用户模式。然后输入以下命令:
# glabel label rootfs /dev/ad0s1a
GEOM_LABEL: Label for provider /dev/ad0s1a is label/rootfs
# glabel label var /dev/ad0s1d
GEOM_LABEL: Label for provider /dev/ad0s1d is label/var
# glabel label usr /dev/ad0s1f
GEOM_LABEL: Label for provider /dev/ad0s1f is label/usr
# glabel label tmp /dev/ad0s1e
GEOM_LABEL: Label for provider /dev/ad0s1e is label/tmp
# glabel label swap /dev/ad0s1b
GEOM_LABEL: Label for provider /dev/ad0s1b is label/swap
# exit系统将继续进行多用户引导。引导完成后,编辑 [/etc/fstab] 文件,并用相应的标签替换传统设备名称。最终的 [/etc/fstab] 文件将如下所示:
# Device Mountpoint FStype Options Dump Pass# /dev/label/swap none swap sw 0 0 /dev/label/rootfs / ufs rw 1 1 /dev/label/tmp /tmp ufs rw 2 2 /dev/label/usr /usr ufs rw 2 2 /dev/label/var /var ufs rw 2 2
系统现在可以重新启动。如果一切顺利,它将正常启动,并且 mount 命令将显示:
# mount
/dev/label/rootfs on / (ufs, local)
devfs on /dev (devfs, local)
/dev/label/tmp on /tmp (ufs, local, soft-updates)
/dev/label/usr on /usr (ufs, local, soft-updates)
/dev/label/var on /var (ufs, local, soft-updates)glabel(8) 类支持基于唯一文件系统 id ufsid 的 UFS 文件系统的标签类型。这些标签可以在 /dev/ufsid 中找到,并在系统启动时自动创建。可以使用 ufsid 标签来使用 /etc/fstab 挂载分区。使用 glabel status 命令可以获取文件系统及其对应的 ufsid 标签列表。
% glabel status
Name Status Components
ufsid/486b6fc38d330916 N/A ad4s1d
ufsid/486b6fc16926168e N/A ad4s1f在上面的示例中, ad4s1d 表示 /var ,而 ad4s1f 表示 /usr 。使用所示的 ufsid 值,可以使用以下条目在 /etc/fstab 中挂载这些分区:
/dev/ufsid/486b6fc38d330916 /var ufs rw 2 2 /dev/ufsid/486b6fc16926168e /usr ufs rw 2 2
任何带有 ufsid 标签的分区都可以通过这种方式挂载,无需手动创建永久标签,同时仍然可以享受设备名称无关挂载的好处。
21.8. 通过 GEOM 实现的 UFS 日志记录
在 FreeBSD 上,支持 UFS 文件系统的日志功能。该实现通过 GEOM 子系统提供,并使用 gjournal 进行配置。与其他文件系统日志实现不同, gjournal 方法是基于块的,而不是作为文件系统的一部分实现的。它是一个 GEOM 扩展。
日志记录存储了文件系统事务的日志,例如在元数据和文件写入到磁盘之前构成完整磁盘写入操作的更改。可以通过重新播放事务日志来重做文件系统事务,以防止文件系统不一致性。
这种方法提供了另一种机制来防止文件系统的数据丢失和不一致性。与跟踪和强制执行元数据更新的软更新以及创建文件系统镜像的快照不同,日志是专门用于此任务的磁盘空间中存储的。为了提高性能,日志可以存储在另一个磁盘上。在这种配置中,应该在要启用日志记录的设备之后列出日志提供者或存储设备。
GENERIC 内核提供对 gjournal 的支持。要在启动时自动加载 geom_journal.ko 内核模块,请将以下行添加到 /boot/loader.conf 文件中:
geom_journal_load="YES"
如果使用自定义内核,请确保以下行在内核配置文件中:
options GEOM_JOURNAL
一旦模块加载完成,可以按照以下步骤在新的文件系统上创建一个日志。在这个例子中, da4 是一个新的 SCSI 磁盘:
# gjournal load
# gjournal label /dev/da4这将加载模块并在 /dev/da4 上创建一个设备节点 /dev/da4.journal 。
现在可以在日志设备上创建 UFS 文件系统,然后将其挂载到现有的挂载点上:
# newfs -O 2 -J /dev/da4.journal
# mount /dev/da4.journal /mnt|
在多个切片的情况下,将为每个单独的切片创建一个日志。例如,如果 ad4s1 和 ad4s2 都是切片,那么 |
可以使用 tunefs 在当前文件系统上启用日志记录。然而,在尝试更改现有文件系统之前, 一定要 先备份数据。在大多数情况下,如果无法创建日志, gjournal 将失败,但这并不能保护免受错误使用 tunefs 导致的数据丢失。有关这些命令的更多信息,请参阅 gjournal(8) 和 tunefs(8) 。
可以对 FreeBSD 系统的引导磁盘进行日志记录。有关详细说明,请参阅文章《在桌面 PC 上实现 UFS 日志记录》( extref:https://docs.freebsd.org/en/articles/gjournal-desktop/ )。
Chapter 22. Z 文件系统(ZFS)
ZFS 是一种先进的文件系统,旨在解决以前存储子系统软件中存在的主要问题。
最初由 Sun™ 开发,持续的开源 ZFS 开发已经转移到了 OpenZFS 项目。
ZFS 有三个主要的设计目标:
完整的功能和术语列表请参见 ZFS 功能和术语。
22.1. ZFS 有何不同之处
ZFS 不仅仅是一个文件系统,它在根本上与传统的文件系统有所不同。将卷管理器和文件系统的传统分离角色结合起来,为 ZFS 提供了独特的优势。文件系统现在能够意识到底层磁盘的结构。传统的文件系统一次只能存在于单个磁盘上。如果有两个磁盘,那么就需要创建两个单独的文件系统。传统的硬件 RAID 配置通过将操作系统呈现为由物理磁盘提供的空间组成的单个逻辑磁盘来避免这个问题,操作系统在其上放置一个文件系统。即使使用像 GEOM 提供的软件 RAID 解决方案,位于 RAID 之上的 UFS 文件系统也认为它正在处理一个单一设备。 ZFS 的卷管理器和文件系统的组合解决了这个问题,并允许创建共享可用存储池的文件系统。 ZFS 意识到物理磁盘布局的一个重要优势是,当向池中添加额外的磁盘时,现有的文件系统会自动增长。然后,这个新空间就可以供文件系统使用。 ZFS 还可以为每个文件系统应用不同的属性。这使得创建单独的文件系统和数据集比创建单个的整体文件系统更有用。
22.2. 快速入门指南
FreeBSD 可以在系统初始化期间挂载 ZFS 池和数据集。要启用它,请将以下行添加到 /etc/rc.conf: 文件中:
zfs_enable="YES"
然后启动服务:
# service zfs start本节中的示例假设有三个 SCSI 磁盘,设备名称分别为 da0、da1 和 da2 。使用 SATA 硬件的用户应该使用 ada 设备名称。
22.2.1. 单磁盘池
要使用单个磁盘设备创建一个简单且非冗余的池,请按以下步骤操作:
# zpool create example /dev/da0要查看新的存储池,请查看 df 命令的输出:
# df
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/ad0s1a 2026030 235230 1628718 13% /
devfs 1 1 0 100% /dev
/dev/ad0s1d 54098308 1032846 48737598 2% /usr
example 17547136 0 17547136 0% /example这个输出显示了创建和挂载 example 池,并且现在可以作为文件系统访问。为用户创建文件以供浏览:
# cd /example
# ls
# touch testfile
# ls -al
total 4
drwxr-xr-x 2 root wheel 3 Aug 29 23:15 .
drwxr-xr-x 21 root wheel 512 Aug 29 23:12 ..
-rw-r--r-- 1 root wheel 0 Aug 29 23:15 testfile此池尚未使用任何高级的 ZFS 功能和属性。要在此池上创建启用了压缩的数据集,请执行以下操作:
# zfs create example/compressed
# zfs set compression=gzip example/compressedexample/compressed 数据集现在是一个 ZFS 压缩文件系统。尝试将一些大文件复制到 /example/compressed。
禁用压缩功能:
# zfs set compression=off example/compressed要卸载文件系统,请使用 zfs umount 命令,然后使用 df 命令进行验证:
# zfs umount example/compressed
# df
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/ad0s1a 2026030 235232 1628716 13% /
devfs 1 1 0 100% /dev
/dev/ad0s1d 54098308 1032864 48737580 2% /usr
example 17547008 0 17547008 0% /example要重新挂载文件系统以使其再次可访问,请使用 zfs mount 命令,并使用 df 命令进行验证:
# zfs mount example/compressed
# df
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/ad0s1a 2026030 235234 1628714 13% /
devfs 1 1 0 100% /dev
/dev/ad0s1d 54098308 1032864 48737580 2% /usr
example 17547008 0 17547008 0% /example
example/compressed 17547008 0 17547008 0% /example/compressed运行 mount 命令会显示池和文件系统:
# mount
/dev/ad0s1a on / (ufs, local)
devfs on /dev (devfs, local)
/dev/ad0s1d on /usr (ufs, local, soft-updates)
example on /example (zfs, local)
example/compressed on /example/compressed (zfs, local)创建后,可以像任何文件系统一样使用 ZFS 数据集。根据需要,可以在每个数据集上设置其他可用的功能。下面的示例创建了一个名为 data 的新文件系统。它假设该文件系统包含重要文件,并将其配置为存储每个数据块的两个副本。
# zfs create example/data
# zfs set copies=2 example/data使用 df 命令查看数据和空间使用情况:
# df
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/ad0s1a 2026030 235234 1628714 13% /
devfs 1 1 0 100% /dev
/dev/ad0s1d 54098308 1032864 48737580 2% /usr
example 17547008 0 17547008 0% /example
example/compressed 17547008 0 17547008 0% /example/compressed
example/data 17547008 0 17547008 0% /example/data请注意,池中的所有文件系统都具有相同的可用空间。在这些示例中使用 df 命令显示,文件系统使用它们所需的空间,并且都从同一个池中获取。 ZFS 摒弃了卷和分区等概念,允许多个文件系统共享同一个池。
销毁不再需要的文件系统和池:
# zfs destroy example/compressed
# zfs destroy example/data
# zpool destroy example22.2.2. RAID-Z
磁盘会出现故障。避免因磁盘故障导致数据丢失的一种方法是使用 RAID。ZFS 在其存储池设计中支持此功能。 RAID-Z 存储池需要三个或更多的磁盘,但提供比镜像存储池更多的可用空间。
这个示例创建了一个 RAID-Z 池,指定要添加到池中的磁盘:
# zpool create storage raidz da0 da1 da2|
Sun™ 建议在 RAID-Z 配置中使用的设备数量应在三到九之间。对于需要由 10 个或更多磁盘组成的单个池的环境,考虑将其分成较小的 RAID-Z 组。如果有两个磁盘可用,可以使用 ZFS 镜像提供冗余性(如果需要)。有关更多详细信息,请参阅 zpool(8)。 |
前面的示例创建了名为 storage 的 zpool 。这个示例在该池中创建了一个名为 home 的新文件系统:
# zfs create storage/home启用压缩并存储目录和文件的额外副本:
# zfs set copies=2 storage/home
# zfs set compression=gzip storage/home要将此目录设置为用户的新家目录,请将用户数据复制到此目录并创建相应的符号链接:
# cp -rp /home/* /storage/home
# rm -rf /home /usr/home
# ln -s /storage/home /home
# ln -s /storage/home /usr/home用户数据现在存储在新创建的 /storage/home 上。通过添加一个新用户并以该用户身份登录来进行测试。
创建一个文件系统快照,以便以后可以回滚:
# zfs snapshot storage/home@08-30-08ZFS 创建数据集的快照,而不是单个目录或文件。
@ 字符是文件系统名称或卷名称之间的分隔符。在删除重要目录之前,先备份文件系统,然后回滚到一个早期的快照,其中目录仍然存在:
# zfs rollback storage/home@08-30-08要列出所有可用的快照,请在文件系统的 .zfs/snapshot 目录中运行 ls 命令。例如,要查看已拍摄的快照:
# ls /storage/home/.zfs/snapshot编写一个脚本来定期对用户数据进行快照。随着时间的推移,快照可能会占用大量的磁盘空间。使用以下命令删除先前的快照:
# zfs destroy storage/home@08-30-08经过测试,使用以下命令将 /storage/home 设置为真实的 /home:
# zfs set mountpoint=/home storage/home运行 df 和 mount 命令来确认系统现在将文件系统视为真实的 /home :
# mount
/dev/ad0s1a on / (ufs, local)
devfs on /dev (devfs, local)
/dev/ad0s1d on /usr (ufs, local, soft-updates)
storage on /storage (zfs, local)
storage/home on /home (zfs, local)
# df
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/ad0s1a 2026030 235240 1628708 13% /
devfs 1 1 0 100% /dev
/dev/ad0s1d 54098308 1032826 48737618 2% /usr
storage 26320512 0 26320512 0% /storage
storage/home 26320512 0 26320512 0% /home这样就完成了 RAID-Z 的配置。通过将以下行添加到 /etc/periodic.conf ,可以将关于创建的文件系统的每日状态更新添加到夜间的 periodic(8) 运行中:
daily_status_zfs_enable="YES"
22.2.3. 恢复 RAID-Z
每个软件 RAID 都有一种监控其 state 的方法。使用以下命令查看 RAID-Z 设备的状态:
# zpool status -x如果所有池都处于 在线 状态,并且一切正常,消息将显示:
all pools are healthy如果出现问题,比如磁盘处于 离线 状态,池的状态将如下所示:
pool: storage
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
storage DEGRADED 0 0 0
raidz1 DEGRADED 0 0 0
da0 ONLINE 0 0 0
da1 OFFLINE 0 0 0
da2 ONLINE 0 0 0
errors: No known data errors"OFFLINE"显示管理员使用以下方式将 da1 下线:
# zpool offline storage da1立即关闭计算机并更换 da1。重新启动计算机并将 da1 返回到池中:
# zpool replace storage da1接下来,再次检查状态,这次不使用 -x 选项以显示所有的池:
# zpool status storage
pool: storage
state: ONLINE
scrub: resilver completed with 0 errors on Sat Aug 30 19:44:11 2008
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz1 ONLINE 0 0 0
da0 ONLINE 0 0 0
da1 ONLINE 0 0 0
da2 ONLINE 0 0 0
errors: No known data errors在这个例子中,一切都正常。
22.2.4. 数据验证
ZFS 使用校验和来验证存储数据的完整性。创建文件系统时会自动启用校验和功能。
|
禁用校验和是可以的,但 不推荐 !校验和占用很少的存储空间,并提供数据完整性。大多数 ZFS 功能在禁用校验和的情况下将无法正常工作。禁用这些校验和不会明显提高性能。 |
验证数据校验和(称为 scrubbing )可以确保 storage 池的完整性,具体操作如下:
# zpool scrub storage一个 scrub 的持续时间取决于存储的数据量。数据量越大,验证所需的时间就越长。由于 scrub 是 I/O 密集型操作, ZFS 只允许同时运行一个 scrub。在 scrub 完成后,可以使用 zpool status 命令查看状态。
# zpool status storage
pool: storage
state: ONLINE
scrub: scrub completed with 0 errors on Sat Jan 26 19:57:37 2013
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz1 ONLINE 0 0 0
da0 ONLINE 0 0 0
da1 ONLINE 0 0 0
da2 ONLINE 0 0 0
errors: No known data errors显示最后一次清 scrub 的完成日期有助于决定何时开始下一次 scrub。例行 scrub 有助于保护数据免受静默损坏,并确保池的完整性。
22.3. zpool 管理
22.3.1. 创建和销毁存储池
创建一个 ZFS 存储池需要做出永久性的决策,因为在创建后无法更改池的结构。最重要的决策是将物理磁盘分组成哪种类型的 vdev 。有关可能选项的详细信息,请参阅 vdev 类型 列表。创建池后,大多数 vdev 类型不允许向 vdev 添加磁盘。例外情况是镜像,它允许向 vdev 添加新磁盘,并且条带可以通过将新磁盘附加到 vdev 来升级为镜像。虽然添加新的 vdev 可以扩展池,但池的布局在创建后无法更改。取而代之的是备份数据,销毁池,然后重新创建池。
创建一个简单的镜像池:
# zpool create mypool mirror /dev/ada1 /dev/ada2
# zpool status
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
errors: No known data errors要使用单个命令创建多个 vdev ,请使用以 vdev 类型关键字 mirror 分隔的磁盘组。
# zpool create mypool mirror /dev/ada1 /dev/ada2 mirror /dev/ada3 /dev/ada4
# zpool status
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada3 ONLINE 0 0 0
ada4 ONLINE 0 0 0
errors: No known data errors池还可以使用分区而不是整个磁盘。将 ZFS 放在单独的分区中可以使同一磁盘具有其他用途的分区。特别是,它允许添加带有引导代码和用于引导的文件系统的分区。这样就可以从同时也是池成员的磁盘启动。在 FreeBSD 上,使用分区而不是整个磁盘时, ZFS 不会带来性能损失。使用分区还允许管理员对磁盘进行“欠配置”,使用不到全部容量。如果将来替换的磁盘与原始磁盘的名义大小相同,但实际容量略小,较小的分区仍将适应替换磁盘。
使用分区创建一个 RAID-Z2 池:
# zpool create mypool raidz2 /dev/ada0p3 /dev/ada1p3 /dev/ada2p3 /dev/ada3p3 /dev/ada4p3 /dev/ada5p3
# zpool status
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
ada3p3 ONLINE 0 0 0
ada4p3 ONLINE 0 0 0
ada5p3 ONLINE 0 0 0
errors: No known data errors销毁一个不再需要的池以重用磁盘。销毁池需要先卸载该池中的文件系统。如果有任何数据集正在使用中,卸载操作将失败,不会销毁池。可以使用 -f 强制销毁池。这可能会导致应用程序中对这些数据集有打开文件的未定义行为。
22.3.2. 添加和移除设备
有两种方法可以将磁盘添加到池中:使用 zpool attach 将磁盘附加到现有的 vdev 上,或者使用 zpool add 将 vdev 添加到池中。一些 vdev 类型 允许在创建后向 vdev 添加磁盘。
使用单个磁盘创建的池缺乏冗余性。它可以检测到损坏,但无法修复,因为没有其他数据的副本。 副本 属性可以从小故障(如坏扇区)中恢复,但不提供与镜像或 RAID-Z 相同级别的保护。从由单个磁盘 vdev 组成的池开始,使用 zpool attach 将新磁盘添加到 vdev 中,创建镜像。还可以使用 zpool attach 将新磁盘添加到镜像组,增加冗余性和读取性能。在为池分区的磁盘上,将第一个磁盘的布局复制到第二个磁盘上。使用 gpart backup 和 gpart restore 可以使这个过程更容易。
通过连接 ada0p3,将单个磁盘(条带)vdev ada1p3 升级为镜像:
# zpool status
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
errors: No known data errors
# zpool attach mypool ada0p3 ada1p3
Make sure to wait until resilvering finishes before rebooting.
If you boot from pool 'mypool', you may need to update boot code on newly attached disk _ada1p3_.
Assuming you use GPT partitioning and _da0_ is your new boot disk you may use the following command:
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da0
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada1
bootcode written to ada1
# zpool status
pool: mypool
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Fri May 30 08:19:19 2014
527M scanned out of 781M at 47.9M/s, 0h0m to go
527M resilvered, 67.53% done
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0 (resilvering)
errors: No known data errors
# zpool status
pool: mypool
state: ONLINE
scan: resilvered 781M in 0h0m with 0 errors on Fri May 30 08:15:58 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
errors: No known data errors当无法将磁盘添加到现有的 vdev 时,例如对于 RAID-Z ,一种替代方法是向池中添加另一个 vdev 。添加 vdev 可以通过在 vdev 之间分布写操作来提供更高的性能。每个 vdev 都提供自己的冗余性。可以混合使用 mirror 和 RAID-Z 等不同类型的 vdev ,但不建议这样做。向包含镜像或 RAID-Z vdev 的池中添加一个非冗余的 vdev 会对整个池中的数据造成风险。分布写操作意味着非冗余磁盘的故障将导致丢失对池中每个块的一部分数据。
ZFS 将数据跨越每个 vdev 进行条带化。例如,使用两个镜像 vdev ,这实际上是一个 RAID 10,将写操作跨越两组镜像。ZFS 分配空间以使每个 vdev 在同一时间达到 100 %的使用率。如果 vdev 具有不同数量的可用空间,性能将降低,因为更多的数据写入将发送到使用率较低的 vdev。
在将新设备连接到引导池时,请记得更新引导代码。
将第二个镜像组(ada2p3 和 ada3p3)附加到现有的镜像中:
# zpool status
pool: mypool
state: ONLINE
scan: resilvered 781M in 0h0m with 0 errors on Fri May 30 08:19:35 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
errors: No known data errors
# zpool add mypool mirror ada2p3 ada3p3
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada2
bootcode written to ada2
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada3
bootcode written to ada3
# zpool status
pool: mypool
state: ONLINE
scan: scrub repaired 0 in 0h0m with 0 errors on Fri May 30 08:29:51 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
ada3p3 ONLINE 0 0 0
errors: No known data errors从池中删除 vdev 是不可能的,如果剩余的冗余足够,从镜像中删除磁盘是独占的。如果镜像组中只剩下一个磁盘,该组将不再是镜像,而变成条带,如果该剩余磁盘故障,将会危及整个池。
从三路镜像组中移除一个磁盘:
# zpool status
pool: mypool
state: ONLINE
scan: scrub repaired 0 in 0h0m with 0 errors on Fri May 30 08:29:51 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
errors: No known data errors
# zpool detach mypool ada2p3
# zpool status
pool: mypool
state: ONLINE
scan: scrub repaired 0 in 0h0m with 0 errors on Fri May 30 08:29:51 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
errors: No known data errors22.3.3. 检查池的状态
池状态非常重要。如果驱动器离线或 ZFS 检测到读取、写入或校验错误,相应的错误计数会增加。status 输出显示了池中每个设备的配置和状态,以及整个池的状态。还显示了要采取的操作和有关上次 scrub 的详细信息。
# zpool status
pool: mypool
state: ONLINE
scan: scrub repaired 0 in 2h25m with 0 errors on Sat Sep 14 04:25:50 2013
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
ada3p3 ONLINE 0 0 0
ada4p3 ONLINE 0 0 0
ada5p3 ONLINE 0 0 0
errors: No known data errors22.3.4. 清除错误
当检测到错误时,ZFS 会增加读取、写入或校验和错误计数。使用 zpool clear mypool 命令清除错误消息并重置计数。清除错误状态对于自动化脚本非常重要,这些脚本在池遇到错误时会通知管理员。如果不清除旧错误,这些脚本可能无法报告后续的错误。
22.3.5. 替换一个正常工作的设备
可能需要用不同的磁盘替换一个磁盘。当替换一个工作中的磁盘时,该过程会在替换期间保持旧磁盘在线。池永远不会进入 降级 状态,从而降低数据丢失的风险。运行 zpool replace 命令将数据从旧磁盘复制到新磁盘。操作完成后, ZFS 会将旧磁盘与 vdev 断开连接。如果新磁盘比旧磁盘大,可能可以使用新空间来扩展 zpool 。请参见 扩展池 。
替换池中的一个正常工作设备:
# zpool status
pool: mypool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
errors: No known data errors
# zpool replace mypool ada1p3 ada2p3
Make sure to wait until resilvering finishes before rebooting.
When booting from the pool 'zroot', update the boot code on the newly attached disk 'ada2p3'.
Assuming GPT partitioning is used and [.filename]#da0# is the new boot disk, use the following command:
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da0
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada2
# zpool status
pool: mypool
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Jun 2 14:21:35 2014
604M scanned out of 781M at 46.5M/s, 0h0m to go
604M resilvered, 77.39% done
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
replacing-1 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0 (resilvering)
errors: No known data errors
# zpool status
pool: mypool
state: ONLINE
scan: resilvered 781M in 0h0m with 0 errors on Mon Jun 2 14:21:52 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
errors: No known data errors22.3.6. 处理故障设备
当池中的磁盘发生故障时,该磁盘所属的 vdev 将进入 降级 状态。数据仍然可用,但性能降低,因为 ZFS 会通过可用的冗余计算缺失的数据。为了将 vdev 恢复到完全功能状态,需要替换故障的物理设备。然后,ZFS 会开始 重建 操作。ZFS 会通过可用的冗余重新计算故障设备上的数据,并将其写入替代设备。完成后,vdev 将返回 在线 状态。
如果 vdev 没有任何冗余,或者设备已经损坏且没有足够的冗余来弥补,那么存储池将进入 故障 状态。除非有足够的设备重新连接存储池,否则存储池将无法运行,需要从备份中恢复数据。
当替换一个故障磁盘时,故障磁盘的名称会变为新磁盘的 GUID。如果替换设备具有相同的设备名称,则不需要为 zpool replace 指定新的设备名称参数。
使用 zpool replace 命令替换故障的磁盘:
# zpool status
pool: mypool
state: DEGRADED
status: One or more devices could not be opened. Sufficient replicas exist for
the pool to continue functioning in a degraded state.
action: Attach the missing device and online it using 'zpool online'.
see: http://illumos.org/msg/ZFS-8000-2Q
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
ada0p3 ONLINE 0 0 0
316502962686821739 UNAVAIL 0 0 0 was /dev/ada1p3
errors: No known data errors
# zpool replace mypool 316502962686821739 ada2p3
# zpool status
pool: mypool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Jun 2 14:52:21 2014
641M scanned out of 781M at 49.3M/s, 0h0m to go
640M resilvered, 82.04% done
config:
NAME STATE READ WRITE CKSUM
mypool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
ada0p3 ONLINE 0 0 0
replacing-1 UNAVAIL 0 0 0
15732067398082357289 UNAVAIL 0 0 0 was /dev/ada1p3/old
ada2p3 ONLINE 0 0 0 (resilvering)
errors: No known data errors
# zpool status
pool: mypool
state: ONLINE
scan: resilvered 781M in 0h0m with 0 errors on Mon Jun 2 14:52:38 2014
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
errors: No known data errors22.3.7. Scrubbing 池
定期对池进行 scrub 操作,最好每个月至少一次。scrub 操作对磁盘的使用较高,运行时会降低性能。在安排 scrub 操作时避免高负载时段,或者使用 vfs.zfs.scrub_delay 来调整 scrub 操作的相对优先级,以防止其影响其他工作负载的速度。
# zpool scrub mypool
# zpool status
pool: mypool
state: ONLINE
scan: scrub in progress since Wed Feb 19 20:52:54 2014
116G scanned out of 8.60T at 649M/s, 3h48m to go
0 repaired, 1.32% done
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ada0p3 ONLINE 0 0 0
ada1p3 ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
ada3p3 ONLINE 0 0 0
ada4p3 ONLINE 0 0 0
ada5p3 ONLINE 0 0 0
errors: No known data errors如果需要取消一个 scrub 操作,请运行 zpool scrub -s mypool 。
22.3.8. 自我修复
存储在数据块中的校验和使文件系统能够自我修复。这个功能会自动修复数据,如果其校验和与存储池中另一个设备上记录的校验和不匹配。例如,一个具有两个磁盘的镜像配置,其中一个驱动器开始出现故障,无法正确存储数据。当数据长时间未被访问时,如长期存档存储,情况会更糟。传统的文件系统需要运行检查和修复数据的命令,如 fsck(8)。这些命令需要时间,在严重情况下,管理员必须决定执行哪个修复操作。当 ZFS 检测到一个数据块的校验和不匹配时,它会尝试从镜像磁盘中读取数据。如果该磁盘能提供正确的数据, ZFS 将将其提供给应用程序,并纠正具有错误校验和的磁盘上的数据。在正常存储池操作期间,这一切都在没有任何系统管理员干预的情况下发生。
下一个示例通过创建一个镜像磁盘池来展示这种自我修复行为,其中包括 /dev/ada0 和 /dev/ada1。
# zpool create healer mirror /dev/ada0 /dev/ada1
# zpool status healer
pool: healer
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
healer ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
errors: No known data errors
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
healer 960M 92.5K 960M - - 0% 0% 1.00x ONLINE -将一些重要数据复制到池中,以使用自我修复功能保护免受数据错误,并为池创建校验和以备后续比较。
# cp /some/important/data /healer
# zfs list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
healer 960M 67.7M 892M 7% 1.00x ONLINE -
# sha1 /healer > checksum.txt
# cat checksum.txt
SHA1 (/healer) = 2753eff56d77d9a536ece6694bf0a82740344d1f通过向镜像中的一个磁盘的开头写入随机数据来模拟数据损坏。为了防止 ZFS 在检测到数据损坏时修复数据,可以在损坏之前导出池,并在之后重新导入。
|
这是一个危险的操作,可能会破坏重要数据,仅用于演示目的。在存储池的正常运行期间,请 不要尝试 执行此操作。此意外损坏示例也不应在任何使用 ZFS 以外的文件系统的磁盘上运行,该磁盘上的另一个分区中也不应该有 ZFS 。请不要使用除了存储池中的设备名称之外的任何其他磁盘设备名称。确保存储池有适当的备份,并在执行命令之前对其进行测试! |
# zpool export healer
# dd if=/dev/random of=/dev/ada1 bs=1m count=200
200+0 records in
200+0 records out
209715200 bytes transferred in 62.992162 secs (3329227 bytes/sec)
# zpool import healer池状态显示一个设备发生了错误。请注意,从池中读取数据的应用程序没有接收到任何错误数据。ZFS 从 ada0 设备提供了正确校验和的数据。要找到校验和错误的设备,请查找 CKSUM 列中包含非零值的设备。
# zpool status healer
pool: healer
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://illumos.org/msg/ZFS-8000-4J
scan: none requested
config:
NAME STATE READ WRITE CKSUM
healer ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 1
errors: No known data errorsZFS 检测到错误,并通过使用未受影响的 ada0 镜像磁盘中的冗余来处理该错误。通过与原始数据进行校验比较,可以确定池是否恢复一致。
# sha1 /healer >> checksum.txt
# cat checksum.txt
SHA1 (/healer) = 2753eff56d77d9a536ece6694bf0a82740344d1f
SHA1 (/healer) = 2753eff56d77d9a536ece6694bf0a82740344d1f在故意篡改之前和之后生成校验和,同时池数据仍然匹配。这显示了当校验和不同时, ZFS 能够自动检测和纠正任何错误。请注意,这需要池中具有足够的冗余。由单个设备组成的池没有自我修复能力。这也是为什么在 ZFS 中校验和如此重要的原因;不要出于任何原因禁用它们。 ZFS 不需要 fsck(8) 或类似的文件系统一致性检查程序来检测和纠正这个问题,并且在出现问题时保持池可用。现在需要进行一次 scrub 操作来覆盖在 ada1 上的损坏数据。
# zpool scrub healer
# zpool status healer
pool: healer
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://illumos.org/msg/ZFS-8000-4J
scan: scrub in progress since Mon Dec 10 12:23:30 2012
10.4M scanned out of 67.0M at 267K/s, 0h3m to go
9.63M repaired, 15.56% done
config:
NAME STATE READ WRITE CKSUM
healer ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 627 (repairing)
errors: No known data errorsScrub 操作从 ada0 读取数据,并将任何具有错误校验和的数据重写到 ada1 上,这可以通过 zpool status 中的 (repairing) 输出来显示。操作完成后,池的状态将发生变化:
# zpool status healer
pool: healer
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://illumos.org/msg/ZFS-8000-4J
scan: scrub repaired 66.5M in 0h2m with 0 errors on Mon Dec 10 12:26:25 2012
config:
NAME STATE READ WRITE CKSUM
healer ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 2.72K
errors: No known data errors在从 ada0 同步所有数据到 ada1 后,完成了 清洗 操作,请通过运行 zpool clear 命令清除池状态中的错误消息。
# zpool clear healer
# zpool status healer
pool: healer
state: ONLINE
scan: scrub repaired 66.5M in 0h2m with 0 errors on Mon Dec 10 12:26:25 2012
config:
NAME STATE READ WRITE CKSUM
healer ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
errors: No known data errors现在,池已经恢复到完全正常的状态,所有错误计数都为零。
22.3.9. 扩展池
每个 vdev 中最小的设备限制了冗余池的可用大小。用一个更大的设备替换最小的设备。在完成 替换 或 重建 操作后,池可以扩展到使用新设备的容量。例如,考虑一个由 1 TB 驱动器和 2 TB 驱动器组成的镜像。可用空间为 1 TB 。当用另一个 2 TB 驱动器替换 1 TB 驱动器时,重新同步过程将现有数据复制到新驱动器上。由于两个设备现在都具有 2 TB 的容量,镜像的可用空间增长到 2 TB。
通过在每个设备上使用 zpool online -e 来开始扩展。在扩展所有设备之后,额外的空间将可用于池。
22.3.10. 导入和导出存储池
在将存储池移动到另一个系统之前,请先 导出(export) 它们。 ZFS 会卸载所有数据集,并将每个设备标记为已导出,但仍然锁定以防止其他磁盘使用。这使得存储池可以在其他支持 ZFS 的机器、其他操作系统甚至不同的硬件架构上导入(有一些注意事项,请参阅 zpool(8))。当数据集有打开的文件时,请使用 zpool export -f 强制导出存储池。请谨慎使用此功能。数据集将被强制卸载,可能导致那些数据集上有打开文件的应用程序出现意外行为。
导出一个未使用的池:
# zpool export mypool导入一个存储池会自动挂载数据集。如果不希望出现这种行为,请使用 zpool import -N 来阻止它。 zpool import -o 为此特定导入设置临时属性。zpool import altroot= 允许使用基本挂载点而不是文件系统的根来导入存储池。如果该存储池最后在另一个系统上使用并且没有正确导出,请使用 zpool import -f 来强制导入。zpool import -a 导入所有未被其他系统使用的存储池。
列出所有可导入的池:
# zpool import
pool: mypool
id: 9930174748043525076
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
mypool ONLINE
ada2p3 ONLINE导入具有替代根目录的池:
# zpool import -o altroot=/mnt mypool
# zfs list
zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 110K 47.0G 31K /mnt/mypool22.3.11. 升级存储池
在升级 FreeBSD 之后,或者从使用较旧版本的系统导入池时,需要手动将池升级到最新的 ZFS 版本以支持新功能。在升级之前,请考虑池是否可能需要在较旧的系统上导入。升级是一个单向过程。升级较旧的池是可能的,但是无法降级具有较新功能的池。
将 v28 池升级以支持 Feature Flags。
# zpool status
pool: mypool
state: ONLINE
status: The pool is formatted using a legacy on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on software that does not support feat
flags.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
errors: No known data errors
# zpool upgrade
This system supports ZFS pool feature flags.
The following pools are formatted with legacy version numbers and are upgraded to use feature flags.
After being upgraded, these pools will no longer be accessible by software that does not support feature flags.
VER POOL
--- ------------
28 mypool
Use 'zpool upgrade -v' for a list of available legacy versions.
Every feature flags pool has all supported features enabled.
# zpool upgrade mypool
This system supports ZFS pool feature flags.
Successfully upgraded 'mypool' from version 28 to feature flags.
Enabled the following features on 'mypool':
async_destroy
empty_bpobj
lz4_compress
multi_vdev_crash_dump只有在完成 zpool upgrade 之后,ZFS 的新功能才会可用。使用 zpool upgrade -v 命令查看升级提供的新功能,以及已经支持的功能。
升级一个池子以支持新的功能标志:
# zpool status
pool: mypool
state: ONLINE
status: Some supported features are not enabled on the pool. The pool can
still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mypool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
errors: No known data errors
# zpool upgrade
This system supports ZFS pool feature flags.
All pools are formatted using feature flags.
Some supported features are not enabled on the following pools. Once a
feature is enabled the pool may become incompatible with software
that does not support the feature. See zpool-features(7) for details.
POOL FEATURE
---------------
zstore
multi_vdev_crash_dump
spacemap_histogram
enabled_txg
hole_birth
extensible_dataset
bookmarks
filesystem_limits
# zpool upgrade mypool
This system supports ZFS pool feature flags.
Enabled the following features on 'mypool':
spacemap_histogram
enabled_txg
hole_birth
extensible_dataset
bookmarks
filesystem_limits|
更新从池中引导的系统的引导代码,以支持新的池版本。在包含引导代码的分区上使用 对于使用 GPT 的传统引导,请使用以下命令: 对于使用 EFI 引导的系统,请执行以下命令: 将引导代码应用于池中的所有可引导磁盘。有关更多信息,请参阅 gpart(8)。 |
22.3.12. 显示池的历史记录
ZFS 记录更改池的命令,包括创建数据集、更改属性或替换磁盘。查看关于池创建的历史记录很有用,还可以检查哪个用户执行了特定的操作以及何时执行的。历史记录不会保存在日志文件中,而是作为池本身的一部分。用于查看这个历史记录的命令被恰当地命名为 zpool history。
# zpool history
History for 'tank':
2013-02-26.23:02:35 zpool create tank mirror /dev/ada0 /dev/ada1
2013-02-27.18:50:58 zfs set atime=off tank
2013-02-27.18:51:09 zfs set checksum=fletcher4 tank
2013-02-27.18:51:18 zfs create tank/backup输出显示了 zpool 和 zfs 命令以某种方式修改了池,并附带了时间戳。不包括像 zfs list 这样的命令。当未指定池名称时, ZFS 会显示所有池的历史记录。
当使用选项 -i 或 -l 时,zpool history 命令可以显示更多的信息。 -i 选项会显示用户发起的事件以及内部记录的 ZFS 事件。
# zpool history -i
History for 'tank':
2013-02-26.23:02:35 [internal pool create txg:5] pool spa 28; zfs spa 28; zpl 5;uts 9.1-RELEASE 901000 amd64
2013-02-27.18:50:53 [internal property set txg:50] atime=0 dataset = 21
2013-02-27.18:50:58 zfs set atime=off tank
2013-02-27.18:51:04 [internal property set txg:53] checksum=7 dataset = 21
2013-02-27.18:51:09 zfs set checksum=fletcher4 tank
2013-02-27.18:51:13 [internal create txg:55] dataset = 39
2013-02-27.18:51:18 zfs create tank/backup通过添加 -l 来显示更多详细信息。以长格式显示历史记录,包括发出命令的用户的名称和发生更改的主机名。
# zpool history -l
History for 'tank':
2013-02-26.23:02:35 zpool create tank mirror /dev/ada0 /dev/ada1 [user 0 (root) on :global]
2013-02-27.18:50:58 zfs set atime=off tank [user 0 (root) on myzfsbox:global]
2013-02-27.18:51:09 zfs set checksum=fletcher4 tank [user 0 (root) on myzfsbox:global]
2013-02-27.18:51:18 zfs create tank/backup [user 0 (root) on myzfsbox:global]输出显示 root 用户使用磁盘 /dev/ada0 和 /dev/ada1 创建了镜像池。在池创建后的命令中还显示了主机名 myzfsbox 。主机名的显示在将池从一个系统导出并在另一个系统导入时变得重要。可以通过为每个命令记录的主机名来区分在另一个系统上发出的命令。
将两个选项 zpool history 结合起来,以便为任何给定的池提供尽可能详细的信息。池历史记录在追踪执行的操作或需要更详细的输出进行调试时提供有价值的信息。
22.3.13. 性能监控
内置的监控系统可以实时显示池的 I/O 统计信息。它显示池中的可用空间和已使用空间的数量,每秒执行的读写操作次数以及使用的 I/O 带宽。默认情况下, ZFS 监视并显示系统中的所有池。提供池名称以限制监控到该池。一个基本示例:
# zpool iostat
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
data 288G 1.53T 2 11 11.3K 57.1K要持续查看 I/O 活动,请在最后一个参数中指定一个数字,表示更新之间等待的秒数间隔。每个间隔后都会打印下一个统计行。按下 Ctrl+C 停止此连续监视。在间隔之后的命令行上给出第二个数字,以指定要显示的统计总数。
使用 -v 参数可以显示更详细的 I/O 统计信息。池中的每个设备都会显示一行统计信息。这对于查看在每个设备上执行的读写操作非常有用,并且可以帮助确定是否有任何单个设备导致池变慢。以下示例显示了一个具有两个设备的镜像池。
# zpool iostat -v
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data 288G 1.53T 2 12 9.23K 61.5K
mirror 288G 1.53T 2 12 9.23K 61.5K
ada1 - - 0 4 5.61K 61.7K
ada2 - - 1 4 5.04K 61.7K
----------------------- ----- ----- ----- ----- ----- -----22.4. zfs 管理
zfs 实用程序可以在池中创建、销毁和管理所有现有的 ZFS 数据集。要管理池本身,请使用 zpool。
22.4.1. 创建和销毁数据集
与传统的磁盘和卷管理器不同,ZFS 中的空间是 不预分配 的。在传统文件系统中,分区和分配空间后,无法在不添加新磁盘的情况下添加新的文件系统。而在 ZFS 中,可以随时创建新的文件系统。每个 数据集 都有属性,包括压缩、去重、缓存和配额等功能,以及其他有用的属性,如只读、大小写敏感、网络文件共享和挂载点。可以将数据集嵌套在彼此之间,并且子数据集将继承其祖先的属性。 委派、复制、快照、jail 允许将每个数据集作为一个单元进行管理和销毁。为每种不同类型或文件集创建单独的数据集具有优势。拥有大量数据集的缺点是,某些命令(如 zfs list)的速度会变慢,并且挂载数百甚至数千个数据集会减慢 FreeBSD 的启动过程。
创建一个新的数据集,并在其上启用 LZ4 压缩。
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 781M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 616K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.20M 93.2G 608K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/tmp 152K 93.2G 152K /var/tmp
# zfs create -o compress=lz4 mypool/usr/mydataset
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 781M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 704K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/mydataset 87.5K 93.2G 87.5K /usr/mydataset
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.20M 93.2G 610K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/tmp 152K 93.2G 152K /var/tmp销毁数据集比删除数据集上的文件要快得多,因为它不涉及扫描文件和更新相应的元数据。
销毁已创建的数据集:
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 880M 93.1G 144K none
mypool/ROOT 777M 93.1G 144K none
mypool/ROOT/default 777M 93.1G 777M /
mypool/tmp 176K 93.1G 176K /tmp
mypool/usr 101M 93.1G 144K /usr
mypool/usr/home 184K 93.1G 184K /usr/home
mypool/usr/mydataset 100M 93.1G 100M /usr/mydataset
mypool/usr/ports 144K 93.1G 144K /usr/ports
mypool/usr/src 144K 93.1G 144K /usr/src
mypool/var 1.20M 93.1G 610K /var
mypool/var/crash 148K 93.1G 148K /var/crash
mypool/var/log 178K 93.1G 178K /var/log
mypool/var/mail 144K 93.1G 144K /var/mail
mypool/var/tmp 152K 93.1G 152K /var/tmp
# zfs destroy mypool/usr/mydataset
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 781M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 616K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.21M 93.2G 612K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/tmp 152K 93.2G 152K /var/tmp在现代版本的 ZFS 中, zfs destroy 是异步的,释放的空间可能需要几分钟才会在池中显示出来。使用 zpool get freeing poolname 命令来查看 freeing 属性,该属性显示了哪些数据集正在后台释放其块。如果存在子数据集,例如 快照 或其他数据集,那么无法销毁父数据集。要销毁一个数据集及其子数据集,可以使用 -r 选项递归地销毁数据集及其子数据集。使用 -n -v 选项列出此操作销毁的数据集和快照,而不实际销毁任何内容。销毁快照释放的空间也会显示出来。
22.4.2. 创建和销毁卷
卷是一种特殊的数据集类型。它不像文件系统那样挂载,而是在 /dev/zvol/poolname/dataset 下以块设备的形式公开。这使得可以将卷用于其他文件系统,用于虚拟机的磁盘备份,或者通过 iSCSI 或 HAST 等协议使其对其他网络主机可用。
使用任何文件系统或者不使用文件系统来格式化一个卷,以存储原始数据。对于用户来说,一个卷看起来就像一个普通的磁盘。在这些 zvol 上放置普通的文件系统提供了普通磁盘或文件系统所没有的功能。例如,使用压缩属性在一个 250MB 的卷上可以创建一个压缩的 FAT 文件系统。
# zfs create -V 250m -o compression=on tank/fat32
# zfs list tank
NAME USED AVAIL REFER MOUNTPOINT
tank 258M 670M 31K /tank
# newfs_msdos -F32 /dev/zvol/tank/fat32
# mount -t msdosfs /dev/zvol/tank/fat32 /mnt
# df -h /mnt | grep fat32
Filesystem Size Used Avail Capacity Mounted on
/dev/zvol/tank/fat32 249M 24k 249M 0% /mnt
# mount | grep fat32
/dev/zvol/tank/fat32 on /mnt (msdosfs, local)销毁一个卷与销毁一个常规文件系统数据集基本相同。该操作几乎是瞬时完成的,但在后台重新获取空闲空间可能需要几分钟的时间。
22.4.3. 重命名数据集
要更改数据集的名称,请使用 zfs rename 命令。要更改数据集的父级,请同样使用此命令。将数据集重命名为具有不同父级的数据集将更改从父级数据集继承的属性的值。将数据集重命名为新位置(从新父级数据集继承)将卸载然后重新挂载它。要防止此行为,请使用 -u 选项。
重命名数据集并将其移动到不同的父数据集下:
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 780M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 704K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/mydataset 87.5K 93.2G 87.5K /usr/mydataset
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.21M 93.2G 614K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/tmp 152K 93.2G 152K /var/tmp
# zfs rename mypool/usr/mydataset mypool/var/newname
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 780M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 616K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.29M 93.2G 614K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/newname 87.5K 93.2G 87.5K /var/newname
mypool/var/tmp 152K 93.2G 152K /var/tmp重命名快照使用相同的命令。由于快照的特性,重命名不能改变它们的父数据集。要重命名递归快照,请指定 -r ;这也会重命名所有子数据集中具有相同名称的快照。
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/newname@first_snapshot 0 - 87.5K -
# zfs rename mypool/var/newname@first_snapshot new_snapshot_name
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/newname@new_snapshot_name 0 - 87.5K -22.4.4. 设置数据集属性
每个 ZFS 数据集都有控制其行为的属性。大多数属性会自动从父数据集继承,但可以在本地进行覆盖。使用 zfs set property=value dataset 在数据集上设置属性。大多数属性有一组有限的有效值,zfs get 将显示每个可能的属性和有效值。使用 zfs inherit 将大多数属性恢复为其继承的值。还可以定义用户自定义属性。它们成为数据集配置的一部分,并提供有关数据集或其内容的进一步信息。为了区分这些自定义属性和作为 ZFS 的一部分提供的属性,可以使用冒号(:)为属性创建自定义命名空间。
# zfs set custom:costcenter=1234 tank
# zfs get custom:costcenter tank
NAME PROPERTY VALUE SOURCE
tank custom:costcenter 1234 local要删除自定义属性,请使用 zfs inherit 命令并加上 -r 选项。如果自定义属性在任何父数据集中都没有定义,这个选项将删除它(但池的历史记录仍然会记录这个更改)。
# zfs inherit -r custom:costcenter tank
# zfs get custom:costcenter tank
NAME PROPERTY VALUE SOURCE
tank custom:costcenter - -
# zfs get all tank | grep custom:costcenter
#22.4.4.1. 获取和设置共享属性
两个常用且有用的数据集属性是 NFS 和 SMB 共享选项。设置这些选项可以定义 ZFS 在网络上共享数据集的方式和方式。目前,FreeBSD 仅支持设置 NFS 共享。要获取共享的当前状态,请输入:
# zfs get sharenfs mypool/usr/home
NAME PROPERTY VALUE SOURCE
mypool/usr/home sharenfs on local
# zfs get sharesmb mypool/usr/home
NAME PROPERTY VALUE SOURCE
mypool/usr/home sharesmb off local要启用数据集的共享,请输入:
# zfs set sharenfs=on mypool/usr/home设置通过 NFS 共享数据集的其他选项,例如 -alldirs、-maproot 和 -network。要在通过 NFS 共享的数据集上设置选项,请输入:
# zfs set sharenfs="-alldirs,-maproot=root,-network=192.168.1.0/24" mypool/usr/home22.4.5. 管理快照
快照 是 ZFS 最强大的功能之一。快照提供了数据集的只读、时间点的副本。通过写时复制(COW),ZFS 通过在磁盘上保留旧版本的数据来快速创建快照。如果没有快照存在,当数据被重写或删除时,ZFS 会回收空间以供将来使用。快照通过记录当前数据集与先前版本之间的差异来保留磁盘空间。允许在整个数据集上进行快照,而不是在单个文件或目录上进行快照。数据集的快照复制其中包含的所有内容。这包括文件系统属性、文件、目录、权限等。快照在创建时不占用额外的空间,但随着它们引用的块的变化而消耗空间。使用 -r 进行递归快照会在数据集及其子数据集上创建具有相同名称的快照,提供文件系统的一致时刻快照。当应用程序在相关数据集上有文件或相互依赖时,这可能很重要。如果没有快照,备份将具有来自不同时间点的文件副本。
ZFS 中的快照提供了许多其他具有快照功能的文件系统所缺乏的功能。快照的典型用法是在执行风险操作(如软件安装或系统升级)时,快速备份文件系统的当前状态。如果操作失败,回滚到快照可以将系统恢复到创建快照时的相同状态。如果升级成功,可以删除快照以释放空间。如果没有快照,升级失败通常需要恢复备份,这是繁琐、耗时的,并且可能需要停机时间,期间系统无法使用。回滚到快照是快速的,即使系统在正常运行中,几乎没有停机时间。考虑到从备份中复制数据所需的时间,对于多 TB 存储系统来说,节省的时间是巨大的。快照不能替代对池的完整备份,但提供了一种快速简便的方式来存储特定时间点的数据集副本。
22.4.5.1. 创建快照
要创建快照,请使用 zfs snapshot dataset@snapshotname 命令。添加 -r 选项可以递归地创建快照,并在所有子数据集上使用相同的名称。
创建整个池的递归快照:
# zfs list -t all
NAME USED AVAIL REFER MOUNTPOINT
mypool 780M 93.2G 144K none
mypool/ROOT 777M 93.2G 144K none
mypool/ROOT/default 777M 93.2G 777M /
mypool/tmp 176K 93.2G 176K /tmp
mypool/usr 616K 93.2G 144K /usr
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/ports 144K 93.2G 144K /usr/ports
mypool/usr/src 144K 93.2G 144K /usr/src
mypool/var 1.29M 93.2G 616K /var
mypool/var/crash 148K 93.2G 148K /var/crash
mypool/var/log 178K 93.2G 178K /var/log
mypool/var/mail 144K 93.2G 144K /var/mail
mypool/var/newname 87.5K 93.2G 87.5K /var/newname
mypool/var/newname@new_snapshot_name 0 - 87.5K -
mypool/var/tmp 152K 93.2G 152K /var/tmp
# zfs snapshot -r mypool@my_recursive_snapshot
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
mypool@my_recursive_snapshot 0 - 144K -
mypool/ROOT@my_recursive_snapshot 0 - 144K -
mypool/ROOT/default@my_recursive_snapshot 0 - 777M -
mypool/tmp@my_recursive_snapshot 0 - 176K -
mypool/usr@my_recursive_snapshot 0 - 144K -
mypool/usr/home@my_recursive_snapshot 0 - 184K -
mypool/usr/ports@my_recursive_snapshot 0 - 144K -
mypool/usr/src@my_recursive_snapshot 0 - 144K -
mypool/var@my_recursive_snapshot 0 - 616K -
mypool/var/crash@my_recursive_snapshot 0 - 148K -
mypool/var/log@my_recursive_snapshot 0 - 178K -
mypool/var/mail@my_recursive_snapshot 0 - 144K -
mypool/var/newname@new_snapshot_name 0 - 87.5K -
mypool/var/newname@my_recursive_snapshot 0 - 87.5K -
mypool/var/tmp@my_recursive_snapshot 0 - 152K -普通的 zfs list 操作不会显示快照。要列出快照,请在 zfs list 后面添加 -t snapshot。 -t all 可以同时显示文件系统和快照。
快照不会直接挂载,因此在 MOUNTPOINT 列中不显示路径。ZFS 在 AVAIL 列中不提及可用磁盘空间,因为快照在创建后是只读的。将快照与原始数据集进行比较:
# zfs list -rt all mypool/usr/home
NAME USED AVAIL REFER MOUNTPOINT
mypool/usr/home 184K 93.2G 184K /usr/home
mypool/usr/home@my_recursive_snapshot 0 - 184K -同时显示数据集和快照可以展示快照以 写时复制 方式工作的原理。它们保存所做的更改(delta),而不是再次保存完整的文件系统内容。这意味着在进行更改时,快照所占用的空间很小。通过将文件复制到数据集中,然后创建第二个快照,可以更加观察空间使用情况:
# cp /etc/passwd /var/tmp
# zfs snapshot mypool/var/tmp@after_cp
# zfs list -rt all mypool/var/tmp
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/tmp 206K 93.2G 118K /var/tmp
mypool/var/tmp@my_recursive_snapshot 88K - 152K -
mypool/var/tmp@after_cp 0 - 118K -第二个快照包含了复制操作后数据集的变化。这样可以节省大量的空间。请注意,快照 mypool/var/tmp@my_recursive_snapshot 的大小在 USED 列中也发生了变化,以显示它与之后拍摄的快照之间的变化。
22.4.5.2. 比较快照
ZFS 提供了一个内置命令,用于比较两个快照之间内容的差异。当用户想要查看文件系统随时间变化的方式时,这非常有帮助,尤其是在有很多快照的情况下。例如, zfs diff 命令可以帮助用户找到最新的快照,其中仍然包含了意外删除的文件。对于前一节创建的两个快照,执行此命令将输出如下结果:
# zfs list -rt all mypool/var/tmp
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/tmp 206K 93.2G 118K /var/tmp
mypool/var/tmp@my_recursive_snapshot 88K - 152K -
mypool/var/tmp@after_cp 0 - 118K -
# zfs diff mypool/var/tmp@my_recursive_snapshot
M /var/tmp/
+ /var/tmp/passwd该命令列出了指定快照(在本例中为 mypool/var/tmp@my_recursive_snapshot )与活动文件系统之间的变化。第一列显示变化类型:
+ |
添加路径或文件。 |
- |
删除路径或文件。 |
M |
修改路径或文件。 |
R |
重命名路径或文件。 |
将输出与表格进行比较,可以清楚地看到 ZFS 在创建快照 mypool/var/tmp@my_recursive_snapshot 之后添加了 passwd 。这也导致了挂载在 /var/tmp 上的父目录的修改。
当使用 ZFS 复制功能将数据集传输到不同的主机进行备份时,比较两个快照是非常有帮助的。
通过提供两个数据集的完整数据集名称和快照名称来比较两个快照:
# cp /var/tmp/passwd /var/tmp/passwd.copy
# zfs snapshot mypool/var/tmp@diff_snapshot
# zfs diff mypool/var/tmp@my_recursive_snapshot mypool/var/tmp@diff_snapshot
M /var/tmp/
+ /var/tmp/passwd
+ /var/tmp/passwd.copy
# zfs diff mypool/var/tmp@my_recursive_snapshot mypool/var/tmp@after_cp
M /var/tmp/
+ /var/tmp/passwd备份管理员可以比较从发送主机接收到的两个快照,并确定数据集中的实际更改。有关更多信息,请参阅 复制 部分。
22.4.5.3. 快照回滚
当至少有一个快照可用时,随时可以回滚到该快照。大多数情况下,当数据集的当前状态不再存在或者更喜欢旧版本时,会出现这种情况。诸如本地开发测试失败、系统更新失败导致系统功能受阻,或者需要恢复已删除的文件或目录等情况都很常见。要回滚快照,请使用 zfs rollback snapshotname 命令。如果存在大量更改,操作将需要很长时间。在此期间,数据集始终保持一致的状态,就像符合 ACID 原则的数据库执行回滚操作一样。这一切都发生在数据集处于活动状态且可访问的情况下,无需停机。一旦快照回滚完成,数据集的状态与快照创建时的状态相同。回滚到快照会丢弃数据集中不属于该快照的所有其他数据。在回滚到以前的快照之前,将当前数据集的状态进行快照是一个好主意,以便稍后需要某些数据。这样,用户可以在快照之间来回切换,而不会丢失仍然有价值的数据。
在第一个示例中,由于一个粗心的 rm 操作删除了比预期更多的数据,因此需要回滚一个快照。
# zfs list -rt all mypool/var/tmp
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/tmp 262K 93.2G 120K /var/tmp
mypool/var/tmp@my_recursive_snapshot 88K - 152K -
mypool/var/tmp@after_cp 53.5K - 118K -
mypool/var/tmp@diff_snapshot 0 - 120K -
# ls /var/tmp
passwd passwd.copy vi.recover
# rm /var/tmp/passwd*
# ls /var/tmp
vi.recover在这一点上,用户注意到额外文件被删除了,并希望将它们恢复。 ZFS 提供了一种简单的方法来使用回滚将它们恢复,当定期对重要数据进行快照时。要将文件恢复并从最后一个快照重新开始,执行以下命令:
# zfs rollback mypool/var/tmp@diff_snapshot
# ls /var/tmp
passwd passwd.copy vi.recover回滚操作将数据集恢复到最后一个快照的状态。也可以回滚到之前拍摄的快照之后拍摄的其他快照的状态。在尝试这样做时,ZFS 会发出以下警告:
# zfs list -rt snapshot mypool/var/tmp
AME USED AVAIL REFER MOUNTPOINT
mypool/var/tmp@my_recursive_snapshot 88K - 152K -
mypool/var/tmp@after_cp 53.5K - 118K -
mypool/var/tmp@diff_snapshot 0 - 120K -
# zfs rollback mypool/var/tmp@my_recursive_snapshot
cannot rollback to 'mypool/var/tmp@my_recursive_snapshot': more recent snapshots exist
use '-r' to force deletion of the following snapshots:
mypool/var/tmp@after_cp
mypool/var/tmp@diff_snapshot这个警告意味着在当前数据集状态和用户想要回滚的快照之间存在快照。要完成回滚操作,请删除这些快照。由于快照是只读的,ZFS 无法跟踪数据集不同状态之间的所有更改。除非用户使用 -r 参数确认这是所需的操作,否则 ZFS 不会删除受影响的快照。如果这是用户的意图,并且理解丢失所有中间快照的后果,请执行以下命令:
# zfs rollback -r mypool/var/tmp@my_recursive_snapshot
# zfs list -rt snapshot mypool/var/tmp
NAME USED AVAIL REFER MOUNTPOINT
mypool/var/tmp@my_recursive_snapshot 8K - 152K -
# ls /var/tmp
vi.recoverzfs list -t snapshot 的输出确认了由于 zfs rollback -r 的结果,中间快照已被删除。
22.4.5.4. 从快照中恢复单个文件
快照存储在父数据集的隐藏目录下: .zfs/snapshots/snapshotname 。默认情况下,即使执行标准的 ls -a 命令,这些目录也不会显示出来。尽管目录不可见,但可以像访问普通目录一样访问它。名为 snapdir 的属性控制这些隐藏目录是否在目录列表中显示。将该属性设置为 visible 可以使它们出现在 ls 和其他处理目录内容的命令的输出中。
# zfs get snapdir mypool/var/tmp
NAME PROPERTY VALUE SOURCE
mypool/var/tmp snapdir hidden default
# ls -a /var/tmp
. .. passwd vi.recover
# zfs set snapdir=visible mypool/var/tmp
# ls -a /var/tmp
. .. .zfs passwd vi.recover通过将文件从快照复制回父数据集,将其恢复到先前的状态。 .zfs/snapshot 下的目录结构中有一个类似于先前拍摄的快照的目录,以便更容易识别它们。下一个示例显示了如何从隐藏的 .zfs 目录中复制文件,从包含文件最新版本的快照中恢复文件:
# rm /var/tmp/passwd
# ls -a /var/tmp
. .. .zfs vi.recover
# ls /var/tmp/.zfs/snapshot
after_cp my_recursive_snapshot
# ls /var/tmp/.zfs/snapshot/after_cp
passwd vi.recover
# cp /var/tmp/.zfs/snapshot/after_cp/passwd /var/tmp即使将 snapdir 属性设置为隐藏,运行 ls .zfs/snapshot 仍然会列出该目录的内容。管理员决定是否显示这些目录。这是每个数据集的设置。从这个隐藏的 .zfs/snapshot 复制文件或目录非常简单。尝试反过来操作会导致以下错误:
# cp /etc/rc.conf /var/tmp/.zfs/snapshot/after_cp/
cp: /var/tmp/.zfs/snapshot/after_cp/rc.conf: Read-only file system该错误提醒用户快照是只读的,创建后不能更改。将文件复制到快照目录或从中删除文件都是不允许的,因为这会改变所表示数据集的状态。
快照占用的空间取决于父文件系统自快照以来的更改量。快照的 written 属性跟踪快照使用的空间。
要销毁快照并回收空间,请使用 zfs destroy dataset@snapshot 命令。添加 -r 选项可以递归删除父数据集下具有相同名称的所有快照。在命令中添加 -n -v 选项可以显示要删除的快照列表以及执行实际销毁操作前将回收的空间的估计值。
22.4.6. 管理克隆实例
克隆是快照的副本,更像一个常规数据集。与快照不同,克隆是可写的和可挂载的,并且具有自己的属性。使用 zfs clone 创建克隆后,无法销毁原始快照。要反转克隆和快照之间的子/父关系,请使用 zfs promote 。将克隆提升为快照成为克隆的子项,而不是原始父数据集的子项。这将改变 ZFS 对空间的计算方式,但实际上不会改变所消耗的空间量。可以在 ZFS 文件系统层次结构中的任何位置挂载克隆,不仅限于快照的原始位置下方。
要展示克隆功能,请使用以下示例数据集:
# zfs list -rt all camino/home/joe
NAME USED AVAIL REFER MOUNTPOINT
camino/home/joe 108K 1.3G 87K /usr/home/joe
camino/home/joe@plans 21K - 85.5K -
camino/home/joe@backup 0K - 87K -克隆的典型用途是在进行特定数据集的实验时,保留快照以备不时之需。由于快照是不可更改的,因此需要创建一个可读/写的快照克隆。在克隆中获得所需的结果后,将克隆提升为数据集并删除旧的文件系统。严格来说,删除父数据集并非必需,因为克隆和数据集可以共存而不会出现问题。
# zfs clone camino/home/joe@backup camino/home/joenew
# ls /usr/home/joe*
/usr/home/joe:
backup.txz plans.txt
/usr/home/joenew:
backup.txz plans.txt
# df -h /usr/home
Filesystem Size Used Avail Capacity Mounted on
usr/home/joe 1.3G 31k 1.3G 0% /usr/home/joe
usr/home/joenew 1.3G 31k 1.3G 0% /usr/home/joenew创建克隆会使其成为数据集在拍摄快照时的精确副本。现在可以独立地更改克隆与其源数据集之间的连接。两者之间的连接是快照。 ZFS 将此连接记录在属性 origin 中。使用 zfs promote 提升克隆将使其成为独立的数据集。这将删除 origin 属性的值,并断开新独立数据集与快照之间的连接。以下示例说明了这一点:
# zfs get origin camino/home/joenew
NAME PROPERTY VALUE SOURCE
camino/home/joenew origin camino/home/joe@backup -
# zfs promote camino/home/joenew
# zfs get origin camino/home/joenew
NAME PROPERTY VALUE SOURCE
camino/home/joenew origin - -在进行一些更改后,例如将 loader.conf 复制到推广的克隆中,旧目录在这种情况下变得过时。相反,推广的克隆可以替代它。为了做到这一点,首先使用 zfs destroy 命令销毁旧数据集,然后使用 zfs rename 命令将克隆重命名为旧数据集的名称(或完全不同的名称)。
# cp /boot/defaults/loader.conf /usr/home/joenew
# zfs destroy -f camino/home/joe
# zfs rename camino/home/joenew camino/home/joe
# ls /usr/home/joe
backup.txz loader.conf plans.txt
# df -h /usr/home
Filesystem Size Used Avail Capacity Mounted on
usr/home/joe 1.3G 128k 1.3G 0% /usr/home/joe克隆的快照现在是一个普通的数据集。它包含了原始快照中的所有数据,以及像 loader.conf 这样添加到其中的文件。在不同的场景中,克隆为 ZFS 用户提供了有用的功能。例如,可以将 jails 作为包含不同安装应用程序集的快照。用户可以克隆这些快照,并根据需要添加自己的应用程序。一旦对更改满意,可以将克隆提升为完整的数据集,并将其提供给最终用户,就像使用真实数据集一样。这样可以节省提供这些监狱时的时间和管理开销。
22.4.7. 复制
将数据存储在一个位置的单个池中会使其暴露于盗窃、自然灾害或人为灾害等风险。定期备份整个池是至关重要的。 ZFS 提供了一个内置的序列化功能,可以将数据的流表示发送到标准输出。使用此功能,可以将这些数据存储在连接到本地系统的另一个池中,也可以将其发送到另一个系统上的网络上。快照是复制的基础(参见 ZFS 快照 部分)。用于复制数据的命令是 zfs send 和 zfs receive。
这些示例展示了使用这两个存储池进行 ZFS 复制的情况:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
backup 960M 77K 896M - - 0% 0% 1.00x ONLINE -
mypool 984M 43.7M 940M - - 0% 4% 1.00x ONLINE -名为 mypool 的池是主要的池,数据的写入和读取在此池中定期进行。在主要池不可用时,使用第二个备用池 backup。请注意,ZFS 不会自动执行此故障转移,而是需要系统管理员在需要时手动执行。使用快照提供一致的文件系统版本进行复制。在创建 mypool 的快照后,通过复制快照将其复制到 backup 池中。这不包括自最近快照以来所做的更改。
# zfs snapshot mypool@backup1
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
mypool@backup1 0 - 43.6M -现在有了一个快照,使用 zfs send 命令创建一个表示快照内容的流。将这个流存储为文件,或者在另一个存储池中接收它。将流写入标准输出,但要将其重定向到文件或管道,否则会出现错误。
# zfs send mypool@backup1
Error: Stream can not be written to a terminal.
You must redirect standard output.使用 zfs send 命令备份数据集时,将其重定向到位于已挂载的备份池上的文件。确保备份池有足够的空间来容纳发送的快照的大小,这指的是快照中包含的数据,而不是与上一个快照的更改。
# zfs send mypool@backup1 > /backup/backup1
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
backup 960M 63.7M 896M - - 0% 6% 1.00x ONLINE -
mypool 984M 43.7M 940M - - 0% 4% 1.00x ONLINE -zfs send 命令将名为 backup1 的快照中的所有数据传输到名为 backup 的存储池中。要自动创建和发送这些快照,请使用 cron(8) 任务。
ZFS 可以将备份存储为实时文件系统,而不是存储为归档文件,从而可以直接访问备份数据。要访问这些流中包含的实际数据,可以使用 zfs receive 将流转换回文件和目录。下面的示例结合了 zfs send 和 zfs receive ,使用管道将数据从一个存储池复制到另一个存储池。在传输完成后,可以直接在接收存储池上使用数据。只能将数据集复制到空数据集。
# zfs snapshot mypool@replica1
# zfs send -v mypool@replica1 | zfs receive backup/mypool
send from @ to mypool@replica1 estimated size is 50.1M
total estimated size is 50.1M
TIME SENT SNAPSHOT
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
backup 960M 63.7M 896M - - 0% 6% 1.00x ONLINE -
mypool 984M 43.7M 940M - - 0% 4% 1.00x ONLINE -22.4.7.1. 增量备份
zfs send 还可以确定两个快照之间的差异,并发送两者之间的个别差异。这样可以节省磁盘空间和传输时间。例如:
# zfs snapshot mypool@replica2
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
mypool@replica1 5.72M - 43.6M -
mypool@replica2 0 - 44.1M -
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
backup 960M 61.7M 898M - - 0% 6% 1.00x ONLINE -
mypool 960M 50.2M 910M - - 0% 5% 1.00x ONLINE -创建一个名为 replica2 的第二个快照。这个第二个快照包含了从现在到上一个快照 replica1 之间对文件系统所做的更改。使用 zfs send -i 命令,并指定快照对,可以生成一个增量复制流,其中包含了更改的数据。如果接收端已经存在初始快照,则此操作将成功。
# zfs send -v -i mypool@replica1 mypool@replica2 | zfs receive /backup/mypool
send from @replica1 to mypool@replica2 estimated size is 5.02M
total estimated size is 5.02M
TIME SENT SNAPSHOT
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
backup 960M 80.8M 879M - - 0% 8% 1.00x ONLINE -
mypool 960M 50.2M 910M - - 0% 5% 1.00x ONLINE -
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
backup 55.4M 240G 152K /backup
backup/mypool 55.3M 240G 55.2M /backup/mypool
mypool 55.6M 11.6G 55.0M /mypool
# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
backup/mypool@replica1 104K - 50.2M -
backup/mypool@replica2 0 - 55.2M -
mypool@replica1 29.9K - 50.0M -
mypool@replica2 0 - 55.0M -增量流复制了变化的数据,而不是整个 replica1。仅发送差异所需的传输时间更短,并且通过不每次复制整个池来节省磁盘空间。这在通过慢速网络或按传输字节计费的网络上进行复制时非常有用。
一个新的文件系统,backup/mypool,可用于存储来自池 mypool 的文件和数据。使用 -p 参数可以复制数据集的属性,包括压缩设置、配额和挂载点。使用 -R 参数可以复制数据集的所有子数据集以及它们的属性。自动化发送和接收操作可以在第二个池中创建定期备份。
22.4.7.2. 通过 SSH 发送加密备份
通过网络发送流是保持远程备份的好方法,但它也有一个缺点。通过网络链路发送的数据没有加密,允许任何人在不知情的情况下拦截和转换流为数据。当将流发送到远程主机时,这是不可取的。使用 SSH 来安全地加密通过网络连接发送的数据。由于 ZFS 需要将流重定向到标准输出,所以通过 SSH 进行管道传输很容易。为了在传输和远程系统上保持文件系统的内容加密,考虑使用 PEFS。
首先,更改一些设置并采取安全预防措施。这描述了执行 zfs send 操作所需的必要步骤;有关 SSH 的更多信息,请参见 OpenSSH 。
将配置更改如下:
-
使用 SSH 密钥在发送和接收主机之间实现无密码 SSH 访问
-
ZFS 需要
root用户的权限来发送和接收流。这需要以root用户身份登录到接收系统。 -
出于安全原因,默认情况下禁止
root用户登录。 -
使用 ZFS 委派 系统,允许每个系统上的非
root用户执行相应的发送和接收操作。在发送系统上:# zfs allow -u someuser send,snapshot mypool -
要挂载池,非特权用户必须拥有该目录的所有权,并且普通用户需要有挂载文件系统的权限。
在接收系统上:
+
# sysctl vfs.usermount=1
vfs.usermount: 0 -> 1
# echo vfs.usermount=1 >> /etc/sysctl.conf
# zfs create recvpool/backup
# zfs allow -u someuser create,mount,receive recvpool/backup
# chown someuser /recvpool/backup非特权用户现在可以接收和挂载数据集,并将 home 数据集复制到远程系统:
% zfs snapshot -r mypool/home@monday
% zfs send -R mypool/home@monday | ssh someuser@backuphost zfs recv -dvu recvpool/backup在池 mypool 上创建一个名为 monday 的文件系统数据集 home 的递归快照。然后,zfs send -R 命令将数据集、所有子数据集、快照、克隆和设置包含在流中。通过 SSH 将输出导向等待的远程主机 backuphost 上的 zfs receive 命令。使用 IP 地址或完全限定域名是良好的实践。接收机将数据写入 recvpool 池上的 backup 数据集。在 zfs recv 命令中添加 -d 选项会使用快照的名称覆盖接收端池的名称。 -u 选项会导致接收端上的文件系统不挂载。使用 -v 选项可以显示有关传输的更多详细信息,包括经过的时间和传输的数据量。
22.4.8. 数据集、用户和组配额
使用 数据集配额 来限制特定数据集消耗的空间量。 引用配额 的工作方式类似,但是计算的是数据集本身使用的空间,不包括快照和子数据集。同样地,使用 用户配额 和 组配额 来防止用户或组使用完池或数据集中的所有空间。
以下示例假设用户已经存在于系统中。在将用户添加到系统之前,请确保首先创建他们的主目录数据集,并将 mountpoint 设置为 /home/bob 。然后,创建用户并将主目录指向数据集的 mountpoint 位置。这将正确设置所有者和组权限,而不会遮盖可能存在的任何预先存在的主目录路径。
为了对 storage/home/bob 强制执行一个 10 GB 的数据集配额:
# zfs set quota=10G storage/home/bob为了强制限制 storage/home/bob 的引用配额为 10 GB :
# zfs set refquota=10G storage/home/bob要移除 storage/home/bob 的 10 GB 配额:
# zfs set quota=none storage/home/bob通用格式为 userquota@user=size ,用户的名称必须符合以下格式之一:
-
POSIX 兼容的名称,例如 joe。
-
POSIX 数值 ID,例如 789。
-
SID 名称,例如 [email protected]。
-
SID 是一个数字 ID,例如 S-1-123-456-789。
例如,要为名为 joe 的用户强制执行 50 GB 的用户配额:
# zfs set userquota@joe=50G要移除任何配额:
# zfs set userquota@joe=none|
|
设置群组配额的一般格式为:groupquota@group=size 。
要将组 firstgroup 的配额设置为 50 GB,请使用以下命令:
# zfs set groupquota@firstgroup=50G要删除组 firstgroup 的配额,或确保未设置配额,请使用以下命令:
# zfs set groupquota@firstgroup=none与用户配额属性一样,非 root 用户可以查看与他们所属的组相关联的配额。具有 groupquota 特权或 root 权限的用户可以查看和设置所有组的所有配额。
要显示文件系统或快照中每个用户使用的空间量以及任何配额,请使用 zfs userspace。要获取组信息,请使用 zfs groupspace。有关支持的选项或如何仅显示特定选项的更多信息,请参阅 zfs(1)。
特权用户和 root 用户可以使用以下命令列出 storage/home/bob 目录的配额:
# zfs get quota storage/home/bob22.4.9. 预留空间
预留空间 保证了数据集上始终可用的一定量空间。预留的空间将不会对其他数据集可用。这个有用的功能确保了重要数据集或日志文件的可用的空闲空间。
reservation 属性的一般格式是 reservation=size,因此要在 storage/home/bob 上设置 10 GB 的预留空间,可以使用以下命令:
# zfs set reservation=10G storage/home/bob取消任何预留空间:
# zfs set reservation=none storage/home/bob同样的原则适用于设置 refreservation 属性以设置 引用预留 ,其一般格式为 refreservation =size 。
该命令显示位于 storage/home/bob 目录下的任何预留空间或引用预留空间。
# zfs get reservation storage/home/bob
# zfs get refreservation storage/home/bob22.4.10. 压缩
ZFS 提供透明压缩功能。在块级别压缩数据可以节省空间,同时提高磁盘吞吐量。如果数据压缩率为 25% ,压缩后的数据写入磁盘的速度与未压缩版本相同,从而实现了 125% 的有效写入速度。压缩也可以作为 去重 的一个很好的替代方案,因为它不需要额外的内存。
ZFS 提供了不同的压缩算法,每种算法都有不同的权衡。在 ZFS v5000 中引入的 LZ4 压缩算法可以在不牺牲性能的情况下对整个池进行压缩。 LZ4 的最大优势是 提前中止(early abort) 功能。如果 LZ4 在数据的头部部分无法达到至少 12.5% 的压缩率, ZFS 会以未压缩的方式写入该块,以避免浪费 CPU 周期尝试压缩已经压缩或无法压缩的数据。有关 ZFS 中可用的不同压缩算法的详细信息,请参阅术语部分中的 压缩 条目。
管理员可以通过数据集属性查看压缩的有效性。
# zfs get used,compressratio,compression,logicalused mypool/compressed_dataset
NAME PROPERTY VALUE SOURCE
mypool/compressed_dataset used 449G -
mypool/compressed_dataset compressratio 1.11x -
mypool/compressed_dataset compression lz4 local
mypool/compressed_dataset logicalused 496G -该数据集使用了 449 GB 的空间(使用的属性)。如果不进行压缩,它将占用 496 GB 的空间(逻辑使用的属性)。这导致了 1.11:1 的压缩比率。
当与 用户配额 结合使用时,压缩可能会产生意想不到的副作用。用户配额限制了用户在数据集上实际消耗的空间(在压缩之后)。如果一个用户的配额是 10GB ,并写入了 10GB 的可压缩数据,他们仍然可以存储更多的数据。如果他们稍后更新一个文件,比如一个数据库,其中包含更多或更少可压缩的数据,可用空间的数量将会改变。这可能导致一个奇怪的情况,即用户没有增加实际数据量( logicalused 属性),但压缩的变化导致他们达到了配额限制。
压缩可能会与备份产生类似的意外交互作用。配额通常用于限制数据存储,以确保有足够的备份空间可用。由于配额不考虑压缩,因此 ZFS 可能会写入比未压缩备份所能容纳的更多数据。
22.4.11. Zstandard 压缩
OpenZFS 2.0 增加了一种新的压缩算法。Zstandard(Zstd)提供比默认的 LZ4 更高的压缩比,同时比替代方案 gzip 速度更快。OpenZFS 2.0 可以通过 FreeBSD 12.1-RELEASE 的 sysutils/openzfs 包获得,并且自 FreeBSD 13.0-RELEASE 以来已成为默认选项。
Zstd 提供了多种压缩级别,可以对性能和压缩比进行细粒度控制。Zstd 的一个主要优势是解压速度与压缩级别无关。对于只写入一次但经常读取的数据, Zstd 允许使用最高的压缩级别而不会影响读取性能。
即使进行频繁的数据更新,启用压缩通常也能提供更高的性能。其中最大的优势之一来自于压缩的 ARC 功能。 ZFS 的自适应替换缓存(ARC)将数据的压缩版本缓存在 RAM 中,每次需要时进行解压缩。这使得相同数量的 RAM 能够存储更多的数据和元数据,从而增加了缓存命中率。
ZFS 提供 19 个级别的 Zstd 压缩,每个级别都可以在更慢的压缩速度下提供更多的空间节省。默认级别是 zstd-3,比 LZ4 提供更好的压缩效果,但速度不会慢太多。级别超过 10 需要大量的内存来压缩每个块,内存小于 16GB 的系统不应使用这些级别。ZFS 还使用了一系列的 Zstd_fast_ 级别,它们的压缩速度更快,但支持的压缩比较低。ZFS 支持 zstd-fast-1 到 zstd-fast-10,以及以 10 为增量的 zstd-fast-20 到 zstd-fast-100,还有 zstd-fast-500 和 zstd-fast-1000,它们提供最小的压缩效果,但具有高性能。
如果 ZFS 无法获取所需的内存来使用 Zstd 压缩块,它将退回到存储未压缩的块。除非在内存受限的系统上使用 Zstd 的最高级别,否则这种情况不太可能发生。ZFS 通过 kstat.zfs.misc.zstd.compress_alloc_fail 统计自加载 ZFS 模块以来发生此情况的次数。
22.4.12. 去重
当启用时,去重 使用每个块的校验和来检测重复块。当一个新块是现有块的副本时,ZFS 会写入一个对现有数据的新引用,而不是整个重复块。如果数据包含大量重复的文件或重复的信息,则可以实现巨大的空间节省。警告:去重需要大量的内存,并且启用压缩可以在不增加额外成本的情况下提供大部分的空间节省。
要激活去重功能,请在目标池上设置 dedup 属性:
# zfs set dedup=on pool去重只会影响写入池中的新数据。仅仅激活此选项不会对已经写入池中的数据进行去重。一个刚刚激活去重属性的池子将会像这个例子一样:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
pool 2.84G 2.19M 2.83G - - 0% 0% 1.00x ONLINE -DEDUP 列显示了池的实际重复消除率。1.00x 的值表示数据尚未进行重复消除。下面的示例将一些系统二进制文件复制了三次,分别放入在上述创建的重复消除池中的不同目录中。
# for d in dir1 dir2 dir3; do
> mkdir $d && cp -R /usr/bin $d &
> done要观察冗余数据的去重,请使用:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
pool 2.84G 20.9M 2.82G - - 0% 0% 3.00x ONLINE -DEDUP 列显示了一个 3.00x 的因子。检测和去重数据的副本使用了三分之一的空间。节省空间的潜力是巨大的,但需要足够的内存来跟踪去重块的成本。
当池中的数据不冗余时,去重并不总是有益的。ZFS 可以通过在现有池上模拟去重来显示潜在的节省空间。
# zdb -S pool
Simulated DDT histogram:
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE
------ ------ ----- ----- ----- ------ ----- ----- -----
1 2.58M 289G 264G 264G 2.58M 289G 264G 264G
2 206K 12.6G 10.4G 10.4G 430K 26.4G 21.6G 21.6G
4 37.6K 692M 276M 276M 170K 3.04G 1.26G 1.26G
8 2.18K 45.2M 19.4M 19.4M 20.0K 425M 176M 176M
16 174 2.83M 1.20M 1.20M 3.33K 48.4M 20.4M 20.4M
32 40 2.17M 222K 222K 1.70K 97.2M 9.91M 9.91M
64 9 56K 10.5K 10.5K 865 4.96M 948K 948K
128 2 9.50K 2K 2K 419 2.11M 438K 438K
256 5 61.5K 12K 12K 1.90K 23.0M 4.47M 4.47M
1K 2 1K 1K 1K 2.98K 1.49M 1.49M 1.49M
Total 2.82M 303G 275G 275G 3.20M 319G 287G 287G
dedup = 1.05, compress = 1.11, copies = 1.00, dedup * compress / copies = 1.16在 zdb -S 完成分析池之后,它会显示激活去重将实现的空间减少比例。在这种情况下, 1.16 是一个主要由压缩提供的较低的节省空间比例。在此池上激活去重将不会节省任何空间,并且不值得为启用去重所需的内存量。使用公式 ratio = dedup * compress / copies,系统管理员可以规划存储分配,决定工作负载是否包含足够的重复块来证明内存需求的合理性。如果数据可以合理压缩,空间节省可能会很好。良好的做法是首先启用压缩,因为压缩还可以大大提高性能。在节省可观且有足够可用内存用于 DDT 的情况下启用去重。
22.4.13. ZFS 和 Jails
使用 zfs jail 命令和相应的 jailed 属性将一个 ZFS 数据集委派给一个 jail。 zfs jail jailid 命令将数据集附加到指定的 jail,zfs unjail 命令将其分离。要在 jails 内控制数据集,需要设置 jailed 属性。由于被 jailed 的数据集可能具有会危及主机安全的挂载点,ZFS 禁止在主机上挂载被 jailed 的数据集。
22.5. 委派管理
一个全面的权限委派系统允许非特权用户执行 ZFS 管理功能。例如,如果每个用户的主目录是一个数据集,用户需要有权限创建和销毁其主目录的快照。执行备份的用户可以获得使用复制功能的权限。ZFS 允许一个使用统计脚本仅以访问所有用户的空间使用数据的方式运行。还可以委派委派权限的能力。权限委派对于每个子命令和大多数属性都是可能的。
22.6. 高级主题
22.6.1. 调优
调整可调节参数以使 ZFS 在不同的工作负载下表现最佳。
-
vfs.zfs.arc.max从 13.x 开始(12.x 为vfs.zfs.arc_max) - ARC 的上限大小。默认值为所有 RAM 减去 1 GB ,或所有 RAM 的 5/8 ,以较大者为准。如果系统运行其他可能需要内存的守护程序或进程,请使用较低的值。可以使用 sysctl(8) 在运行时调整此值,并在 /boot/loader.conf 或 /etc/sysctl.conf 中设置。 -
vfs.zfs.arc.meta_limit从 13.x 版本开始(12.x 版本为vfs.zfs.arc_meta_limit) - 限制用于存储元数据的 ARC 的数量。默认值为vfs.zfs.arc.max的四分之一。如果工作负载涉及大量文件和目录的操作,或者频繁的元数据操作,增加此值将提高性能,但会减少适应于 ARC 的文件数据量。可以使用 sysctl(8) 在 /boot/loader.conf 或 /etc/sysctl.conf 中在运行时调整此值。 -
vfs.zfs.arc.min从 13.x 开始(12.x 为vfs.zfs.arc_min) - 降低 ARC 的大小。默认值为vfs.zfs.arc.meta_limit的一半。调整此值以防止其他应用程序将整个 ARC 压力过大。可以使用 sysctl(8) 在运行时调整此值,并在 /boot/loader.conf 或 /etc/sysctl.conf 中进行调整。 -
vfs.zfs.vdev.cache.size- 在池中的每个设备上预留的用作缓存的内存的预分配量。使用的总内存量将是此值乘以设备数量。在引导时和 /boot/loader.conf 中设置此值。 -
vfs.zfs.min_auto_ashift- 在创建池时自动使用的较低的ashift(扇区大小)。该值是 2 的幂。默认值为9表示2^9 = 512,即 512 字节的扇区大小。为了避免写放大并获得最佳性能,将此值设置为池中设备使用的最大扇区大小。普通硬盘的扇区大小为 4 KB 。在这些硬盘上使用默认的
ashift值9会导致写放大。一个 4 KB 的写入数据实际上会被分成八个 512 字节的写入操作。在创建存储池时,ZFS 会尝试从所有设备中读取原生扇区大小,但是具有 4 KB 扇区的硬盘会报告它们的扇区大小为 512 字节,以保证兼容性。在创建存储池之前,将vfs.zfs.min_auto_ashift设置为12(2^12 = 4096)可以强制 ZFS 在这些硬盘上使用 4 KB 块以获得最佳性能。对于计划进行磁盘升级的存储池来说,强制使用 4 KB 块也是有用的。未来的磁盘使用 4 KB 扇区,并且在创建存储池后无法更改
ashift值。在某些特定情况下,较小的 512 字节块大小可能更可取。当与用于数据库或作为虚拟机存储的 512 字节磁盘一起使用时,小规模随机读取时的数据传输量较少。这可以在使用较小的 ZFS 记录大小时提供更好的性能。
-
vfs.zfs.prefetch_disable- 禁用预读取。值为0表示启用,值为1表示禁用。默认值为0,除非系统内存小于 4 GB。预读取通过读取比请求的块更大的块到 ARC 中,希望很快需要这些数据。如果工作负载有大量的随机读取,禁用预读取可能会通过减少不必要的读取来提高性能。可以随时使用 sysctl(8) 调整此值。 -
vfs.zfs.vdev.trim_on_init- 控制是否在将新设备添加到池中时对其运行TRIM命令。这可以确保 SSD 的最佳性能和寿命,但会花费额外的时间。如果设备已经进行了安全擦除,则禁用此设置将使新设备的添加更快。随时可以使用 sysctl(8) 调整此值。 -
vfs.zfs.vdev.max_pending- 限制每个设备的待处理 I/O 请求的数量。较高的值将保持设备命令队列满,并可能提供更高的吞吐量。较低的值将减少延迟。您可以随时使用 sysctl(8) 调整此值。 -
vfs.zfs.top_maxinflight- 每个顶级 vdev 的未完成 I/O 的上限。限制命令队列的深度以防止高延迟。该限制是针对每个顶级 vdev 的,意味着该限制独立应用于每个 镜像 、 RAID-Z 或其他 vdev 。可以随时使用 sysctl(8) 调整此值。 -
vfs.zfs.l2arc_write_max- 限制每秒写入 L2ARC 的数据量。通过限制写入设备的数据量,此可调整参数可以延长固态硬盘(SSD)的使用寿命。您可以随时使用 sysctl(8) 调整此值。 -
vfs.zfs.l2arc_write_boost- 将此可调整值添加到vfs.zfs.l2arc_write_max中,并增加对 SSD 的写入速度,直到从 L2ARC 中驱逐第一个块。这个"Turbo Warmup Phase"可以减少重启后空的 L2ARC 带来的性能损失。随时可以使用 sysctl(8) 调整此值。 -
vfs.zfs.scrub_delay- 在进行scrub时,每个 I/O 之间的延迟时间。为了确保scrub不会干扰池的正常操作,如果有其他 I/O 正在进行,scrub会在每个命令之间进行延迟。该值控制了scrub生成的总 IOPS(每秒 I/O 数)的限制。设置的粒度由kern.hz的值确定,默认为每秒 1000 个滴答。更改此设置会导致不同的有效 IOPS 限制。默认值为4,因此限制为: 1000 个滴答/秒 ÷ 4 = 250 IOPS 。使用值为 20 将得到限制:1000 个滴答/秒 ÷ 20 = 50 IOPS。池上的最近活动限制了scrub的速度,由vfs.zfs.scan_idle确定。随时可以使用 sysctl(8) 调整此值。 -
vfs.zfs.resilver_delay- 在 重建 过程中,每个 I/O 之间插入的延迟时间,以毫秒为单位。为了确保 resilver 不会干扰池的正常操作,如果有其他 I/O 正在进行,resilver 将在每个命令之间延迟。该值控制由 resilver 生成的总 IOPS(每秒 I/O 数)的限制。ZFS 通过kern.hz的值确定设置的粒度,默认为每秒 1000 个滴答。更改此设置会导致不同的有效 IOPS 限制。默认值为 2 ,结果为:1000 个滴答/秒 ÷ 2 = 500 IOPS 。如果另一个设备故障可能导致池发生故障,从而导致数据丢失,则将池恢复到 在线 状态可能更为重要。值为 0 将使 resilver 操作与其他操作具有相同的优先级,加快修复过程。池上的其他最近活动会限制 resilver 的速度,由vfs.zfs.scan_idle确定。随时可以使用 sysctl(8) 调整此值。 -
vfs.zfs.scan_idle- 距离上次操作的毫秒数,用于判断池是否处于空闲状态。当池处于空闲状态时, ZFS 会禁用对scrub和 重建 的速率限制。您可以随时使用 sysctl(8) 调整此值。 -
vfs.zfs.txg.timeout- 两个 事务组 之间的最长时间间隔,以秒为单位。当前事务组将数据写入池中,并且如果自上一个事务组以来经过了这么长时间,则会启动一个新的事务组。如果写入的数据足够多,事务组可能会提前触发。默认值为 5 秒。增大该值可能会通过延迟异步写入来提高读取性能,但这可能会导致写入事务组时性能不均衡。可以随时使用 sysctl(8) 调整此值。
22.6.2. i386 上的 ZFS
ZFS 提供的一些功能对内存要求较高,可能需要在内存有限的系统上进行调整以达到最佳效率。
22.6.2.1. 内存
作为一个较低的值,总系统内存应至少为 1GB 。推荐的 RAM 数量取决于存储池的大小和 ZFS 使用的功能。一个经验法则是每 1TB 存储空间需要 1GB 的 RAM 。如果使用去重功能,一个经验法则是每 1TB 存储空间需要 5GB 的 RAM 用于去重。虽然一些用户在较少的 RAM 下使用 ZFS,但在负载较重的系统下可能会因内存耗尽而发生崩溃。对于 RAM 低于推荐要求的系统,可能需要进一步调整 ZFS 。
22.6.2.2. 内核配置
由于 i386™ 平台的地址空间限制, i386™ 架构上的 ZFS 用户必须将此选项添加到自定义内核配置文件中,重新构建内核并重新启动:
options KVA_PAGES=512
这将扩展内核地址空间,允许 vm.kvm_size 可调参数超过 1 GB 的限制,或者超过 PAE 的 2 GB 限制。为了找到最合适的选项值,将所需的地址空间以兆字节为单位除以四。在这个例子中,为 2 GB 选择 512。
22.6.2.3. 加载器可调参数
在所有 FreeBSD 架构上增加了 kmem 地址空间。一个具有 1 GB 物理内存的测试系统通过将这些选项添加到 /boot/loader.conf 并重新启动来受益。
vm.kmem_size="330M" vm.kmem_size_max="330M" vfs.zfs.arc.max="40M" vfs.zfs.vdev.cache.size="5M"
有关 ZFS 相关调优的更详细建议列表,请参阅 https://wiki.freebsd.org/ZFSTuningGuide 。
22.8. ZFS 功能和术语
ZFS 不仅仅是一个文件系统,它在根本上是不同的。ZFS 将文件系统和卷管理器的角色结合在一起,使新的存储设备能够添加到活动系统中,并且新的空间可以立即在该池中的现有文件系统上使用。通过结合传统上分开的角色, ZFS 能够克服以前阻止 RAID 组能够增长的限制。vdev 是池中的顶级设备,可以是简单的磁盘或 RAID 转换,如镜像或 RAID-Z 阵列。 ZFS 文件系统(称为 datasets )每个都可以访问整个池的合并空闲空间。池中使用的块会减少每个文件系统可用的空间。这种方法避免了广泛分区中常见的问题,即空闲空间在分区之间变得碎片化。
存储池是 ZFS 的最基本构建块。一个存储池由一个或多个 vdev 组成, vdev 是存储数据的底层设备。然后使用存储池来创建一个或多个文件系统(数据集)或块设备(卷)。 这些数据集和卷共享剩余的自由空间。每个存储池都有一个唯一的名称和 GUID 来进行标识。存储池上的 ZFS 版本号决定了可用的功能。 |
|||||
一个池由一个或多个 vdev 组成,它们本身是一个单独的磁盘或一组磁盘,转换为 RAID 。当使用大量的 vdev 时, ZFS 会将数据分散在 vdev 上,以提高性能和最大化可用空间。所有的 vdev 都必须至少 128MB 大小。
|
|||||
事务组是 ZFS 将块更改分组并写入池的方式。事务组是 ZFS 用来确保一致性的原子单位。 ZFS 为每个事务组分配一个唯一的 64 位连续标识符。同时可以有最多三个活动事务组,分别处于以下三种状态之一: * 打开(Open) - 新的事务组开始时处于打开状态并接受新的写入。始终有一个处于打开状态的事务组,但如果达到限制,事务组可能会拒绝新的写入。一旦打开的事务组达到限制,或达到了 |
|||||
ZFS 使用自适应替换缓存(ARC),而不是更传统的最近最少使用(LRU)缓存。LRU 缓存是一个简单的缓存项列表,按照对象最近使用的时间排序,将新项添加到列表的头部。当缓存已满时,从列表的尾部逐出项以为更活跃的对象腾出空间。 ARC 由四个列表组成:最近最常使用(MRU)对象和最频繁使用(MFU)对象,以及每个列表的幽灵列表。这些幽灵列表跟踪被逐出的对象,以防止将它们重新添加到缓存中。这通过避免具有偶尔使用历史的对象来提高缓存命中率。同时使用 MRU 和 MFU 的另一个优点是,扫描整个文件系统将逐出 MRU 或 LRU 缓存中的所有数据,以便为这些新访问的内容腾出空间。在 ZFS 中,还有一个跟踪最常使用对象的 MFU,并保留最常访问块的缓存。 |
|||||
L2ARC 是 ZFS 缓存系统的第二级。 RAM 存储主要的 ARC 。由于可用的 RAM 数量通常有限, ZFS 还可以使用 缓存 vdevs 。由于与传统的旋转硬盘相比,固态硬盘(SSD)具有更高的速度和更低的延迟,因此通常将其用作缓存设备。 L2ARC 是完全可选的,但拥有一个 L2ARC 将提高从 SSD 读取缓存文件的速度,而不必从常规磁盘读取。 L2ARC 还可以加速 去重,因为不适合 RAM 但适合 L2ARC 的去重表(DDT)比必须从磁盘读取的 DDT 快得多。对缓存设备添加的数据速率限制可以防止额外的写入过早磨损 SSD 。在缓存填满之前(为了腾出空间而驱逐的第一个块),写入 L2ARC 的限制为写入限制和增加限制的总和,之后限制为写入限制。一对 sysctl 值控制这些速率限制。 |
|||||
ZIL 通过使用比主存储池中使用的存储设备(如 SSD)更快的设备来加速同步事务。当应用程序请求同步写入(保证数据存储到磁盘而不仅仅是缓存以供以后写入时),将数据写入更快的 ZIL 存储,然后稍后将其刷新到常规磁盘上,大大降低了延迟并提高了性能。像数据库这样的同步工作负载将从 ZIL 中受益。而常规的异步写入(如复制文件)则根本不会使用 ZIL。 |
|||||
与传统的文件系统不同,ZFS 在写入数据时不会直接覆盖旧数据,而是写入一个不同的块。完成写入后,元数据会更新以指向新的位置。当发生截断写入(系统崩溃或断电导致文件写入中断)时,文件的完整原始内容仍然可用,而 ZFS 会丢弃不完整的写入。这也意味着 ZFS 在意外关闭后不需要进行 fsck(8) 操作。 |
|||||
数据集 是 ZFS 文件系统、卷、快照或克隆的通用术语。每个数据集都有一个唯一的名称,格式为 poolname/path@snapshot。池的根也是一个数据集。子数据集具有层次结构的名称,类似于目录。例如,mypool/home,即 home 数据集,是 mypool 的子数据集,并从其继承属性。通过创建 mypool/home/user,可以进一步扩展此结构。这个孙子数据集将从父级和祖父级继承属性。在子数据集上设置属性以覆盖从父级和祖父级继承的默认值。可以将数据集及其子数据集的管理 委托 给其他用户。 |
|||||
ZFS 数据集通常用作文件系统。与大多数其他文件系统一样,ZFS 文件系统会挂载到系统目录层次结构的某个位置,并包含具有权限、标志和其他元数据的文件和目录。 |
|||||
ZFS 还可以创建卷,它们会显示为磁盘设备。卷具有与数据集相似的许多功能,包括写时复制、快照、克隆和校验和。卷对于在 ZFS 上运行其他文件系统格式(如 UFS 虚拟化)或导出 iSCSI 扩展非常有用。 |
|||||
ZFS 的 写时复制 (COW)设计允许几乎瞬间创建具有任意名称的一致性快照。在对数据集进行快照或对包含所有子数据集的父数据集进行递归快照之后,新数据将进入新的块,但不会将旧块回收为可用空间。快照包含原始文件系统版本,活动文件系统包含自快照以来所做的任何更改,而不使用其他空间。写入活动文件系统的新数据使用新的块来存储这些数据。随着块在活动文件系统中不再使用,快照将增长,但仅在快照中使用。将这些快照以只读方式挂载可以恢复先前的文件版本。可以将活动文件系统回滚到特定快照的 回滚 是可能的,从而撤消在快照之后进行的任何更改。池中的每个块都有一个引用计数器,用于跟踪使用该块的快照、克隆、数据集或卷。随着文件和快照被删除,引用计数减少,当不再引用块时,回收可用空间。使用 保留 标记快照将导致任何试图销毁它的尝试返回 |
|||||
克隆快照也是可能的。克隆是快照的可写版本,允许文件系统分叉为一个新的数据集。与快照一样,克隆最初不占用新的空间。当新数据写入克隆时,使用新的块,克隆的大小增长。当在克隆的文件系统或卷中覆盖块时,先前块的引用计数减少。删除克隆所依赖的快照是不可能的,因为克隆依赖于它。快照是父级,克隆是子级。克隆可以被 提升(promoted),反转这种依赖关系,使克隆成为父级,先前的父级成为子级。此操作不需要新的空间。由于父级和子级使用的空间相互转换,可能会影响现有的配额和预留空间。 |
|||||
每个块也都有校验和。所使用的校验算法是每个数据集的属性,参见 * |
|||||
每个数据集都有一个压缩属性,默认为关闭状态。将此属性设置为可用的压缩算法。这将导致对写入数据集的所有新数据进行压缩。除了减少所使用的空间外,读写吞吐量通常也会增加,因为需要读取或写入的块较少。 * LZ4 - 在 ZFS 池版本 5000(feature flags)中添加,LZ4 现在是推荐的压缩算法。当处理可压缩数据时,LZ4 的工作速度比 LZJB 快约 50 %,处理不可压缩数据时,速度快三倍以上。LZ4 的解压速度也比 LZJB 快约 80 %。在现代 CPU 上,LZ4 通常可以以超过 500 MB/s 的速度进行压缩,并以超过 1.5 GB/s 的速度进行解压缩(每个单独的 CPU 核心)。 * LZJB - 默认的压缩算法。由 Jeff Bonwick( ZFS 的原始创建者之一)创建。与 GZIP 相比,LZJB 提供了较好的压缩效果,并且 CPU 开销较小。在将来,默认的压缩算法将更改为 LZ4 。
* GZIP - ZFS 中提供的一种流压缩算法。使用 GZIP 的主要优势之一是其可配置的压缩级别。在设置 |
|||||
当 |
|||||
在写入数据时,校验和可以检测重复的数据块。通过去重,现有相同块的引用计数增加,节省存储空间。ZFS 在内存中保留一个去重表(DDT)来检测重复的数据块。该表包含一系列唯一的校验和、这些块的位置和引用计数。在写入新数据时,ZFS 计算校验和并将其与列表进行比较。当找到匹配项时,它使用现有的数据块。使用 SHA256 校验和算法进行去重提供了安全的加密哈希。去重是可调整的。如果 |
|||||
与 fsck(8) 类似的一致性检查不同,ZFS 使用 |
|||||
ZFS 提供了快速准确的数据集、用户和组空间账户,以及配额和空间预留。这使得管理员可以对空间分配进行精细控制,并允许为关键文件系统预留空间。 ZFS 支持不同类型的配额:数据集配额、引用配额 (refquota)、用户配额 和 组配额。 配额限制了数据集及其后代的总大小,包括数据集的快照、子数据集和这些数据集的快照。
+
[NOTE]
====
卷不支持配额,因为 |
|||||
引用配额限制了数据集可以消耗的空间量,通过强制执行一个硬限制。这个硬限制包括数据集本身引用的空间,但不包括后代使用的空间,比如文件系统或快照。 |
|||||
用户配额对于限制指定用户使用的空间量非常有用。 |
|||||
群组配额限制了指定群组可以使用的空间量。 |
|||||
任何类型的预留空间在以下情况下非常有用:在新系统中规划和测试磁盘空间分配的适用性,或确保文件系统上有足够的空间用于音频日志或系统恢复程序和文件。 |
|||||
|
|||||
当替换一个故障的磁盘时, ZFS 必须用丢失的数据填充新的磁盘。重建 是使用分布在剩余驱动器上的奇偶校验信息来计算并将丢失的数据写入新驱动器的过程。 |
|||||
处于 |
|||||
如果存在足够的冗余以避免使存储池或虚拟设备进入 故障 状态,管理员会将单个设备设置为 |
|||||
处于 |
|||||
处于 |
Chapter 23. 其他文件系统
23.1. 简介
文件系统是任何操作系统的重要组成部分。它们允许用户上传和存储文件,提供对数据的访问,并使硬盘变得有用。不同的操作系统在其本机文件系统上有所不同。传统上,本机的 FreeBSD 文件系统一直是 Unix 文件系统 UFS,现已现代化为 UFS2。自 FreeBSD 7.0 以来,Z 文件系统(ZFS)也作为本机文件系统可用。有关更多信息,请参见 Z 文件系统(ZFS)。
除了本地文件系统之外,FreeBSD 还支持多种其他文件系统,以便可以本地访问来自其他操作系统的数据,例如存储在本地连接的 USB 存储设备、闪存驱动器和硬盘上的数据。这包括对 Linux® 扩展文件系统(EXT)的支持。
对于不同的文件系统,FreeBSD 提供了不同级别的支持。有些需要加载内核模块,而其他一些可能需要安装工具集。一些非本地文件系统的支持是完全读写的,而其他一些则只支持只读。
阅读完本章后,您将了解到:
-
本地文件系统和支持的文件系统之间的区别。
-
FreeBSD 支持哪些文件系统?
-
如何启用、配置、访问和使用非本机文件系统。
在阅读本章之前,您应该:
-
了解 UNIX® 和 FreeBSD 基础知识。
-
熟悉基础的 内核配置和编译。
-
在 FreeBSD 中,安装软件 会让您感到很方便。
-
对 FreeBSD 中的 磁盘、存储和设备名称有一些了解。
23.2. Linux® 文件系统
FreeBSD 提供了对多种 Linux® 文件系统的内置支持。本节介绍如何加载支持和挂载支持的 Linux® 文件系统。
23.2.1. ext2 / ext3 / ext4
自 FreeBSD 2.2 版本起,内核对 ext2 文件系统的支持已经可用。ext2fs(5) 驱动程序允许 FreeBSD 内核对 ext2、ext3 和 ext4 文件系统进行读写操作。
|
目前还不支持日志记录和加密。 |
要访问一个 ext 文件系统,通过指定其 FreeBSD 分区名称和现有的挂载点来挂载 ext 卷。这个例子将 /dev/ada1s1 挂载到 /mnt 上:
# mount -t ext2fs /dev/ada1s1 /mntChapter 24. 虚拟化
24.1. 简介
虚拟化软件允许多个操作系统同时在同一台计算机上运行。这种针对个人电脑的软件系统通常包括一个主机操作系统,它运行虚拟化软件并支持任意数量的客户操作系统。
阅读完本章后,您将了解:
-
主机操作系统和客户操作系统之间的区别。
-
如何在以下虚拟化平台上安装 FreeBSD :
-
Parallels Desktop (苹果( R ) macOS ( R ))
-
VMware Fusion (苹果( R ) macOS ( R ))
-
VirtualBox™ ( Microsoft® Windows® 、 Intel®-based Apple® macOS® 、 Linux )
-
bhyve ( FreeBSD )
-
-
如何调整 FreeBSD 系统以在虚拟化环境下获得最佳性能。
在阅读本章之前,你应该:
-
了解如何交叉引用: bsdinstall[bsdinstall ,安装 FreeBSD] 。
-
了解如何进行交叉引用:高级网络设置 [advanced-networking ,设置网络连接] 。
-
了解如何交叉引用: ports[ports ,安装额外的第三方软件] 。
24.2. 在 Parallels Desktop for macOS® 上作为客户机的 FreeBSD
Parallels Desktop for Mac ( R )是一款商业软件产品,适用于运行 macOS ( R ) 10.14.6 或更高版本的 Apple ( R ) Mac ( R )计算机。 FreeBSD 是一个完全支持的客户操作系统。一旦在 macOS ( R )上安装了 Parallels ,用户必须配置一个虚拟机,然后安装所需的客户操作系统。
24.2.1. 在 Mac 上使用 Parallels Desktop 安装 FreeBSD
在 Parallels 上安装 FreeBSD 的第一步是创建一个新的虚拟机来安装 FreeBSD 。
选择菜单:从 DVD 或镜像文件安装 Windows 或其他操作系统 [] ,然后继续。
选择 FreeBSD 镜像文件。
选择菜单:其他作为操作系统 [] 。
|
选择 FreeBSD 会导致启动时出现引导错误。 |
命名虚拟机并在安装之前检查菜单:自定义设置 []
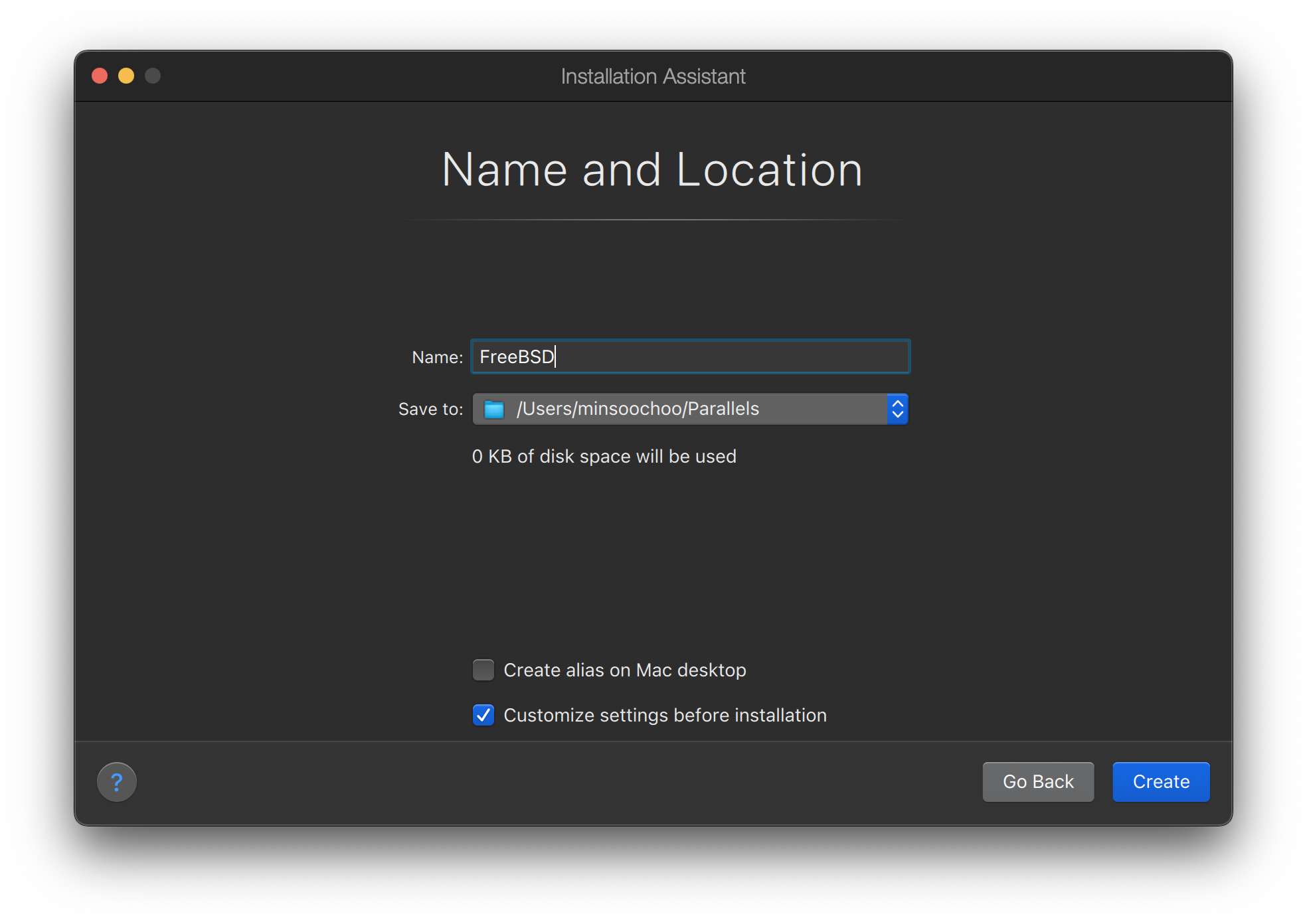
当配置窗口弹出时,转到菜单:硬件 [] 选项卡,选择菜单:启动顺序 [] ,然后点击菜单:高级 [] 。然后,选择 *EFI 64 位 * 作为菜单: BIOS[] 。
点击菜单:确定 [] ,关闭配置窗口,然后点击菜单:继续 [] 。
虚拟机将自动启动。按照通用步骤安装 FreeBSD 。
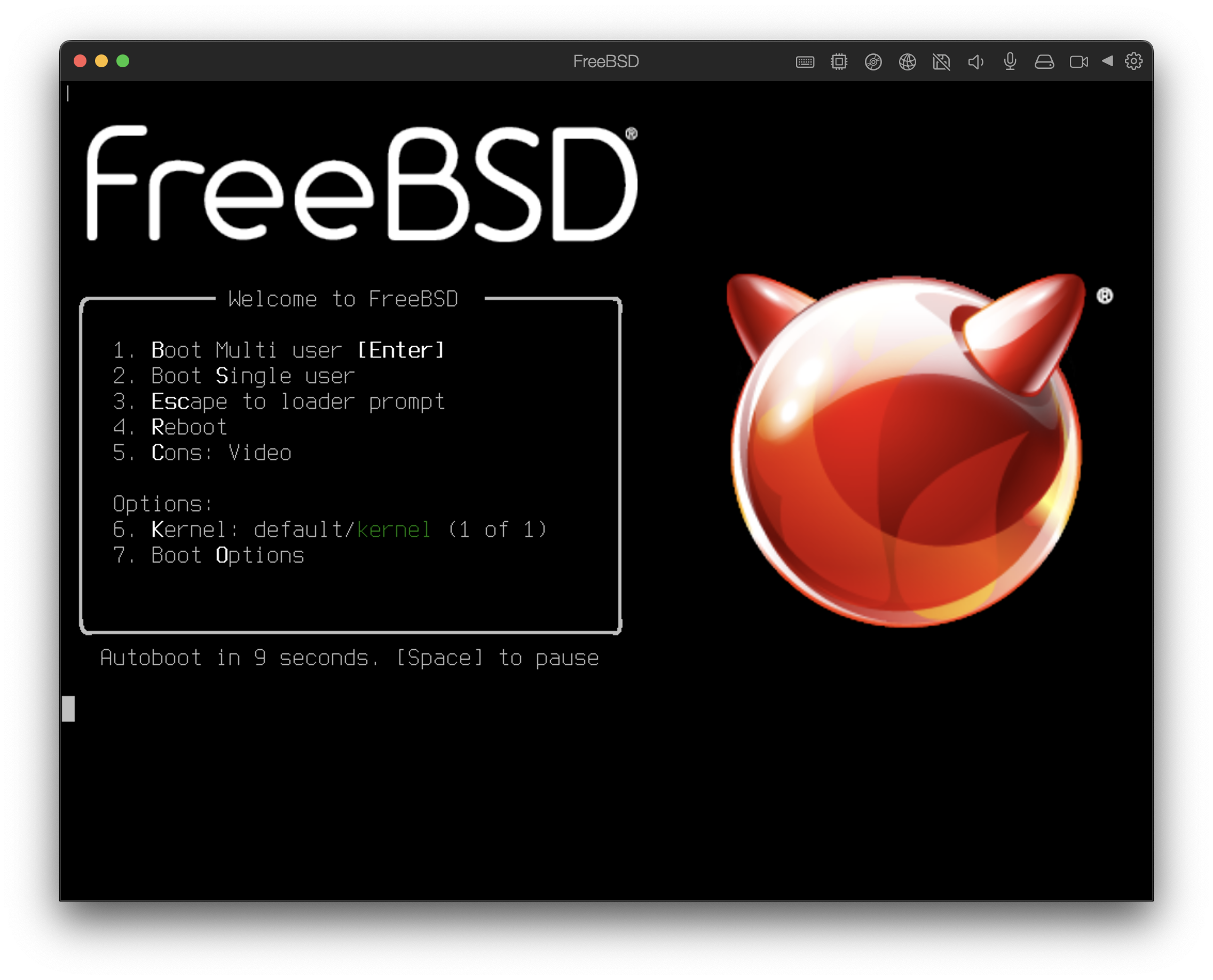
24.2.2. 在 Parallels 上配置 FreeBSD
在使用 Parallels 在 macOS® X 上成功安装 FreeBSD 之后,可以采取一些配置步骤来优化系统以进行虚拟化操作。
-
设置引导加载程序变量
最重要的步骤是减少在 Parallels 环境下 FreeBSD 的 CPU 利用率,方法是将
kern.hz可调参数降低。通过在 /boot/loader.conf 文件中添加以下行来实现:kern.hz=100
如果没有这个设置,一个空闲的 FreeBSD Parallels 虚拟机将会占用大约一个处理器 iMac® 的 15% 的 CPU 。在进行这个更改后,使用率将会接近 5% 。
-
创建一个新的内核配置文件
-
配置网络
24.3. 在 macOS 上使用 VMware Fusion 作为客户机的 FreeBSD
VMware Fusion for Mac ( R )是一款商业软件产品,适用于运行 macOS ( R ) 12 或更高版本的 Apple ( R ) Mac ( R )计算机。 FreeBSD 是一个完全支持的客户操作系统。一旦在 macOS ( R )上安装了 VMware Fusion ,用户可以配置虚拟机,然后安装所需的客户操作系统。
24.3.1. 在 VMware Fusion 上安装 FreeBSD
第一步是启动 VMware Fusion ,它将加载虚拟机库。点击【+ → 新建】来创建虚拟机:
这将加载新的虚拟机助手。选择【创建自定义虚拟机】并点击【继续】以继续:
在提示时,选择 [.guimenuitem]# 其他 # 作为 [.guimenuitem]# 操作系统 # ,并选择 或 [.guimenuitem]#FreeBSD X 64 位 # 作为菜单 : 版本 [] 。
选择固件(推荐使用 UEFI ):
选择 [.guimenuitem]# 创建新的虚拟磁盘 # 并点击 [.guimenuitem]# 继续 # :
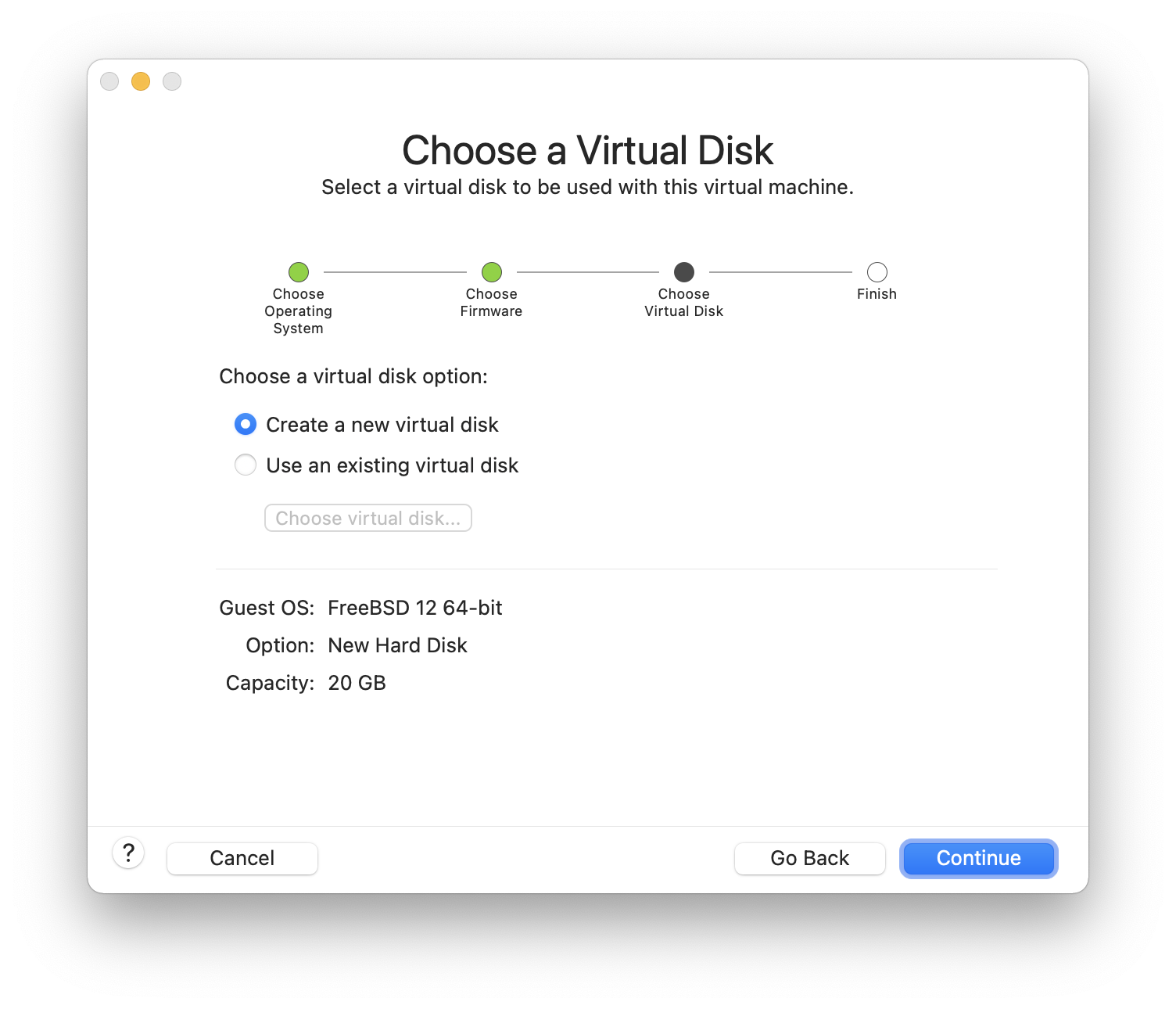
检查配置并点击 [.guimenuitem]# 完成 # 。
选择虚拟机的名称和保存的目录:
按下 Command + E 打开虚拟机设置,然后点击 。
选择 FreeBSD ISO 镜像或者从 CD/DVD 中选择:
启动虚拟机:
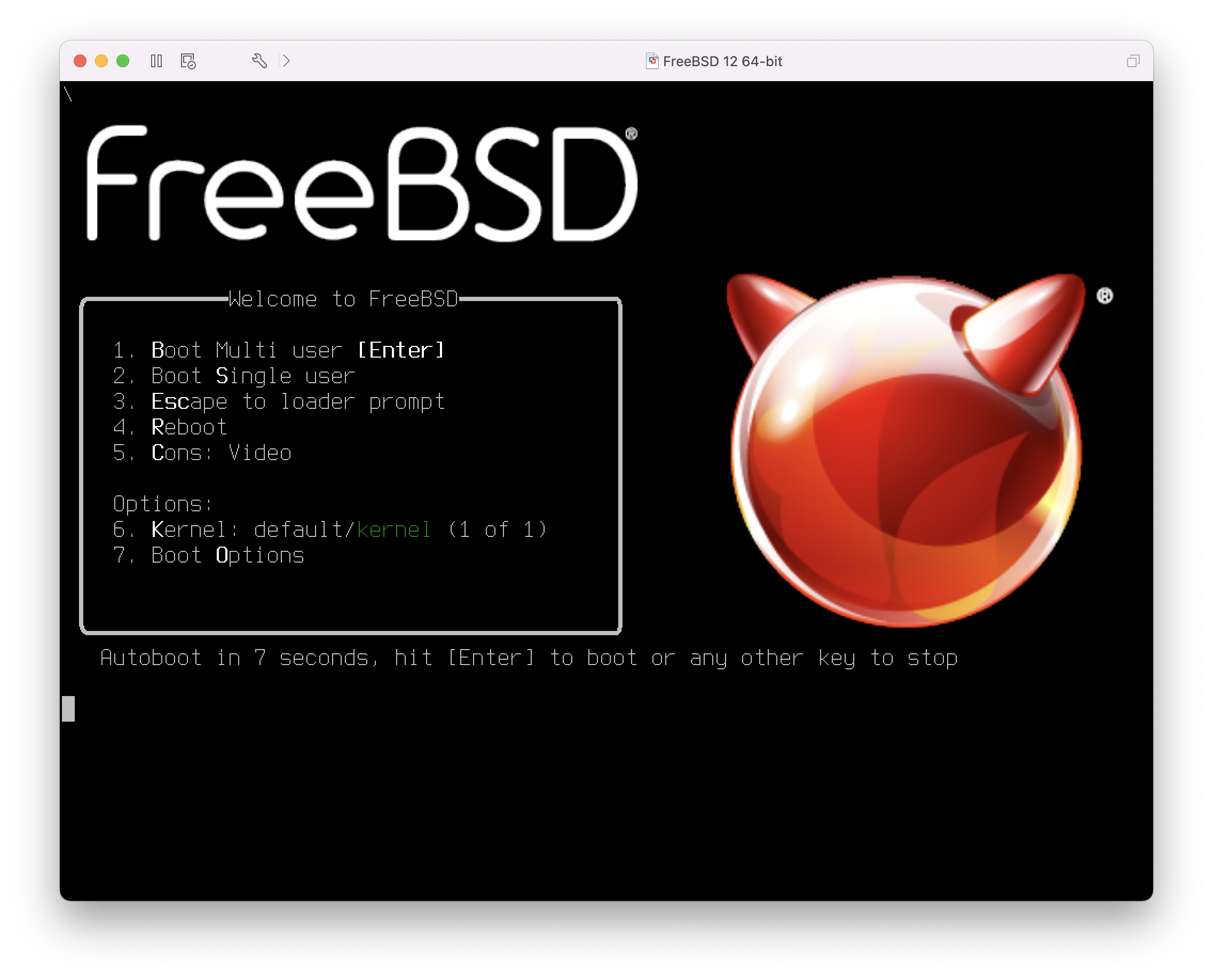
按照通常的方式安装 FreeBSD :
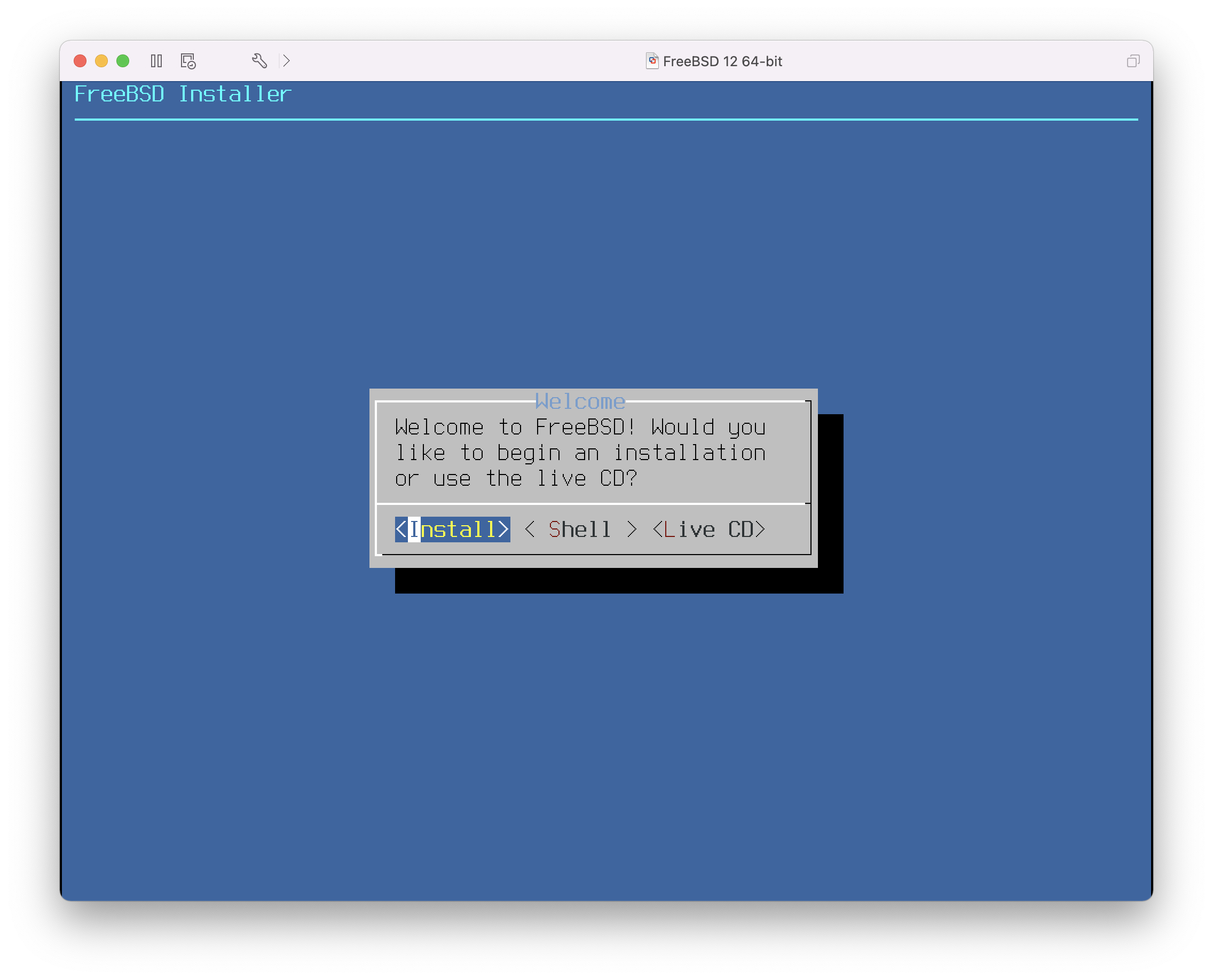
安装完成后,可以修改虚拟机的设置,例如内存使用量和虚拟机可以访问的 CPU 数量。
|
虚拟机运行时无法修改虚拟机的系统硬件设置。 |
CD-ROM 设备的状态。通常,当虚拟机不再需要 CD/DVD/ISO 时,它会与之断开连接。
最后需要更改的是虚拟机如何连接到网络。为了允许虚拟机与主机以外的其他机器进行连接,选择 [.guimenuitem]# 直接连接物理网络(桥接) # 。否则,推荐选择 [.guimenuitem]# 共享主机的互联网连接( NAT ) # ,这样虚拟机可以访问互联网,但网络无法访问虚拟机。
修改设置后,启动新安装的 FreeBSD 虚拟机。
24.3.2. 在 VMware Fusion 上配置 FreeBSD
在使用 VMware Fusion 成功安装 FreeBSD 到 macOS® X 之后,可以采取一些配置步骤来优化系统以进行虚拟化操作。
-
设置引导加载程序变量
最重要的步骤是在 VMware Fusion 环境下减少 FreeBSD 的 CPU 利用率,方法是将
kern.hz可调参数降低。通过在 [/boot/loader.conf] 文件中添加以下行来实现:kern.hz=100
如果没有这个设置,一个空闲的 FreeBSD VMware Fusion 客户机将使用大约 15% 的单处理器 iMac® 的 CPU 。在进行这个更改之后,使用率将接近 5% 。
-
创建一个新的内核配置文件
-
配置网络
最基本的网络设置使用 DHCP 将虚拟机连接到与主机 Mac® 相同的局域网。可以通过在
/etc/rc.conf文件中添加ifconfig_em0 ="DHCP"来实现。更高级的网络设置在《高级网络设置》中有描述。 -
安装驱动程序和 open-vm-tools
要在 VMWare 上顺畅运行 FreeBSD ,需要安装驱动程序:
# pkg install xf86-video-vmware xf86-input-vmmouse open-vm-tools
24.4. 在 VirtualBox™ 上作为客户机的 FreeBSD
FreeBSD 在 VirtualBox™ 中作为客户机运行良好。这款虚拟化软件适用于大多数常见操作系统,包括 FreeBSD 本身。
VirtualBox™ 客户机附加组件提供以下支持:
-
剪贴板共享。
-
鼠标指针集成。
-
主机时间同步。
-
窗口缩放。
-
无缝模式。
|
这些命令在 FreeBSD 虚拟机中运行。 |
首先,在 FreeBSD 客户机中安装包: emulators/virtualbox-ose-additions[] 。这将安装端口:
# cd /usr/ports/emulators/virtualbox-ose-additions && make install clean将以下行添加到 [/etc/rc.conf] 文件中:
vboxguest_enable="YES" vboxservice_enable="YES"
如果使用 ntpd(8) 或 ntpdate(8) ,请禁用主机时间同步:
vboxservice_flags="--disable-timesync"
Xorg 会自动识别 vboxvideo 驱动程序。也可以在 /etc/X11/xorg.conf 文件中手动输入。
Section "Device" Identifier "Card0" Driver "vboxvideo" VendorName "InnoTek Systemberatung GmbH" BoardName "VirtualBox Graphics Adapter" EndSection
要使用 vboxmouse 驱动程序,请在 /etc/X11/xorg.conf 中调整鼠标部分。
Section "InputDevice" Identifier "Mouse0" Driver "vboxmouse" EndSection
通过使用 mount_vboxvfs 挂载,可以访问主机和虚拟机之间的共享文件夹进行文件传输。可以使用 VirtualBox GUI 或通过 vboxmanage 在主机上创建共享文件夹。例如,要在名为_BSDBox_的虚拟机下创建一个名为_myshare_的共享文件夹,位于 /mnt/bsdboxshare ,运行以下命令:
# vboxmanage sharedfolder add 'BSDBox' --name myshare --hostpath /mnt/bsdboxshare请注意,共享文件夹的名称不能包含空格。在虚拟机中挂载共享文件夹的方法如下:
# mount_vboxvfs -w myshare /mnt24.5. 使用 VirtualBox™ 将 FreeBSD 作为主机
VirtualBox™ 是一个积极开发的完整虚拟化软件包,适用于包括 Windows® 、 macOS® 、 Linux® 和 FreeBSD 在内的大多数操作系统。它能够同样运行 Windows® 或类 UNIX® 的客户机。它以开源软件的形式发布,但也有一些闭源组件可在单独的扩展包中获取。这些组件包括对 USB 2.0 设备的支持。有关更多信息,请参阅 VirtualBox™ 维基的 下载页面 。目前,这些扩展在 FreeBSD 上不可用。
24.5.1. 安装 VirtualBox™
VirtualBox™ 可以作为 FreeBSD 的一个软件包或端口在 emulators/virtualbox-ose 中获得。可以使用以下命令安装该端口:
# cd /usr/ports/emulators/virtualbox-ose
# make install clean端口配置菜单中的一个有用选项是“ GuestAdditions ”程序套件。这些程序在客户操作系统中提供了许多有用的功能,如鼠标指针集成(允许鼠标在主机和客户之间共享,无需按特殊的键盘快捷键切换)和更快的视频渲染,尤其是在 Windows® 客户中。在客户安装完成后,可以在菜单 : 设备 [] 菜单中找到客户附加组件。
在首次启动 VirtualBox™ 之前,需要进行一些配置更改。该端口会在 /boot/modules 中安装一个内核模块,必须将其加载到正在运行的内核中:
# kldload vboxdrv为了确保模块在重新启动后始终加载,将以下行添加到 [/boot/loader.conf] 文件中:
vboxdrv_load="YES"
要使用允许桥接或仅主机网络的内核模块,请将以下行添加到 [/etc/rc.conf] 文件中,并重新启动计算机:
vboxnet_enable="YES"
在安装 VirtualBox™ 时会创建 vboxusers 组。所有需要访问 VirtualBox™ 的用户都必须添加为该组的成员。可以使用 pw 命令来添加新成员:
# pw groupmod vboxusers -m yourusername/dev/vboxnetctl 的默认权限很严格,需要更改以支持桥接网络:
# chown root:vboxusers /dev/vboxnetctl
# chmod 0660 /dev/vboxnetctl要使此权限更改永久生效,请将以下行添加到 /etc/devfs.conf 文件中:
own vboxnetctl root:vboxusers perm vboxnetctl 0660
要启动 VirtualBox™ ,请在 Xorg 会话中输入以下命令:
% VirtualBox有关配置和使用 VirtualBox™ 的更多信息,请参阅 官方网站 。有关 FreeBSD 特定信息和故障排除说明,请参阅 FreeBSD wiki 中的相关页面 。
24.5.2. VirtualBox™ USB 支持
VirtualBox™ 可以配置为将 USB 设备传递给客户操作系统。 OSE 版本的主机控制器仅限于模拟 USB 1.1 设备,直到支持 USB 2.0 和 3.0 设备的扩展包在 FreeBSD 上可用为止。
要使 VirtualBox™ 能够识别连接到计算机的 USB 设备,用户需要是 operator 组的成员。
# pw groupmod operator -m yourusername然后,将以下内容添加到 /etc/devfs.rules 中,如果该文件尚不存在,则创建该文件:
[system=10] add path 'usb/*' mode 0660 group operator
要加载这些新规则,请将以下内容添加到 [/etc/rc.conf] 文件中:
devfs_system_ruleset="system"
然后,重新启动 devfs :
# service devfs restart重新启动登录会话和 VirtualBox™ 以使这些更改生效,并根据需要创建 USB 过滤器。
24.5.3. VirtualBox™ 主机 DVD/CD 访问
通过共享物理驱动器,可以实现从虚拟机访问主机的 DVD/CD 驱动器。在 VirtualBox™ 中,可以在虚拟机的设置中的存储窗口中进行设置。如果需要,首先创建一个空的 IDECD/DVD 设备。然后从弹出菜单中选择主机驱动器作为虚拟 CD/DVD 驱动器的选择。将会出现一个名为“ Passthrough ”的复选框。这允许虚拟机直接使用硬件。例如,只有在选择了此选项后,音频 CD 或刻录机才能正常工作。
为了使用户能够使用 VirtualBox™ 的 DVD/CD 功能,他们需要访问 /dev/xpt0 、 /dev/cdN 和 /dev/passN 。通常通过将用户添加到 operator 组来实现此目的。需要通过在 /etc/devfs.conf 中添加以下行来更正对这些设备的权限:
perm cd* 0660 perm xpt0 0660 perm pass* 0660
# service devfs restart24.6. 使用 bhyve 作为 FreeBSD 主机
bhyve 是一个基于 BSD 许可的虚拟机监控程序,自 FreeBSD 10.0-RELEASE 版本起成为基础系统的一部分。该虚拟机监控程序支持多种客户操作系统,包括 FreeBSD 、 OpenBSD 和许多 Linux® 发行版。默认情况下, bhyve 提供串行控制台访问,并不模拟图形控制台。它利用较新的 CPU 的虚拟化卸载功能,避免了传统的指令转换和手动管理内存映射的方法。
bhyve 设计要求处理器支持 Intel® 扩展页表 (EPT) 或 AMD® 快速虚拟化索引 (RVI) 或嵌套页表 (NPT) 。托管具有多个虚拟 CPU 的 Linux® 客户机或 FreeBSD 客户机需要 VMX 无限制模式支持 (UG) 。大多数较新的处理器,特别是 Intel® Core™ i3/i5/i7 和 Intel® Xeon™ E3/E5/E7 ,都支持这些功能。 UG 支持是在 Intel 的 Westmere 微架构中引入的。有关支持 EPT 的 Intel® 处理器的完整列表,请参阅 https://ark.intel.com/content/www/us/en/ark/search/featurefilter.html ? productType = 873 & 0_ExtendedPageTables = True[] 。 RVI 出现在第三代及以后的 AMD Opteron™(Barcelona) 处理器上。判断处理器是否支持 bhyve 的最简单方法是运行 dmesg 命令或在 AMD® 处理器的 Features2 行上查找 POPCNT 处理器特性标志,或在 Intel® 处理器的 VT-x 行上查找 EPT 和 UG 。
24.6.1. 准备主机
在 bhyve 中创建虚拟机的第一步是配置主机系统。首先,加载 bhyve 内核模块:
# kldload vmm然后,在虚拟机中为网络设备创建一个名为 tap 的接口,以便连接到该接口。为了使网络设备能够参与网络通信,还需创建一个桥接接口,其中包含 tap 接口和物理接口作为成员。在这个例子中,物理接口是 igb0。
# ifconfig tap0 create
# sysctl net.link.tap.up_on_open=1
net.link.tap.up_on_open: 0 -> 1
# ifconfig bridge0 create
# ifconfig bridge0 addm igb0 addm tap0
# ifconfig bridge0 up24.6.2. 创建一个 FreeBSD 虚拟机
创建一个文件作为虚拟磁盘用于客户机。指定虚拟磁盘的大小和名称:
# truncate -s 16G guest.img下载一个 FreeBSD 的安装镜像来进行安装:
# fetch https://download.freebsd.org/releases/ISO-IMAGES/13.1/FreeBSD-13.1-RELEASE-amd64-bootonly.iso
FreeBSD-13.1-RELEASE-amd64-bootonly.iso 366 MB 16 MBps 22sFreeBSD 附带了一个示例脚本,用于在 bhyve 中运行虚拟机。该脚本将启动虚拟机并在循环中运行,因此如果虚拟机崩溃,它将自动重新启动。脚本接受多个选项来控制机器的配置: -c 控制虚拟 CPU 的数量, -m 限制可用于客户机的内存量, -t 定义要使用的 tap 设备, -d 指示要使用的磁盘映像, -i 告诉 bhyve 从 CD 映像而不是磁盘启动, -I 定义要使用的 CD 映像。最后一个参数是虚拟机的名称,用于跟踪正在运行的虚拟机。此示例在安装模式下启动虚拟机:
# sh /usr/share/examples/bhyve/vmrun.sh -c 1 -m 1024M -t tap0 -d guest.img -i -I FreeBSD-13.1-RELEASE-amd64-bootonly.iso guestname虚拟机将启动并开始安装程序。在虚拟机中安装系统后,当系统在安装结束时询问是否进入 shell ,请选择“是”。
重新启动虚拟机。虚拟机重新启动会导致 bhyve 退出,但是 vmrun.sh 脚本会在循环中运行 bhyve 并自动重新启动它。当这种情况发生时,选择从引导加载程序菜单中的重新启动选项以退出循环。现在可以从虚拟磁盘启动客户机。
# sh /usr/share/examples/bhyve/vmrun.sh -c 4 -m 1024M -t tap0 -d guest.img guestname24.6.3. 创建一个 Linux® 虚拟机
为了引导除 FreeBSD 之外的操作系统,必须首先安装 sysutils/grub2-bhyve 端口。
接下来,创建一个文件作为虚拟磁盘用于客户机。
# truncate -s 16G linux.img使用 bhyve 启动虚拟机是一个两步骤的过程。首先必须加载内核,然后才能启动客户机。使用 sysutils/grub2-bhyve 加载 Linux® 内核。创建一个 device.map ,供 grub 使用,将虚拟设备映射到主机系统上的文件。
(hd0) ./linux.img (cd0) ./somelinux.iso
使用包: sysutils/grub2-bhyve[] 从 ISO 镜像中加载 Linux® 内核:
# grub-bhyve -m device.map -r cd0 -M 1024M linuxguest这将启动 grub 。如果安装 CD 包含一个 grub.cfg 文件,将显示一个菜单。如果没有,必须手动定位并加载 vmlinuz 和 initrd 文件:
grub> ls
(hd0) (cd0) (cd0,msdos1) (host)
grub> ls (cd0)/isolinux
boot.cat boot.msg grub.conf initrd.img isolinux.bin isolinux.cfg memtest
splash.jpg TRANS.TBL vesamenu.c32 vmlinuz
grub> linux (cd0)/isolinux/vmlinuz
grub> initrd (cd0)/isolinux/initrd.img
grub> boot现在 Linux® 内核已经加载完毕,可以启动虚拟机了:
# bhyve -A -H -P -s 0:0,hostbridge -s 1:0,lpc -s 2:0,virtio-net,tap0 -s 3:0,virtio-blk,./linux.img \
-s 4:0,ahci-cd,./somelinux.iso -l com1,stdio -c 4 -m 1024M linuxguest系统将启动并启动安装程序。在虚拟机中安装系统后,重新启动虚拟机。这将导致 bhyve 退出。在可以再次启动之前,需要销毁虚拟机的实例。
# bhyvectl --destroy --vm=linuxguest现在可以直接从虚拟磁盘启动客户机。加载内核:
# grub-bhyve -m device.map -r hd0,msdos1 -M 1024M linuxguest
grub> ls
(hd0) (hd0,msdos2) (hd0,msdos1) (cd0) (cd0,msdos1) (host)
(lvm/VolGroup-lv_swap) (lvm/VolGroup-lv_root)
grub> ls (hd0,msdos1)/
lost+found/ grub/ efi/ System.map-2.6.32-431.el6.x86_64 config-2.6.32-431.el6.x
86_64 symvers-2.6.32-431.el6.x86_64.gz vmlinuz-2.6.32-431.el6.x86_64
initramfs-2.6.32-431.el6.x86_64.img
grub> linux (hd0,msdos1)/vmlinuz-2.6.32-431.el6.x86_64 root=/dev/mapper/VolGroup-lv_root
grub> initrd (hd0,msdos1)/initramfs-2.6.32-431.el6.x86_64.img
grub> boot启动虚拟机:
# bhyve -A -H -P -s 0:0,hostbridge -s 1:0,lpc -s 2:0,virtio-net,tap0 \
-s 3:0,virtio-blk,./linux.img -l com1,stdio -c 4 -m 1024M linuxguestLinux® 现在将在虚拟机中启动,并最终呈现给您登录提示符。登录并使用虚拟机。完成后,重新启动虚拟机以退出 bhyve 。销毁虚拟机实例:
# bhyvectl --destroy --vm=linuxguest24.6.4. 使用 UEFI 固件引导 bhyve 虚拟机
除了 bhyveload 和 grub-bhyve 之外, bhyve 虚拟机监视器还可以使用 UEFI 用户空间固件引导虚拟机。这个选项可能支持其他加载器不支持的客户操作系统。
为了在 bhyve 中使用 UEFI 支持,首先需要获取 UEFI 固件镜像。可以通过安装 sysutils/bhyve-firmware 端口或包来完成。
在固件安装完成后,将标志 -l bootrom ,/path/to/firmware 添加到您的 bhyve 命令行中。实际的 bhyve 命令可能如下所示:
# bhyve -AHP -s 0:0,hostbridge -s 1:0,lpc \
-s 2:0,virtio-net,tap1 -s 3:0,virtio-blk,./disk.img \
-s 4:0,ahci-cd,./install.iso -c 4 -m 1024M \
-l bootrom,/usr/local/share/uefi-firmware/BHYVE_UEFI.fd \
guestsysutils/bhyve-firmware 还包含一个启用了 CSM 的固件,用于以传统 BIOS 模式启动不支持 UEFI 的虚拟机:
# bhyve -AHP -s 0:0,hostbridge -s 1:0,lpc \
-s 2:0,virtio-net,tap1 -s 3:0,virtio-blk,./disk.img \
-s 4:0,ahci-cd,./install.iso -c 4 -m 1024M \
-l bootrom,/usr/local/share/uefi-firmware/BHYVE_UEFI_CSM.fd \
guest24.6.5. bhyve 客户机的图形 UEFI 帧缓冲
UEFI 固件支持对于主要以图形为主的客户操作系统(如 Microsoft Windows® )特别有用。
还可以使用 -s 29 , fbuf , tcp =0.0.0.0:5900 标志来启用对 UEFI-GOP 帧缓冲的支持。可以使用 w =800 和 h =600 来配置帧缓冲的分辨率,并且可以通过添加 wait 来指示 bhyve 在启动客户机之前等待 VNC 连接。帧缓冲可以通过主机或通过 VNC 协议通过网络访问。此外,还可以添加 -s 30 , xhci , tablet 以实现与主机的精确鼠标光标同步。
生成的 bhyve 命令将如下所示:
# bhyve -AHP -s 0:0,hostbridge -s 31:0,lpc \
-s 2:0,virtio-net,tap1 -s 3:0,virtio-blk,./disk.img \
-s 4:0,ahci-cd,./install.iso -c 4 -m 1024M \
-s 29,fbuf,tcp=0.0.0.0:5900,w=800,h=600,wait \
-s 30,xhci,tablet \
-l bootrom,/usr/local/share/uefi-firmware/BHYVE_UEFI.fd \
guest注意,在 BIOS 仿真模式下,一旦控制权从固件转移到客户操作系统,帧缓冲将停止接收更新。
24.6.6. 使用 ZFS 与 bhyve 虚拟机
如果主机上可用 ZFS ,使用 ZFS 卷而不是磁盘映像文件可以为客户机提供显著的性能优势。可以通过以下方式创建 ZFS 卷:
# zfs create -V16G -o volmode=dev zroot/linuxdisk0在启动虚拟机时,将 ZFS 卷指定为磁盘驱动器:
# bhyve -A -H -P -s 0:0,hostbridge -s 1:0,lpc -s 2:0,virtio-net,tap0 -s3:0,virtio-blk,/dev/zvol/zroot/linuxdisk0 \
-l com1,stdio -c 4 -m 1024M linuxguest24.6.7. 虚拟机控制台
将 bhyve 控制台包装在会话管理工具(如 sysutils/tmux 或 sysutils/screen )中是有优势的,这样可以分离和重新连接到控制台。还可以将 bhyve 的控制台设置为一个空调制解调器设备,可以使用 cu 访问。为此,加载 nmdm 内核模块,并将 -l com1 , stdio 替换为 -l com1 , /dev/nmdm0A 。 /dev/nmdm 设备会根据需要自动创建,每个设备都是一对,对应于空调制解调器电缆的两端( /dev/nmdm0A 和 /dev/nmdm0B )。有关更多信息,请参阅 nmdm(4) 。
# kldload nmdm
# bhyve -A -H -P -s 0:0,hostbridge -s 1:0,lpc -s 2:0,virtio-net,tap0 -s 3:0,virtio-blk,./linux.img \
-l com1,/dev/nmdm0A -c 4 -m 1024M linuxguest
# cu -l /dev/nmdm0B
Connected
Ubuntu 13.10 handbook ttyS0
handbook login:24.6.8. 管理虚拟机
每个虚拟机都在 /dev/vmm 目录下创建了一个设备节点。这样管理员就可以轻松地查看正在运行的虚拟机列表。
# ls -al /dev/vmm
total 1
dr-xr-xr-x 2 root wheel 512 Mar 17 12:19 ./
dr-xr-xr-x 14 root wheel 512 Mar 17 06:38 ../
crw------- 1 root wheel 0x1a2 Mar 17 12:20 guestname
crw------- 1 root wheel 0x19f Mar 17 12:19 linuxguest
crw------- 1 root wheel 0x1a1 Mar 17 12:19 otherguest可以使用 bhyvectl 命令销毁指定的虚拟机:
# bhyvectl --destroy --vm=guestname24.7. FreeBSD 作为 Xen™ 主机
Xen 是一种基于 GPLv2 许可的 1 型虚拟化监控程序 ,适用于 Intel® 和 ARM® 架构。 FreeBSD 自 8.0 版本起包含了 i386™ 和 AMD® 64 位 DomU 以及 Amazon EC2 非特权域(虚拟机)支持,并在 FreeBSD 11.0 中增加了 Dom0 控制域(主机)支持。在 FreeBSD 11 中,对于半虚拟化( PV )域的支持已被移除,取而代之的是硬件虚拟化( HVM )域,这提供了更好的性能。
Xen™ 是一个裸金属虚拟化监控程序,这意味着它是在 BIOS 之后加载的第一个程序。然后启动一个特殊的特权客户机,称为 Domain-0 (简称为 Dom0 )。 Dom0 利用其特权直接访问底层物理硬件,使其成为高性能解决方案。它能够直接访问磁盘控制器和网络适配器。 Dom0 还使用 Xen™ 管理工具来管理和控制 Xen™ 虚拟化监控程序,创建、列出和销毁虚拟机( VMs )。 Dom0 为非特权域(通常称为 DomU )提供虚拟磁盘和网络。 Xen™ Dom0 可以与其他虚拟化监控程序解决方案的服务控制台进行比较,而 DomU 是运行各个客户机虚拟机的地方。
Xen™ 可以在不同的 Xen™ 服务器之间迁移虚拟机。当两个 Xen 主机共享相同的底层存储时,迁移可以在不必先关闭虚拟机的情况下进行。相反,迁移是在 DomU 运行时进行的,无需重新启动或计划停机时间。这在维护场景或升级窗口中非常有用,以确保 DomU 提供的服务仍然可用。 Xen™ 的许多其他功能列在 Xen Wiki 概述页面 上。请注意,目前并非所有功能都在 FreeBSD 上受支持。
24.7.1. Xen™ Dom0 的硬件要求
要在主机上运行 Xen™ 虚拟机监视器,需要一定的硬件功能。硬件虚拟化域需要主机处理器支持扩展页表( EPT )和输入 / 输出内存管理单元( IOMMU )。
|
为了运行 FreeBSD Xen™ Dom0 ,必须使用传统引导( BIOS )启动该设备。 |
24.7.2. Xen™ Dom0 控制域设置
FreeBSD 11 的用户应安装基于 Xen 4.7 版本的包: emulators/xen-kernel47[] 和包: sysutils/xen-tools47[] 。运行在 FreeBSD-12.0 或更新版本上的系统可以分别使用基于 Xen 4.11 的包: emulators/xen-kernel411[] 和包: sysutils/xen-tools411[] 。
在安装 Xen 软件包后,必须编辑配置文件以准备主机进行 Dom0 集成。在 [/etc/sysctl.conf] 中添加条目可以禁用内存页面的限制。否则,具有较高内存需求的 DomU 虚拟机将无法运行。
# echo 'vm.max_wired=-1' >> /etc/sysctl.conf另一个与内存相关的设置涉及更改 /etc/login.conf ,将 memorylocked 选项设置为 unlimited 。否则,创建 DomU 域可能会失败,并显示 Cannot allocate memory 错误。在对 /etc/login.conf 进行更改后,运行 cap_mkdb 以更新能力数据库。有关详细信息,请参阅 资源限制 。
# sed -i '' -e 's/memorylocked=64K/memorylocked=unlimited/' /etc/login.conf
# cap_mkdb /etc/login.conf在 /etc/ttys 中添加一个 Xen™ 控制台的条目:
# echo 'xc0 "/usr/libexec/getty Pc" xterm onifconsole secure' >> /etc/ttys在 /boot/loader.conf 中选择一个 Xen™ 内核会激活 Dom0 。 Xen™ 还需要来自主机机器的 CPU 和内存资源,用于自身和其他 DomU 域。 CPU 和内存的数量取决于个体需求和硬件能力。在这个例子中,为 Dom0 提供了 8 GB 的内存和 4 个虚拟 CPU 。串行控制台也被激活,并定义了日志选项。
以下命令用于 Xen 4.7 软件包:
# echo 'hw.pci.mcfg=0' >> /boot/loader.conf
# echo 'if_tap_load="YES"' >> /boot/loader.conf
# echo 'xen_kernel="/boot/xen"' >> /boot/loader.conf
# echo 'xen_cmdline="dom0_mem=8192M dom0_max_vcpus=4 dom0pvh=1 console=com1,vga com1=115200,8n1 guest_loglvl=all loglvl=all"' >> /boot/loader.conf对于 Xen 版本 4.11 及更高版本,应使用以下命令:
# echo 'if_tap_load="YES"' >> /boot/loader.conf
# echo 'xen_kernel="/boot/xen"' >> /boot/loader.conf
# echo 'xen_cmdline="dom0_mem=8192M dom0_max_vcpus=4 dom0=pvh console=com1,vga com1=115200,8n1 guest_loglvl=all loglvl=all"' >> /boot/loader.conf|
Xen™ 为 DomU 虚拟机创建的日志文件存储在 [/var/log/xen] 目录中。如果遇到问题,请务必检查该目录的内容。 |
在系统启动时激活 xencommons 服务:
# sysrc xencommons_enable=yes这些设置足以启动一个启用了 Dom0 的系统。然而,它缺乏用于 DomU 虚拟机的网络功能。为了解决这个问题,需要定义一个桥接接口,使用系统的主要网络接口(主机网络接口名称替换为_em0_),以便 DomU 虚拟机可以连接到网络。
# sysrc cloned_interfaces="bridge0"
# sysrc ifconfig_bridge0="addm em0 SYNCDHCP"
# sysrc ifconfig_em0="up"重新启动主机以加载 Xen™ 内核并启动 Dom0 。
# reboot在成功启动 Xen™ 内核并再次登录系统后,使用 Xen™ 管理工具 xl 来显示有关域的信息。
# xl list
Name ID Mem VCPUs State Time(s)
Domain-0 0 8192 4 r----- 962.0输出确认了 Dom0 (称为 Domain-0 )的 ID 为 0 并且正在运行。它还具有之前在 /boot/loader.conf 中定义的内存和虚拟 CPU 。更多信息可以在 Xen™ 文档 中找到。现在可以创建 DomU 客户机虚拟机。
24.7.3. Xen™ DomU 客户机虚拟机配置
非特权域由配置文件和虚拟或物理硬盘组成。 DomU 的虚拟磁盘存储可以是由 truncate(1) 创建的文件,也可以是 中描述的 ZFS 卷。 在此示例中,使用了一个 20 GB 的卷。 使用 ZFS 卷、 FreeBSD ISO 映像、 1 GB 的 RAM 和两个虚拟 CPU 创建了一个虚拟机。 ISO 安装文件使用 fetch(1) 获取,并保存在名为 freebsd.iso 的本地文件中。
# fetch https://download.freebsd.org/releases/ISO-IMAGES/13.1/FreeBSD-13.1-RELEASE-amd64-bootonly.iso -o freebsd.iso创建了一个名为 xendisk0 的 20 GB ZFS 卷,用作虚拟机的磁盘空间。
# zfs create -V20G -o volmode=dev zroot/xendisk0新的 DomU 客户机虚拟机在一个文件中定义。一些特定的定义,如名称、键盘映射和 VNC 连接详细信息也被定义。以下是一个示例的最小 DomU 配置的 freebsd.cfg 文件内容:
# cat freebsd.cfg
builder = "hvm" (1)
name = "freebsd" (2)
memory = 1024 (3)
vcpus = 2 (4)
vif = [ 'mac=00:16:3E:74:34:32,bridge=bridge0' ] (5)
disk = [
'/dev/zvol/tank/xendisk0,raw,hda,rw', (6)
'/root/freebsd.iso,raw,hdc:cdrom,r' (7)
]
vnc = 1 (8)
vnclisten = "0.0.0.0"
serial = "pty"
usbdevice = "tablet"这些行将被更详细地解释:
| 1 | 这定义了要使用的虚拟化类型。 hvm 指的是硬件辅助虚拟化或硬件虚拟机。客户操作系统可以在具有虚拟化扩展的 CPU 上无需修改即可运行,提供与在物理硬件上运行几乎相同的性能。 generic 是默认值,创建一个 PV 域。 <.> 虚拟机的名称,用于区分在同一 Dom0 上运行的其他虚拟机。必填项。 <.> 分配给虚拟机的内存数量,以兆字节为单位。此数量从超级监视程序的总可用内存中减去,而不是从 Dom0 的内存中减去。 <.> 客户虚拟机可用的虚拟 CPU 数量。为了获得最佳性能,请不要创建具有超过主机上物理 CPU 数量的虚拟 CPU 的客户。 <.> 虚拟网络适配器。这是连接到主机网络接口的桥接器。 mac 参数是设置在虚拟网络接口上的 MAC 地址。如果未提供 MAC ,则此参数是可选的, Xen™ 将生成一个随机的 MAC 地址。 <.> 磁盘、文件或 ZFS 磁盘存储的完整路径,用于此虚拟机。选项和多个磁盘定义由逗号分隔。 <.> 定义安装初始操作系统的启动介质。在此示例中,它是之前下载的 ISO 镜像。请参阅 Xen™ 文档以了解其他类型的设备和设置选项。 <.> 控制 VNC 连接到 DomU 的串行控制台的选项。按顺序,它们是:激活 VNC 支持,定义要监听的 IP 地址,串行控制台的设备节点,以及精确定位鼠标和其他输入方法的输入方法。 keymap 定义要使用的键盘映射,默认为 english 。 |
在使用所有必要选项创建文件之后,通过将其作为参数传递给 xl create 来创建 DomU 。
# xl create freebsd.cfg|
每次重新启动 Dom0 时,必须再次将配置文件传递给 |
xl list 的输出确认了 DomU 已经被创建。
# xl list
Name ID Mem VCPUs State Time(s)
Domain-0 0 8192 4 r----- 1653.4
freebsd 1 1024 1 -b---- 663.9要开始安装基本操作系统,请启动 VNC 客户端,并将其指向主机的主网络地址或在 freebsd.cfg 文件的 vnclisten 行中定义的 IP 地址。操作系统安装完成后,关闭 DomU 并断开 VNC 查看器的连接。编辑 freebsd.cfg 文件,删除包含 cdrom 定义的行,或在行的开头插入一个 # 字符进行注释。要加载这个新的配置,需要使用 xl destroy 命令删除旧的 DomU ,参数可以是名称或 ID 。然后,使用修改后的 freebsd.cfg 文件重新创建 DomU 。
# xl destroy freebsd
# xl create freebsd.cfg然后可以使用 VNC 查看器再次访问该机器。这次,它将从已安装操作系统的虚拟磁盘启动,并可用作虚拟机。
24.7.4. 故障排除
本节包含基本信息,以帮助解决在使用 FreeBSD 作为 Xen™ 主机或客户机时遇到的问题。
24.7.4.1. 主机启动故障排除
请注意,以下故障排除提示适用于 Xen™ 4.11 或更新版本。如果您仍在使用 Xen™ 4.7 并且遇到问题,请考虑迁移到更新版本的 Xen™ 。
为了解决主机启动问题,您可能需要使用串行电缆或调试 USB 电缆。可以通过向 loader.conf 中的 xen_cmdline 选项添加选项来获取详细的 Xen™ 引导输出。一些相关的调试选项包括:
-
iommu = debug:可用于打印有关 IOMMU 的额外诊断信息。 -
dom0 = verbose:可用于打印有关 dom0 构建过程的额外诊断信息。 -
sync_console:用于强制同步控制台输出的标志。在调试过程中非常有用,可以避免由于速率限制而丢失消息。在生产环境中永远不要使用此选项,因为它可能允许恶意虚拟机通过控制台对 Xen™ 进行拒绝服务( DoS )攻击。
为了识别任何问题, FreeBSD 也应该以详细模式启动。要激活详细启动,请运行以下命令:
# echo 'boot_verbose="YES"' >> /boot/loader.conf如果这些选项都无法解决问题,请将串行引导日志发送至 mailto:freebsd-xen @ FreeBSD.org[freebsd-xen @ FreeBSD.org] 和 mailto:xen-devel @ lists.xenproject.org[xen-devel @ lists.xenproject.org] 以进行进一步分析。
24.7.4.2. 访客创建故障排除
在创建虚拟机时也可能出现问题,下面尝试为那些试图诊断虚拟机创建问题的人提供一些帮助。
创建虚拟机失败最常见的原因是 xl 命令输出错误并以非 0 的返回码退出。如果提供的错误信息不足以帮助确定问题,还可以通过多次使用 xl 命令的 v 选项来获取更详细的输出。
# xl -vvv create freebsd.cfg
Parsing config from freebsd.cfg
libxl: debug: libxl_create.c:1693:do_domain_create: Domain 0:ao 0x800d750a0: create: how=0x0 callback=0x0 poller=0x800d6f0f0
libxl: debug: libxl_device.c:397:libxl__device_disk_set_backend: Disk vdev=xvda spec.backend=unknown
libxl: debug: libxl_device.c:432:libxl__device_disk_set_backend: Disk vdev=xvda, using backend phy
libxl: debug: libxl_create.c:1018:initiate_domain_create: Domain 1:running bootloader
libxl: debug: libxl_bootloader.c:328:libxl__bootloader_run: Domain 1:not a PV/PVH domain, skipping bootloader
libxl: debug: libxl_event.c:689:libxl__ev_xswatch_deregister: watch w=0x800d96b98: deregister unregistered
domainbuilder: detail: xc_dom_allocate: cmdline="", features=""
domainbuilder: detail: xc_dom_kernel_file: filename="/usr/local/lib/xen/boot/hvmloader"
domainbuilder: detail: xc_dom_malloc_filemap : 326 kB
libxl: debug: libxl_dom.c:988:libxl__load_hvm_firmware_module: Loading BIOS: /usr/local/share/seabios/bios.bin
...如果详细输出无法帮助诊断问题,还可以在 /var/log/xen 中找到 QEMU 和 Xen™ 工具栈的日志。请注意,日志名称后面附加了域的名称,因此如果域的名称为 freebsd ,您应该能找到一个 /var/log/xen/xl-freebsd.log 和可能还有一个 /var/log/xen/qemu-dm-freebsd.log 。这两个日志文件都可能包含有用的调试信息。如果以上方法都无法解决问题,请将您面临的问题的描述和尽可能多的信息发送到 mailto:freebsd-xen @ FreeBSD.org[freebsd-xen @ FreeBSD.org] 和 mailto:xen-devel @ lists.xenproject.org[xen-devel @ lists.xenproject.org] 以获取帮助。
Chapter 25. 本地化 - i18n/L10n 的使用和设置
25.1. 简介
FreeBSD 是一个分布式项目,用户和贡献者遍布全球。因此, FreeBSD 支持多种语言的本地化,允许用户以非英语语言查看、输入或处理数据。可以选择大多数主要语言,包括但不限于:中文、德语、日语、韩语、法语、俄语和越南语。
国际化一词被缩写为 i18n ,代表着“ internationalization ”中第一个字母和最后一个字母之间的字母数量。 L10n 使用相同的命名方案,但是从“ localization ”中计算。 i18n/L10n 的方法、协议和应用程序允许用户使用他们选择的语言。
本章讨论了 FreeBSD 的国际化和本地化功能。阅读本章后,您将了解到:
-
如何构建区域名称。
-
如何为登录 shell 设置区域设置。
-
如何配置控制台以支持非英语语言。
-
如何为不同的语言配置 Xorg 。
-
如何找到符合国际化标准的应用程序。
-
如何找到配置特定语言的更多信息。
在阅读本章之前,您应该:
-
了解如何交叉引用: ports[ports ,安装额外的第三方应用程序] 。
25.2. 使用本地化
本地化设置基于三个组件:语言代码、国家代码和编码。区域设置名称由这些部分构成,如下所示:
LanguageCode_CountryCode.Encoding
_语言代码_和_国家代码_用于确定国家和特定的语言变体。 常见的语言和国家代码 提供了一些语言代码_国家代码的示例:
| 语言代码_国家代码 | 描述 |
|---|---|
en_US |
英语,美国 |
ru_RU |
俄罗斯,俄罗斯 |
zh_TW |
繁體中文,台灣 |
可以通过输入以下命令来查看所有可用的区域设置列表:
% locale -a | more确定当前的区域设置:
% locale特定语言的字符集,如 ISO8859-1 、 ISO8859-15 、 KOI8-R 和 CP437 ,在 multibyte(3) 中有描述。字符集的活动列表可以在 IANA 注册表 中找到。
一些语言,比如中文或日文,不能用 ASCII 字符表示,需要使用宽字符或多字节字符的扩展语言编码。宽字符或多字节编码的例子包括 EUC 和 Big5 。旧的应用程序可能会将这些编码误认为控制字符,而新的应用程序通常能够识别这些字符。根据实现的不同,用户可能需要使用宽字符或多字节字符支持来编译应用程序,或者正确配置它。
|
FreeBSD 使用与 Xorg 兼容的区域编码。 |
本节的其余部分描述了在 FreeBSD 系统上配置区域设置的各种方法。下一节将讨论查找和编译支持国际化( i18n )的应用程序的注意事项。
25.2.1. 设置登录 Shell 的区域设置
区域设置可以在用户的 [.filename]# ~ /.login_conf# 文件中或者用户的 shell 启动文件中进行配置: [.filename]# ~ /.profile# 、 [.filename]# ~ /.bashrc# 或者 [.filename]# ~ /.cshrc# 。
应设置两个环境变量:
-
LANG,用于设置区域设置 -
MM_CHARSET是一个设置应用程序使用的 MIME 字符集的变量。
除了用户的 shell 配置外,这些变量还应该为特定的应用程序配置和 Xorg 配置设置。
25.2.1.1. 登录类方法
这是推荐的方法,因为它为每个可能的 shell 分配了所需的区域设置和 MIME 字符集的环境变量。这个设置可以由每个用户执行,也可以由超级用户为所有用户配置。
这个最简示例在个人用户的主目录的 .login_conf 文件中设置了两个变量,用于 Latin-1 编码。
me:\ :charset=ISO-8859-1:\ :lang=de_DE.ISO8859-1:
这是一个用户的示例 [.filename]# ~ /.login_conf# ,它设置了使用 BIG-5 编码的繁体中文的变量。由于一些应用程序不正确地遵守中文、日文和韩文的区域变量,因此需要更多的变量。
#Users who do not wish to use monetary units or time formats #of Taiwan can manually change each variable me:\ :lang=zh_TW.Big5:\ :setenv=LC_ALL=zh_TW.Big5,LC_COLLATE=zh_TW.Big5,LC_CTYPE=zh_TW.Big5,LC_MESSAGES=zh_TW.Big5,LC_MONETARY=zh_TW.Big5,LC_NUMERIC=zh_TW.Big5,LC_TIME=zh_TW.Big5:\ :charset=big5:\ :xmodifiers="@im=gcin": #Set gcin as the XIM Input Server
超级用户可以选择配置系统中的所有用户进行本地化。在 /etc/login.conf 文件中,可以使用以下变量来设置区域设置和 MIME 字符集:
language_name|Account Type Description:\ :charset=MIME_charset:\ :lang=locale_name:\ :tc=default:
因此,前面的 Latin-1 示例将如下所示:
german|German Users Accounts:\ :charset=ISO-8859-1:\ :lang=de_DE.ISO8859-1:\ :tc=default:
请参阅 login.conf(5) 以获取有关这些变量的更多详细信息。请注意,它已经包含了预定义的_russian_类。
每当编辑 /etc/login.conf 文件时,请记得执行以下命令来更新能力数据库:
# cap_mkdb /etc/login.conf|
对于最终用户来说,需要在他们的 |
25.2.1.1.1. 更改登录类别的实用工具
除了手动编辑 /etc/login.conf 文件外,还有一些工具可用于设置新创建用户的区域设置。
使用 vipw 添加新用户时,需要指定 language 来设置区域设置:
user:password:1111:11:language:0:0:User Name:/home/user:/bin/sh
当使用 adduser 命令添加新用户时,可以预先配置默认语言适用于所有新用户,或者为单个用户指定语言。
如果所有新用户使用相同的语言,请在 /etc/adduser.conf 中设置 defaultclass =language 。
要在创建用户时覆盖此设置,请在此提示处输入所需的区域设置:
Enter login class: default []:或者在调用 adduser 时指定要设置的区域设置:
# adduser -class language如果使用 pw 来添加新用户,请按照以下方式指定区域设置:
# pw useradd user_name -L language要更改现有用户的登录类别,可以使用 chpass 命令。以超级用户身份调用该命令,并将要编辑的用户名作为参数提供。
# chpass user_name25.2.1.2. Shell 启动文件方法
不推荐使用第二种方法,因为每个使用的 shell 都需要手动配置,每个 shell 都有不同的配置文件和语法。例如,要为 sh shell 设置德语语言,可以将以下行添加到 .filename 文件中的 ` ~ /.profile` 中,以仅为该用户设置 shell 。这些行也可以添加到 /etc/profile 或 /usr/share/skel/dot.profile 中,以为所有用户设置该 shell 。
LANG=de_DE.ISO8859-1; export LANG MM_CHARSET=ISO-8859-1; export MM_CHARSET
然而,对于 csh shell ,配置文件的名称和使用的语法有所不同。以下是与 [.filename]# ~ /.login# 、 /etc/csh.login 或 /usr/share/skel/dot.login 等效的设置:
setenv LANG de_DE.ISO8859-1 setenv MM_CHARSET ISO-8859-1
为了使事情变得复杂,配置 Xorg 所需的语法也取决于 shell 。第一个示例适用于 sh shell ,第二个示例适用于 csh shell :
LANG=de_DE.ISO8859-1; export LANG
setenv LANG de_DE.ISO8859-1
25.2.2. 控制台设置
控制台提供了几种本地化字体。要查看可用字体的列表,请键入 ls /usr/share/syscons/fonts 。要配置控制台字体,请在 /etc/rc.conf 中指定字体名称,不包括 .fnt 后缀。
font8x16=font_name font8x14=font_name font8x8=font_name
可以通过将以下内容添加到 [/etc/rc.conf] 来设置键位映射和屏幕映射:
scrnmap=screenmap_name keymap=keymap_name keychange="fkey_number sequence"
要查看可用的屏幕映射列表,请键入 ls /usr/share/syscons/scrnmaps 。在指定_screenmap_name_时,请不要包括 .scm 后缀。通常需要具有相应映射字体的屏幕映射作为解决方案,以便将位 8 扩展到 VGA 适配器的字体字符矩阵的位 9 ,以便在屏幕字体使用位 8 列时将字母移出伪图形区域。
要查看可用的键盘映射列表,请输入 ls /usr/share/syscons/keymaps 。在指定 keymap_name 时,不要包括 .kbd 后缀。要在不重新启动的情况下测试键盘映射,请使用 kbdmap(1) 。
通常需要使用 keychange 条目来将功能键编程为与所选终端类型匹配,因为功能键序列无法在键映射中定义。
接下来,在所有虚拟终端条目的 /etc/ttys 中设置正确的控制台终端类型。 字符集的终端类型定义 总结了可用的终端类型。
| 字符集 | 终端类型 |
|---|---|
ISO8859-1 or ISO8859-15 |
|
ISO8859-2 |
|
ISO8859-7 |
|
KOI8-R |
|
KOI8-U |
|
CP437 (VGA default) |
|
US-ASCII |
|
对于具有宽字符或多字节字符的语言,请从 FreeBSD Ports Collection 中安装适用于该语言的控制台。可用的端口在 从 Ports Collection 可用的控制台 中进行了总结。安装完成后,请参考端口的 pkg-message 或 man 页面以获取配置和使用说明。
| 语言 | 端口位置 |
|---|---|
繁体中文( BIG-5 ) |
包: chinese/big5con[] |
中文 / 日文 / 韩文 |
包: chinese/cce[] |
中文 / 日文 / 韩文 |
包: chinese/zhcon[] |
日本人 |
包: chinese/kon2[] |
日本人 |
包:日语 /kon2-14 点 [] |
日本人 |
包: japanese/kon2-16dot[] |
如果在 [/etc/rc.conf] 中启用了鼠标,可能需要进行额外的配置。默认情况下, syscons(4) 驱动程序的鼠标光标占用字符集中的 0xd0-0xd3 范围。如果语言使用此范围,请通过在 [/etc/rc.conf] 中添加以下行来移动光标的范围:
mousechar_start=3
25.2.3. Xorg 设置
描述了如何安装和配置 Xorg 。在配置 Xorg 进行本地化时,可以从 FreeBSD Ports Collection 中获取额外的字体和输入法。应用程序特定的国际化设置,如字体和菜单,可以在 [.filename]# ~ /.Xresources# 中进行调整,这样用户就可以在图形应用程序菜单中查看他们选择的语言。
X 输入法( XIM )协议是用于输入非英语字符的 Xorg 标准。 可用的输入方法 总结了在 FreeBSD Ports Collection 中可用的输入法应用程序。还有其他 Fcitx 和 Uim 应用程序可用。
| 语言 | 输入法 |
|---|---|
中文 |
包: chinese/gcin[] |
中文 |
包: chinese/ibus-chewing[] |
中文 |
包: chinese/ibus-pinyin[] |
中文 |
包: chinese/oxim[] |
中文 |
包: chinese/scim-fcitx[] |
中文 |
包: chinese/scim-pinyin[] |
中文 |
包: chinese/scim-tables[] |
日本人 |
包: japanese/ibus-anthy[] |
日本人 |
包: japanese/ibus-mozc[] |
日本人 |
包:日语 /ibus-skk[] |
日本人 |
|
日本人 |
|
日本人 |
包: japanese/scim-anthy[] |
日本人 |
包: japanese/scim-canna[] |
日本人 |
包: japanese/scim-honoka[] |
日本人 |
包: japanese/scim-honoka-plugin-romkan[] |
日本人 |
包: japanese/scim-honoka-plugin-wnn[] |
日本人 |
包: japanese/scim-prime[] |
日本人 |
|
日本人 |
|
日本人 |
包: japanese/scim-tomoe[] |
日本人 |
包: japanese/scim-uim[] |
日本人 |
|
日本人 |
|
日本人 |
包: japanese/uim-anthy[] |
韩国人 |
|
韩国人 |
|
韩国人 |
包:韩国 / 纳比 [] |
韩国人 |
|
韩国人 |
|
越南语 |
|
越南语 |
25.3. 寻找国际化应用程序
国际化( i18n )应用程序是使用库中的国际化工具包进行编程的。这些工具包允许开发人员编写一个简单的文件,并将显示的菜单和文本翻译成每种语言。
链接: FreeBSD Ports Collection 包含许多应用程序,这些应用程序内置了对多种语言的宽字符或多字节字符的支持。这些应用程序的名称中包含“ i18n ”,以便于识别。然而,它们并不总是支持所需的语言。
一些应用程序可以使用特定的字符集进行编译。通常在端口的 Makefile 文件中完成,或者通过传递一个值给 configure 来实现。有关如何确定所需的 configure 值或在构建端口时使用哪些编译选项的更多信息,请参阅相应的 FreeBSD 端口源代码中的 i18n 文档。
25.4. 特定语言的区域配置
本节提供了将 FreeBSD 系统本地化为俄语的配置示例。然后,它还提供了一些本地化其他语言的附加资源。
25.4.1. 俄语( KOI8-R 编码)
本节展示了将 FreeBSD 系统本地化为俄语所需的具体设置。有关每种类型设置的更详细描述,请参阅 使用本地化 。
要为登录 shell 设置此区域设置,请将以下行添加到每个用户的 [.filename]# ~ /.login_conf# 文件中:
me:My Account:\ :charset=KOI8-R:\ :lang=ru_RU.KOI8-R:
要配置控制台,请将以下行添加到 [/etc/rc.conf] 文件中:
keymap="ru.utf-8" scrnmap="utf-82cp866" font8x16="cp866b-8x16" font8x14="cp866-8x14" font8x8="cp866-8x8" mousechar_start=3
对于 [/etc/ttys] 中的每个 ttyv 条目,请使用 cons25r 作为终端类型。
要配置打印,需要一个特殊的输出过滤器,将 KOI8-R 转换为 CP866 ,因为大多数带有俄语字符的打印机都配备了硬件代码页 CP866 。 FreeBSD 包含了一个默认的过滤器,位于 [/usr/libexec/lpr/ru/koi2alt] 。要使用这个过滤器,将以下条目添加到 [/etc/printcap] 中:
lp|Russian local line printer:\ :sh:of=/usr/libexec/lpr/ru/koi2alt:\ :lp=/dev/lpt0:sd=/var/spool/output/lpd:lf=/var/log/lpd-errs:
请参考 printcap(5) 以获取更详细的解释。
要在挂载的 MS-DOS® 文件系统中配置对俄语文件名的支持,请在向 [/etc/fstab] 添加条目时包括 -L 和区域设置名称:
/dev/ad0s2 /dos/c msdos rw,-Lru_RU.KOI8-R 0 0
请参考 mount_msdosfs(8) 获取更多详细信息。
要为 Xorg 配置俄文字体,请安装包: x11-fonts/xorg-fonts-cyrillic[] 。然后,在 /etc/X11/xorg.conf 中检查 "Files" 部分。以下行必须在任何其他 FontPath 条目之前添加:
FontPath "/usr/local/lib/X11/fonts/cyrillic"
在 Ports Collection 中提供了额外的西里尔字体。
要激活俄语键盘,请将以下内容添加到 /etc/xorg.conf 文件的 "Keyboard" 部分:
Option "XkbLayout" "us,ru" Option "XkbOptions" "grp:toggle"
确保在该文件中将 XkbDisable 注释掉。
对于 grp:toggle ,使用 右 Alt ;对于 grp:ctrl_shift_toggle ,使用 Ctrl+Shift ;对于 grp:caps_toggle ,使用 CapsLock 。在 LAT 模式下,仍然可以使用旧的 CapsLock 功能,使用 Shift+CapsLock 。由于某种未知的原因, grp:caps_toggle 在 Xorg 中无法正常工作。
如果键盘上有"Windows®"键,并且一些非字母键映射不正确,请将以下行添加到 /etc/xorg.conf 文件中:
Option "XkbVariant" ",winkeys"
|
俄罗斯的 XKB 键盘可能无法与非本地化的应用程序配合使用。最低程度的本地化应用程序应在程序早期调用 `XtSetLanguageProc(NULL , NULL , NULL) ; ` 函数。 |
请参考 http://koi8.pp.ru/xwin.html 获取有关本地化 Xorg 应用程序的更多说明。有关 KOI8-R 编码的更一般信息,请参考 http://koi8.pp.ru/ 。
25.4.2. 其他语言特定资源
本节列出了一些配置其他区域设置的附加资源。
- 繁體中文(台灣)
-
FreeBSD-Taiwan 项目在 http://netlab.cse.yzu.edu.tw/ \~ statue/freebsd/zh-tut/ 上提供了一份关于 FreeBSD 的中文 HOWTO 文档。
- 希腊语本地化
-
有关 FreeBSD 中希腊语支持的完整文章可以在此处找到: https://www.FreeBSD.org/doc/gr/articles/greek-language-support/ ,该文章仅以希腊语提供,并作为官方 FreeBSD 希腊文档的一部分。
- 日本语和韩国语本地化
-
对于日语,请参考 http://www.jp.FreeBSD.org/ ,对于韩语,请参考 http://www.kr.FreeBSD.org/ 。
- 非英语的 FreeBSD 文档
-
一些 FreeBSD 的贡献者已经将 FreeBSD 文档的部分内容翻译成其他语言。这些翻译可以通过 [FreeBSD 网站](https://www.FreeBSD.org/) 上的链接或者在
/usr/share/doc目录中找到。
Chapter 26. 更新和升级 FreeBSD
26.1. 简介
FreeBSD 在发布之间处于不断的开发中。有些人喜欢使用官方发布的版本,而其他人则喜欢与最新的开发保持同步。然而,即使是官方发布的版本也经常会更新以修复安全和其他关键问题。无论使用哪个版本, FreeBSD 都提供了所有必要的工具来保持系统更新,并允许在版本之间进行轻松升级。本章介绍如何跟踪开发系统以及保持 FreeBSD 系统最新的基本工具。
阅读完本章后,您将了解:
-
如何使用 freebsd-update 或 Git 来保持 FreeBSD 系统的最新状态。
-
如何将已安装系统的状态与已知的原始副本进行比较。
-
如何使用 Git 或文档 port 来保持已安装文档的最新状态。
-
两个开发分支之间的区别:FreeBSD-STABLE 和 FreeBSD-CURRENT。
-
如何重建和重新安装整个基础系统。
在阅读本章之前,您应该:
-
正确设置网络连接(高级网络设置)。
-
了解如何安装额外的第三方软件(安装应用程序:软件包和 port)。
|
在本章中,使用 |
26.2. FreeBSD 更新
及时应用安全补丁和升级到操作系统的新版本是系统管理的重要方面。FreeBSD 包含一个名为 freebsd-update 的实用程序,可用于执行这两个任务。
该实用程序支持对 FreeBSD 进行二进制安全性和勘误更新,无需手动编译和安装补丁或新内核。二进制更新适用于安全团队当前支持的所有架构和版本。支持的版本列表及其预计的生命周期日期可在 https://www.FreeBSD.org/security/ 上找到。
该实用程序还支持将操作系统升级到次要点版本以及升级到另一个发布分支。在升级到新版本之前,请查看其发布公告,因为其中包含与该版本相关的重要信息。发布公告可从 https://www.FreeBSD.org/releases/ 获取。
|
如果存在使用 freebsd-update(8) 功能的 crontab(5),在升级操作系统之前必须将其禁用。 |
本节描述了 freebsd-update 使用的配置文件,演示了如何应用安全补丁以及如何升级到次要或主要操作系统版本,并讨论了升级操作系统时的一些考虑因素。
26.2.1. 配置文件
freebsd-update 的默认配置文件可以直接使用。一些用户可能希望调整默认配置文件 /etc/freebsd-update.conf ,以便更好地控制该过程。该文件中的注释解释了可用的选项,但以下内容可能需要更多的解释:
# Components of the base system which should be kept updated. Components world kernel
该参数控制着哪些部分的 FreeBSD 将保持最新。默认情况下,会更新整个基础系统和内核。也可以指定单个组件,例如 src/base 或 src/sys 。然而,最好的选择是将其保持默认状态,因为更改它以包括特定项需要列出每个所需的项。随着时间的推移,这可能会导致源代码和二进制文件不同步,从而产生灾难性后果。
# Paths which start with anything matching an entry in an IgnorePaths # statement will be ignored. IgnorePaths /boot/kernel/linker.hints
为了在更新过程中保留指定目录,例如 /bin 或 /sbin 的内容不变,可以将它们的路径添加到此语句中。此选项可用于防止 freebsd-update 覆盖本地修改。
# Paths which start with anything matching an entry in an UpdateIfUnmodified # statement will only be updated if the contents of the file have not been # modified by the user (unless changes are merged; see below). UpdateIfUnmodified /etc/ /var/ /root/ /.cshrc /.profile
此选项仅会更新指定目录中未修改的配置文件。用户所做的任何更改都会阻止这些文件的自动更新。还有另一个选项 KeepModifiedMetadata ,它会指示 freebsd-update 在合并过程中保存更改。
# When upgrading to a new FreeBSD release, files which match MergeChanges # will have any local changes merged into the version from the new release. MergeChanges /etc/ /var/named/etc/ /boot/device.hints
freebsd-update 应尝试合并的配置文件目录列表。文件合并过程是一系列类似于 mergemaster 的 diff(1) 补丁,但选项较少。合并可以被接受、打开编辑器或导致 freebsd-update 中止。如果不确定,备份 /etc 并接受合并。有关 mergemaster 的更多信息,请参阅 mergemaster(8)。
# Directory in which to store downloaded updates and temporary # files used by FreeBSD Update. # WorkDir /var/db/freebsd-update
该目录是用于存放所有补丁和临时文件的位置。在用户进行版本升级的情况下,该位置应至少有 1GB 的可用磁盘空间。
# When upgrading between releases, should the list of Components be # read strictly (StrictComponents yes) or merely as a list of components # which *might* be installed of which FreeBSD Update should figure out # which actually are installed and upgrade those (StrictComponents no)? # StrictComponents no
当将此选项设置为 yes 时,freebsd-update 将假设 Components 列表是完整的,并且不会尝试在列表之外进行更改。实际上,freebsd-update 将尝试更新属于 Components 列表的每个文件。
请参考 freebsd-update.conf(5) 获取更多详细信息。
26.2.2. 应用安全补丁
应用 FreeBSD 安全补丁的过程已经简化,管理员可以使用 freebsd-update 来保持系统完全更新。有关 FreeBSD 安全公告的更多信息,请参阅 “FreeBSD 安全公告”。
可以使用以下命令下载和安装 FreeBSD 安全补丁。第一个命令将确定是否有可用的未解决补丁,并且如果应用了这些补丁,将列出将被修改的文件。第二个命令将应用这些补丁。
# freebsd-update fetch
# freebsd-update install如果更新应用了任何内核补丁,系统将需要重新启动以引导到已打补丁的内核。如果补丁被应用于正在运行的二进制文件,受影响的应用程序应该重新启动,以便使用已打补丁的二进制版本。
|
通常,用户需要准备好重新启动系统。要知道系统是否需要由于内核更新而重新启动,请执行命令 |
系统可以通过将以下条目添加到 /etc/crontab 来配置每天自动检查更新:
@daily root freebsd-update cron
如果存在补丁,它们将会自动下载但不会被应用。系统会向 root 用户发送一封电子邮件,以便可以审查这些补丁,并使用 freebsd-update install 命令手动安装它们。
如果出现任何问题,freebsd-update 可以使用以下命令回滚最后一组更改:
# freebsd-update rollback
Uninstalling updates... done.如果内核或任何内核模块被修改,系统应该重新启动,并且应该重新启动任何受影响的二进制文件。
只有 GENERIC 内核可以被 freebsd-update 自动更新。如果安装了自定义内核,则需要在 freebsd-update 完成更新后重新构建和安装它。默认的内核名称是 GENERIC。可以使用 uname(1) 命令来验证其安装情况。
|
始终保留一个 GENERIC 内核的副本在 /boot/GENERIC 中。这对于诊断各种问题和进行版本升级非常有帮助。请参考 使用 FreeBSD 9.X 及更高版本的自定义内核 了解如何获取 GENERIC 内核的副本的说明。 |
除非已更改 /etc/freebsd-update.conf 中的默认配置,否则 freebsd-update 将与其他更新一起安装更新的内核源代码。然后可以按照通常的方式重新构建和重新安装新的自定义内核。
freebsd-update 分发的更新并不总是涉及内核。如果内核源代码没有被 freebsd-update install 修改过,那么重新构建自定义内核是不必要的。然而,freebsd-update 总是会更新 /usr/src/sys/conf/newvers.sh 文件。通过 uname -r 命令报告的 -p 数字表示的当前补丁级别是从这个文件中获取的。即使没有其他变化,重新构建自定义内核也可以使 uname 准确地报告系统的当前补丁级别。这在维护多个系统时特别有帮助,因为它可以快速评估每个系统中安装的更新。
26.2.3. 执行次要和主要版本升级
从一个 FreeBSD 的次要版本升级到另一个次要版本被称为 次要版本 升级。一个例子:
-
从 FreeBSD 13.1 升级到 13.2 。
主要版本升级会增加主要版本号。一个例子:
-
FreeBSD 13.2 升级至 14.0。
通过为 freebsd-update 提供一个发布版本目标,可以执行两种类型的升级。
|
在每次新的
— 而且,至关重要的是:
因此,无论是小型还是大型操作系统升级,如果您的软件包要求包括任何内核模块:
|
|
如果系统正在运行自定义内核,请确保在升级之前在 /boot/GENERIC 目录下存在一个 GENERIC 内核的副本。请参考 使用 FreeBSD 9.X 及更高版本的自定义内核 以获取 GENERIC 内核的副本的说明。 |
在 FreeBSD 13.1 系统上运行以下命令将升级到 FreeBSD 13.2:
# freebsd-update -r 13.2-RELEASE upgrade在接收到命令后,freebsd-update 将评估配置文件和当前系统,以尝试收集执行升级所需的信息。屏幕上将显示一个列表,列出已检测到和未检测到的组件。例如:
Looking up update.FreeBSD.org mirrors... 1 mirrors found.
Fetching metadata signature for 13.1-RELEASE from update1.FreeBSD.org... done.
Fetching metadata index... done.
Inspecting system... done.
The following components of FreeBSD seem to be installed:
kernel/smp src/base src/bin src/contrib src/crypto src/etc src/games
src/gnu src/include src/krb5 src/lib src/libexec src/release src/rescue
src/sbin src/secure src/share src/sys src/tools src/ubin src/usbin
world/base world/info world/lib32 world/manpages
The following components of FreeBSD do not seem to be installed:
kernel/generic world/catpages world/dict world/doc world/games
world/proflibs
Does this look reasonable (y/n)? y在这一点上,freebsd-update 将尝试下载升级所需的所有文件。在某些情况下,用户可能会被要求回答关于安装哪些文件或如何继续的问题。
当使用自定义内核时,上述步骤将产生类似以下的警告:
WARNING: This system is running a "MYKERNEL" kernel, which is not a
kernel configuration distributed as part of FreeBSD 13.1-RELEASE.
This kernel will not be updated: you MUST update the kernel manually
before running "/usr/sbin/freebsd-update install"此警告可以在此时安全地忽略。更新的 GENERIC 内核将作为升级过程中的中间步骤使用。
一旦所有补丁都下载到本地系统后,它们将被应用。这个过程可能需要一些时间,具体取决于机器的速度和工作负载。然后将合并配置文件。合并过程需要一些用户干预,因为可能需要合并文件或者在屏幕上出现编辑器进行手动合并。每次成功合并的结果都会在进程继续时显示给用户。如果合并失败或被忽略,进程将中止。用户可能希望在以后的某个时间备份 /etc 目录并手动合并重要文件,例如 master.passwd 或 group。
|
系统尚未进行修改,因为所有的修补和合并都在另一个目录中进行。一旦所有的修补程序都成功应用,所有的配置文件都已经合并,并且看起来进程将顺利进行,用户可以使用以下命令将更改提交到磁盘: |
首先,将对内核和内核模块进行补丁。如果系统正在运行自定义内核,请使用 nextboot(8) 命令将内核设置为下一次启动时更新的 /boot/GENERIC 。
# nextboot -k GENERIC|
在使用 GENERIC 内核重新启动之前,请确保它包含了系统正常启动和连接到网络所需的所有驱动程序,如果正在更新的机器是远程访问的。特别是,如果正在运行的自定义内核包含通常由内核模块提供的内置功能,请确保使用 /boot/loader.conf 工具将这些模块临时加载到 GENERIC 内核中。建议在升级过程完成之前禁用非必要的服务以及任何磁盘和网络挂载。 |
现在应该使用更新的内核重新启动机器:
# shutdown -r now一旦系统恢复在线状态,使用以下命令重新启动 freebsd-update。由于进程的状态已被保存,freebsd-update 将不会从头开始,而是继续进行下一阶段并删除所有旧的共享库和对象文件。
# freebsd-update install|
根据库版本号是否有所增加,安装过程可能只有两个阶段,而不是三个阶段。 |
升级已完成。如果这是一个主要版本的升级,请按照 在主要版本升级后升级软件包 中描述的步骤重新安装所有端口和软件包。
26.2.3.1. 使用 FreeBSD 9.X 及更高版本的自定义内核
在使用 freebsd-update 前,请确保 /boot/GENERIC 目录下存在一个 GENERIC 内核的副本。如果只构建了一个自定义内核,那么 /boot/kernel.old 目录下的内核就是 GENERIC 内核。只需将此目录重命名为 /boot/GENERIC。
如果自定义内核已经构建了多次,或者不知道自定义内核已经构建了多少次,请获取与当前操作系统版本匹配的 GENERIC 内核的副本。如果可以物理访问系统,则可以从安装介质中安装 GENERIC 内核的副本:
# mount /cdrom
# cd /cdrom/usr/freebsd-dist
# tar -C/ -xvf kernel.txz boot/kernel/kernel或者,也可以从源代码重新构建并安装 GENERIC 内核:
# cd /usr/src
# make kernel __MAKE_CONF=/dev/null SRCCONF=/dev/null为了使这个内核被 freebsd-update 识别为 GENERIC 内核,必须确保 GENERIC 配置文件没有被任何方式修改过。同时建议在构建内核时不使用任何其他特殊选项。
不需要重新启动到 GENERIC kernel 内核,因为 freebsd-update 只需要存在 /boot/GENERIC 文件。
26.2.3.2. 在主要版本升级后升级软件包
通常,在小版本升级后,已安装的应用程序将继续正常工作,没有问题。主要版本使用不同的应用程序二进制接口(ABIs),这将导致大多数第三方应用程序无法正常工作。在进行主要版本升级后,所有已安装的软件包和端口都需要升级。可以使用 pkg upgrade 命令升级软件包。要升级已安装的端口,请使用类似于 ports-mgmt/portmaster 的实用工具。
强制升级所有已安装的软件包将使用存储库中的新版本替换软件包,即使版本号没有增加。这是因为在升级 FreeBSD 的主要版本之间时,ABI 版本会发生变化。可以通过执行以下操作来完成强制升级:
# pkg-static upgrade -f使用以下命令可以重新构建所有已安装的应用程序:
# portmaster -af该命令将显示每个具有可配置选项的应用程序的配置屏幕,并等待用户与这些屏幕进行交互。为了防止这种行为,并仅使用默认选项,请在上述命令中包含 -G。
一旦软件升级完成,通过最后一次调用 freebsd-update 来完成升级过程,以解决升级过程中的所有问题。
# freebsd-update install如果临时使用了 GENERIC 内核,现在是构建和安装新的自定义内核的时候了,可以按照 配置 FreeBSD 内核 中的说明进行操作。
将机器重启到新的 FreeBSD 版本。升级过程现在已经完成。
26.2.4. 系统状态比较
可以使用 freebsd-update IDS 命令来测试已安装的 FreeBSD 版本与已知的良好副本之间的状态。该命令评估系统实用程序、库和配置文件的当前版本,并可用作内置的入侵检测系统(IDS)。
|
这个命令不能替代真正的入侵检测系统,比如 security/snort。由于 |
开始比较之前,请指定要将结果保存到的输出文件:
# freebsd-update IDS >> outfile.ids系统将会被检查,并且会将文件的详细列表以及已知发布版本和当前安装版本的 SHA256 哈希值发送到指定的输出文件中。
列表中的条目非常长,但输出格式很容易解析。例如,要获取与发布版本不同的所有文件的列表,请执行以下命令:
# cat outfile.ids | awk '{ print $1 }' | more
/etc/master.passwd
/etc/motd
/etc/passwd
/etc/pf.conf由于存在更多的文件,此示例输出已被截断。一些文件具有自然的修改。例如,如果系统中添加了用户,/etc/passwd 文件将被修改。内核模块可能会有所不同,因为 freebsd-update 可能已经对它们进行了更新。要排除特定的文件或目录,请将它们添加到 /etc/freebsd-update.conf 文件中的 IDSIgnorePaths 选项中。
26.3. 更新引导代码
以下手册描述了引导代码和引导加载程序的升级过程:gpart(8)、gptboot(8)、gptzfsboot(8) 和 loader.efi(8)。
26.4. 更新文档集合
文档是 FreeBSD 操作系统的一个重要组成部分。虽然 FreeBSD 网站上始终提供最新版本的文档(文档门户),但拥有一个最新的本地副本也是很方便的,包括 FreeBSD 网站、手册、常见问题解答和文章。
本节介绍如何使用源代码或 FreeBSD Ports Collection 来保持本地的 FreeBSD 文档最新。
有关编辑和提交文档更正的信息,请参阅 FreeBSD 文档项目新贡献者入门指南(FreeBSD Documentation Project Primer for New Contributors)。
26.4.1. 从源代码更新文档
从源代码重新构建 FreeBSD 文档需要一系列工具,这些工具不是 FreeBSD 基本系统的一部分。可以按照 FreeBSD 文档项目入门指南中的 these steps 来安装所需的工具。
安装完成后,使用 git 获取文档源代码的干净副本:
# git clone https://git.FreeBSD.org/doc.git /usr/doc下载文档源文件可能需要一些时间。请让它运行直到完成。
未来可以通过运行以下命令获取文档源的更新:
# git pull一旦文档源的最新快照被获取到 /usr/doc 目录下,所有准备工作就完成了,可以更新已安装的文档。
可以通过输入以下命令来执行完整更新:
# cd /usr/doc
# make26.5. 跟踪开发分支
FreeBSD 有两个开发分支:FreeBSD-CURRENT 和 FreeBSD-STABLE。
本节提供了每个分支及其预期受众的解释,以及如何使系统与每个相应分支保持最新的说明。
26.5.1. 使用 FreeBSD-CURRENT
FreeBSD-CURRENT 是 FreeBSD 开发的“最前沿”,使用 FreeBSD-CURRENT 的用户需要具备较高的技术能力。希望跟踪开发分支但技术水平较低的用户应该选择跟踪 FreeBSD-STABLE。
FreeBSD-CURRENT 是 FreeBSD 的最新源代码,包括正在进行中的工作、实验性的更改以及可能存在于下一个官方发布版本中的过渡机制。虽然许多 FreeBSD 开发人员每天编译 FreeBSD-CURRENT 源代码,但在某些短暂的时间内,源代码可能无法构建。这些问题会尽快解决,但是 FreeBSD-CURRENT 是否带来灾难或新功能可能取决于源代码同步的时间。
FreeBSD-CURRENT 提供给三个主要的利益群体使用:
-
活跃在 FreeBSD 社区中,正在积极参与源代码树某个部分工作的成员。
-
FreeBSD 社区的活跃测试人员。他们愿意花时间解决问题,就 FreeBSD 的变化和整体方向提出主题建议,并提交补丁。
-
希望密切关注事物、使用当前源代码进行参考,或偶尔发表评论或贡献代码的用户。
FreeBSD-CURRENT 不应被视为在下一次发布之前获取新功能的快速途径,因为预发布功能尚未经过完全测试,很可能包含错误。它也不是获取错误修复的快速方式,因为每个提交都有可能引入新的错误而不是修复现有的错误。 FreeBSD-CURRENT 在任何情况下都不是“官方支持”的。
要追踪 FreeBSD-CURRENT:
-
加入 FreeBSD-CURRENT mailing list 和 Commit messages for the main branch of the src repository 邮件列表。这是非常重要的,可以看到人们对系统当前状态的评论,并接收有关 FreeBSD-CURRENT 当前状态的重要公告。
Commit messages for the main branch of the src repository 列表记录每次更改的提交日志条目,以及可能的副作用的相关信息。
要加入这些邮件列表,请转到 FreeBSD list server,点击要订阅的列表,并按照说明进行操作。为了跟踪整个源代码树的变化,而不仅仅是 FreeBSD-CURRENT 的变化,请订阅 Commit messages for all branches of the src repository。
-
与 FreeBSD-CURRENT 源代码同步。通常情况下,使用
git从 FreeBSD Git 存储库的main分支检出 -CURRENT 代码(请参阅 “使用 Git”)。 -
由于存储库的大小,一些用户选择只同步他们感兴趣的或者他们正在贡献补丁的源代码部分。然而,计划从源代码编译操作系统的用户必须下载整个 FreeBSD-CURRENT,而不仅仅是选择的部分。
在编译 FreeBSD-CURRENT 之前,请仔细阅读 /usr/src/Makefile 文件,并按照 从源代码更新 FreeBSD 中的说明进行操作。阅读 FreeBSD-CURRENT mailing list 和 /usr/src/UPDATING 文件以了解其他引导程序的更新情况,有时在进行下一个版本发布的过程中可能需要这些更新。
-
积极参与!鼓励 FreeBSD-CURRENT 用户提交他们对增强功能或修复错误的建议。附带代码的建议将会受到欢迎。
26.5.2. 使用 FreeBSD-STABLE
FreeBSD-STABLE 是用于制作主要发布版本的开发分支。更改以较慢的速度进入此分支,并且通常假定它们首先在 FreeBSD-CURRENT 中进行了测试。这仍然是一个开发分支,并且在任何给定时间,FreeBSD-STABLE 的源代码可能适用或不适用于一般使用。它只是另一个工程开发轨道,而不是面向最终用户的资源。没有资源进行测试的用户应该运行最新版本的 FreeBSD。
对于那些对追踪或参与 FreeBSD 开发过程感兴趣的人,尤其是与下一个 FreeBSD 版本相关的人,应该考虑关注 FreeBSD-STABLE。
尽管 FreeBSD-STABLE 分支应该始终能够编译和运行,但无法保证这一点。由于运行 FreeBSD-STABLE 的人比运行 FreeBSD-CURRENT 的人更多,因此不可避免地会在 FreeBSD-STABLE 中发现一些在 FreeBSD-CURRENT 中不明显的错误和边界情况。因此,不应盲目跟踪 FreeBSD-STABLE 。特别重要的是,在没有在开发或测试环境中彻底测试代码的情况下,不要将任何生产服务器更新到 FreeBSD-STABLE。
跟踪 FreeBSD-STABLE 的方法:
-
加入 FreeBSD-STABLE mailing list 以便及时了解在 FreeBSD-STABLE 中可能出现的构建依赖项或其他需要特别关注的问题。开发人员还会在这个邮件列表中发布公告,当他们考虑一些有争议的修复或更新时,给用户一个机会回应,如果他们有任何关于拟议变更的问题需要提出。
加入与正在跟踪的分支相关的 git 列表。例如,跟踪 13-STABLE 分支的用户应该加入 Commit messages for the stable branches of the src repository。该列表记录每个更改的提交日志条目,以及可能的副作用的任何相关信息。
要加入这些列表,请转到 FreeBSD list server,点击要订阅的列表,并按照说明进行操作。为了跟踪整个源代码树的变化,请订阅 Commit messages for all branches of the src repository。
-
要安装一个新的 FreeBSD-STABLE 系统,请从 安装最新的 FreeBSD-STABLE 版本,或者使用从 FreeBSD-STABLE 构建的每月快照。有关快照的更多信息,请参考 www.freebsd.org/snapshots。
要编译或升级现有的 FreeBSD 系统到 FreeBSD-STABLE,使用
git来检出所需分支的源代码。分支名称,例如stable/13,在 www.freebsd.org/releng 上列出。 -
在编译或升级到 FreeBSD-STABLE 之前,请仔细阅读 /usr/src/Makefile 并按照 从源代码更新 FreeBSD 中的说明进行操作。阅读 FreeBSD-STABLE mailing list 和 /usr/src/UPDATING 以了解其他引导程序的最新信息,有时在进行下一个版本发布的过程中可能需要这些信息。
26.5.3. The N-number
在追踪错误时,了解使用哪些版本的源代码创建了出现问题的系统非常重要。 FreeBSD 在内核中提供了编译的版本信息。uname(1) 可以检索到这些信息,例如:
% uname -v
FreeBSD 14.0-CURRENT #112 main-n247514-031260d64c18: Tue Jun 22 20:43:19 MDT 2021 fred@machine:/usr/home/fred/obj/usr/home/fred/git/head/amd64.amd64/sys/FRED最后一个字段提供了有关内核名称、构建内核的人以及编译位置的信息。观察第四个字段,它由几个部分组成:
main-n247514-031260d64c18
main (1)
n247514 (2)
031260d64c18 (3)
(4)| 1 | Git 分支名称。注意:仅对项目发布的分支(main,stable/XX 和 releng/XX)进行 n-numbers 的比较才有效。本地分支的 n-numbers 将与其父分支的提交重叠。 <.> n-number 是从包含在该行中的 Git 哈希开始的 Git 存储库的提交线性计数。 <.> 检出树的 Git 哈希 <.> 当内核在具有未提交更改的树中构建时,有时会出现后缀 -dirty 。在此示例中,它不存在,因为 FRED 内核是从原始的检出构建的。 |
git rev-list 命令用于查找与 Git 哈希对应的 n-number。例如:
% git rev-list --first-parent --count 031260d64c18 (1)
247514 (2)| 1 | 要翻译的 git 哈希(上面示例中的哈希被重用) <.> n-number。 |
通常这个数字并不是非常重要。然而,当提交了错误修复时,这个数字可以快速确定修复是否存在于当前运行的系统中。开发人员通常会引用提交的哈希值(或提供具有该哈希值的 URL),而不是 n-number,因为哈希值是一个易于识别的变更标识符,而 n-number 则不是。安全公告和勘误通知也会注明一个 n-number,可以直接与您的系统进行比较。当您需要使用浅层 Git 克隆时,您无法可靠地比较 n-number,因为 git rev-list 命令会计算仓库中的所有修订版本,而浅层克隆会省略一些修订版本。
26.6. 从源代码更新 FreeBSD
通过从源代码编译来更新 FreeBSD 相比二进制更新有几个优点。可以使用选项构建代码以充分利用特定的硬件。可以使用非默认设置构建基本系统的部分,或者在不需要或不希望的地方完全省略它们。与仅安装二进制更新相比,构建过程更新系统需要更长时间,但允许完全定制以生成定制版本的 FreeBSD。
26.6.1. 快速入门
这是一个快速参考,用于通过从源代码构建来更新 FreeBSD 的典型步骤。后面的章节将更详细地描述这个过程。
|
当从 mergemaster(8) 切换到 etcupdate(8) 时,第一次运行可能会错误地合并更改,从而生成虚假的冲突。为了防止这种情况发生,在更新源代码和构建新的系统之前,请执行以下步骤:
|
-
更新和构建
# git pull /usr/src (1) check /usr/src/UPDATING (2) # cd /usr/src (3) # make -j4 buildworld (4) # make -j4 kernel (5) # shutdown -r now (6) # etcupdate -p (7) # cd /usr/src (8) # make installworld (9) # etcupdate -B (10) # shutdown -r now (11)
| 1 | 获取最新版本的源代码。有关获取和更新源代码的更多信息,请参阅 更新源代码 。 |
| 2 | 在从源代码构建之前或之后,请检查 /usr/src/UPDATING 是否有任何需要手动执行的步骤。 |
| 3 | 进入源代码目录。 |
编译整个世界,除了内核之外的一切。
| 1 | 编译并安装内核。这相当于执行 make buildkernel installkernel 命令。 |
| 2 | 重新启动系统以加载新内核。 |
| 3 | 在安装世界之前,需要更新和合并位于 /etc/ 的配置文件。 |
| 4 | 进入源代码目录。 |
| 5 | 安装世界。 |
| 6 | 更新并合并 /etc/ 中的配置文件。 |
| 7 | 重新启动系统以使用新构建的世界和内核。 |
26.6.3. 更新源代码
FreeBSD 源代码位于 /usr/src/ 目录下。更新源代码的首选方法是通过 Git 版本控制系统。请确认源代码已经处于版本控制下:
# cd /usr/src
# git remote --v
origin https://git.freebsd.org/src.git (fetch)
origin https://git.freebsd.org/src.git (push)这表示 /usr/src/ 已经受到版本控制,可以使用 git(1) 进行更新。
# git pull /usr/src如果目录最近没有更新,更新过程可能需要一些时间。完成后,源代码将是最新的,可以开始下一节中描述的构建过程。
|
获取源代码: 如果输出显示 |
| uname -r 的输出结果 | 仓库路径 | 描述 |
|---|---|---|
|
|
发布版本加上仅包含关键安全和错误修复补丁。这个分支推荐给大多数用户使用。 |
|
|
稳定版本加上该分支上的所有额外开发。STABLE 指的是应用程序二进制接口(ABI)不会改变,因此为早期版本编译的软件仍然可以运行。例如,为了在 FreeBSD 10.1 上运行而编译的软件仍然可以在稍后编译的 FreeBSD 10-STABLE 上运行。 稳定分支偶尔会有错误或不兼容性,可能会影响用户,尽管这些问题通常会很快修复。 |
|
|
最新的未发布开发版本的 FreeBSD。CURRENT 分支可能存在重大错误或不兼容性问题,仅推荐给高级用户使用。 |
使用 uname(1) 命令确定正在使用的 FreeBSD 版本。
# uname -r
13.2-RELEASE根据 FreeBSD 版本和存储库分支,用于更新 13.2-RELEASE 的源码具有存储路径 releng/13.2 。在检出源码时使用该路径:
# mv /usr/src /usr/src.bak (1)
# git clone --branch releng/13.2 https://git.FreeBSD.org/src.git /usr/src (2)| 1 | 将旧目录移开。如果该目录没有本地修改,可以删除。 |
| 2 | 将从 FreeBSD 版本和存储库分支 的路径添加到存储库 URL 中。第三个参数是本地系统上源代码的目标目录。 |
26.6.4. 从源代码构建
整个 世界 或者说除了内核外的所有操作系统被编译。首先这样做是为了提供最新的工具来构建内核。然后构建内核本身:
# cd /usr/src
# make buildworld
# make buildkernel编译后的代码被写入到 /usr/obj 。
这些是基本步骤。下面描述了用于控制构建的其他选项。
26.6.4.1. 执行清理构建
一些 FreeBSD 构建系统的版本会在临时对象目录 /usr/obj 中保留先前编译的代码。这可以通过避免重新编译未更改的代码来加快后续的构建过程。要强制进行全面的清理重建,请在开始构建之前使用 cleanworld 命令。
# make cleanworld26.6.4.2. 设置作业数量
增加多核处理器上的构建作业数量可以提高构建速度。使用 sysctl hw.ncpu 确定核心数。处理器和不同版本的 FreeBSD 使用的构建系统各不相同,因此测试是唯一确定不同作业数量如何影响构建速度的可靠方法。作为起点,考虑在核心数的一半和两倍之间选择值。作业数量使用 -j 参数指定。
例 33. 增加构建作业的数量
使用四个作业构建世界和内核:
# make -j4 buildworld buildkernel26.6.4.3. 仅构建内核
如果源代码发生了变化,必须完成 buildworld。之后,可以随时运行 buildkernel 来构建内核。要仅构建内核:
# cd /usr/src
# make buildkernel26.6.4.4. 构建自定义内核
标准的 FreeBSD 内核基于一个名为 GENERIC 的_内核配置文件_。 GENERIC 内核包含了最常用的设备驱动程序和选项。有时候,构建一个自定义内核是有用或必要的,可以添加或删除设备驱动程序或选项以满足特定需求。
例如,某人正在开发一台内存严重有限的小型嵌入式计算机,可以删除不需要的设备驱动程序或选项,以使内核稍微变小。
内核配置文件位于 /usr/src/sys/arch/conf/ ,其中 arch 是从 uname -m 命令的输出中获取的。在大多数计算机上,这个值是 amd64 ,因此配置文件目录为 /usr/src/sys/amd64/conf/ 。
|
/usr/src 可以被删除或重新创建,因此最好将自定义内核配置文件保存在一个单独的目录中,比如 /root。将内核配置文件链接到 conf 目录中。如果该目录被删除或覆盖,可以将内核配置重新链接到新的目录中。 |
可以通过复制 GENERIC 配置文件来创建自定义配置文件。在这个例子中,新的自定义内核是用于存储服务器的,所以被命名为 STORAGESERVER。
# cp /usr/src/sys/amd64/conf/GENERIC /root/STORAGESERVER
# cd /usr/src/sys/amd64/conf
# ln -s /root/STORAGESERVER .然后编辑 /root/STORAGESERVER,根据 config(5) 中所示的方式添加或删除设备或选项。
通过在命令行中设置 KERNCONF 为内核配置文件来构建自定义内核:
# make buildkernel KERNCONF=STORAGESERVER26.6.5. 安装编译后的代码
在完成 buildworld 和 buildkernel 步骤后,新的内核和系统已被安装:
# cd /usr/src
# make installkernel
# shutdown -r now
# cd /usr/src
# make installworld
# shutdown -r now如果构建了自定义内核,则还必须设置 KERNCONF 以使用新的自定义内核:
# cd /usr/src
# make installkernel KERNCONF=STORAGESERVER
# shutdown -r now
# cd /usr/src
# make installworld
# shutdown -r now26.6.6. 完成更新
完成更新还需要进行一些最后的任务。任何已修改的配置文件都将与新版本合并,过时的库将被定位并删除,然后系统将重新启动。
26.6.6.1. 使用 etcupdate(8) 合并配置文件
etcupdate(8) 是一个用于管理不作为 installworld 的一部分而更新的文件的工具,例如位于 /etc/ 中的文件。它通过对这些文件所做的更改与本地版本进行三方合并来管理更新。与 mergemaster(8) 的交互提示相比,它还旨在最小化用户干预的程度。
|
通常情况下,etcupdate(8) 在执行任务时不需要任何特定的参数。然而,第一次使用 etcupdate(8) 时,有一个方便的中间命令用于检查将要执行的操作: 该命令允许用户审计配置更改。 |
如果 etcupdate(8) 无法自动合并文件,则可以通过手动交互来解决合并冲突,方法是执行以下命令:
# etcupdate resolve|
当从 mergemaster(8) 切换到 etcupdate(8) 时,第一次运行可能会错误地合并更改,从而生成虚假的冲突。为了防止这种情况发生,在更新源代码和构建新的系统之前,请执行以下步骤:
|
26.6.6.2. 使用 mergemaster(8) 合并配置文件
mergemaster(8) 提供了一种将对系统配置文件所做的更改与这些文件的新版本合并的方法。 mergemaster(8) 是 etcupdate(8) 的替代方法。使用 -Ui 选项,mergemaster(8) 会自动更新未被用户修改的文件,并安装尚未存在的新文件。
# mergemaster -Ui如果一个文件需要手动合并,交互式显示将允许用户选择保留文件的哪些部分。有关更多信息,请参阅 mergemaster(8)。
如果没有使用标准的 /usr/src 路径,必须向 mergemaster(8) 传递另一个参数:
# mergemaster -Ui PATH_TO_SRC26.6.6.3. 检查过时的文件和库
更新后可能会保留一些过时的文件或目录。这些文件可以位于以下位置:
# make check-old删除:
# make delete-old还可能存在一些过时的库。可以使用以下方法检测到这些库:
# make check-old-libs也删除
# make delete-old-libs当删除了这些旧库后,仍在使用这些旧库的程序将停止工作。这些程序必须在删除旧库后重新构建或替换。
|
当所有旧文件或目录都被确认为安全可删除时,可以通过在命令中设置 |
26.7. 多台机器的追踪
当多台机器需要跟踪同一个源代码树时,让每台系统都下载源代码并重新构建会浪费磁盘空间、网络带宽和 CPU 周期。解决方案是让一台机器完成大部分工作,而其他机器通过 NFS 挂载这个工作。本节介绍了一种实现方法。有关使用 NFS 的更多信息,请参考 “网络文件系统(NFS)”。
首先,确定一组将运行相同二进制文件的机器,称为 构建集。每台机器可以有自定义的内核,但将运行相同的用户空间二进制文件。从该集合中选择一台机器作为 构建机器,用于构建世界和内核。理想情况下,这是一台速度快且具有足够空闲 CPU 来运行 make buildworld 和 make buildkernel 的机器。
选择一台机器作为 测试机器,在将软件更新投入生产之前对其进行测试。这台机器必须能够承受较长时间的停机。它可以是构建机器,但不一定是。
此构建集中的所有机器都需要通过 NFS 从构建机器挂载 /usr/obj 和 /usr/src。对于多个构建集,/usr/src 应该在一个构建机器上,并在其他机器上通过 NFS 挂载。
确保构建集中所有机器上的 /etc/make.conf 和 /etc/src.conf 与构建机器保持一致。这意味着构建机器必须构建基本系统的所有部分,以便构建集中的任何机器都可以安装。此外,每个构建机器应该使用 /etc/make.conf 中的 KERNCONF 设置其内核名称,并且构建机器应该在其 KERNCONF 中列出所有这些内核,将自己的内核列在第一位。构建机器必须在 /usr/src/sys/arch/conf 中拥有每个机器的内核配置文件。
在构建机上,按照 从源代码更新 FreeBSD 中描述的方式构建内核和世界,但不要在构建机上安装任何东西。相反,将构建好的内核安装在测试机上。在测试机上,通过 NFS 挂载 /usr/src 和 /usr/obj。然后,运行 shutdown now 进入单用户模式,以便安装新的内核和世界,并像往常一样运行 mergemaster。完成后,重新启动以返回到正常的多用户操作。
在验证测试机上的一切正常工作后,使用相同的步骤在构建集中的每台其他机器上安装新软件。
相同的方法可以用于 ports 树。第一步是通过 NFS 将 /usr/ports 共享给构建集中的所有机器。要配置 /etc/make.conf 以共享 distfiles,将 DISTDIR 设置为一个由 NFS 挂载映射到 root 用户的可写共享目录。如果要在本地构建端口,则每台机器应将 WRKDIRPREFIX 设置为本地构建目录。或者,如果构建系统要构建并分发软件包给构建集中的机器,则在构建系统上将 PACKAGES 设置为类似于 DISTDIR 的目录。
26.8. 在非 FreeBSD 主机上构建
从历史上看,构建 FreeBSD 需要一个 FreeBSD 主机。如今,FreeBSD 可以在 Linux 发行版和 macOS 上构建。
在非 FreeBSD 主机上构建 FreeBSD 的推荐方法是使用 tools/build/make.py 脚本。该脚本作为 bmake 的包装器,bmake 是 FreeBSD 使用的 make 实现。它确保了必要的工具,包括实际的 FreeBSD 的 make(1) ,被引导并且构建环境被正确配置。特别是,它设置了外部工具链变量,如 XCC、XLD 等。此外,该脚本可以将任何额外的命令参数,如 -j 4 用于并行构建或特定的 make 目标,传递给 bmake。
|
最近版本的 |
否则,构建 FreeBSD 所需的先决条件列表相当简短。实际上,它只需要安装几个依赖项。
在 macOS 上,唯一的依赖是 LLVM。必要的依赖项可以通过包管理器(例如,Homebrew)进行安装。
brew install llvm在 Linux 发行版上,安装 Clang 10.0 或更新版本,以及 libarchive 和 libbz2 的头文件(通常打包为 libarchive-dev 和 libbz2-dev)。
一旦安装了依赖项,主机就应该能够构建 FreeBSD。
例如,下面的 tools/build/make.py 命令构建整个项目:
MAKEOBJDIRPREFIX=/tmp/obj tools/build/make.py -j 8 TARGET=arm64 TARGET_ARCH=aarch64 buildworld它在 8 个 CPU 上为目标 aarch64:arm64 构建世界,并使用 /tmp/obj 作为对象文件。请注意,在非 FreeBSD 主机上构建时,变量 MAKEOBJDIRPREFIX、TARGET 和 TARGET_ARCH 是必需的。此外,请确保创建由 MAKEOBJDIRPREFIX 环境变量指向的对象目录。
Chapter 27. DTrace
27.1. 简介
DTrace,也被称为动态跟踪,是由 Sun™ 开发的一种工具,用于定位生产和预生产系统中的性能瓶颈。除了诊断性能问题外,DTrace 还可以用于帮助调查和调试 FreeBSD 内核和用户程序中的意外行为。
DTrace 是一个出色的性能分析工具,具有令人印象深刻的一系列功能,用于诊断系统问题。它还可以用于运行预先编写的脚本,以利用其功能。用户可以使用 DTrace D 语言编写自己的实用工具,根据特定需求自定义性能分析。
FreeBSD 实现提供了对内核 DTrace 的完全支持,并对用户空间 DTrace 提供了实验性支持。用户空间 DTrace 允许用户使用 pid 提供程序对用户空间程序进行函数边界跟踪,并在用户空间程序中插入静态探针以供后续跟踪。一些 ports,如 databases/postgresql12-server 和 lang/php74,具有启用静态探针的 DTrace 选项。
DTrace 的官方指南由 Illumos 项目维护,网址为 DTrace 指南。
阅读完本章后,您将了解:
-
什么是 DTrace 及其提供的功能。
-
Solaris™ DTrace 实现与 FreeBSD 提供的实现之间的区别。
-
如何在 FreeBSD 上启用和使用 DTrace。
在阅读本章之前,您应该:
-
了解 UNIX® 和 FreeBSD 基础知识(FreeBSD Basics)。
-
对 FreeBSD 的安全性有一定的了解(Security)。
27.2. 实现差异
尽管 FreeBSD 中的 DTrace 与 Solaris™ 中的 DTrace 相似,但仍存在一些差异。主要的差异在于,在 FreeBSD 中,DTrace 是作为一组内核模块实现的,只有在加载这些模块之后才能使用 DTrace。要加载所有必要的模块:
# kldload dtraceall从 FreeBSD 10.0-RELEASE 开始,当运行 dtrace 时,模块会自动加载。
FreeBSD 使用 DDB_CTF 内核选项来启用对从内核模块和内核本身加载 CTF 数据的支持。 CTF 是 Solaris™ Compact C Type Format,它封装了一种类似于 DWARF 和古老的 stabs 的调试信息的简化形式。CTF 数据是由 ctfconvert 和 ctfmerge 构建工具添加到二进制文件中的。ctfconvert 实用程序解析由编译器创建的 DWARF 部分合并到可执行文件或共享库中。ELF 调试部分,而 ctfmerge 将对象中的 CTFELF
FreeBSD 和 Solaris™ 存在一些不同的 providers 程序。其中最显著的是 dtmalloc provider,它允许在 FreeBSD 内核中按类型跟踪 malloc()。 Solaris™ 中的一些 provider,如 cpc 和 mib,在 FreeBSD 中不存在。这些可能会出现在未来的 FreeBSD 版本中。此外,两个操作系统中都可用的一些 provider 不兼容,因为它们的探测器具有不同的参数类型。因此,在 Solaris™ 上编写的 D 脚本可能无法在 FreeBSD 上不经修改地工作,反之亦然。
由于安全差异,只有 root 用户可以在 FreeBSD 上使用 DTrace。Solaris™ 在安全方面有一些低级别的安全检查,在 FreeBSD 中尚不存在。因此,/dev/dtrace/dtrace 严格限制为 root 用户。
DTrace 属于 Common Development and Distribution License(CDDL)许可证。要在 FreeBSD 上查看此许可证,请参阅 /usr/src/cddl/contrib/opensolaris/OPENSOLARIS.LICENSE 文件,或在线查看 http://opensource.org/licenses/CDDL-1.0。虽然支持 DTrace 的 FreeBSD 内核是 BSD 许可证,但在以二进制形式分发模块或加载二进制文件时,使用 CDDL 许可证。
27.3. 启用 DTrace 支持
在 FreeBSD 9.2 和 10.0 中,DTrace 支持已经内置在 GENERIC 内核中。使用早期版本的 FreeBSD 或者更喜欢静态编译 DTrace 支持的用户应该在自定义内核配置文件中添加以下行,并按照 配置FreeBSD内核 中的说明重新编译内核。
options KDTRACE_HOOKS options DDB_CTF makeoptions DEBUG=-g makeoptions WITH_CTF=1
使用 AMD64 架构的用户还应添加以下行:
options KDTRACE_FRAME
此选项提供对 FBT 的支持。虽然在没有此选项的情况下 DTrace 也可以工作,但对于函数边界跟踪的支持将受到限制。
一旦 FreeBSD 系统重启到新内核,或者使用 kldload dtraceall 加载了 DTrace 内核模块,系统将需要支持 Korn shell,因为 DTrace Toolkit 中有几个工具是用 ksh 编写的。确保安装了 shells/ksh93 软件包或 port。也可以在 shells/pdksh 或 shells/mksh 下运行这些工具。
最后,安装当前的 DTrace Toolkit,这是一个收集系统信息的现成脚本集合。其中包括检查打开文件、内存、CPU 使用情况等脚本。 FreeBSD 10 会将其中一些脚本安装在 /usr/share/dtrace 目录下。对于其他版本的 FreeBSD,或者要安装完整的 DTrace Toolkit,可以使用 sysutils/dtrace-toolkit 包或 port 进行安装。
|
在 /usr/share/dtrace 中找到的脚本已经专门移植到了 FreeBSD。并非所有在 DTrace Toolkit 中找到的脚本都可以直接在 FreeBSD 上运行,有些脚本可能需要一些努力才能在 FreeBSD 上运行。 |
DTrace 工具包中包含了许多使用 DTrace 特殊语言编写的脚本。这种语言被称为 D 语言,它与 C ++非常相似。本文档不会深入讨论该语言的细节,但在 Illumos 动态跟踪指南 中有详细介绍。
27.4. 使用 DTrace
DTrace 脚本由一个或多个探针(或称为仪器点)的列表组成,每个探针都与一个动作相关联。当探针的条件满足时,执行相应的动作。例如,当文件被打开、进程被启动或者代码行被执行时,可能会触发一个动作。动作可以是记录一些信息或修改上下文变量。读取和写入上下文变量允许探针共享信息并协同分析不同事件之间的关联性。
要查看所有探针,管理员可以执行以下命令:
# dtrace -l | more每个探针都有一个 ID,一个 PROVIDER(dtrace 或 fbt),一个 MODULE 和一个 FUNCTION NAME。有关此命令的更多信息,请参阅 dtrace(1)。
本节中的示例提供了如何使用 DTrace Toolkit 中两个完全支持的脚本的概述:hotkernel 和 procsystime 脚本。
hotkernel 脚本旨在识别哪个函数使用了最多的内核时间。它将产生类似以下的输出:
# cd /usr/local/share/dtrace-toolkit
# ./hotkernel
Sampling... Hit Ctrl-C to end.按照指示,使用 Ctrl+C 键组合来停止进程。在终止后,脚本将显示一个内核函数列表和时间信息,按时间递增的顺序排序输出:
kernel`_thread_lock_flags 2 0.0%
0xc1097063 2 0.0%
kernel`sched_userret 2 0.0%
kernel`kern_select 2 0.0%
kernel`generic_copyin 3 0.0%
kernel`_mtx_assert 3 0.0%
kernel`vm_fault 3 0.0%
kernel`sopoll_generic 3 0.0%
kernel`fixup_filename 4 0.0%
kernel`_isitmyx 4 0.0%
kernel`find_instance 4 0.0%
kernel`_mtx_unlock_flags 5 0.0%
kernel`syscall 5 0.0%
kernel`DELAY 5 0.0%
0xc108a253 6 0.0%
kernel`witness_lock 7 0.0%
kernel`read_aux_data_no_wait 7 0.0%
kernel`Xint0x80_syscall 7 0.0%
kernel`witness_checkorder 7 0.0%
kernel`sse2_pagezero 8 0.0%
kernel`strncmp 9 0.0%
kernel`spinlock_exit 10 0.0%
kernel`_mtx_lock_flags 11 0.0%
kernel`witness_unlock 15 0.0%
kernel`sched_idletd 137 0.3%
0xc10981a5 42139 99.3%这个脚本也可以用于内核模块。要使用这个功能,请使用 -m 选项运行脚本:
# ./hotkernel -m
Sampling... Hit Ctrl-C to end.
^C
MODULE COUNT PCNT
0xc107882e 1 0.0%
0xc10e6aa4 1 0.0%
0xc1076983 1 0.0%
0xc109708a 1 0.0%
0xc1075a5d 1 0.0%
0xc1077325 1 0.0%
0xc108a245 1 0.0%
0xc107730d 1 0.0%
0xc1097063 2 0.0%
0xc108a253 73 0.0%
kernel 874 0.4%
0xc10981a5 213781 99.6%procsystime 脚本用于捕获并打印给定进程 ID(PID) 或进程名称的系统调用时间使用情况。在下面的示例中,一个新的 /bin/csh 实例被创建。然后,执行了 procsystime 并保持等待状态,同时在另一个 csh 实例中输入了一些命令。这是这个测试的结果:
# ./procsystime -n csh
Tracing... Hit Ctrl-C to end...
^C
Elapsed Times for processes csh,
SYSCALL TIME (ns)
getpid 6131
sigreturn 8121
close 19127
fcntl 19959
dup 26955
setpgid 28070
stat 31899
setitimer 40938
wait4 62717
sigaction 67372
sigprocmask 119091
gettimeofday 183710
write 263242
execve 492547
ioctl 770073
vfork 3258923
sigsuspend 6985124
read 3988049784如图所示,read() 系统调用使用的时间最长,以纳秒为单位,而 getpid() 系统调用使用的时间最短。
Chapter 28. USB 设备模式 /USB OTG
28.1. 简介
本章介绍了在 FreeBSD 中使用 USB 设备模式和 USB On The Go ( USB OTG )。这包括虚拟串行控制台、虚拟网络接口和虚拟 USB 驱动器的使用。
当在支持 USB 设备模式或 USB OTG 的硬件上运行时,例如许多嵌入式板上内置的硬件, FreeBSD USB 堆栈可以运行在“设备模式”下。设备模式使得计算机能够以不同种类的 USB 设备类别呈现自身,包括串口、网络适配器、大容量存储设备,或者它们的组合。像笔记本电脑或台式电脑这样的 USB 主机可以像访问物理 USB 设备一样访问它们。设备模式有时也被称为“ USB 小工具模式”。
硬件可以通过两种基本方式提供设备模式功能:一种是使用单独的“客户端端口”,该端口仅支持设备模式;另一种是使用 USB OTG ( On-The-Go )端口,该端口可以同时提供设备模式和主机模式。对于 USB OTG 端口, USB 堆栈会根据连接到端口的设备自动切换主机端和设备端。将 USB 设备(如存储设备)连接到端口会导致 FreeBSD 切换到主机模式。将 USB 主机(如计算机)连接到端口会导致 FreeBSD 切换到设备模式。而单用途的“客户端端口”始终以设备模式工作。
FreeBSD 向 USB 主机呈现的内容取决于 hw.usb.template sysctl 。一些模板提供单个设备,例如串行终端;其他模板提供多个设备,可以同时使用。一个例子是模板 10 ,它提供了一个大容量存储设备、一个串行控制台和一个网络接口。请参阅 usb_template(4) 以获取可用值的列表。
请注意,在某些情况下,根据硬件和主机操作系统的不同,为了使主机注意到配置更改,必须要么物理断开并重新连接,要么以特定于系统的方式强制重新扫描 USB 总线。当主机上运行 FreeBSD 时,可以使用 usbconfig(8) reset 命令。如果 USB 主机已经连接到 USBOTG 插座,则还必须在加载 usb_template.ko 之后执行此操作。
阅读完本章后,您将了解:
-
在 FreeBSD 上如何设置 USB 设备模式功能。
-
如何在 FreeBSD 上配置虚拟串口。
-
如何从不同的操作系统连接到虚拟串口。
-
如何配置 FreeBSD 以提供虚拟 USB 网络接口。
-
如何配置 FreeBSD 以提供虚拟 USB 存储设备。
28.2. USB 虚拟串口
28.2.1. 配置 USB 设备模式串口
虚拟串口支持由模板 3 、 8 和 10 提供。请注意,模板 3 可以在 Microsoft Windows 10 上使用,无需特殊驱动程序和 INF 文件。其他主机操作系统可以与这三个模板一起使用。必须加载 usb_template(4) 和 umodem(4) 内核模块。
要启用 USB 设备模式的串口,请将以下行添加到 [/etc/ttys] 文件中:
ttyU0 "/usr/libexec/getty 3wire" vt100 onifconsole secure ttyU1 "/usr/libexec/getty 3wire" vt100 onifconsole secure
然后将以下行添加到 [/etc/devd.conf] 文件中:
notify 100 {
match "system" "DEVFS";
match "subsystem" "CDEV";
match "type" "CREATE";
match "cdev" "ttyU[0-9]+";
action "/sbin/init q";
};
如果 devd(8) 已经在运行,请重新加载配置。
# service devd restart确保所需的模块已加载并在启动时设置正确的模板,通过将这些行添加到 [/boot/loader.conf]# 文件中,如果该文件不存在,则创建它:
umodem_load="YES"
hw.usb.template=3要在不重新启动的情况下加载模块并设置模板,请使用以下命令:
# kldload umodem
# sysctl hw.usb.template=328.2.2. 从 FreeBSD 连接到 USB 设备模式串口
要连接到配置为提供 USB 设备模式串行端口的板子,将 USB 主机(例如笔记本电脑)连接到板子的 USB OTG 或 USB 客户端端口。在主机上使用 pstat -t 命令列出终端线路。在列表的末尾附近,您应该会看到一个 USB 串行端口,例如"ttyU0"。要打开连接,请使用:
# cu -l /dev/ttyU0按下 Enter 键几次后,您将看到一个登录提示符。
28.2.3. 在 macOS 上连接 USB 设备模式串口
要连接到配置为提供 USB 设备模式串行端口的板子,将 USB 主机(例如笔记本电脑)连接到板子的 USB OTG 或 USB 客户端端口。要打开连接,请使用:
# cu -l /dev/cu.usbmodemFreeBSD128.2.4. 在 Linux 上连接 USB 设备模式串口
要连接到配置为提供 USB 设备模式串行端口的板子,将 USB 主机(例如笔记本电脑)连接到板子的 USB OTG 或 USB 客户端端口。要打开连接,请使用:
# minicom -D /dev/ttyACM028.2.5. 在 Microsoft Windows 10 上连接 USB 设备模式串口
要连接到配置为提供 USB 设备模式串口的板子,需要将 USB 主机(例如笔记本电脑)连接到板子的 USB OTG 或 USB 客户端端口。要打开连接,您需要一个串口终端程序,例如 PuTTY 。要检查 Windows 使用的 COM 端口名称,请运行设备管理器,展开“端口( COM 和 LPT )”。您将看到一个类似于“ USB 串行设备( COM4 )”的名称。运行您选择的串口终端程序,例如 PuTTY 。在 PuTTY 对话框中将“连接类型”设置为“串行”,在“串行线路”对话框中输入从设备管理器获取的 COMx ,并点击打开。
28.3. USB 设备模式网络接口
虚拟网络接口的支持由模板 1 、 8 和 10 提供。请注意,它们都不适用于 Microsoft Windows 。其他主机操作系统都适用于这三个模板。必须加载 usb_template(4) 和 if_cdce(4) 内核模块。
确保所需的模块已加载并在启动时设置正确的模板,通过将这些行添加到 [/boot/loader.conf]# 文件中,如果该文件不存在,则创建它:
if_cdce_load="YES" hw.usb.template=1
要在不重新启动的情况下加载模块并设置模板,请使用以下命令:
# kldload if_cdce
# sysctl hw.usb.template=128.4. USB 虚拟存储设备
|
cfumass(4) 驱动程序是一个 USB 设备模式驱动程序,首次在 FreeBSD 12.0 中可用。 |
模板 0 和 10 提供了大容量存储目标。必须加载 usb_template(4) 和 cfumass(4) 内核模块。 cfumass(4) 与 CTL 子系统进行接口交互,该子系统也用于 iSCSI 或光纤通道目标。在主机端, USB 大容量存储发起器只能访问一个逻辑单元( LUN ),即 LUN 0 。
28.4.1. 使用 cfumass 启动脚本配置 USB 大容量存储目标
设置只读 USB 存储目标的最简单方法是使用 cfumass rc 脚本。要以这种方式配置它,将要呈现给 USB 主机机器的文件复制到 /var/cfumass 目录,并将以下行添加到 /etc/rc.conf 文件中:
cfumass_enable="YES"
要在不重新启动的情况下配置目标,请运行以下命令:
# service cfumass start与串行和网络功能不同,模板不应在 /boot/loader.conf 中设置为 0 或 10 。这是因为在设置模板之前必须设置 LUN 。当启动时, cfumass 启动脚本会自动设置正确的模板编号。
28.4.2. 使用其他方法配置 USB 大容量存储设备
本章的其余部分提供了在不使用 cfumass rc 文件的情况下设置目标的详细描述。如果想要提供可写的逻辑单元( LUN ),这是必要的。
USB Mass Storage 不需要运行 ctld(8) 守护进程,尽管如果需要可以使用它。这与 iSCSI 不同。因此,有两种配置目标的方式: ctladm(8) 或 ctld(8) 。两者都需要加载 cfumass.ko 内核模块。可以手动加载该模块:
# kldload cfumass如果 cfumass.ko 没有被编译进内核中,可以在 /boot/loader.conf 中设置在启动时加载该模块:
cfumass_load="YES"
可以在没有 ctld(8) 守护进程的情况下创建一个 LUN 。
# ctladm create -b block -o file=/data/target0这将把图像文件 /data/target0 的内容作为 LUN 提供给 USB 主机。在执行命令之前,文件必须存在。要在系统启动时配置 LUN ,请将该命令添加到 /etc/rc.local 中。
ctld(8) 也可以用来管理逻辑单元( LUNs )。创建 /etc/ctl.conf 文件,添加一行到 /etc/rc.conf 文件中,以确保在启动时自动启动 ctld(8) ,然后启动守护进程。
这是一个简单的 /etc/ctl.conf 配置文件的示例。有关选项的更完整描述,请参考 ctl.conf(5) 。
target naa.50015178f369f092 {
lun 0 {
path /data/target0
size 4G
}
}
该示例创建了一个具有单个 LUN 的单个目标。 naa.50015178f369f092 是由 32 个随机十六进制数字组成的设备标识符。 path 行定义了指向支持 LUN 的文件或 zvol 的完整路径。在启动 ctld(8) 之前,该文件必须存在。第二行是可选的,用于指定 LUN 的大小。
为了确保 ctld(8) 守护进程在启动时自动启动,请将以下行添加到 .filename#/etc/rc.conf#:
ctld_enable="YES"
要启动 ctld(8) ,请运行以下命令:
# service ctld start当启动 ctld(8) 守护进程时,它会读取 .filename#/etc/ctl.conf# 文件。如果在守护进程启动后编辑了此文件,则重新加载更改以立即生效:
# service ctld reloadPart IV: 网络通信
FreeBSD 是最广泛部署的高性能网络服务器操作系统之一。本部分的章节内容包括:
-
串行通信
-
PPP 和以太网上的 PPP
-
电子邮件
-
运行网络服务器
-
防火墙
-
其他高级网络主题
这些章节的设计是在需要信息时阅读。它们不需要按照特定的顺序阅读,也不需要在使用 FreeBSD 在网络环境中之前阅读所有章节。
Chapter 29. 串行通信
29.1. 简介
UNIX® 一直以来都支持串行通信,因为最早的 UNIX® 机器依赖串行线路进行用户输入和输出。从平均终端只包含一个每秒 10 个字符的串行打印机和一个键盘的时代以来,情况发生了很大变化。本章介绍了在 FreeBSD 上使用串行通信的一些方法。
阅读完本章后,您将了解:
-
如何将终端连接到 FreeBSD 系统。
-
如何使用调制解调器拨打远程主机。
-
如何允许远程用户通过调制解调器登录到 FreeBSD 系统。
-
如何从串行控制台启动 FreeBSD 系统。
在阅读本章之前,你应该:
-
了解如何 配置和安装自定义内核。
-
了解 FreeBSD 的权限和进程。
-
可以访问与 FreeBSD 一起使用的串行硬件的技术手册。
29.2. 串行术语和硬件
以下术语常用于串行通信:
- bps
-
每秒比特数(bps)是数据传输的速率。
- DTE
-
数据终端设备(DTE)是串行通信中的两个端点之一。一个例子就是计算机。
- DCE
-
数据通信设备(DCE)是串行通信中的另一端点。通常情况下,它是一个调制解调器或串行终端。
- RS-232
-
最初定义硬件串行通信的标准。后来更名为 TIA-232。
在涉及通信数据速率时,本节不使用术语“波特(baud)”。波特是指在一段时间内进行的电气状态转换的数量,而 bps 是正确的术语。
要将串行终端连接到 FreeBSD 系统,需要计算机上的串行端口和连接到串行设备的适当电缆。已经熟悉串行硬件和电缆的用户可以安全地跳过本节。
29.2.1. 串行电缆和端口
有几种不同类型的串行电缆。其中最常见的两种类型是空模拟电缆和标准 RS-232 电缆。硬件的文档应该描述所需的电缆类型。
这两种类型的电缆在连接线缆到连接器的方式上有所不同。每根线代表一个信号,定义的信号总结在 RS-232C 信号名称 中。标准的串行电缆直接传递所有的 RS-232C 信号。例如,电缆一端的“传输数据”引脚连接到另一端的“传输数据”引脚。这种类型的电缆用于将调制解调器连接到 FreeBSD 系统,并且也适用于某些终端。
空模拟电缆将一个端口上的“传输数据”引脚与另一个端口上的“接收数据”引脚进行切换。连接器可以是 DB-25 或 DB-9。
可以使用在 DB-25 到 DB-25 空调制模电缆、DB-9 到 DB-9 的空模线缆 和 DB-9 到 DB-25 空模拟电缆 中总结的引脚连接来构建一个空调制电缆。虽然标准要求使用直通的引脚 1 到引脚 1 的“保护地”线,但通常会省略。一些终端只使用引脚 2 、 3 和 7 ,而其他终端则需要不同的配置。如果有疑问,请参考硬件的文档。
| 首字母缩略词 | 名称 |
|---|---|
RD |
接收到的数据 |
TD |
传输的数据 |
DTR |
数据终端就绪 |
DSR |
数据集准备完毕 |
DCD |
数据载波检测 |
SG |
Signal Ground |
RTS |
请求发送 |
CTS |
发送准备 |
| 信号 | 引脚号码 | 引脚号码 | 信号 | |
|---|---|---|---|---|
SG |
7 |
连接到 |
7 |
SG |
TD |
2 |
连接到 |
3 |
RD |
RD |
3 |
连接到 |
2 |
TD |
RTS |
4 |
连接到 |
5 |
CTS |
CTS |
5 |
连接到 |
4 |
RTS |
DTR |
20 |
连接到 |
6 |
DSR |
DTR |
20 |
连接到 |
8 |
DCD |
DSR |
6 |
连接到 |
20 |
DTR |
DCD |
8 |
连接到 |
20 |
DTR |
| 信号 | 引脚号码 | 引脚号码 | 信号 | |
|---|---|---|---|---|
RD |
2 |
连接到 |
3 |
TD |
TD |
3 |
连接到 |
2 |
RD |
DTR |
4 |
连接到 |
6 |
DSR |
DTR |
4 |
连接到 |
1 |
DCD |
SG |
5 |
连接到 |
5 |
SG |
DSR |
6 |
连接到 |
4 |
DTR |
DCD |
1 |
连接到 |
4 |
DTR |
RTS |
7 |
连接到 |
8 |
CTS |
CTS |
8 |
连接到 |
7 |
RTS |
| 信号 | 引脚号码 | 引脚号码 | 信号 | |
|---|---|---|---|---|
RD |
2 |
连接到 |
2 |
TD |
TD |
3 |
连接到 |
3 |
RD |
DTR |
4 |
连接到 |
6 |
DSR |
DTR |
4 |
连接到 |
8 |
DCD |
SG |
5 |
连接到 |
7 |
SG |
DSR |
6 |
连接到 |
20 |
DTR |
DCD |
1 |
连接到 |
20 |
DTR |
RTS |
7 |
连接到 |
5 |
CTS |
CTS |
8 |
连接到 |
4 |
RTS |
|
当一个端口的一根引脚连接到另一个端口的一对引脚时,通常会使用一根短线连接这对引脚的连接器,以及一根长线连接到另一个单独的引脚。 |
串口是在 FreeBSD 主机和终端之间传输数据的设备。存在几种类型的串口。在购买或制作电缆之前,请确保它适配终端和 FreeBSD 系统上的串口。
大多数终端设备都有 DB-25 端口。个人电脑可能有 DB-25 或 DB-9 端口。多端口串行卡可能有 RJ-12 或 RJ-45 端口。请查看随附硬件的文档,以了解端口类型的规格,或者通过目视确认端口类型。
在 FreeBSD 中,每个串口通过 /dev 中的一个条目进行访问。有两种不同类型的条目:
-
呼叫端口的命名方式为 /dev/ttyuN ,其中 N 为端口号,从零开始计数。如果终端连接到第一个串口(COM1),则使用 /dev/ttyu0 来引用该终端。如果终端连接到第二个串口(COM2),则使用 /dev/ttyu1 ,依此类推。通常,呼叫端口用于终端。呼叫端口要求串行线路正确工作时要断言“数据载波检测”信号。
-
在 FreeBSD 8.X 及更高版本上,呼叫输出端口被命名为 /dev/cuauN,而在 FreeBSD 7.X 及更低版本上被命名为 /dev/cuadN。呼叫输出端口通常不用于终端,而是用于调制解调器。如果串行电缆或终端不支持“数据载波检测”信号,可以使用呼叫输出端口。
FreeBSD 还提供了初始化设备(/dev/ttyuN.init 和 /dev/cuauN.init 或 /dev/cuadN.init)和锁定设备( /dev/ttyuN.lock 和 /dev/cuauN.lock 或 /dev/cuadN.lock)。初始化设备用于在每次打开端口时初始化通信端口参数,例如对于使用 RTS/CTS 信号进行流量控制的调制解调器,可以使用 crtscts。锁定设备用于锁定端口上的标志,以防止用户或程序更改某些参数。有关终端设置、锁定和初始化设备以及设置终端选项的信息,请参阅 termios(4) 、uart(4) 和 stty(1)。
29.2.2. 串口配置
默认情况下,FreeBSD 支持四个串口,通常被称为 COM1、COM2、COM3 和 COM4。FreeBSD 还支持一些简单的多串口接口卡,如 BocaBoard 1008 和 2016,以及一些更智能的多串口卡,如 Digiboard 制造的卡。然而,默认内核只会寻找标准的 COM 端口。
要查看系统是否识别串口,请查找以 uart 开头的系统引导消息。
# grep uart /var/run/dmesg.boot如果系统无法识别所有所需的串口,可以将其他条目添加到 /boot/device.hints 文件中。该文件已经包含了针对 COM1 的 hint.uart.0. 条目和针对 COM1 的 hint.uart.1. 条目。当为 COM3 添加串口条目时,请使用 0x3E8 ,而对于 COM4,请使用 0x2E8。常见的 IRQ 地址是 COM3 的 5 和 COM4 的 9。
要确定端口使用的默认终端 I/O 设置集,请指定其设备名称。此示例确定了 COM2 上呼入端口的设置。
# stty -a -f /dev/ttyu1系统范围内的串行设备初始化由 /etc/rc.d/serial 控制。该文件影响串行设备的默认设置。要更改设备的设置,请使用 stty 命令。默认情况下,更改的设置在设备关闭之前有效,当设备重新打开时,它会恢复到默认设置。要永久更改默认设置,请打开并调整初始化设备的设置。例如,要为 ttyu5 打开 CLOCAL 模式、 8 位通信和 XON/XOFF 流控制,请输入:
# stty -f /dev/ttyu5.init clocal cs8 ixon ixoff为了防止应用程序更改某些设置,请对锁定设备进行调整。例如,要将 ttyu5 的速度锁定为 57600 bps ,请输入:
# stty -f /dev/ttyu5.lock 57600现在,任何打开 ttyu5 并尝试更改端口速度的应用程序都将被困在 57600 bps。
29.3. 终端
终端提供了一种方便且低成本的方式,用于在未连接到计算机控制台或网络的情况下访问 FreeBSD 系统。本节介绍了如何在 FreeBSD 中使用终端。
最初的 UNIX® 系统没有控制台。相反,用户通过连接到计算机的串口登录并运行程序。
在几乎所有类 UNIX® 操作系统中,包括 FreeBSD ,仍然存在在串行端口上建立登录会话的能力。通过使用连接到未使用的串行端口的终端,用户可以登录并运行任何通常可以在控制台或 xterm 窗口中运行的文本程序。
FreeBSD 系统可以连接多个终端。可以使用一台旧的备用计算机作为终端,通过有线连接到运行 FreeBSD 的更强大的计算机上。这可以将原本可能是单用户计算机转变为功能强大的多用户系统。
FreeBSD 支持三种类型的终端:
- 哑终端
-
哑终端是一种专门通过串行线连接到计算机的硬件。它们被称为“哑终端”,是因为它们只有足够的计算能力来显示、发送和接收文本。这些设备上无法运行任何程序。相反,哑终端连接到运行所需程序的计算机上。
有许多制造商生产的数百种哑终端,几乎任何一种终端都可以与 FreeBSD 配合使用。一些高端终端甚至可以显示图形,但只有特定的软件包才能利用这些高级功能。
在工作环境中,工人不需要访问图形应用程序时,哑终端非常受欢迎。
- 计算机作为终端的角色
-
由于哑终端只具备足够的能力来显示、发送和接收文本,任何多余的计算机都可以成为哑终端。所需的只是正确的电缆和一些在计算机上运行的“终端仿真”软件。
这个配置非常有用。例如,如果一个用户正在忙于在 FreeBSD 系统的控制台上工作,另一个用户可以同时使用一台性能较弱的个人电脑作为终端连接到 FreeBSD 系统上进行纯文本工作。
例如,要从运行 FreeBSD 的客户端系统连接到另一个系统的串行连接:
# cu -l /dev/cuauN端口从零开始编号。这意味着 COM1 对应的是 /dev/cuau0 。
通过 Ports Collection 可以获得其他的程序,例如 comms/minicom 。
- X 终端
-
X 终端是最复杂的终端类型。它们通常不连接串行端口,而是连接到像以太网这样的网络。它们不仅仅局限于纯文本应用程序,还可以显示任何 Xorg 应用程序。
本章不涵盖 X 终端的设置、配置或使用。
29.3.1. 终端配置
本节介绍了如何配置 FreeBSD 系统以在串行终端上启用登录会话。它假设系统能够识别终端所连接的串行端口,并且终端使用了正确的连接线缆。
在 FreeBSD 中,init 读取 /etc/ttys 文件并在可用的终端上启动一个 getty 进程。 getty 进程负责读取登录名并启动 login 程序。允许登录的 FreeBSD 系统上的端口在 /etc/ttys 文件中列出。例如,第一个虚拟控制台 ttyv0 在该文件中有一个条目,允许在控制台上登录。该文件还包含其他虚拟控制台、串口和伪终端的条目。对于硬连线终端,串口的 /dev 条目被列为不带 /dev 部分的形式。例如,/dev/ttyv0 被列为 ttyv0。
默认的 /etc/ttys 配置支持前四个串口,即 ttyu0 到 ttyu3。
ttyu0 "/usr/libexec/getty std.9600" dialup off secure ttyu1 "/usr/libexec/getty std.9600" dialup off secure ttyu2 "/usr/libexec/getty std.9600" dialup off secure ttyu3 "/usr/libexec/getty std.9600" dialup off secure
当连接终端到其中一个端口时,修改默认条目以设置所需的速度和终端类型,打开设备,并且如果需要,更改端口的安全设置。如果终端连接到另一个端口,添加一个端口的条目。
配置终端条目 配置了两个终端在 /etc/ttys 中。第一个条目配置了一个连接到 COM2 的 Wyse-50 终端。第二个条目配置了一台运行 Procomm 终端软件模拟 VT-100 终端的旧计算机。该计算机连接到多端口串行卡的第六个串行端口。
例 34. 配置终端条目
ttyu1 "/usr/libexec/getty std.38400" wy50 on insecure ttyu5 "/usr/libexec/getty std.19200" vt100 on insecure
第一个字段指定了串行终端的设备名称。
第二个字段告诉 getty 初始化并打开线路,设置线路速度,提示用户输入用户名,然后执行 login 程序。可选的 getty 类型 配置终端线路的特性,如 bps 速率和奇偶校验。可用的 getty 类型在 /etc/gettytab 中列出。在几乎所有情况下,以 std 开头的 getty 类型适用于硬连线终端,因为这些条目忽略奇偶校验。每个 bps 速率从 110 到 115200 都有一个 std 条目。有关更多信息,请参阅 gettytab(5)。在设置 getty 类型时,请确保与终端使用的通信设置匹配。对于此示例,Wyse-50 不使用奇偶校验,并以 38400 bps 连接。计算机不使用奇偶校验,并以 19200 bps 连接。
第三个字段是终端的类型。对于拨号端口,通常使用 unknown 或 dialup,因为用户可以使用几乎任何类型的终端或软件进行拨号。由于有线终端的终端类型不会改变,可以指定来自 /etc/termcap 的真实终端类型。在这个例子中, Wyse-50 使用真实的终端类型,而运行 Procomm 的计算机设置为模拟 VT-100 。
第四个字段指定端口是否应该被启用。要在该端口上启用登录,此字段必须设置为 on。
最后一个字段用于指定端口是否安全。将端口标记为 secure 表示该端口足够可信,允许 root 从该端口登录。不安全的端口不允许 root 登录。在不安全的端口上,用户必须从非特权帐户登录,然后使用 su 或类似的机制获取超级用户权限,如 “超级用户帐户” 中所述。出于安全原因,建议将此设置更改为 insecure。
在对 /etc/ttys 文件进行任何更改后,向 init 进程发送 SIGHUP(hangup)信号,强制其重新读取配置文件。
# kill -HUP 1由于 init 始终是系统上运行的第一个进程,因此它的进程 ID 始终为 1 。
如果一切设置正确,所有电缆都已连接好,终端已经启动,那么每个终端现在应该运行着一个 getty 进程,并且每个终端上都应该有登录提示符可用。
29.3.2. 连接故障排除
即使在对细节极为细致入微的情况下,设置终端时仍然可能出现问题。以下是一些常见症状和一些建议的解决方法。
如果没有出现登录提示,请确保终端已插好并已开机。如果终端是个人电脑充当的,确保它在正确的串口上运行终端仿真软件。
确保电缆牢固地连接到终端和 FreeBSD 计算机上。确保它是正确类型的电缆。
确保终端和 FreeBSD 在波特率和奇偶校验设置上达成一致。对于视频显示终端,请确保对比度和亮度控制已调高。如果是打印终端,请确保纸张和墨水充足。
使用 ps 命令确保 getty 进程正在运行并为终端提供服务。例如,以下列表显示 getty 正在第二个串口 ttyu1 上运行,并且正在使用 /etc/gettytab 中的 std.38400 条目:
# ps -axww|grep ttyu
22189 d1 Is+ 0:00.03 /usr/libexec/getty std.38400 ttyu1如果没有运行 getty 进程,请确保端口在 /etc/ttys 中已启用。在修改 /etc/ttys 后记得运行 kill -HUP 1 命令。
如果 getty 进程正在运行,但终端仍然没有显示登录提示符,或者显示了提示符但无法接受键入的输入,那么终端或电缆可能不支持硬件握手。尝试将 /etc/ttys 中的条目从 std.38400 更改为 3wire.38400 ,然后在修改 /etc/ttys 后运行 kill -HUP 1 命令。 3wire 条目类似于 std ,但忽略了硬件握手。当使用 3wire 时,可能还需要降低波特率或启用软件流控制以防止缓冲区溢出。
如果登录提示符显示垃圾字符,请确保终端和 FreeBSD 在波特率和奇偶校验设置上达成一致。检查 getty 进程,确保使用了正确的 getty 类型。如果没有,请编辑 /etc/ttys 并运行 kill -HUP 1 。
如果字符出现重复,并且在键入时密码出现,请将终端或终端仿真软件从“half duplex”或“local echo”切换到“full duplex”。
29.4. 拨入服务
为了配置一个用于拨入服务的 FreeBSD 系统,与配置终端类似,只是使用调制解调器而不是终端设备。 FreeBSD 支持外部和内部调制解调器。
外部调制解调器更方便,因为它们通常可以通过存储在非易失性 RAM 中的参数进行配置,并且它们通常提供带有指示灯的指示器,显示重要的 RS-232 信号的状态,以指示调制解调器是否正常运行。
内置调制解调器通常缺乏非易失性 RAM ,因此它们的配置可能仅限于设置 DIP 开关。如果内置调制解调器有任何信号指示灯,当系统盖盖上时时很难查看。
使用外部调制解调器时,需要使用适当的电缆。标准的 RS-232C 串行电缆应该足够。
FreeBSD 在超过 2400 bps 的速度下需要 RTS 和 CTS 信号进行流控制,需要 CD 信号来检测呼叫是否已接听或线路是否已挂断,并且需要 DTR 信号在会话结束后重置调制解调器。有些电缆没有连接所有必需的信号,所以如果登录会话在线路挂断后仍然存在,可能是电缆存在问题。有关这些信号的更多信息,请参考 串行电缆和端口 。
与其他类 UNIX® 操作系统一样, FreeBSD 使用硬件信号来判断呼叫是否已接听或线路是否已挂断,并在呼叫结束后挂断和重置调制解调器。 FreeBSD 避免向调制解调器发送命令或监视调制解调器的状态报告。
FreeBSD 支持 NS8250 、 NS16450 、 NS16550 和 NS16550A 基于 RS-232C (CCITT V.24) 通信接口。8250 和 16450 设备具有单字符缓冲区。 16550 设备提供了一个 16 字符缓冲区,可以提高系统性能。普通的 16550 设备存在缺陷,无法使用 16 字符缓冲区,因此如果可能的话,请使用 16550A 设备。由于单字符缓冲区设备需要操作系统进行更多的工作,所以更倾向于使用基于 16550A 的串行接口卡。如果系统有许多活动的串行端口或将承受重负载,基于 16550A 的卡对于低误码率通信更好。
本节的其余部分演示了如何配置调制解调器以接收传入连接,如何与调制解调器通信,并提供一些故障排除技巧。
29.4.1. 调制解调器配置
与终端一样,init 为每个配置的串口生成一个 getty 进程,用于拨入连接。当用户拨号并且调制解调器连接成功时,调制解调器会报告“Carrier Detect”信号。内核注意到已检测到载波,并指示 getty 打开端口并在指定的初始线速度下显示一个 login: 提示符。在典型的配置中,如果接收到垃圾字符,通常是由于调制解调器的连接速度与配置的速度不同, getty 会尝试调整线速度,直到接收到合理的字符为止。用户输入登录名后,getty 执行 login ,通过询问用户的密码,然后启动用户的 shell 来完成登录过程。
关于拨号调制解调器有两种观点。一种配置方法是设置调制解调器和系统,以便无论远程用户以何种速度拨入,拨入的 RS-232 接口都以固定速度运行。这种配置的好处是远程用户总是能立即看到系统登录提示。缺点是系统不知道用户的真实数据速率,因此像 Emacs 这样的全屏程序不会调整其屏幕绘制方法,以使其在较慢的连接下响应更好。
第二种方法是配置 RS-232 接口,根据远程用户的连接速度来变化速度。由于 getty 不了解任何特定调制解调器的连接速度报告,它会以初始速度发送 login: 消息,并监视响应中返回的字符。如果用户看到乱码,他们应该按下 Enter 直到看到一个可识别的提示符。如果数据速率不匹配,getty 会将用户输入的任何内容视为乱码,尝试下一个速度,并再次给出 login: 提示符。在用户看到一个良好的提示符之前,这个过程通常只需要按下一个或两个按键。这个登录序列看起来不像锁定速度的方法那样干净,但是低速连接的用户应该能够从全屏程序中获得更好的交互响应。
在锁定调制解调器的数据通信速率时,不需要对 /etc/gettytab 进行任何更改。然而,对于匹配速度的配置,可能需要添加额外的条目来定义调制解调器使用的速率。此示例配置了一个速率为 14.4 Kbps 的调制解调器,顶部接口速率为 19.2 Kbps ,使用 8 位,无奇偶校验连接。它配置 getty 以 19.2 Kbps 启动 V.32bis 连接的通信速率,然后循环使用 9600 bps 、 2400 bps 、 1200 bps 、 300 bps ,最后回到 19.2 Kbps 。通信速率循环是通过 nx= (next table) 功能实现的。每行使用 tc= (table continuation) 条目来获取特定数据速率的其余设置。
#
# Additions for a V.32bis Modem
#
um|V300|High Speed Modem at 300,8-bit:\
:nx=V19200:tc=std.300:
un|V1200|High Speed Modem at 1200,8-bit:\
:nx=V300:tc=std.1200:
uo|V2400|High Speed Modem at 2400,8-bit:\
:nx=V1200:tc=std.2400:
up|V9600|High Speed Modem at 9600,8-bit:\
:nx=V2400:tc=std.9600:
uq|V19200|High Speed Modem at 19200,8-bit:\
:nx=V9600:tc=std.19200:
对于一个 28.8 Kbps 的调制解调器,或者为了利用 14.4 Kbps 调制解调器上的压缩功能,可以使用更高的通信速率,如下面的示例所示:
#
# Additions for a V.32bis or V.34 Modem
# Starting at 57.6 Kbps
#
vm|VH300|Very High Speed Modem at 300,8-bit:\
:nx=VH57600:tc=std.300:
vn|VH1200|Very High Speed Modem at 1200,8-bit:\
:nx=VH300:tc=std.1200:
vo|VH2400|Very High Speed Modem at 2400,8-bit:\
:nx=VH1200:tc=std.2400:
vp|VH9600|Very High Speed Modem at 9600,8-bit:\
:nx=VH2400:tc=std.9600:
vq|VH57600|Very High Speed Modem at 57600,8-bit:\
:nx=VH9600:tc=std.57600:
对于 CPU 速度较慢或负载较重的系统,如果没有基于 16550A 的串口,这种配置可能会在 57.6 Kbps 时产生 uart "silo" 错误。
/etc/ttys 的配置与 配置终端条目 类似,但是传递给 getty 的参数不同,并且使用 dialup 作为终端类型。将 xxx 替换为 init 将在设备上运行的进程。
ttyu0 "/usr/libexec/getty xxx" dialup on
dialup 终端类型可以进行更改。例如,将 vt102 设置为默认终端类型,允许用户在远程系统上使用 VT102 仿真。
对于锁定速度的配置,请使用 /etc/gettytab 中列出的有效类型指定速度。以下示例是针对一个端口速度锁定在 19.2 Kbps 的调制解调器:
ttyu0 "/usr/libexec/getty std.19200" dialup on
在匹配速度配置中,该条目需要引用 /etc/gettytab 中适当的起始 "auto-baud" 条目。继续以一个以 19.2 Kbps 启动的匹配速度调制解调器为例,使用以下条目:
ttyu0 "/usr/libexec/getty V19200" dialup on
在编辑 /etc/ttys 文件后,在向 init 发送信号之前,请等待调制解调器正确配置并连接。
# kill -HUP 1高速调制解调器,如 V.32、V.32bis 和 V.34 调制解调器,使用硬件(RTS/CTS)流控制。使用 stty 命令为调制解调器端口设置硬件流控制标志。以下示例在 COM2 的拨入和拨出初始化设备上设置了 crtscts 标志:
# stty -f /dev/ttyu1.init crtscts
# stty -f /dev/cuau1.init crtscts29.4.2. 故障排除
本节提供了一些解决无法连接到 FreeBSD 系统的拨号调制解调器的技巧。
将调制解调器连接到 FreeBSD 系统并启动系统。如果调制解调器具有状态指示灯,请观察当系统控制台上出现 login: 提示时,调制解调器的 DTR 指示灯是否亮起。如果它亮起,那应该意味着 FreeBSD 已经在适当的通信端口上启动了一个 getty 进程,并且正在等待调制解调器接受呼叫。
如果 DTR 指示灯没有亮起,请通过控制台登录 FreeBSD 系统,并输入 ps ax 命令查看 FreeBSD 是否在正确的端口上运行了 getty 进程:
114 ?? I 0:00.10 /usr/libexec/getty V19200 ttyu0如果第二列包含的是 d0 而不是 ?? ,并且调制解调器尚未接受呼叫,这意味着 getty 已经完成了对通信端口的打开。这可能表明存在电缆问题或调制解调器配置错误,因为在调制解调器断开检测信号被断言之前,getty 不应该能够打开通信端口。
如果没有 getty 进程等待打开端口,请再次检查在 /etc/ttys 中端口的条目是否正确。此外,请检查 /var/log/messages 以查看是否有来自 init 或 getty 的日志消息。
接下来,请尝试拨入系统。确保在远程系统上使用 8 位、无奇偶校验和 1 个停止位。如果没有立即出现提示符,或者提示符显示乱码,请尝试每秒按下 Enter 键一次。如果仍然没有出现 login: 提示符,请尝试发送 BREAK 信号。当使用高速调制解调器时,在锁定拨号调制解调器的接口速度后再次拨号。
如果仍然没有出现 login: 提示符,请再次检查 /etc/gettytab ,并仔细确认以下内容:
-
在 /etc/ttys 文件中指定的初始能力名称与 /etc/gettytab 文件中的能力名称匹配。
-
每个
nx=条目都与 gettytab 的能力名称相匹配。 -
每个
tc=条目都与另一个 gettytab 能力名称匹配。
如果 FreeBSD 系统上的调制解调器不会应答,请确保调制解调器配置为在 DTR 被断开时接听电话。如果调制解调器似乎已正确配置,请通过检查调制解调器的指示灯来验证 DTR 线是否被断开。
如果仍然无法解决问题,请尝试发送电子邮件到 FreeBSD general questions mailing list,描述调制解调器和问题。
29.5. 拨出服务
以下是通过调制解调器将主机连接到另一台计算机的提示。这适用于与远程主机建立终端会话。
如果使用 PPP 存在问题,这种连接方式可以帮助获取互联网上的文件。如果 PPP 无法正常工作,可以使用终端会话来通过 FTP 获取所需文件。然后使用 zmodem 将其传输到计算机上。
29.5.1. 使用一台 Stock Hayes 调制解调器
tip 内置了一个通用的 Hayes 拨号器。在 /etc/remote 文件中使用 at=hayes 。
Hayes 驱动程序不够智能,无法识别一些较新调制解调器消息的高级功能,例如 BUSY、NO DIALTONE 或 CONNECT 115200。在使用 tip 和 ATX0&W 时,请关闭这些消息。
tip 的拨号超时时间为 60 秒。调制解调器应该使用更短的时间,否则 tip 会认为存在通信问题。尝试使用 ATS7=45&W。
29.5.2. 使用 AT 命令
在 /etc/remote 中创建一个"direct"条目。例如,如果调制解调器连接到第一个串口, /dev/cuau0 ,请使用以下行:
cuau0:dv=/dev/cuau0:br#19200:pa=none
在 br 功能中使用调制解调器支持的最高 bps 速率。然后,键入 tip cuau0 以连接到调制解调器。
或者,使用以下命令将 cu 作为 root 使用:
# cu -lline -sspeedline 是串口,例如 /dev/cuau0 ,而 speed 是速度,例如 57600 。输入完 AT 命令后,输入 ~. 退出。
29.5.3. @ 符号不起作用
电话号码功能中的 @ 符号告诉 tip 在 /etc/phones 文件中查找电话号码。但是,在像 /etc/remote 这样的功能文件中, @ 符号也是一个特殊字符,因此需要用反斜杠进行转义:
pn=\@
29.5.4. 从命令行拨号
在 /etc/remote 中添加一个 "generic" 条目。例如:
tip115200|Dial any phone number at 115200 bps:\
:dv=/dev/cuau0:br#115200:at=hayes:pa=none:du:
tip57600|Dial any phone number at 57600 bps:\
:dv=/dev/cuau0:br#57600:at=hayes:pa=none:du:
现在应该可以工作了。
# tip -115200 5551234喜欢使用 cu 而不是 tip 的用户可以使用通用的 cu 条目:
cu115200|Use cu to dial any number at 115200bps:\
:dv=/dev/cuau1:br#57600:at=hayes:pa=none:du:
并且类型:
# cu 5551234 -s 11520029.5.5. 设置波特率
为 tip1200 或 cu1200 添加一个条目,但请根据 br 功能使用适当的 bps 速率。 tip 认为默认的速率是 1200 bps ,这就是为什么它会寻找 tip1200 条目的原因。然而,并不一定非要使用 1200 bps 。
29.5.6. 通过终端服务器访问多台主机
不必每次等待连接并输入 CONNECT host ,可以使用 tip 的 cm 功能。例如,在 /etc/remote 中添加以下条目,可以通过输入 tip pain 或 tip muffin 连接到主机 pain 或 muffin ,以及通过输入 tip deep13 连接到终端服务器。
pain|pain.deep13.com|Forrester's machine:\
:cm=CONNECT pain\n:tc=deep13:
muffin|muffin.deep13.com|Frank's machine:\
:cm=CONNECT muffin\n:tc=deep13:
deep13:Gizmonics Institute terminal server:\
:dv=/dev/cuau2:br#38400:at=hayes:du:pa=none:pn=5551234:
29.5.7. 使用多行显示 tip 提示信息
这通常是一个问题,当一所大学拥有多条调制解调器线路,并有几千名学生试图使用它们时。
在 /etc/remote 中添加一条条目,并使用 ` @ ` 作为 pn 功能的标识符:
big-university:\
:pn=\@:tc=dialout
dialout:\
:dv=/dev/cuau3:br#9600:at=courier:du:pa=none:
然后,在 /etc/phones 中列出电话号码:
big-university 5551111 big-university 5551112 big-university 5551113 big-university 5551114
tip 会按照列表中的顺序尝试每个数字,然后放弃。要保持重试,可以在一个 while 循环中运行 tip 。
29.5.8. 使用 Force 字符
Ctrl+P 是默认的 "force" 字符,用于告诉 tip 下一个字符是字面数据。可以使用 ~s 转义将强制字符设置为任何其他字符,该转义意味着 "set a variable."。
在新行后面输入 ~sforce=single-char。single-char 是任意一个字符。如果省略 single-char,则强制字符为空字符,可以通过键入 Ctrl+2 或 Ctrl+Space 来访问。一个很好的 single-char 值是 Shift+Ctrl+6,这只在某些终端服务器上使用。
要更改 force 字符,请在 ~/.tiprc 中指定以下内容:
force=single-char
29.5.9. 大写字母
当按下 Ctrl+A 时,会发生这种情况,这是 tip 的 "raise character",专为那些键盘上的大写锁定键损坏的人设计的。使用 ~s 来设置 raisechar 为合理的值。如果两个特性都没有使用,它可以被设置为与强制字符相同。
这是一个给需要在 Emacs 中输入 Ctrl+2 和 Ctrl+A 的用户的示例 ~/.tiprc 文件:
force=^^ raisechar=^^
^^ 是 Shift+Ctrl+6。
29.6. 设置串行控制台
FreeBSD 具有通过串口作为控制台来启动系统的能力。这种配置对于希望在没有键盘或显示器连接的机器上安装 FreeBSD 的系统管理员以及希望调试内核或设备驱动程序的开发人员非常有用。
如 FreeBSD 引导过程 中所描述的,FreeBSD 采用了三阶段的引导过程。前两个阶段是存储在引导磁盘上 FreeBSD 分区的开头的引导块代码。然后,引导块加载并运行引导加载程序作为第三阶段的代码。
为了设置从串行控制台启动,需要配置引导块代码、引导加载程序代码和内核。
29.6.1. 快速串行控制台配置
本节提供了设置串行控制台的快速概述。当哑终端连接到 COM1 时,可以使用此过程。
过程:在 COM1 上配置串行控制台
-
将串行电缆连接到 COM1 和控制终端。
-
要配置启动消息在串行控制台上显示,以超级用户身份执行以下命令:
# echo 'console="comconsole"' >> /boot/loader.conf -
编辑 /etc/ttys 文件,将
off改为on,将dialup改为vt100,针对 ttyu0 条目。否则,通过串行控制台连接时将不需要密码,可能导致安全漏洞。 -
重新启动系统以查看更改是否生效。
如果需要不同的配置,请参阅下一节以获取更详细的配置说明。
29.6.2. 深入的串行控制台配置
本节提供了在 FreeBSD 中设置串行控制台所需步骤的更详细解释。
过程:配置串行控制台
-
准备一根串行电缆。
使用空模拟电缆或标准串行电缆和空模拟适配器。有关串行电缆的讨论,请参见 串行电缆和端口 。
-
拔下键盘。
许多系统在开机自检(POST)期间会检测键盘,并且如果未检测到键盘,将生成错误。一些机器在键盘未连接时将拒绝启动。
如果计算机在出现错误时抱怨,但仍能正常启动,那么无需进行进一步配置。
如果计算机在没有连接键盘的情况下拒绝启动,请配置 BIOS 以忽略此错误。请参考主板的手册以获取详细信息。
尝试在 BIOS 中将键盘设置为 "Not installed"。该设置告诉 BIOS 在开机时不要探测键盘,因此如果键盘不存在,它就不会发出警告。如果 BIOS 中没有这个选项,请寻找一个名为 "Halt on Error" 的选项。将其设置为 "All but Keyboard" 或 "No Errors" 将产生相同的效果。
如果系统上有 PS/2® 鼠标,请将其拔出。PS/2® 鼠标与键盘共享一些硬件,如果鼠标仍然插着,可能会让键盘探测程序误以为键盘仍然存在。
虽然大多数系统可以在没有键盘的情况下启动,但有些系统在没有图形适配器的情况下无法启动。一些系统可以通过在 BIOS 配置中将 "graphics adapter" 设置为 "Not installed" 来配置为无图形适配器启动。其他系统不支持此选项,如果系统中没有显示硬件,将拒绝启动。对于这些机器,即使只是一个糟糕的单色板,也要插入某种图形卡。不需要连接显示器。
-
将一个哑终端、一个带有调制解调器程序的旧计算机,或者另一台 UNIX® 系统的串行端口插入串行端口。
-
在串口上,向 /boot/device.hints 添加适当的
hint.uart.*条目。一些多串口卡还需要内核配置选项。请参考 uart(4) 获取所需的选项和每个支持的串口的设备提示。 -
在引导驱动器的
a分区的根目录中创建名为boot.config的文件。这个文件指示引导块代码如何引导系统。为了激活串行控制台,需要一个或多个以下选项。当使用多个选项时,请将它们都包含在同一行中:
-h-
在内部和串行控制台之间切换。使用此选项来切换控制台设备。例如,要从内部(视频)控制台启动,请使用
-h将引导加载程序和内核指定使用串行端口作为控制台设备。或者,要从串行端口启动,请使用-h告诉引导加载程序和内核使用视频显示作为控制台。 -D-
在单一和双重控制台配置之间切换。在单一配置中,控制台将根据
-h的状态,选择内部控制台(视频显示)或串口。在双重控制台配置中,无论-h的状态如何,视频显示和串口将同时成为控制台。然而,双重控制台配置仅在引导块运行时生效。一旦引导加载程序获得控制权,由-h指定的控制台将成为唯一的控制台。 -P-
使引导块探测键盘。如果未找到键盘,则自动设置
-D和-h选项。由于当前版本的引导块空间限制,
-P只能检测到扩展键盘。少于 101 个键且没有 F11 和 F12 键的键盘可能无法被检测到。由于这个限制,某些笔记本电脑上的键盘可能无法正确识别。如果是这种情况,请不要使用-P。使用
-P来自动选择控制台,或者使用-h来激活串行控制台。更多详细信息请参考 boot(8) 和 boot.config(5) 。除了
-P之外的选项都会传递给引导加载程序。引导加载程序将通过检查-h的状态来确定内部视频还是串口应该成为控制台。这意味着如果在 /boot.config 中指定了-D但未指定-h,则串口只能在引导块期间用作控制台,因为引导加载程序将使用内部视频显示作为控制台。
-
启动机器。
当 FreeBSD 启动时,引导块会将 /boot.config 的内容回显到控制台。例如:
/boot.config: -P Keyboard: no如果在 /boot.config 中存在
-P,则第二行才会出现,并指示键盘的存在或不存在。这些消息会发送到串行或内部控制台,或者两者都会发送,具体取决于 /boot.config 中的选项。选项 消息发送至 无
内部控制台
-h串行控制台
-D串行和内部控制台
-Dh串行和内部控制台
-P,键盘存在内部控制台
-P,键盘缺失串行控制台
在消息之后,启动块将会有一个小的暂停,然后继续加载引导加载程序,并在打印任何进一步的消息到控制台之前。在正常情况下,没有必要中断启动块,但可以这样做以确保设置正确。
在控制台上按下除 Enter 键以外的任意键,以中断引导过程。然后引导块将提示进一步的操作:
>> FreeBSD/i386 BOOT Default: 0:ad(0,a)/boot/loader boot:根据 /boot.config 中的选项,验证上述消息是否出现在串行或内部控制台上,或者两者都有。如果消息出现在正确的控制台上,请按下 Enter 键继续引导过程。
如果串行终端上没有提示符,说明设置有问题。输入
-h然后按下键盘上的 Enter 或 Return 键,告诉引导块(然后是引导加载程序和内核)选择串行端口作为控制台。系统启动后,返回并检查出了什么问题。
在引导过程的第三阶段,可以通过在引导加载程序中设置适当的环境变量来在内部控制台和串行控制台之间切换。有关更多信息,请参阅 loader(8) 。
|
无论 /boot.config 中的选项如何,此行在 /boot/loader.conf 或 /boot/loader.conf.local 中配置引导加载程序和内核将其引导消息发送到串行控制台。 console="comconsole" 这行应该是 /boot/loader.conf 的第一行,以便尽早在串行控制台上显示引导消息。 如果该行不存在,或者设置为 目前,引导加载程序没有与引导块中的 |
|
虽然不是必需的,但可以通过串行线提供“登录”提示。要配置此功能,请按照 终端配置 中的说明编辑 /etc/ttys 中串行端口的条目。如果串行端口的速度已更改,请将 |
29.6.3. 设置更快的串口速度
默认情况下,串口设置为 9600 波特率, 8 位数据位,无奇偶校验, 1 个停止位。要更改默认控制台速度,请使用以下选项之一:
-
编辑 /etc/make.conf 文件,并将
BOOT_COMCONSOLE_SPEED设置为新的控制台速度。然后,重新编译并安装引导块和引导加载程序:# cd /sys/boot # make clean # make # make install如果串行控制台的配置方式与使用
-h引导不同,或者内核使用的串行控制台与引导块使用的不同,可以将以下选项添加到自定义内核配置文件中,并编译一个新的内核,以设置所需的速度:options CONSPEED=19200
-
将
-S19200引导选项添加到 /boot.config 文件中,将19200替换为要使用的速度。 -
将以下选项添加到 /boot/loader.conf 文件中。将
115200替换为要使用的速度。boot_multicons="YES" boot_serial="YES" comconsole_speed="115200" console="comconsole,vidconsole"
29.6.4. 通过串行线进入 DDB 调试器
要配置从串行控制台进入内核调试器的能力,请将以下选项添加到自定义内核配置文件中,并按照 Configuring the FreeBSD Kernel 中的说明编译内核。请注意,虽然这对于远程诊断很有用,但如果串口上生成了一个虚假的 BREAK 信号,也是很危险的。有关内核调试器的更多信息,请参阅 ddb(4) 和 ddb(8)。
options BREAK_TO_DEBUGGER options DDB
Chapter 30. PPP
30.1. 简介
FreeBSD 支持点对点( PPP )协议,可以使用拨号调制解调器建立网络或互联网连接。本章介绍了如何在 FreeBSD 中配置基于调制解调器的通信服务。
阅读完本章后,您将了解:
-
如何配置、使用和排除故障 PPP 连接。
-
如何设置以太网上的 PPP ( PPPoE )。
-
如何设置 PPP over ATM ( PPPoA )。
在阅读本章之前,您应该:
-
熟悉基本的网络术语。
-
了解拨号连接和 PPP 的基本原理和目的。
30.2. 配置 PPP
FreeBSD 提供了内置的支持,用于使用 ppp(8) 管理拨号 PPP 连接。默认的 FreeBSD 内核提供了对 .tun 文件的支持,该文件用于与调制解调器硬件进行交互。配置是通过编辑至少一个配置文件来完成的,并且提供了包含示例的配置文件。最后,使用 ppp 来启动和管理连接。
为了使用 PPP 连接,需要以下物品:
-
一个拨号上网账户,由互联网服务提供商( ISP )提供。
-
一个拨号调制解调器。
-
ISP 的拨号号码。
-
由 ISP 分配的登录名和密码。
-
一个或多个 DNS 服务器的 IP 地址。通常,这些地址由 ISP 提供。如果没有提供, FreeBSD 可以配置为使用 DNS 协商。
如果缺少任何必要的信息,请联系互联网服务提供商。
以下信息可能由 ISP 提供,但并非必需:
-
默认网关的 IP 地址。如果这个信息未知, ISP 将在连接设置过程中自动提供正确的值。在 FreeBSD 上配置 PPP 时,这个地址被称为
HISADDR。 -
子网掩码。如果 ISP 没有提供子网掩码,则在 ppp(8) 配置文件中将使用
255.255.255.255。如果 ISP 分配了静态 IP 地址和主机名,则应将其输入到配置文件中。否则,在连接设置期间,此信息将自动提供。
本节的其余部分演示了如何配置 FreeBSD 以适应常见的 PPP 连接场景。所需的配置文件是 [/etc/ppp/ppp.conf] ,其他文件和示例可在 [/usr/share/examples/ppp/] 中找到。
|
在本节中,许多文件示例都显示了行号。这些行号是为了更容易跟踪讨论而添加的,并不是要放在实际文件中。 在编辑配置文件时,正确的缩进非常重要。以 |
30.2.1. 基本配置
为了配置 PPP 连接,首先使用 ISP 的拨入信息编辑 [/etc/ppp/ppp.conf] 文件。该文件的描述如下:
1 default: 2 set log Phase Chat LCP IPCP CCP tun command 3 ident user-ppp VERSION 4 set device /dev/cuau0 5 set speed 115200 6 set dial "ABORT BUSY ABORT NO\\sCARRIER TIMEOUT 5 \ 7 \"\" AT OK-AT-OK ATE1Q0 OK \\dATDT\\T TIMEOUT 40 CONNECT" 8 set timeout 180 9 enable dns 10 11 provider: 12 set phone "(123) 456 7890" 13 set authname foo 14 set authkey bar 15 set timeout 300 16 set ifaddr x.x.x.x/0 y.y.y.y/0 255.255.255.255 0.0.0.0 17 add default HISADDR
- 第一行
-
识别
default条目。当运行ppp时,该条目中的命令(第 2 到 9 行)会自动执行。 - 第 2 行
-
启用详细日志记录参数以测试连接。一旦配置正常工作,此行应缩减为:
set log phase tun
- 第三行
-
显示与连接另一端运行的 PPP 软件的 ppp(8) 版本。
- 第 4 行
-
标识了调制解调器连接的设备,其中 COM1 是 /dev/cuau0 ,而 COM2 是 /dev/cuau1 。
- 第 5 行
-
设置连接速度。如果在旧调制解调器上
115200不起作用,请尝试使用38400。 - 第 6 行和第 7 行
-
将拨号字符串写成期望 - 发送语法。有关更多信息,请参阅 chat(8) 。
请注意,为了提高可读性,该命令会继续到下一行。如果行的最后一个字符是 ` \ ` ,则 ppp.conf 中的任何命令都可以这样做。
- 第 8 行
-
设置链接的空闲超时时间,单位为秒。
- 第 9 行
-
指示对等方确认 DNS 设置。如果本地网络正在运行自己的 DNS 服务器,则应该将此行注释掉,方法是在行首添加“ # +”,或者将其删除。
- 第 10 行
-
为了提高可读性而留下的空行。空行在 ppp(8) 中会被忽略。
- 第 11 行
-
标识一个名为
provider的条目。可以将其更改为 ISP 的名称,以便可以使用load ISP来启动连接。 - 第 12 行
-
使用 ISP 的电话号码。可以使用冒号(
:)或竖线字符( ` | ` )作为分隔符来指定多个电话号码。要循环使用这些号码,请使用冒号。要始终首先尝试拨打第一个号码,并且只有在第一个号码失败时才使用其他号码,请使用竖线字符。始终使用引号(")将整组电话号码括起来,以防止拨号失败。 - 第 13 行和第 14 行
-
使用 ISP 的用户名和密码。
- 第 15 行
-
设置连接的默认空闲超时时间(以秒为单位)。在此示例中,连接在 300 秒的不活动后将自动关闭。要防止超时,将此值设置为零。
- 第 16 行
-
设置接口地址。使用的值取决于是否从 ISP 获取了静态 IP 地址,还是在连接过程中协商动态 IP 地址。
如果 ISP 分配了静态 IP 地址和默认网关,请将_x.x.x.x_替换为静态 IP 地址,并将_y.y.y.y_替换为默认网关的 IP 地址。如果 ISP 只提供了静态 IP 地址而没有网关地址,请将_y.y.y.y_替换为
10.0.0.2/0。如果每次建立连接时 IP 地址都会更改,请将此行更改为以下值。这告诉 ppp(8) 使用 IP 配置协议( IPCP )来协商动态 IP 地址:
set ifaddr 10.0.0.1/0 10.0.0.2/0 255.255.255.255 0.0.0.0
- 第 17 行
-
保持这行不变,因为它会向网关添加一个默认路由。
HISADDR将自动替换为第 16 行指定的网关地址。重要的是,这行出现在第 16 行之后。
根据 ppp(8) 是手动启动还是自动启动,可能还需要创建一个 .filename#/etc/ppp/ppp.linkup# 文件,其中包含以下内容。在以 -auto 模式运行 ppp 时,需要此文件。此文件在连接建立后使用。此时, IP 地址已被分配,现在可以添加路由表条目。创建此文件时,请确保_provider_与 .filename#ppp.conf# 的第 11 行中演示的值匹配。
provider:
add default HISADDR
当在静态 IP 地址配置中“猜测”默认网关地址时,也需要此文件。在这种情况下,从 ppp.conf 中删除第 17 行,并创建包含上述两行的 /etc/ppp/ppp.linkup 文件。有关此文件的更多示例可以在 /usr/share/examples/ppp/ 中找到。
默认情况下, ppp 必须以 root 用户身份运行。要更改此默认设置,请将应该运行 ppp 的用户的帐户添加到 /etc/group 文件中的 network 组中。
然后,使用 allow 命令给用户访问 /etc/ppp/ppp.conf 中的一个或多个条目的权限。例如,要给 fred 和 mary 只能访问 provider: 条目的权限,在 provider: 部分添加以下行:
allow users fred mary
将指定用户授予对所有条目的访问权限,请将该行放在 default 部分中。
30.2.2. 高级配置
可以配置 PPP 在需要时提供 DNS 和 NetBIOS 名称服务器地址。
要在 PPP 版本 1.x 中启用这些扩展功能,可以将以下行添加到 /etc/ppp/ppp.conf 的相关部分。
enable msext set ns 203.14.100.1 203.14.100.2 set nbns 203.14.100.5
对于 PPP 版本 2 及以上:
accept dns set dns 203.14.100.1 203.14.100.2 set nbns 203.14.100.5
这将向客户端提供主要和次要的名称服务器地址,以及一个 NetBIOS 名称服务器主机。
在 2 版本及以上,如果省略了 set dns 行, PPP 将使用在 /etc/resolv.conf 中找到的值。
30.2.2.1. PAP 和 CHAP 身份验证
一些互联网服务提供商( ISP )设置他们的系统,使连接的身份验证部分使用 PAP 或 CHAP 身份验证机制之一完成。如果是这种情况, ISP 在连接时不会提供“ login: ”提示,而是立即开始使用 PPP 进行通信。
PAP 比 CHAP 安全性较低,但通常情况下安全性并不是一个问题,因为密码虽然以明文形式通过 PAP 发送,但只是通过串行线传输。破解者很难进行“窃听”。
必须进行以下修改:
13 set authname MyUserName 14 set authkey MyPassword 15 set login
- 第 13 行
-
这行指定了 PAP/CHAP 用户名。请插入正确的值作为_MyUserName_。
- 第 14 行
-
这行指定了 PAP/CHAP 密码。请插入正确的值作为_MyPassword_。您可能还想添加一行额外的内容,例如:
16 accept PAP
或者
16 accept CHAP
为了明确这是意图,但是默认情况下, PAP 和 CHAP 都被接受。
- 第 15 行
-
当使用 PAP 或 CHAP 时, ISP 通常不需要登录到服务器。因此,请禁用“ set login ”字符串。
30.2.2.2. 使用 PPP 网络地址转换功能
PPP 具有使用内部 NAT 而无需内核转发功能的能力。可以通过在 /etc/ppp/ppp.conf 文件中添加以下行来启用此功能:
nat enable yes
另外,也可以通过命令行选项 -nat 来启用 NAT 。此外,还有一个名为 ppp_nat 的 /etc/rc.conf 开关,默认情况下是启用的。
在使用此功能时,可以考虑包含以下选项 /etc/ppp/ppp.conf ,以启用传入连接转发:
nat port tcp 10.0.0.2:ftp ftp nat port tcp 10.0.0.2:http http
或者完全不信任外界
nat deny_incoming yes
30.2.3. 最终系统配置
虽然 ppp 已经配置好了,但是还需要对 /etc/rc.conf 进行一些编辑。
从上到下逐步操作这个文件,在 `hostname = ` 行上确保已设置:
hostname="foo.example.com"
如果 ISP 提供了静态 IP 地址和名称,请将此名称用作主机名。
查找 network_interfaces 变量。要配置系统按需拨号 ISP ,请确保将 tun0 设备添加到列表中,否则将其删除。
network_interfaces="lo0 tun0" ifconfig_tun0=
|
ppp -auto mysystem 此脚本在网络配置时执行,以自动模式启动 ppp 守护进程。如果此机器充当网关,请考虑包含 |
确保在 /etc/rc.conf 文件中,将路由器程序设置为 NO ,使用以下行:
router_enable="NO"
重要的是不要启动 routed 守护进程,因为 routed 倾向于删除 ppp 创建的默认路由表条目。
确保 sendmail_flags 行不包含 -q 选项可能是一个好主意,否则 sendmail 会不时尝试进行网络查找,可能导致您的机器拨号。您可以尝试:
sendmail_flags="-bd"
缺点是每当 ppp 链接时, sendmail 被迫重新检查邮件队列。为了自动化这个过程,在 ppp.linkup 中包含 ` ! bg` 。
1 provider: 2 delete ALL 3 add 0 0 HISADDR 4 !bg sendmail -bd -q30m
另一种方法是设置一个“ dfilter ”来阻止 SMTP 流量。有关详细信息,请参考示例文件。
30.2.4. 使用 ppp
只剩下重新启动机器了。重新启动后,要么输入:
# ppp然后执行 dial provider 命令来启动 PPP 会话,或者,要配置 ppp 在有出站流量且 start_if.tun0 不存在时自动建立会话,请输入:
# ppp -auto provider在 ppp 程序在后台运行时,可以通过适当设置诊断端口来进行通信。要实现这一点,请将以下行添加到配置中:
set server /var/run/ppp-tun%d DiagnosticPassword 0177
这将告诉 PPP 监听指定的 UNIX® 域套接字,在允许访问之前要求客户端提供指定的密码。名称中的 %d 将被替换为正在使用的 tun 设备号。
一旦建立了一个套接字,可以在希望操作正在运行的程序的脚本中使用 pppctl(8) 程序。
30.2.5. 配置拨入服务
getty 的替代方案是 comms/mgetty + sendfax (端口),这是 getty 的智能版本,专为拨号线路而设计。
使用 mgetty 的优点是它能够主动与调制解调器进行通信,这意味着如果在 /etc/ttys 中关闭了端口,调制解调器将不会接听电话。
mgetty 的后续版本(从 0.99beta 开始)还支持自动检测 PPP 流,允许客户端无需脚本即可访问服务器。
请参考 http://mgetty.greenie.net/doc/mgetty_toc.html 获取有关 mgetty 的更多信息。
默认情况下, comms/mgetty + sendfax 包的端口带有启用的 AUTO_PPP 选项,允许 mgetty 检测 PPP 连接的 LCP 阶段并自动生成 ppp shell 。然而,由于默认的登录 / 密码序列不会发生,因此需要使用 PAP 或 CHAP 对用户进行身份验证。
本节假设用户已经成功编译并安装了 comms/mgetty + sendfax[] 软件包。
确保 /usr/local/etc/mgetty + sendfax/login.config 包含以下内容:
/AutoPPP/ - - /etc/ppp/ppp-pap-dialup
这将告诉 mgetty 在检测到 PPP 连接时运行 ppp-pap-dialup 。
创建一个名为 [/etc/ppp/ppp-pap-dialup] 的可执行文件,其中包含以下内容:
#!/bin/sh exec /usr/sbin/ppp -direct pap$IDENT
对于在 [/etc/ttys] 中启用的每个拨号线路,创建一个相应的条目在 [/etc/ppp/ppp.conf] 中。这将与我们上面创建的定义和谐共存。
pap: enable pap set ifaddr 203.14.100.1 203.14.100.20-203.14.100.40 enable proxy
使用这种方法登录的每个用户都需要在 /etc/ppp/ppp.secret 中拥有用户名 / 密码,或者可以选择在 /etc/passwd 中添加以下选项以通过 PAP 验证用户。
enable passwdauth
要为一些用户分配静态 IP 地址,请将该数字作为第三个参数指定在 [/etc/ppp/ppp.secret] 中。有关示例,请参见 [/usr/share/examples/ppp/ppp.secret.sample] 。
30.3. PPP 连接故障排除
本节涵盖了在使用调制解调器连接时可能出现的一些问题。一些 ISP 会显示 ssword 提示,而其他人则显示 password 。如果 ppp 脚本没有相应地编写,登录尝试将失败。调试 ppp 连接的最常见方法是按照本节所述手动连接。
30.3.1. 检查设备节点
在使用自定义内核时,请确保在内核配置文件中包含以下行:
device uart
uart 设备已经包含在 GENERIC 内核中,因此在这种情况下不需要额外的步骤。只需使用以下命令检查 dmesg 输出中的调制解调器设备:
# dmesg | grep uart这应该显示有关 uart 设备的一些相关输出。这些是我们需要的 COM 端口。如果调制解调器表现得像一个标准串口,它应该会列在 uart1 或者 COM2 上。如果是这样的话,不需要重新编译内核。当进行匹配时,如果调制解调器在 uart1 上,调制解调器设备将会是 /dev/cuau1 。
30.3.2. 手动连接
通过手动控制 ppp 连接到互联网是快速、简单且调试连接或获取有关 ISP 处理 ppp 客户端连接的信息的好方法。让我们从命令行开始 PPP 。请注意,在我们的所有示例中,我们将使用_example_作为运行 PPP 的机器的主机名。要启动 ppp :
# pppppp ON example> set device /dev/cuau1这个第二个命令将调制解调器设备设置为 cuau1 。
ppp ON example> set speed 115200这将连接速度设置为 115 , 200 kbps 。
ppp ON example> enable dns这将告诉 ppp 配置解析器并将 nameserver 行添加到 /etc/resolv.conf 中。如果 ppp 无法确定主机名,可以稍后手动设置。
ppp ON example> term这将切换到“终端”模式,以手动控制调制解调器。
deflink: Entering terminal mode on /dev/cuau1 type '~h' for help
at
OK
atdt123456789使用 at 命令初始化调制解调器,然后使用 atdt 命令和 ISP 的号码开始拨号过程。
CONNECT如果我们遇到与硬件无关的连接问题,这里是我们尝试解决问题的地方。确认连接。
ISP Login:myusername在这个提示符下,返回由 ISP 提供的用户名的提示符。
ISP Pass:mypassword在提示符下,请回复由 ISP 提供的密码。就像登录 FreeBSD 一样,密码不会显示出来。
Shell or PPP:ppp根据互联网服务提供商的不同,可能不会出现此提示。如果出现了,它会询问是否使用提供商的 shell 或启动 ppp 。在这个例子中,选择了 ppp 以建立互联网连接。
Ppp ON example>请注意,在这个例子中,第一个 p 已经被大写了。这表明我们已经成功连接到了互联网服务提供商。
Ppp ON example>我们已经成功通过我们的 ISP 进行了身份验证,并正在等待分配的 IP 地址。
PPP ON example>我们已经就一个 IP 地址达成协议,并成功完成了连接。
PPP ON example>add default HISADDR在这里,我们添加了默认路由,我们需要在与外部世界通信之前这样做,因为目前唯一建立的连接是与对等方的连接。如果由于现有路由而失败,请在 add 前面加上感叹号 ` ! ` 。或者,在进行实际连接之前设置这个选项,它将相应地协商一个新的路由。
如果一切顺利,我们现在应该已经建立了与互联网的活动连接,可以使用 CTRL+z 将其置于后台。如果 PPP 返回到 ppp ,则表示连接已丢失。这是很重要的信息,因为它显示了连接状态。大写的 P 表示与互联网服务提供商的连接,小写的 p 表示连接已丢失。
30.3.3. 调试
如果无法建立连接,请使用 set ctsrts off 关闭硬件流控制 CTS/RTS 。这主要发生在连接到一些支持 PPP 的终端服务器时,当 PPP 尝试向通信链路写入数据时, PPP 会挂起并等待一个可能永远不会到来的 CTS 信号。使用此选项时,请包括 set accmap ,因为可能需要打败依赖于从端到端传递某些字符的硬件,大部分时间是 XON/XOFF 。有关此选项及其使用方法的更多信息,请参阅 ppp(8) 。
一个较旧的调制解调器可能需要设置奇偶校验为“偶校验”。默认情况下,奇偶校验被设置为无校验,但在较旧的调制解调器上,当流量大增时,会用于错误检查。
PPP 可能无法返回到命令模式,这通常是一种协商错误,即 ISP 正在等待协商开始。此时,使用 ` ~ p` 将强制 PPP 开始发送配置信息。
如果登录提示从未出现,则很可能需要进行 PAP 或 CHAP 身份验证。要使用 PAP 或 CHAP ,在进入终端模式之前,请将以下选项添加到 PPP 中:
ppp ON example> set authname myusername将 myusername 替换为由 ISP 分配的用户名。
ppp ON example> set authkey mypassword将 mypassword 替换为由 ISP 分配的密码。
如果建立了连接,但似乎找不到任何域名,请尝试使用 ping(8) 命令 ping 一个 IP 地址。如果出现 100% 的数据包丢失,很可能是没有设置默认路由。请再次检查在连接期间是否设置了 add default HISADDR 。如果可以连接到远程 IP 地址,可能是因为没有将解析器地址添加到 [/etc/resolv.conf] 文件中。该文件应该如下所示:
domain example.com nameserver x.x.x.x nameserver y.y.y.y
_x.x.x.x_和_y.y.y.y_应该替换为 ISP 的 DNS 服务器的 IP 地址。
要配置 syslog(3) 以提供 PPP 连接的日志记录,请确保以下行存在于 /etc/syslog.conf 文件中:
!ppp *.* /var/log/ppp.log
30.4. 使用以太网上的点对点协议( PPP over Ethernet , PPPoE )
本节介绍了如何设置以太网上的 PPP ( PPPoE )。
这是一个工作的 ppp.conf 的示例:
default: set log Phase tun command # you can add more detailed logging if you wish set ifaddr 10.0.0.1/0 10.0.0.2/0 name_of_service_provider: set device PPPoE:xl1 # replace xl1 with your Ethernet device set authname YOURLOGINNAME set authkey YOURPASSWORD set dial set login add default HISADDR
以 root 身份运行:
# ppp -ddial name_of_service_provider将以下内容添加到 [/etc/rc.conf] 文件中:
ppp_enable="YES" ppp_mode="ddial" ppp_nat="YES" # if you want to enable nat for your local network, otherwise NO ppp_profile="name_of_service_provider"
30.4.1. 使用 PPPoE 服务标签
有时候需要使用服务标签来建立连接。服务标签用于区分连接到给定网络的不同 PPPoE 服务器。
任何必需的服务标签信息应该在 ISP 提供的文档中。
作为最后的办法,可以尝试安装 net/rr-pppoe 包或端口。但请记住,这可能会取消您的调制解调器的编程并使其变得无用,所以在执行之前请三思。只需安装随调制解调器一起提供的程序。然后,从程序中访问 System 菜单。配置文件的名称应该在那里列出。通常是_ISP_。
配置文件中的配置项 set device 中,配置文件名(服务标签)将作为 PPPoE 配置项的提供者部分。详细信息请参考 ppp(8) 。配置项应该如下所示:
set device PPPoE:xl1:ISP
不要忘记将_xl1_更改为适合以太网卡的正确设备。
不要忘记将_ISP_更改为配置文件。
有关更多信息,请参阅 Renaud Waldura 的 [使用 FreeBSD 在 DSL 上获得更便宜的宽带] ( http://renaud.waldura.com/doc/freebsd/pppoe/ )。
30.4.2. 使用 3Com® HomeConnect™ ADSL Modem Dual Link 的 PPPoE
该调制解调器不遵循在 RFC 2516 中定义的 PPPoE 规范。
为了使 FreeBSD 能够与该设备通信,必须设置一个 sysctl 。可以通过更新 /etc/sysctl.conf 文件,在启动时自动完成此操作。
net.graph.nonstandard_pppoe=1
或者可以立即使用命令完成:
# sysctl net.graph.nonstandard_pppoe=1很遗憾,由于这是一个系统级的设置,无法同时与普通的 PPPoE 客户端或服务器以及 3Com® HomeConnect™ ADSL 调制解调器进行通信。
30.5. 使用 ATM 上的 PPP ( PPPoA )
以下是如何设置 PPP over ATM ( PPPoA )的说明。 PPPoA 是欧洲 DSL 提供商中的一种流行选择。
30.5.1. 使用 mpd
mpd 应用程序可以用于连接各种服务,特别是 PPTP 服务。可以使用 net/mpd5 包或端口进行安装。许多 ADSL 调制解调器要求在调制解调器和计算机之间创建一个 PPTP 隧道。
安装完成后,配置 mpd 以适应提供商的设置。端口会提供一组示例配置文件,这些文件在 [/usr/local/etc/mpd/] 目录下有详细的文档。有一份完整的 mpd 配置指南以 HTML 格式提供,位于 [/usr/ports/shared/doc/mpd/] 目录下。以下是连接到 ADSL 服务的 mpd 示例配置。配置分为两个文件,首先是 mpd.conf 文件:
|
这个例子 mpd.conf 只适用于 mpd 4.x 版本。 |
default:
load adsl
adsl:
new -i ng0 adsl adsl
set bundle authname username (1)
set bundle password password (2)
set bundle disable multilink
set link no pap acfcomp protocomp
set link disable chap
set link accept chap
set link keep-alive 30 10
set ipcp no vjcomp
set ipcp ranges 0.0.0.0/0 0.0.0.0/0
set iface route default
set iface disable on-demand
set iface enable proxy-arp
set iface idle 0
open
| 1 | 用于与您的 ISP 进行身份验证的用户名。 <.> 用于与您的 ISP 进行身份验证的密码。 |
关于要建立的链接或链接的信息可以在 mpd.links 中找到。下面是一个与上面示例相配套的 mpd.links 示例:
adsl:
set link type pptp
set pptp mode active
set pptp enable originate outcall
set pptp self 10.0.0.1 (1)
set pptp peer 10.0.0.138 (2)
| 1 | 运行 mpd 的 FreeBSD 计算机的 IP 地址。 <.> ADSL 调制解调器的 IP 地址。 Alcatel SpeedTouch™ Home 的默认 IP 地址是 10.0.0.138 。 |
可以通过以下命令作为“ root ”用户轻松初始化连接。
# mpd -b adsl查看连接的状态:
% ifconfig ng0
ng0: flags=88d1<UP,POINTOPOINT,RUNNING,NOARP,SIMPLEX,MULTICAST> mtu 1500
inet 216.136.204.117 --> 204.152.186.171 netmask 0xffffffff使用 mpd 是在 FreeBSD 上连接 ADSL 服务的推荐方法。
30.5.2. 使用 pptpclient
还可以使用 FreeBSD 来连接其他 PPPoA 服务,使用的软件包是: net/pptpclient[] 。
要使用 net/pptpclient 连接到 DSL 服务,请安装端口或包,然后编辑 /etc/ppp/ppp.conf 。下面是一个示例的 ppp.conf 部分。有关 ppp.conf 选项的更多信息,请参阅 ppp(8) 。
adsl: set log phase chat lcp ipcp ccp tun command set timeout 0 enable dns set authname username (1) set authkey password (2) set ifaddr 0 0 add default HISADDR
| 1 | DSL 供应商的用户名。 <.> 您账户的密码。 |
|
由于账户密码以明文形式添加到 ppp.conf 文件中,请确保没有人可以读取此文件的内容: |
这将打开一个用于 DSL 路由器的 PPP 会话的隧道。以太网 DSL 调制解调器有一个预配置的 LAN IP 地址用于连接。在 Alcatel SpeedTouch™ Home 的情况下,该地址是 10.0.0.138 。路由器的文档应该列出设备使用的地址。要打开隧道并启动 PPP 会话:
# pptp address adsl|
如果在这个命令的末尾添加一个和号("&"), pptp 将返回提示符。 |
将创建一个名为 tun 的虚拟隧道设备,用于 pptp 和 ppp 进程之间的交互。一旦提示返回,或者 pptp 进程确认连接后,检查隧道:
% ifconfig tun0
tun0: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500
inet 216.136.204.21 --> 204.152.186.171 netmask 0xffffff00
Opened by PID 918如果连接失败,请检查路由器的配置,通常可以使用 Web 浏览器访问。此外,检查 pptp 的输出和日志文件 /var/log/ppp.log ,以获取线索。
Chapter 31. 电子邮件
31.1. 简介
“电子邮件”,更为人所知的是 email ,是当今最广泛使用的通信形式之一。本章介绍了在 FreeBSD 上运行邮件服务器的基本概念,以及使用 FreeBSD 发送和接收电子邮件的简介。如需更全面的内容,请参考 Bibliography 中列出的书籍。
本章内容包括:
-
发送和接收电子邮件涉及哪些软件组件?
-
如何配置 DragonFly Mail Agent 。
-
在 FreeBSD 中,基本的 Sendmail 配置文件位于哪里?
-
远程邮箱和本地邮箱的区别。
-
如何安装和配置替代的邮件传输代理( Mail Transfer Agent ),以替换 DragonFly Mail Agent 或 Sendmail 。
-
如何解决常见的邮件服务器问题。
-
如何配置 Sendmail 仅发送邮件。
-
如何在 Sendmail 中配置 SMTP 身份验证以增加安全性。
-
如何安装和使用邮件用户代理( Mail User Agent ),例如 mutt ,来发送和接收电子邮件。
-
如何从远程的 POP 或 IMAP 服务器下载邮件。
-
如何自动应用过滤器和规则到收件箱中的电子邮件。
31.2. 邮件组件
电子邮件交换涉及五个主要部分:邮件用户代理( MUA ),邮件传输代理( MTA ),邮件主机,远程或本地邮箱以及 DNS 。本节概述了这些组件。
- 邮件用户代理( MUA )
-
邮件用户代理( MUA )是一种用于撰写、发送和接收电子邮件的应用程序。这个应用程序可以是一个命令行程序,比如内置的
mail实用程序,也可以是来自 Ports Collection 的第三方应用程序,比如 alpine 、 elm 或 mutt 。 Ports Collection 中还提供了许多图形化程序,包括 Claws Mail 、 Evolution 和 Thunderbird 。一些组织提供了一个可以通过 Web 浏览器访问的 Web 邮件程序。关于在 FreeBSD 上安装和使用 MUA 的更多信息可以在 邮件用户代理 中找到。 - 邮件传输代理( MTA )
-
邮件传输代理( MTA )负责接收传入邮件和投递传出邮件。从 FreeBSD 14.0 版本开始,默认的 MTA 是 DragonFly Mail Agent ( dma(8) );在早期版本中,默认的 MTA 是 sendmail(8) 。其他 MTA ,包括 Exim 、 Postfix 和 qmail ,可以安装来替换默认的 MTA 。
- 邮件主机和邮箱
-
邮件主机是负责为主机或网络传递和接收邮件的服务器。邮件主机收集发送到该域的所有邮件,并根据配置将其存储在默认的
mbox或备选的 Maildir 格式中。一旦邮件被存储,可以使用 MUA 在本地阅读,也可以使用 POP 或 IMAP 等协议进行远程访问和收取。如果邮件在本地阅读,则不需要安装 POP 或 IMAP 服务器。 - 域名系统( DNS )
-
域名系统( DNS )及其守护进程 named(8) 在邮件传递中起着重要作用。为了将邮件从一个站点传递到另一个站点,邮件传输代理( MTA )将在 DNS 中查找远程站点,以确定哪个主机将接收目标站点的邮件。当邮件从远程主机发送到 MTA 时,也会发生这个过程。
31.3. DragonFly Mail Agent ( DMA )
DragonFly Mail Agent (DMA) 是 FreeBSD 14.0 版本开始的默认邮件传输代理( MTA )。 dma(8) 是一个小型的邮件传输代理,专为家庭和办公室使用而设计。它接收来自本地安装的邮件用户代理( MUA )的邮件,并将邮件传递到本地或远程目的地。远程传递包括多个功能,如 TLS/SSL 支持和 SMTP 身份验证。
dma(8) 并不是用来替代真正的、大型的邮件传输代理( MTA )如 sendmail(8) 或 postfix(1) 的。因此, dma(8) 不会监听端口 25 来接收传入连接。
31.3.1. 配置 DragonFly Mail Agent (DMA)
DMA 带有一个默认配置,适用于许多部署。自定义设置在 [/etc/dma/dma.conf] 中定义, SMTP 身份验证在 [/etc/dma/auth.conf] 中配置。
31.3.1.1. 使用 DMA 通过 Gmail 路由发送邮件( STARTTLS:SMTP 示例)
这个示例 /etc/dma/dma.conf 可以用来通过 Google 的 SMTP 服务器发送邮件。
SMARTHOST smtp.gmail.com PORT 587 AUTHPATH /etc/dma/auth.conf SECURETRANSFER STARTTLS MASQUERADE [email protected]
在 [/etc/dma/auth.conf] 文件中,可以通过一行代码设置身份验证。
[email protected]|smtp.gmail.com:password
执行以下命令来测试配置:
% echo this is a test | mail -v -s testing-email [email protected]31.3.1.2. 使用 DMA 将出站邮件通过 Fastmail 路由( SSL/TLS 示例)
这个示例 /etc/dma/dma.conf 可以用来通过 Fastmail 的 SMTP 服务器发送邮件。
SMARTHOST smtp.fastmail.com PORT 465 AUTHPATH /etc/dma/auth.conf SECURETRANSFER MAILNAME example.server.com
在 [/etc/dma/auth.conf] 文件中,可以通过一行代码设置身份验证。
[email protected]|smtp.fastmail.com:password
执行以下命令来测试配置:
% echo this is a test | mail -v -s testing-email [email protected]31.3.1.3. 使用 DMA 将出站邮件路由到自定义邮件主机
这个示例 /etc/dma/dma.conf 可以用来使用自定义邮件主机发送邮件。
SMARTHOST mail.example.org PORT 587 AUTHPATH /etc/dma/auth.conf SECURETRANSFER STARTTLS
在 [/etc/dma/auth.conf] 文件中,可以通过一行代码设置身份验证。
[email protected]|mail.example.org:password
执行以下命令来测试配置:
% echo this is a test | mail -v -s testing-email [email protected]31.4. Sendmail 是一种用于电子邮件传输的开源软件。它是一种邮件传输代理( MTA ),用于将电子邮件从发送者的计算机发送到接收者的计算机。 Sendmail 具有广泛的功能和灵活性,可以在各种操作系统上运行,并且被广泛用于互联网上的电子邮件传输。它支持多种邮件协议和格式,并提供了丰富的配置选项,使用户能够根据自己的需求进行定制。 Sendmail 是互联网上最早的邮件传输代理之一,至今仍然被广泛使用。
Sendmail 是一个古老而多功能的邮件传输代理( MTA ),在 UNIX 和类 UNIX 系统中有着悠久的历史。它曾是 FreeBSD 基本系统的一部分,直到 FreeBSD 13 版本,提供强大的电子邮件传输功能、广泛的自定义选项以及对复杂路由和过滤的支持。
31.4.1. 配置文件
Sendmail 的配置文件位于 [/etc/mail/] 目录中。
- /etc/mail/access
-
此访问数据库文件定义了哪些主机或 IP 地址可以访问本地邮件服务器以及他们的访问权限。以“ OK ”列出的主机是允许向本主机发送邮件的,默认选项是只要邮件的最终目的地是本地机器即可。以“ REJECT ”列出的主机将被拒绝所有邮件连接。以“ RELAY ”列出的主机可以使用此邮件服务器发送任何目的地的邮件。以“ ERROR ”列出的主机将返回带有指定邮件错误的邮件。如果将主机列为“ SKIP ”, Sendmail 将中止对此条目的当前搜索,而不接受或拒绝邮件。以“ QUARANTINE ”列出的主机的消息将被保留,并将收到指定的文本作为保留原因。
在 FreeBSD 的示例配置文件 /etc/mail/access.sample 中可以找到使用这些选项的 IPv4 和 IPv6 地址的示例。
要配置访问数据库,请使用示例中显示的格式在 [/etc/mail/access] 文件中进行条目输入,但不要在条目前面加上注释符号(
#)。为每个需要配置访问权限的主机或网络创建一个条目。与表格左侧匹配的邮件发送者将受到表格右侧操作的影响。每当此文件更新时,更新其数据库并重新启动 Sendmail :
# makemap hash /etc/mail/access < /etc/mail/access # service sendmail restart - /etc/mail/aliases
-
这个数据库文件包含了一个虚拟邮箱列表,这些邮箱可以扩展到用户、文件、程序或其他别名。以下是一些条目,用于说明文件格式:
root: localuser ftp-bugs: joe,eric,paul bit.bucket: /dev/null procmail: "|/usr/local/bin/procmail"
冒号左侧的邮箱名称会被扩展为右侧的目标邮箱。第一个条目将
root邮箱扩展为localuser邮箱,然后在.filename/etc/mail/aliases 数据库中查找。如果找不到匹配项,则将消息发送到localuser。第二个条目显示了一个邮件列表。邮件发送到ftp-bugs会被扩展为三个本地邮箱joe、eric和paul。远程邮箱可以指定为_user @ example.com_。第三个条目展示了如何将邮件写入文件,本例中为.filename/dev/null 。最后一个条目演示了如何通过 UNIX® 管道将邮件发送到一个程序,即.filename/usr/local/bin/procmail 。有关此文件格式的更多信息,请参考 aliases(5) 。每当此文件更新时,运行
newaliases命令以更新和初始化别名数据库。 - /etc/mail/sendmail.cf
-
这是 Sendmail 的主配置文件。它控制 Sendmail 的整体行为,包括从重写电子邮件地址到向远程邮件服务器打印拒绝消息的一切。因此,这个配置文件非常复杂。幸运的是,对于标准邮件服务器来说,这个文件很少需要更改。
主 Sendmail 配置文件可以使用定义 Sendmail 功能和行为的 m4 宏来构建。有关详细信息,请参阅
/usr/src/contrib/sendmail/cf/README文件。每当对该文件进行更改时,需要重新启动 Sendmail 才能使更改生效。
- /etc/mail/virtusertable
-
这个数据库文件将虚拟域和用户的邮件地址映射到真实的邮箱。这些邮箱可以是本地的、远程的、在 [/etc/mail/aliases](/etc/mail/aliases) 中定义的别名,或者是文件。这样可以在一台机器上托管多个虚拟域。
FreeBSD 在 [/etc/mail/virtusertable.sample] 提供了一个示例配置文件,以进一步展示其格式。以下示例演示了如何使用该格式创建自定义条目:
[email protected] root [email protected] [email protected] @example.com joe
此文件按照第一匹配的顺序进行处理。当电子邮件地址与左侧的地址匹配时,它将映射到右侧列出的本地邮箱。在此示例中,第一条目的格式将特定的电子邮件地址映射到本地邮箱,而第二条目的格式将特定的电子邮件地址映射到远程邮箱。最后,任何未与前面的条目匹配的来自
example.com的电子邮件地址将匹配最后一个映射,并发送到本地邮箱joe。创建自定义条目时,请使用此格式并将其添加到 /etc/mail/virtusertable 。每当编辑此文件时,请更新其数据库并重新启动 Sendmail :# makemap hash /etc/mail/virtusertable < /etc/mail/virtusertable # service sendmail restart - /etc/mail/relay-domains
-
在默认的 FreeBSD 安装中, Sendmail 被配置为只能从运行它的主机发送邮件。例如,如果有一个 POP 服务器可用,用户可以从远程位置检查邮件,但他们将无法从外部位置发送出站邮件。通常,在尝试发送邮件后的几分钟内,将会收到来自
MAILER-DAEMON的邮件,并附带有5.7 Relaying Denied的消息。最直接的解决方案是将 ISP 的 FQDN 添加到 [/etc/mail/relay-domains] 文件中。如果需要多个地址,请每行添加一个地址:
your.isp.example.com other.isp.example.net users-isp.example.org www.example.org
在创建或编辑此文件后,使用
service sendmail restart重新启动 Sendmail 。现在,只要在此列表中的任何主机通过系统发送邮件,并且用户在系统上有一个账户,邮件将会成功发送。这使得用户可以远程从系统发送邮件,而不会使系统暴露于来自互联网的垃圾邮件中继。
31.5. 更改邮件传输代理
从 FreeBSD 14.0 版本开始,默认的 MTA 是 dma(8) ,而在 14.0 之前,默认的 MTA 是 sendmail(8) 。然而,系统管理员可以更改系统的 MTA 。在 FreeBSD Ports Collection 的 mail 类别中提供了多种可选的 MTA 。
|
如果默认的出站邮件服务被禁用,重要的是要用替代的邮件传递系统来替代它。否则,像 periodic(8) 这样的系统功能将无法通过电子邮件传递其结果。系统的许多部分都期望有一个可用的邮件传输代理( MTA )。如果应用程序在禁用后继续使用默认的二进制文件尝试发送电子邮件,邮件可能会进入非活动队列并永远无法传递。 |
31.5.1. 替换 Sendmail 与其他 MTA
为了完全禁用 sendmail(8) ,执行以下命令:
# sysrc sendmail_enable="NO"
# sysrc sendmail_submit_enable="NO"
# sysrc sendmail_outbound_enable="NO"
# sysrc sendmail_msp_queue_enable="NO"要仅禁用 sendmail(8) 的传入邮件服务,请执行以下命令:
# sysrc sendmail_enable="NO"然后停止 sendmail(8) 服务:
# service sendmail onestop由于 sendmail(8) 非常普遍,一些软件假设它已经安装和配置好,因此需要进行一些额外的配置。请检查 .filename#/etc/periodic.conf# 文件,并确保这些值设置为 NO 。如果该文件不存在,请创建并添加以下条目:
daily_clean_hoststat_enable="NO" daily_status_mail_rejects_enable="NO" daily_status_include_submit_mailq="NO" daily_submit_queuerun="NO"
下一步是安装另一个 MTA ,本示例将使用 dma(8) 。如上所述, dma(8) 是 FreeBSD 14.0 版本开始的默认 MTA 。因此,如果您使用的是旧版本,则只需要从 ports 安装它。
要安装它,请执行以下命令:
# pkg install dma按照 << 配置 Dragonfly 邮件代理 >> 中所示进行配置。
然后将文件 /etc/mail/mailer.conf 中的所有条目更改为 dma(8) :
# $FreeBSD$ # # Execute the "real" sendmail program, named /usr/libexec/sendmail/sendmail # # If dma(8) is installed, an example mailer.conf that uses dma(8) instead can # be found in /usr/share/examples/dma # sendmail /usr/local/libexec/dma mailq /usr/local/libexec/dma newaliases /usr/local/libexec/dma
|
当使用基本系统中包含的 dma(8) 版本时,路径将更改为 [/usr/libexec/dma]#. |
为了确保在启动或关机之前将队列中的所有内容刷新,请执行以下命令:
# sysrc dma_flushq_enable="YES"一旦所有配置完成,建议重新启动系统。重新启动可以确保系统正确配置,以便在启动时自动启动新的 MTA 。
31.5.2. 用其他邮件传输代理( MTA )替换 DragonFly Mail Agent ( DMA )
如上所述,从 FreeBSD 14.0 版本开始,默认的 MTA 是 DMA 。在这个例子中,将使用 mail/postfix 作为替代的 MTA 。
在安装 mail/postfix 之前,需要进行一些额外的配置。检查 /etc/periodic.conf 并确保这些值设置为 NO 。如果该文件不存在,请创建它并添加以下条目:
daily_clean_hoststat_enable="NO" daily_status_mail_rejects_enable="NO" daily_status_include_submit_mailq="NO" daily_submit_queuerun="NO"
然后安装包: mail/postfix[] :
# pkg install postfix要在系统启动时启动 mail/postfix ,执行以下命令:
# sysrc postfix_enable="YES"|
在安装应用程序后阅读安装消息是一个好的做法。它提供了有关设置等方面的有用信息。 |
如果在 /usr/local/etc/mail/mailer.conf 中 * 尚未 * 激活后缀,请执行以下命令:
mv /usr/local/etc/mail/mailer.conf /usr/local/etc/mail/mailer.conf.old
install -d /usr/local/etc/mail
install -m 0644 /usr/local/share/postfix/mailer.conf.postfix /usr/local/etc/mail/mailer.conf在使用 SASL 时,请确保 postfix 有权限读取 sasldb 文件。可以通过将 postfix 添加到 mail 组,并将 /usr/local/etc/sasldb* 文件设置为 mail 组可读(这应该是新安装的默认设置)来实现这一点。
一旦所有配置完成,建议重新启动系统。重新启动可以确保系统正确配置,以便在启动时自动启动新的 MTA 。
31.6. 邮件用户代理
MUA 是一种用于发送和接收电子邮件的应用程序。随着电子邮件的“演变”和变得越来越复杂, MUA 变得越来越强大,为用户提供了更多的功能和灵活性。 FreeBSD Ports Collection 的“ mail ”类别中包含了许多 MUA 。这些包括图形化的电子邮件客户端,如 Evolution 或 Balsa ,以及基于控制台的客户端,如 mutt 或 alpine 。
31.6.1. 邮件
mail(1) 是默认安装在 FreeBSD 上的 MUA (邮件用户代理)。它是一个基于控制台的 MUA ,提供发送和接收基于文本的电子邮件所需的基本功能。它提供有限的附件支持,并且只能访问本地邮箱。
虽然 mail(1) 本身不支持与 POP 或 IMAP 服务器的交互,但可以使用诸如 fetchmail 或 getmail 之类的应用程序将这些邮箱下载到本地的 mbox 中。
为了发送和接收电子邮件,请运行 mail(1) 。
% mail用户的邮箱内容位于 /var/mail 中,会被 mail(1) 自动读取。如果邮箱为空,该工具将退出并显示一条消息表示未找到邮件。如果存在邮件,应用程序界面将启动,并显示一份消息列表。
消息会自动编号,如下面的示例所示:
Mail version 8.1 6/6/93. Type ? for help. "/var/mail/username": 3 messages 3 new >N 1 root@localhost Mon Mar 8 14:05 14/510 "test" N 2 root@localhost Mon Mar 8 14:05 14/509 "user account" N 3 root@localhost Mon Mar 8 14:05 14/509 "sample"
现在可以通过键入 t 后跟消息编号来阅读消息。
这个例子读取第一封电子邮件:
& t 1 Message 1: From root@localhost Mon Mar 8 14:05:52 2004 X-Original-To: username@localhost Delivered-To: username@localhost To: username@localhost Subject: test Date: Mon, 8 Mar 2004 14:05:52 +0200 (SAST) From: root@localhost (Charlie Root) This is a test message, please reply if you receive it.
如本示例所示,消息将显示完整的标题。
要再次显示消息列表,请按下 h 。
如果需要回复邮件,请按下 R 或 r 键。 R 命令指示 mail(1) 仅回复邮件的发送者,而 r 命令则回复给所有其他收件人。这些命令可以在回复的邮件编号后面添加。在输入回复内容后,邮件的结尾应该用单独一行的 . 标记。
下面是一个示例:
& R 1 To: root@localhost Subject: Re: test Thank you, I did get your email. . EOT
要发送一封新邮件,按下 m 键,然后输入收件人的电子邮件地址。可以通过使用 , 分隔符来指定多个收件人。然后可以输入邮件的主题,然后是邮件内容。邮件的结束应该在单独的一行上放置一个单独的 . 。
& mail root@localhost Subject: I mastered mail Now I can send and receive email using mail ... :) . EOT
|
mail(1) 并不是为了处理附件而设计的,因此在处理附件方面表现不佳。较新的邮件用户代理( MUAs )以更智能的方式处理附件。 |
31.6.2. Mutt 是一个基于文本的电子邮件客户端,它在 Unix-like 操作系统上运行。它具有高度可定制性和灵活性,可以通过配置文件进行个性化设置。 Mutt 支持多种邮件协议,包括 POP3 、 IMAP 和 SMTP ,并且可以与其他工具集成,如 GnuPG 和 Muttprint 。它被广泛用于命令行环境下的电子邮件管理。
Mutt 是一个功能强大的邮件用户代理程序,具有许多功能,包括:
-
线程消息的能力。
-
PGP 支持对电子邮件进行数字签名和加密。
-
MIME 支持。
-
Maildir 支持。
-
高度可定制。
请参考链接: [http://www.mutt.org](http://www.mutt.org) 获取有关 Mutt 的更多信息。
|
值得一提的是一个名为 NeoMutt 的 Mutt 分支,它带来了额外的功能。请访问链接了解更多信息: [NeoMutt 网站](https://neomutt.org/about.html) 。如果选择 NeoMutt ,请将以下命令示例中的 |
Mutt 可以使用 mail/mutt 端口进行安装。安装完成后,可以通过以下命令启动 Mutt :
% muttMutt 将自动读取并显示用户邮箱的内容,路径为 /var/mail 。如果没有找到邮件, Mutt 将等待用户的命令。下面的示例显示了 Mutt 显示消息列表的情况:
要阅读一封电子邮件,使用光标键选择它,然后按下 Enter 。下面是 Mutt 显示电子邮件的示例:
与 mail(1) 类似, Mutt 可以用于仅回复邮件的发件人,也可以回复给所有收件人。要仅回复给邮件的发件人,按下键盘上的 [r] 键。要向原始发件人和所有收件人发送群组回复,按下键盘上的 [g] 键。
|
默认情况下, Mutt 使用 vi(1) 编辑器来创建和回复电子邮件。每个用户可以通过在其主目录中创建或编辑 .filename#.muttrc# 文件并设置 |
按下 m 键来撰写一封新的邮件。在输入有效的主题后, Mutt 将启动 vi(1) 以便编写邮件内容。完成邮件内容后,保存并退出 vi 。 Mutt 将恢复,并显示待发送邮件的摘要屏幕。要发送邮件,请按下 y 键。下面是摘要屏幕的示例:
Mutt 包含丰富的帮助信息,可以通过在大多数菜单中按下 ? 来访问。在适当的情况下,顶部行还显示键盘快捷键。
31.6.3. 阿尔卑斯
Alpine 面向初学者用户,同时也包含一些高级功能。
|
在过去, Alpine 曾发现过几个远程漏洞,允许远程攻击者通过发送特制的电子邮件,在本地系统上以用户身份执行任意代码。虽然已经修复了已知的问题,但 Alpine 的代码编写方式存在安全隐患, FreeBSD 安全官员认为可能还存在其他未被发现的漏洞。用户在安装 Alpine 时需自行承担风险。 |
可以使用 mail/alpine 端口安装当前版本的 alpine 。安装完成后,可以通过以下命令启动 alpine :
% alpine当 alpine 第一次运行时,它会显示一个问候页面,其中包含简要介绍,以及 alpine 开发团队的请求,要求发送一封匿名电子邮件,以便他们判断有多少用户在使用他们的客户端。要发送这封匿名邮件,请按下 Enter 。或者,按下 E 退出问候页面,而不发送匿名邮件。下面是问候页面的示例:
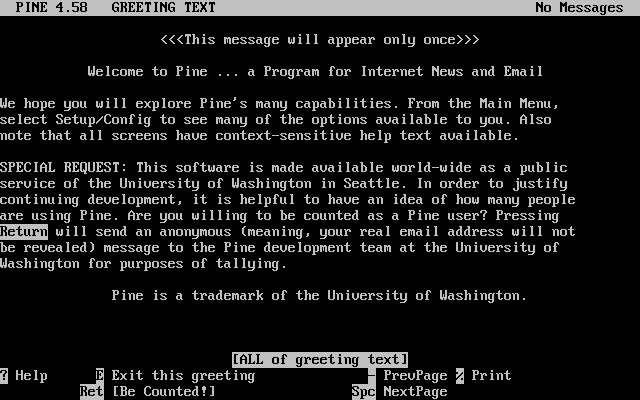
然后显示主菜单,可以使用光标键进行导航。该主菜单提供了快捷方式,用于撰写新邮件、浏览邮件目录和管理通讯录条目。在主菜单下方,显示了与当前任务相关的执行特定功能的键盘快捷键。
alpine 打开的默认目录是 inbox 。要查看消息索引,请按下 I ,或选择下面显示的 选项。
消息索引显示当前目录中的消息,并可以使用光标键进行导航。按下 Enter 可以阅读突出显示的消息。
在下面的截图中, alpine 显示了一个示例消息。屏幕底部显示了上下文键盘快捷键。一个快捷键的示例是 r ,它告诉 MUA 回复当前显示的消息。
在 alpine 中回复电子邮件是使用 pico 编辑器完成的, pico 编辑器是 alpine 的默认安装选项。 pico 编辑器使得浏览邮件变得容易,并且对于新手用户来说比 vi(1) 或 mail(1) 更容易使用。完成回复后,按下 Ctrl+X 即可发送邮件。在发送邮件之前, alpine 会要求确认。
可以使用主菜单中的 选项来自定义 Alpine 。
31.7. 高级主题
本节涵盖了更复杂的主题,如邮件配置和为整个域名设置邮件。
31.7.1. 基本配置
只要配置了 /etc/resolv.conf 或者网络可以访问到配置的 DNS 服务器,就可以直接向外部主机发送电子邮件。要将电子邮件传递到 FreeBSD 主机上的 MTA ,请执行以下操作之一:
-
为该域名运行一个 DNS 服务器。
-
将邮件直接发送到机器的 FQDN 。
为了直接将邮件投递到主机,它必须拥有一个永久的静态 IP 地址,而不是动态 IP 地址。如果系统位于防火墙后面,必须配置防火墙以允许 SMTP 流量。要在主机上直接接收邮件,必须配置以下两种方式之一:
-
确保 DNS 中最低编号的 MX 记录指向主机的静态 IP 地址。
-
确保 DNS 中没有主机的 MX 记录。
以上两种方法都可以直接将邮件发送到主机。
试试这个:
# hostname输出应该类似于以下内容:
example.FreeBSD.org
# host example.FreeBSD.org输出应该类似于以下内容:
example.FreeBSD.org has address 204.216.27.XX
在这个例子中,直接发送到 mailto:yourlogin @ example.FreeBSD.org[yourlogin @ example.FreeBSD.org] 的邮件应该可以正常工作,前提是在 example.FreeBSD.org 上运行了一个功能齐全的 MTA 。请注意, dma(8) 不会在端口 25 上监听传入连接,因此在这种情况下不能使用它。
对于这个例子:
# host example.FreeBSD.org输出应该类似于以下内容:
example.FreeBSD.org has address 204.216.27.XX example.FreeBSD.org mail is handled (pri=10) by nevdull.FreeBSD.org
所有发送到 example.FreeBSD.org 的邮件将会被收集在 nevdull 上,使用相同的用户名,而不是直接发送到您的主机。
上述信息由 DNS 服务器处理。携带邮件路由信息的 DNS 记录是邮件交换器记录( MX 记录)。如果不存在 MX 记录,则邮件将通过其 IP 地址直接传递给主机。
freefall.FreeBSD.org 的 MX 记录曾经是这样的:
freefall MX 30 mail.crl.net freefall MX 40 agora.rdrop.com freefall MX 10 freefall.FreeBSD.org freefall MX 20 who.cdrom.com
freefall 有许多 MX 记录。最低的 MX 号码对应的主机直接接收邮件,如果可用的话。如果由于某种原因无法访问该主机,下一个较低编号的主机将暂时接收邮件,并在较低编号的主机可用时将其传递。
备用 MX 站点应该有独立的互联网连接,以便发挥最大的作用。您的互联网服务提供商可以提供这项服务。
31.7.2. 域名的邮件
在为网络配置邮件传输代理( MTA )时,任何发送到其域中的主机的邮件都应该被重定向到 MTA ,以便用户可以在主邮件服务器上接收到他们的邮件。
为了使生活更加方便,在 MTA 和带有 MUA 的系统上应该存在相同的用户名的用户账户。使用 adduser(8) 命令来创建用户账户。
|
除了将本地用户添加到主机上之外,还有一种称为虚拟用户的替代方法。像 Cyrus 和 Dovecot 这样的程序可以集成到 MTA 中,用于处理用户、邮件存储,并通过 POP3 和 IMAP 提供访问。 |
MTA 必须成为网络上每个工作站的指定邮件交换器。这是通过 DNS 配置中的 MX 记录来完成的:
example.FreeBSD.org A 204.216.27.XX ; Workstation MX 10 nevdull.FreeBSD.org ; Mailhost
无论 A 记录指向何处,这将把工作站的邮件重定向到 MTA 。邮件将发送到 MX 主机。
这必须在 DNS 服务器上进行配置。如果网络没有运行自己的 DNS 服务器,请与 ISP 或 DNS 提供商联系。
以下是虚拟邮件托管的示例。
考虑一个域名为 customer1.org 的客户,所有发送给 customer1.org 的邮件都应该发送到 mail.myhost.com 。
DNS 条目应该如下所示:
customer1.org MX 10 mail.myhost.com
为了仅处理 customer1.org 域名的电子邮件,不需要为其创建 A 记录。然而,如果没有为 customer1.org 创建 A 记录,则无法使用 ping 命令对其进行测试。
告诉 MTA 应该接受哪些域名和 / 或主机名的邮件。对于 Sendmail ,以下任一方式都可以使用:
-
在使用
FEATURE(use_cw_file)时,将主机添加到 /etc/mail/local-host-names 中。 -
在 /etc/sendmail.cf 文件中添加一行
Cwyour.host.com。
31.7.3. 设置仅发送的配置
有许多情况下,人们可能只想通过中继发送邮件。一些例子包括:
-
计算机是一台台式机,需要使用诸如 mail(1) 这样的程序,使用 ISP 的邮件中继。
-
计算机是一个服务器,不处理本地邮件,但需要将所有邮件传递给中继进行处理。
虽然任何邮件传输代理( MTA )都能够满足这个特定需求,但是仅仅为了处理邮件转发而正确配置一个功能齐全的 MTA 可能会很困难。像 Sendmail 和 Postfix 这样的程序对于这种用途来说过于复杂。
此外,一个典型的互联网接入服务协议可能禁止用户运行“邮件服务器”。
满足这些需求的最简单方法是使用包含在 [configuring-dragonfly-mail-agent ,基本系统 ] 中的 dma(8) MTA 。对于版本低于 13.2 的系统,需要从 ports 进行安装。
除了 dma(8) 之外,还可以使用第三方软件来实现相同的功能,比如 mail/ssmtp 。
# cd /usr/ports/mail/ssmtp
# make install replace clean安装完成后,可以使用 /usr/local/etc/ssmtp/ssmtp.conf 配置 mail/ssmtp 。
[email protected] mailhub=mail.example.com rewriteDomain=example.com hostname=_HOSTNAME_
使用真实的电子邮件地址替换 root 。在 mail.example.com 的位置输入 ISP 的出站邮件中继。一些 ISP 称其为“出站邮件服务器”或“ SMTP 服务器”。
请确保禁用 Sendmail ,包括出站邮件服务。有关详细信息,请参阅 [mail-disable-sendmail] 。
包: mail/ssmtp[] 还有其他可用的选项。有关更多信息,请参阅 /usr/local/etc/ssmtp 中的示例或 ssmtp 的手册页。
以这种方式设置 ssmtp 允许计算机上需要发送邮件的任何软件正常运行,同时不违反 ISP 的使用政策,也不允许计算机被劫持用于发送垃圾邮件。
31.7.4. Sendmail 中的 SMTP 身份验证
在 MTA 上配置 SMTP 身份验证提供了许多好处。 SMTP 身份验证为 Sendmail 增加了一层安全性,并为切换主机的移动用户提供了在不需要每次重新配置邮件客户端设置的情况下使用相同 MTA 的能力。
从 Ports Collection 安装包: security/cyrus-sasl2[] 。该端口支持许多编译时选项。对于在此示例中演示的 SMTP 身份验证方法,请确保 LOGIN 未禁用。
安装完包 :security/cyrus-sasl2[] 后,编辑 /usr/local/lib/sasl2/Sendmail.conf ,如果该文件不存在则创建,并添加以下行:
pwcheck_method: saslauthd
接下来,安装包: security/cyrus-sasl2-saslauthd[] ,并执行以下命令:
# sysrc saslauthd_enable="YES"最后,启动 saslauthd 守护进程:
# service saslauthd start该守护进程用作 Sendmail 的代理,用于对 FreeBSD passwd(5) 数据库进行身份验证。这样可以避免为每个需要使用 SMTP 身份验证的用户创建新的用户名和密码,并保持登录和邮件密码相同。
接下来,编辑 [/etc/make.conf] 文件,并添加以下行:
SENDMAIL_CFLAGS=-I/usr/local/include/sasl -DSASL SENDMAIL_LDADD=/usr/local/lib/libsasl2.so
这些行为 Sendmail 提供了在编译时链接到 cyrus-sasl2 的正确配置选项。在重新编译 Sendmail 之前,请确保已安装 cyrus-sasl2 。
通过执行以下命令重新编译 Sendmail :
# cd /usr/src/lib/libsmutil
# make cleandir && make obj && make
# cd /usr/src/lib/libsm
# make cleandir && make obj && make
# cd /usr/src/usr.sbin/sendmail
# make cleandir && make obj && make && make install如果 /usr/src 没有发生大量更改,并且所需的共享库可用,那么这个编译过程不应该出现任何问题。
在重新编译和安装 Sendmail 之后,编辑 [/etc/mail/freebsd.mc] 或本地 [.mc] 文件。许多管理员选择使用 hostname(1) 的输出作为 [.mc] 文件的名称,以确保唯一性。
添加以下行:
dnl set SASL options TRUST_AUTH_MECH(`GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnl define(`confAUTH_MECHANISMS', `GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnl
这些选项配置了 Sendmail 用于对用户进行身份验证的不同方法。如果要使用除 pwcheck 之外的方法,请参考 Sendmail 文档。
最后,在 [/etc/mail] 目录下运行 make(1) 。这将运行新的 .mc 文件并创建一个名为 freebsd.cf 或者与本地 .mc 文件相同的名称的 .cf 文件。
然后,运行 make install restart 命令,它将会把文件复制到 sendmail.cf ,并且正确地重新启动 Sendmail 。
有关此过程的更多信息,请参考 [/etc/mail/Makefile](/etc/mail/Makefile) 。
要测试配置,请使用 MUA 发送一封测试邮件。如需进一步调查,请将 Sendmail 的 LogLevel 设置为 13 ,并观察 /var/log/maillog 中是否有任何错误。
有关更多信息,请参考 http://www.sendmail.org/ ~ ca/email/auth.html[SMTP 认证] 。
Chapter 32. 网络服务器
32.1. 简介
本章介绍了 UNIX® 系统上一些常用的网络服务。这包括安装、配置、测试和维护许多不同类型的网络服务。本章中还包含了示例配置文件,供参考使用。
到本章结束时,读者将会了解:
-
如何管理 inetd 守护进程。
-
如何设置网络文件系统(NFS)。
-
如何设置网络信息服务器(NIS)以实现用户账户的集中和共享。
-
如何将 FreeBSD 设置为 LDAP 服务器或客户端
-
如何使用 DHCP 设置自动网络设置。
-
如何设置域名服务器(DNS)。
-
如何设置 Apache HTTP 服务器。
-
如何设置一个文件传输协议(FTP)服务器。
-
如何使用 Samba 为 Windows® 客户端设置文件和打印服务器。
-
如何使用网络时间协议(NTP)同步时间和日期,并设置时间服务器。
-
如何设置 iSCSI。
本章假设读者具备以下基本知识:
-
/etc/rc 脚本。
-
网络术语。
-
安装额外的第三方软件(安装应用程序:软件包和 Ports)。
32.2. inetd 超级服务器
inetd(8) 守护进程有时被称为超级服务器,因为它管理许多服务的连接。不需要启动多个应用程序,只需启动 inetd 服务即可。当 inetd 接收到由其管理的服务的连接时,它确定连接所需的程序,为该程序生成一个进程,并为该程序分配一个套接字。与在独立模式下单独运行每个守护进程相比,使用 inetd 来处理不常用的服务可以减少系统负载。
inetd 主要用于生成其他守护进程,但也会处理一些内部的简单协议,例如 chargen、auth、time、echo、discard 和 daytime。
本节介绍了配置 inetd 的基础知识。
32.2.1. 配置文件
配置 inetd 是通过编辑 /etc/inetd.conf 文件来完成的。该配置文件的每一行表示一个可以由 inetd 启动的应用程序。默认情况下,每一行都以注释(#)开头,表示 inetd 不监听任何应用程序。要配置 inetd 监听应用程序的连接,请删除该应用程序行开头的 #。
在保存您的编辑后,通过编辑 /etc/rc.conf 配置 inetd 在系统启动时启动:
inetd_enable="YES"
要立即启动 inetd,以便它监听您配置的服务,请键入:
# service inetd start一旦 inetd 启动,每当对 /etc/inetd.conf 文件进行修改时,需要通知它。
例 35. 重新加载 inetd 配置文件
# service inetd reload通常情况下,应用程序的默认条目无需编辑,只需删除 # 即可。在某些情况下,可能需要编辑默认条目。
作为一个例子,这是 IPv4 上 ftpd(8) 的默认条目:
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
一个条目中的七列如下:
service-name
socket-type
protocol
{wait|nowait}[/max-child[/max-connections-per-ip-per-minute[/max-child-per-ip]]]
user[:group][/login-class]
server-program
server-program-arguments
在哪里:
- 服务名称
-
要启动的守护进程的服务名称。它必须对应于 /etc/services 中列出的服务。这决定了 inetd 监听哪个端口以接收该服务的传入连接。当使用自定义服务时,必须首先将其添加到 /etc/services 中。
- 套接字类型
-
可以使用
stream、dgram、raw或seqpacket。对于 TCP 连接,请使用stream,对于 UDP 服务,请使用dgram。 - 协议
-
使用以下协议名称之一:
协议名称 解释 tcp or tcp4
TCP IPv4
udp or udp4
UDP IPv4
tcp6
TCP IPv6
udp6
UDP IPv6
tcp46
Both TCP IPv4 and IPv6
udp46
Both UDP IPv4 and IPv6
- {wait|nowait}[/max-child[/max-connections-per-ip-per-minute[/max-child-per-ip]]]
-
在这个字段中,必须指定
wait或nowait。max-child、max-connections-per-ip-per-minute和max-child-per-ip是可选的。wait|nowait表示服务是否能够处理自己的套接字。dgram套接字类型必须使用wait,而通常是多线程的stream守护进程应该使用nowait。wait通常将多个套接字交给单个守护进程处理,而nowait则为每个新套接字生成一个子守护进程。max-child参数设置了 inetd 可以生成的子守护进程的最大数量。例如,要限制守护进程的实例数为十个,可以在nowait后面加上/10。指定/0允许无限数量的子进程。max-connections-per-ip-per-minute限制每个特定 IP 地址每分钟的连接数。一旦达到限制,该 IP 地址的进一步连接将被丢弃,直到分钟结束。例如,值为/10将限制每个特定 IP 地址每分钟的连接尝试次数为十次。max-child-per-ip限制在任何单个 IP 地址上代表启动的子进程数量。这些选项可以限制过度的资源消耗,并帮助防止拒绝服务攻击。在 fingerd(8) 的默认设置中可以看到一个示例:
finger stream tcp nowait/3/10 nobody /usr/libexec/fingerd fingerd -k -s
- 用户
-
守护进程将以哪个用户名运行。守护进程通常以
root、daemon或nobody运行。 - 服务器程序
-
守护进程的完整路径。如果守护进程是由 inetd 内部提供的服务,请使用
internal。 - 服务器程序参数
-
用于指定在调用守护程序时要传递的任何命令参数。如果守护程序是内部服务,请使用
internal。
32.2.2. 命令行选项
像大多数服务器守护程序一样, inetd 有一些选项可以用来修改其行为。默认情况下,inetd 使用 -wW -C 60 启动。这些选项启用了所有服务的 TCP 包装器,包括内部服务,并防止任何 IP 地址在一分钟内请求超过 60 次的服务。
要更改传递给 inetd 的默认选项,请在 /etc/rc.conf 中添加一个 inetd_flags 条目。如果 inetd 已经在运行,请使用 service inetd restart 重新启动它。
可用的速率限制选项有:
- -c 最大值
-
指定每个服务的默认最大并发调用数,其中默认值为无限制。可以通过在 /etc/inetd.conf 中使用
max-child来对每个服务进行单独设置。 - -C 速率
-
指定单个 IP 地址每分钟可以调用服务的默认最大次数。可以通过在 /etc/inetd.conf 中使用
max-connections-per-ip-per-minute来覆盖每个服务的基础上。 - -R 速率
-
指定一个服务在一分钟内可以被调用的最大次数,其中默认值为
256。设置为0表示允许无限次调用。 - -s 最大值
-
指定单个 IP 地址在任何一次中可以调用服务的最大次数,其中默认值为无限。可以通过在 /etc/inetd.conf 中使用
max-child-per-ip来覆盖每个服务的基础设置。
还有其他选项可用。请参考 inetd(8) 获取完整的选项列表。
32.2.3. 安全考虑
许多可以由 inetd 管理的守护进程并不注重安全性。一些守护进程,比如 fingerd,可能提供对攻击者有用的信息。只启用所需的服务,并监控系统是否存在过多的连接尝试。可以使用 max-connections-per-ip-per-minute、max-child 和 max-child-per-ip 来限制此类攻击。
默认情况下,TCP 包装器是启用的。请参考 hosts_access(5) 了解如何在各种 inetd 调用的守护进程上设置 TCP 限制的更多信息。
32.3. 网络文件系统(NFS)
FreeBSD 支持网络文件系统(NFS),它允许服务器通过网络与客户端共享目录和文件。使用 NFS,用户和程序可以像访问本地存储的文件一样访问远程系统上的文件。
NFS 有许多实际用途。其中一些常见的用途包括:
-
在网络上,原本需要在每个客户端上重复的数据可以保存在一个单一的位置,并且可以被网络上的客户端访问。
-
多个客户端可能需要访问 /usr/ports/distfiles 目录。共享该目录可以快速访问源文件,而无需将它们下载到每个客户端。
-
在大型网络中,通常更方便地配置一个中央 NFS 服务器,用于存储所有用户的主目录。用户可以在网络中的任何客户端登录,并访问他们的主目录。
-
NFS 导出的管理变得更加简化。例如,只需要在一个文件系统中设置安全性或备份策略。
-
可移动媒体存储设备可以被网络上的其他机器使用。这减少了网络中设备的数量,并提供了一个集中管理安全性的位置。从集中安装媒体上安装软件到多台机器上通常更加方便。
NFS 由一个服务器和一个或多个客户端组成。客户端远程访问存储在服务器机器上的数据。为了使其正常运行,需要配置和运行一些进程。
这些守护进程必须在服务器上运行:
| 守护进程 | 描述 |
|---|---|
nfsd |
NFS 守护进程负责为 NFS 客户端提供服务。 |
mountd |
NFS 挂载守护进程负责处理从 nfsd 接收到的请求。 |
rpcbind |
该守护进程允许 NFS 客户端发现 NFS 服务器正在使用的端口。 |
在客户端上运行 nfsiod[8] 可以提高性能,但不是必需的。
32.3.1. 配置服务器
NFS 服务器将共享的文件系统在 /etc/exports 文件中指定。该文件中的每一行都指定了要导出的文件系统,客户端对该文件系统的访问权限以及任何访问选项。在向该文件添加条目时,每个导出的文件系统、其属性和允许的主机必须出现在同一行上。如果条目中没有列出客户端,则任何网络上的客户端都可以挂载该文件系统。
以下是示例的 /etc/exports 条目,演示了如何导出文件系统。这些示例可以根据读者网络上的文件系统和客户端名称进行修改。在此文件中可以使用许多选项,但这里只提到了一些。有关所有选项的完整列表,请参阅 exports(5) 。
这个示例展示了如何将 /cdrom 导出到名为 alpha、bravo 和 charlie 的三台主机:
/cdrom -ro alpha bravo charlie
-ro 标志使文件系统变为只读,防止客户端对导出的文件系统进行任何更改。此示例假设主机名要么在 DNS 中,要么在 /etc/hosts 文件中。如果网络没有 DNS 服务器,请参考 hosts(5)。
下面的示例通过 IP 地址将 /home 导出给三个客户端。这对于没有 DNS 或 /etc/hosts 条目的网络非常有用。 -alldirs 标志允许子目录作为挂载点。换句话说,它不会自动挂载子目录,但会允许客户端根据需要挂载所需的目录。
/usr/home -alldirs 10.0.0.2 10.0.0.3 10.0.0.4
下一个示例将 /a 导出,以便来自不同域的两个客户端可以访问该文件系统。-maproot=root 允许远程系统上的 root 用户以 root 身份在导出的文件系统上写入数据。如果未指定 -maproot=root ,客户端的 root 用户将被映射到服务器的 nobody 账户,并受到为 nobody 定义的访问限制的约束。
/a -maproot=root host.example.com box.example.org
每个文件系统只能指定一个客户端。例如,如果 /usr 是一个单独的文件系统,那么这些条目将是无效的,因为两个条目都指定了相同的主机:
# Invalid when /usr is one file system /usr/src client /usr/ports client
在这种情况下,正确的格式是使用一个条目:
/usr/src /usr/ports client
下面是一个有效的导出列表示例,其中 /usr 和 /exports 是本地文件系统:
# Export src and ports to client01 and client02, but only # client01 has root privileges on it /usr/src /usr/ports -maproot=root client01 /usr/src /usr/ports client02 # The client machines have root and can mount anywhere # on /exports. Anyone in the world can mount /exports/obj read-only /exports -alldirs -maproot=root client01 client02 /exports/obj -ro
要在启动时启用 NFS 服务器所需的进程,请将以下选项添加到 /etc/rc.conf 文件中:
rpcbind_enable="YES" nfs_server_enable="YES" mountd_enable="YES"
现在可以通过运行以下命令来启动服务器:
# service nfsd start每当 NFS 服务器启动时,mountd 也会自动启动。然而,mountd 只在启动时读取 /etc/exports 文件。为了使后续对 /etc/exports 文件的编辑立即生效,强制 mountd 重新读取它:
# service mountd reload请参考 nfsv4(4) 了解 NFS 版本 4 的设置描述。
32.3.2. 配置客户端
要启用 NFS 客户端,请在每个客户端的 /etc/rc.conf 文件中设置此选项:
nfs_client_enable="YES"
然后,在每个 NFS 客户端上运行以下命令:
# service nfsclient start客户端现在已经拥有了挂载远程文件系统所需的一切。在这些示例中,服务器的名称是 server,客户端的名称是 client。要将 server 上的 /home 挂载到 client 上的 /mnt 挂载点,可以执行以下操作:
# mount server:/home /mnt现在,位于 /home 目录中的文件和目录将在 client 上的 /mnt 目录中可用。
要在每次客户端启动时挂载远程文件系统,请将其添加到 /etc/fstab 文件中:
server:/home /mnt nfs rw 0 0
请参考 fstab(5),了解所有可用选项的描述。
32.3.3. 锁定
某些应用程序需要文件锁定才能正常运行。要启用锁定,请在客户端和服务器上执行以下命令:
# sysrc rpc_lockd_enable="YES"然后启动服务:
# service lockd start如果服务器上不需要锁定,可以在运行 mount 时包含 -L 来配置 NFS 客户端进行本地锁定。有关详细信息,请参阅 mount_nfs(8) 。
32.3.4. 使用 autofs(5) 自动挂载
autofs(5) 设施是几个组件的通用名称,这些组件一起允许在访问文件系统中的文件或目录时自动挂载远程和本地文件系统。它由内核组件 autofs(5) 和几个用户空间应用程序 automount(8)、automountd(8) 和 autounmountd(8) 组成。它作为先前的 FreeBSD 版本中 amd(8) 的替代品。amd 仍然提供向后兼容性,因为两者使用不同的映射格式;autofs 使用的映射格式与其他 SVR4 自动挂载程序(如 Solaris、MacOS X 和 Linux 中的自动挂载程序)相同。
autofs(5) 虚拟文件系统由 automount(8) 在指定的挂载点上挂载,通常在启动过程中调用。
每当一个进程尝试访问 autofs(5) 挂载点中的文件时,内核将通知 automountd(8) 守护进程并暂停触发进程。 automountd(8) 守护进程将通过查找正确的映射并根据其挂载文件系统来处理内核请求,然后向内核发出释放被阻塞进程的信号。 autounmountd(8) 守护进程会在一段时间后自动卸载自动挂载的文件系统,除非它们仍在使用中。
主要的 autofs 配置文件是 /etc/auto_master。它将各个映射分配给顶级挂载点。有关 auto_master 和映射语法的解释,请参考 auto_master(5) 。
在 /net 上挂载了一个特殊的自动挂载映射。当在该目录中访问文件时,autofs(5) 会查找相应的远程挂载并自动挂载它。例如,尝试访问 /net/foobar/usr 中的文件会告诉 automountd(8) 从主机 foobar 挂载 /usr 导出。
例 36. 使用 autofs(5) 挂载一个导出目录
在这个例子中,showmount -e 显示了可以从 NFS 服务器 foobar 挂载的导出文件系统。
% showmount -e foobar
Exports list on foobar:
/usr 10.10.10.0
/a 10.10.10.0
% cd /net/foobar/usrshowmount 命令的输出显示 /usr 目录被导出。当切换到 /host/foobar/usr 目录时, automountd(8) 会拦截请求并尝试解析主机名 foobar。如果成功,automountd(8) 会自动挂载源导出。
要在启动时启用 autofs(5),请将以下行添加到 /etc/rc.conf 中:
autofs_enable="YES"
然后可以通过运行 autofs(5) 来启动 autofs[5]。
# service automount start
# service automountd start
# service autounmountd startautofs(5) 映射格式与其他操作系统相同。来自其他来源的关于该格式的信息可能会很有用,比如 Mac OS X 文档 。
请参考 automount(8)、automountd(8)、autounmountd(8) 和 auto_master(5) 手册页面获取更多信息。
32.4. 网络信息系统(NIS)
网络信息系统(NIS)旨在集中管理类 UNIX® 系统,如 Solaris™、HP-UX、AIX®、Linux、NetBSD、OpenBSD 和 FreeBSD。NIS 最初被称为 Yellow Pages,但由于商标问题而更改了名称。这就是为什么 NIS 命令以 yp 开头的原因。
NIS 是一种基于远程过程调用(RPC)的客户端/服务器系统,允许 NIS 域内的一组机器共享一组公共的配置文件。这使得系统管理员可以仅使用最少的配置数据设置 NIS 客户端系统,并且可以从单一位置添加、删除或修改配置数据。
FreeBSD 使用 NIS 协议的第 2 版本。
32.4.1. NIS 术语和流程
表 28.1 总结了 NIS 使用的术语和重要过程。
| 术语 | 描述 |
|---|---|
NIS domain name |
NIS 服务器和客户端共享一个 NIS 域名。通常,这个域名与 DNS 无关。 |
此服务启用了 RPC ,并且必须在运行 NIS 服务器或充当 NIS 客户端时才能运行。 |
|
该服务将 NIS 客户端绑定到其 NIS 服务器。它将获取 NIS 域名并使用 RPC 连接到服务器。它是 NIS 环境中客户端/服务器通信的核心。如果客户端机器上没有运行此服务,将无法访问 NIS 服务器。 |
|
这是 NIS 服务器的进程。如果该服务停止运行,服务器将无法响应 NIS 请求,因此希望有一个从服务器接管。一些非 FreeBSD 客户端可能不会尝试使用从服务器重新连接,这些客户端可能需要重新启动 ypbind 进程。 |
|
这个进程只在 NIS 主服务器上运行。这个守护进程允许 NIS 客户端更改他们的 NIS 密码。如果这个守护进程没有运行,用户将不得不登录到 NIS 主服务器并在那里更改他们的密码。 |
32.4.2. 机器类型
在 NIS 环境中有三种类型的主机:
-
NIS 主服务器
该服务器充当主机配置信息的中央存储库,并维护所有 NIS 客户端使用的文件的权威副本。NIS 客户端使用的 passwd、group 和其他各种文件存储在主服务器上。虽然一个机器可以成为多个 NIS 域的 NIS 主服务器,但本章不涵盖这种类型的配置,因为它假设一个相对规模较小的 NIS 环境。
-
NIS 从服务器
NIS 从服务器维护 NIS 主服务器数据文件的副本,以提供冗余。从服务器还有助于平衡主服务器的负载,因为 NIS 客户端总是连接到首先响应的 NIS 服务器。
-
NIS 客户端
NIS 客户端在登录时对 NIS 服务器进行身份验证。
许多文件的信息可以通过 NIS 共享。master.passwd、group 和 hosts 文件通常通过 NIS 共享。每当客户端上的进程需要通常在这些文件中找到的信息时,它会向绑定的 NIS 服务器发出查询。
32.4.3. 规划考虑因素
本节描述了一个示例的 NIS 环境,该环境由 15 台 FreeBSD 机器组成,没有集中的管理点。每台机器都有自己的 /etc/passwd 和 /etc/master.passwd 文件。这些文件只能通过手动干预来保持同步。目前,当在实验室中添加用户时,这个过程必须在所有 15 台机器上重复执行。
实验室的配置如下:
| 机器名称 | IP 地址 | 机器角色 |
|---|---|---|
`` |
|
NIS 主服务器 |
|
|
NIS 从服务器 |
|
|
教职员工工作站 |
|
|
客户端机器 |
|
|
其他客户机 |
如果这是第一次开发 NIS 方案,应该提前进行彻底的规划。无论网络规模如何,规划过程中需要做出几个决策。
32.4.3.1. 选择一个 NIS 域名
当客户端广播其信息请求时,它会包含其所属的 NIS 域的名称。这就是在一个网络上多个服务器如何知道哪个服务器应该回答哪个请求的方式。将 NIS 域名视为一组主机的名称。
一些组织选择使用其互联网域名作为 NIS 域名。这并不推荐,因为在调试网络问题时可能会引起混淆。NIS 域名应在网络中是唯一的,并且如果能描述它所代表的机器组,那将会很有帮助。例如,Acme 公司的艺术部门可能在"acme-art"的 NIS 域中。本示例将使用域名 test-domain 。
然而,一些非 FreeBSD 操作系统要求 NIS 域名与互联网域名相同。如果网络中的一个或多个机器有此限制,则必须使用互联网域名作为 NIS 域名。
32.4.4. 配置 NIS 主服务器
所有 NIS 文件的规范副本存储在主服务器上。用于存储信息的数据库称为 NIS 映射。在 FreeBSD 中,这些映射存储在 /var/yp/[domainname] 中,其中 [domainname] 是 NIS 域的名称。由于支持多个域,因此可能会有多个目录,每个域一个目录。每个域都有自己独立的映射集。
NIS 主服务器和从服务器通过 ypserv(8) 处理所有 NIS 请求。该守护进程负责接收来自 NIS 客户端的传入请求,将请求的域和映射名称转换为相应数据库文件的路径,并将数据库中的数据传输回客户端。
根据环境需求,设置主 NIS 服务器可以相对简单。由于 FreeBSD 提供了内置的 NIS 支持,只需要通过将以下行添加到 /etc/rc.conf 来启用 NIS :
nisdomainname="test-domain" (1) nis_server_enable="YES" (2) nis_yppasswdd_enable="YES" (3)
| 1 | 这行代码将 NIS 域名设置为 test-domain。 <.> 这将在系统启动时自动启动 NIS 服务器进程。 <.> 这将启用 rpc.yppasswdd(8) 守护进程,以便用户可以从客户端机器上更改他们的 NIS 密码。 |
在一个多服务器域中,需要注意服务器机器也是 NIS 客户端的情况。通常最好强制服务器绑定到自己,而不是允许它们广播绑定请求并可能相互绑定。如果一个服务器崩溃,其他服务器依赖于它,可能会出现奇怪的故障模式。最终,所有客户端都会超时并尝试绑定到其他服务器,但涉及的延迟可能相当大,并且故障模式仍然存在,因为服务器可能会再次相互绑定。
一个既是服务器又是客户端的服务器可以通过在 /etc/rc.conf 中添加以下额外的行来强制绑定到特定的服务器:
nis_client_enable="YES" (1) nis_client_flags="-S test-domain,server" (2)
| 1 | 这样可以运行客户端的内容。 <.> 这行代码将 NIS 域名设置为 test-domain 并绑定到自身。 |
保存编辑后,输入 /etc/netstart 来重新启动网络并应用在 /etc/rc.conf 中定义的值。在初始化 NIS 映射之前,启动 ypserv(8):
# service ypserv start32.4.4.1. 初始化 NIS 映射
NIS 映射是从 NIS 主服务器上的配置文件 /etc 生成的,只有一个例外:/etc/master.passwd。这是为了防止密码传播到 NIS 域中的所有服务器。因此,在初始化 NIS 映射之前,请配置主密码文件:
# cp /etc/master.passwd /var/yp/master.passwd
# cd /var/yp
# vi master.passwd建议删除所有系统账户的条目,以及不需要传播到 NIS 客户端的任何用户账户,例如 root 和其他管理账户。
|
通过将 /var/yp/master.passwd 的权限设置为 |
完成此任务后,初始化 NIS 映射。FreeBSD 包含 ypinit(8) 脚本来完成此操作。在为主服务器生成映射时,包括 -m 选项并指定 NIS 域名:
ellington# ypinit -m test-domain
Server Type: MASTER Domain: test-domain
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If not, something might not work.
At this point, we have to construct a list of this domains YP servers.
rod.darktech.org is already known as master server.
Please continue to add any slave servers, one per line. When you are
done with the list, type a <control D>.
master server : ellington
next host to add: coltrane
next host to add: ^D
The current list of NIS servers looks like this:
ellington
coltrane
Is this correct? [y/n: y] y
[..output from map generation..]
NIS Map update completed.
ellington has been setup as an YP master server without any errors.这将从 /var/yp/Makefile.dist 创建 /var/yp/Makefile 。默认情况下,此文件假设环境中只有一个 NIS 服务器和仅有 FreeBSD 客户端。由于 test-domain 有一个从服务器,因此请编辑 /var/yp/Makefile 中的此行,使其以注释(#)开头:
NOPUSH = "True"
32.4.5. 设置一个 NIS 从服务器
要设置一个 NIS 从服务器,登录到从服务器并像主服务器一样编辑 /etc/rc.conf。不要生成任何 NIS 映射,因为这些映射已经存在于主服务器上。在从服务器上运行 ypinit 时,使用 -s(代表从服务器)而不是 -m (代表主服务器)。此选项除了域名外,还需要提供 NIS 主服务器的名称,如下例所示:
coltrane# ypinit -s ellington test-domain
Server Type: SLAVE Domain: test-domain Master: ellington
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If not, something might not work.
There will be no further questions. The remainder of the procedure
should take a few minutes, to copy the databases from ellington.
Transferring netgroup...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byuser...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byhost...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring group.bygid...
ypxfr: Exiting: Map successfully transferred
Transferring group.byname...
ypxfr: Exiting: Map successfully transferred
Transferring services.byname...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.byname...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.byname...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring netid.byname...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring ypservers...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byname...
ypxfr: Exiting: Map successfully transferred
coltrane has been setup as an YP slave server without any errors.
Remember to update map ypservers on ellington.这将在从服务器上生成一个名为 /var/yp/test-domain 的目录,其中包含 NIS 主服务器映射的副本。在每个从服务器上添加这些 /etc/crontab 条目将强制从服务器将其映射与主服务器上的映射同步:
20 * * * * root /usr/libexec/ypxfr passwd.byname 21 * * * * root /usr/libexec/ypxfr passwd.byuid
这些条目不是强制性的,因为主服务器会自动尝试将任何映射更改推送到从服务器。然而,由于客户端可能依赖从服务器提供正确的密码信息,建议强制频繁更新密码映射。这在繁忙的网络上尤为重要,因为映射更新可能并不总是完成。
要完成配置,请在从服务器上运行 /etc/netstart 以启动 NIS 服务。
32.4.6. 设置 NIS 客户端
一个 NIS 客户端使用 ypbind(8) 绑定到一个 NIS 服务器。这个守护进程在本地网络上广播 RPC 请求。这些请求指定了客户端上配置的域名。如果同一域中的一个 NIS 服务器接收到其中一个广播,它将回应 ypbind,并记录服务器的地址。如果有多个可用的服务器,客户端将使用第一个回应的服务器的地址,并将所有的 NIS 请求定向到该服务器。客户端会定期自动 ping 服务器,以确保它仍然可用。如果在合理的时间内未收到回复,ypbind 将标记该域为未绑定,并重新开始广播,希望找到另一个服务器。
要将 FreeBSD 机器配置为 NIS 客户端:
-
编辑 /etc/rc.conf 文件,并按照以下顺序添加以下行,以设置 NIS 域名并在网络启动时启动 ypbind(8):
nisdomainname="test-domain" nis_client_enable="YES"
-
要从 NIS 服务器导入所有可能的密码条目,请使用
vipw命令从 /etc/master.passwd 中删除除一个之外的所有用户账户。在删除账户时,请记住至少应保留一个本地账户,并且该账户应该是wheel组的成员。如果 NIS 出现问题,可以使用该本地账户远程登录,成为超级用户并修复问题。在保存编辑之前,请在文件末尾添加以下行:+:::::::::
这行配置将使客户端为 NIS 服务器密码映射中具有有效帐户的任何人在客户端上提供一个帐户。有许多方法可以通过修改这行来配置 NIS 客户端。其中一种方法在 使用 Netgroups 中有描述。如需更详细的阅读,请参考 O’Reilly Media 出版的
Managing NFS and NIS一书。 -
要从 NIS 服务器导入所有可能的组条目,请将以下行添加到 /etc/group 文件中:
+:*::
要立即启动 NIS 客户端,请以超级用户身份执行以下命令:
# /etc/netstart
# service ypbind start完成这些步骤后,在客户端上运行 ypcat passwd 应该显示服务器的 passwd 映射。
32.4.7. NIS 安全
由于 RPC 是基于广播的服务,因此在同一域中运行 ypbind 的任何系统都可以检索 NIS 映射的内容。为了防止未经授权的事务, ypserv(8) 支持一个名为"securenets"的功能,可以用来限制对给定一组主机的访问。默认情况下,此信息存储在 /var/yp/securenets 中,除非 ypserv(8) 使用 -p 和替代路径启动。该文件包含由空格分隔的网络规范和网络掩码组成的条目。以 ` "#" ` 开头的行被视为注释。一个示例的 securenets 可能如下所示:
# allow connections from local host -- mandatory 127.0.0.1 255.255.255.255 # allow connections from any host # on the 192.168.128.0 network 192.168.128.0 255.255.255.0 # allow connections from any host # between 10.0.0.0 to 10.0.15.255 # this includes the machines in the testlab 10.0.0.0 255.255.240.0
如果 ypserv(8) 接收到与这些规则匹配的地址的请求,它将正常处理该请求。如果地址未能匹配规则,请求将被忽略,并记录一条警告信息。如果 securenets 不存在,ypserv 将允许来自任何主机的连接。
TCP Wrapper 是一种替代的访问控制机制,用于提供对 securenets 的访问控制。虽然这两种访问控制机制都增加了一定的安全性,但它们都容易受到“IP 欺骗”攻击的影响。所有与 NIS 相关的流量都应该在防火墙上被阻止。
使用 securenets 的服务器可能无法为使用过时的 TCP/IP 实现的合法 NIS 客户端提供服务。其中一些实现在进行广播时将所有主机位设置为零,或者在计算广播地址时未观察子网掩码。虽然可以通过更改客户端配置来解决其中一些问题,但其他问题可能会迫使退役这些客户端系统或放弃 securenets。
使用 TCP Wrapper 会增加 NIS 服务器的延迟。额外的延迟可能足够长,以至于在繁忙的网络中,特别是在速度较慢的 NIS 服务器上,会导致客户端程序超时。如果一个或多个客户端受到延迟的影响,将这些客户端转换为 NIS 从服务器,并强制它们绑定到自己。
32.4.7.1. 禁止某些用户
在这个例子中,basie 系统是 NIS 域中的一个教职工工作站。主 NIS 服务器上的 passwd 映射包含了教职工和学生的账户。本节演示了如何允许教职工登录这个系统,同时拒绝学生登录。
为了防止指定的用户登录系统,即使他们在 NIS 数据库中存在,使用 vipw 在客户端的 /etc/master.passwd 末尾添加 -username,其中 username 是要禁止登录的用户的用户名,并且正确的冒号数量。被阻止用户的行必须在允许 NIS 用户的 + 行之前。在这个例子中,bill 被禁止登录到 basie。
basie# cat /etc/master.passwd
root:[password]:0:0::0:0:The super-user:/root:/bin/csh
toor:[password]:0:0::0:0:The other super-user:/root:/bin/sh
daemon:*:1:1::0:0:Owner of many system processes:/root:/usr/sbin/nologin
operator:*:2:5::0:0:System &:/:/usr/sbin/nologin
bin:*:3:7::0:0:Binaries Commands and Source,,,:/:/usr/sbin/nologin
tty:*:4:65533::0:0:Tty Sandbox:/:/usr/sbin/nologin
kmem:*:5:65533::0:0:KMem Sandbox:/:/usr/sbin/nologin
games:*:7:13::0:0:Games pseudo-user:/usr/games:/usr/sbin/nologin
news:*:8:8::0:0:News Subsystem:/:/usr/sbin/nologin
man:*:9:9::0:0:Mister Man Pages:/usr/share/man:/usr/sbin/nologin
bind:*:53:53::0:0:Bind Sandbox:/:/usr/sbin/nologin
uucp:*:66:66::0:0:UUCP pseudo-user:/var/spool/uucppublic:/usr/libexec/uucp/uucico
xten:*:67:67::0:0:X-10 daemon:/usr/local/xten:/usr/sbin/nologin
pop:*:68:6::0:0:Post Office Owner:/nonexistent:/usr/sbin/nologin
nobody:*:65534:65534::0:0:Unprivileged user:/nonexistent:/usr/sbin/nologin
-bill:::::::::
+:::::::::
basie#32.4.8. 使用 Netgroups
在较大的网络上,禁止特定用户登录到个别系统变得不可扩展,并且很快失去了 NIS 的主要优势:_集中化_管理。
Netgroups 是为处理具有数百个用户和机器的大型复杂网络而开发的。它们的使用类似于 UNIX® 组,主要区别在于缺乏数字 ID,并且可以通过包含用户账户和其他 netgroups 来定义 netgroup。
为了扩展本章中使用的示例,NIS 域将被扩展以添加表 28.2 和 28.3 中显示的用户和系统。
| 用户名 | 描述 |
|---|---|
|
IT 部门员工 |
|
IT 部门学徒 |
|
员工 |
|
实习生 |
| 机器名称 | 描述 |
|---|---|
|
只有 IT 员工才能登录这些服务器。 |
|
IT 部门的所有成员都被允许登录这些服务器。 |
|
员工使用的普通工作站。 |
|
一台非常老旧的机器,没有任何关键数据。甚至实习生都可以使用这个系统。 |
在使用 netgroups 配置这种情况时,每个用户都被分配到一个或多个 netgroups,并且登录权限会对 netgroup 的所有成员进行允许或禁止。当添加一个新的机器时,必须为所有 netgroups 定义登录限制。当添加一个新用户时,必须将该账户添加到一个或多个 netgroups 中。如果 NIS 设置得当,只需要修改一个中央配置文件就可以授予或拒绝对机器的访问权限。
第一步是初始化 NIS 的 netgroup 映射。在 FreeBSD 中,默认情况下不会创建此映射。在 NIS 主服务器上,使用编辑器创建一个名为 /var/yp/netgroup 的映射。
这个例子创建了四个网络组,分别代表 IT 员工、IT 学徒、员工和实习生:
IT_EMP (,alpha,test-domain) (,beta,test-domain)
IT_APP (,charlie,test-domain) (,delta,test-domain)
USERS (,echo,test-domain) (,foxtrott,test-domain) \
(,golf,test-domain)
INTERNS (,able,test-domain) (,baker,test-domain)
每个条目配置一个 netgroup。条目中的第一列是 netgroup 的名称。每对括号表示一个或多个用户的组或另一个 netgroup 的名称。在指定用户时,每个组内的三个逗号分隔字段表示:
-
表示用户有效的其他字段所在的主机名。如果未指定主机名,则条目在所有主机上有效。
-
属于此网络组的帐户的名称。
-
帐户的 NIS 域。可以将帐户从其他 NIS 域导入到网络组中。
如果一个组包含多个用户,请使用空格分隔每个用户。此外,每个字段可以包含通配符。有关详细信息,请参阅 netgroup(5)。
不应使用超过 8 个字符的 Netgroup 名称。这些名称区分大小写,使用大写字母作为 Netgroup 名称是区分用户、机器和 Netgroup 名称的简单方法。
一些非 FreeBSD 的 NIS 客户端无法处理包含超过 15 个条目的 netgroup。可以通过创建多个包含 15 个或更少用户的子 netgroup 以及一个由子 netgroup 组成的真正的 netgroup 来绕过此限制,如下面的示例所示:
BIGGRP1 (,joe1,domain) (,joe2,domain) (,joe3,domain) [...] BIGGRP2 (,joe16,domain) (,joe17,domain) [...] BIGGRP3 (,joe31,domain) (,joe32,domain) BIGGROUP BIGGRP1 BIGGRP2 BIGGRP3
如果单个网络组中存在超过 225 个(15 乘以 15)用户,请重复此过程。
要激活和分发新的 NIS 映射:
ellington# cd /var/yp
ellington# make这将生成三个 NIS 映射文件 netgroup、netgroup.byhost 和 netgroup.byuser。使用 ypcat(1) 的映射键选项来检查新的 NIS 映射文件是否可用:
ellington% ypcat -k netgroup
ellington% ypcat -k netgroup.byhost
ellington% ypcat -k netgroup.byuser第一个命令的输出应该类似于 /var/yp/netgroup 文件的内容。只有在创建了特定主机的 netgroup 时,第二个命令才会产生输出。第三个命令用于获取用户的 netgroup 列表。
要配置客户端,请使用 vipw(8) 来指定 netgroup 的名称。例如,在名为 war 的服务器上,替换这一行:
+:::::::::
with
+@IT_EMP:::::::::
这指定只有在 netgroup IT_EMP 中定义的用户将被导入到此系统的密码数据库中,并且只有这些用户被允许登录到此系统。
此配置也适用于 shell 的 ~ 函数和所有在用户名称和数字用户 ID 之间转换的例程。换句话说,cd ~user 将无法工作,ls -l 将显示数字 ID 而不是用户名,find . -user joe -print 将以 No such user 的消息失败。要解决此问题,导入所有用户条目时不允许它们登录到服务器。可以通过添加额外的一行来实现这一点:
+:::::::::/usr/sbin/nologin
这行配置将客户端配置为导入所有条目,但将这些条目中的 shell 替换为 /usr/sbin/nologin。
请确保在 +@IT_EMP::::::::: _之后_放置额外的空行。否则,从 NIS 导入的所有用户帐户将将 /usr/sbin/nologin 作为其登录 shell,而没有人将能够登录到系统。
要配置较不重要的服务器,请将服务器上的旧 +::::::::: 替换为以下行:
+@IT_EMP::::::::: +@IT_APP::::::::: +:::::::::/usr/sbin/nologin
工作站的相应行为:
+@IT_EMP::::::::: +@USERS::::::::: +:::::::::/usr/sbin/nologin
NIS 支持从其他 netgroups 创建 netgroups,这在用户访问策略发生变化时非常有用。一个可能的情况是创建基于角色的 netgroups。例如,可以创建一个名为 BIGSRV 的 netgroup 来定义重要服务器的登录限制,另一个名为 SMALLSRV 的 netgroup 用于不太重要的服务器,以及一个名为 USERBOX 的 netgroup 用于工作站。每个 netgroup 都包含被允许登录到这些机器上的 netgroups。NIS`netgroup` 映射的新条目如下所示:
BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS
当能够定义具有相同限制的机器组时,这种定义登录限制的方法运作得相当不错。不幸的是,这只是个例而不是规则。大多数情况下,需要能够按照每台机器的基础定义登录限制。
机器特定的网络组定义是处理策略变更的另一种可能性。在这种情况下,每个系统的 /etc/master.passwd 文件包含两行以"+"开头的内容。第一行添加了一个允许登录到该机器的帐户的网络组,第二行添加了所有其他帐户,并将其 shell 设置为 /usr/sbin/nologin。建议使用主机名的大写版本作为网络组的名称:
+@BOXNAME::::::::: +:::::::::/usr/sbin/nologin
一旦在所有机器上完成了这个任务,就不再需要再次修改本地版本的 /etc/master.passwd 文件了。所有后续的更改都可以通过修改 NIS 映射来处理。以下是一个可能的 netgroup 映射的示例:
# Define groups of users first IT_EMP (,alpha,test-domain) (,beta,test-domain) IT_APP (,charlie,test-domain) (,delta,test-domain) DEPT1 (,echo,test-domain) (,foxtrott,test-domain) DEPT2 (,golf,test-domain) (,hotel,test-domain) DEPT3 (,india,test-domain) (,juliet,test-domain) ITINTERN (,kilo,test-domain) (,lima,test-domain) D_INTERNS (,able,test-domain) (,baker,test-domain) # # Now, define some groups based on roles USERS DEPT1 DEPT2 DEPT3 BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS # # And a groups for a special tasks # Allow echo and golf to access our anti-virus-machine SECURITY IT_EMP (,echo,test-domain) (,golf,test-domain) # # machine-based netgroups # Our main servers WAR BIGSRV FAMINE BIGSRV # User india needs access to this server POLLUTION BIGSRV (,india,test-domain) # # This one is really important and needs more access restrictions DEATH IT_EMP # # The anti-virus-machine mentioned above ONE SECURITY # # Restrict a machine to a single user TWO (,hotel,test-domain) # [...more groups to follow]
并不总是建议使用基于机器的网络组。当部署几十个或几百个系统时,可以使用基于角色的网络组代替基于机器的网络组,以保持 NIS 映射的大小在合理范围内。
32.4.9. 密码格式
NIS 要求 NIS 域内的所有主机使用相同的密码加密格式。如果用户在 NIS 客户端上认证时遇到问题,可能是由于密码格式不同。在异构网络中,该格式必须由所有操作系统支持,其中 DES 是最低公共标准。
要检查服务器或客户端使用的格式,请查看 /etc/login.conf 文件的这个部分:
default:\ :passwd_format=des:\ :copyright=/etc/COPYRIGHT:\ [Further entries elided]
在这个例子中,系统使用 DES 格式进行密码哈希。其他可能的值包括 blf 表示 Blowfish,md5 表示 MD5,sha256 和 sha512 分别表示 SHA-256 和 SHA-512。要获取更多信息和系统上可用选项的最新列表,请参考 crypt(3) 手册页。
如果需要编辑主机上的格式以匹配在 NIS 域中使用的格式,则在保存更改后必须重新构建登录能力数据库。
# cap_mkdb /etc/login.conf|
在登录能力数据库重建之后,只有当每个用户在更改密码之后,现有用户账户的密码格式才会更新。 |
32.5. 轻量级目录访问协议(LDAP)
轻量级目录访问协议(LDAP)是一种应用层协议,用于访问、修改和认证使用分布式目录信息服务的对象。可以将其视为存储多个层次结构、同质信息的电话簿或记录簿。它在 Active Directory 和 OpenLDAP 网络中使用,并允许用户使用单个帐户访问多个层次的内部信息。例如,电子邮件认证、获取员工联系信息和内部网站认证可能都会使用 LDAP 服务器记录库中的单个用户帐户。
本节提供了在 FreeBSD 系统上配置 LDAP 服务器的快速入门指南。它假设管理员已经有了一个设计计划,其中包括要存储的信息类型,该信息将用于什么目的,哪些用户应该访问该信息,以及如何保护该信息免受未经授权的访问。
32.5.1. LDAP 术语和结构
在开始配置之前,需要了解 LDAP 使用的几个术语。所有目录条目由一组_属性_组成。每个属性集都包含一个称为_Distinguished Name_(DN)的唯一标识符,通常由其他属性(如常见的或_Relative Distinguished Name_ (RDN))构建而成。类似于目录具有绝对路径和相对路径,可以将 DN 视为绝对路径,将 RDN 视为相对路径。
一个示例 LDAP 条目如下所示。此示例搜索指定用户帐户(uid)、组织单位(ou)和组织(o)的条目:
% ldapsearch -xb "uid=trhodes,ou=users,o=example.com"
# extended LDIF
#
# LDAPv3
# base <uid=trhodes,ou=users,o=example.com> with scope subtree
# filter: (objectclass=*)
# requesting: ALL
#
# trhodes, users, example.com
dn: uid=trhodes,ou=users,o=example.com
mail: [email protected]
cn: Tom Rhodes
uid: trhodes
telephoneNumber: (123) 456-7890
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1这个示例条目显示了 dn、mail、cn、uid 和 telephoneNumber 属性的值。cn 属性是 RDN。
有关 LDAP 及其术语的更多信息,请访问 http://www.openldap.org/doc/admin24/intro.html。
32.5.2. 配置 LDAP 服务器
FreeBSD 没有提供内置的 LDAP 服务器。开始配置过程,需要安装 net/openldap-server 包或者使用 port 进行安装。
# pkg install openldap-server在 package 中启用了一组大量的默认选项。通过运行 pkg info openldap-server 来查看它们。如果它们不足够(例如需要 SQL 支持),请考虑使用适当的 framework 重新编译该 port。
安装过程会创建目录 /var/db/openldap-data 来存储数据。必须创建用于存储证书的目录:
# mkdir /usr/local/etc/openldap/private下一步是配置证书颁发机构。以下命令必须从 /usr/local/etc/openldap/private 目录下执行。这很重要,因为文件权限需要限制,并且用户不应该访问这些文件。有关证书及其参数的更详细信息,请参阅 OpenSSL。要创建证书颁发机构,请使用以下命令并按照提示进行操作:
# openssl req -days 365 -nodes -new -x509 -keyout ca.key -out ../ca.crt提示的条目可以是通用的,除了 Common Name 之外。这个条目必须与系统主机名_不同_。如果这将是一个自签名证书,请在主机名前加上 CA 表示证书颁发机构。
下一步是创建证书签名请求和私钥。输入以下命令并按照提示进行操作:
# openssl req -days 365 -nodes -new -keyout server.key -out server.csr在证书生成过程中,请确保正确设置 Common Name 属性。证书签名请求必须由证书颁发机构签名,才能用作有效证书。
# openssl x509 -req -days 365 -in server.csr -out ../server.crt -CA ../ca.crt -CAkey ca.key -CAcreateserial证书生成过程的最后一步是生成和签署客户端证书:
# openssl req -days 365 -nodes -new -keyout client.key -out client.csr
# openssl x509 -req -days 3650 -in client.csr -out ../client.crt -CA ../ca.crt -CAkey ca.key在提示时,请记得使用相同的 Common Name 属性。完成后,请确保通过前面的命令生成了总共八(8)个新文件。
运行 OpenLDAP 服务器的守护进程是 slapd。它的配置是通过 slapd.ldif 文件进行的:旧的 slapd.conf 已被 OpenLDAP 弃用。
配置示例 可以在 slapd.ldif 中找到,并且还可以在 /usr/local/etc/openldap/slapd.ldif.sample 中找到。选项在 slapd-config(5) 中有文档记录。slapd.ldif 的每个部分,就像所有其他 LDAP 属性集一样,都通过 DN 唯一标识。请确保在 dn: 语句和所需部分的末尾之间没有空行。在下面的示例中,将使用 TLS 来实现安全通道。第一部分表示全局配置:
# # See slapd-config(5) for details on configuration options. # This file should NOT be world readable. # dn: cn=config objectClass: olcGlobal cn: config # # # Define global ACLs to disable default read access. # olcArgsFile: /var/run/openldap/slapd.args olcPidFile: /var/run/openldap/slapd.pid olcTLSCertificateFile: /usr/local/etc/openldap/server.crt olcTLSCertificateKeyFile: /usr/local/etc/openldap/private/server.key olcTLSCACertificateFile: /usr/local/etc/openldap/ca.crt #olcTLSCipherSuite: HIGH olcTLSProtocolMin: 3.1 olcTLSVerifyClient: never
在这里必须指定证书颁发机构、服务器证书和服务器私钥文件。建议让客户端选择安全密码并省略选项 olcTLSCipherSuite (与除 openssl 之外的 TLS 客户端不兼容)。选项 olcTLSProtocolMin 允许服务器要求最低安全级别:建议使用。虽然服务器必须进行验证,但客户端不需要:olcTLSVerifyClient: never。
第二部分是关于后端模块的,可以按照以下方式进行配置:
# # Load dynamic backend modules: # dn: cn=module,cn=config objectClass: olcModuleList cn: module olcModulepath: /usr/local/libexec/openldap olcModuleload: back_mdb.la #olcModuleload: back_bdb.la #olcModuleload: back_hdb.la #olcModuleload: back_ldap.la #olcModuleload: back_passwd.la #olcModuleload: back_shell.la
第三部分专门用于加载数据库所需的 ldif 模式:它们是必不可少的。
dn: cn=schema,cn=config objectClass: olcSchemaConfig cn: schema include: file:///usr/local/etc/openldap/schema/core.ldif include: file:///usr/local/etc/openldap/schema/cosine.ldif include: file:///usr/local/etc/openldap/schema/inetorgperson.ldif include: file:///usr/local/etc/openldap/schema/nis.ldif
接下来是前端配置部分:
# Frontend settings
#
dn: olcDatabase={-1}frontend,cn=config
objectClass: olcDatabaseConfig
objectClass: olcFrontendConfig
olcDatabase: {-1}frontend
olcAccess: to * by * read
#
# Sample global access control policy:
# Root DSE: allow anyone to read it
# Subschema (sub)entry DSE: allow anyone to read it
# Other DSEs:
# Allow self write access
# Allow authenticated users read access
# Allow anonymous users to authenticate
#
#olcAccess: to dn.base="" by * read
#olcAccess: to dn.base="cn=Subschema" by * read
#olcAccess: to *
# by self write
# by users read
# by anonymous auth
#
# if no access controls are present, the default policy
# allows anyone and everyone to read anything but restricts
# updates to rootdn. (e.g., "access to * by * read")
#
# rootdn can always read and write EVERYTHING!
#
olcPasswordHash: {SSHA}
# {SSHA} is already the default for olcPasswordHash
另一个部分专门介绍了 配置后端,这是以全局超级用户的身份访问 OpenLDAP 服务器配置的唯一方式。
dn: olcDatabase={0}config,cn=config
objectClass: olcDatabaseConfig
olcDatabase: {0}config
olcAccess: to * by * none
olcRootPW: {SSHA}iae+lrQZILpiUdf16Z9KmDmSwT77Dj4U
默认管理员用户名是 cn=config。在 shell 中输入 slappasswd ,选择一个密码并使用其哈希值填写到 olcRootPW 中。如果在导入 slapd.ldif 之前没有指定此选项,将来将无法修改 全局配置 部分。
最后一节是关于数据库后端的内容:
#######################################################################
# LMDB database definitions
#######################################################################
#
dn: olcDatabase=mdb,cn=config
objectClass: olcDatabaseConfig
objectClass: olcMdbConfig
olcDatabase: mdb
olcDbMaxSize: 1073741824
olcSuffix: dc=domain,dc=example
olcRootDN: cn=mdbadmin,dc=domain,dc=example
# Cleartext passwords, especially for the rootdn, should
# be avoided. See slappasswd(8) and slapd-config(5) for details.
# Use of strong authentication encouraged.
olcRootPW: {SSHA}X2wHvIWDk6G76CQyCMS1vDCvtICWgn0+
# The database directory MUST exist prior to running slapd AND
# should only be accessible by the slapd and slap tools.
# Mode 700 recommended.
olcDbDirectory: /var/db/openldap-data
# Indices to maintain
olcDbIndex: objectClass eq
该数据库托管了 LDAP 目录的实际内容。除了 mdb 之外,还有其他类型可用。它的超级用户(与全局用户不同)在这里进行配置: olcRootDN 中是一个(可能是自定义的)用户名,olcRootPW 中是密码哈希值;可以像以前一样使用 slappasswd。
配置完成后,必须将 slapd.ldif 放置在一个空目录中。建议将其创建为:
# mkdir /usr/local/etc/openldap/slapd.d/导入配置数据库:
# /usr/local/sbin/slapadd -n0 -F /usr/local/etc/openldap/slapd.d/ -l /usr/local/etc/openldap/slapd.ldif启动 slapd 守护进程:
# /usr/local/libexec/slapd -F /usr/local/etc/openldap/slapd.d/可以使用选项 -d 进行调试,如在 slapd(8) 中所指定的那样。要验证服务器是否正在运行和工作:
# ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts
# extended LDIF
#
# LDAPv3
# base <> with scope baseObject
# filter: (objectclass=*)
# requesting: namingContexts
#
#
dn:
namingContexts: dc=domain,dc=example
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1服务器仍然必须是可信的。如果之前从未进行过此操作,请按照以下说明进行操作。安装 OpenSSL 软件包或 port:
# pkg install openssl从存储 ca.crt 的目录(在本例中为 /usr/local/etc/openldap)中运行:
# c_rehash .CA 证书和服务器证书现在在各自的角色中被正确识别。要验证这一点,请从 server.crt 目录中运行以下命令:
# openssl verify -verbose -CApath . server.crt如果 slapd 正在运行,请重新启动它。如 /usr/local/etc/rc.d/slapd 中所述,为了在启动时正确运行 slapd ,必须将以下行添加到 /etc/rc.conf:
slapd_enable="YES" slapd_flags='-h "ldapi://%2fvar%2frun%2fopenldap%2fldapi/ ldap://0.0.0.0/"' slapd_sockets="/var/run/openldap/ldapi" slapd_cn_config="YES"
slapd 在启动时不提供调试功能。请检查 /var/log/debug.log、dmesg -a 和 /var/log/messages 以进行调试。
以下示例将组 team 和用户 john 添加到仍为空的 domain.example LDAP 数据库中。首先,创建文件 domain.ldif:
# cat domain.ldif
dn: dc=domain,dc=example
objectClass: dcObject
objectClass: organization
o: domain.example
dc: domain
dn: ou=groups,dc=domain,dc=example
objectClass: top
objectClass: organizationalunit
ou: groups
dn: ou=users,dc=domain,dc=example
objectClass: top
objectClass: organizationalunit
ou: users
dn: cn=team,ou=groups,dc=domain,dc=example
objectClass: top
objectClass: posixGroup
cn: team
gidNumber: 10001
dn: uid=john,ou=users,dc=domain,dc=example
objectClass: top
objectClass: account
objectClass: posixAccount
objectClass: shadowAccount
cn: John McUser
uid: john
uidNumber: 10001
gidNumber: 10001
homeDirectory: /home/john/
loginShell: /usr/bin/bash
userPassword: secret请参阅 OpenLDAP 文档以获取更多详细信息。使用 slappasswd 将明文密码 secret 替换为 userPassword 中的哈希值。在允许 john 登录的所有系统中,指定的路径 loginShell 必须存在。最后,使用 mdb 管理员来修改数据库:
# ldapadd -W -D "cn=mdbadmin,dc=domain,dc=example" -f domain.ldif只有全局超级用户才能对 global configuration 部分进行修改。例如,假设最初指定了选项 olcTLSCipherSuite: HIGH:MEDIUM:SSLv3,现在必须删除该选项。首先,创建一个包含以下内容的文件:
# cat global_mod
dn: cn=config
changetype: modify
delete: olcTLSCipherSuite然后,应用修改:
# ldapmodify -f global_mod -x -D "cn=config" -W当被询问时,请提供在 configuration backend 部分选择的密码。用户名不是必需的:在这里,cn=config 表示要修改的数据库部分的 DN。或者,使用 ldapmodify 删除数据库的单行,ldapdelete 删除整个条目。
如果出现问题,或者全局超级用户无法访问配置后端,可以删除并重新编写整个配置:
# rm -rf /usr/local/etc/openldap/slapd.d/可以编辑并重新导入 slapd.ldif 文件。请在没有其他解决方案可用时才按照此步骤操作。
这仅是服务器的配置。同一台机器还可以托管一个 LDAP 客户端,具有独立的配置。
32.6. 动态主机配置协议(DHCP)
动态主机配置协议(DHCP)允许系统连接到网络,以便为在该网络上进行通信所需的寻址信息分配地址。FreeBSD 包含了 OpenBSD 版本的 dhclient,客户端使用它来获取寻址信息。FreeBSD 没有安装 DHCP 服务器,但在 FreeBSD Ports Collection 中提供了几个服务器可供选择。 DHCP 协议的完整描述可在 RFC 2131 中找到。还可以在 isc.org/downloads/dhcp/ 上找到相关的信息资源。
本节介绍了如何使用内置的 DHCP 客户端。然后介绍了如何安装和配置 DHCP 服务器。
|
在 FreeBSD 中,bpf(4) 设备同时被 DHCP 服务器和 DHCP 客户端所需。这个设备已经包含在 FreeBSD 安装的 GENERIC 内核中。如果用户选择创建自定义内核,并且使用 DHCP,需要保留这个设备。 需要注意的是,bpf 还允许特权用户在该系统上运行网络数据包嗅探器。 |
32.6.1. 配置 DHCP 客户端
FreeBSD 安装程序中包含了 DHCP 客户端支持,这使得配置新安装的系统从现有的 DHCP 服务器自动获取网络地址信息变得非常容易。有关网络配置的示例,请参考 帐户、时区、服务和加固。
当在客户端机器上执行 dhclient 命令时,它开始广播请求配置信息。默认情况下,这些请求使用 UDP 端口 68 。服务器在 UDP 端口 67 上回复,给客户端分配一个 IP 地址和其他相关的网络信息,如子网掩码、默认网关和 DNS 服务器地址。这些信息以 DHCP "租约"的形式存在,并且在可配置的时间内有效。这样可以自动重用不再连接到网络的客户端的过时 IP 地址。DHCP 客户端可以从服务器获取大量信息。详细列表可在 dhcp-options(5) 中找到。
默认情况下,当 FreeBSD 系统启动时,它的 DHCP 客户端在后台或异步运行。在 DHCP 过程完成时,其他启动脚本继续运行,从而加快了系统的启动速度。
后台 DHCP 在 DHCP 服务器快速响应客户端请求时运行良好。然而,在某些系统上,DHCP 可能需要很长时间才能完成。如果网络服务在 DHCP 分配网络地址信息之前尝试运行,它们将失败。使用同步模式的 DHCP 可以解决这个问题,因为它会暂停启动过程,直到 DHCP 配置完成。
这行代码在 /etc/rc.conf 文件中用于配置后台或异步模式:
ifconfig_fxp0="DHCP"
如果系统在安装过程中配置为使用 DHCP,则此行可能已经存在。在这些示例中,将 fxp0 替换为要动态配置的接口的名称,如 “设置网络接口卡” 中所述。
要配置系统使用同步模式,并在启动过程中暂停,直到 DHCP 完成,请使用"`SYNCDHCP`"。
ifconfig_fxp0="SYNCDHCP"
还有其他的客户端选项可用。在 rc.conf(5) 中搜索 dhclient 以获取详细信息。
DHCP 客户端使用以下文件:
-
/etc/dhclient.conf
dhclient使用的配置文件。通常,该文件只包含注释,因为默认设置适用于大多数客户端。该配置文件在 dhclient.conf(5) 中有详细描述。 -
/sbin/dhclient
有关该命令本身的更多信息可以在 dhclient(8) 中找到。
-
/sbin/dhclient-script
这是一个特定于 FreeBSD 的 DHCP 客户端配置脚本。它在 dhclient-script(8) 中有详细描述,但是通常不需要用户进行任何修改以正常运行。
-
/var/db/dhclient.leases.interface
DHCP 客户端在此文件中保留了一个有效租约的数据库,该文件被写入为日志,并在 dhclient.leases(5) 中进行了描述。
32.6.2. 安装和配置 DHCP 服务器
本节演示了如何使用 Internet Systems Consortium (ISC) 实现的 DHCP 服务器将 FreeBSD 系统配置为 DHCP 服务器。可以使用 net/isc-dhcp44-server 软件包或 port 安装此实现及其文档。
net/isc-dhcp44-server 将安装一个示例配置文件。将 /usr/local/etc/dhcpd.conf.example 复制到 /usr/local/etc/dhcpd.conf,并对这个新文件进行任何编辑。
配置文件由子网和主机的声明组成,这些声明定义了提供给 DHCP 客户端的信息。例如,以下行配置了以下内容:
option domain-name "example.org";(1)
option domain-name-servers ns1.example.org;(2)
option subnet-mask 255.255.255.0;(3)
default-lease-time 600;(4)
max-lease-time 72400;(5)
ddns-update-style none;(6)
subnet 10.254.239.0 netmask 255.255.255.224 {
range 10.254.239.10 10.254.239.20;(7)
option routers rtr-239-0-1.example.org, rtr-239-0-2.example.org;(8)
}
host fantasia {
hardware ethernet 08:00:07:26:c0:a5;(9)
fixed-address fantasia.fugue.com;(10)
}
| 1 | 此选项指定将提供给客户端的默认搜索域。有关更多信息,请参阅 resolv.conf(5)。 <.> 此选项指定客户端应使用的逗号分隔的 DNS 服务器列表。它们可以按照完全限定域名(FQDN)列出,如示例中所示,也可以按照它们的 IP 地址列出。 <.> 提供给客户端的子网掩码。 <.> 默认租约到期时间(以秒为单位)。客户端可以配置为覆盖此值。 <.> 租约的最大允许时间长度(以秒为单位)。如果客户端请求更长的租约,租约仍将发放,但仅在 max-lease-time 内有效。 <.> none 的默认值禁用动态 DNS 更新。将其更改为 interim 会配置 DHCP 服务器在发放租约时更新 DNS 服务器,以便 DNS 服务器知道哪些 IP 地址与网络中的哪些计算机相关联。除非已配置 DNS 服务器支持动态 DNS,否则不要更改默认设置。 <.> 此行创建一个可用 IP 地址池,用于分配给 DHCP 客户端。地址范围必须对先前行中指定的网络或子网有效。 <.> 声明对于在开放的 { 括号之前指定的网络或子网有效的默认网关。 <.> 指定客户端的硬件 MAC 地址,以便 DHCP 服务器在其发出请求时能够识别客户端。 <.> 指定此主机始终应获得相同的 IP 地址。使用主机名是正确的,因为 DHCP 服务器将在返回租约信息之前解析主机名。 |
此配置文件支持更多选项。有关详细信息和示例,请参阅与服务器一起安装的 dhcpd.conf(5)。
完成 dhcpd.conf 的配置后,在 /etc/rc.conf 中启用 DHCP 服务器:
dhcpd_enable="YES" dhcpd_ifaces="dc0"
将 dc0 替换为 DHCP 服务器应该监听 DHCP 客户端请求的接口(或接口,用空格分隔)。
通过执行以下命令启动服务器:
# service isc-dhcpd start对服务器配置的任何未来更改都需要停止 dhcpd 服务,然后使用 service(8) 启动。
DHCP 服务器使用以下文件。请注意,手册页面已与服务器软件一起安装。
-
/usr/local/sbin/dhcpd
有关 dhcpd 服务器的更多信息可以在 dhcpd(8) 中找到。
-
/usr/local/etc/dhcpd.conf
服务器配置文件需要包含所有应提供给客户端的信息,以及有关服务器操作的信息。此配置文件在 dhcpd.conf(5) 中有详细描述。
-
/var/db/dhcpd.leases
DHCP 服务器将其发放的租约记录在此文件中,该文件被写入为日志。请参考 dhcpd.leases(5),其中提供了稍长一些的描述。
-
/usr/local/sbin/dhcrelay
这个守护进程用于高级环境中,其中一个 DHCP 服务器将客户端的请求转发到另一个位于不同网络上的 DHCP 服务器。如果需要这个功能,请安装 net/isc-dhcp44-relay 包或 port。安装包括了提供更多详细信息的 dhcrelay(8)。
32.7. 域名系统(DNS)
域名系统(DNS)是一种将域名映射到 IP 地址,反之亦然的协议。DNS 通过一个相对复杂的系统来协调互联网上的域名,包括权威根域名服务器、顶级域名(TLD)和其他规模较小的名称服务器,这些服务器托管和缓存各个域名的信息。在系统上执行 DNS 查找时,不需要运行名称服务器。
下表描述了与 DNS 相关的一些术语:
| 术语 | 定义 |
|---|---|
正向(Forward) DNS |
主机名到 IP 地址的映射。 |
起源(Origin) |
指的是特定区域文件中涵盖的域名。 |
解析器(Resolver) |
系统进程通过向名称服务器查询区域信息的方式进行。 |
反向(Reverse) DNS |
IP 地址到主机名的映射。 |
根区(Root zone) |
互联网区域层次结构的起始点。所有区域都属于根区域,类似于文件系统中所有文件都属于根目录。 |
区域(Zone) |
由同一管理机构管理的个人域、子域或 DNS 的一部分。 |
区域的示例:
-
.通常在文档中用来指代根区域。 -
org.是根域下的顶级域名(TLD)。 -
example.org.是org.顶级域名下的一个区域。 -
1.168.192.in-addr.arpa是一个区域,引用了所有属于 `192.168.1.*`IP 地址空间的 IP 地址。
正如我们所看到的,主机名的更具体部分出现在其左侧。例如,example.org. 比 org. 更具体,而 org. 比根域更具体。主机名的每个部分的布局很像文件系统: /dev 目录位于根目录下,依此类推。
32.7.1. 运行名称服务器的原因
名称服务器通常有两种形式:权威名称服务器和缓存(也称为解析)名称服务器。
当需要一个权威名称服务器时:
-
一个想要向世界提供 DNS 信息,并对查询进行权威回复的服务。
-
一个域名,比如
example.org,已经注册,需要为其下的主机名分配 IP 地址。 -
一个 IP 地址块需要反向 DNS 条目( IP 到主机名)。
-
备份或第二名称服务器,称为从服务器,将回复查询。
当需要缓存名称服务器时:
-
本地 DNS 服务器可能比查询外部名称服务器更快地缓存和响应。
当查询 www.FreeBSD.org 时,解析器通常会查询上行 ISP 的名称服务器,并检索回复。使用本地缓存的 DNS 服务器,查询只需由缓存的 DNS 服务器向外部世界发起一次。由于信息被本地缓存,额外的查询将不需要离开本地网络。
32.7.2. DNS 服务器配置
Unbound 在 FreeBSD 基本系统中提供。默认情况下,它只为本地机器提供 DNS 解析。虽然基本系统包可以配置为提供超出本地机器的解析服务,但建议通过从 FreeBSD Ports Collection 安装 Unbound 来满足此类需求。
要启用 Unbound ,请将以下内容添加到 /etc/rc.conf 文件中:
local_unbound_enable="YES"
在新的 Unbound 配置中,任何已存在的名字服务器在 /etc/resolv.conf 文件中将被配置为转发器。
|
如果列出的任何一个名称服务器不支持 DNSSEC,本地 DNS 解析将失败。请确保测试每个名称服务器并删除测试失败的名称服务器。以下命令将显示运行在 |
一旦确认每个域名服务器都支持 DNSSEC,启动 Unbound :
# service local_unbound onestart这将负责更新 /etc/resolv.conf 以便查询 DNSSEC 安全域名能够正常工作。例如,运行以下命令来验证 FreeBSD.org 的 DNSSEC 信任树:
% drill -S FreeBSD.org
;; Number of trusted keys: 1
;; Chasing: freebsd.org. A
DNSSEC Trust tree:
freebsd.org. (A)
|---freebsd.org. (DNSKEY keytag: 36786 alg: 8 flags: 256)
|---freebsd.org. (DNSKEY keytag: 32659 alg: 8 flags: 257)
|---freebsd.org. (DS keytag: 32659 digest type: 2)
|---org. (DNSKEY keytag: 49587 alg: 7 flags: 256)
|---org. (DNSKEY keytag: 9795 alg: 7 flags: 257)
|---org. (DNSKEY keytag: 21366 alg: 7 flags: 257)
|---org. (DS keytag: 21366 digest type: 1)
| |---. (DNSKEY keytag: 40926 alg: 8 flags: 256)
| |---. (DNSKEY keytag: 19036 alg: 8 flags: 257)
|---org. (DS keytag: 21366 digest type: 2)
|---. (DNSKEY keytag: 40926 alg: 8 flags: 256)
|---. (DNSKEY keytag: 19036 alg: 8 flags: 257)
;; Chase successful32.7.3. 权威名称服务器配置
FreeBSD 在基本系统中不提供权威名称服务器软件。鼓励用户安装第三方应用程序,如 dns/nsd 或 dns/bind918 包或 port。
32.8. Apache HTTP Server 是一个开源的 Web 服务器软件,它是目前最流行的 Web 服务器之一。它由 Apache 软件基金会开发和维护,可运行在多种操作系统上,包括 Windows、Linux 和 Unix 等。 Apache HTTP Server 具有高度可扩展性和灵活性,支持多种模块和插件,可以实现各种功能,如动态内容生成、虚拟主机配置和安全性控制等。它还提供了丰富的文档和社区支持,使得用户能够轻松地学习和使用。无论是个人网站还是大型企业应用,Apache HTTP Server 都是一个可靠和强大的选择。
开源的 Apache HTTP 服务器是最广泛使用的 Web 服务器。FreeBSD 默认不安装这个 Web 服务器,但可以通过包 :www/apache24[] 包或 port 进行安装。
本节概述了如何在 FreeBSD 上配置和启动 Apache HTTP Server 的 2.x 版本。有关 Apache 2.X 及其配置指令的更详细信息,请参阅 httpd.apache.org。
32.8.1. 配置和启动 Apache
在 FreeBSD 中,主要的 Apache HTTP 服务器配置文件被安装在 /usr/local/etc/apache2x/httpd.conf,其中 x 代表版本号。这个 ASCII 文本文件以 # 开头的行作为注释。最经常修改的指令有:
ServerRoot "/usr/local"-
指定 Apache 安装的默认目录层次结构。二进制文件存储在服务器根目录的 bin 和 sbin 子目录中,配置文件存储在 etc/apache2x 子目录中。
ServerAdmin [email protected]-
将此更改为接收服务器问题的电子邮件地址。此地址还会出现在一些由服务器生成的页面上,例如错误文档。
ServerName www.example.com:80-
允许管理员设置一个主机名,该主机名将发送给服务器的客户端。例如,可以使用
www代替实际的主机名。如果系统没有注册的 DNS 名称,请输入其 IP 地址。如果服务器将监听一个替代端口,请将80更改为替代端口号。 DocumentRoot "/usr/local/www/apache2_x_/data"-
文档将被提供的目录。默认情况下,所有请求都从此目录获取,但可以使用符号链接和别名指向其他位置。
在进行更改之前,始终将默认的 Apache 配置文件备份是一个好主意。当 Apache 的配置完成后,保存文件并使用 apachectl 验证配置。运行 apachectl configtest 应该返回 Syntax OK。
要在系统启动时启动 Apache,请将以下行添加到 /etc/rc.conf 文件中:
apache24_enable="YES"
如果要使用非默认选项启动 Apache,则可以将以下行添加到 /etc/rc.conf 以指定所需的标志:
apache24_flags=""
如果 apachectl 没有报告配置错误,请立即启动 httpd :
# service apache24 start可以通过在 Web 浏览器中输入 http://localhost 来测试 httpd 服务,将 localhost 替换为运行 httpd 的机器的完全限定域名。显示的默认网页是 /usr/local/www/apache24/data/index.html。
在 httpd 运行时,可以使用以下命令测试 Apache 配置是否存在错误:
# service apache24 configtest|
需要注意的是, |
32.8.2. 虚拟主机
虚拟主机允许多个网站在一个 Apache 服务器上运行。虚拟主机可以是基于 IP 的或基于名称的。基于 IP 的虚拟主机为每个网站使用不同的 IP 地址。基于名称的虚拟主机使用客户端的 HTTP/1.1 头部来确定主机名,这样可以让多个网站共享同一个 IP 地址。
要设置 Apache 使用基于名称的虚拟主机,为每个网站添加一个 VirtualHost 块。例如,对于名为 www.domain.tld 的 Web 服务器,其虚拟域为 www.someotherdomain.tld,请将以下条目添加到 httpd.conf 文件中:
<VirtualHost *>
ServerName www.domain.tld
DocumentRoot /www/domain.tld
</VirtualHost>
<VirtualHost *>
ServerName www.someotherdomain.tld
DocumentRoot /www/someotherdomain.tld
</VirtualHost>
对于每个虚拟主机,请将 ServerName 和 DocumentRoot 的值替换为要使用的值。
有关设置虚拟主机的更多信息,请参阅官方 Apache 文档:http://httpd.apache.org/docs/vhosts/[http://httpd.apache.org/docs/vhosts/]。
32.8.3. Apache 模块
Apache 使用模块来增强基本服务器提供的功能。请参考 http://httpd.apache.org/docs/current/mod/,了解可用模块的完整列表和配置细节。
在 FreeBSD 中,一些模块可以使用 www/apache24 port 进行编译。在 /usr/ports/www/apache24 目录下输入 make config 命令可以查看可用的模块以及默认启用的模块。如果模块没有与端口一起编译,FreeBSD Ports Collection 提供了一种简单的方法来安装许多模块。本节介绍了三个最常用的模块。
32.8.3.1. SSL 支持
在某个时间点上,Apache 中支持 SSL 需要一个名为 mod_ssl 的辅助模块。但现在情况已经改变,Apache 的默认安装中已经内置了 SSL 功能。在安装的文件中有一个示例,可以了解如何启用 SSL 网站支持,该文件位于 /usr/local/etc/apache24/extra 目录下的 httpd-ssl.conf 文件中。在这个目录中还有一个名为 ssl.conf-sample 的示例文件。建议同时评估这两个文件,以正确设置 Apache Web 服务器中的安全网站。
在 SSL 配置完成后,必须取消注释主要的 http.conf 文件中的以下行,以便在下次重新启动或重新加载 Apache 时激活更改:
#Include etc/apache24/extra/httpd-ssl.conf
|
SSL 版本 2 和版本 3 存在已知的漏洞问题。强烈建议在旧的 SSL 选项之外启用 TLS 版本 1.2 和 1.3。可以通过在 ssl.conf 中设置以下选项来实现: |
SSLProtocol all -SSLv3 -SSLv2 +TLSv1.2 +TLSv1.3 SSLProxyProtocol all -SSLv2 -SSLv3 -TLSv1 -TLSv1.1
为了完成 Web 服务器中 SSL 的配置,请取消以下行的注释,以确保在重新启动或重新加载期间将配置拉入 Apache 中:
# Secure (SSL/TLS) connections Include etc/apache24/extra/httpd-ssl.conf
在 httpd.conf 文件中,还必须取消以下行的注释,以完全支持 Apache 中的 SSL:
LoadModule authn_socache_module libexec/apache24/mod_authn_socache.so LoadModule socache_shmcb_module libexec/apache24/mod_socache_shmcb.so LoadModule ssl_module libexec/apache24/mod_ssl.so
下一步是与证书颁发机构合作,在系统上安装适当的证书。这将为网站建立一个信任链,防止出现自签名证书的警告。
32.8.3.2. mod_perl
mod_perl 模块使得可以用 Perl 编写 Apache 模块。此外,嵌入在服务器中的持久解释器避免了启动外部解释器的开销和 Perl 启动时间的惩罚。
可以使用 www/mod_perl2 包或 port 安装 mod_perl。有关使用此模块的文档可以在 http://perl.apache.org/docs/2.0/index.html 找到。
32.8.3.3. mod_php
PHP: Hypertext Preprocessor(PHP)是一种通用的脚本语言,特别适用于网页开发。它可以嵌入到 HTML 中,其语法借鉴了 C、Java™ 和 Perl,旨在让网页开发人员能够快速编写动态生成的网页。
通过安装适当的端口,可以为 Apache 和任何其他用 PHP 编写的功能添加支持。
对于所有支持的版本,请使用 pkg 搜索软件包数据库:
# pkg search php将显示一个列表,其中包括版本和它们提供的附加功能。这些组件是完全模块化的,这意味着通过安装适当的端口来启用功能。要为 Apache 安装 PHP 7.4 版本,请执行以下命令:
# pkg install mod_php74如果需要安装任何依赖包,它们也将被安装。
默认情况下,PHP 将不会被启用。要使其生效,需要将以下行添加到位于 /usr/local/etc/apache24 目录中的 Apache 配置文件中:
<FilesMatch "\.php$">
SetHandler application/x-httpd-php
</FilesMatch>
<FilesMatch "\.phps$">
SetHandler application/x-httpd-php-source
</FilesMatch>
此外,配置文件中的 DirectoryIndex 也需要更新,并且需要重新启动或重新加载 Apache 才能使更改生效。
使用 pkg 也可以安装许多 PHP 功能的支持。例如,要安装 XML 或 SSL 的支持,请安装它们各自的 port:
# pkg install php74-xml php74-openssl与之前一样,即使只是安装了一个模块,也需要重新加载 Apache 配置文件才能使更改生效。
要执行优雅重启以重新加载配置,请执行以下命令:
# apachectl graceful安装完成后,有两种方法可以获取已安装的 PHP 支持模块和构建的环境信息。第一种方法是安装完整的 PHP 二进制文件,并运行命令来获取信息:
# pkg install php74# php -i |less需要将输出传递给一个分页器,比如 more 或 less,以便更容易地处理大量的输出。
最后,要对 PHP 的全局配置进行任何更改,需要使用一个文档完善的文件,安装在 /usr/local/etc/php.ini。在安装时,该文件不存在,因为有两个版本可供选择,一个是 php.ini-development,另一个是 php.ini-production。这些是管理员在部署过程中的起点。
32.8.3.4. HTTP2 支持
在使用 pkg 安装 port 时,默认情况下,Apache 支持 HTTP2 协议。新版本的 HTTP 相比之前的版本有很多改进,包括利用单个连接访问网站,减少 TCP 连接的总往返次数。此外,数据包头部数据被压缩,HTTP2 默认要求加密。
当 Apache 配置为仅使用 HTTP2 时,Web 浏览器将需要安全的、加密的 HTTPS 连接。当 Apache 配置为同时使用两个版本时,如果在连接过程中出现任何问题,HTTP1.1 将被视为备选选项。
虽然这个变化确实需要管理员进行一些改动,但这些改动是积极的,并且对于每个人来说都意味着一个更安全的互联网。这些改动只需要对目前没有实施 SSL 和 TLS 的网站进行。
|
此配置依赖于前面的部分,包括 TLS 支持。建议在继续进行此配置之前按照那些说明进行操作。 |
通过取消注释 /usr/local/etc/apache24/httpd.conf 中的一行来启用 http2 模块,并将 mpm_prefork 模块替换为 mpm_event 模块,因为前者不支持 HTTP2。
LoadModule http2_module libexec/apache24/mod_http2.so LoadModule mpm_event_module libexec/apache24/mod_mpm_event.so
|
有一个单独的 mod_http2 port 可用。它的存在是为了更快地提供安全性和错误修复,而不是使用捆绑的 apache24 port 安装的模块。它不是必需的 HTTP2 支持,但可供选择。安装后,应在 Apache 配置中使用 mod_h2.so 替代 mod_http2.so。 |
在 Apache 中实现 HTTP2 有两种方法;一种是全局应用于所有站点和系统上运行的每个 VirtualHost。要在全局启用 HTTP2,请在 ServerName 指令下添加以下行:
Protocols h2 http/1.1
|
要在明文上启用 HTTP2,请在 httpd.conf 中使用 h2h2chttp/1.1。 |
在这里使用 h2c 将允许明文的 HTTP2 数据在系统中传递,但不推荐这样做。此外,在这里使用 http/1.1 将允许系统在需要时回退到 HTTP1.1 版本的协议。
要为单个虚拟主机启用 HTTP2,请在 httpd.conf 或 httpd-ssl.conf 中的 VirtualHost 指令中添加相同的行。
使用 apachectlreload 命令重新加载配置,并在访问托管页面之后使用以下任一方法测试配置:
# grep "HTTP/2.0" /var/log/httpd-access.log这应该返回类似以下的内容:
192.168.1.205 - - [18/Oct/2020:18:34:36 -0400] "GET / HTTP/2.0" 304 - 192.0.2.205 - - [18/Oct/2020:19:19:57 -0400] "GET / HTTP/2.0" 304 - 192.0.0.205 - - [18/Oct/2020:19:20:52 -0400] "GET / HTTP/2.0" 304 - 192.0.2.205 - - [18/Oct/2020:19:23:10 -0400] "GET / HTTP/2.0" 304 -
另一种方法是使用网页浏览器内置的站点调试器或 tcpdump;然而,使用任何一种方法都超出了本文档的范围。
通过使用 mod_proxy_http2.so 模块支持 HTTP2 反向代理连接。在配置 ProxyPass 或 RewriteRules [P] 语句时,应使用 h2:// 作为连接。
32.8.4. 动态网站
除了 mod_perl 和 mod_php 之外,还有其他语言可用于创建动态网页内容。这些包括 Django 和 Ruby on Rails。
32.8.4.1. Django
Django 是一个 BSD 许可的框架,旨在让开发人员快速编写高性能、优雅的 Web 应用程序。它提供了一个对象关系映射器,使得数据类型可以作为 Python 对象进行开发。它还提供了一个丰富的动态数据库访问 API,开发人员无需编写 SQL 语句即可对这些对象进行操作。此外,它还提供了一个可扩展的模板系统,使得应用程序的逻辑与 HTML 的呈现分离。
Django 依赖于 mod_python 和一个 SQL 数据库引擎。在 FreeBSD 中,包 www/py-django 的端口会自动安装 mod_python,并支持 PostgreSQL、MySQL 或 SQLite 数据库,默认为 SQLite。要更改数据库引擎,请在 /usr/ports/www/py-django 目录下输入 make config,然后安装 port。
一旦安装了 Django,应用程序将需要一个项目目录以及 Apache 配置,以便使用嵌入式 Python 解释器。该解释器用于调用站点上特定 URL 的应用程序。
要配置 Apache 将某些 URL 的请求传递给 Web 应用程序,请将以下内容添加到 httpd.conf,并指定项目目录的完整路径:
<Location "/">
SetHandler python-program
PythonPath "['/dir/to/the/django/packages/'] + sys.path"
PythonHandler django.core.handlers.modpython
SetEnv DJANGO_SETTINGS_MODULE mysite.settings
PythonAutoReload On
PythonDebug On
</Location>
请参考 https://docs.djangoproject.com 获取有关如何使用 Django 的更多信息。
32.8.4.2. Ruby on Rails
Ruby on Rails 是另一个开源的 Web 框架,提供了完整的开发堆栈。它经过优化,可以使 Web 开发人员更加高效和能够快速编写强大的应用程序。在 FreeBSD 上,可以使用 www/rubygem-rails 包或 port 进行安装。
请参考 http://guides.rubyonrails.org,了解如何使用 Ruby on Rails 的更多信息。
32.9. 文件传输协议(FTP)
文件传输协议(FTP)为用户提供了一种简单的方式来在 FTP 服务器之间传输文件。FreeBSD 在基本系统中包含了 FTP 服务器软件 ftpd。
FreeBSD 提供了几个配置文件来控制对 FTP 服务器的访问。本节概述了这些文件。有关内置 FTP 服务器的更多详细信息,请参阅 ftpd(8)。
32.9.1. 配置
最重要的配置步骤是决定哪些账户将被允许访问 FTP 服务器。FreeBSD 系统有许多系统账户,不应该允许 FTP 访问。不允许任何 FTP 访问的用户列表可以在 /etc/ftpusers 中找到。默认情况下,它包括系统账户。可以添加其他不允许访问 FTP 的用户。
在某些情况下,可能希望限制某些用户的访问权限,而不完全阻止他们使用 FTP。可以通过创建 /etc/ftpchroot 文件来实现,如 ftpchroot(5) 中所述。该文件列出了受 FTP 访问限制的用户和组。
要启用服务器的匿名 FTP 访问,请在 FreeBSD 系统上创建一个名为 ftp 的用户。然后用户将能够使用用户名 ftp 或 anonymous 登录到 FTP 服务器。当提示输入密码时,任何输入都将被接受,但按照惯例,应将电子邮件地址用作密码。当匿名用户登录时,FTP 服务器将调用 chroot(2) 来限制访问仅限于 ftp 用户的主目录。
有两个文本文件可以创建,用于指定要显示给 FTP 客户端的欢迎消息。/etc/ftpwelcome 的内容将在用户到达登录提示之前显示给他们。成功登录后,将显示 /etc/ftpmotd 的内容。请注意,该文件的路径是相对于登录环境的,因此对于匿名用户,将显示 ~ftp/etc/ftpmotd 的内容。
一旦配置了 FTP 服务器,将适当的变量设置在 /etc/rc.conf 中,以便在启动时启动该服务:
ftpd_enable="YES"
立即启动服务:
# service ftpd start通过输入以下命令来测试与 FTP 服务器的连接:
% ftp localhostftpd 守护进程使用 syslog(3) 来记录日志消息。默认情况下,系统日志守护进程将会将与 FTP 相关的消息写入到 /var/log/xferlog 文件中。FTP 日志的位置可以通过修改 /etc/syslog.conf 文件中的以下行来进行更改:
ftp.info /var/log/xferlog
|
注意运行匿名 FTP 服务器可能涉及的潜在问题。特别是,要三思而后行,是否允许匿名用户上传文件。可能会发现 FTP 站点成为非授权商业软件交易或更糟糕的场所。如果需要匿名 FTP 上传,则要验证权限,以便这些文件在被管理员审核之前不能被其他匿名用户读取。 |
32.10. 适用于 Microsoft® Windows® 客户端的文件和打印服务(Samba)
Samba 是一个流行的开源软件包,使用 SMB/CIFS 协议提供文件和打印服务。该协议内置于 Microsoft® Windows® 系统中。通过安装 Samba 客户端库,它可以添加到非 Microsoft® Windows® 系统中。该协议允许客户端访问共享的数据和打印机。这些共享可以映射为本地磁盘驱动器,共享的打印机可以像本地打印机一样使用。
在 FreeBSD 上,可以使用 net/samba413 端口或 port 来安装 Samba 客户端库。该客户端提供了 FreeBSD 系统访问 Microsoft® Windows® 网络中的 SMB/CIFS 共享的能力。
通过安装相同的 net/samba413 包或 port, FreeBSD 系统也可以配置为 Samba 服务器。这使得管理员可以在 FreeBSD 系统上创建 SMB/CIFS 共享,这些共享可以被运行 Microsoft® Windows® 或 Samba 客户端库的客户端访问。
32.10.1. 服务器配置
Samba 的配置文件位于 /usr/local/etc/smb4.conf。在使用 Samba 之前,必须先创建该文件。
这里展示了一个简单的 smb4.conf 文件,用于在工作组中与 Windows® 客户端共享目录和打印机。对于涉及 LDAP 或 Active Directory 的更复杂设置,使用 samba-tool(8) 创建初始的 smb4.conf 更为简便。
[global] workgroup = WORKGROUP server string = Samba Server Version %v netbios name = ExampleMachine wins support = Yes security = user passdb backend = tdbsam # Example: share /usr/src accessible only to 'developer' user [src] path = /usr/src valid users = developer writable = yes browsable = yes read only = no guest ok = no public = no create mask = 0666 directory mask = 0755
32.10.1.1. 全局设置
在 /usr/local/etc/smb4.conf 中添加描述网络的设置:
workgroup-
要服务的工作组的名称。
netbios name-
Samba 服务器所知的 NetBIOS 名称。默认情况下,它与主机的 DNS 名称的第一个组件相同。
server string-
在
net view和其他一些网络工具的输出中显示的字符串,这些工具旨在显示有关服务器的描述性文本。 wins support-
Samba 是否将作为 WINS 服务器。请勿在网络上的多个服务器上启用对 WINS 的支持。
32.10.1.2. 安全设置
/usr/local/etc/smb4.conf 中最重要的设置是安全模型和后端密码格式。这些指令控制以下选项:
security-
最常见的设置是
security = share和security = user。如果客户端使用的用户名与其在 FreeBSD 机器上的用户名相同,则应使用用户级安全性。这是默认的安全策略,它要求客户端在访问共享资源之前先登录。在共享级别安全中,客户端在尝试连接到共享资源之前不需要使用有效的用户名和密码登录服务器。这是旧版本 Samba 的默认安全模型。
passdb backend-
Samba 有几种不同的后端身份验证模型。客户端可以使用 LDAP、NIS+、SQL 数据库或修改后的密码文件进行身份验证。推荐的身份验证方法是
tdbsam,适用于简单的网络环境,本文将介绍该方法。对于更大或更复杂的网络,推荐使用ldapsam。smbpasswd曾经是默认选项,但现在已经过时。
32.10.1.3. Samba 用户
为了让 Windows® 客户端能够访问共享文件夹,FreeBSD 用户账户必须映射到 SambaSAMAccount 数据库中。使用 pdbedit(8) 命令来映射已存在的 FreeBSD 用户账户。
# pdbedit -a -u username本节仅提及了最常用的设置。有关可用配置选项的其他信息,请参阅 官方 Samba Wiki 。
32.10.2. 启动 Samba
要在启动时启用 Samba ,请将以下行添加到 /etc/rc.conf 文件中:
samba_server_enable="YES"
立即启动 Samba:
# service samba_server start
Performing sanity check on Samba configuration: OK
Starting nmbd.
Starting smbd.Samba 由三个独立的守护进程组成。nmbd 和 smbd 守护进程都由 samba_enable 启动。如果还需要 winbind 名称解析,请设置:
winbindd_enable="YES"
可以随时通过键入以下命令停止 Samba:
# service samba_server stopSamba 是一个复杂的软件套件,具有与 Microsoft® Windows® 网络广泛集成的功能。有关超出此处所描述的基本配置的功能的更多信息,请参阅 https://www.samba.org 。
32.11. 使用 NTP 进行时钟同步
随着时间的推移,计算机的时钟容易偏离。这是一个问题,因为许多网络服务要求网络上的计算机共享相同准确的时间。准确的时间也需要确保文件时间戳保持一致。网络时间协议(NTP)是在网络中提供时钟准确性的一种方式。
FreeBSD 包含 ntpd(8),可以配置为查询其他 NTP 服务器以同步该机器上的时钟,或为网络中的其他计算机提供时间服务。
本节介绍了如何在 FreeBSD 上配置 ntpd。更多的文档可以在 HTML 格式的 /usr/share/doc/ntp/ 中找到。
32.11.1. NTP 配置
在 FreeBSD 上,可以使用内置的 ntpd 来同步系统的时钟。ntpd 是使用 rc.conf(5) 变量和 /etc/ntp.conf 进行配置的,详细信息请参见以下章节。
ntpd 通过 UDP 数据包与其网络对等方进行通信。您的机器与其 NTP 对等方之间的任何防火墙都必须配置为允许端口 123 上的 UDP 数据包的进出。
32.11.1.1. /etc/ntp.conf 文件
ntpd 读取 /etc/ntp.conf 文件来确定要查询的 NTP 服务器。建议选择多个 NTP 服务器,以防其中一个服务器无法访问或其时钟不可靠。当 ntpd 接收到响应时,它会优先选择可靠的服务器而不是不可靠的服务器。被查询的服务器可以是本地网络的服务器、由 ISP 提供的服务器,或者从一个 在线的公共可访问的 NTP 服务器列表 中选择。选择公共 NTP 服务器时,选择地理位置接近的服务器并查看其使用政策。pool 配置关键字从服务器池中选择一个或多个服务器。有一个 在线的公共可访问的 NTP 池列表,按地理区域组织。此外,FreeBSD 提供了一个由项目赞助的池,即 0.freebsd.pool.ntp.org。
例 37. 示例 /etc/ntp.conf
这是一个 ntp.conf 文件的简单示例。它可以直接使用;它包含了在公共可访问网络连接上操作的推荐 restrict 选项。
# Disallow ntpq control/query access. Allow peers to be added only # based on pool and server statements in this file. restrict default limited kod nomodify notrap noquery nopeer restrict source limited kod nomodify notrap noquery # Allow unrestricted access from localhost for queries and control. restrict 127.0.0.1 restrict ::1 # Add a specific server. server ntplocal.example.com iburst # Add FreeBSD pool servers until 3-6 good servers are available. tos minclock 3 maxclock 6 pool 0.freebsd.pool.ntp.org iburst # Use a local leap-seconds file. leapfile "/var/db/ntpd.leap-seconds.list"
该文件的格式在 ntp.conf(5) 中有描述。下面的描述仅提供了上面示例文件中使用的关键字的快速概述。
默认情况下,NTP 服务器对任何网络主机都是可访问的。restrict 关键字用于控制哪些系统可以访问该服务器。支持多个 restrict 条目,每个条目都可以细化之前语句中给出的限制。示例中显示的值允许本地系统完全查询和控制访问,而只允许远程系统查询时间。有关更多详细信息,请参阅 ntp.conf(5) 中的 访问控制支持(Access Control Support) 子节。
server 关键字指定要查询的单个服务器。文件可以包含多个 server 关键字,每行列出一个服务器。pool 关键字指定服务器池。 ntpd 将根据需要从该池中添加一个或多个服务器,以达到使用 tos minclock 值指定的对等体数量。iburst 关键字指示 ntpd 在首次建立联系时与服务器执行八次快速数据包交换,以帮助快速同步系统时间。
leapfile 关键字指定了一个包含闰秒信息的文件的位置。该文件由 periodic(8) 自动更新。此关键字指定的文件位置必须与 /etc/rc.conf 中的 ntp_db_leapfile 变量设置的位置匹配。
32.11.1.2. 在 /etc/rc.conf 文件中的 NTP 条目
将 ntpd_enable=YES 设置为在启动时启动 ntpd。一旦将 ntpd_enable=YES 添加到 /etc/rc.conf 文件中,可以通过输入以下命令立即启动 ntpd 而无需重新启动系统:
# service ntpd start只需设置 ntpd_enable 就可以使用 ntpd。下面列出的 rc.conf 变量也可以根据需要进行设置。
将 ntpd_sync_on_start=YES 设置为允许 ntpd 在启动时一次性调整时钟的任意量。通常情况下,如果时钟偏差超过 1000 秒,ntpd 会记录错误消息并退出。此选项在没有电池备份的实时时钟的系统上特别有用。
将 ntpd_oomprotect=YES 设置为保护 ntpd 守护进程免受系统尝试从内存不足(OOM)条件中恢复时被终止。
将 ntpd_config= 设置为备用的 ntp.conf 文件的位置。
将 ntpd_flags= 设置为包含所需的任何其他 ntpd 标志,但避免使用这些由 /etc/rc.d/ntpd 内部管理的标志。
-
-p(pid 文件位置) -
-c(设置ntpd_config=代替)
32.11.1.3. ntpd 和非特权的 ntpd 用户
在 FreeBSD 上,ntpd 可以作为非特权用户启动和运行。这需要使用 mac_ntpd(4) 策略模块。/etc/rc.d/ntpd 启动脚本首先检查 NTP 配置。如果可能,它会加载 mac_ntpd 模块,然后以非特权用户 ntpd(用户 ID 为 123 )启动 ntpd。为了避免文件和目录访问的问题,当配置中包含任何与文件相关的选项时,启动脚本不会自动以 ntpd 身份启动 ntpd。
如果 ntpd_flags 中存在以下任何一项,则需要按照下面描述的手动配置来以 ntpd 用户身份运行:
-
-f or --driftfile
-
-i or --jaildir
-
-k or --keyfile
-
-l or --logfile
-
-s or --statsdir
在 ntp.conf 文件中出现以下关键字之一,需要按照下面描述的方式手动配置才能以 ntpd 用户身份运行:
-
crypto
-
driftfile
-
key
-
logdir
-
statsdir
要手动配置 ntpd 以用户 ntpd 运行,您必须:
-
确保
ntpd用户可以访问配置中指定的所有文件和目录。 -
安排加载或编译
mac_ntpd模块到内核中。详细信息请参阅 mac_ntpd(4)。 -
在 /etc/rc.conf 中设置
ntpd_user ="ntpd"。
32.11.2. 使用 PPP 连接的 NTP
ntpd 在正常运行时不需要与互联网保持永久连接。然而,如果配置了 PPP 连接以按需拨号,应该阻止 NTP 流量触发拨号或保持连接活动。这可以通过在 /etc/ppp/ppp.conf 文件中使用 filter 指令进行配置。例如:
set filter dial 0 deny udp src eq 123 # Prevent NTP traffic from initiating dial out set filter dial 1 permit 0 0 set filter alive 0 deny udp src eq 123 # Prevent incoming NTP traffic from keeping the connection open set filter alive 1 deny udp dst eq 123 # Prevent outgoing NTP traffic from keeping the connection open set filter alive 2 permit 0/0 0/0
有关更多详细信息,请参阅 ppp(8) 中的 PACKET FILTERING 部分以及 /usr/share/examples/ppp/ 中的示例。
|
一些互联网接入提供商会阻止低编号端口的访问,这会导致 NTP 无法正常工作,因为回复无法到达目标机器。 |
32.12. iSCSI 启动程序和目标配置
iSCSI 是一种通过网络共享存储的方式。与在文件系统级别工作的 NFS 不同,iSCSI 在块设备级别工作。
在 iSCSI 术语中,共享存储的系统被称为 目标(target)。存储可以是物理磁盘,也可以是表示多个磁盘或物理磁盘部分的区域。例如,如果磁盘使用 ZFS 格式化,可以创建一个 zvol 作为 iSCSI 存储使用。
访问 iSCSI 存储的客户端被称为 发起者(initiators)。对于发起者来说,通过 iSCSI 可用的存储看起来像一个未格式化的原始磁盘,称为逻辑单元 (LUN) 。磁盘的设备节点出现在 /dev/ 中,设备必须单独进行格式化和挂载。
FreeBSD 提供了本地的基于内核的 iSCSI 目标和发起者。本节描述了如何将 FreeBSD 系统配置为目标或发起者。
32.12.1. 配置 iSCSI 目标
要配置一个 iSCSI 目标,需要创建一个名为 /etc/ctl.conf 的配置文件,然后在 /etc/rc.conf 中添加一行,以确保 ctld(8) 守护进程在启动时自动启动,最后启动守护进程。
以下是一个简单的 /etc/ctl.conf 配置文件的示例。有关此文件可用选项的更完整描述,请参阅 ctl.conf(5) 。
portal-group pg0 {
discovery-auth-group no-authentication
listen 0.0.0.0
listen [::]
}
target iqn.2012-06.com.example:target0 {
auth-group no-authentication
portal-group pg0
lun 0 {
path /data/target0-0
size 4G
}
}
第一个条目定义了 pg0 门户组。门户组定义了 ctld(8) 守护进程将监听哪些网络地址。discovery-auth-group no-authentication 条目表示任何发起者都可以在没有身份验证的情况下执行 iSCSI 目标发现。第三和第四行配置 ctld(8) 在默认端口 3260 上监听所有 IPv4(listen 0.0.0.0)和 IPv6(listen [::])地址。
不需要定义一个门户组,因为有一个内置的门户组叫做 default。在这种情况下,default 和 pg0 的区别在于,使用 default 时,目标发现始终被拒绝,而使用 pg0 时,目标发现始终被允许。
第二个条目定义了一个单一的目标。目标有两个可能的含义:一个用于提供 iSCSI 服务的机器,或者是一个命名的 LUN 组。这个示例使用了后者的含义,其中 iqn.2012-06.com.example:target0 是目标名称。这个目标名称适用于测试目的。实际使用时,将 com.example 更改为真实的域名,反转过来。2012-06 代表获取该域名控制权的年份和月份,而 target0 可以是任何值。在这个配置文件中可以定义任意数量的目标。
auth-group no-authentication 行允许所有发起者连接到指定的目标,而 portal-group pg0 则通过 pg0 门户组使目标可访问。
下一节定义了 LUN。对于发起者来说,每个 LUN 将被视为一个独立的磁盘设备。每个目标可以定义多个 LUN。每个 LUN 由一个数字标识,其中 LUN 0 是必需的。path /data/target0-0 行定义了支持 LUN 的文件或 zvol 的完整路径。在启动 ctld(8) 之前,该路径必须存在。第二行是可选的,用于指定 LUN 的大小。
接下来,为了确保 ctld(8) 守护进程在启动时自动启动,请将以下行添加到 /etc/rc.conf 文件中:
ctld_enable="YES"
要启动 ctld(8) ,请运行以下命令:
# service ctld start当启动 ctld(8) 守护进程时,它会读取 /etc/ctl.conf 文件。如果在守护进程启动后编辑了此文件,请使用此命令使更改立即生效:
# service ctld reload32.12.1.1. 身份验证
前面的示例在本质上是不安全的,因为它没有使用身份验证,任何人都可以完全访问所有目标。为了要求使用用户名和密码来访问目标,请按以下方式修改配置:
auth-group ag0 {
chap username1 secretsecret
chap username2 anothersecret
}
portal-group pg0 {
discovery-auth-group no-authentication
listen 0.0.0.0
listen [::]
}
target iqn.2012-06.com.example:target0 {
auth-group ag0
portal-group pg0
lun 0 {
path /data/target0-0
size 4G
}
}
auth-group 部分定义了用户名和密码对。试图连接到 iqn.2012-06.com.example:target0 的发起者必须首先指定一个已定义的用户名和密码。然而,目标发现仍然允许在没有身份验证的情况下进行。要求目标发现进行身份验证,请将 discovery-auth-group 设置为已定义的 auth-group 名称,而不是 no-authentication。
通常为每个发起者定义一个单独的导出目标是很常见的。作为上述语法的简写,用户名和密码可以直接在目标条目中指定:
target iqn.2012-06.com.example:target0 {
portal-group pg0
chap username1 secretsecret
lun 0 {
path /data/target0-0
size 4G
}
}
32.12.2. 配置 iSCSI 发起者
|
本节中描述的 iSCSI 发起者从 FreeBSD 10.0-RELEASE 开始得到支持。要使用旧版本中提供的 iSCSI initiator,请参考 iscontrol(8) 。 |
iSCSI 发起者要求 iscsid(8) 守护进程正在运行。该守护进程不使用配置文件。要在启动时自动启动它,请将以下行添加到 /etc/rc.conf 文件中:
iscsid_enable="YES"
要启动 iscsid(8),请运行以下命令:
# service iscsid start连接到目标可以使用或不使用 /etc/iscsi.conf 配置文件。本节演示了两种类型的连接方式。
32.12.2.1. 无需配置文件连接到目标
要将发起者连接到单个目标,请指定门户的 IP 地址和目标的名称:
# iscsictl -A -p 10.10.10.10 -t iqn.2012-06.com.example:target0要验证连接是否成功,请运行 iscsictl 命令,不带任何参数。输出应该类似于以下内容:
Target name Target portal State iqn.2012-06.com.example:target0 10.10.10.10 Connected: da0
在这个例子中, iSCSI 会话成功建立,其中 /dev/da0 代表已连接的逻辑单元( LUN )。如果 iqn.2012-06.com.example:target0 目标导出多个 LUN,则输出的该部分将显示多个设备节点。
Connected: da0 da1 da2.任何错误都将在输出中报告,以及系统日志中。例如,这个消息通常意味着 iscsid(8) 守护进程未运行:
Target name Target portal State iqn.2012-06.com.example:target0 10.10.10.10 Waiting for iscsid(8)
以下消息提示存在网络问题,例如错误的 IP 地址或端口:
Target name Target portal State iqn.2012-06.com.example:target0 10.10.10.11 Connection refused
这条消息意味着指定的目标名称是错误的:
Target name Target portal State iqn.2012-06.com.example:target0 10.10.10.10 Not found
这条消息表示目标需要进行身份验证:
Target name Target portal State iqn.2012-06.com.example:target0 10.10.10.10 Authentication failed
要指定 CHAP 用户名和密码,使用以下语法:
# iscsictl -A -p 10.10.10.10 -t iqn.2012-06.com.example:target0 -u user -s secretsecret32.12.2.2. 使用配置文件连接到目标
要使用配置文件进行连接,请创建一个名为 /etc/iscsi.conf 的文件,并将其内容设置为以下内容:
t0 {
TargetAddress = 10.10.10.10
TargetName = iqn.2012-06.com.example:target0
AuthMethod = CHAP
chapIName = user
chapSecret = secretsecret
}
t0 指定了配置文件部分的别名。它将被发起者用来指定要使用的配置。其他行指定了连接过程中要使用的参数。TargetAddress 和 TargetName 是必需的,而其他选项是可选的。在这个例子中,显示了 CHAP 用户名和密码。
要连接到定义的目标,请指定昵称:
# iscsictl -An t0或者,要连接到配置文件中定义的所有目标,请使用:
# iscsictl -Aa要使发起者自动连接到 /etc/iscsi.conf 中的所有目标,请将以下内容添加到 /etc/rc.conf 中:
iscsictl_enable="YES" iscsictl_flags="-Aa"
Chapter 33. 防火墙
33.1. 简介
防火墙使得过滤通过系统流动的进出流量成为可能。防火墙可以使用一个或多个“规则”集来检查进出网络连接的网络数据包,并允许流量通过或阻止它。防火墙的规则可以检查数据包的一个或多个特征,如协议类型、源或目标主机地址以及源或目标端口。
防火墙可以增强主机或网络的安全性。它们可以用于执行以下一项或多项功能:
-
保护和隔离内部网络中的应用程序、服务和机器,以防止来自公共互联网的不必要的流量。
-
限制或禁止内部网络主机访问公共互联网的服务。
-
支持网络地址转换(NAT),允许内部网络使用私有 IP 地址,并使用单个 IP 地址或共享的自动分配的公共地址池与公共互联网建立单一连接。
FreeBSD 基本系统内置了三个防火墙:PF、IPFW 和 IPFILTER(也称为 IPF)。FreeBSD 还提供了两个流量整形器,用于控制带宽使用:altq(4) 和 dummynet(4)。ALTQ 通常与 PF 紧密关联,而 dummynet 与 IPFW 关联。每个防火墙使用规则来控制数据包对 FreeBSD 系统的访问,尽管它们的实现方式不同,并且每个防火墙都有不同的规则语法。
FreeBSD 提供多个防火墙,以满足各种用户的不同需求和偏好。每个用户应该评估哪个防火墙最适合他们的需求。
阅读完本章后,您将了解:
-
如何定义数据包过滤规则。
-
FreeBSD 内置防火墙的区别。
-
如何使用和配置 PF 防火墙。
-
如何使用和配置 IPFW 防火墙。
-
如何使用和配置 IPFILTER 防火墙。
在阅读本章之前,你应该:
-
了解基本的 FreeBSD 和互联网概念。
|
由于所有防火墙都是基于检查选定数据包控制字段的值,因此防火墙规则集的创建者必须了解 TCP/IP 的工作原理,数据包控制字段中不同值的含义,以及这些值在正常会话中的使用方式。对于一个很好的介绍,请参考 Daryl 的 TCP/IP 入门指南 。 |
33.2. 防火墙概念
一个规则集包含一组规则,根据数据包中包含的值来通过或阻止数据包。主机之间的双向数据包交换构成一个会话对话。防火墙规则集处理来自公共互联网的数据包以及系统作为对其响应而产生的数据包。每个 TCP/IP 服务都由其协议和监听端口预定义。目标为特定服务的数据包源自源地址使用非特权端口,并且目标地址上的特定服务端口。所有上述参数都可以用作选择条件来创建将通过或阻止服务的规则。
要查找未知的端口号,请参考 /etc/services。或者,访问 [http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers](http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers),进行端口号查找以找到特定端口号的用途。
请查看此链接,了解 Trojans 使用的端口号。
FTP 有两种模式:主动模式和被动模式。它们的区别在于数据通道的获取方式。被动模式更安全,因为数据通道是由原始的 FTP 会话请求者获取的。关于 FTP 和不同模式的详细解释,请参见 http://www.slacksite.com/other/ftp.html。
防火墙规则集可以是“排他性(exclusive)”或“包容性(inclusive)”。排他性防火墙允许所有流量通过,除了与规则集匹配的流量。而包容性防火墙则相反,它只允许与规则匹配的流量通过,阻止其他所有流量。
一个包容性防火墙可以更好地控制出站流量,因此对于向公共互联网提供服务的系统来说是更好的选择。它还可以控制来自公共互联网的流量类型,以便访问私有网络。所有不符合规则的流量都会被阻止并记录。包容性防火墙通常比排他性防火墙更安全,因为它们显著降低了允许不需要的流量的风险。
|
除非另有说明,本章中的所有配置和示例规则集都创建包容性防火墙规则集。 |
可以使用“有状态防火墙(stateful firewall)”进一步加强安全性。这种类型的防火墙会跟踪打开的连接,并且只允许与现有连接匹配或打开新的允许连接的流量通过。
有状态过滤将流量视为会话中的双向数据包交换。当在匹配规则上指定状态时,防火墙会动态生成每个会话期间预期交换的数据包的内部规则。它具有足够的匹配能力来确定数据包是否适用于会话。任何不符合会话模板的数据包都会被自动拒绝。
当会话完成时,它将从动态状态表中移除。
有状态过滤允许我们专注于阻止/通过新的会话。如果新的会话被通过,所有后续的数据包将自动被允许通过,任何冒充的数据包将自动被拒绝。如果新的会话被阻止,它的所有后续数据包都将被禁止。有状态过滤提供了高级匹配能力,能够抵御攻击者使用的各种攻击方法。
NAT 代表网络地址转换。NAT 功能使得防火墙后面的私有局域网能够共享一个由 ISP 分配的 IP 地址,即使该地址是动态分配的。NAT 允许局域网中的每台计算机都能够访问互联网,而无需为多个互联网账户或 IP 地址向 ISP 付费。
NAT 会自动将局域网上每个系统的私有 LAN IP 地址转换为单个公共 IP 地址,以便在通过防火墙发送到公共互联网的数据包中使用。它还会对返回的数据包执行相反的转换。
根据 RFC 1918,以下 IP 地址范围被保留用于私有网络,这些地址将不会直接路由到公共互联网,因此可用于与 NAT 一起使用:
-
10.0.0.0/8。 -
172.16.0.0/12。 -
192.168.0.0/16。
|
在处理防火墙规则时,请非常小心。某些配置可能会将管理员锁在服务器外。为了安全起见,考虑从本地控制台执行初始防火墙配置,而不是通过 ssh 远程执行。 |
33.3. PF
自从 FreeBSD 5.3 版本以来,OpenBSD 的 PF 防火墙的移植版本已经作为基本系统的一部分包含在其中。PF 是一个完整的、功能齐全的防火墙,可选择性地支持 ALTQ(Alternate Queuing ),提供了服务质量(QoS)功能。
OpenBSD 项目在 PF FAQ 中维护了 PF 的权威参考。Peter Hansteen 在 http://home.nuug.no/\~ peter/pf/[http://home.nuug.no/~peter/pf/] 上维护了一个详尽的 PF 教程。
|
阅读 PF FAQ 时,请记住多年来,FreeBSD 的 PF 版本与上游的 OpenBSD 版本有很大的差异。在 FreeBSD 上,不是所有的功能都与 OpenBSD 上的工作方式相同,反之亦然。 |
FreeBSD packet filter mailing list 是一个很好的地方,可以询问有关配置和运行 PF 防火墙的问题。在提问之前,请先查看邮件列表的存档,因为可能已经有人回答过了。
本手册的这一部分重点介绍了与 FreeBSD 相关的 PF。它演示了如何启用 PF 和 ALTQ。还提供了在 FreeBSD 系统上创建规则集的几个示例。
33.3.1. 启用 PF
要使用 PF,首先必须加载其内核模块。本节描述了可以添加到 /etc/rc.conf 文件中以启用 PF 的条目。
首先,在 /etc/rc.conf 中添加 pf_enable=yes。
# sysrc pf_enable=yes当启动 PF 时,可以传递在 pfctl(8) 中描述的其他选项。在 /etc/rc.conf 中添加或更改此条目,并在两个引号("")之间指定任何所需的标志。
pf_flags="" # additional flags for pfctl startup
如果 PF 无法找到其规则集配置文件,则不会启动。默认情况下,FreeBSD 不提供规则集,并且没有 /etc/pf.conf 文件。示例规则集可以在 /usr/share/examples/pf/ 中找到。如果已经将自定义规则集保存在其他位置,请在 /etc/rc.conf 文件中添加一行,指定文件的完整路径:
pf_rules="/path/to/pf.conf"
PF 提供了日志记录支持,可以通过 pflog(4) 来查看。要启用日志记录支持,请将 pflog_enable=yes 添加到 /etc/rc.conf 文件中。
# sysrc pflog_enable=yes还可以添加以下行来更改日志文件的默认位置,或者指定在启动 pflog(4) 时传递的任何其他标志:
pflog_logfile="/var/log/pflog" # where pflogd should store the logfile pflog_flags="" # additional flags for pflogd startup
最后,如果防火墙后面有一个局域网,并且需要转发局域网上的计算机的数据包,或者需要进行网络地址转换(NAT),请启用以下选项:
gateway_enable="YES" # Enable as LAN gateway
保存所需的编辑后,可以通过输入以下命令启动带有日志支持的 PF:
# service pf start
# service pflog start默认情况下,PF 从 /etc/pf.conf 读取其配置规则,并根据该文件中指定的规则或定义修改、丢弃或通过数据包。FreeBSD 安装包含位于 /usr/share/examples/pf/ 的几个示例文件。请参考 PF FAQ 以获取完整的 PF 规则集覆盖范围。
要控制 PF,请使用 pfctl 命令。有用的 pfctl 选项 总结了一些对该命令有用的选项。有关所有可用选项的描述,请参阅 pfctl(8)。
| 命令 | 目的 |
|---|---|
|
启用 PF 。 |
|
禁用 PF 。 |
|
清除所有的 NAT、过滤、状态和表规则,并重新加载 /etc/pf.conf 文件。 |
|
关于过滤规则、 NAT 规则或状态表的报告。 |
|
检查 /etc/pf.conf 是否有错误,但不要加载规则集。 |
|
security/sudo 是用于运行需要提升权限的命令,例如 |
要监视通过 PF 防火墙的流量,请考虑安装 sysutils/pftop 包或 port。安装完成后,可以运行 pftop 以查看类似于 top(1) 的格式的流量的实时快照。
33.3.2. PF 规则集
本节演示如何创建自定义规则集。它从最简单的规则集开始,并通过多个示例来构建其概念,以展示 PF 的许多功能在实际应用中的用法。
最简单的规则集适用于不运行任何服务且需要访问一个网络(可能是互联网)的单台机器。要创建这个最小的规则集,请编辑 /etc/pf.conf 文件,使其如下所示:
block in all pass out all keep state
第一条规则默认拒绝所有传入流量。第二条规则允许由该系统创建的连接通过,并保留这些连接的状态信息。这些状态信息允许这些连接的返回流量通过,并且只应在可信任的机器上使用。可以使用以下命令加载规则集:
# pfctl -e ; pfctl -f /etc/pf.conf除了保持状态,PF 还提供了可以在创建规则时定义和使用的 列表 和 宏。宏可以包含列表,并且需要在使用之前进行定义。例如,在规则集的最顶部插入以下行:
tcp_services = "{ ssh, smtp, domain, www, pop3, auth, pop3s }"
udp_services = "{ domain }"
PF 不仅可以识别端口号,还可以识别端口名称,只要这些名称在 /etc/services 文件中列出。这个例子创建了两个宏。第一个宏是一个包含七个 TCP 端口名称的列表,第二个宏是一个 UDP 端口名称。一旦定义了宏,就可以在规则中使用它们。在这个例子中,除了由该系统发起的与七个指定的 TCP 服务和一个指定的 UDP 服务相关的连接之外,所有流量都被阻止。
tcp_services = "{ ssh, smtp, domain, www, pop3, auth, pop3s }"
udp_services = "{ domain }"
block all
pass out proto tcp to any port $tcp_services keep state
pass proto udp to any port $udp_services keep state
尽管 UDP 被认为是一种无状态协议,但 PF 能够跟踪一些状态信息。例如,当传递一个 UDP 请求来询问域名服务器的域名时,PF 会监视响应并将其传递回去。
每当对规则集进行编辑时,必须加载新的规则,以便可以使用它们:
# pfctl -f /etc/pf.conf如果没有语法错误,pfctl 在加载规则时不会输出任何消息。在尝试加载规则之前,也可以对规则进行测试:
# pfctl -nf /etc/pf.conf包括 -n 会导致规则仅被解释而不被加载。这提供了纠正任何错误的机会。在任何时候,只有最后一个有效的规则集被加载,直到 PF 被禁用或加载了一个新的规则集。
|
在 |
33.3.2.1. 一个带有 NAT 的简单网关
本节演示了如何配置运行 PF 的 FreeBSD 系统,使其充当至少一台其他计算机的网关。网关需要至少两个网络接口,每个接口连接到不同的网络。在本示例中,xl0 连接到互联网, xl1 连接到内部网络。
首先,启用网关以使机器将其接收到的网络流量从一个接口转发到另一个接口。这个 sysctl 设置将转发 IPv4 数据包:
# sysctl net.inet.ip.forwarding=1要转发 IPv6 流量,请使用:
# sysctl net.inet6.ip6.forwarding=1要在系统启动时启用这些设置,请使用 sysrc(8) 将它们添加到 /etc/rc.conf 文件中。
# sysrc gateway_enable=yes
# sysrc ipv6_gateway_enable=yes使用 ifconfig 命令验证两个接口是否都已启动并运行。
接下来,创建 PF 规则以允许网关传递流量。虽然以下规则允许来自内部网络主机的有状态流量通过网关,但 to 关键字不能保证从源到目的地的完全通过:
pass in on xl1 from xl1:network to xl0:network port $ports keep state
该规则只允许流量通过内部接口进入网关。要让数据包继续传递,需要一个匹配的规则:
pass out on xl0 from xl1:network to xl0:network port $ports keep state
虽然这两个规则可以工作,但这样具体的规则很少需要。对于忙碌的网络管理员来说,一个可读的规则集是更安全的规则集。本节的其余部分演示了如何尽可能简化规则以提高可读性。例如,这两个规则可以用一条规则来替代:
pass from xl1:network to any port $ports keep state
可以使用宏来替代 interface:network 表示法,使规则集更易读。例如,可以定义一个 $localnet 宏,表示直接连接到内部接口的网络($xl1:network)。另外,也可以将 $localnet 的定义更改为 IP 地址/子网掩码 表示法来表示网络,例如 192.168.100.1/24 表示私有地址的子网。
如果需要的话,$localnet 甚至可以被定义为一个网络列表。无论具体需求如何,一个合理的 $localnet 定义可以在典型的通过规则中使用,如下所示:
pass from $localnet to any port $ports keep state
以下示例规则集允许内部网络上的机器发起的所有流量。它首先定义了两个宏,用于表示网关的外部和内部 3COM 接口。
|
对于拨号用户,外部接口将使用 tun0。对于 ADSL 连接,特别是使用以太网上的 PPP(PPPoE)的连接,正确的外部接口是 tun0,而不是物理以太网接口。 |
ext_if = "xl0" # macro for external interface - use tun0 for PPPoE
int_if = "xl1" # macro for internal interface
localnet = $int_if:network
# ext_if IP address could be dynamic, hence ($ext_if)
nat on $ext_if from $localnet to any -> ($ext_if)
block all
pass from { lo0, $localnet } to any keep state
这个规则集引入了 nat 规则,用于处理内部网络中不可路由的地址到分配给外部接口的 IP 地址的网络地址转换。nat 规则的最后部分周围的括号 ($ext_if) 是在外部接口的 IP 地址是动态分配时包含的。它确保即使外部 IP 地址发生变化,网络流量也能够正常运行而不会有严重的中断。
请注意,这个规则集可能允许更多的流量从网络中通过,而实际上并不需要这么多。一个合理的设置可以创建这个宏:
client_out = "{ ftp-data, ftp, ssh, domain, pop3, auth, nntp, http, \
https, cvspserver, 2628, 5999, 8000, 8080 }"
用于主要通行规则中:
pass inet proto tcp from $localnet to any port $client_out \
flags S/SA keep state
可能还需要一些其他的通行规则。这个规则允许在外部接口上使用 SSH :
pass in inet proto tcp to $ext_if port ssh
这个宏定义和规则允许内部客户端使用 DNS 和 NTP 服务。
udp_services = "{ domain, ntp }"
pass quick inet proto { tcp, udp } to any port $udp_services keep state
请注意这条规则中的 quick 关键字。由于规则集包含多个规则,因此了解规则集中规则之间的关系非常重要。规则按照从上到下的顺序进行评估,按照它们编写的顺序进行。对于每个由 PF 评估的数据包或连接,规则集中的 最后一个匹配的规则 是应用的规则。然而,当一个数据包匹配包含 quick 关键字的规则时,规则处理停止,数据包根据该规则进行处理。当需要对一般规则进行异常处理时,这非常有用。
33.3.2.2. 创建一个 FTP 代理
由于 FTP 协议的特性,配置工作中的 FTP 规则可能会出现问题。 FTP 在防火墙出现几十年之前就存在,并且在设计上存在不安全性。使用 FTP 的最常见问题包括:
-
密码以明文形式传输。
-
该协议要求使用至少两个 TCP 连接(控制和数据),并且这两个连接要使用不同的端口。
-
当建立会话时,数据使用随机选择的端口进行通信。
对于需要使用 FTP 的情况,PF 提供了将 FTP 流量重定向到一个名为 ftp-proxy(8) 的小型代理程序,该程序包含在 FreeBSD 的基本系统中。代理的作用是使用一组锚点动态插入和删除规则,以正确处理 FTP 流量。
要启用 FTP 代理,请将以下行添加到 /etc/rc.conf 文件中:
ftpproxy_enable="YES"
然后通过运行以下命令启动代理:
# service ftp-proxy start对于基本配置,需要将三个元素添加到 /etc/pf.conf 文件中。首先是代理将用于插入生成的 FTP 会话规则的锚点:
nat-anchor "ftp-proxy/*" rdr-anchor "ftp-proxy/*"
其次,需要一个通过规则来允许 FTP 流量进入代理服务器。
第三,重定向和 NAT 规则需要在过滤规则之前定义。在 nat 规则之后立即插入以下 rdr 规则:
rdr pass on $int_if proto tcp from any to any port ftp -> 127.0.0.1 port 8021
最后,允许重定向的流量通过。
pass out proto tcp from $proxy to any port ftp
$proxy 是代理守护程序绑定的地址的展开形式。
保存 /etc/pf.conf 文件,加载新的规则,并从客户端验证 FTP 连接是否正常工作:
# pfctl -f /etc/pf.conf这个例子涵盖了一个基本的设置,其中本地网络中的客户端需要联系其他地方的 FTP 服务器。这个基本配置应该适用于大多数 FTP 客户端和服务器的组合。如 ftp-proxy(8) 所示,通过在 ftpproxy_flags= 行中添加选项,可以改变代理的行为。一些客户端或服务器可能有特定的问题,在配置中必须进行补偿,或者可能需要以特定的方式集成代理,例如将 FTP 流量分配给特定的队列。
要以 PF 和 ftp-proxy(8) 保护的方式运行 FTP 服务器,可以配置一个独立的 ftp-proxy 以反向模式运行,使用 -R 选项,在一个独立的端口上,并具有自己的重定向通过规则。
33.3.2.3. 管理 ICMP
许多用于调试或故障排除 TCP/IP 网络的工具依赖于 Internet 控制消息协议(ICMP),该协议专门设计用于调试。
ICMP 协议在主机和网关之间发送和接收 控制消息(ontrol messages),主要是为了向发送方提供有关到目标主机的任何异常或困难条件的反馈。路由器使用 ICMP 来协商数据包大小和其他传输参数,这个过程通常被称为 路径 MTU 发现(path MTU discovery)。
从防火墙的角度来看,一些 ICMP 控制消息容易受到已知的攻击向量的攻击。此外,无条件地允许所有诊断流量通过可以使调试更容易,但也会使他人更容易提取有关网络的信息。因此,以下规则可能不是最佳选择:
pass inet proto icmp from any to any
一种解决方案是允许本地网络中的所有 ICMP 流量通过,同时阻止来自网络外部的所有探测。
pass inet proto icmp from $localnet to any keep state pass inet proto icmp from any to $ext_if keep state
还有其他可用的选项,这些选项展示了 PF 的一些灵活性。例如,可以指定 ping(8) 和 traceroute(8) 使用的消息,而不是允许所有的 ICMP 消息。首先,定义一个用于该类型消息的宏:
icmp_types = "echoreq"
和一个使用宏的规则:
pass inet proto icmp all icmp-type $icmp_types keep state
如果需要其他类型的 ICMP 数据包,请将 icmp_types 扩展为这些数据包类型的列表。输入 more /usr/src/sbin/pfctl/pfctl_parser.c 以查看 PF 支持的 ICMP 消息类型列表。请参考 http://www.iana.org/assignments/icmp-parameters/icmp-parameters.xhtml 以了解每个消息类型的解释。
由于 Unix 的 traceroute 默认使用 UDP,因此需要添加另一条规则来允许 Unix 的 traceroute。
# allow out the default range for traceroute(8): pass out on $ext_if inet proto udp from any to any port 33433 >< 33626 keep state
由于 Microsoft Windows 系统上的 TRACERT.EXE 使用 ICMP 回显请求消息,因此只需要第一个规则来允许来自这些系统的网络跟踪。Unix 的 traceroute 也可以指示使用其他协议,并且如果使用了 -I 选项,它将使用 ICMP 回显请求消息。有关详细信息,请参阅 traceroute(8) 手册页。
33.3.2.3.1. 路径 MTU 发现
Internet 协议被设计为与设备无关,设备无关的一个结果是无法可靠地预测给定连接的最佳数据包大小。数据包大小的主要限制是 最大传输单元(MTU),它设置了接口的数据包大小的上限。输入 ifconfig 命令可以查看系统网络接口的 MTU 值。
TCP/IP 使用一种称为路径 MTU 发现的过程来确定连接的正确数据包大小。该过程发送大小不同的数据包,并设置“不分片(Do not fragment)”标志,期望在达到上限时收到一个 ICMP 返回数据包,其类型为“type 3, code 4”。Type 3 表示“目标不可达(destination unreachable)”,Code 4 表示“需要分片,但设置了不分片标志(fragmentation needed,but the do-not-fragment flag is set)”。为了支持与其他 MTU 的连接,可以将 destination unreachable 类型添加到 icmp_types 宏中,以允许路径 MTU 发现。
icmp_types = "{ echoreq, unreach }"
由于 pass 规则已经使用了该宏,所以不需要修改 pass 规则来支持新的 ICMP 类型。
pass inet proto icmp all icmp-type $icmp_types keep state
33.3.2.4. 使用表格
某些类型的数据在特定时间对过滤和重定向很重要,但它们的定义太长了,无法包含在规则集文件中。 PF 支持使用表格,这些表格是定义的列表,可以在不需要重新加载整个规则集的情况下进行操作,并且可以提供快速查找。表格名称始终用 < > 括起来,就像这样:
table <clients> { 192.168.2.0/24, !192.168.2.5 }
在这个例子中,192.168.2.0/24 网络是表的一部分,除了地址 192.168.2.5,它使用 ! 运算符被排除在外。还可以从文件中加载表,其中每个项目都在单独的行上,就像在这个例子中看到的那样 /etc/clients:
192.168.2.0/24 !192.168.2.5
要引用该文件,请按照以下方式定义表格:
table <clients> persist file "/etc/clients"
一旦表被定义,就可以通过规则进行引用:
pass inet proto tcp from <clients> to any port $client_out flags S/SA keep state
可以使用 pfctl 实时操作表的内容。以下示例将另一个网络添加到表中:
# pfctl -t clients -T add 192.168.1.0/16请注意,通过这种方式进行的任何更改将立即生效,这使它们非常适合测试,但在断电或重启后将不会保留。要使更改永久生效,可以修改规则集中表的定义或编辑表所引用的文件。可以使用 cron(8) 作业来维护表的磁盘副本,该作业定期将表的内容转储到磁盘上,使用类似 pfctl -t clients -T show >/etc/clients 的命令。或者,也可以使用 /etc/clients 更新内存中的表内容:
# pfctl -t clients -T replace -f /etc/clients33.3.2.5. 使用过载表保护 SSH
那些在外部接口上运行 SSH 的人可能在身份验证日志中看到类似于以下内容的信息:
Sep 26 03:12:34 skapet sshd[25771]: Failed password for root from 200.72.41.31 port 40992 ssh2 Sep 26 03:12:34 skapet sshd[5279]: Failed password for root from 200.72.41.31 port 40992 ssh2 Sep 26 03:12:35 skapet sshd[5279]: Received disconnect from 200.72.41.31: 11: Bye Bye Sep 26 03:12:44 skapet sshd[29635]: Invalid user admin from 200.72.41.31 Sep 26 03:12:44 skapet sshd[24703]: input_userauth_request: invalid user admin Sep 26 03:12:44 skapet sshd[24703]: Failed password for invalid user admin from 200.72.41.31 port 41484 ssh2
这表明正在进行一次暴力攻击,某人或某个程序正在尝试发现能够让他们进入系统的用户名和密码。
如果需要合法用户进行外部 SSH 访问,更改 SSH 使用的默认端口可以提供一定的保护。然而,PF 提供了一种更优雅的解决方案。通过 Pass 规则,可以限制连接主机的操作,并将违规者放入被拒绝某些或全部访问的地址表中。甚至可以断开超出限制的机器的所有现有连接。
要进行配置,请在规则集的表格部分创建此表格。
table <bruteforce> persist
然后,在规则集的早期位置添加规则,以阻止暴力访问,同时允许合法访问:
block quick from <bruteforce>
pass inet proto tcp from any to $localnet port $tcp_services \
flags S/SA keep state \
(max-src-conn 100, max-src-conn-rate 15/5, \
overload <bruteforce> flush global)
括号中的部分定义了限制条件,数字应根据当地要求进行更改。可以按以下方式阅读:
max-src-conn 是指允许来自一个主机的同时连接数。
max-src-conn-rate 是每秒钟(5)允许来自任何单个主机的新连接的速率(15)。
overload <bruteforce> 的意思是任何超过这些限制的主机都会将其地址添加到 bruteforce 表中。规则集会阻止来自 bruteforce 表中地址的所有流量。
最后,flush global 表示当一个主机达到限制时,该主机的所有连接 (global) 将被终止 (flush) 。
|
这些规则将 不会 阻止慢速暴力破解者,如 http://home.nuug.no/~peter/hailmary2013/ 中所描述的。 |
这个示例规则集主要是为了说明。例如,如果希望有大量的连接,但对于 ssh 的要求更加严格,可以在规则集的早期添加以下类似的规则来补充上面的规则:
pass quick proto { tcp, udp } from any to any port ssh \
flags S/SA keep state \
(max-src-conn 15, max-src-conn-rate 5/3, \
overload <bruteforce> flush global)
|
不一定需要阻止所有超载器: 值得注意的是,过载机制是一种通用技术,不仅适用于 SSH,并且完全阻止来自违规者的所有流量并不总是最优的选择。 例如,可以使用过载规则来保护邮件服务或网络服务,并且可以在规则中使用过载表来将违规者分配到带有最小带宽分配的队列中,或者重定向到特定的网页。 |
随着时间的推移,表格将被过载规则填满,其大小将逐渐增长,占用更多的内存。有时,被阻止的 IP 地址是一个动态分配的地址,后来被分配给了一个有合法理由与本地网络中的主机通信的主机。
对于这种情况,pfctl 提供了过期表项的功能。例如,以下命令将删除在 86400 秒内没有被引用的 <bruteforce> 表项:
# pfctl -t bruteforce -T expire 86400类似的功能由 security/expiretable 提供,该包会删除在指定时间内未被访问的表条目。
安装完成后,可以运行 expiretable 来删除指定时限之前的 <bruteforce> 表条目。以下示例将删除所有 24 小时之前的条目:
/usr/local/sbin/expiretable -v -d -t 24h bruteforce
33.3.2.6. 防止垃圾邮件的保护措施
不要将其与 spamassassin 捆绑的 spamd 守护程序混淆,mail/spamd 可以通过配置 PF 来提供对垃圾邮件的外部防御。这个 spamd 通过一组重定向钩入 PF 配置。
垃圾邮件发送者往往发送大量的消息,垃圾邮件主要来自一些友好的垃圾邮件网络和大量被劫持的机器,这些都会被迅速报告给封锁列表。
当接收到来自黑名单中地址的 SMTP 连接时,spamd 会呈现其横幅,并立即切换到一种模式,以逐字节地回答 SMTP 流量。这种技术旨在尽可能浪费垃圾邮件发送者的时间,被称为“蜿蜒(tarpitting)”。具体实现使用逐字节 SMTP 回复的方法通常被称为“口吃(stuttering)”。
这个示例演示了使用自动更新的屏蔽列表设置 spamd 的基本步骤。有关更多信息,请参考安装在 mail/spamd 中的 man 页面。
在邮件服务器前的典型网关上,主机很快就会在几秒钟到几分钟内被困住。
PF 还支持 灰名单(greylisting),它会暂时拒绝来自未知主机的带有 45n 代码的消息。在合理的时间内再次尝试的灰名单主机的消息将被放行。符合 RFC 1123 和 RFC 2821 规定的发件人的流量将立即被放行。
关于灰名单技术的更多信息可以在 greylisting.org 网站上找到。灰名单最令人惊讶的事情之一,除了它的简单性,就是它仍然有效。垃圾邮件发送者和恶意软件编写者一直非常慢地适应绕过这种技术。
配置灰名单的基本步骤如下:
配置灰名单过程
-
确保按照上一个步骤的说明,将 fdescfs(5) 挂载起来。
-
要以灰名单模式运行 spamd,请将以下行添加到 /etc/rc.conf 文件中:
spamd_grey="YES" # use spamd greylisting if YES
请参考 spamd 手册,了解其他相关参数的描述。
-
完成灰名单设置的步骤:
# service obspamd restart # service obspamlogd start
在幕后,spamdb 数据库工具和 spamlogd 白名单更新程序为灰名单功能执行重要功能。spamdb 是管理员通过 /var/db/spamdb 数据库的内容来管理阻止、灰名单和允许名单的主要界面。
33.3.2.7. 网络维护
本节介绍了如何使用 block-policy、scrub 和 antispoof 来使规则集的行为正常。
block-policy 是一个选项,可以在规则集的 options 部分中设置,该部分位于重定向和过滤规则之前。该选项确定了 PF 在规则阻止主机时发送的反馈信息(如果有的话)。该选项有两个可能的值:drop 会丢弃被阻止的数据包而不提供反馈,return 会返回一个状态码,例如 Connection refused。
如果未设置,默认策略为 drop。要更改 block-policy,请指定所需的值:
set block-policy return
在 PF 中,scrub 是一个关键字,它可以启用网络数据包的规范化。该过程会重新组装分段的数据包,并且丢弃具有无效标志组合的 TCP 数据包。启用 scrub 可以提供一定程度的保护,防止基于数据包片段处理不正确的某些攻击。有许多选项可供选择,但最简单的形式适用于大多数配置:
scrub in all
一些服务,如 NFS,需要特定的片段处理选项。有关更多信息,请参阅 https://home.nuug.no/~peter/pf/en/scrub.html
这个例子重新组装片段,清除“不分段(do not fragment)”位,并将最大分段大小设置为 1440 字节:
scrub in all fragment reassemble no-df max-mss 1440
antispoof 机制通过阻止出现在逻辑上不可能的接口和方向上的数据包,主要保护免受伪造或伪装的 IP 地址的活动的影响。
这些规则可以过滤掉来自世界其他地方的伪造流量,以及源自本地网络的任何伪造数据包。
antispoof for $ext_if antispoof for $int_if
33.3.2.8. 处理非可路由地址
即使有一个正确配置的网关来处理网络地址转换,人们可能仍然需要弥补其他人的错误配置。常见的错误配置是允许非可路由地址的流量进入互联网。由于来自非可路由地址的流量可能参与多种拒绝服务攻击技术,建议通过外部接口明确地阻止非可路由地址的流量进入网络。
在这个例子中,定义了一个包含非可路由地址的宏,然后在阻止规则中使用。对这些地址的流量在网关的外部接口上被静默丢弃。
martians = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
10.0.0.0/8, 169.254.0.0/16, 192.0.2.0/24, \
0.0.0.0/8, 240.0.0.0/4 }"
block drop in quick on $ext_if from $martians to any
block drop out quick on $ext_if from any to $martians
33.3.3. 启用 ALTQ
在 FreeBSD 上,可以使用 ALTQ 与 PF 一起提供服务质量(QoS)。一旦启用 ALTQ,可以在规则集中定义队列,确定出站数据包的处理优先级。
在启用 ALTQ 之前,请参考 altq(4) 以确定系统上安装的网络卡驱动程序是否支持它。
ALTQ 不可用作可加载的内核模块。如果系统的接口支持 ALTQ,请按照 配置 FreeBSD 内核 中的说明创建自定义内核。以下内核选项可用。第一个选项用于启用 ALTQ。其他选项中至少需要一个来指定队列调度算法:
options ALTQ options ALTQ_CBQ # Class Based Queuing (CBQ) options ALTQ_RED # Random Early Detection (RED) options ALTQ_RIO # RED In/Out options ALTQ_HFSC # Hierarchical Packet Scheduler (HFSC) options ALTQ_PRIQ # Priority Queuing (PRIQ)
以下调度算法可用:
- CBQ
-
基于类的排队(CBQ)用于将连接的带宽划分为不同的类别或队列,以根据过滤规则对流量进行优先级排序。
- RED
-
随机早期检测(RED)用于通过测量队列的长度并将其与队列的最小和最大阈值进行比较来避免网络拥塞。当队列超过最大阈值时,所有新的数据包将被随机丢弃。
- RIO
-
在随机早期检测输入输出(RIO)模式中,RED 维护多个平均队列长度和多个阈值,每个 QOS 级别对应一个阈值。
- HFSC
-
层次公平服务曲线分组调度器(HFSC)的描述可以在 http://www-2.cs.cmu.edu/hzhang/HFSC/main.html[http://www-2.cs.cmu.edu/hzhang/HFSC/main.html] 找到。
- PRIQ
-
优先队列(PRIQ)始终首先传递位于较高队列中的流量。
有关调度算法和示例规则集的更多信息,请访问 OpenBSD 的网络存档: https://web.archive.org/web/20151109213426/http://www.openbsd.org/faq/pf/queueing.html 。
33.4. IPFW
IPFW 是为 FreeBSD 编写的一种有状态防火墙,支持 IPv4 和 IPv6。它由几个组件组成:内核防火墙过滤规则处理器及其集成的数据包计数功能、日志记录功能、 NAT、dummynet(4) 流量整形器、转发功能、桥接功能和 ipstealth 功能。
FreeBSD 在 /etc/rc.firewall 中提供了一个示例规则集,该规则集定义了几种常见场景的防火墙类型,以帮助新手用户生成适当的规则集。IPFW 提供了一个强大的语法,高级用户可以使用它来创建符合特定环境安全要求的自定义规则集。
本节介绍了如何启用 IPFW,提供了其规则语法的概述,并演示了几个常见配置场景的规则集。
33.4.1. 启用 IPFW
IPFW 已经作为一个可加载的内核模块包含在基本的 FreeBSD 安装中,这意味着不需要自定义内核来启用 IPFW。
对于那些希望将 IPFW 支持静态编译到自定义内核中的用户,请参阅 IPFW 内核选项。
要在启动时配置系统以启用 IPFW ,请将 firewall_enable ="YES" 添加到 /etc/rc.conf 文件中。
# sysrc firewall_enable="YES"要使用 FreeBSD 提供的默认防火墙类型之一,请添加另一行来指定类型:
# sysrc firewall_type="open"可用的类型有:
-
open:允许通过所有流量。 -
client: 仅保护本机。 -
simple:保护整个网络。 -
closed:完全禁用 IP 流量,除了回环接口之外。 -
workstation:使用有状态规则仅保护此计算机。 -
UNKNOWN:禁用防火墙规则的加载。 -
filename: 包含防火墙规则集的文件的完整路径。
如果 firewall_type 被设置为 client 或 simple ,请修改 /etc/rc.firewall 中的默认规则以适应系统的配置。
请注意,filename 类型用于加载自定义规则集。
加载自定义规则集的另一种方法是将 firewall_script 变量设置为包含 IPFW 命令的可执行脚本的绝对路径。本节中使用的示例假设 firewall_script 设置为 /etc/ipfw.rules。
# sysrc firewall_script="/etc/ipfw.rules"要通过 syslogd(8) 启用日志记录,请包含以下行:
# sysrc firewall_logging="YES"|
只有带有 |
没有设置日志限制的 /etc/rc.conf 变量。要限制每个连接尝试中规则被记录的次数,请在 /etc/sysctl.conf 中使用以下行指定数字:
# echo "net.inet.ip.fw.verbose_limit=5" >> /etc/sysctl.conf要通过名为 ipfw0 的专用接口启用日志记录,请将以下行添加到 /etc/rc.conf 中:
# sysrc firewall_logif="YES"然后使用 tcpdump 查看被记录的内容:
# tcpdump -t -n -i ipfw0|
只有在附加了 tcpdump 时,才会出现由于日志记录而产生的额外开销。 |
保存所需的编辑后,启动防火墙。要立即启用日志记录限制,还需设置上述 sysctl 值。
# service ipfw start
# sysctl net.inet.ip.fw.verbose_limit=533.4.2. IPFW 规则语法
当一个数据包进入 IPFW 防火墙时,它会与规则集中的第一条规则进行比较,并按顺序逐条进行,从上到下移动。当数据包与规则的选择参数匹配时,执行规则的动作,并终止该数据包的规则集搜索。这被称为“先中者胜(first match wins)”。如果数据包不匹配任何规则,则被强制 IPFW 默认规则号 65535 捕获,该规则拒绝所有数据包并将其静默丢弃。然而,如果数据包与包含 count、skipto 或 tee 关键字的规则匹配,搜索将继续进行。有关这些关键字如何影响规则处理的详细信息,请参阅 ipfw(8)。
创建 IPFW 规则时,关键字必须按照以下顺序编写。某些关键字是必需的,而其他关键字是可选的。大写字母表示变量,小写字母表示必须在其后出现的变量。 # 符号用于标记注释的开始,可以出现在规则的末尾或单独的一行上。空行将被忽略。
CMD RULE_NUMBER set SET_NUMBER ACTION log LOG_AMOUNT PROTO from SRC SRC_PORT to DST DST_PORT OPTIONS
本节提供了这些关键字及其选项的概述。这不是一个详尽无遗的选项列表。有关创建 IPFW 规则时可用的规则语法的完整描述,请参阅 ipfw(8)。
- CMD
-
每条规则都必须以
ipfw add开头。 - RULE_NUMBER
-
每个规则都与一个从
1到65534的数字相关联。该数字用于指示规则处理的顺序。多个规则可以具有相同的数字,这种情况下它们按照添加的顺序应用。 - SET_NUMBER
-
每个规则与一个从
0到31的集合编号相关联。可以单独禁用或启用集合,从而可以快速添加或删除一组规则。如果未指定 SET_NUMBER ,则规则将被添加到集合0中。 - 动作(ACTION)
-
规则可以与以下动作之一关联。当数据包与规则的选择条件匹配时,将执行指定的动作。
allow | accept | pass | permit:这些关键字是等效的,允许匹配规则的数据包通过。check-state:检查数据包是否与动态状态表匹配。如果找到匹配项,则执行与生成此动态规则相关联的操作,否则转到下一条规则。check-state规则没有选择条件。如果规则集中没有check-state规则,则在第一个keep-state或limit规则处检查动态规则表。count:更新与规则匹配的所有数据包的计数器。搜索将继续进行下一个规则。deny | drop:这两个词都表示静默丢弃与此规则匹配的数据包。还有其他可用的操作。有关详细信息,请参阅 ipfw(8)。
- LOG_AMOUNT
-
当一个数据包与带有
log关键字的规则匹配时,将会向 syslogd(8) 记录一条消息,该消息的设施名称为SECURITY。只有在特定规则的记录的数据包数量不超过指定的 LOG_AMOUNT 时才会发生记录。如果没有指定 LOG_AMOUNT,则限制值将从net.inet.ip.fw.verbose_limit的值中获取。值为零将移除记录限制。一旦达到限制,可以通过清除该规则的记录计数器或数据包计数器来重新启用记录,使用ipfw resetlog命令。在满足所有其他数据包匹配条件之后,进行日志记录,并在对数据包执行最终操作之前。管理员决定在哪些规则上启用日志记录。
- 协议(PROTO)
-
这个可选值可以用来指定在 /etc/protocols 中找到的任何协议名称或编号。
- 源地址(SRC)
-
from关键字后面必须跟着源地址或表示源地址的关键字。地址可以用any、me(在此系统上配置的任何接口的地址)、me6(在此系统上配置的任何 IPv6 地址)或table后跟包含地址列表的查找表的编号来表示。在指定 IP 地址时,可以选择性地跟着 CIDR 掩码或子网掩码。例如,1.2.3.4/25或1.2.3.4:255.255.255.128。 - 源端口(SRC_PORT)
-
可以使用端口号或者从 /etc/services 中的名称来指定可选的源端口。
- 目标地址(DST)
-
to关键字后面必须跟着目标地址或代表目标地址的关键字。在 SRC 部分描述的相同关键字和地址可以用来描述目标。 - 目标端口(DST_PORT)
-
可以使用端口号或者从 /etc/services 文件中的名称来指定可选的目标端口。
- 选项(OPTIONS)
-
源和目的地后面可以跟随几个关键字。顾名思义,OPTIONS 是可选的。常用的选项包括
in或out,用于指定数据包流动的方向,icmptypes后面跟随 ICMP 消息的类型,以及keep-state。当匹配到
keep-state规则时,防火墙将创建一个动态规则,该规则匹配源地址和目标地址以及端口之间的双向流量,使用相同的协议。动态规则功能容易受到 SYN 洪水攻击的资源耗尽问题的影响,该攻击会打开大量的动态规则。为了使用 IPFW 来对抗这种类型的攻击,可以使用
limit选项。该选项通过检查打开的动态规则,计算该规则和 IP 地址组合出现的次数,来限制同时会话的数量。如果该计数大于limit指定的值,数据包将被丢弃。有数十种选项可供选择。有关每个可用选项的描述,请参阅 ipfw(8)。
33.4.3. 示例规则集
本节演示了如何创建一个名为 /etc/ipfw.rules 的示例有状态防火墙规则脚本。在这个示例中,所有连接规则使用 in 或 out 来明确方向。它们还使用 via interface-name 来指定数据包所经过的接口。
|
在首次创建或测试防火墙规则集时,考虑临时设置此可调整项: net.inet.ip.fw.default_to_accept="1" 这将将 ipfw(8) 的默认策略设置为比默认的 |
防火墙脚本首先指示它是一个 Bourne shell 脚本,并清除任何现有的规则。然后它创建 cmd 变量,这样在每个规则的开头就不需要输入 ipfw add 。它还定义了 pif 变量,表示连接到互联网的接口的名称。
#!/bin/sh # Flush out the list before we begin. ipfw -q -f flush # Set rules command prefix cmd="ipfw -q add" pif="dc0" # interface name of NIC attached to Internet
前两条规则允许在可信的内部接口和回环接口上的所有流量通过。
# Change xl0 to LAN NIC interface name $cmd 00005 allow all from any to any via xl0 # No restrictions on Loopback Interface $cmd 00010 allow all from any to any via lo0
下一个规则允许数据包通过,如果它与动态规则表中的现有条目匹配:
$cmd 00101 check-state
下面的规则集定义了内部系统可以与互联网上的主机建立哪些有状态连接:
# Allow access to public DNS # Replace x.x.x.x with the IP address of a public DNS server # and repeat for each DNS server in /etc/resolv.conf $cmd 00110 allow tcp from any to x.x.x.x 53 out via $pif setup keep-state $cmd 00111 allow udp from any to x.x.x.x 53 out via $pif keep-state # Allow access to ISP's DHCP server for cable/DSL configurations. # Use the first rule and check log for IP address. # Then, uncomment the second rule, input the IP address, and delete the first rule $cmd 00120 allow log udp from any to any 67 out via $pif keep-state #$cmd 00120 allow udp from any to x.x.x.x 67 out via $pif keep-state # Allow outbound HTTP and HTTPS connections $cmd 00200 allow tcp from any to any 80 out via $pif setup keep-state $cmd 00220 allow tcp from any to any 443 out via $pif setup keep-state # Allow outbound email connections $cmd 00230 allow tcp from any to any 25 out via $pif setup keep-state $cmd 00231 allow tcp from any to any 110 out via $pif setup keep-state # Allow outbound ping $cmd 00250 allow icmp from any to any out via $pif keep-state # Allow outbound NTP $cmd 00260 allow udp from any to any 123 out via $pif keep-state # Allow outbound SSH $cmd 00280 allow tcp from any to any 22 out via $pif setup keep-state # deny and log all other outbound connections $cmd 00299 deny log all from any to any out via $pif
下一组规则控制来自互联网主机到内部网络的连接。它首先拒绝通常与攻击相关的数据包,然后明确允许特定类型的连接。所有从互联网发起的授权服务都使用 limit 来防止洪水攻击。
# Deny all inbound traffic from non-routable reserved address spaces $cmd 00300 deny all from 192.168.0.0/16 to any in via $pif #RFC 1918 private IP $cmd 00301 deny all from 172.16.0.0/12 to any in via $pif #RFC 1918 private IP $cmd 00302 deny all from 10.0.0.0/8 to any in via $pif #RFC 1918 private IP $cmd 00303 deny all from 127.0.0.0/8 to any in via $pif #loopback $cmd 00304 deny all from 0.0.0.0/8 to any in via $pif #loopback $cmd 00305 deny all from 169.254.0.0/16 to any in via $pif #DHCP auto-config $cmd 00306 deny all from 192.0.2.0/24 to any in via $pif #reserved for docs $cmd 00307 deny all from 204.152.64.0/23 to any in via $pif #Sun cluster interconnect $cmd 00308 deny all from 224.0.0.0/3 to any in via $pif #Class D & E multicast # Deny public pings $cmd 00310 deny icmp from any to any in via $pif # Deny ident $cmd 00315 deny tcp from any to any 113 in via $pif # Deny all Netbios services. $cmd 00320 deny tcp from any to any 137 in via $pif $cmd 00321 deny tcp from any to any 138 in via $pif $cmd 00322 deny tcp from any to any 139 in via $pif $cmd 00323 deny tcp from any to any 81 in via $pif # Deny fragments $cmd 00330 deny all from any to any frag in via $pif # Deny ACK packets that did not match the dynamic rule table $cmd 00332 deny tcp from any to any established in via $pif # Allow traffic from ISP's DHCP server. # Replace x.x.x.x with the same IP address used in rule 00120. #$cmd 00360 allow udp from any to x.x.x.x 67 in via $pif keep-state # Allow HTTP connections to internal web server $cmd 00400 allow tcp from any to me 80 in via $pif setup limit src-addr 2 # Allow inbound SSH connections $cmd 00410 allow tcp from any to me 22 in via $pif setup limit src-addr 2 # Reject and log all other incoming connections $cmd 00499 deny log all from any to any in via $pif
最后一条规则记录所有不符合规则集中任何规则的数据包:
# Everything else is denied and logged $cmd 00999 deny log all from any to any
33.4.4. 内核级网络地址转换(In-kernel NAT)
FreeBSD 的 IPFW 防火墙有两种 NAT 实现:用户空间实现 natd(8) 和更近期的内核 NAT 实现。两者都与 IPFW 配合工作,提供网络地址转换功能。这可以用于提供 Internet 连接共享解决方案,使多台内部计算机可以使用单个公共 IP 地址连接到互联网。
要实现这一点,连接到互联网的 FreeBSD 机器必须充当网关。该系统必须具有两个网络接口卡(NIC),其中一个连接到互联网,另一个连接到内部局域网(LAN)。连接到 LAN 的每台机器应分配一个私有网络空间中的 IP 地址,如 RFC 1918 所定义。
为了启用 IPFW 内核中的 NAT 功能,需要进行一些额外的配置。要在启动时启用内核中的 NAT 支持,必须在 /etc/rc.conf 文件中设置以下内容:
gateway_enable="YES" firewall_enable="YES" firewall_nat_enable="YES"
|
当设置了 |
当规则集包含有状态的规则时,NAT 规则的位置至关重要,并且使用 skipto 操作。skipto 操作需要一个规则编号,以便知道要跳转到哪个规则。下面的示例基于前一节中显示的防火墙规则集进行构建。它添加了一些额外的条目并修改了一些现有规则,以便为内核中的 NAT 配置防火墙。首先添加一些额外的变量,这些变量表示要跳转到的规则编号,keep-state 选项以及将用于减少规则数量的 TCP 端口列表。
#!/bin/sh ipfw -q -f flush cmd="ipfw -q add" skip="skipto 1000" pif=dc0 ks="keep-state" good_tcpo="22,25,37,53,80,443,110"
使用内核级别的 NAT 时,由于 libalias(3) 的架构,需要禁用 TCP 分段卸载(TSO),libalias(3) 是一个作为内核模块实现的库,用于提供 IPFW 的内核级别 NAT 功能。可以使用 ifconfig(8) 在每个网络接口上禁用 TSO,也可以使用 sysctl(8) 在整个系统上禁用 TSO。要在整个系统上禁用 TSO,需要在 /etc/sysctl.conf 中设置以下内容:
net.inet.tcp.tso="0"
还将配置一个 NAT 实例。可以配置多个 NAT 实例,每个实例都有自己的配置。在这个例子中,只需要一个 NAT 实例,即 NAT 实例号 1。配置可以包括一些选项,如:if 表示公共接口,same_ports 确保别名端口和本地端口号映射相同,unreg_only 将只处理未注册(私有)地址空间的 NAT 实例,reset 将帮助保持一个正常运行的 NAT 实例,即使 IPFW 机器的公共 IP 地址发生变化。有关可以传递给单个 NAT 实例配置的所有可能选项,请参阅 ipfw(8)。在配置有状态的 NAT 防火墙时,需要允许将已转换的数据包重新注入防火墙进行进一步处理。可以通过在防火墙脚本的开始处禁用 one_pass 行为来实现这一点。
ipfw disable one_pass ipfw -q nat 1 config if $pif same_ports unreg_only reset
入站 NAT 规则被插入在允许所有受信任和回环接口上的所有流量的两个规则之后,并且在重新组装规则之后,但在 check-state 规则之前。在此示例中,为此 NAT 规则选择的规则编号(例如 100)比前三个规则更高,但比 check-state 规则更低非常重要。此外,由于内核 NAT 的行为,建议在第一个 NAT 规则之前和允许受信任接口上的流量的规则之后放置一个重新组装规则。通常情况下,不应发生 IP 分段,但在处理 IPSEC/ESP/GRE 隧道流量时可能会发生,并且在将完整数据包交给内核 NAT 设备之前需要重新组装片段。
|
在使用用户空间的 natd(8) 时,不需要使用 reassemble 规则,因为 IPFW 的 在这个示例中使用的 NAT 实例和规则编号与由 rc.firewall 创建的默认 NAT 实例和规则编号不匹配。 rc.firewall 是一个设置 FreeBSD 中默认防火墙规则的脚本。 |
$cmd 005 allow all from any to any via xl0 # exclude LAN traffic $cmd 010 allow all from any to any via lo0 # exclude loopback traffic $cmd 099 reass all from any to any in # reassemble inbound packets $cmd 100 nat 1 ip from any to any in via $pif # NAT any inbound packets # Allow the packet through if it has an existing entry in the dynamic rules table $cmd 101 check-state
出站规则已经被修改,将 allow 操作替换为 $skip 变量,表示规则处理将继续在规则 1000 处。七个 tcp 规则已被替换为规则 125,因为 $good_tcpo 变量包含了七个允许的出站端口。
|
请记住,IPFW 的性能主要取决于规则集中存在的规则数量。 |
# Authorized outbound packets $cmd 120 $skip udp from any to x.x.x.x 53 out via $pif $ks $cmd 121 $skip udp from any to x.x.x.x 67 out via $pif $ks $cmd 125 $skip tcp from any to any $good_tcpo out via $pif setup $ks $cmd 130 $skip icmp from any to any out via $pif $ks
入站规则保持不变,除了最后一条规则,它移除了 via$pif,以便捕获入站和出站规则。NAT 规则必须跟随这个最后的出站规则,规则号必须比最后一条规则的号码更高,并且规则号必须被 skipto 动作引用。在这个规则集中,规则号为 1000 的规则处理将所有数据包传递给我们配置的实例进行 NAT 处理。下一条规则允许经过 NAT 处理的任何数据包通过。
$cmd 999 deny log all from any to any $cmd 1000 nat 1 ip from any to any out via $pif # skipto location for outbound stateful rules $cmd 1001 allow ip from any to any
在这个例子中,规则 100、101、125、1000 和 1001 控制出站和入站数据包的地址转换,以便动态状态表中的条目始终注册私有 LANIP 地址。
考虑一个内部的网络浏览器,它通过 80 端口初始化一个新的出站 HTTP 会话。当第一个出站数据包进入防火墙时,它不匹配规则 100 ,因为它是向外而不是向内的。它通过规则 101 ,因为这是第一个数据包,并且尚未被添加到动态状态表中。该数据包最终匹配规则 125 ,因为它是在允许的端口上进行出站,并且具有来自内部局域网的源 IP 地址。匹配此规则后,会执行两个操作。首先,keep-state 操作将一个条目添加到动态状态表中,并执行指定的操作 skipto rule 1000。接下来,数据包经过 NAT 处理并发送到互联网。该数据包到达目标 Web 服务器,生成并发送一个响应数据包。这个新的数据包进入规则集的顶部。它匹配规则 100,并将其目标 IP 地址映射回原始的内部地址。然后,它经过 check-state 规则的处理,在表中被识别为一个现有的会话,并被释放到局域网。
在入站方面,规则集必须拒绝恶意数据包,并仅允许授权的服务。与入站规则匹配的数据包将被发布到动态状态表,并将数据包释放到局域网。作为响应生成的数据包被 check-state 规则识别为属于现有会话。然后,它将被发送到规则 1000 进行网络地址转换(NAT),然后释放到出站接口。
|
从用户空间的 natd(8) 过渡到内核级别的 NAT 可能一开始看起来是无缝的,但有一个小问题。当使用 GENERIC 内核时,当在 /etc/rc.conf 中启用 |
33.4.4.1. 端口重定向
NAT 的一般缺点是 LAN 客户端无法从互联网访问。 LAN 上的客户端可以向外部建立连接,但无法接收传入连接。如果尝试在 LAN 客户端机器上运行互联网服务,这将带来问题。一个简单的解决方法是将 NAT 提供机器上的选定互联网端口重定向到 LAN 客户端。
例如,IRC 服务器运行在客户端 A 上,而 Web 服务器运行在客户端 B 上。为了使其正常工作,必须将接收到的 6667 端口(IRC)和 80 端口(HTTP)的连接重定向到相应的机器上。
使用内核级别的 NAT,所有配置都在 NAT 实例配置中完成。要查看内核级别 NAT 实例可以使用的所有选项,请参考 ipfw(8)。 IPFW 的语法遵循 natd 的语法。redirect_port 的语法如下:
redirect_port proto targetIP:targetPORT[-targetPORT] [aliasIP:]aliasPORT[-aliasPORT] [remoteIP[:remotePORT[-remotePORT]]]
要配置上述示例设置,参数应为:
redirect_port tcp 192.168.0.2:6667 6667 redirect_port tcp 192.168.0.3:80 80
在上述规则集中将这些参数添加到 NAT 实例 1 的配置后,TCP 端口将被端口转发到运行 IRC 和 HTTP 服务的局域网客户机。
ipfw -q nat 1 config if $pif same_ports unreg_only reset \ redirect_port tcp 192.168.0.2:6667 6667 \ redirect_port tcp 192.168.0.3:80 80
可以使用 redirect_port 指示端口范围而不是单个端口。例如,tcp 192.168.0.2:2000-3000 2000-3000 将会将所有在端口 2000 到 3000 上接收到的连接重定向到客户端 A 上的端口 2000 到 3000 。
33.4.4.2. 地址重定向
如果有多个 IP 地址可用,地址重定向非常有用。每个局域网客户端可以通过 ipfw(8) 分配自己的外部 IP 地址,然后 ipfw(8) 将重写来自局域网客户端的出站数据包,使用正确的外部 IP 地址,并将所有进入特定 IP 地址的流量重定向回特定的局域网客户端。这也被称为静态 NAT 。例如,如果可用的 IP 地址为 128.1.1.1、128.1.1.2 和 128.1.1.3,则 128.1.1.1 可以用作 ipfw(8) 机器的外部 IP 地址,而 128.1.1.2 和 128.1.1.3 则被转发回局域网客户端 A 和 B。
redirect_addr 的语法如下,其中 localIP 是局域网客户端的内部 IP 地址,publicIP 是与局域网客户端对应的外部 IP 地址。
redirect_addr localIP publicIP
在这个例子中,参数将被读取为:
redirect_addr 192.168.0.2 128.1.1.2 redirect_addr 192.168.0.3 128.1.1.3
与 redirect_port 类似,这些参数也被放置在 NAT 实例配置中。通过地址重定向,不需要进行端口重定向,因为所有接收到的特定 IP 地址的数据都会被重定向。
ipfw(8) 机器上的外部 IP 地址必须处于活动状态,并且必须与外部接口进行别名设置。有关详细信息,请参阅 rc.conf(5)。
33.4.4.3. 用户空间 NAT
让我们从一个声明开始:用户空间的 NAT 实现:natd(8),比内核中的 NAT 有更多的开销。为了让 natd(8) 翻译数据包,数据包必须从内核复制到用户空间,然后再返回,这带来了额外的开销,而内核中的 NAT 则没有这种开销。
要在启动时启用用户空间 NAT 守护进程 natd(8),以下是在文件 /etc/rc.conf 中的最小配置。其中,natd_interface 设置为连接到互联网的网卡的名称。natd(8) 的 rc(8) 脚本将自动检查是否使用动态 IP 地址,并配置自身以处理该地址。
gateway_enable="YES" natd_enable="YES" natd_interface="rl0"
通常情况下,上述内核 NAT 的规则集也可以与 natd(8) 一起使用。唯一的例外是内核 NAT 实例的配置 (ipfw -q nat 1 config …) ,不需要与重组规则 99 一起使用,因为其功能已包含在 divert 操作中。规则编号 100 和 1000 需要稍作修改,如下所示。
$cmd 100 divert natd ip from any to any in via $pif $cmd 1000 divert natd ip from any to any out via $pif
要配置端口或地址重定向,使用与内核 NAT 相似的语法。然而,现在,与内核 NAT 不同,我们不再在规则集脚本中指定配置,而是最好在配置文件中配置 natd(8)。为了做到这一点,必须通过 /etc/rc.conf 传递一个额外的标志,指定配置文件的路径。
natd_flags="-f /etc/natd.conf"
|
指定的文件必须包含一行一个的配置选项列表。有关配置文件和可能的变量的更多信息,请参阅 natd(8)。以下是两个示例条目,每行一个: redirect_port tcp 192.168.0.2:6667 6667 redirect_addr 192.168.0.3 128.1.1.3 |
33.4.5. IPFW 命令
ipfw 可以在防火墙运行时手动添加或删除单个规则。使用这种方法的问题是,当系统重新启动时,所有更改都会丢失。建议将所有规则写入一个文件,并在启动时使用该文件加载规则,并在该文件更改时替换当前运行的防火墙规则。
ipfw 是一种将运行中的防火墙规则显示到控制台屏幕的有用方法。 IPFW 计费功能会为每个规则动态创建一个计数器,用于计算与规则匹配的每个数据包。在测试规则的过程中,列出规则及其计数器是确定规则是否按预期工作的一种方式。
列出所有正在运行的规则的顺序:
# ipfw list列出所有正在运行的规则,并显示规则最后匹配的时间戳:
# ipfw -t list下一个示例列出了匹配规则的会计信息和数据包计数,以及规则本身。第一列是规则编号,其后是匹配的数据包和字节数,然后是规则本身。
# ipfw -a list除了静态规则外,列出动态规则:
# ipfw -d list为了显示已过期的动态规则:
# ipfw -d -e list将计数器归零:
# ipfw zero将编号为 NUM 的规则的计数器清零:
# ipfw zero NUM33.4.5.1. 记录防火墙消息
即使启用了日志功能,IPFW 也不会自动生成任何规则日志。防火墙管理员决定哪些规则将被记录,并在这些规则中添加 log 关键字。通常只有拒绝规则会被记录。习惯上,在规则集中将“ipfw default deny everything”规则复制一份,并在最后一条规则中包含 log 关键字。这样,就可以查看所有未匹配规则集中任何规则的数据包。
日志记录是一把双刃剑。如果不小心处理,过多的日志数据或者 DoS 攻击可能会填满磁盘的日志文件。日志消息不仅会被写入 syslogd,还会显示在根控制台屏幕上,很快就会变得令人讨厌。
IPFIREWALL_VERBOSE_LIMIT=5 内核选项限制了发送给 syslogd(8) 的连续消息数量,这些消息涉及给定规则的数据包匹配。当内核中启用了这个选项时,关于特定规则的连续消息数量被限制在指定的数量上。200 条相同的日志消息并没有什么好处。当这个选项设置为五时,关于特定规则的五条连续消息将被记录到 syslogd 中,其余相同的连续消息将被计数并以类似以下的短语发布到 syslogd 中:
last message repeated 45 times
所有已记录的数据包消息默认写入到 /var/log/security,该路径在 /etc/syslog.conf 中定义。
33.4.5.2. 构建规则脚本
大多数经验丰富的 IPFW 用户会创建一个包含规则的文件,并以与脚本运行兼容的方式编码它们。这样做的主要好处是防火墙规则可以批量刷新,而无需重新启动系统来激活它们。这种方法在测试新规则时非常方便,因为可以根据需要执行该过程多次。作为脚本,可以使用符号替换来将常用值替换为多个规则中的值。
这个示例脚本与 sh(1)、csh(1) 和 tcsh(1) shells 使用的语法兼容。符号替换字段以美元符号 ($) 为前缀。符号字段没有 $ 前缀。用于填充符号字段的值必须用双引号 ("") 括起来。
像这样开始规则文件:
############### start of example ipfw rules script ############# # ipfw -q -f flush # Delete all rules # Set defaults oif="tun0" # out interface odns="192.0.2.11" # ISP's DNS server IP address cmd="ipfw -q add " # build rule prefix ks="keep-state" # just too lazy to key this each time $cmd 00500 check-state $cmd 00502 deny all from any to any frag $cmd 00501 deny tcp from any to any established $cmd 00600 allow tcp from any to any 80 out via $oif setup $ks $cmd 00610 allow tcp from any to $odns 53 out via $oif setup $ks $cmd 00611 allow udp from any to $odns 53 out via $oif $ks ################### End of example ipfw rules script ############
规则并不重要,因为这个例子的重点是如何填充符号替换字段。
如果上面的示例位于 /etc/ipfw.rules 文件中,则可以使用以下命令重新加载规则:
# sh /etc/ipfw.rules/etc/ipfw.rules 可以位于任何位置,文件的名称也可以是任意的。
通过手动运行这些命令也可以实现相同的效果:
# ipfw -q -f flush
# ipfw -q add check-state
# ipfw -q add deny all from any to any frag
# ipfw -q add deny tcp from any to any established
# ipfw -q add allow tcp from any to any 80 out via tun0 setup keep-state
# ipfw -q add allow tcp from any to 192.0.2.11 53 out via tun0 setup keep-state
# ipfw -q add 00611 allow udp from any to 192.0.2.11 53 out via tun0 keep-state33.4.6. IPFW 内核选项
options IPFIREWALL # enables IPFW options IPFIREWALL_VERBOSE # enables logging for rules with log keyword to syslogd(8) options IPFIREWALL_VERBOSE_LIMIT=5 # limits number of logged packets per-entry options IPFIREWALL_DEFAULT_TO_ACCEPT # sets default policy to pass what is not explicitly denied options IPFIREWALL_NAT # enables basic in-kernel NAT support options LIBALIAS # enables full in-kernel NAT support options IPFIREWALL_NAT64 # enables in-kernel NAT64 support options IPFIREWALL_NPTV6 # enables in-kernel IPv6 NPT support options IPFIREWALL_PMOD # enables protocols modification module support options IPDIVERT # enables NAT through natd(8)
|
IPFW 可以作为内核模块加载:上述选项默认情况下被构建为模块,或者可以在运行时使用可调节参数进行设置。 |
33.5. IPFILTER (IPF)
IPFILTER,也称为 IPF,是一个跨平台的开源防火墙,已经移植到多个操作系统,包括 FreeBSD、NetBSD、OpenBSD 和 Solaris™。
IPFILTER 是一个位于内核的防火墙和 NAT 机制,可以由用户空间程序进行控制和监控。可以使用 ipf 设置或删除防火墙规则,使用 ipnat 设置或删除 NAT 规则,使用 ipfstat 打印 IPFILTER 内核部分的运行时统计信息,并可以使用 ipmon 将 IPFILTER 的操作记录到系统日志文件中。
IPF 最初使用“最后匹配规则获胜(the last matching rule wins)”的规则处理逻辑,并且只使用无状态规则。此后,IPF 已经进行了增强,包括了 quick 和 keep state 选项。
IPF FAQ 位于 http://www.phildev.net/ipf/index.html。IPFilter 邮件列表的可搜索存档可在 http://marc.info/?l=ipfilter 上找到。
本手册的这一部分重点介绍了与 FreeBSD 相关的 IPF。它提供了包含 quick 和 keep state 选项的规则示例。
33.5.1. 启用 IPF
IPF 被包含在基本的 FreeBSD 安装中作为一个可加载的内核模块,这意味着不需要自定义内核来启用 IPF 。
对于喜欢将 IPF 支持静态编译到自定义内核中的用户,请参考 配置 FreeBSD 内核 中的说明。以下内核选项可用:
options IPFILTER options IPFILTER_LOG options IPFILTER_LOOKUP options IPFILTER_DEFAULT_BLOCK
options IPFILTER 启用对 IPFILTER 的支持,options IPFILTER_LOG 启用使用 ipl 伪设备对于每个带有 log 关键字的规则进行 IPF 日志记录,IPFILTER_LOOKUP 启用 IP 池以加快 IP 查找速度,而 options IPFILTER_DEFAULT_BLOCK 更改默认行为,使得任何不符合防火墙 pass 规则的数据包都被阻止。
要在启动时配置系统以启用 IPF,请将以下条目添加到 /etc/rc.conf 文件中。这些条目还将启用日志记录和 default pass all。要将默认策略更改为 block all 而无需编译自定义内核,请记住在规则集的末尾添加一个 block all 规则。
ipfilter_enable="YES" # Start ipf firewall
ipfilter_rules="/etc/ipf.rules" # loads rules definition text file
ipv6_ipfilter_rules="/etc/ipf6.rules" # loads rules definition text file for IPv6
ipmon_enable="YES" # Start IP monitor log
ipmon_flags="-Ds" # D = start as daemon
# s = log to syslog
# v = log tcp window, ack, seq
# n = map IP & port to names
如果需要 NAT 功能,还需要添加以下行:
gateway_enable="YES" # Enable as LAN gateway ipnat_enable="YES" # Start ipnat function ipnat_rules="/etc/ipnat.rules" # rules definition file for ipnat
然后,现在开始启动 IPF:
# service ipfilter start
要加载防火墙规则,请使用 ipf 指定规则集文件的名称。可以使用以下命令替换当前运行的防火墙规则:
# ipf -Fa -f /etc/ipf.rules-Fa 选项会清空所有内部规则表,-f 选项用于指定包含要加载的规则的文件。
这提供了对自定义规则集进行更改并使用最新的规则副本更新正在运行的防火墙的能力,而无需重新启动系统。这种方法对于测试新规则非常方便,因为可以根据需要执行该过程多次。
有关此命令可用的其他标志的详细信息,请参考 ipf(8)。
33.5.2. IPF 规则语法
本节描述了用于创建有状态规则的 IPF 规则语法。在创建规则时,请记住,除非规则中出现了 quick 关键字,否则每个规则都会按顺序读取,应用的是 最后匹配的规则。这意味着,即使第一个匹配数据包的规则是 pass,如果后面有一个匹配的规则是 block,数据包将被丢弃。示例规则集可以在 /usr/share/examples/ipfilter 中找到。
创建规则时,使用 # 字符来标记注释的开始,并且可以出现在规则的末尾,以解释该规则的功能,或者独占一行。任何空行都会被忽略。
在规则中使用的关键字必须按照特定的顺序从左到右进行编写。一些关键字是必需的,而其他一些是可选的。一些关键字具有子选项,这些子选项可能是关键字本身,并且还可以包含更多的子选项。关键字的顺序如下所示,其中大写字母表示变量,小写字母表示必须在其后面的变量之前出现的关键字:
ACTION DIRECTION OPTIONS proto PROTO_TYPE from SRC_ADDR SRC_PORT to DST_ADDR DST_PORT TCP_FLAG|ICMP_TYPE keep state STATE
本节描述了每个关键字及其选项。这不是一个详尽无遗的选项列表。有关在创建 IPF 规则和使用每个关键字的示例时可以使用的规则语法的完整描述,请参阅 ipf(5)。
- 动作(ACTION)
-
action 关键字指示如果数据包与该规则匹配,应该采取什么操作。每个规则都 必须 有一个动作。以下动作被识别:
block:丢弃该数据包。pass:允许数据包通过。log:生成一条日志记录。count:计算数据包和字节数的数量,可以提供规则使用频率的指示。auth:将数据包排队,以便由另一个程序进一步处理。call:提供对内置于 IPF 中的函数的访问,允许执行更复杂的操作。decapsulate:移除任何头部以便处理数据包的内容。 - 方向(DIRECTION)
-
接下来,每个规则必须明确指定流量的方向,使用以下关键字之一:
in:规则应用于入站数据包。out: 规则应用于出站数据包。all: 规则适用于任何方向。如果系统有多个接口,可以在指定方向时同时指定接口。一个例子是
in on fxp0。 - 选项(OPTIONS)
-
选项是可选的。然而,如果指定了多个选项,则必须按照这里显示的顺序使用。
log:在执行指定的操作时,数据包头部的内容将被写入到 ipl(4) 数据包日志伪设备中。quick: 如果一个数据包符合这个规则,那么规则指定的操作将会执行,并且对于这个数据包,不会再进行任何后续规则的处理。on:必须跟随着ifconfig(8)中显示的接口名称。只有当数据包通过指定的接口以指定的方向传输时,规则才会匹配。使用
log关键字时,可以按照以下顺序使用以下限定词:body:表示在报文头部之后,将记录报文内容的前 128 个字节。first:如果log关键字与keep state选项一起使用,建议使用此选项,以便仅记录触发的数据包,而不是与状态连接匹配的每个数据包。还有其他选项可用于指定错误返回消息。有关更多详细信息,请参阅 ipf(5)。
- 协议类型(PROTO_TYPE)
-
协议类型是可选的。然而,如果规则需要指定 SRC_PORT 或 DST_PORT ,则协议类型是必需的,因为它定义了协议的类型。在指定协议类型时,使用
proto关键字,后面跟着来自 /etc/protocols 的协议号或名称。示例协议名称包括tcp、udp或icmp。如果指定了 PROTO_TYPE,但未指定 SRC_PORT 或 DST_PORT,则该规则将匹配该协议的所有端口号。 - 源地址
-
from关键字是必需的,并且后面跟着一个关键字,表示数据包的来源。来源可以是主机名、IP 地址后跟 CIDR 掩码、地址池或关键字all。有关示例,请参阅 ipf(5)。没有办法匹配那些不容易用点分十进制形式或掩码长度表示的 IP 地址范围。可以使用 net-mgmt/ipcalc 软件包或 port 来简化 CIDR 掩码的计算。有关该实用程序的更多信息,请访问其网页:http://jodies.de/ipcalc[http://jodies.de/ipcalc]。
- 源端口(SRC_PORT)
-
源端口号是可选的。但是,如果使用了源端口号,规则中必须首先定义 PROTO_TYPE。端口号还必须在
proto关键字之前。支持多种不同的比较运算符:` =
(等于),!=(不等于),<`(小于),>(大于),⇐(小于等于)和>=(大于等于)。要指定端口范围,请将两个端口号放在
<>(小于和大于)、><(大于和小于)或:(大于或等于和小于或等于)之间。 - 目标地址
-
to关键字是必需的,后面跟着一个关键字,表示数据包的目的地。与 SRC_ADDR 类似,它可以是主机名、IP 地址后跟 CIDR 掩码、地址池或关键字all。 - 目标端口(DST_PORT)
-
与 SRC_PORT 类似,目标端口号是可选的。然而,如果使用了目标端口号,规则中必须首先定义 PROTO_TYPE 。端口号还必须在
proto关键字之前。 - TCP_FLAG|ICMP_TYPE
-
如果指定
tcp作为 PROTO_TYPE,那么可以使用字母来指定标志,其中每个字母代表用于确定连接状态的可能的 TCP 标志之一。可能的值包括:S(SYN),A(ACK),P(PSH),F(FIN),U(URG),R(RST),C(CWN)和E(ECN)。如果指定了
icmp作为 PROTO_TYPE,可以指定要匹配的 ICMP 类型。有关允许的类型,请参阅 ipf(5)。 - 状态(STATE)
-
如果一个
pass规则包含keep state,IPF 将在其动态状态表中添加一个条目,并允许匹配连接的后续数据包。IPF 可以跟踪 TCP、UDP 和 ICMP 会话的状态。任何 IPF 可以确定是活动会话的一部分的数据包,即使是不同的协议,也将被允许通过。在 IPF 中,目标要通过连接到公共互联网的接口发送的数据包首先会与动态状态表进行匹配检查。如果数据包与活动会话对话的下一个预期数据包匹配,它将离开防火墙,并且会话对话流的状态将在动态状态表中更新。不属于已经活动会话的数据包将会与出站规则集进行检查。从连接到公共互联网的接口进入的数据包首先会与动态状态表进行匹配检查。如果数据包与活动会话的下一个预期数据包匹配,它将离开防火墙,并且会话对话流的状态将在动态状态表中更新。不属于已经活动会话的数据包将会与入站规则集进行检查。
在
keep state之后可以添加几个关键字。如果使用了这些关键字,它们可以设置各种控制有状态过滤的选项,例如设置连接限制或连接时长。请参考 ipf(5) 以获取可用选项及其描述的列表。
33.5.3. 示例规则集
本节演示如何创建一个示例规则集,该规则集仅允许与 pass 规则匹配的服务,并阻止所有其他服务。
FreeBSD 使用回环接口(lo0)和 IP 地址 127.0.0.1 进行内部通信。防火墙规则集必须包含允许这些内部使用的数据包自由传输的规则:
# no restrictions on loopback interface pass in quick on lo0 all pass out quick on lo0 all
与互联网连接的公共接口用于授权和控制所有出站和入站连接的访问。如果一个或多个接口连接到私有网络,那些内部接口可能需要规则来允许源自局域网的数据包在内部网络之间或连接到互联网的接口之间流动。规则集应该分为三个主要部分:任何受信任的内部接口、通过公共接口的出站连接和通过公共接口的入站连接。
这两条规则允许所有流量通过一个名为 xl0 的受信任的局域网接口传输。
# no restrictions on inside LAN interface for private network pass out quick on xl0 all pass in quick on xl0 all
公共接口的出站和入站部分的规则应该将最常匹配的规则放在不常匹配的规则之前,而该部分的最后一条规则应该阻止并记录该接口和方向的所有数据包。
这组规则定义了名为 dc0 的公共接口的出站部分。这些规则保持状态并标识内部系统被授权用于公共互联网访问的特定服务。所有规则都使用 quick 并指定适当的端口号和(如果适用)目标地址。
# interface facing Internet (outbound) # Matches session start requests originating from or behind the # firewall, destined for the Internet. # Allow outbound access to public DNS servers. # Replace x.x.x.x with address listed in /etc/resolv.conf. # Repeat for each DNS server. pass out quick on dc0 proto tcp from any to x.x.x.x port = 53 flags S keep state pass out quick on dc0 proto udp from any to x.x.x.x port = 53 keep state # Allow access to ISP's specified DHCP server for cable or DSL networks. # Use the first rule, then check log for the IP address of DHCP server. # Then, uncomment the second rule, replace z.z.z.z with the IP address, # and comment out the first rule pass out log quick on dc0 proto udp from any to any port = 67 keep state #pass out quick on dc0 proto udp from any to z.z.z.z port = 67 keep state # Allow HTTP and HTTPS pass out quick on dc0 proto tcp from any to any port = 80 flags S keep state pass out quick on dc0 proto tcp from any to any port = 443 flags S keep state # Allow email pass out quick on dc0 proto tcp from any to any port = 110 flags S keep state pass out quick on dc0 proto tcp from any to any port = 25 flags S keep state # Allow NTP pass out quick on dc0 proto tcp from any to any port = 37 flags S keep state # Allow FTP pass out quick on dc0 proto tcp from any to any port = 21 flags S keep state # Allow SSH pass out quick on dc0 proto tcp from any to any port = 22 flags S keep state # Allow ping pass out quick on dc0 proto icmp from any to any icmp-type 8 keep state # Block and log everything else block out log first quick on dc0 all
公共接口入站部分的规则示例首先阻止所有不需要的数据包。这样可以减少最后一个规则记录的数据包数量。
# interface facing Internet (inbound) # Block all inbound traffic from non-routable or reserved address spaces block in quick on dc0 from 192.168.0.0/16 to any #RFC 1918 private IP block in quick on dc0 from 172.16.0.0/12 to any #RFC 1918 private IP block in quick on dc0 from 10.0.0.0/8 to any #RFC 1918 private IP block in quick on dc0 from 127.0.0.0/8 to any #loopback block in quick on dc0 from 0.0.0.0/8 to any #loopback block in quick on dc0 from 169.254.0.0/16 to any #DHCP auto-config block in quick on dc0 from 192.0.2.0/24 to any #reserved for docs block in quick on dc0 from 204.152.64.0/23 to any #Sun cluster interconnect block in quick on dc0 from 224.0.0.0/3 to any #Class D & E multicast # Block fragments and too short tcp packets block in quick on dc0 all with frags block in quick on dc0 proto tcp all with short # block source routed packets block in quick on dc0 all with opt lsrr block in quick on dc0 all with opt ssrr # Block OS fingerprint attempts and log first occurrence block in log first quick on dc0 proto tcp from any to any flags FUP # Block anything with special options block in quick on dc0 all with ipopts # Block public pings and ident block in quick on dc0 proto icmp all icmp-type 8 block in quick on dc0 proto tcp from any to any port = 113 # Block incoming Netbios services block in log first quick on dc0 proto tcp/udp from any to any port = 137 block in log first quick on dc0 proto tcp/udp from any to any port = 138 block in log first quick on dc0 proto tcp/udp from any to any port = 139 block in log first quick on dc0 proto tcp/udp from any to any port = 81
每当规则上有带有 log first 选项的日志消息时,运行 ipfstat -hio 来评估该规则被匹配的次数。大量的匹配可能表明系统正在遭受攻击。
入站部分的其余规则定义了允许从互联网发起的连接。最后一条规则拒绝了所有未在本节中明确允许的连接。
# Allow traffic in from ISP's DHCP server. Replace z.z.z.z with # the same IP address used in the outbound section. pass in quick on dc0 proto udp from z.z.z.z to any port = 68 keep state # Allow public connections to specified internal web server pass in quick on dc0 proto tcp from any to x.x.x.x port = 80 flags S keep state # Block and log only first occurrence of all remaining traffic. block in log first quick on dc0 all
33.5.4. 配置 NAT
要启用 NAT,请将以下语句添加到 /etc/rc.conf 文件中,并指定包含 NAT 规则的文件的名称:
gateway_enable="YES" ipnat_enable="YES" ipnat_rules="/etc/ipnat.rules"
NAT 规则是灵活的,可以实现许多不同的功能,以满足商业和家庭用户的需求。这里介绍的规则语法已经简化,以展示常见用法。有关完整的规则语法描述,请参考 ipnat(5)。
NAT 规则的基本语法如下所示,其中 map 是规则的开始,IF 应替换为外部接口的名称:
map IF LAN_IP_RANGE -> PUBLIC_ADDRESS
LAN_IP_RANGE 是内部客户端使用的 IP 地址范围。通常情况下,它是一个私有地址范围,比如 192.168.1.0/24 。PUBLIC_ADDRESS 可以是静态外部 IP 地址,也可以是关键字 0/32,表示分配给 IF 的 IP 地址。
在 IPF 中,当一个数据包从局域网带有公共目的地到达防火墙时,它首先通过防火墙规则集的出站规则。然后,数据包被传递到 NAT 规则集,该规则集从上到下进行读取,第一个匹配的规则获胜。IPF 会将每个 NAT 规则与数据包的接口名称和源 IP 地址进行测试。当数据包的接口名称与 NAT 规则匹配时,将检查数据包在私有局域网中的源 IP 地址是否落在 LAN_IP_RANGE 指定的 IP 地址范围内。如果匹配成功,数据包的源 IP 地址将被重写为 PUBLIC_ADDRESS 指定的公共 IP 地址。IPF 会在其内部 NAT 表中发布一个条目,以便当数据包从互联网返回时,可以将其映射回原始的私有 IP 地址,然后将其传递给防火墙规则进行进一步处理。
对于拥有大量内部系统或多个子网的网络来说,将每个私有 IP 地址汇集到一个公共 IP 地址中的过程会成为一个资源问题。有两种方法可以解决这个问题。
第一种方法是分配一段端口作为源端口使用。通过添加 portmap 关键字,可以指示 NAT 仅使用指定范围内的源端口。
map dc0 192.168.1.0/24 -> 0/32 portmap tcp/udp 20000:60000
或者,使用 auto 关键字,告诉 NAT 确定可用于使用的端口:
map dc0 192.168.1.0/24 -> 0/32 portmap tcp/udp auto
第二种方法是使用一个公共地址池。当局域网地址太多无法适应单个公共地址,并且有一块公共 IP 地址可用时,这种方法非常有用。这些公共地址可以作为一个池, NAT 会从中选择一个 IP 地址,将数据包的地址映射为其外部传输时的地址。
公共 IP 地址的范围可以使用网络掩码或 CIDR 表示法来指定。这两个规则是等价的:
map dc0 192.168.1.0/24 -> 204.134.75.0/255.255.255.0 map dc0 192.168.1.0/24 -> 204.134.75.0/24
常见做法是将公共可访问的 Web 服务器或邮件服务器隔离到内部网络段。这些服务器的流量仍然需要经过 NAT ,但需要进行端口重定向以将入站流量定向到正确的服务器。例如,要将使用内部地址 10.0.10.25 的 Web 服务器映射到其公共 IP 地址 20.20.20.5,请使用以下规则:
rdr dc0 20.20.20.5/32 port 80 -> 10.0.10.25 port 80
如果它是唯一的 Web 服务器,这个规则也会起作用,因为它会将所有外部 HTTP 请求重定向到 10.0.10.25。
rdr dc0 0.0.0.0/0 port 80 -> 10.0.10.25 port 80
IPF 内置了一个可以与 NAT 一起使用的 FTP 代理。它监视所有出站流量,以检测主动或被动的 FTP 连接请求,并动态创建临时过滤规则,其中包含 FTP 数据通道使用的端口号。这样就不需要打开大范围的高阶端口来进行 FTP 连接。
在这个例子中,第一条规则调用代理来处理内部局域网的出站 FTP 流量。第二条规则将 FTP 流量从防火墙传递到互联网,第三条规则处理内部局域网的所有非 FTP 流量。
map dc0 10.0.10.0/29 -> 0/32 proxy port 21 ftp/tcp map dc0 0.0.0.0/0 -> 0/32 proxy port 21 ftp/tcp map dc0 10.0.10.0/29 -> 0/32
FTP 的 map 规则在 NAT 规则之前,这样当一个数据包匹配到 FTP 规则时, FTP 代理会创建临时过滤规则,以便让 FTP 会话数据包通过并进行 NAT。所有不是 FTP 的局域网数据包如果匹配到第三条规则,也会进行 NAT 处理。
如果没有 FTP 代理,将需要以下防火墙规则。请注意,如果没有代理,需要允许所有大于 1024 的端口:
# Allow out LAN PC client FTP to public Internet # Active and passive modes pass out quick on rl0 proto tcp from any to any port = 21 flags S keep state # Allow out passive mode data channel high order port numbers pass out quick on rl0 proto tcp from any to any port > 1024 flags S keep state # Active mode let data channel in from FTP server pass in quick on rl0 proto tcp from any to any port = 20 flags S keep state
每当编辑包含 NAT 规则的文件时,运行 ipnat 命令并使用 -CF 选项来删除当前的 NAT 规则,并清空动态转换表的内容。同时,使用 -f 选项并指定要加载的 NAT 规则集的名称。
# ipnat -CF -f /etc/ipnat.rules显示 NAT 统计信息:
# ipnat -s要列出 NAT 表的当前映射:
# ipnat -l要打开详细模式并显示与规则处理、活动规则和表项相关的信息:
# ipnat -v33.5.5. 查看 IPF 统计信息
IPF 包括 ipfstat(8),可用于检索和显示统计信息,这些统计信息是在数据包通过防火墙时匹配规则时收集的。统计信息从上次启动防火墙或使用 ipf -Z 将其重置为零的上次重置以来累积。
默认的 ipfstat 输出如下所示:
input packets: blocked 99286 passed 1255609 nomatch 14686 counted 0
output packets: blocked 4200 passed 1284345 nomatch 14687 counted 0
input packets logged: blocked 99286 passed 0
output packets logged: blocked 0 passed 0
packets logged: input 0 output 0
log failures: input 3898 output 0
fragment state(in): kept 0 lost 0
fragment state(out): kept 0 lost 0
packet state(in): kept 169364 lost 0
packet state(out): kept 431395 lost 0
ICMP replies: 0 TCP RSTs sent: 0
Result cache hits(in): 1215208 (out): 1098963
IN Pullups succeeded: 2 failed: 0
OUT Pullups succeeded: 0 failed: 0
Fastroute successes: 0 failures: 0
TCP cksum fails(in): 0 (out): 0
Packet log flags set: (0)有几个选项可供选择。当使用 -i 参数表示入站规则,或使用 -o 参数表示出站规则时,该命令将检索并显示内核当前安装和使用的相应过滤规则列表。如果想要同时看到规则编号,可以加上 -n 参数。例如,ipfstat -on 将显示带有规则编号的出站规则表:
@1 pass out on xl0 from any to any
@2 block out on dc0 from any to any
@3 pass out quick on dc0 proto tcp/udp from any to any keep state在每个规则前加上匹配次数的计数,请使用 -h 选项。例如,ipfstat -oh 显示出站内部规则表,每个规则前都有它的使用次数计数。
2451423 pass out on xl0 from any to any
354727 block out on dc0 from any to any
430918 pass out quick on dc0 proto tcp/udp from any to any keep state要以类似于 top(1) 的格式显示状态表,请使用 ipfstat -t 命令。当防火墙遭受攻击时,此选项可以识别和查看攻击数据包。可选的子标志提供了实时监控目标或源 IP、端口或协议的能力。有关详细信息,请参阅 ipfstat(8)。
33.5.6. IPF 日志记录
IPF 提供了 ipmon 工具,可以将防火墙的日志信息以人类可读的格式写入。使用该工具需要首先按照 配置 FreeBSD 内核 中的说明,在自定义内核中添加 options IPFILTER_LOG 选项。
该命令通常以守护进程模式运行,以提供连续的系统日志文件,以便可以回顾过去事件的记录。由于 FreeBSD 内置了 syslogd(8) 设施来自动轮转系统日志,因此默认的 rc.conf ipmon_flags 语句使用了 -Ds 选项。
ipmon_flags="-Ds" # D = start as daemon
# s = log to syslog
# v = log tcp window, ack, seq
# n = map IP & port to names
日志记录提供了事后审查的能力,可以查看诸如哪些数据包被丢弃、它们来自哪些地址以及它们的目的地是什么等信息。这些信息在追踪攻击者方面非常有用。
一旦在 rc.conf 中启用了日志记录功能,并使用 service ipmon start 启动后,IPF 将只记录包含 log 关键字的规则。防火墙管理员决定哪些规则应该被记录,通常只有拒绝规则会被记录。习惯上,在规则集中的最后一个规则中包含 log 关键字。这样可以查看所有未匹配规则集中任何规则的数据包。
默认情况下,ipmon -Ds 模式使用 local0 作为日志设备。以下日志级别可用于进一步分离记录的数据:
LOG_INFO - packets logged using the "log" keyword as the action rather than pass or block.
LOG_NOTICE - packets logged which are also passed
LOG_WARNING - packets logged which are also blocked
LOG_ERR - packets which have been logged and which can be considered short due to an incomplete header为了将 IPF 设置为将所有数据记录到 /var/log/ipfilter.log 文件中,首先创建一个空文件:
# touch /var/log/ipfilter.log然后,要将所有记录的消息写入指定的文件,请将以下语句添加到 /etc/syslog.conf 文件中:
local0.* /var/log/ipfilter.log
要激活更改并指示 syslogd(8) 读取修改后的 /etc/syslog.conf,请运行 service syslogd reload。
不要忘记编辑 /etc/newsyslog.conf 来轮转新的日志文件。
ipmon 生成的消息由以空格分隔的数据字段组成。所有消息都包含以下共同字段:
-
数据包接收日期。
-
数据包接收时间。格式为 HH:MM:SS.F,表示小时、分钟、秒和秒的小数部分。
-
处理数据包的接口名称。
-
规则的组和规则编号的格式为
@0:17。 -
动作:
p表示通过,b表示阻止,S表示短数据包,n表示未匹配任何规则,L表示日志规则。 -
地址写作三个字段:源地址和端口由逗号分隔,→ 符号,以及目标地址和端口。例如:
209.53.17.22,80 → 198.73.220.17,1722。 -
以协议名称或编号后跟
PR:例如,PR tcp。 -
len后面跟着数据包的头部长度和总长度:例如,len 20 40。
如果数据包是 TCP 数据包,则会有一个额外的字段,以连字符开头,后面跟着对应于设置的任何标志的字母。请参考 ipf(5) 以获取字母和它们的标志列表。
如果数据包是一个 ICMP 数据包,那么在末尾将会有两个字段:第一个字段始终是“icmp”,下一个字段是 ICMP 消息和子消息类型,用斜杠分隔。例如:对于一个端口不可达的消息,表示为 icmp 3/3。
33.6. 黑名单服务
Blacklistd 是一个守护进程,监听套接字以接收来自其他守护进程的有关连接尝试失败或成功的通知。它最常用于阻止在开放端口上进行过多的连接尝试。一个典型的例子是在互联网上运行的 SSH 收到大量来自机器人或脚本的密码猜测和入侵尝试。使用 blacklistd ,守护进程可以通知防火墙在多次尝试后创建一个过滤规则,以阻止来自单个源的过多连接尝试。 Blacklistd 最初在 NetBSD 上开发,并在版本 7 中首次出现。FreeBSD 11 从 NetBSD 导入了 blacklistd。
本章介绍了如何设置和配置 blacklistd ,并提供了如何使用它的示例。读者应该熟悉基本的防火墙概念,如规则。有关详细信息,请参阅防火墙章节。示例中使用了 PF,但在 FreeBSD 上可用的其他防火墙也应该能够与 blacklistd 一起使用。
33.6.1. 启用 Blacklistd
blacklistd 的主要配置存储在 blacklistd.conf(5) 中。还有一些命令行选项可用于更改 blacklistd 的运行时行为。重启后的持久配置应存储在 /etc/blacklistd.conf 中。要在系统启动时启用守护进程,请在 /etc/rc.conf 中添加一行 blacklistd_enable,如下所示:
# sysrc blacklistd_enable=yes要手动启动服务,请运行以下命令:
# service blacklistd start33.6.2. 创建一个 Blacklistd 规则集
黑名单规则在 blacklistd.conf(5) 中配置,每行一个条目。每个规则包含一个由空格或制表符分隔的元组。规则可以属于 local 或 remote,分别适用于运行 blacklistd 的机器或外部来源。
33.6.2.1. 本地规则
一个本地规则的示例 blacklistd.conf 条目如下:
[local] ssh stream * * * 3 24h
在 [local] 部分之后的所有规则都被视为本地规则(这是默认情况),适用于本地机器。当遇到 [remote] 部分时,其后的所有规则都被视为远程机器规则。
规则由七个字段组成,字段之间用制表符或空格分隔。前四个字段用于标识应该被加入黑名单的流量。接下来的三个字段定义了黑名单的行为。通配符用星号(*)表示,可以匹配该字段中的任何内容。第一个字段定义了位置,对于本地规则来说,这些是网络端口。位置字段的语法如下:
[address|interface][/mask][:port]
地址可以以数字格式指定为 IPv4 ,也可以以方括号指定为 IPv6 。还可以使用类似 em0 的接口名称。
套接字类型由第二个字段定义。TCP 套接字的类型是 stream,而 UDP 则表示为 dgram 。上面的示例使用 TCP,因为 SSH 正在使用该协议。
协议可以在 blacklistd 规则的第三个字段中使用。可以使用以下协议:tcp,udp,tcp6,udp6 或数字。通常使用通配符(如示例中)来匹配所有协议,除非有理由通过特定协议区分流量。
在第四个字段中,定义了报告事件的守护进程的有效用户或所有者。可以在这里使用用户名或 UID ,也可以使用通配符(参见上面的示例规则)。
数据包过滤规则的名称由第五个字段声明,该字段开始规则的行为部分。默认情况下,blacklistd 将所有阻止的数据包放在名为 blacklistd 的 pf 锚点下,就像这样在 pf.conf 中:
anchor "blacklistd/*" in on $ext_if block in pass out
对于单独的块列表,可以在此字段中使用锚点名称。在其他情况下,通配符就足够了。当名称以连字符(-)开头时,意味着应该使用带有默认规则名称前缀的锚点。使用连字符的修改示例如下所示:
ssh stream * * -ssh 3 24h
有了这样的规则,任何新的阻止列表规则都会被添加到一个名为 blacklistd-ssh 的锚点中。
为了针对单个规则违规封锁整个子网,可以在规则名称中使用 /。这会导致名称的剩余部分被解释为要应用于规则中指定的地址的掩码。例如,这个规则将封锁与 /24 相邻的每个地址。
22 stream tcp * */24 3 24h
|
在这里指定正确的协议是很重要的。 IPv4 和 IPv6 对待 /24 的方式不同,这就是为什么在这个规则的第三个字段中不能使用“ * ”。 |
这条规则定义了如果该网络中的任何一个主机表现不当,那么该网络上的其他所有内容也将被阻止。
第六个字段称为 nfail,它设置了在特定远程 IP 被列入黑名单之前所需的登录失败次数。当在此位置使用通配符时,意味着永远不会发生阻止。在上面的示例规则中,定义了三次限制,这意味着在一次连接中尝试三次登录 SSH 后,该 IP 将被阻止。
在 blacklistd 规则定义中,最后一个字段指定了主机被加入黑名单的时间长度。默认单位是秒,但也可以使用后缀 m、h 和 d 分别指定分钟、小时和天。
整个示例规则的意思是,当通过 SSH 进行三次身份验证后,将为该主机生成一个新的 PF 阻止规则。规则匹配是通过首先按顺序检查本地规则来进行的,从最具体到最不具体。当发生匹配时,将应用 remote 规则,并且匹配的 remote 规则将更改名称、nfail 和 disable 字段。
33.6.2.2. 远程规则
远程规则用于指定 blacklistd 根据当前评估的远程主机来改变其行为的方式。远程规则中的每个字段与本地规则中的字段相同,唯一的区别在于 blacklistd 使用它们的方式。为了解释这一点,我们使用以下示例规则:
[remote] 203.0.113.128/25 * * * =/25 = 48h
地址字段可以是 IP 地址(IPv4 或 IPv6),端口或两者兼有。这允许为特定的远程地址范围设置特殊规则,就像这个例子中一样。套接字类型、协议和所有者字段的解释与本地规则完全相同。
然而,名称字段是不同的:远程规则中的等号(=)告诉 blacklistd 使用匹配的本地规则的值。这意味着防火墙规则条目被采用,并添加了 /25 前缀(一个 255.255.255.128 的网络掩码)。当来自该地址范围的连接被列入黑名单时,整个子网都会受到影响。在这里也可以使用 PF 锚点名称,这样 blacklistd 将为该地址块添加到该名称的锚点的规则。当指定通配符时,将使用默认表。
可以为地址定义 nfail 列中的自定义失败次数。这对于特定规则的例外情况非常有用,可以允许某人对规则应用更宽松或更宽容的登录尝试。当在第六个字段中使用星号时,阻止功能将被禁用。
远程规则允许对登录尝试的限制进行更严格的执行,相比于来自本地网络(如办公室)的尝试。
33.6.3. 黑名单客户端配置
在 FreeBSD 中有几个软件包可以利用 blacklistd 的功能。其中最重要的两个是 ftpd(8) 和 sshd(8) ,用于阻止过多的连接尝试。要在 SSH 守护程序中激活 blacklistd,请将以下行添加到 /etc/ssh/sshd_config 文件中:
UseBlacklist yes
在进行这些更改后,重新启动 sshd 以使其生效。
对于 ftpd(8) 的黑名单功能已启用,可以使用 -B 选项,在 /etc/inetd.conf 文件中或者作为 /etc/rc.conf 文件中的一个标志来设置,如下所示:
ftpd_flags="-B"
这就是使这些程序与 blacklistd 通信所需的全部内容。
33.6.4. 黑名单管理
Blacklistd 为用户提供了一个名为 blacklistctl(8) 的管理工具。它显示由 blacklistd.conf(5) 中定义的规则所屏蔽的地址和网络。要查看当前被屏蔽的主机列表,可以使用 dump 和 -b 组合,如下所示。
# blacklistctl dump -b
address/ma:port id nfail last access
213.0.123.128/25:22 OK 6/3 2019/06/08 14:30:19这个例子显示,来自地址范围 213.0.123.128/25 的端口 22 上有 3 次允许的尝试中有 6 次失败。列出的尝试次数比允许的次数多,因为 SSH 允许客户端在单个 TCP 连接上尝试多次登录。正在进行中的连接不会被 blacklistd 停止。最后一次连接尝试在输出的 last access 列中列出。
要查看此主机在封锁列表上的剩余时间,请在上一个命令中添加 -r 。
# blacklistctl dump -br
address/ma:port id nfail remaining time
213.0.123.128/25:22 OK 6/3 36s在这个例子中,还有 36 秒的时间,直到这个主机不再被阻止。
33.6.5. 从阻止列表中移除主机
有时候在剩余时间到期之前需要将主机从阻止列表中移除。不幸的是,blacklistd 中没有这样的功能。然而,可以使用 pfctl 将地址从 PF 表中移除。对于每个被阻止的端口,在 /etc/pf.conf 中的 blacklistd 锚点内定义了一个子锚点。例如,如果有一个用于阻止端口 22 的子锚点,它被称为 blacklistd/22。在该子锚点内有一个包含被阻止地址的表。该表的名称是 port 加上端口号。在这个例子中,它将被称为 port22。有了这些信息,现在可以使用 pfctl(8) 来显示所有列出的地址。
# pfctl -a blacklistd/22 -t port22 -T show
...
213.0.123.128/25
...在确定要从列表中解除阻止的地址之后,以下命令将其从列表中移除:
# pfctl -a blacklistd/22 -t port22 -T delete 213.0.123.128/25该地址现在已从 PF 中移除,但仍会显示在 blacklistctl 列表中,因为它不知道在 PF 中所做的任何更改。blacklistd 数据库中的条目最终会过期并从其输出中删除。 如果主机再次匹配 blacklistd 中的阻止规则,则该条目将被再次添加。
Chapter 34. 高级网络
34.1. 简介
本章涵盖了一些高级网络主题。
阅读完本章后,您将了解:
-
网关和路由的基础知识。
-
如何设置 USB 网络共享。
-
如何设置 IEEE® 802.11 和 Bluetooth® 设备。
-
如何将 FreeBSD 配置为桥接模式。
-
如何设置网络 PXE 引导。
-
如何在 FreeBSD 中启用和利用 Common Address Redundancy Protocol (CARP) 的功能。
-
如何在 FreeBSD 上配置多个 VLAN。
-
配置蓝牙耳机。
在阅读本章之前,你应该:
-
了解 /etc/rc 脚本的基础知识。
-
熟悉基本的网络术语。
-
了解 FreeBSD 上的基本网络配置(FreeBSD 网络)。
-
了解如何配置和安装新的 FreeBSD 内核(配置 FreeBSD 内核)。
-
了解如何安装额外的第三方软件(安装应用程序:软件包和 Ports)。
34.2. 网关和路由
路由 是一种机制,允许系统找到到另一个系统的网络路径。路由 是一对定义好的地址,表示“目标(destination)”和“网关(gateway)”。路由指示当尝试到达指定的目标时,通过指定的网关发送数据包。目标有三种类型:单个主机、子网和“默认”。如果没有其他路由适用,将使用“默认路由”。网关也有三种类型:单个主机、接口(也称为链路)和以太网硬件(MAC)地址。已知的路由存储在路由表中。
本节提供了路由基础知识的概述。然后演示了如何将 FreeBSD 系统配置为路由器,并提供了一些故障排除技巧。
34.2.1. 路由基础知识
要查看 FreeBSD 系统的路由表,请使用 netstat(1) 命令。
% netstat -r
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default outside-gw UGS 37 418 em0
localhost localhost UH 0 181 lo0
test0 0:e0:b5:36:cf:4f UHLW 5 63288 re0 77
10.20.30.255 link#1 UHLW 1 2421
example.com link#1 UC 0 0
host1 0:e0:a8:37:8:1e UHLW 3 4601 lo0
host2 0:e0:a8:37:8:1e UHLW 0 5 lo0 =>
host2.example.com link#1 UC 0 0
224 link#1 UC 0 0这个示例中的条目如下:
- 默认
-
这个表中的第一条路由指定了
默认(default)路由。当本地系统需要与远程主机建立连接时,它会检查路由表以确定是否存在已知路径。如果远程主机与表中的条目匹配,系统会检查是否可以使用该条目中指定的接口进行连接。如果目标与任何条目都不匹配,或者所有已知路径都失败,则系统将使用默认路由的条目。对于局域网上的主机, 默认路由中的
网关(Gateway)字段设置为直接连接到互联网的系统。在阅读此条目时,请验证Flags列是否指示网关可用(UG)。如果一台机器本身作为外部世界的网关,那么它的默认路由将是互联网服务提供商(ISP)的网关机器。
- 本地主机
-
第二条路由是
localhost(本地主机)路由。在Netif列中指定的接口为 lo0 ,也被称为环回设备。这表示所有发送到该目的地的流量都应该是内部流量,而不是通过网络发送出去。 - MAC 地址
-
以
0:e0:开头的地址是 MAC 地址。在 FreeBSD 中,它会自动识别本地以太网上的任何主机(例如test0),并在以太网接口(re0)上添加一个用于该主机的路由。这种类型的路由有一个超时时间,在Expire列中显示,如果主机在特定时间内没有响应,路由将被自动删除。这些主机是使用路由信息协议(RIP)进行识别的,该协议根据最短路径确定计算到本地主机的路由。 - 子网
-
FreeBSD 会自动为本地子网添加子网路由。在这个例子中,
10.20.30.255是子网10.20.30的广播地址,example.com是与该子网关联的域名。link#1表示机器上的第一个以太网卡。本地网络主机和本地子网的路由由一个名为 routed(8) 的守护进程自动配置。如果该进程未运行,则只会存在由管理员静态定义的路由。
- 主机
-
host1行是通过其以太网地址引用主机。由于它是发送主机,FreeBSD 知道要使用回环接口(lo0),而不是以太网接口。两个
host2行表示使用 ifconfig(8) 创建的别名。在 lo0 接口之后的⇒符号表示除了环回地址之外,还设置了一个别名。这样的路由只会出现在支持别名的主机上,而本地网络上的所有其他主机将会有一个link#1行用于这样的路由。 - 224
-
最后一行(目标子网
224)处理多播。
每个路由的各种属性可以在 Flags 列中看到。 常见的路由表标志 总结了一些这些标志及其含义:
| 标志 | 目的 |
|---|---|
U |
路由已激活(上行)。 |
H |
路由目的地是一个单独的主机。 |
G |
将任何东西发送到这个目的地,然后由这个网关决定从哪里发送。 |
S |
此路由是静态配置的。 |
C |
为机器连接克隆一个基于此路由的新路由。这种类型的路由通常用于本地网络。 |
W |
该路由是基于本地区域网络(克隆)路由进行自动配置的。 |
L |
路由涉及对以太网(链路)硬件的引用。 |
在 FreeBSD 系统上,可以通过在 /etc/rc.conf 文件中指定默认网关的 IP 地址来定义默认路由:
defaultrouter="10.20.30.1"
还可以使用 route 命令手动添加路由:
# route add default 10.20.30.1请注意,手动添加的路由在重新启动后将不会保留。有关手动操作网络路由表的更多信息,请参阅 route(8) 。
34.2.2. 使用静态路由配置路由器
如果一个 FreeBSD 系统是一个双主机系统,它可以被配置为网络的默认网关或路由器。双主机系统是指至少连接在两个不同网络上的主机。通常,每个网络都连接到一个独立的网络接口,尽管可以使用 IP 别名来将多个地址绑定到一个物理接口上,每个地址位于不同的子网上。
为了使系统在接口之间转发数据包,FreeBSD 必须配置为路由器。互联网标准和良好的工程实践阻止了 FreeBSD 项目默认启用此功能,但可以通过将以下行添加到 [/etc/rc.conf] 来配置在启动时启动:
gateway_enable="YES" # Set to YES if this host will be a gateway
要立即启用路由功能,请将 sysctl(8) 变量 net.inet.ip.forwarding 设置为 1 。要停止路由功能,请将此变量重置为 0。
路由器的路由表需要额外的路由,以便知道如何到达其他网络。路由可以通过手动添加静态路由或使用路由协议自动学习来添加。静态路由适用于小型网络,本节描述了如何为小型网络添加静态路由条目。
|
对于大型网络来说,静态路由很快就变得不可扩展。 FreeBSD 附带了标准的 BSD 路由守护程序 routed(8),它提供了 RIP 协议的版本 1 和 2 以及 IRDP 协议。可以使用 net/quagga 包或端口安装 BGP 和 OSPF 路由协议的支持。 |
考虑以下网络:
在这种情况下,RouterA 是一台充当互联网路由器的 FreeBSD 机器。它设置了一个默认路由到 10.0.0.1 ,使其能够与外部世界连接。RouterB 已经配置为使用 192.168.1.1 作为其默认网关。
在添加任何静态路由之前,RouterA 上的路由表如下所示:
% netstat -nr
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 10.0.0.1 UGS 0 49378 xl0
127.0.0.1 127.0.0.1 UH 0 6 lo0
10.0.0.0/24 link#1 UC 0 0 xl0
192.168.1.0/24 link#2 UC 0 0 xl1根据当前的路由表,RouterA 没有到达 192.168.2.0/24 网络的路由。以下命令将使用 192.168.1.2 作为下一跳,将 Internal Net 2 网络添加到 RouterA 的路由表中:
# route add -net 192.168.2.0/24 192.168.1.2现在,RouterA 可以访问 192.168.2.0/24 网络上的任何主机。然而,如果 FreeBSD 系统重新启动,路由信息将不会持久化。如果需要静态路由持久化,将其添加到 /etc/rc.conf 文件中。
# Add Internal Net 2 as a persistent static route static_routes="internalnet2" route_internalnet2="-net 192.168.2.0/24 192.168.1.2"
static_routes 配置变量是一个由空格分隔的字符串列表,其中每个字符串引用一个路由名称。变量 route_internalnet2 包含了该路由名称的静态路由。
在 static_routes 中使用多个字符串可以创建多个静态路由。以下是添加 192.168.0.0/24 和 192.168.1.0/24 网络的静态路由的示例:
static_routes="net1 net2" route_net1="-net 192.168.0.0/24 192.168.0.1" route_net2="-net 192.168.1.0/24 192.168.1.1"
34.2.3. 故障排除
当一个地址空间被分配给一个网络时,服务提供商会配置他们的路由表,以便将所有网络流量发送到该站点的链路上。但是外部站点如何知道将其数据包发送到网络的 ISP 呢?
有一个系统负责跟踪所有分配的地址空间,并定义它们与互联网骨干网的连接点,即负责在国内外承载互联网流量的主干线路。每个骨干机器都有一个主表的副本,该表将特定网络的流量引导到特定的骨干运营商,然后通过服务提供商链路一直传递,直到到达特定的网络。
服务提供商的任务是向骨干站点宣传他们是连接点,从而为站点提供内部路径。这被称为路由传播。
有时候,路由传播存在问题,导致一些站点无法连接。也许最有用的用于尝试找出路由中断位置的命令是 traceroute。当 ping 失败时,它非常有用。
使用 traceroute 命令时,需要指定要连接的远程主机的地址。输出结果将显示沿着尝试路径的网关主机,最终要么到达目标主机,要么因为连接不上而终止。更多信息,请参考 traceroute(8)。
34.2.4. 多播考虑因素
FreeBSD 原生支持多播应用程序和多播路由。在 FreeBSD 上运行多播应用程序不需要任何特殊配置。支持多播路由需要将以下选项编译到自定义内核中:
options MROUTING
可以使用 net/mrouted 包或 port 安装多播路由守护程序 mrouted。该守护程序实现了 DVMRP 多播路由协议,并通过编辑 /usr/local/etc/mrouted.conf 来配置以设置隧道和 DVMRP。安装 mrouted 还会安装 map-mbone 和 mrinfo,以及它们的相关手册页。请参考这些手册页获取配置示例。
|
在许多多播安装中,DVMRP 协议大多被 PIM 协议取代。有关更多信息,请参阅 pim(4) 。 |
34.3. 虚拟主机
FreeBSD 的常见用途之一是虚拟站点托管,其中一个服务器在网络上表现为多个服务器。这是通过将多个网络地址分配给单个接口来实现的。
一个给定的网络接口有一个“真实”的地址,可以有任意数量的“别名”地址。这些别名通常是通过在 /etc/rc.conf 中添加别名条目来添加的,如下面的示例所示:
# sysrc ifconfig_fxp0_alias0="inet xxx.xxx.xxx.xxx netmask xxx.xxx.xxx.xxx"别名条目必须以 alias0 开头,使用连续的数字,例如 alias0,alias1 等等。配置过程将在第一个缺失的数字处停止。
别名网络掩码的计算非常重要。对于给定的接口,必须有一个地址能正确表示网络的网络掩码。任何其他落在该网络内的地址都必须具有全为 1 的网络掩码,可以表示为 255.255.255.255 或 0xffffffff。
例如,考虑 fxp0 接口连接到两个网络的情况:10.1.1.0 的子网掩码为 255.255.255.0,202.0.75.16 的子网掩码为 255.255.255.240。系统需要配置为出现在范围 10.1.1.1 到 10.1.1.5 和 202.0.75.17 到 202.0.75.20 中。给定网络范围中只有第一个地址应具有真实的子网掩码。其余的地址(10.1.1.2 到 10.1.1.5 和 202.0.75.18 到 202.0.75.20)必须配置为子网掩码 255.255.255.255。
以下是配置适配器以适应此场景的 /etc/rc.conf 条目:
# sysrc ifconfig_fxp0="inet 10.1.1.1 netmask 255.255.255.0"
# sysrc ifconfig_fxp0_alias0="inet 10.1.1.2 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias1="inet 10.1.1.3 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias2="inet 10.1.1.4 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias3="inet 10.1.1.5 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias4="inet 202.0.75.17 netmask 255.255.255.240"
# sysrc ifconfig_fxp0_alias5="inet 202.0.75.18 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias6="inet 202.0.75.19 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias7="inet 202.0.75.20 netmask 255.255.255.255"用空格分隔的 IP 地址范围列表更简单地表达这个概念。第一个地址将使用指定的子网掩码,而其他地址将使用子网掩码 255.255.255.255。
# sysrc ifconfig_fxp0_aliases="inet 10.1.1.1-5/24 inet 202.0.75.17-20/28"34.4. 无线高级认证
FreeBSD 支持多种连接无线网络的方式。本节介绍如何进行高级身份验证以连接无线网络。
要建立连接并进行基本身份验证以连接到无线网络,可以参考网络章节中的 Connection and Authentication to a Wireless Network 部分来了解如何操作。
34.4.1. WPA 与 EAP-TLS
使用 WPA 的第二种方式是通过 802.1X 后端认证服务器。在这种情况下,WPA 被称为 WPA 企业版,以区别于较不安全的 WPA 个人版。WPA 企业版中的认证是基于可扩展认证协议(EAP)的。
EAP 不带有加密方法。相反,EAP 被嵌入在一个加密隧道中。有许多 EAP 认证方法,但 EAP-TLS、EAP-TTLS 和 EAP-PEAP 是最常见的。
EAP 与传输层安全性(EAP-TLS)是一种得到广泛支持的无线认证协议,因为它是第一个被 Wi-Fi 联盟 认证的 EAP 方法。EAP-TLS 需要三个证书来运行:安装在所有设备上的证书颁发机构(CA)的证书,用于认证服务器的服务器证书,以及每个无线客户端的一个客户端证书。在这种 EAP 方法中,认证服务器和无线客户端通过展示各自的证书来相互认证,然后验证这些证书是由组织的 CA 签名的。
与以前一样,配置是通过 /etc/wpa_supplicant.conf 进行的:
network={
ssid="freebsdap" (1)
proto=RSN (2)
key_mgmt=WPA-EAP (3)
eap=TLS (4)
identity="loader" (5)
ca_cert="/etc/certs/cacert.pem" (6)
client_cert="/etc/certs/clientcert.pem" (7)
private_key="/etc/certs/clientkey.pem" (8)
private_key_passwd="freebsdmallclient" (9)
}
| 1 | 这个字段表示网络名称( SSID )。 <.> 这个示例使用了 RSN IEEE® 802.11i 协议,也被称为 WPA2。 <.> key_mgmt 行指定了要使用的密钥管理协议。在这个示例中,使用的是使用 EAP 认证的 WPA。 <.> 这个字段表示连接的 EAP 方法。 <.> identity 字段包含了 EAP 的身份字符串。 <.> ca_cert 字段指定了 CA 证书文件的路径名。这个文件用于验证服务器证书。 <.> client_cert 行给出了客户端证书文件的路径名。这个证书是每个无线客户端的独特证书。 <.> private_key 字段是客户端证书私钥文件的路径名。 <.> private_key_passwd 字段包含了私钥的密码短语。 |
然后,将以下行添加到 /etc/rc.conf 文件中:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
下一步是启动界面:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUAL还可以使用 wpa_supplicant(8) 和 ifconfig(8) 手动启动接口。
34.4.2. WPA 与 EAP-TTLS
使用 EAP-TLS,认证服务器和客户端都需要证书。使用 EAP-TTLS,客户端证书是可选的。这种方法类似于一个 Web 服务器,即使访问者没有客户端证书,也会创建一个安全的 SSL 隧道。EAP-TTLS 使用加密的 TLS 隧道来安全传输认证数据。
所需的配置可以添加到 /etc/wpa_supplicant.conf 文件中:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=TTLS (1)
identity="test" (2)
password="test" (3)
ca_cert="/etc/certs/cacert.pem" (4)
phase2="auth=MD5" (5)
}
| 1 | 这个字段指定了连接的 EAP 方法。 <.> identity 字段包含了在加密的 TLS 隧道内进行 EAP 身份验证的身份字符串。<.> password 字段包含了 EAP 身份验证的密码。 <.> ca_cert 字段指示 CA 证书文件的路径名。这个文件用于验证服务器证书。 <.> 这个字段指定了在加密的 TLS 隧道中使用的身份验证方法。在这个例子中,使用了 EAP 和 MD5-Challenge 。“内部身份验证”阶段通常被称为“第二阶段”。 |
接下来,将以下行添加到 /etc/rc.conf 文件中:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
下一步是启动界面:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 21
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUAL34.4.3. WPA 与 EAP-PEAP
|
PEAPv0/EAP-MSCHAPv2 是最常见的 PEAP 方法。在本章中,术语 PEAP 用于指代该方法。 |
Protected EAP(PEAP)是作为 EAP-TTLS 的替代方案而设计的,在 EAP-TLS 之后是最常用的 EAP 标准。在一个混合操作系统的网络中,PEAP 应该是仅次于 EAP-TLS 的最受支持的标准。
PEAP 与 EAP-TTLS 类似,它使用服务器端证书来通过在客户端和认证服务器之间创建加密的 TLS 隧道来验证客户端,从而保护后续的认证信息交换。 PEAP 认证与 EAP-TTLS 不同之处在于,它以明文方式广播用户名,只有密码在加密的 TLS 隧道中发送。而 EAP-TTLS 将同时使用 TLS 隧道传输用户名和密码。
将以下行添加到 /etc/wpa_supplicant.conf 以配置 EAP-PEAP 相关设置:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=PEAP (1)
identity="test" (2)
password="test" (3)
ca_cert="/etc/certs/cacert.pem" (4)
phase1="peaplabel=0" (5)
phase2="auth=MSCHAPV2" (6)
}
| 1 | 这个字段指定了连接的 EAP 方法。 <.> identity 字段包含了在加密的 TLS 隧道内进行 EAP 认证的身份字符串。 <.> password 字段包含了 EAP 认证的密码。 <.> ca_cert 字段指示了 CA 证书文件的路径名。这个文件用于验证服务器证书。 <.> 这个字段包含了第一阶段认证的参数,即 TLS 隧道。根据使用的认证服务器,指定一个特定的标签进行认证。大多数情况下,标签将是"client EAP encryption",可以通过使用 peaplabel = 0 来设置。更多信息可以在 wpa_supplicant.conf(5) 中找到。 <.> 这个字段指定了在加密的 TLS 隧道中使用的认证协议。在 PEAP 的情况下,它是 auth = MSCHAPV2。 |
将以下内容添加到 [/etc/rc.conf] 文件中:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
然后,启动界面:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 21
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUAL34.5. 无线自组网模式
IBSS 模式,也称为自组网模式,旨在用于点对点连接。例如,要在机器 A 和 B 之间建立一个自组网,选择两个 IP 地址和一个 SSID。
在 A 上:
# ifconfig wlan0 create wlandev ath0 wlanmode adhoc
# ifconfig wlan0 inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:c3:0d:ac
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <adhoc>
status: running
ssid freebsdap channel 2 (2417 Mhz 11g) bssid 02:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burstadhoc 参数表示接口正在以 IBSS 模式运行。
B 现在应该能够检测到 A:
# ifconfig wlan0 create wlandev ath0 wlanmode adhoc
# ifconfig wlan0 up scan
SSID/MESH ID BSSID CHAN RATE S:N INT CAPS
freebsdap 02:11:95:c3:0d:ac 2 54M -64:-96 100 IS WME输出中的 I 确认了 A 处于自组网模式。现在,将 B 配置为不同的 IP 地址:
# ifconfig wlan0 inet 192.168.0.2 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <adhoc>
status: running
ssid freebsdap channel 2 (2417 Mhz 11g) bssid 02:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burst现在,A 和 B 都准备好交换信息了。
34.5.1. FreeBSD 主机访问点
FreeBSD 可以充当访问点(AP),从而无需购买硬件 AP 或运行自组网。当 FreeBSD 机器充当网关连接到另一个网络(如互联网)时,这一点尤其有用。
34.5.1.1. 基本设置
在将 FreeBSD 机器配置为 AP 之前,必须为无线网卡配置适当的网络支持和所使用的安全协议。有关更多详细信息,请参阅 [network-wireless-basic] 。
|
目前,用于 Windows® 驱动程序的 NDIS 驱动程序包装器不支持 AP 操作。只有原生的 FreeBSD 无线驱动程序支持 AP 模式。 |
一旦加载了无线网络支持,检查无线设备是否支持主机模式接入点模式,也称为 hostap 模式:
# ifconfig wlan0 create wlandev ath0
# ifconfig wlan0 list caps
drivercaps=6f85edc1<STA,FF,TURBOP,IBSS,HOSTAP,AHDEMO,TXPMGT,SHSLOT,SHPREAMBLE,MONITOR,MBSS,WPA1,WPA2,BURST,WME,WDS,BGSCAN,TXFRAG>
cryptocaps=1f<WEP,TKIP,AES,AES_CCM,TKIPMIC>此输出显示了该卡的功能。HOSTAP 一词确认了该无线网卡可以充当 AP 。还列出了各种支持的加密算法:WEP、TKIP 和 AES。这些信息表明可以在 AP 上使用哪些安全协议。
在创建网络伪设备时,无线设备只能被设置为 hostap 模式,因此必须先销毁先前创建的设备:
# ifconfig wlan0 destroy在设置其他参数之前,使用正确的选项重新生成。
# ifconfig wlan0 create wlandev ath0 wlanmode hostap
# ifconfig wlan0 inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap mode 11g channel 1再次使用 ifconfig(8) 命令查看 wlan0 接口的状态:
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:c3:0d:ac
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <hostap>
status: running
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burst dtimperiod 1 -dfshostap 参数表示接口正在以基于主机的访问点模式运行。
可以通过在 /etc/rc.conf 文件中添加以下行来在启动时自动进行接口配置:
wlans_ath0="wlan0" create_args_wlan0="wlanmode hostap" ifconfig_wlan0="inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap mode 11g channel 1"
34.5.1.2. 无身份验证或加密的基于主机的接入点
虽然不建议在没有任何身份验证或加密的情况下运行 AP,但这是检查 AP 是否工作的简单方法。这种配置对于调试客户端问题也很重要。
一旦配置了 AP,从另一台无线机器上发起扫描以找到 AP:
# ifconfig wlan0 create wlandev ath0
# ifconfig wlan0 up scan
SSID/MESH ID BSSID CHAN RATE S:N INT CAPS
freebsdap 00:11:95:c3:0d:ac 1 54M -66:-96 100 ES WME客户端机器找到了 AP 并且可以与其关联:
# ifconfig wlan0 inet 192.168.0.2 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet OFDM/54Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 bmiss 7
scanvalid 60 bgscan bgscanintvl 300 bgscanidle 250 roam:rssi 7
roam:rate 5 protmode CTS wme burst34.5.1.3. WPA2 基于主机的接入点
本节重点介绍使用 WPA2 安全协议设置 FreeBSD 访问点。有关 WPA 和基于 WPA 的无线客户端配置的更多详细信息,请参阅 [network-wireless-wpa] 。
hostapd[8] 守护进程用于处理 WPA2 启用的访问点上的客户端身份验证和密钥管理。
在充当 AP 的 FreeBSD 机器上执行以下配置操作。一旦 AP 正确工作,可以在启动时通过在 /etc/rc.conf 文件中添加以下行来自动启动 hostapd(8) :
hostapd_enable="YES"
在尝试配置 hostapd(8) 之前,请先配置 基本设置 中介绍的基本设置。
34.5.1.3.1. WPA2-PSK 是一种 Wi-Fi 网络安全协议,它使用预共享密钥(PSK)来进行身份验证和加密。
WPA2-PSK 适用于无法或不希望使用后端认证服务器的小型网络。
配置是在 /etc/hostapd.conf 中完成的:
interface=wlan0 (1) debug=1 (2) ctrl_interface=/var/run/hostapd (3) ctrl_interface_group=wheel (4) ssid=freebsdap (5) wpa=2 (6) wpa_passphrase=freebsdmall (7) wpa_key_mgmt=WPA-PSK (8) wpa_pairwise=CCMP (9)
| 1 | 用于访问点的无线接口。 <.> 在执行 hostapd(8) 期间使用的详细程度。值为 1 表示最低级别。 <.> hostapd(8) 用于存储与外部程序(如 hostapd_cli(8))通信的域套接字文件的路径名。在此示例中使用默认值。 <.> 允许访问控制接口文件的组。 <.> 将出现在无线扫描中的无线网络名称或 SSID。 <.> 启用 WPA 并指定所需的 WPA 身份验证协议。值为 2 配置 AP 为 WPA2,推荐使用。仅在需要过时的 WPA 时设置为 1。 <.> 用于 WPA 身份验证的 ASCII 密码。 <.> 要使用的密钥管理协议。此示例设置为 WPA-PSK 。 <.> 访问点接受的加密算法。在此示例中,仅接受 CCMP (AES)密码。 CCMP 是 TKIP 的替代方案,在可能的情况下强烈推荐使用。仅当有无法使用 CCMP 的设备时才应允许使用 TKIP。 |
下一步是启动 hostapd(8) :
# service hostapd forcestart# ifconfig wlan0
wlan0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 04:f0:21:16:8e:10
inet6 fe80::6f0:21ff:fe16:8e10%wlan0 prefixlen 64 scopeid 0x9
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
media: IEEE 802.11 Wireless Ethernet autoselect mode 11na <hostap>
status: running
ssid No5ignal channel 36 (5180 MHz 11a ht/40+) bssid 04:f0:21:16:8e:10
country US ecm authmode WPA2/802.11i privacy MIXED deftxkey 2
AES-CCM 2:128-bit AES-CCM 3:128-bit txpower 17 mcastrate 6 mgmtrate 6
scanvalid 60 ampdulimit 64k ampdudensity 8 shortgi wme burst
dtimperiod 1 -dfs
groups: wlan一旦 AP 运行起来,客户端就可以与其关联。更多详细信息请参见 [network-wireless-wpa]。可以使用 ifconfig wlan0 list sta 命令查看与 AP 关联的设备。
34.6. USB 网络共享
许多手机提供通过 USB 共享数据连接的选项(通常称为“网络共享”)。此功能使用 RNDIS、CDC 或自定义的 Apple® iPhone®/iPad® 协议之一。
在连接设备之前,将适当的驱动程序加载到内核中:
# kldload if_urndis
# kldload if_cdce
# kldload if_ipheth一旦设备连接上,ue_0_ 将可用于像普通网络设备一样使用。请确保设备上已启用“USB 网络共享”选项。
要使此更改永久生效并在启动时将驱动程序作为模块加载,将以下适当的行放置在 /boot/loader.conf 中:
if_urndis_load="YES"
if_cdce_load="YES"
if_ipheth_load="YES"34.7. 蓝牙
蓝牙是一种无线技术,用于在 2.4 GHz 无线频段中创建个人网络,其范围为 10 米。网络通常是由便携设备(如手机、手持设备和笔记本电脑)自动形成的。与 Wi-Fi 无线技术不同,蓝牙提供更高级的服务配置文件,例如类似 FTP 的文件服务器、文件推送、语音传输、串行线仿真等。
本节描述了在 FreeBSD 系统上使用 USB 蓝牙适配器的方法。然后,它介绍了各种蓝牙协议和实用工具。
34.7.1. 加载蓝牙支持
在 FreeBSD 中,蓝牙堆栈是使用 netgraph(4) 框架实现的。ng_ubt(4) 支持各种各样的蓝牙 USB 适配器。基于 Broadcom BCM2033 的蓝牙设备由 ubtbcmfw(4) 和 ng_ubt(4) 驱动程序支持。3Com 蓝牙 PC 卡 3CRWB60-A 由 ng_bt3c(4) 驱动程序支持。基于串口和 UART 的蓝牙设备由 sio(4)、 ng_h4(4) 和 hcseriald(8) 驱动程序支持。
在连接设备之前,确定设备使用的是上述驱动程序中的哪一个,然后加载该驱动程序。例如,如果设备使用的是 ng_ubt(4) 驱动程序:
# kldload ng_ubt如果在系统启动期间将蓝牙设备连接到系统上,可以通过将驱动程序添加到 /boot/loader.conf 来配置系统在引导时加载模块。
ng_ubt_load="YES"
一旦驱动程序加载完成,插入 USB dongle。如果驱动程序加载成功,类似以下内容的输出将出现在控制台和 /var/log/messages 文件中:
ubt0: vendor 0x0a12 product 0x0001, rev 1.10/5.25, addr 2
ubt0: Interface 0 endpoints: interrupt=0x81, bulk-in=0x82, bulk-out=0x2
ubt0: Interface 1 (alt.config 5) endpoints: isoc-in=0x83, isoc-out=0x3,
wMaxPacketSize=49, nframes=6, buffer size=294要启动和停止蓝牙堆栈,请使用其启动脚本。在拔下设备之前停止堆栈是一个好主意。启动蓝牙堆栈可能需要启动 hcsecd(8) 。启动堆栈时,输出应类似于以下内容:
# service bluetooth start ubt0
BD_ADDR: 00:02:72:00:d4:1a
Features: 0xff 0xff 0xf 00 00 00 00 00
<3-Slot> <5-Slot> <Encryption> <Slot offset>
<Timing accuracy> <Switch> <Hold mode> <Sniff mode>
<Park mode> <RSSI> <Channel quality> <SCO link>
<HV2 packets> <HV3 packets> <u-law log> <A-law log> <CVSD>
<Paging scheme> <Power control> <Transparent SCO data>
Max. ACL packet size: 192 bytes
Number of ACL packets: 8
Max. SCO packet size: 64 bytes
Number of SCO packets: 834.7.2. 查找其他蓝牙设备
主机控制器接口(HCI)提供了一种统一的方法来访问蓝牙基带功能。在 FreeBSD 中,为每个蓝牙设备创建一个 netgraph HCI 节点。有关更多详细信息,请参阅 ng_hci(4)。
发现 RF 附近的蓝牙设备是最常见的任务之一。这个操作被称为“查询”。查询和其他 HCI 相关的操作是使用 hccontrol(8) 完成的。下面的示例显示了如何查找在范围内的蓝牙设备。设备列表应该在几秒钟内显示出来。请注意,只有在远程设备设置为“可发现”模式时,它才会回答查询。
% hccontrol -n ubt0hci inquiry
Inquiry result, num_responses=1
Inquiry result #0
BD_ADDR: 00:80:37:29:19:a4
Page Scan Rep. Mode: 0x1
Page Scan Period Mode: 00
Page Scan Mode: 00
Class: 52:02:04
Clock offset: 0x78ef
Inquiry complete. Status: No error [00]BD_ADDR 是蓝牙设备的唯一地址,类似于网络卡的 MAC 地址。这个地址在与设备进行进一步通信时是必需的,并且可以为 BD_ADDR 分配一个可读的名称。已知的蓝牙主机的信息包含在 /etc/bluetooth/hosts 文件中。以下示例显示了如何获取分配给远程设备的可读名称:
% hccontrol -n ubt0hci remote_name_request 00:80:37:29:19:a4
BD_ADDR: 00:80:37:29:19:a4
Name: Pav's T39如果对远程蓝牙设备进行查询,将会以"your.host.name (ubt0)"的形式找到计算机。本地设备的名称可以随时更改。
远程设备可以在 /etc/bluetooth/hosts 中分配别名。有关 /etc/bluetooth/hosts 文件的更多信息可以在 bluetooth.hosts(5) 中找到。
蓝牙系统提供了两个蓝牙设备之间的点对点连接,或者在多个蓝牙设备之间共享的点对多点连接。以下示例展示了如何创建与远程设备的连接:
% hccontrol -n ubt0hci create_connection BT_ADDRcreate_connection 函数接受 BT_ADDR 和主机别名作为参数,在 /etc/bluetooth/hosts 文件中定义。
以下示例显示了如何获取本地设备的活动基带连接列表:
% hccontrol -n ubt0hci read_connection_list
Remote BD_ADDR Handle Type Mode Role Encrypt Pending Queue State
00:80:37:29:19:a4 41 ACL 0 MAST NONE 0 0 OPEN当需要终止基带连接时,连接句柄(connection handle) 非常有用,尽管通常不需要手动执行此操作。堆栈会自动终止不活动的基带连接。
# hccontrol -n ubt0hci disconnect 41
Connection handle: 41
Reason: Connection terminated by local host [0x16]输入 hccontrol help 以获取可用 HCI 命令的完整列表。大多数 HCI 命令不需要超级用户权限。
34.7.3. 设备配对
默认情况下,蓝牙通信不需要进行身份验证,任何设备都可以与其他设备进行通信。蓝牙设备(如手机)可以选择要求进行身份验证以提供特定服务。蓝牙身份验证通常使用一个最长为 16 个字符的 ASCII 字符串作为 PIN 码。用户需要在两台设备上输入相同的 PIN 码。用户输入 PIN 码后,两台设备将生成一个 链接密钥。之后,链接密钥可以存储在设备或持久存储中。下次,两台设备将使用先前生成的链接密钥。这个过程称为 配对。请注意,如果链接密钥被任一设备丢失,配对必须重新进行。
hcsecd(8) 守护进程负责处理蓝牙认证请求。默认的配置文件是 /etc/bluetooth/hcsecd.conf。下面是一个示例部分,其中手机的 PIN 码设置为 1234:
device {
bdaddr 00:80:37:29:19:a4;
name "Pav's T39";
key nokey;
pin "1234";
}
对于 PIN 码,唯一的限制是长度。一些设备,如蓝牙耳机,可能有一个固定的内置 PIN 码。-d 开关强制 hcsecd(8) 保持在前台,以便可以清楚地看到发生了什么。将远程设备设置为接收配对并启动与远程设备的蓝牙连接。远程设备应指示接受配对并请求 PIN 码。输入与 hcsecd.conf 中列出的相同的 PIN 码。现在计算机和远程设备已配对。或者,可以在远程设备上启动配对。
可以将以下行添加到 /etc/rc.conf 中,以配置 hcsecd(8) 在系统启动时自动启动:
hcsecd_enable="YES"
以下是 hcsecd(8) 守护进程输出的示例:
hcsecd[16484]: Got Link_Key_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', link key doesn't exist hcsecd[16484]: Sending Link_Key_Negative_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Got PIN_Code_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', PIN code exists hcsecd[16484]: Sending PIN_Code_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4
34.7.4. 使用 PPP 配置文件的网络访问
可以使用拨号网络(DUN)配置文件将手机配置为无线调制解调器,以连接到拨号上网服务器。它还可以用于配置计算机接收来自手机的数据呼叫。
使用 PPP 配置文件进行网络访问可以为单个蓝牙设备或多个蓝牙设备提供局域网访问。它还可以使用 PPP 网络通过串行电缆仿真实现 PC 与 PC 之间的连接。
在 FreeBSD 中,这些配置文件是通过 ppp(8) 和 rfcomm_pppd(8) 包装器实现的,该包装器将蓝牙连接转换为 PPP 可以使用的内容。在使用配置文件之前,必须在 /etc/ppp/ppp.conf 中创建一个新的 PPP 标签。请参考 rfcomm_pppd(8) 中的示例。
在这个例子中,使用 rfcomm_pppd(8) 来打开与远程设备的连接,其 BD_ADDR 为 00:80:37:29:19:a4 ,在一个 DUNRFCOMM 通道上。
# rfcomm_pppd -a 00:80:37:29:19:a4 -c -C dun -l rfcomm-dialup实际的通道号将通过使用 SDP 协议从远程设备获取。可以手动指定 RFCOMM 通道,在这种情况下,rfcomm_pppd(8) 将不执行 SDP 查询。使用 sdpcontrol(8) 来查找远程设备上的 RFCOMM 通道。
为了使用 PPPLAN 服务提供网络访问,必须运行 sdpd(8) 并在 /etc/ppp/ppp.conf 中创建一个新的 LAN 客户端条目。请参考 rfcomm_pppd(8) 中的示例。最后,在有效的 RFCOMM 通道号上启动 RFCOMMPPP 服务器。RFCOMMPPP 服务器将自动在本地 SDP 守护进程中注册蓝牙 LAN 服务。下面的示例显示了如何启动 RFCOMMPPP 服务器。
# rfcomm_pppd -s -C 7 -l rfcomm-server34.7.5. 蓝牙协议
本节提供了各种蓝牙协议的概述,包括它们的功能和相关工具。
34.7.5.1. 逻辑链路控制和适配协议(L2CAP)
逻辑链路控制和适配协议(L2CAP)为上层协议提供面向连接和无连接的数据服务。L2CAP 允许更高级的协议和应用程序传输和接收最长为 64 千字节的 L2CAP 数据包。
L2CAP 基于 通道(channels) 概念。通道是在基带连接之上的逻辑连接,每个通道以多对一的方式绑定到单个协议上。多个通道可以绑定到同一个协议,但一个通道不能绑定到多个协议。在通道上接收到的每个 L2CAP 数据包都会被传递给相应的高层协议。多个通道可以共享同一个基带连接。
在 FreeBSD 中,为每个蓝牙设备创建一个 netgraph L2CAP 节点。该节点通常连接到下游的蓝牙 HCI 节点和上游的蓝牙套接字节点。 L2CAP 节点的默认名称为"devicel2cap"。有关更多详细信息,请参阅 ng_l2cap(4) 。
一个有用的命令是 l2ping(8),它可以用来 ping 其他设备。一些蓝牙实现可能不会返回所有发送给它们的数据,所以在下面的示例中 0 bytes 是正常的。
# l2ping -a 00:80:37:29:19:a4
0 bytes from 0:80:37:29:19:a4 seq_no=0 time=48.633 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=1 time=37.551 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=2 time=28.324 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=3 time=46.150 ms result=0l2control(8) 实用程序用于对 L2CAP 节点执行各种操作。此示例演示了如何获取本地设备的逻辑连接(通道)列表和基带连接列表。
% l2control -a 00:02:72:00:d4:1a read_channel_list
L2CAP channels:
Remote BD_ADDR SCID/ DCID PSM IMTU/ OMTU State
00:07:e0:00:0b:ca 66/ 64 3 132/ 672 OPEN
% l2control -a 00:02:72:00:d4:1a read_connection_list
L2CAP connections:
Remote BD_ADDR Handle Flags Pending State
00:07:e0:00:0b:ca 41 O 0 OPEN另一个诊断工具是 btsockstat(1)。它类似于 netstat(1),但用于蓝牙网络相关的数据结构。下面的示例显示了与上面的 l2control(8) 相同的逻辑连接。
% btsockstat
Active L2CAP sockets
PCB Recv-Q Send-Q Local address/PSM Foreign address CID State
c2afe900 0 0 00:02:72:00:d4:1a/3 00:07:e0:00:0b:ca 66 OPEN
Active RFCOMM sessions
L2PCB PCB Flag MTU Out-Q DLCs State
c2afe900 c2b53380 1 127 0 Yes OPEN
Active RFCOMM sockets
PCB Recv-Q Send-Q Local address Foreign address Chan DLCI State
c2e8bc80 0 250 00:02:72:00:d4:1a 00:07:e0:00:0b:ca 3 6 OPEN34.7.5.2. 无线电频率通信(RFCOMM)
RFCOMM 协议通过 L2CAP 协议提供串口的仿真。RFCOMM 是一个简单的传输协议,还提供了模拟 RS-232(EIATIA-232-E)串口的 9 个电路的附加功能。它支持两个蓝牙设备之间的最多 60 个同时连接(RFCOMM 通道)。
对于 RFCOMM 而言,一个完整的通信路径涉及到两个在通信端点上运行的应用程序,它们之间有一个通信段。RFCOMM 旨在覆盖利用设备串口的应用程序。通信段是从一个设备直接连接到另一个设备的蓝牙链路。
RFCOMM 只关注直接连接情况下设备之间的连接,或者设备与网络情况下的调制解调器之间的连接。RFCOMM 可以支持其他配置,例如通过蓝牙无线技术在一侧进行通信并在另一侧提供有线接口的模块。
在 FreeBSD 中,RFCOMM 是在蓝牙套接字层实现的。
34.7.5.3. 服务发现协议(SDP)
服务发现协议(SDP)提供了客户端应用程序发现由服务器应用程序提供的服务的存在以及这些服务的属性的方法。服务的属性包括提供的服务类型或类别以及利用该服务所需的机制或协议信息。
SDP 涉及 SDP 服务器和 SDP 客户端之间的通信。服务器维护一个描述与服务器相关的服务特性的服务记录列表。每个服务记录包含有关单个服务的信息。客户端可以通过发出 SDP 请求从 SDP 服务器维护的服务记录中检索信息。如果客户端或与客户端相关的应用程序决定使用某个服务,则必须打开与服务提供者的单独连接以利用该服务。SDP 提供了一种发现服务及其属性的机制,但不提供利用这些服务的机制。
通常,SDP 客户端根据服务的某些期望特征来搜索服务。然而,有时候希望在没有关于服务的任何先前信息的情况下,发现 SDP 服务器的服务记录描述了哪些类型的服务。这个寻找任何提供的服务的过程被称为 浏览。
蓝牙 SDP 服务器(sdpd(8))和命令行客户端(sdpcontrol(8))已包含在标准的 FreeBSD 安装中。以下示例展示了如何执行 SDP 浏览查询。
% sdpcontrol -a 00:01:03:fc:6e:ec browse
Record Handle: 00000000
Service Class ID List:
Service Discovery Server (0x1000)
Protocol Descriptor List:
L2CAP (0x0100)
Protocol specific parameter #1: u/int/uuid16 1
Protocol specific parameter #2: u/int/uuid16 1
Record Handle: 0x00000001
Service Class ID List:
Browse Group Descriptor (0x1001)
Record Handle: 0x00000002
Service Class ID List:
LAN Access Using PPP (0x1102)
Protocol Descriptor List:
L2CAP (0x0100)
RFCOMM (0x0003)
Protocol specific parameter #1: u/int8/bool 1
Bluetooth Profile Descriptor List:
LAN Access Using PPP (0x1102) ver. 1.0请注意,每个服务都有一系列属性,例如 RFCOMM 通道。根据服务的不同,用户可能需要注意其中一些属性。某些蓝牙实现不支持服务浏览,并可能返回一个空列表。在这种情况下,可以搜索特定的服务。下面的示例演示了如何搜索 OBEX 对象推送(OPUSH)服务:
% sdpcontrol -a 00:01:03:fc:6e:ec search OPUSH在 FreeBSD 上为蓝牙客户端提供服务是通过 sdpd(8) 服务器完成的。可以将以下行添加到 /etc/rc.conf 文件中:
sdpd_enable="YES"
然后可以使用以下命令启动 sdpd(8) 守护进程:
# service sdpd start希望为远程客户端提供蓝牙服务的本地服务器应用程序将在本地 SDP 守护进程中注册该服务。这样的应用程序示例是 rfcomm_pppd(8) 。一旦启动,它将在本地 SDP 守护进程中注册蓝牙局域网服务。
可以通过在本地控制通道上发出 SDP 浏览查询来获取注册到本地 SDP 服务器的服务列表。
# sdpcontrol -l browse34.7.5.4. OBEX 对象推送(OPUSH)
Object Exchange(OBEX)是一种广泛使用的协议,用于移动设备之间的简单文件传输。它主要用于红外通信,用于笔记本电脑或个人数字助理(PDA)之间的通用文件传输,以及在手机和其他具有个人信息管理(PIM)应用程序的设备之间发送名片或日历条目。
OBEX 服务器和客户端是由 obexapp 实现的,可以使用 comms/obexapp[] 软件包或 port 进行安装。
OBEX 客户端用于从 OBEX 服务器推送或拉取对象。一个示例对象可以是名片或约会。OBEX 客户端可以通过 SDP 从远程设备获取 RFCOMM 通道号。这可以通过指定服务名称而不是 RFCOMM 通道号来完成。支持的服务名称有:IrMC,FTRN 和 OPUSH。还可以将 RFCOMM 通道指定为数字。下面是一个 OBEX 会话的示例,其中从手机中提取设备信息对象,并将一个新对象,名片,推送到手机的目录中。
% obexapp -a 00:80:37:29:19:a4 -C IrMC
obex> get telecom/devinfo.txt devinfo-t39.txt
Success, response: OK, Success (0x20)
obex> put new.vcf
Success, response: OK, Success (0x20)
obex> di
Success, response: OK, Success (0x20)为了提供 OPUSH 服务,必须运行 sdpd(8) 并创建一个根文件夹,用于存储所有传入的对象。根文件夹的默认路径是 /var/spool/obex。最后,在有效的 RFCOMM 通道号上启动 OBEX 服务器。OBEX 服务器将自动在本地 SDP 守护进程中注册 OPUSH 服务。下面的示例显示了如何启动 OBEX 服务器。
# obexapp -s -C 1034.7.5.5. 串口配置文件(SPP)
串口配置文件(SPP)允许蓝牙设备执行串行电缆仿真。该配置文件允许传统应用程序通过虚拟串口抽象将蓝牙用作电缆替代品。
在 FreeBSD 中,rfcomm_sppd(1) 实现了 SPP ,并且使用伪终端作为虚拟串口抽象。下面的示例展示了如何连接到远程设备的串口服务。rfcomm_sppd(1) 不需要指定 RFCOMM 通道,它可以通过 SDP 从远程设备获取。如果要覆盖这个行为,可以在命令行上指定一个 RFCOMM 通道。
# rfcomm_sppd -a 00:07:E0:00:0B:CA -t
rfcomm_sppd[94692]: Starting on /dev/pts/6...
/dev/pts/6一旦连接成功,伪终端可以被用作串口。
# cu -l /dev/pts/6伪终端会被打印到标准输出,并可以被包装脚本读取。
PTS=`rfcomm_sppd -a 00:07:E0:00:0B:CA -t` cu -l $PTS
34.7.6. 故障排除
默认情况下,当 FreeBSD 接受新连接时,它会尝试执行角色切换并成为主设备。一些不支持角色切换的较旧的蓝牙设备将无法连接。由于角色切换是在建立新连接时执行的,因此无法询问远程设备是否支持角色切换。然而,有一个 HCI 选项可以在本地禁用角色切换:
# hccontrol -n ubt0hci write_node_role_switch 0要显示蓝牙数据包,请使用第三方软件包 hcidump,可以使用 comms/hcidump 软件包或 port 进行安装。该实用程序类似于 tcpdump(1),可用于在终端上显示蓝牙数据包的内容,并将蓝牙数据包转储到文件中。
34.8. 桥接
有时候,将一个网络(比如以太网段)划分为网络段,而无需创建 IP 子网并使用路由器将这些网络段连接起来,是非常有用的。以这种方式连接两个网络的设备被称为“桥接器”。
桥接器通过学习每个网络接口上设备的 MAC 地址来工作。只有当源 MAC 地址和目标 MAC 地址位于不同的网络上时,它才会在网络之间转发流量。在许多方面,桥接器类似于只有很少端口的以太网交换机。可以配置具有多个网络接口的 FreeBSD 系统来充当桥接器。
桥接在以下情况下非常有用:
- 连接网络
-
桥接的基本操作是连接两个或多个网络段。使用主机级桥接而不是网络设备有许多原因,例如布线限制或防火墙。桥接还可以将以 hostap 模式运行的无线接口连接到有线网络,并充当访问点。
- 过滤/流量整形防火墙
-
当需要防火墙功能而不需要路由或网络地址转换(NAT)时,可以使用桥接。
一个例子是一个通过 DSL 或 ISDN 连接到 ISP 的小公司。ISP 提供了 13 个公共 IP 地址,网络上有 10 台计算机。在这种情况下,由于子网划分问题,使用基于路由器的防火墙是困难的。而基于桥接的防火墙可以在没有任何 IP 地址问题的情况下进行配置。
- 网络分流器
-
桥接器可以连接两个网络段,以便使用桥接接口上的 bpf(4) 和 tcpdump(1) 来检查它们之间传递的所有以太网帧,或者通过将所有帧的副本发送到一个额外的接口,即监控端口。
- 二层虚拟专用网络(Layer 2 VPN)
-
通过将网络桥接到 EtherIP 隧道或基于 tap(4) 的解决方案(如 OpenVPN),可以通过 IP 链接将两个以太网网络连接起来。
- 二层冗余
-
一个网络可以通过多个链路连接在一起,并使用生成树协议(STP)来阻塞冗余路径。
本节介绍了如何使用 if_bridge(4) 将 FreeBSD 系统配置为桥接模式。还提供了 netgraph 桥接驱动程序的配置方法,详见 ng_bridge(4) 。
|
数据包过滤可以与任何钩入 pfil(9) 框架的防火墙软件包一起使用。桥接可以与 altq(4) 或 dummynet(4) 一起用作流量整形器。 |
34.8.1. 启用桥接功能
在 FreeBSD 中,if_bridge(4) 是一个内核模块,当创建一个桥接接口时,ifconfig(8) 会自动加载它。也可以通过在自定义内核配置文件中添加 device if_bridge 来编译桥接支持到自定义内核中。
使用接口克隆来创建桥接。要创建桥接接口:
# ifconfig bridge create
bridge0
# ifconfig bridge0
bridge0: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:00:00:00:00:00 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:00:00:00:00:00 priority 0 ifcost 0 port 0当创建一个桥接接口时,它会自动分配一个随机生成的以太网地址。maxaddr 和 timeout 参数控制桥接将保留多少个 MAC 地址在其转发表中,以及每个条目在最后一次被检测到后多少秒后被删除。其他参数控制 STP 的操作方式。
接下来,指定要添加为桥接成员的网络接口。为了使桥接转发数据包,所有成员接口和桥接都需要处于启动状态:
# ifconfig bridge0 addm fxp0 addm fxp1 up
# ifconfig fxp0 up
# ifconfig fxp1 up桥接器现在可以在 fxp0 和 fxp1 之间转发以太网帧。在 /etc/rc.conf 中添加以下行,以便在启动时创建桥接器:
cloned_interfaces="bridge0" ifconfig_bridge0="addm fxp0 addm fxp1 up" ifconfig_fxp0="up" ifconfig_fxp1="up"
如果桥接主机需要一个 IP 地址,请在桥接接口上设置,而不是在成员接口上设置。该地址可以静态设置或通过 DHCP 设置。以下示例设置了一个静态 IP 地址:
# ifconfig bridge0 inet 192.168.0.1/24还可以将 IPv6 地址分配给桥接口。要使更改永久生效,请将寻址信息添加到 /etc/rc.conf 文件中。
|
当启用数据包过滤时,桥接的数据包将通过过滤器从桥接接口的原始接口进入,并通过适当的接口出去。任何一个阶段都可以被禁用。当数据包流向很重要时,最好在成员接口上设置防火墙,而不是在桥接本身上设置。 该桥接器具有多个可配置的设置,用于传递非 IP 和 IP 数据包,并使用 ipfw(8) 进行第二层防火墙设置。有关更多信息,请参阅 if_bridge(4) 。 |
34.8.2. 启用生成树
为了使以太网网络正常运行,两个设备之间只能存在一条活动路径。 STP 协议可以检测到环路,并将冗余链路置于阻塞状态。如果其中一条活动链路失败,STP 会计算出一棵不同的树,并启用一条被阻塞的路径,以恢复网络中所有节点的连接。
快速生成树协议(RSTP 或 802.1w)与传统的生成树协议(STP)向后兼容。RSTP 提供更快的收敛速度,并与相邻交换机交换信息,以便快速转换到转发模式,而不会创建环路。FreeBSD 支持 RSTP 和 STP 作为操作模式,其中 RSTP 是默认模式。
可以使用 ifconfig(8) 在成员接口上启用 STP。对于具有 fxp0 和 fxp1 作为当前接口的桥接,可以使用以下命令启用 STP :
# ifconfig bridge0 stp fxp0 stp fxp1
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether d6:cf:d5:a0:94:6d
id 00:01:02:4b:d4:50 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 0 port 0
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 3 priority 128 path cost 200000 proto rstp
role designated state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role designated state forwarding这个桥的生成树 ID 是 00:01:02:4b:d4:50,优先级是 32768。由于根 ID 相同,这表明这是生成树的根桥。
网络上的另一座桥梁也启用了 STP :
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:13:d4:9a:06:7a priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role root state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 5 priority 128 path cost 200000 proto rstp
role designated state forwarding该行 root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4 显示根桥为 00:01:02:4b:d4:50,从该桥到根桥的路径成本为 400000。到达根桥的路径通过 port 4,即 fxp0。
34.8.3. 桥接接口参数
几个 ifconfig 参数是专门用于桥接接口的。本节概述了这些参数的一些常见用法。完整的可用参数列表在 ifconfig(8) 中有描述。
- private
-
私有接口不会将任何流量转发到其他被指定为私有接口的端口。流量会被无条件地阻塞,因此不会转发任何以太网帧,包括 ARP 数据包。如果需要选择性地阻止流量,应该使用防火墙。
- span
-
一个 SPAN 端口会传输桥接器接收到的每个以太网帧的副本。一个桥接器上配置的 SPAN 端口数量是无限的,但是如果一个接口被指定为 SPAN 端口,它就不能再被用作常规的桥接端口。这对于在连接到桥接器的 SPAN 端口之一的另一台主机上被动地监听桥接网络非常有用。例如,要将所有帧的副本发送到名为 fxp4 的接口上。
# ifconfig bridge0 span fxp4 - sticky
-
如果桥接成员接口被标记为粘性(sticky),动态学习的地址条目将被视为转发缓存中的静态条目。粘性条目不会因为地址在不同接口上出现而被清除或替换。这提供了静态地址条目的好处,而无需预先填充转发表。在桥接的特定段上学习的客户端不能漫游到另一个段。
使用粘性地址的一个例子是将桥接器与 VLAN 结合使用,以便在不浪费 IP 地址空间的情况下隔离客户网络。假设
CustomerA位于vlan100,CustomerB位于vlan101,桥接器的地址为192.168.0.1:# ifconfig bridge0 addm vlan100 sticky vlan100 addm vlan101 sticky vlan101 # ifconfig bridge0 inet 192.168.0.1/24在这个例子中,两个客户端都将
192.168.0.1视为它们的默认网关。由于桥接缓存是粘性的,一个主机无法伪造另一个客户的 MAC 地址以拦截其流量。可以使用防火墙或私有接口来阻止 VLAN 之间的任何通信,就像在这个例子中所看到的那样:
# ifconfig bridge0 private vlan100 private vlan101客户之间完全隔离,可以分配整个
/24地址范围而无需进行子网划分。接口后面的唯一源 MAC 地址数量可以被限制。一旦达到限制,具有未知源地址的数据包将被丢弃,直到现有的主机缓存条目过期或被删除。
以下示例将
vlan100上CustomerA的以太网设备的最大数量设置为 10 :# ifconfig bridge0 ifmaxaddr vlan100 10
桥接接口还支持监控模式,在 bpf(4) 处理后丢弃数据包,不再进行进一步处理或转发。这可以用于将两个或多个接口的输入多路复用到单个 bpf(4) 流中。这对于重构通过两个独立接口传输 RX/TX 信号的网络监听器的流量非常有用。例如,要将四个网络接口的输入作为一个流进行读取:
# ifconfig bridge0 addm fxp0 addm fxp1 addm fxp2 addm fxp3 monitor up
# tcpdump -i bridge034.8.4. SNMP 监控
桥接接口和 STP 参数可以通过 bsnmpd(1) 进行监控,该工具包含在 FreeBSD 基本系统中。导出的桥接 MIB 符合 IETF 标准,因此可以使用任何 SNMP 客户端或监控软件来检索数据。
要在桥接器上启用监控,请取消注释 /etc/snmpd.config 中的此行,即删除开头的 # 符号:
begemotSnmpdModulePath."bridge" = "/usr/lib/snmp_bridge.so"
其他配置设置,如社区名称和访问列表,可能需要在此文件中进行修改。有关更多信息,请参阅 bsnmpd(1) 和 snmp_bridge(3)。保存这些编辑后,将此行添加到 /etc/rc.conf:
bsnmpd_enable="YES"
然后,启动 bsnmpd(1):
# service bsnmpd start以下示例使用 Net-SNMP 软件(net-mgmt/net-snmp)从客户端系统查询桥接。也可以使用 net-mgmt/bsnmptools port。从运行 Net-SNMP 的 SNMP 客户端,在 $HOME/.snmp/snmp.conf 中添加以下行以导入桥接 MIB 定义:
mibdirs +/usr/share/snmp/mibs mibs +BRIDGE-MIB:RSTP-MIB:BEGEMOT-MIB:BEGEMOT-BRIDGE-MIB
使用 IETF BRIDGE-MIB(RFC4188)监控单个桥接设备:
% snmpwalk -v 2c -c public bridge1.example.com mib-2.dot1dBridge
BRIDGE-MIB::dot1dBaseBridgeAddress.0 = STRING: 66:fb:9b:6e:5c:44
BRIDGE-MIB::dot1dBaseNumPorts.0 = INTEGER: 1 ports
BRIDGE-MIB::dot1dStpTimeSinceTopologyChange.0 = Timeticks: (189959) 0:31:39.59 centi-seconds
BRIDGE-MIB::dot1dStpTopChanges.0 = Counter32: 2
BRIDGE-MIB::dot1dStpDesignatedRoot.0 = Hex-STRING: 80 00 00 01 02 4B D4 50
...
BRIDGE-MIB::dot1dStpPortState.3 = INTEGER: forwarding(5)
BRIDGE-MIB::dot1dStpPortEnable.3 = INTEGER: enabled(1)
BRIDGE-MIB::dot1dStpPortPathCost.3 = INTEGER: 200000
BRIDGE-MIB::dot1dStpPortDesignatedRoot.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedCost.3 = INTEGER: 0
BRIDGE-MIB::dot1dStpPortDesignatedBridge.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedPort.3 = Hex-STRING: 03 80
BRIDGE-MIB::dot1dStpPortForwardTransitions.3 = Counter32: 1
RSTP-MIB::dot1dStpVersion.0 = INTEGER: rstp(2)dot1dStpTopChanges.0 的值为 2,表示 STP 桥接拓扑已经发生了两次变化。拓扑变化意味着网络中的一个或多个链路发生了变化或故障,并重新计算了新的树形结构。dot1dStpTimeSinceTopologyChange.0 的值将显示这一事件发生的时间。
要监控多个桥接口,可以使用私有的 BEGEMOT-BRIDGE-MIB。
% snmpwalk -v 2c -c public bridge1.example.com
enterprises.fokus.begemot.begemotBridge
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge0" = STRING: bridge0
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge2" = STRING: bridge2
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge0" = STRING: e:ce:3b:5a:9e:13
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge2" = STRING: 12:5e:4d:74:d:fc
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge0" = INTEGER: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge2" = INTEGER: 1
...
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge0" = Timeticks: (116927) 0:19:29.27 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge2" = Timeticks: (82773) 0:13:47.73 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge0" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge2" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge0" = Hex-STRING: 80 00 00 40 95 30 5E 31
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge2" = Hex-STRING: 80 00 00 50 8B B8 C6 A9要通过 mib-2.dot1dBridge 子树更改被监视的桥接口:
% snmpset -v 2c -c private bridge1.example.com
BEGEMOT-BRIDGE-MIB::begemotBridgeDefaultBridgeIf.0 s bridge234.9. 链路聚合和故障转移
FreeBSD 提供了 lagg(4) 接口,可以将多个网络接口聚合成一个虚拟接口,以实现故障转移和链路聚合。故障转移允许流量在至少一个聚合网络接口建立连接时继续传输。链路聚合在支持 LACP 的交换机上效果最佳,因为该协议可以在双向传输流量的同时响应单个链路的故障。
lagg 接口支持的聚合协议决定了哪些端口用于出站流量,以及特定端口是否接受入站流量。lagg(4) 支持以下协议:
- 故障转移(failover)
-
这种模式只通过主端口发送和接收流量。如果主端口不可用,将使用下一个活动端口。添加到虚拟接口的第一个接口是主端口,随后添加的接口将用作故障转移设备。如果故障转移到非主端口,原始端口在再次可用时将恢复为主端口。
- 负载均衡(loadbalance)
-
这提供了一个静态设置,并且不与对等方协商聚合或交换帧以监视链路。如果交换机支持 LACP,则应使用该协议。
- lacp
-
IEEE® 802.3ad 链路聚合控制协议(LACP)与对等方协商一组可聚合的链路,形成一个或多个链路聚合组(LAG)。每个 LAG 由相同速度的端口组成,设置为全双工操作,并且流量在 LAG 中的端口之间进行平衡,以获得最大总速度。通常,只有一个包含所有端口的 LAG 。在物理连接发生变化时,LACP 将迅速收敛到新的配置。
LACP 根据哈希协议头信息平衡传出流量,并从任何活动端口接受传入流量。哈希包括以太网源地址和目的地址,如果可用,还包括 VLAN 标签以及 IPv4 或 IPv6 源地址和目的地址。
- roundrobin
-
这种模式通过循环调度器将出站流量分发到所有活动端口,并接受来自任何活动端口的入站流量。由于这种模式违反了以太网帧的顺序,因此应谨慎使用。
- broadcast
-
该模式将出站流量发送到 lagg 接口上配置的所有端口,并在任何端口上接收帧。
34.9.1. 配置示例
本节演示了如何配置 Cisco® 交换机和 FreeBSD 系统以实现 LACP 负载均衡。然后,它展示了如何配置两个以故障转移模式工作的以太网接口,以及如何在以太网接口和无线接口之间配置故障转移模式。
例 38. 使用 Cisco® 交换机进行 LACP 聚合
这个例子将一个 FreeBSD 机器上的两个 fxp(4) 以太网接口连接到 Cisco® 交换机的前两个以太网端口,作为一个负载均衡和容错链接。可以添加更多接口以增加吞吐量和容错性。请根据本地配置替换示例中显示的 Cisco® 端口名称、以太网设备、通道组号和 IP 地址的名称。
以太网链路上的帧排序是强制性的,任何两个站点之间的流量总是通过同一物理链路传输,这限制了最大速度为一个接口的速度。传输算法尝试使用尽可能多的信息来区分不同的流量,并在可用接口之间平衡流量。
在 Cisco® 交换机上,将 FastEthernet0/1 和 FastEthernet0/2 接口添加到通道组 1 中:
interface FastEthernet0/1
channel-group 1 mode active
channel-protocol lacp
!
interface FastEthernet0/2
channel-group 1 mode active
channel-protocol lacp在 FreeBSD 系统上,使用物理接口 fxp0 和 fxp1 创建 lagg(4) 接口,并使用 IP 地址 10.0.0.3/24 将接口启动:
# ifconfig fxp0 up
# ifconfig fxp1 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto lacp laggport fxp0 laggport fxp1 10.0.0.3/24接下来,验证虚拟接口的状态:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
inet 10.0.0.3 netmask 0xffffff00 broadcast 10.0.0.255
media: Ethernet autoselect
status: active
laggproto lacp
laggport: fxp1 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: fxp0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>标记为“ ACTIVE ”的端口是与远程交换机协商的链路聚合组(LAG)的一部分。通过这些活动端口传输和接收流量。在上述命令中添加 -v 以查看 LAG 标识符。
查看 Cisco® 交换机上的端口状态:
switch# show lacp neighbor
Flags: S - Device is requesting Slow LACPDUs
F - Device is requesting Fast LACPDUs
A - Device is in Active mode P - Device is in Passive mode
Channel group 1 neighbors
Partner's information:
LACP port Oper Port Port
Port Flags Priority Dev ID Age Key Number State
Fa0/1 SA 32768 0005.5d71.8db8 29s 0x146 0x3 0x3D
Fa0/2 SA 32768 0005.5d71.8db8 29s 0x146 0x4 0x3D要获取更详细的信息,请输入 show lacp neighbor detail 。
要在重新启动后保留此配置,请将以下条目添加到 FreeBSD 系统上的 /etc/rc.conf 文件中:
ifconfig_fxp0="up" ifconfig_fxp1="up" cloned_interfaces="lagg0" ifconfig_lagg0="laggproto lacp laggport fxp0 laggport fxp1 10.0.0.3/24"
例 39. 故障转移模式
如果主接口丢失连接,可以使用故障转移模式切换到备用接口。要配置故障转移,请确保底层物理接口正常工作,然后创建 lagg(4) 接口。在这个例子中,fxp0 是主接口,fxp1 是备用接口,虚拟接口被分配了一个 IP 地址为 10.0.0.15/24。
# ifconfig fxp0 up
# ifconfig fxp1 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto failover laggport fxp0 laggport fxp1 10.0.0.15/24虚拟接口应该类似于这样:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
inet 10.0.0.15 netmask 0xffffff00 broadcast 10.0.0.255
media: Ethernet autoselect
status: active
laggproto failover
laggport: fxp1 flags=0<>
laggport: fxp0 flags=5<MASTER,ACTIVE>流量将在 fxp0 上进行传输和接收。如果 fxp0 上的连接丢失,fxp1 将成为活动连接。如果主接口上的连接恢复,它将再次成为活动连接。
要在重新启动后保留此配置,请将以下条目添加到 /etc/rc.conf 文件中:
ifconfig_fxp0="up" ifconfig_fxp1="up" cloned_interfaces="lagg0" ifconfig_lagg0="laggproto failover laggport fxp0 laggport fxp1 10.0.0.15/24"
例 40. 以太网和无线接口之间的故障转移模式
对于笔记本电脑用户来说,通常希望将无线设备配置为次要设备,仅在以太网连接不可用时使用。通过使用 lagg(4) ,可以配置故障转移,优先选择以太网连接,以提高性能和安全性,同时保持通过无线连接传输数据的能力。
这是通过使用无线接口的 MAC 地址覆盖以太网接口的 MAC 地址来实现的。
在这个例子中,以太网接口 re0 是主接口,无线接口 wlan0 是备份接口。wlan0 接口是从 ath0 物理无线接口创建的,并且以太网接口将配置无线接口的 MAC 地址。首先,将无线接口启动(将 FR 替换为您自己的两个字母的国家代码),但不设置 IP 地址。将 wlan0 替换为与系统的无线接口名称匹配的名称:
# ifconfig wlan0 create wlandev ath0 country FR ssid my_router up现在您可以确定无线接口的 MAC 地址:
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether b8:ee:65:5b:32:59
groups: wlan
ssid Bbox-A3BD2403 channel 6 (2437 MHz 11g ht/20) bssid 00:37:b7:56:4b:60
regdomain ETSI country FR indoor ecm authmode WPA2/802.11i privacy ON
deftxkey UNDEF AES-CCM 2:128-bit txpower 30 bmiss 7 scanvalid 60
protmode CTS ampdulimit 64k ampdudensity 8 shortgi -stbctx stbcrx
-ldpc wme burst roaming MANUAL
media: IEEE 802.11 Wireless Ethernet MCS mode 11ng
status: associated
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>ether 行将包含指定接口的 MAC 地址。现在,将以太网接口的 MAC 地址更改为匹配的地址:
# ifconfig re0 ether b8:ee:65:5b:32:59确保 re0 接口处于启动状态,然后使用 re0 作为主接口创建 lagg(4) 接口,并设置故障转移至 wlan0。
# ifconfig re0 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto failover laggport re0 laggport wlan0虚拟接口应该类似于这样:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether b8:ee:65:5b:32:59
laggproto failover lagghash l2,l3,l4
laggport: re0 flags=5<MASTER,ACTIVE>
laggport: wlan0 flags=0<>
groups: lagg
media: Ethernet autoselect
status: active然后,启动 DHCP 客户端以获取 IP 地址:
# dhclient lagg0要在重新启动后保留此配置,请将以下条目添加到 /etc/rc.conf 文件中:
ifconfig_re0="ether b8:ee:65:5b:32:59" wlans_ath0="wlan0" ifconfig_wlan0="WPA" create_args_wlan0="country FR" cloned_interfaces="lagg0" ifconfig_lagg0="up laggproto failover laggport re0 laggport wlan0 DHCP"
34.10. 使用 PXE 进行无盘操作
Intel® Preboot eXecution Environment (PXE) 允许操作系统通过网络引导。例如,FreeBSD 系统可以通过网络引导并在没有本地磁盘的情况下运行,使用从 NFS 服务器挂载的文件系统。PXE 支持通常在 BIOS 中可用。要在机器启动时使用 PXE,在 BIOS 设置中选择 从网络引导(Boot from network) 选项或在系统初始化期间键入功能键。
为了提供操作系统在网络上启动所需的文件,PXE 设置还需要正确配置的 DHCP、TFTP 和 NFS 服务器,其中:
-
初始参数,如 IP 地址、可执行的引导文件名和位置、服务器名称和根路径,是从 DHCP 服务器获取的。
-
操作系统加载程序文件使用 TFTP 进行引导。
-
文件系统使用 NFS 加载。
当计算机进行 PXE 引导时,它通过 DHCP 接收关于获取初始引导加载程序文件的信息。主机计算机接收到这些信息后,通过 TFTP 下载引导加载程序,然后执行引导加载程序。在 FreeBSD 中,引导加载程序文件是 /boot/pxeboot。在 /boot/pxeboot 执行后,FreeBSD 内核被加载,随后进行 FreeBSD 的引导过程,如 FreeBSD引导过程 中所述。
|
对于基于 UEFI PXE 的引导,要使用的实际引导加载程序文件是 /boot/loader.efi 。请参阅下面的章节 调试 PXE 问题,了解如何使用 /boot/loader.efi 。 |
本节介绍了如何在 FreeBSD 系统上配置这些服务,以便其他系统可以通过 PXE 引导进入 FreeBSD。有关更多信息,请参阅 diskless(8)。
|
如上所述,提供这些服务的系统是不安全的。它应该存在于网络的受保护区域,并且其他主机不应信任它。 |
34.10.1. 设置 PXE 环境
本节中显示的步骤配置了内置的 NFS 和 TFTP 服务器。下一节演示了如何安装和配置 DHCP 服务器。在本示例中,用于 PXE 用户的文件的目录是 /b/tftpboot/FreeBSD/install。重要的是,该目录存在,并且在 /etc/inetd.conf 和 /usr/local/etc/dhcpd.conf 中设置了相同的目录名。
-
创建根目录,该目录将包含一个要进行 NFS 挂载的 FreeBSD 安装。
# export NFSROOTDIR=/b/tftpboot/FreeBSD/install # mkdir -p ${NFSROOTDIR} -
通过将以下行添加到 /etc/rc.conf 来启用 NFS 服务器:
nfs_server_enable="YES"
-
通过将以下内容添加到 /etc/exports,将无磁盘根目录通过 NFS 导出:
/b -ro -alldirs -maproot=root
-
启动 NFS 服务器:
# service nfsd start -
通过将以下行添加到 /etc/rc.conf 来启用 inetd(8):
inetd_enable="YES"
-
请取消注释 /etc/inetd.conf 中的以下行,确保它不以
#符号开头:tftp dgram udp wait root /usr/libexec/tftpd tftpd blocksize 1468 -l -s /b/tftpboot
指定的 tftp 块大小,例如 1468 字节,替换了默认大小 512 字节。某些 PXE 版本要求使用 TCP 版本的 TFTP 。在这种情况下,取消注释包含
stream tcp的第二个tftp行。 -
启动 inetd(8):
# service inetd start -
将基本系统安装到 ${NFSROOTDIR} 中,可以通过解压官方存档或重新构建 FreeBSD 内核和用户空间来完成(有关更详细的说明,请参阅 “从源代码更新 FreeBSD” ,但在运行
make installkernel和make installworld命令时不要忘记添加DESTDIR =${NFSROOTDIR}。 -
测试 TFTP 服务器是否正常工作,并且能够通过 PXE 下载引导加载程序:
# tftp localhost tftp> get FreeBSD/install/boot/pxeboot Received 264951 bytes in 0.1 seconds -
编辑 ${NFSROOTDIR}/etc/fstab 并创建一个条目以通过 NFS 挂载根文件系统:
# Device Mountpoint FSType Options Dump Pass myhost.example.com:/b/tftpboot/FreeBSD/install / nfs ro 0 0
将 myhost.example.com 替换为 NFS 服务器的主机名或 IP 地址。在这个例子中,根文件系统以只读方式挂载,以防止 NFS 客户端可能删除根文件系统的内容。
-
为通过 PXE 引导的客户机在 PXE 环境中设置根密码:
# chroot ${NFSROOTDIR} # passwd -
如有需要,通过编辑 ${NFSROOTDIR}/etc/ssh/sshd_config 文件并启用
PermitRootLogin选项,可以为使用 PXE 引导的客户机启用 ssh(1)PermitRootLogin。该选项在 sshd_config(5) 中有详细说明。 -
在 ${NFSROOTDIR} 中进行任何其他所需的 PXE 环境自定义。这些自定义可能包括安装软件包或使用 vipw(8) 编辑密码文件。
当从 NFS 根卷引导时,/etc/rc 检测到 NFS 引导并运行 /etc/rc.initdiskless。在这种情况下,/etc 和 /var 需要是内存支持的文件系统,以便这些目录可写,但 NFS 根目录是只读的。
# chroot ${NFSROOTDIR}
# mkdir -p conf/base
# tar -c -v -f conf/base/etc.cpio.gz --format cpio --gzip etc
# tar -c -v -f conf/base/var.cpio.gz --format cpio --gzip var当系统启动时,将创建并挂载 /etc 和 /var 的内存文件系统,并将 cpio.gz 文件的内容复制到其中。默认情况下,这些文件系统的最大容量为 5 兆字节。如果您的存档不适合,通常是 /var 安装了二进制包的情况下,可以通过在 ${NFSROOTDIR}/conf/base/etc/md_size 和 ${NFSROOTDIR}/conf/base/var/md_size 文件中放入所需的 512 字节扇区数(例如,5 兆字节为 10240 扇区)来请求更大的大小,分别用于 /etc 和 /var 文件系统。
34.10.2. 配置 DHCP 服务器
DHCP 服务器不需要与 TFTP 和 NFS 服务器位于同一台机器上,但它需要在网络中可访问。
DHCP 不是 FreeBSD 基本系统的一部分,但可以使用 net/isc-dhcp44-server 端口或 port 进行安装。
安装完成后,编辑配置文件 /usr/local/etc/dhcpd.conf。根据以下示例配置 next-server、filename 和 root-path 设置:
subnet 192.168.0.0 netmask 255.255.255.0 {
range 192.168.0.2 192.168.0.3 ;
option subnet-mask 255.255.255.0 ;
option routers 192.168.0.1 ;
option broadcast-address 192.168.0.255 ;
option domain-name-servers 192.168.35.35, 192.168.35.36 ;
option domain-name "example.com";
# IP address of TFTP server
next-server 192.168.0.1 ;
# path of boot loader obtained via tftp
filename "FreeBSD/install/boot/pxeboot" ;
# pxeboot boot loader will try to NFS mount this directory for root FS
option root-path "192.168.0.1:/b/tftpboot/FreeBSD/install/" ;
}
next-server 指令用于指定 TFTP 服务器的 IP 地址。
filename 指令定义了路径为 /boot/pxeboot 的文件名。使用的是相对路径,这意味着路径中不包括 /b/tftpboot。
root-path 选项定义了 NFS 根文件系统的路径。
在保存编辑后,通过将以下行添加到 /etc/rc.conf 来在启动时启用 DHCP :
dhcpd_enable="YES"
然后启动 DHCP 服务:
# service isc-dhcpd start34.10.3. 调试 PXE 问题
一旦所有服务都配置并启动完成, PXE 客户端应该能够通过网络自动加载 FreeBSD 。如果某个特定的客户端无法连接,当该客户端机器启动时,进入 BIOS 配置菜单并确认其设置为从网络启动。
本节介绍了一些故障排除技巧,用于确定配置问题的根源,以防止任何客户端无法进行 PXE 引导。
-
使用 net/wireshark 包或 port 来调试 PXE 引导过程中涉及的网络流量,如下图所示。
 图 61. PXE 引导过程与 NFS 根目录挂载
图 61. PXE 引导过程与 NFS 根目录挂载-
客户端广播一个 DHCPDISCOVER 消息。
-
DHCP 服务器响应 IP 地址、next-server、filename 和 root-path 的值。
-
客户端向 next-server 发送一个 TFTP 请求,请求检索文件名。
-
TFTP 服务器响应并向客户端发送文件名。
-
客户端执行文件名为 pxeboot(8),然后加载内核。当内核执行时,通过 root-path 指定的根文件系统将通过 NFS 挂载。
-
-
在 TFTP 服务器上,读取 /var/log/xferlog 以确保从正确的位置检索到 pxeboot。要测试此示例配置:
# tftp 192.168.0.1 tftp> get FreeBSD/install/boot/pxeboot Received 264951 bytes in 0.1 seconds -
确保可以通过 NFS 挂载根文件系统。要测试此示例配置,请执行以下操作:
# mount -t nfs 192.168.0.1:/b/tftpboot/FreeBSD/install /mnt -
对于基于 UEFI PXE 的引导,请将 boot/pxeboot 文件替换为 boot/loader.efi 文件:
# chroot ${NFSROOTDIR}
# mv boot/pxeboot boot/pxeboot.original
# cp boot/loader.efi boot/pxeboot
34.11. 通用地址冗余协议(CARP)
通用地址冗余协议(CARP)允许多个主机共享相同的 IP 地址和虚拟主机 ID(VHID),以提供一个或多个服务的高可用性。这意味着一个或多个主机可能会失败,而其他主机将自动接管,使用户无法看到服务中断。
除了共享的 IP 地址外,每个主机还有自己的 IP 地址用于管理和配置。共享同一个 IP 地址的所有机器具有相同的 VHID 。每个虚拟 IP 地址的 VHID 必须在网络接口的广播域中是唯一的。
在 FreeBSD 中,使用 CARP 实现高可用性是内置的,尽管根据 FreeBSD 的版本不同,配置步骤可能略有不同。本节提供了适用于 FreeBSD 10 版本之前、以及等于或之后版本的相同示例配置。
这个示例配置了三个主机的故障转移支持,每个主机都有唯一的 IP 地址,但提供相同的网页内容。它有两个不同的主服务器,分别命名为 hosta.example.org 和 hostb.example.org ,还有一个共享备份命名为 hostc.example.org 。
这些机器使用循环轮询 DNS 配置进行负载均衡。主备机器的配置完全相同,只是主机名和管理 IP 地址不同。这些服务器必须具有相同的配置并运行相同的服务。当发生故障切换时,只有当备份服务器可以访问相同的内容时,才能正确地回答共享 IP 地址上的服务请求。备份机器还有两个额外的 CARP 接口,分别用于主内容服务器的每个 IP 地址。当发生故障时,备份服务器将接管失败的主机器的 IP 地址。
34.11.1. 在 FreeBSD 10 及更高版本上使用 CARP
通过在 /boot/loader.conf 中为 carp.ko 内核模块添加条目,启用 CARP 的启动时支持。
carp_load="YES"
立即加载模块而无需重新启动:
# kldload carp对于喜欢使用自定义内核的用户,请在自定义内核配置文件中包含以下行,并按照 配置 FreeBSD 内核 中描述的方式编译内核。
device carp
主机名、管理 IP 地址和子网掩码、共享 IP 地址以及 VHID 都是通过向 /etc/rc.conf 添加条目来设置的。以下示例适用于 hosta.example.org:
hostname="hosta.example.org" ifconfig_em0="inet 192.168.1.3 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 1 pass testpass alias 192.168.1.50/32"
下一组条目是针对 hostb.example.org 的。由于它代表了第二个主机,所以它使用了不同的共享 IP 地址和 VHID 。然而,使用 pass 指定的密码必须相同,因为 CARP 只会监听和接受来自具有正确密码的机器的广告。
hostname="hostb.example.org" ifconfig_em0="inet 192.168.1.4 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 2 pass testpass alias 192.168.1.51/32"
第三台机器 hostc.example.org 配置为处理来自任一主机的故障转移。该机器配置了两个 CARPVHID,一个用于处理每个主机的虚拟 IP 地址。 CARP 广告偏差 advskew 被设置为确保备份主机比主机广告晚,因为 advskew 控制多个备份服务器时的优先顺序。
hostname="hostc.example.org" ifconfig_em0="inet 192.168.1.5 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 1 advskew 100 pass testpass alias 192.168.1.50/32" ifconfig_em0_alias1="inet vhid 2 advskew 100 pass testpass alias 192.168.1.51/32"
配置了两个 CARPVHID 意味着 hostc.example.org 将会注意到主服务器中的任何一个不可用。如果主服务器在备份服务器之前无法进行广告宣传,备份服务器将会接管共享 IP 地址,直到主服务器再次可用。
|
如果原始主服务器再次可用, |
配置完成后,要么重新启动网络,要么重新启动每个系统。高可用性现在已启用。
34.11.2. 在 FreeBSD 9 及更早版本上使用 CARP
这些版本的 FreeBSD 的配置与前一节中描述的类似,只是首先必须创建一个 CARP 设备并在配置中引用它。
通过在 /boot/loader.conf 中加载 if_carp.ko 内核模块,启用 CARP 的启动时支持。
if_carp_load="YES"
立即加载模块而无需重新启动:
# kldload carp对于喜欢使用自定义内核的用户,请在自定义内核配置文件中包含以下行,并按照 配置 FreeBSD 内核 中描述的方式编译内核。
device carp
接下来,在每台主机上创建一个 CARP 设备:
# ifconfig carp0 create通过在 /etc/rc.conf 中添加所需的行,设置主机名、管理 IP 地址、共享 IP 地址和 VHID。由于使用虚拟 CARP 设备而不是别名,所以使用实际的子网掩码 /24 而不是 /32。以下是 hosta.example.org 的条目:
hostname="hosta.example.org" ifconfig_fxp0="inet 192.168.1.3 netmask 255.255.255.0" cloned_interfaces="carp0" ifconfig_carp0="vhid 1 pass testpass 192.168.1.50/24"
在 hostb.example.org 上:
hostname="hostb.example.org" ifconfig_fxp0="inet 192.168.1.4 netmask 255.255.255.0" cloned_interfaces="carp0" ifconfig_carp0="vhid 2 pass testpass 192.168.1.51/24"
第三台机器 hostc.example.org 配置为处理来自任一主机的故障转移:
hostname="hostc.example.org" ifconfig_fxp0="inet 192.168.1.5 netmask 255.255.255.0" cloned_interfaces="carp0 carp1" ifconfig_carp0="vhid 1 advskew 100 pass testpass 192.168.1.50/24" ifconfig_carp1="vhid 2 advskew 100 pass testpass 192.168.1.51/24"
|
在 GENERIC FreeBSD 内核中禁用了抢占。如果使用自定义内核启用了抢占, 这应该在与正确主机对应的 carp 接口上完成。 |
配置完成后,要么重新启动网络,要么重新启动每个系统。高可用性现在已启用。
34.12. 虚拟局域网(VLANs)
VLAN(虚拟局域网)是一种将网络虚拟分割成许多不同子网络的方法,也被称为分段。每个分段都有自己的广播域,并与其他 VLAN 隔离开来。
在 FreeBSD 上,VLAN 必须由网络适配器驱动程序支持。要查看哪些驱动程序支持 VLAN ,请参考 vlan(4) 手册页。
配置 VLAN 时,需要了解一些信息。首先,是哪个网络接口?其次, VLAN 标签是什么?
要在运行时配置 VLAN ,使用网卡 em0 和 VLAN 标签 5 ,命令如下:
# ifconfig em0.5 create vlan 5 vlandev em0 inet 192.168.20.20/24|
看到接口名称包括了网卡驱动名称和 VLAN 标签,用句点分隔吗?这是一种最佳实践,可以在一个机器上存在多个 VLAN 时,方便维护 VLAN 配置。 |
要在启动时配置 VLAN ,必须更新 /etc/rc.conf 文件。要复制上述配置,需要添加以下内容:
vlans_em0="5" ifconfig_em0_5="inet 192.168.20.20/24"
可以通过简单地将标签添加到 vlans_em0 字段,并添加一行额外的配置网络的代码来添加其他 VLAN。
为了在关联的硬件发生更改时只需要更新少量配置变量,给接口分配一个符号名称是很有用的。例如,安全摄像头需要在 em0 上运行 VLAN 1 。如果以后将 em0 卡替换为使用 ixgb(4) 驱动程序的卡,所有对 em0.1 的引用都不需要更改为 ixgb0.1。
要配置 VLAN 5,在网卡 em0 上分配接口名称 cameras,并为接口分配 IP 地址 192.168.20.20 ,使用 24 位前缀,使用以下命令:
# ifconfig em0.5 create vlan 5 vlandev em0 name cameras inet 192.168.20.20/24对于名为 video 的接口,请使用以下内容:
# ifconfig video.5 create vlan 5 vlandev video name cameras inet 192.168.20.20/24要在启动时应用更改,请将以下行添加到 /etc/rc.conf 文件中:
vlans_video="cameras" create_args_cameras="vlan 5" ifconfig_cameras="inet 192.168.20.20/24"
Part V: 附录
附录 A: 获取 FreeBSD
A.1. 镜像
FreeBSD 项目的官方镜像由项目集群管理员操作的多台机器组成,并且通过 GeoDNS 进行管理,以将用户引导到最近的可用镜像。当前的镜像位置包括澳大利亚、巴西、德国、日本(两个站点)、马来西亚、南非、中国台湾、英国和美国(加利福尼亚州、新泽西州和华盛顿州)。
官方镜像服务:
| 服务名称 | 协议 | 更多信息 |
|---|---|---|
docs.FreeBSD.org |
FreeBSD 文档门户网站。 |
|
download.FreeBSD.org |
与 |
|
git.FreeBSD.org |
通过 |
更多详细信息请参考 using git 部分。 |
pkg.FreeBSD.org |
pkg(8) 可以通过 |
pkg(8) 程序使用的官方 FreeBSD 软件包仓库。 |
vuxml.FreeBSD.org / www.VuXML.org |
FreeBSD 项目的 VuXML 网页。 |
|
www.FreeBSD.org |
FreeBSD 网站。 |
所有官方镜像都支持 IPv4 和 IPv6 。
http://ftp-archive.FreeBSD.org 不在 GeoDNS 基础设施中,只托管在一个地点(美国)。
该项目正在寻找新的场地;愿意赞助的人,请联系集群管理员团队获取更多信息。
由社区和其他公司维护的镜像列表:
| 国家 | 主机名 | 协议 |
|---|---|---|
ftp.au.FreeBSD.org |
||
ftp3.au.FreeBSD.org |
||
ftp.at.FreeBSD.org |
||
ftp2.br.FreeBSD.org |
||
ftp3.br.FreeBSD.org |
||
ftp.bg.FreeBSD.org |
||
ftp.cz.FreeBSD.org |
||
ftp.dk.FreeBSD.org |
||
ftp.fi.FreeBSD.org |
||
ftp.fr.FreeBSD.org |
||
ftp3.fr.FreeBSD.org |
||
ftp6.fr.FreeBSD.org |
||
ftp.de.FreeBSD.org |
||
ftp1.de.FreeBSD.org |
||
ftp2.de.FreeBSD.org |
||
ftp5.de.FreeBSD.org |
||
ftp7.de.FreeBSD.org |
||
ftp.gr.FreeBSD.org |
||
ftp2.gr.FreeBSD.org |
||
ftp.jp.FreeBSD.org |
||
ftp2.jp.FreeBSD.org |
||
ftp3.jp.FreeBSD.org |
||
ftp4.jp.FreeBSD.org |
||
ftp6.jp.FreeBSD.org |
||
mirror.ps.kz |
||
mirror.neolabs.kz |
||
ftp.kr.FreeBSD.org |
||
ftp2.kr.FreeBSD.org |
||
ftp.lv.FreeBSD.org |
||
ftp.nl.FreeBSD.org |
||
ftp2.nl.FreeBSD.org |
||
mirror.nl.altushost.com |
||
ftp.nz.FreeBSD.org |
||
ftp.no.FreeBSD.org |
||
ftp.pl.FreeBSD.org |
||
ftp.ru.FreeBSD.org |
||
ftp2.ru.FreeBSD.org |
||
ftp.si.FreeBSD.org |
||
ftp.za.FreeBSD.org |
||
ftp2.za.FreeBSD.org |
||
ftp4.za.FreeBSD.org |
||
ftp.se.FreeBSD.org |
||
mirror.se.altushost.com |
||
ftp4.tw.FreeBSD.org |
||
ftp5.tw.FreeBSD.org |
||
ftp.ua.FreeBSD.org |
||
ftp.uk.FreeBSD.org |
||
ftp2.uk.FreeBSD.org |
||
ftp11.FreeBSD.org |
||
ftp14.FreeBSD.org |
||
ftp5.FreeBSD.org |
社区镜像支持的协议列表最近更新于 2022 年 1 月 31 日,但不保证实时更新。
A.2. 使用 Git
A.2.1. 介绍
截至 2020 年 12 月,FreeBSD 使用 git 作为存储所有 FreeBSD 基础源代码和文档的主要版本控制系统。截至 2021 年 4 月,FreeBSD 使用 git 作为存储所有 FreeBSD Ports 集合的唯一版本控制系统。
|
Git 通常是开发者工具。用户可能更喜欢使用 |
本节演示了如何在 FreeBSD 系统上安装 Git,并使用它创建一个 FreeBSD 源代码仓库的本地副本。
A.2.3. 运行 Git
要将源代码的干净副本获取到本地目录中,使用 git clone 命令。这个文件目录被称为 工作树(working tree)。
Git 使用 URL 来指定一个仓库。有三个不同的仓库,src 用于 FreeBSD 系统源代码,doc 用于文档,ports 用于 FreeBSD Ports 集合。这三个仓库都可以通过两种不同的协议访问:HTTPS 和 SSH。例如,URL https://git.FreeBSD.org/src.git 指定了 src 仓库的主分支,使用 https 协议。
| 项目 | Git URL |
|---|---|
通过 HTTPS 访问只读源代码仓库 |
|
通过匿名 SSH 只读访问源代码仓库 |
|
通过 HTTPS 访问的只读文档仓库 |
|
通过匿名 SSH 访问的只读文档仓库 |
|
通过 HTTPS 访问只读端口的代码仓库 |
|
通过匿名 SSH 访问只读端口的代码仓库 |
|
项目成员维护的外部镜像也可用;请参考 外部镜像源 部分。
要克隆 FreeBSD 系统源代码仓库的副本:
# git clone -o freebsd https://git.FreeBSD.org/src.git /usr/src-o freebsd 选项指定了源;按照 FreeBSD 文档的约定,源被假定为 freebsd 。由于初始检出必须下载远程存储库的完整分支,可能需要一些时间。请耐心等待。
最初,工作树包含了与 CURRENT 对应的 main 分支的源代码。要切换到 13-STABLE 分支,可以执行以下操作:
# cd /usr/src
# git checkout stable/13可以使用 git pull 命令更新工作树。要更新上面示例中创建的文件 /usr/src,请使用:
# cd /usr/src
# git pull --rebase更新比检出要快得多,只传输已更改的文件。
A.2.4. 基于 Web 的代码仓库浏览器
FreeBSD 项目使用 cgit 作为基于 Web 的存储库浏览器: https://cgit.FreeBSD.org/ 。
A.2.5. 开发者指南
有关对存储库的写访问权限的信息,请参阅 Committer’s Guide。
A.2.6. 外部镜像源
这些镜像不托管在 FreeBSD.org 上,但仍由项目成员维护。用户和开发者可以在这些镜像上拉取或浏览存储库。doc 和 src GitHub 存储库的拉取请求正在接受;否则,与这些镜像的项目工作流程仍在讨论中。
- Codeberg
- GitHub
- GitLab
A.2.7. 邮件列表
FreeBSD 项目中用于一般使用和关于 git 的问题的主要邮件列表是 freebsd-git 。有关更多详细信息,包括提交消息列表,请参阅 邮件列表 章节。
A.2.8. SSH 主机密钥
-
gitrepo.FreeBSD.org 主机的指纹:
-
ECDSA key fingerprint is
SHA256:seWO5D27ySURcx4bknTNKlC1mgai0whP443PAKEvvZA -
ED25519 key fingerprint is
SHA256:lNR6i4BEOaaUhmDHBA1WJsO7H3KtvjE2r5q4sOxtIWo -
RSA key fingerprint is
SHA256:f453CUEFXEJAXlKeEHV+ajJfeEfx9MdKQUD7lIscnQI
-
-
git.FreeBSD.org host key fingerprints:
-
ECDSA key fingerprint is
SHA256:/UlirUAsGiitupxmtsn7f9b7zCWd0vCs4Yo/tpVWP9w -
ED25519 key fingerprint is
SHA256:y1ljKrKMD3lDObRUG3xJ9gXwEIuqnh306tSyFd1tuZE -
RSA key fingerprint is
SHA256:jBe6FQGoH4HjvrIVM23dcnLZk9kmpdezR/CvQzm7rJM
-
这些也被发布为 DNS 中的 SSHFP 记录。
A.3. 使用 Subversion
A.3.1. 介绍
截至 2020 年 12 月,FreeBSD 使用 git 作为主要版本控制系统,用于存储所有 FreeBSD 的源代码和文档。从 git 仓库的 stable/11、stable/12 和相关的 releng 分支中导出的更改将被导入到 Subversion 仓库中。这种导出将在这些分支的生命周期内继续进行。从 2012 年 7 月到 2021 年 3 月,FreeBSD 使用 Subversion 作为存储所有 FreeBSD Ports Collection 的唯一版本控制系统。截至 2021 年 4 月,FreeBSD 使用 git 作为存储所有 FreeBSD Ports Collection 的唯一版本控制系统。
|
Subversion 通常是开发人员工具。用户可能更喜欢使用 |
本节介绍了如何在 FreeBSD 系统上安装 Subversion,并使用它创建一个 FreeBSD 仓库的本地副本。还包括有关使用 Subversion 的其他信息。
A.3.2. Svnlite
在 FreeBSD 上已经安装了 Subversion 的轻量级版本 svnlite。只有在需要 Python 或 Perl API ,或者需要更高版本的 Subversion 时,才需要使用端口或软件包版本的 Subversion。
与正常的 Subversion 使用唯一的区别是命令名称为 svnlite。
A.3.3. 安装
如果 svnlite 不可用或者需要完整版本的 Subversion,则必须安装它。
Subversion 可以从 Ports Collection 安装:
# cd /usr/ports/devel/subversion
# make install cleanSubversion 也可以作为一个软件包进行安装:
# pkg install subversionA.3.4. 运行 Subversion
要将源代码的干净副本获取到本地目录中,请使用 svn 命令。这个目录中的文件被称为 本地工作副本(local working copy)。
|
在首次使用 |
Subversion 使用 URL 来指定一个仓库,其格式为 protocol://hostname/path。路径的第一个组件是要访问的 FreeBSD 仓库。有三个不同的仓库,base 用于 FreeBSD 基本系统源代码,ports 用于 Ports Collection ,doc 用于文档。例如, URL https://svn.FreeBSD.org/base/head/ 指定了 src 仓库的主分支,使用 https 协议。
使用类似以下命令从给定的代码库中进行检出操作:
# svn checkout https://svn.FreeBSD.org/repository/branch lwcdir在哪里:
-
repository 是项目的一个仓库:
base、ports或doc。 -
branch 的依赖取决于所使用的代码库。
ports和doc主要在head分支中进行更新,而base则在head下维护了最新版本的 -CURRENT ,并在stable/11(11.x)和stable/12(12.x)下维护了相应的最新版本的 -STABLE 分支。 -
lwcdir 是指定分支的内容应放置的目标目录。通常情况下,对于
ports来说,目标目录是 /usr/ports,对于base来说,目标目录是 /usr/src,对于doc来说,目标目录是 /usr/doc。
这个例子使用 HTTPS 协议从 FreeBSD 仓库检出源代码树,将本地工作副本放在 /usr/src 目录下。如果 /usr/src 目录已经存在但不是由 svn 创建的,请在检出之前重命名或删除它。
# svn checkout https://svn.FreeBSD.org/base/head /usr/src由于初始检出需要下载远程仓库的完整分支,可能需要一些时间。请耐心等待。
在初始检出之后,可以通过运行以下命令来更新本地工作副本:
# svn update lwcdir要更新上面示例中创建的 /usr/src 文件,请使用以下命令:
# svn update /usr/src更新比检出要快得多,只传输已更改的文件。
在检出之后,更新本地工作副本的另一种方法是通过 /usr/ports、/usr/src 和 /usr/doc 目录中的 Makefile 提供的。设置 SVN_UPDATE 并使用 update 目标。例如,要更新 /usr/src:
# cd /usr/src
# make update SVN_UPDATE=yesA.3.5. Subversion 镜像站点
FreeBSD 的 Subversion 仓库是:
svn.FreeBSD.org
这是一个公开可访问的镜像网络,使用 GeoDNS 来选择合适的后端服务器。要通过浏览器查看 FreeBSD Subversion 存储库,请使用 https://svnweb.FreeBSD.org/。
HTTPS 是首选的协议,但是需要安装 security/ca_root_nss 软件包以便自动验证证书。
A.3.6. 更多信息请参考
关于使用 Subversion 的其他信息,请参阅名为 《Subversion Book》 的书籍,或者 Subversion 文档 。
A.4. CD 和 DVD 套装
FreeBSD CD 和 DVD 套装可从多家在线零售商购买:
-
FreeBSD Mall, Inc. + 1164 Claremont Dr + Brentwood, CA + 94513 + USA + Phone: +1 925 240-6652 + Fax: +1 925 674-0821 + Email: [email protected] + Website: https://www.freebsdmall.com
-
Getlinux + 网站:https://www.getlinux.fr/
-
Dr. Hinner EDV + Schäftlarnstr. 10 // 4. Stock + D-81371 München + Germany + Phone: +49 171 417 544 6 + Email: [email protected] + Website: http://www.hinner.de/linux/freebsd.html
附录 B: 参考文献
虽然手册为 FreeBSD 操作系统的各个组件提供了确切的参考,但它们很少说明如何将这些组件组合起来以使整个操作系统顺利运行。因此,没有什么能替代一本关于 UNIX® 系统管理的好书或用户手册。
B.1. FreeBSD 参考文献
-
《绝对 FreeBSD : FreeBSD 完全指南》,第三版,由 No Starch Press 出版, 2018 年。 ISBN : 978-1593278922 。
-
《 FreeBSD Mastery: 存储基础》是由 Tilted Windmill Press 于 2014 年出版的图书。 ISBN 号为 978-1642350098 。
-
《 FreeBSD Mastery: Specialty Filesystems 》是由 Tilted Windmill Press 于 2015 年出版的图书。 ISBN 号为 978-1642350111 。
-
《 FreeBSD Mastery: ZFS 》是由 Tilted Windmill Press 于 2015 年出版的图书。 ISBN 号为 978-1642350005 。
-
《 FreeBSD Mastery: Advanced ZFS 》是由 Tilted Windmill Press 于 2016 年出版的图书。 ISBN 号为 978-0692688687 。
-
《 FreeBSD Mastery: Jails 》是由 Tilted Windmill Press 于 2019 年出版的图书。 ISBN 号为 978-1642350241 。
-
《 FreeBSD 设备驱动程序:勇敢者指南》是由 No Starch Press 于 2012 年出版的。 ISBN : 978-1593272043 。
-
《 Freebsd 操作系统的设计与实现》第二版,由 Pearson Education , Inc. 于 2014 年出版。 ISBN : 978-0321968975 。
-
《 UNIX 和 Linux 系统管理手册》,第五版,由 Pearson Education , Inc. 出版, 2017 年。 ISBN : 978-0134277554 。
-
《设计 BSD Rootkits 》,由 No Starch Press 于 2007 年出版。 ISBN : 978-1593271428 。
-
FreeBSD 使用 VNET 的 Jails ,发布在 [gumroad](https://rderik.gumroad.com/l/uwOLZ) 上。
B.2. 安全参考
-
《 PF 之书: OpenBSD 防火墙的无废话指南》第三版,由 No Starch Press 于 2014 年出版。 ISBN : 978-1593275891 。
-
《 SSH 精通: OpenSSH 、 PuTTY 、隧道和密钥》,第二版, 2018 年。 ISBN : 978-1642350029
B.3. UNIX® 历史
-
狮子,约翰 狮子对 UNIX 的评论,第 6 版,附源代码. ITP 媒体集团, 1996 年。 ISBN 1573980137
-
Raymond , Eric S. 《新黑客词典,第三版》。 MIT 出版社, 1996 年。 ISBN 0-262-68092-0 。也被称为 http://www.catb.org/ ~ esr/jargon/html/index.html[Jargon File] 。
-
Salus , Peter H. 《 UNIX 的四分之一个世纪》。 Addison-Wesley 出版公司, 1994 年。 ISBN 0-201-54777-5 。
-
Simon Garfinkel , Daniel Weise , Steven Strassmann. 《 UNIX-HATERS 手册》。 IDG Books Worldwide , Inc. , 1994 年。 ISBN 1-56884-203-1 。已绝版,但可在 在线 获取。
-
Don Libes , Sandy Ressler 《与 UNIX 共度的生活》 - 特别版。 Prentice-Hall , Inc. , 1989 年。 ISBN 0-13-536657-7
-
BSD 家族树. 在 FreeBSD 机器上,可以通过链接 https://cgit.freebsd.org/src/tree/share/misc/bsd-family-tree 或链接 /usr/share/misc/bsd-family-tree 来查看。
-
网络化的计算机科学技术报告库。
-
计算机系统研究组( CSRG )的旧版 BSD 发布。 http://www.mckusick.com/csrg/ :这套 4CD 包含了从 1BSD 到 4.4BSD 和 4.4BSD-Lite2 的所有 BSD 版本(不包括 2.11BSD ,遗憾)。最后一张光盘还包含了最终的源代码和 SCCS 文件。
-
Kernighan , Brian Unix: A History and a Memoir. Kindle Direct Publishing , 2020. ISBN 978-169597855-3
B.4. 期刊、杂志和期刊
-
https://www.admin-magazin.de/ [Admin Magazin] (德语),由 Medialinx AG 出版。 ISSN : 2190-1066
-
https://www.bsdnow.tv/ 【 BSD Now - 视频播客】,由 Jupiter Broadcasting LLC 发布
-
[FreeBSD Journal] ,由 S & W Publishing 出版,由 FreeBSD Foundation 赞助。 ISBN : 978-0-615-88479-0 。
附录 C: 互联网资源
FreeBSD 的发展速度对于纸质媒体来说太快了,无法实现及时向人们传递信息的目的。为了了解最新的发展动态,电子媒体是最佳选择。
FreeBSD 用户社区提供了很多技术支持,其中论坛、聊天和电子邮件是最受欢迎和有效的沟通方式。
下面概述了最重要的联系点。链接: 社区维基区域 可能更加更新。
请将任何冗余或尚未在下面列出的资源告知 FreeBSD documentation project mailing list 。
C.1. 网站
-
链接: https://forums.FreeBSD.org/ [FreeBSD 论坛] 提供了一个基于 Web 的讨论论坛,用于讨论 FreeBSD 的问题和技术。
-
链接: FreeBSD Wiki 提供了一些尚未包含在手册中的各种信息。
-
链接: https://docs.FreeBSD.org/ [文档门户] 不仅提供了 FreeBSD 手册,还有超过四十本书籍和文章。
-
链接: https://freebsdfoundation.org/our-work/journal/browser-based-edition/ [FreeBSD Journal] 是由 [The FreeBSD Foundation] 发布的免费、经过专业编辑的双月刊技术杂志。
-
链接: BSDConferences YouTube 频道 提供了来自世界各地 BSD 会议的高质量视频集合。这是观看关键开发人员就 FreeBSD 的新工作进行演示的绝佳方式。
-
链接: https://www.freebsd.org/status/ [FreeBSD 状态报告] 每三个月发布一次,跟踪 FreeBSD 开发的进展情况。
-
这里有一个链接: [FreeBSD 专注的 Reddit 小组](https://www.reddit.com/r/freebsd/) ,位于 r/freebsd 。
-
链接: [Super User](https://superuser.com/questions/tagged/freebsd) 和 [Server Fault](https://serverfault.com/questions/tagged/freebsd) ,这是面向系统管理员的 Stack Exchange 服务。
-
链接: FreeBSD Discord 服务器 ,是一个用于交流和建立社区的服务, FreeBSD 社区成员可以在这里社交、获取支持或支持他人、学习、贡献、合作,并及时了解与 FreeBSD 相关的一切。
-
链接: IRC 频道 ,是一种广泛实施、技术成熟、开放标准的文本聊天方式。
C.2. 邮件列表
邮件列表是向集中的 FreeBSD 受众提问或开展技术讨论的最直接方式。有许多不同的 FreeBSD 主题的邮件列表。将问题发送到最合适的邮件列表将无疑能够获得更快速和更准确的回复。
技术列表线程应保持技术性。
所有 FreeBSD 的用户和开发者都应该订阅 FreeBSD announcements mailing list 。
|
为了测试 FreeBSD 邮件列表的功能,请发送到 FreeBSD test mailing list 。请不要向其他列表发送测试消息。 |
如果对于应该将问题发布到哪个列表感到困惑,请参阅 如何从 FreeBSD-questions 邮件列表中获得最佳结果 。
在发布到任何列表之前,请:
-
通过阅读邮件列表常见问题( FAQ )文档,了解如何最好地使用邮件列表,例如如何避免频繁重复的讨论。
-
搜索存档,以确定是否有其他人已经发布了你打算发布的内容。
存档搜索界面包括:
-
https://lists.freebsd.org/search ( FreeBSD ,实验性)
-
https://www.freebsd.org/search/ (DuckDuckGo)
请注意,这也意味着发送到 FreeBSD 邮件列表的消息将永久存档。当保护隐私是一个问题时,考虑使用一次性的次要电子邮件地址,并且只发布公共信息。
FreeBSD 提供的存档文件:
-
不要将链接呈现为链接。
-
不要呈现内联图片。
-
不要呈现 HTML 消息的 HTML 内容。
FreeBSD 公共邮件列表可以在这里查看: [邮件列表链接] 。
C.2.1. 如何订阅或取消订阅
在 https://lists.freebsd.org 上,点击列表的名称以显示其选项。
订阅后,要发帖,请发送邮件至 listname @ FreeBSD.org 。该消息将会重新分发给订阅该列表的成员。
C.2.2. 列表基本规则
所有的 FreeBSD 邮件列表都有一些基本规则,任何使用它们的人都必须遵守。如果不遵守这些准则,将会收到两封来自 FreeBSD 邮件管理员 mailto:postmaster @ FreeBSD.org[postmaster @ FreeBSD.org] 的书面警告。在第三次违规后,该发帖人将被从所有 FreeBSD 邮件列表中移除,并被过滤以阻止进一步的发帖。我们很遗憾这些规则和措施是必要的,但如今的互联网环境相当恶劣,许多人未能意识到其中一些机制是多么脆弱。
道路规则:
-
任何帖子的主题都应符合其所发布到的列表的基本描述。如果列表是关于技术问题的,帖子应包含技术讨论。持续的无关废话或争吵只会削弱邮件列表对所有人的价值,这是不可容忍的。对于没有特定主题的自由讨论,可以自由使用 FreeBSD chat mailing list 。
-
不应该在超过 2 个邮件列表上发布帖子,只有在明确且明显需要同时发布到两个列表时才可以。对于大多数列表来说,已经有很多订阅者重叠,除非是最奇特的组合(比如“ -stable 和 -scsi ”),否则没有理由同时在多个列表上发布。如果收到一封带有多个邮件列表的
Cc行的消息,请在回复之前修剪Cc行。无论发起者是谁,回复的人仍然负责跨列表发布。 -
在争论的背景下,不允许进行人身攻击和使用粗俗语言,这适用于用户和开发者。严重违反网络礼仪的行为,比如在未经允许的情况下摘录或转发私人邮件,虽然不会受到特别的强制执行,但会受到谴责。
-
严禁宣传与 FreeBSD 无关的产品或服务,如果明显违反垃圾邮件广告的行为,将立即被封禁。
C.2.3. 在邮件列表上进行过滤
FreeBSD 邮件列表通过多种方式进行过滤,以避免分发垃圾邮件、病毒和其他不需要的电子邮件。本节中描述的过滤操作并不包括用于保护邮件列表的所有操作。
邮件列表只允许特定类型的附件。在将电子邮件分发到邮件列表之前,将删除在下面列表中找不到的 MIME 内容类型的所有附件。
-
application/octet-stream
-
application/pdf
-
application/pgp-signature
-
application/x-pkcs7-signature
-
message/rfc822
-
multipart/alternative
-
multipart/related
-
multipart/signed
-
text/html
-
text/plain
-
text/x-diff
-
text/x-patch
|
一些邮件列表可能允许附件包含其他 MIME 内容类型,但上述列表适用于大多数邮件列表。 |
如果一个多部分消息包含 text/plain 和 text/html 部分:
-
收件人将收到两个部分。
-
lists.freebsd.org 将以 text/plain 格式呈现,同时提供查看原始文本的选项(包括源代码和其中的原始 HTML )。
如果 text/plain 不附带 text/html:
-
将会从 HTML 转换为纯文本。
C.3. Usenet 新闻组
除了两个特定于 FreeBSD 的新闻组外,还有许多其他讨论 FreeBSD 或与 FreeBSD 用户相关的新闻组。
C.3.1. BSD 特定的新闻组
以下是一些与 BSD 操作系统相关的特定新闻组:
-
comp.unix.bsd - 讨论与 BSD 操作系统相关的问题和话题。
-
comp.unix.bsd.freebsd.misc - 专门讨论 FreeBSD 操作系统的问题和话题。
-
comp.unix.bsd.netbsd.misc - 专门讨论 NetBSD 操作系统的问题和话题。
-
comp.unix.bsd.openbsd.misc - 专门讨论 OpenBSD 操作系统的问题和话题。
这些新闻组是 BSD 用户和开发者之间交流和讨论的重要平台。无论是寻求帮助、分享经验还是讨论最新的开发动态,这些新闻组都是获取 BSD 相关信息的有价值资源。
-
链接: news:comp.unix.bsd.freebsd.announce[comp.unix.bsd.freebsd.announce]
-
链接: news:comp.unix.bsd.freebsd.misc[comp.unix.bsd.freebsd.misc]
-
链接: news:de.comp.os.unix.bsd[de.comp.os.unix.bsd] (德语)
-
链接: news:fr.comp.os.bsd[fr.comp.os.bsd] (法语)
C.3.2. 其他感兴趣的 UNIX® 新闻组
-
链接 :news:comp.unix[comp.unix]
-
链接 :news:comp.unix.questions[comp.unix.questions]
-
链接: news:comp.unix.admin[comp.unix.admin]
-
链接: news:comp.unix.programmer[comp.unix.programmer]
-
链接: news:comp.unix.shell[comp.unix.shell]
-
链接: news:comp.unix.misc[comp.unix.misc]
-
链接: news:comp.unix.bsd[comp.unix.bsd]
附录 D: OpenPGP 密钥
这里显示了 FreeBSD.org 官员的 OpenPGP 密钥。这些密钥可用于验证签名或向其中一位官员发送加密电子邮件。 FreeBSD OpenPGP 密钥的完整列表可在 PGP Keys 文章中找到。完整的密钥环可以在 pgpkeyring.txt 下载。
D.1. 官员们
D.1.1. Security Officer Team <[email protected]>
pub rsa4096/D9AD2A18057474CB 2022-12-11 [C] [expires: 2026-01-24]
Key fingerprint = 0BE3 3275 D74C 953C 79F8 1107 D9AD 2A18 0574 74CB
uid FreeBSD Security Officer <[email protected]>
sub rsa4096/6E58DE901F001AEF 2022-12-11 [S] [expires: 2024-01-05]
sub rsa4096/46DB26D62F6039B7 2022-12-11 [E] [expires: 2024-01-05]
-----BEGIN PGP PUBLIC KEY BLOCK----- mQINBGOVdeUBEADHF5VGg1iPbACB+7lomX6aDytUf0k2k2Yc/Kp6lfYv7JKU+1nr TcNF7Gt1YkajPSeWRKNZw/X94g4w5TEOHbJ6QQWx9g+N7RjEq75actQ/r2N5zY4S ujfFTepbvgR55mLTxlxGKFBmNrfNbpHRyh4GwFRgPlxf5Jy9SB+0m54yFS4QlSd0 pIzO0CLkjHUFy/8S93oSK2zUkgok5gLWruBXom+8VC3OtBElkWswPkE1pKZvMQCv VyM+7BS+MCFXSdZczDZZoEzpQJGhUYFsdg0KqlLv6z1rP+HsgUYKTkRpcrumDQV0 MMuCE4ECU6nFDDTnbR8Wn3LF5oTt0GtwS0nWf+nZ1SFTDURcSPR4Lp/PKjuDAkOS P8BaruCNx1ItHSwcnXw0gS4+h8FjtWNZpsawtzjjgApcl+m9KP6dkBcbN+i1DHm6 NG6YQVtVWyN8aOKmoC/FEm1CWh1bv+ri9XOkF2EqT/ktbjbT1hFoFGBkS9/35y1G 3KKyWtwKcyF4OXcArl6sQwGgiYnZEG3sUMaGrwQovRtMf7le3cAYsMkXyiAnEufa deuabYLD8qp9L/eNo+9aZmhJqQg4EQb+ePH7bGPNDZ+M5oGUwReX857FoWaPhs4L dAKQ1YwASxdKKh8wnaamjIeZSGP5TCjurH7pADAIaB3/D+ZNl2a7od+C1wARAQAB tDdGcmVlQlNEIFNlY3VyaXR5IE9mZmljZXIgPHNlY3VyaXR5LW9mZmljZXJAZnJl ZWJzZC5vcmc+iQJSBBMBCgA8AhsBBAsJCAcEFQoJCAUWAgMBAAIeBQIXgBYhBAvj MnXXTJU8efgRB9mtKhgFdHTLBQJjlXeQBQkF3u+rAAoJENmtKhgFdHTLOVoQALS3 cj7rqYkHiV4zDYrgPEp9O1kAyGI8VdfGAMkDVTqr+wP4v/o7LIUrgwZl5qxesVFB VknFr0Wp5g9h0iAjasoI5sDd6tH2SmumhBHXFVdftzDQhrugxH6fWRhHs0SaFYCk Qt5nFbcpUfWgtQ35XTbsL8iENdYpjKXsSFQrJneGSwxIjWYTFn6ps/AI3gwR8+Bn OffEFdYugJ049O6Vu6YBFJHrnMO7NbF4v95dVYuLtpMIaXWM+V9KITmhaBzFz5fM Q7UOzcLlbxOYKNIWcp8QQk429mayKW5VUeUExUD1ZzBHn+P6ZG7QTMDu/RmBqiHo ewCMVz4n9uXT5BiOngE4CvS0WQwHzK+k9MLpG2u/Bo9+LT0Ceh9Ou1rfU5+0tRwl GyOFFjf3INS7I7gkcAwxQ7dzDItN/UQPZpg8y9mABU2x4enz0AvTnb61d/1dnTEr tdNgU433he0ZnD1HurZCjBEWC656wv6iMdWcD8gjhMbmEpPmjvXcYlTO6zhEygSM DiwdQCWK2W4++YJerA6ULBi3niNWBpofOFH8XylV56ruhjtHCo7+/3carcMoPOJv lVZ1zCKxLro3TRBT15JTFBGqblRyTopFK3PuxW//GTnZOtpQEOV6yL4RAXcWeC1d 1hb5k/YxUmRF6XsDNEH4b08T8ZO8dV3dAV43Wh1oiQEzBBABCAAdFiEEuyjUCzYO 7pNq7RVv5fe8y6O93fgFAmObXVYACgkQ5fe8y6O93fiBlwf/W8y1XXJIx1ZA3n6u f7aS70rbP9KFPr4U0dixwKE/gbtIQ9ckeNXrDDWz0v0NCz4qS+33IPiJg1WcY3vR W90e7QgAueCo5TdZPImPbCs42vadpa5byMXS4Pw+xyT+d/yp2oLKYbj3En4bg1GM w71DezIjvV+e01UR++u1t9yZ8LOWM5Kumz1zyQLZDZ8qIKt1bBfpa+E0cEqtNQWu iGhQE3AHI8eWV+jBkg5y2zHRIevbWb1UPsj43lgkFtAGHk9rrM8Rmgr4AXr531iD srBwauKZ/MElcF3MINuLH+gkPPaFHw/YIpLRLaZXZVsw3Xi1RNXI2n2ea29dvs/C Lcf1vYkCMwQQAQgAHRYhBPwOh4rlr+eIAo1jVdOXkvSep+XCBQJjm14FAAoJENOX kvSep+XC0DcP/1ZB7k9p1T+9QbbZZE1PJiHby3815ccH3XKexbNmmakHIn3L6Cet F891Kqt9ssbhFRMNtyZ/k/8y8Hv5bKxVep5/HMyK+8aqfDFN0WMrqZh0/CiR6DJh gnAmPNw/hAVHMHaYGII9kCrFfPFJ02FKoc81g9F08odb7TV+UlvRjkErhRxF+dGS wQoO0RCbf0Z1cs7nd0Vb2z4IJh4XMxBjWc/uQ2Q9dH/0uRzwpAnR4YX+MG5YrX7Z zBvDyR0r76iQwRSDKgioNgkr6R3rq1NZGdaj+8b0LzdOqtzKJ/eupDe3+H67e/EN qymtreGjrubpiU9bKvYArisUqhE5KtguryvR6Qz9bj87nPg33DT3WWGVrwFRxBox dbWzjQFv0wug8m4GAwVF7fPR5/eW7IHw8zvgn0vSPcZz7MZ4e6Y5jN4kA5/xWJYZ Sps54qQWB+FA30unIXN68KqdIzONIbtaY3W4/JjJUCm4T+wEjKaH+wJX8w1DMjlg mkTmGh/UrTyC1vXbPgk9Sy3cRTICR1T9z7W8UlmTtnKrUklrjlFR7SXzrEXzLGOX Fm+NEHpHNXqzcm6c3QfzY/yQ9HSAQ/t7SUQ9caRePbDz3/msyPxtGFor9roQv6VN wRXCyRgkH4Y5tPhJAQ8G/FxX+VXFb93QL0lfelb23/BBu6cUwW63SRn5uQINBGOV dskBEADqo8z6TFAhrvHhJV5wHdj67guoYvpXP8gvdCqos8SLluqi0AWgJEwlqu7L mKQ6qMoJ+2DN6y+dEtvOVgBAgF63LLf3FQKq9FB/3uqeIiQlCIl3H43f8KttEZzf /lbry4Y6QhS2OXM31Ut9Q+1IfTGwvs1E8/J1U4jQrAGqNKknXyQyMweJ0jvvcSLJ nv3S7COUJVOT3cTgVeh3RIQlFzqK2rSQmygDpS8bT8MjCsZr+KGezKpbddKXio4a QW/e6nCMyYR8bo0GQ9DpsyAOsaENnkghncQhA7GdPZK9xLMNQMCp0OdcZlqRVjRZ OutuzNW6PPoczs/NQq02YWK4BPtSV7+ldS9gPZTLIpnRNQRzcnA0vnQTqSAfasVw sAGm+MpH7zcaMf2Tw1K08u7+5gyObgzUzQmGLCgo9VIncnDis0s4gfTmtrr5jCeV 7LYDQX+2fApMtXbVXeKJem1PS+Z6LPbW2HklxYuG5nFgewCYlQjKujfiwW1Clhi4 JQeE1Naobbaar99V/VeoHrOYAEWP0bkUyrFcocLJ+0g3KpjSkctIptgGGpMBKe4U 9O7pWoTki8Yz/uYQn/p0iZcG8SfKM8I4283jdsi5SUiNNJJZCBQTVA7d8MxUVv5+ qpX/v5XqYM3pHza2DLXzwfAE9O2dgN1OMZYIld+OnWcpm2PxIwARAQABiQRyBBgB CgAmFiEEC+MydddMlTx5+BEH2a0qGAV0dMsFAmOVdskCGwIFCQICKQACQAkQ2a0q GAV0dMvBdCAEGQEKAB0WIQS2FSd+gQh991yBgztuWN6QHwAa7wUCY5V2yQAKCRBu WN6QHwAa77gbEADpUBT14cesITuMsOWYsyEtNmB4UlTFWCktk/YzyCotasZxIhMP Xih9G1tDo9ExIWT8jNjSSA+w0Viua/PirDLvI8JtX1JiK3nwMenwlXwlkRAk9TJW y944YegHF/5ytntwZ/L4BMYc3MztyZbw+sDwnNBZKYmO8gwfYobtfoGxOR4Onb37 bbUVw62xHQIn2zafSmMQ4oMXZTm9EteIYwgcrC1h+Urv5IXCJZHrqmXCPE5g5XZ1 G9jqkwlaRYWjcLD0qxwc5m9LNrF6OBS9N6S7DncIYt9VupI5OCr1uRSqzqaBMFDC lTTH+dAx3b6J1KFB0UiHP3FeTalFh8L3NE+dN9apNAgkUWv/v4oo/6dkRu3NZse2 RAo/o2X5r40qk/lhydQRZTSTFsiuH3VUWVsgmqAHnHW7pMMw8FAlKhyRSFnhbW7r e0jj8XMIO7G5yjQKQCnYuPdXbx++bP1PzsEWDv9j/sph5arcosdo6tEXklWHED17 MEPIton1+NRfsU0peEVggQXlwdTcZN/h7FeCZ56dcwCWdCpSlv6CcWzRXSNUyJpK a9qfIqBX/monjy7w5IHmhvLwAYI6IoT11h1QDEfGfhrwWPwOjnXsaYm5E7wv8w69 PxMbOJbMpWSg8L7xW3LXKR1VwXggUC1+b3y67E5Ggi1hf0lfTnTMpL2ClO2QD/oC hMIafhzxbjh2WzgYahVHZH3gpHc1/0Bnc07s9+Pa6EYYM9r0XzezLW7bswOjVloR FreQ3FIF/2OSN0OGdm7dyYl0OliTIDDDlwK/l8bcckUcpHNR1dw0P3KvDlmLmzZy G4HmzzSBa9jiFirEfcg2rnGc6Zi382jGVALuYVplPXyMOUiChp0AAQZzTIYpXw/g pBE6em2k740yuK6WqG4yXXgk67FoH10TQvMd4Q73K4zw+9DMpThlUHcfBmAoViZw il7C0xl+ysHX8ZI3JU8s1r3XAnpqdHi4Wpixm/ctXbVnTSA3FQr2SctJYqR1VHRW GMW+Ii2SQDS+t9bZTzOgAPLDtfy+JqhBpwCB1a1EHftkJEojpfZipaYGkf3yc+vN wUeUHp/csF9CT7Qbqaj1t7fVWzv7jcVKpRwngIT4vTSzqbo6WC34FuUAH0t7tJ5K eZ625AqEFLmtqtDo+ydJhZrVrXBNXPfkx5hSVW/I9hvckMNwA3t0KfQC2sz+Z1Q1 a4vDWQYRytfyrgZkWGbXMn6l1JyqIolgJZuax2kYs7Vu3t8KptqCbv0ZBAGoMm7r RLgVodhI9voA8YxCirSChrueJYn+JKk8MIyk3DdXpBoocMIAjFJAUgXjV5NQpZMy xR8BEiQnBcHRIKVWEEyhbLtHpmCEsnKNyKVGoxs31LkCDQRjlXcHARAAykVVzNmj 1k82yBbv3VRbmjrCeud3Wcg75LitzfurZMTPwoYcK7Gjk3B99na3oufTgEjniltq mDXtvtrSE+RrfscWQvbyfhXIx3HQKwCbdAR9Sx0rrHApXZK5xh5VytXW6lw3g91c Puy7Ujv8DgJZcUkbTjvMnRnz2UlmJASICruCG8SiKcLSyb7Rrpqj+hyoKBYIozXI I87LMleV5Gu/b1JGdjOIxH6rZTTH3GD1eXoYzBSYXBslz2c5FW8sft9tTr927wSC gBiuCUU4Vkb9NKiVIZZFIyJq/PQlIP+L6sQ3hohPhZ8F74v1bLUCas3GIA77MqbM dC7clLEOdyv7L6Fx35bSCrDXQWgj2NYtwvuRH7prSI6O4lJdKimraXcNp+I/G0IW avgIZCHMEczp7j+/8013cXRelVsnpFCmHuWR+9/PyraW9SUeF7MnSnXFeaF9/0Ie N1UyGYCbPn6KYEBeTaai2018pvSkUR6fXFjcr9Q8DiD6g+xKPj3kyy8iD14gwJwL f/PRIRQxYf+y3LInM+p+nJ8bBl5NwiP2+Daj5Gca+ZwtVgD8QZOg+T3TmS/9wrve jLxtnI4HTMyDtP09paAtQ7SyqOqjQzDeScXJKDehFeVyKU9C9891fQm/Aulz0NaW vX7UaQJcnTyVa6Alz3oIlC6kpFvUhsLShRcAEQEAAYkCPAQYAQoAJhYhBAvjMnXX TJU8efgRB9mtKhgFdHTLBQJjlXcHAhsMBQkCAikAAAoJENmtKhgFdHTLDC0P/AgO YRwd0WXIVFOiZQGNt4ra7NxkiGSSAvnyVzrdQ+V7mInYUG+ZhL7StBLnexUSxxyf kp+Q7BOvIqWW9ZuXQjO6Kp9rDEAtx9al9kkfNMxKcMd+Be847IUxCu6pEMAcCvs8 0LQKdtPSwQXZkXNp3wz18uq2RdTHiaAQI0YngJWqDvkpjy5TO/8GZHAR/nzsVPn+ IAh53kyMUHZUUNf0YAFy9NNsfEJkjGfGXdyzXlLFPSUCh9na55TqRZhZlJcV5oQz /jKY8nCzaaZXQCRsmCEtcKf0zHedfo1Nln0dqtuu75HNbf8eDcNl3Qn2+Sjw9p8/ SXU1a2DJfvgKq9OCPNPFdOeqtFfNxzMrt+FwLa7iLSms+1ddzLKLtLCmguKRpkIs UWFSY7H6ZLlOO2AXIVkE3Gc7uIDCTN9xNwL2w+hZoWaJB/qrkQhjMb5ZCmdyPzSb GXcdY4/qgWP+FklFix4p4yS8nMtOjzusV0zoKwysvARNHp75pYzRu08WKXWtdUAI 06OzLRvFNXw4kR/LGdibKO+cG8HSR2JpUQN1WHGBKrMsBfiaBdrj39Xoz+7Myv6f f8DUl2ThXp9WbxLlwUhfGhRq3dwHjEZpP05YPejU0+vp5L1WjQSwmVGXzVIbrx9L 5C2TZ9fbtPrxgbgBrfMx9nFSxW4Uu1O5BtEL58mk =tw96 -----END PGP PUBLIC KEY BLOCK-----
D.1.2. Core Team Secretary <[email protected]>
pub rsa4096/BE3DF7A86914D607 2022-07-29 [SC] [expires: 2024-07-28]
Key fingerprint = E0C0 73CF 01A2 A902 800C 3680 BE3D F7A8 6914 D607
uid FreeBSD Core Team Secretary <[email protected]>
sub rsa4096/7882C7A2CA320B52 2022-07-29 [E] [expires: 2024-07-28]
Key fingerprint = 7828 1422 F522 802B 00AE 0410 7882 C7A2 CA32 0B52
-----BEGIN PGP PUBLIC KEY BLOCK----- mQINBGLkULYBEACsS9RbAv8gIyZWtIWgBeK6+ircHRW0LsetvHqQYlY6gfRWDLN+ 467o0dHwAz4c1jyq7Or+1gy2Kr2VpcPZr1kjNTx5NbvoybQJMIMs77o9LS3Q2pA0 3Dpi8LSaM77rCmIXFmKEspbuPyjjTjKUtpOmzvwMDq8ke7ZHrqkJOessKQVGUSJc o+4hcN6S4gGRgzRHLOuPtDqIfxFuHjr+4ZEGeispJHZqtl+HwBOEdoG966hKo/Ae eyIRMB1vioqf8GHuiVHZ3YJbbcLN/4oMMtN/aIgucfspKo2O95zUETkimGTBlEl0 RVFXF5kq3gq2p7+7Sl3OQ3Kw8LQ9ueinWNJ5/3X06UowsRbOxtx7Jtp4DFwhpHj/ LTdEUSjiVzeZKiqDOqvgjq2ZN4hLHEZYan3mv55AUnwzwzMD04P42mNHetCJnuNP ZGGL/wmABc8X4tx/fGddECKBzCM8hHBG7WQkDUnMTpODhBXCcC+rm6Vz7FS1zv67 CftMneqWnDDZtf/XclnHI6iOJZPcY/ljV+QxGs+oLvn2mlR6xzHu9osYfGuozA6x PIxrSgB7PWFSuSvqtN7fSwAiXOAI5zFpZ4HP8wjFt7SWfMaovc/FR8rzYaZSZYAk 0l+FmsMbBGvkHNdPyk/4CWqj3dg4HCFAeqUWVLo3qKHdTOQaTqavyYYBCwARAQAB tDhGcmVlQlNEIENvcmUgVGVhbSBTZWNyZXRhcnkgPGNvcmUtc2VjcmV0YXJ5QGZy ZWVic2Qub3JnPokCVAQTAQoAPhYhBODAc88BoqkCgAw2gL4996hpFNYHBQJi5FC2 AhsDBQkDwmcABQsJCAcDBRUKCQgLBRYDAgEAAh4FAheAAAoJEL4996hpFNYHPRwP /R5lWY8RcsAxAwXqzCRww1N2D6aRVUK+wJfxlMYRFjT9o0phmlSQxhORJATbjLm3 prLkpFBsMOScDmG7kWttPSHoQFKBiA7IznVeT4hka9c3Id21EL54GEjjDyp6AFev G5kNCu8vS6SxmyUD9U2Q7PiEiEq7907tfydJfJ5BEzS5Az6KTOITaZ716qxQVQFR 6i6ChMCBABT059QngTiRp0sY2TPzTepHxEyrE//8M0mgyBsaRWPQP712sVujjx82 /3fXMxKwnJTGRhy0qR+DbIeSK/OiU4OJISG1XG/IkAQEqPwG6UilXy60l5PectJD FAGRgky/Jmh9QTL4lhFLmpEyQhjVOZANZ1lqfD6lEjsf/Adr3stcKLNMLT8xewKo LrFzSWMXh35HsSM/ZJng9CiJlAckGNBwuYp+5z49vBWaUXj9/KzK+0uKO6OspDIG sF7M33BOqOP48ssIZWdJihwMA8qSX+ZFq+yMn8YdPmszXcEe4H4U1curdGWMm7IF DwUl9cMEfYiPhvuO5taJBDerEbynyMI6oYbFnfl3Bb4rknlatiCzKXrzR1OuRtho RkAPVSnEru0FTgCHToRdj81qyAwa6VMsEtVvqhNtsWBvr8W9Bdj1zZUV0hCJOzZN UfAmlRXkud8lK4UyxBHUrNSy4ufGRjMNOhuUmBZVwrTSiQIzBBABCgAdFiEES2Tp 4L3ps+zAa1xm2MjIO0nybxcFAmLkVMoACgkQ2MjIO0nybxdeBBAAhCqcnsVVUpL6 w9CQV71kkSoT0649GkbWeG+ob1XgXvjxCSRb7mxSx7KCiUkLtnzVUOe+qp15pbAm o9zlHZ/yQQxA3pUX5npIIiWXSWknA3DGNKE52RJ1tbpIVhFjrseXa4gsrxrUVtCF dHsCFl/G6Zr1h+OutL6DHxQH0ZI2OmxRQFxE0Bwjyx3HdLmtKCEZVYUuhMoCya9m 5Uu98nQOMH7jDMbj8za7JJiwZwjKNZfiNck8Ekq0DEXr3CKSueobHr3JqSLt9VKV WzaGKDQ/sVQz4L7GZfR1yMAJQlWulsTvxGG4SWxnFsus9GNydQIEmkTfDLmBXkl4 PNNsTirNir3ld7KEIY07jffqK88uV3nZ+Cc2VUdM4GRddH4LdJnKyY+O8AXrEAse 9aUmWGmesbOSAV0ATLGfFM96eFuGMdgwxl25W3RxKlLABAdLRd5smW5RCDOSyrqZ 0F3mpqCGMG84Us93/G5hdYsULuJxlufMur4SO5kRp6h/+tuDR1TAzkAoHut16ODD fnto8OhmLk1W3yfddh8i5e5jBU1NZkmHSYOKhs0iBcSBR0t594E3xNCUQYNZswlZ rVNCL7o1HEuln0p+qrcOVWqQ9ovb4mE5qupRydr4+moxmJy6y5bQp3QaIxentHnY 1aq8A8o2OV8sFNbH70p7+fB+W1HeviS5Ag0EYuRQtgEQAMT6Pik/xPzARb/UjjVS Wvo7AQjtLC3yKNg1yAey3T0gp6YKYs5vlMJckS48LDZagiqgcDucly52nk2sMWqu +yllgBLrwm+SY4g7hqrDgXrOspZUyLysKB5fyF60qOGcjfmZgAFPh8MN4Zym/tD1 3dThrSsBJJ9jrX8OCBLlV5sXbbpx6jwtLe4wzeJOfMctW+U3U6zmJw8ZOYU7cG/M 5xSh1s9W1iju4DXo63gOtnyYad27BexHu19e/nAwxQwLaofDX9R9Y0pORFHI1SuO IrQIHXhwgZHVRBNulPtM2zVVN1jWC5X9YLu4rc/F01BO0B4GQosYtlmcK7Rm7obx Dm+o0pPw3xyFnl1vOXWsmRDUP6qATk3YKuHdYRe33SxFPm7iWEB+rVL41dqquMRO L7HIt9ho9MWTac2a9jHIX17xK9Q/P/zy6ZLjwtcyirPezct4GWvIPJ+mdrmI39nn Y/TFcBZ3G0BtwasFnuFjHbkjcBlqvtHc1Zg/hISaEDTbSDr0TMLpxG2OpT5xqMkq PO8S04IpMtKWd1aRliv9vE65UHAGHVe8EOVmGT7Tk9cCqFxrxpwE8n+KU5JGUGTc BnpuCedT3txnZZc90d/+yMotJPpLUmOdndj782Y4B5y5JXpTefvxN2lBOorVN1xu zH43SkAA7lvuN0x4QpmzWJoLABEBAAGJAjwEGAEKACYWIQTgwHPPAaKpAoAMNoC+ PfeoaRTWBwUCYuRQtgIbDAUJA8JnAAAKCRC+PfeoaRTWB/RdD/94yvoMl/VtJqTR Lc7Qu41y/SdczDAfCGPts49uu56xRqCfcLZOLr4PNXh49x0UWFroTcpcFlcsS++D EOoR2DoyxB1+KKRhceBo1CmQ8Y7RQ0LpQzYPkqBmzVEZK/I5dKf+RX83E7sa5L28 UpCrsDSsp7dVrxmwdiiOsJBD1vA5vIGgtgTGewMNmPO4wbhmjFTIxPnSND6wRYyW SBgKkEz5lnA6zHOMYiXabKI/oY23xq4YRu2UOVoZMUkXoqR09McwrqMI4+XJBSwC c2G6FI4uEO6YIDGXlUZhCGDGwE+HVcP6/jshyi1HOtUpcemle//YSvyrp6N/8XkZ RX/dvUNIBl+ykIE/wb75PWI7QTNLWkJmCU/ft9m1KEHAwccyxHJxXWurnBbMgMan VfLYH4uJ0eH/O65zTIzRdZcMO4kY1vVllAKXY9Httxpdua0n+4rHplxL4ZfRL7Y4 5h7/Xiz5xfGcYxPd5/ezfYzcvfDr4danX8fBe7U9F2VaO/QOhcgCLV8TevR1Ku/0 GUOfPAH6rhZaLqqz92Y2hOX1QQ6MabB92DUFZh+5SUxCzqI6cAiH60Rbf9ZI579s L32GpxZ6BPISnsy69SNAVBiczw8EthEY1KhdN9QOuHppqcGsOlIz8cKVojqzILwj GT6wtOZXl/ri7I8x3Fr89V3sUvmg1w== =2Il1 -----END PGP PUBLIC KEY BLOCK-----
D.1.3. Ports Management Team Secretary <[email protected]>
pub ed25519/E3C401F60D709D59 2023-03-06 [SC] [expires: 2027-03-05]
Key fingerprint = BED4 A1D3 6555 B681 2E9F ABDA E3C4 01F6 0D70 9D59
uid FreeBSD Ports Management Team Secretary <[email protected]>
sub cv25519/2C92B55E27A641C3 2023-03-06 [E] [expires: 2027-03-05]
-----BEGIN PGP PUBLIC KEY BLOCK----- mDMEZAXJvxYJKwYBBAHaRw8BAQdASFAC20WL3R1T6uNyGMZbfJCxDkcP4C5vi3Op tcZ2fbq0R0ZyZWVCU0QgUG9ydHMgTWFuYWdlbWVudCBUZWFtIFNlY3JldGFyeSA8 cG9ydG1nci1zZWNyZXRhcnlARnJlZUJTRC5vcmc+iJYEExYKAD4WIQS+1KHTZVW2 gS6fq9rjxAH2DXCdWQUCZAXJvwIbAwUJB4TOAAULCQgHAwUVCgkICwUWAwIBAAIe BQIXgAAKCRDjxAH2DXCdWYN1AP43TjyfZtZ3DLYT++g0+SuPsoO/3yWVybA+UmFL zb8MngEA+LLNUfvEwCuXS/soh+ww5bpfmi3UUmeGiQEAXug3iA+JATMEEAEKAB0W IQT7N0XIbxXo7ayBMvzYKU7Du8TX1QUCZAXLkwAKCRDYKU7Du8TX1XHMB/9R1MX4 6zMgpKqPPt76GOI+eGEdBK6bY8aJZjQGdqTh9f6VtXVoTGIG7cvhc9X8tDBoB0PT 2KZWheF51AV1+NHU4HwLAQ1BMebrFvWSfkw4xg4fBGwDhz9/GN85No+Js772V5ey 8lRiL6meRVWxMlLyWcxGd8JjcC5yX/iAUQ3SBGCLqW7unWjjg7CTd+AMBwcqPGrv ax8q6eFVguJcHJAjMnKf6HAy4cpK3s+uMoUBCGnszSN12B3ysKfyC4pNO/pix5tA Q5v8aRqTeFPh5zmNhWo0KGPzplTPqRQSHDl7GDQC8Ru3MhzFkeWzHsexjZVwS6W2 DPcYpuuAsA0XOZIZiQIzBBABCgAdFiEEEBpxaxYrAOVb7eoFrbv4YQo3ibcFAmQF 0u0ACgkQrbv4YQo3ibccwg/9F2Xuic3nhKxRbB3mJeDo6SYQETa/Gh1qQ34+8zlt 8UMazOx67gnYQfy+pXjro6eQ2up0a4eUYezcNOudqAQD21nRz3HA6EQVNcE/TzEA xl5CJntTaLOt7S+EDXFW5BuQIvhhoMGgm8+WNVgA0EJ7tfL0OcYBSvr19fqwChEn 9c14cSk6mgHSsleP5NvskYN053pxHwy0LTSb8YBBv52th37t/CRFC1363rS5q+D7 JixFopd1O5pKpA5ipvE4gGgRjPtwjx0SjjepwK/3fuhEJQQyKzTIKlMfu2Dj/iR2 Li1Sfccau5LQXOj9fUITU3u1YG7yrm8VGzT7ao4d+KRwgMLjd2pLqiGIbbJwGBiP FRmtilWQoeIlmSlFX4obAA517DOK0pW1mH8+eEn4EJd3SekT3yzFyKTASv0J48Z8 3F928xg+eZvHxVC0t1J+J5IG0gt3EEncuWKIPQGR7PiQbti6R3FQVTz6WfMWOebP Qi0E9F/Aqakr6Vj2sKGrDq+ebpaF5G8Yw1YrUl2IDiPzkCegp3ZbI0wh11Xvzhi8 LXPQGK4jBQas4G8cegfitzmtdGRHYrbMv0R9I4mvaL+WlOuD2AvyVG28lguqVhnN AZP+ohdquYyX2CNCVvbKWAtXo6Ur0vWG8BL8m6defAtEkIwVBALaOHQOSI3aNUz4 lwy4OARkBcm/EgorBgEEAZdVAQUBAQdAsefmSfxEOdOr02+K/6noYCuJ1FeAWVz6 jFYQ+9w6jggDAQgHiH4EGBYKACYWIQS+1KHTZVW2gS6fq9rjxAH2DXCdWQUCZAXJ vwIbDAUJB4TOAAAKCRDjxAH2DXCdWRl4AP9h5ot212BK29S6ZcMBhHvmtF5PG1oD c7LnZycSRmbFiwEAndCMpAGOhDW8iVgDd0wLQq/ZMPe+xccfG1b3zFH2EgE= =iiAT -----END PGP PUBLIC KEY BLOCK-----
D.1.4. [email protected] 是一个占位符,表示文档工程部门秘书的电子邮件地址。
pub rsa2048/E1C03580AEB45E58 2019-10-31 [SC] [expires: 2022-10-30]
Key fingerprint = F24D 7B32 B864 625E 5541 A0E4 E1C0 3580 AEB4 5E58
uid FreeBSD Doceng Team Secretary <[email protected]>
sub rsa2048/9EA8D713509472FC 2019-10-31 [E] [expires: 2022-10-30]
-----BEGIN PGP PUBLIC KEY BLOCK----- mQENBF27FFcBCADeoSsIgyQUY8vREwkTikwFFlNg31MVy5s/Nq1cNK1PRfRMnprS yfB62KqbYuz16bmQKaA9zHN4FGfiTvR6tl66LVHm1s/5HPiLv8sP14GsruLro9zN v72dO7a9i68bMw+jarPOnu9dGiDFEI0dACOkdCGEYKEUapQeNpmWRrQ46BeXyFwF JcNx76bJJUkwk6fWC0W63D762e6lCEX6ndoaPjjLBnFvtx13heNGUc8RukBwe2mA U5pSGHj47J05bdWiRSwZaXa8PcW+20zTWaP755w7zWe4h60GANY7OsT9nuOqsioJ QonxTrJuZweKRV8fNQ1EfDws3HZr7/7iXvO3ABEBAAG0PEZyZWVCU0QgRG9jZW5n IFRlYW0gU2VjcmV0YXJ5IDxkb2Nlbmctc2VjcmV0YXJ5QGZyZWVic2Qub3JnPokB VAQTAQoAPhYhBPJNezK4ZGJeVUGg5OHANYCutF5YBQJduxRXAhsDBQkFo5qABQsJ CAcDBRUKCQgLBRYDAgEAAh4BAheAAAoJEOHANYCutF5YB2IIALw+EPYmOz9qlqIn oTFmk/5MrcdzC5iLEfxubbF6TopDWsWPiOh5mAuvfEmROSGf6ctvdYe9UtQV3VNY KeeyskeFrIBOFo2KG/dFqKPAWef6IfhbW3HWDWo5uOBg01jHzQ/pB1n6SMKiXfsM idL9wN+UQKxF3Y7S/bVrZTV0isRUolO9+8kQeSYT/NMojVM0H2fWrTP/TaNEW4fY JBDAl5hsktzdl8sdbNqdC0GiX3xb4GvgVzGGQELagsxjfuXk6PfOyn6Wx2d+yRcI FrKojmhihBp5VGFQkntBIXQkaW0xhW+WBGxwXdaAl0drQlZ3W+edgdOl705x73kf Uw3Fh2a5AQ0EXbsUVwEIANEPAsltM4vFj2pi5xEuHEcZIrIX/ZJhoaBtZkqvkB+H 4pu3/eQHK5hg0Dw12ugffPMz8mi57iGNI9TXd8ZYMJxAdvEZSDHCKZTX9G+FcxWa /AzKNiG25uSISzz7rMB/lV1gofCdGtpHFRFTiNxFcoacugTdlYDiscgJZMJSg/hC GXBdEKXR5WRAgAGandcL8llCToOt1lZEOkd5vJM861w6evgDhAZ2HGhRuG8/NDxG r4UtlnYGUCFof/Q4oPNbDJzmZXF+8OQyTNcEpVD3leEOWG1Uv5XWS2XKVHcHZZ++ ISo/B5Q6Oi3SJFCVV9f+g09YF+PgfP/mVMBgif2fT20AEQEAAYkBPAQYAQoAJhYh BPJNezK4ZGJeVUGg5OHANYCutF5YBQJduxRXAhsMBQkFo5qAAAoJEOHANYCutF5Y kecIAMTh2VHQqjXHTszQMsy3NjiTVVITI3z+pzY0u2EYmLytXQ2pZMzLHMcklmub 5po0X4EvL6bZiJcLMI2mSrOs0Gp8P3hyMI40IkqoLMp7VA2LFlPgIJ7K5W4oVwf8 khY6lw7qg2l69APm/MM3xAyiL4p6MU8tpvWg5AncZ6lxyy27rxVflzEtCrKQuG/a oVaOlMjH3uxvOK6IIxlhvWD0nKs/e2h2HIAZ+ILE6ytS5ZEg2GXuigoQZdEnv71L xyvE9JANwGZLkDxnS5pgN2ikfkQYlFpJEkrNTQleCOHIIIp8vgJngEaP51xOIbQM CiG/y3cmKQ/ZfH7BBvlZVtZKQsI= =MQKT -----END PGP PUBLIC KEY BLOCK-----
FreeBSD 词汇表
这个词汇表包含了在 FreeBSD 社区和文档中使用的术语和缩写。
A
- ACPI 机器语言
-
伪代码由一个在符合 ACPI 的操作系统中的虚拟机解释,它在底层硬件和向操作系统呈现的文档化接口之间提供了一层。
- ACPI 源语言
-
AML 是一种编程语言。
- 访问控制列表
-
一个附加在对象上的权限列表,通常是文件或网络设备。
- 高级配置与电源接口
-
ACPI 是一种规范,它提供了硬件接口的抽象,使操作系统不需要了解底层硬件即可充分利用它。ACPI 发展并取代了以前由 APM、PNPBIOS 和其他技术提供的功能,并提供了控制功耗、机器暂停、设备启用和禁用等功能。
- 应用程序编程接口
-
一组程序、协议和工具,用于指定一个或多个程序部分之间的规范交互方式;它们如何、何时以及为什么协同工作,以及它们共享或操作的数据。
- 高级电源管理
-
APM 是一种 API,使操作系统能够与 BIOS 协同工作,以实现电源管理。对于大多数应用程序来说,APM 已被更通用和强大的 ACPI 规范所取代。
- 高级可编程中断控制器
- 高级技术附件
- 异步传输模式
- 认证邮局协议
- 自动挂载守护进程
-
当访问文件系统中的文件或目录时,自动挂载文件系统的守护进程。
B
- BAR
-
参见 基地址寄存器 。
- BIND 是一种开源的域名系统( DNS )软件。它用于将域名转换为 IP 地址,并将 IP 地址转换为域名。 BIND 是最常用的 DNS 服务器软件之一,被广泛用于互联网和企业网络中。它提供了高度可靠和可扩展的 DNS 解析服务,支持各种功能和配置选项。 BIND 还具有强大的安全功能,可以防止 DNS 欺骗和其他网络攻击。
-
参见《 Berkeley Internet Name Domain 》。
- 基本输入输出系统( BIOS )
-
参见《基本输入 / 输出系统( BIOS )》词汇表。
- BSD 是一种开放源代码的操作系统,它基于 Unix 的设计原则。 BSD 是 Berkeley Software Distribution 的缩写,最早由加州大学伯克利分校开发。 BSD 操作系统具有稳定性、可靠性和安全性的特点,并且被广泛用于服务器和嵌入式系统等领域。 BSD 操作系统有多个不同的分支,包括 FreeBSD 、 OpenBSD 和 NetBSD 等。这些分支在 BSD 的基础上进行了不同程度的修改和改进,以满足不同用户的需求。 BSD 操作系统也被许多大型互联网公司使用,如苹果公司的 macOS 就是基于 FreeBSD 开发的。总体而言, BSD 是一个强大而灵活的操作系统,为用户提供了丰富的功能和可定制性。
-
参见《伯克利软件发行版 (Berkeley Software Distribution) 》。
- 基地址寄存器
-
确定 PCI 设备将响应的地址范围的寄存器。
- 基本输入 / 输出系统
-
BIOS 的定义在一定程度上取决于上下文。有些人将其称为带有基本例程的 ROM 芯片,用于提供软件和硬件之间的接口。其他人将其称为包含在芯片中的一组例程,用于帮助引导系统。有些人还可能将其称为用于配置引导过程的屏幕。 BIOS 是特定于个人电脑的,但其他系统也有类似的东西。
- 伯克利互联网域名系统
-
DNS 协议的实现。
- 伯克利软件发行版
-
这是加州大学伯克利分校的计算机系统研究组( CSRG )为 AT & T 的 32V UNIX® 所做的改进和修改所赋予的名称。 FreeBSD 是 CSRG 工作的后代。
- 自行车棚建设
-
一种现象,即许多人对一个简单的话题发表意见,而对一个复杂的话题几乎没有讨论。有关该术语的起源,请参见 FAQ ,涂漆自行车棚 。
C 是一种通用的编程语言,广泛用于开发各种应用程序和系统软件。它是一种高级语言,具有强大的表达能力和灵活性。 C 语言具有简洁的语法和丰富的库函数,使得开发者可以快速编写高效的代码。它还具有良好的可移植性,可以在不同的操作系统和硬件平台上运行。 C 语言在计算机科学和软件工程领域有着重要的地位,是学习和理解计算机底层原理的基础。
- CD 是一种光盘,全称为“ Compact Disc ”,是一种用于存储和播放音频、视频和数据的介质。它具有高容量、长寿命和良好的音质特点,被广泛应用于音乐、电影、软件和游戏等领域。 CD 通常以数字形式存储数据,通过激光技术读取和写入数据。它是数字化时代的重要媒介之一,为人们提供了便捷的娱乐和信息获取方式。
-
参见 载波检测 。
- CHAP ( Challenge-Handshake Authentication Protocol )
-
请参阅《挑战握手认证协议》章节。
- CLIP 是一种基于深度学习的图像和文本理解模型。它能够同时理解图像和文本,并将它们映射到一个共享的语义空间中。 CLIP 的目标是使计算机能够理解和推理出图像和文本之间的关系,从而实现更高级的视觉和语言任务。通过训练大规模的图像和文本数据集, CLIP 能够学习到丰富的视觉和语义表示,从而在各种任务中展现出强大的性能。
-
请参阅《经典 IP over ATM 》的 [clip-glossary] 部分。
- COFF ( Common Object File Format )是一种通用的目标文件格式,用于存储编译后的程序代码和数据。它被广泛用于计算机软件开发中,特别是在 Windows 操作系统上。 COFF 文件包含了可执行文件、动态链接库和静态库等形式的目标文件。它提供了一种标准化的方式来组织和管理程序的代码和数据,使得不同的编译器和链接器能够互相兼容和交互操作。 COFF 文件格式定义了文件头、节表、符号表和重定位表等部分,以及其他一些附加信息。通过解析 COFF 文件,计算机系统可以加载和执行程序,实现软件的运行和功能。
-
请参阅 通用目标文件格式 。
- 中央处理器
-
参见 中央处理器 。
- CTS 是指 Compatibility Test Suite ,即兼容性测试套件。它是用于测试 Android 设备和应用程序是否符合 Android 兼容性标准的一套测试工具和测试用例。 CTS 包含了一系列的测试,包括功能测试、性能测试、稳定性测试等,以确保 Android 设备和应用程序在不同硬件和软件环境下的兼容性和稳定性。 CTS 是 Android 兼容性计划的重要组成部分,通过使用 CTS 进行测试,可以确保 Android 设备和应用程序的互操作性和一致性。
-
参见《 cts-glossary , Clear To Send 》。
- 载波检测
-
RS232C 信号表示已检测到载波。
- 中央处理器
-
也被称为处理器。这是计算机的大脑,所有的计算都在这里进行。有许多不同的架构,具有不同的指令集。其中比较知名的有 Intel-x86 及其衍生产品、 Arm 和 PowerPC 。
- 挑战 - 握手认证协议
-
基于客户端和服务器之间共享的秘密,对用户进行身份验证的方法。
- 经典的 ATM 上的 IP
- 清除发送
-
RS232C 信号表示远程系统被授权发送数据。
- 通用对象文件格式
D
- DAC 是数字到模拟转换器( Digital-to-Analog Converter )的缩写,它是一种将数字信号转换为模拟信号的设备或电路。 DAC 在许多应用中都起着重要的作用,例如音频设备、通信系统和控制系统等。它将数字信号的离散值转换为连续的模拟信号,以便在模拟电路中进行处理或输出。 DAC 的性能通常由分辨率、采样率、线性度和动态范围等参数来衡量。
-
请参阅 自主访问控制 。
- DDB
-
请参阅 调试器 。
- 数据加密标准( DES )是一种对称密钥加密算法,用于保护数据的机密性。它使用 56 位密钥对 64 位的数据块进行加密和解密。 DES 算法在计算机安全领域得到广泛应用,但由于其较短的密钥长度,已经被认为不够安全。
-
请参阅《数据加密标准》( Data Encryption Standard )。
- 动态主机配置协议( DHCP )
-
参见《动态主机配置协议( Dynamic Host Configuration Protocol )术语表》。
- DNS ( Domain Name System )是一种用于将域名转换为 IP 地址的分布式命名系统。它充当了互联网上的电话簿,将人类可读的域名映射到计算机可理解的 IP 地址。 DNS 的主要功能包括域名解析、域名注册和域名管理等。通过 DNS ,用户可以通过输入域名来访问网站、发送电子邮件等。 DNS 的工作原理是通过查询分布在全球各地的 DNS 服务器来获取域名与 IP 地址之间的映射关系。
-
参见 域名系统 。
- DSDT ( Differentiated System Description Table )是一种 ACPI ( Advanced Configuration and Power Interface )规范中定义的表格,用于描述计算机硬件的配置和功能。 DSDT 表格包含了操作系统在启动过程中需要的关键信息,如设备的类型、特性和驱动程序的加载方式。操作系统在启动时会读取 DSDT 表格,并根据其中的信息来正确地配置和管理硬件设备。
- DSR 是指动态频谱分配( Dynamic Spectrum Allocation )的缩写。动态频谱分配是一种无线通信技术,通过实时监测和管理无线频谱资源的利用,以提高频谱利用效率和满足不同用户和应用的需求。它可以根据实际需求动态地分配和重新分配频谱资源,以最大程度地提高频谱利用率和网络性能。
-
参见 数据集就绪 。
- DTR 是指“定义测试关系( Define The Relationship )”。
-
参见 数据终端就绪 。
- DVMRP ( Distance Vector Multicast Routing Protocol )是一种距离向量组播路由协议。它用于在互联网中传输组播数据包,并通过距离向量算法来确定最佳的组播路径。 DVMRP 使用基于距离的度量来选择最短路径,并使用组播树来转发数据包。它是一种基于 IP 的组播路由协议,适用于小型网络和较简单的拓扑结构。
-
参见《距离向量组播路由协议词汇表》( Distance-Vector Multicast Routing Protocol )。
- 自主访问控制
- 数据加密标准
-
一种加密信息的方法,传统上用作 UNIX® 密码的加密方法和 crypt(3) 函数的加密方法。
- 数据集准备完毕
-
RS232C 信号是从调制解调器发送到计算机或终端的信号,表示准备好发送和接收数据。
参见 也可以参考数据终端就绪 。
- 数据终端就绪
-
RS232C 信号是从计算机或终端发送到调制解调器的信号,表示准备好发送和接收数据。
- 调试器
-
一个交互式的内核工具,用于检查系统的状态,通常在系统崩溃后用于确定故障周围的事件。
- 差异化系统描述表
-
一个 ACPI 表,提供关于基本系统配置信息的基本信息。
- 距离向量多播路由协议
- 域名系统
-
将人类可读的主机名(即 mail.example.net )转换为 Internet 地址,反之亦然的系统。
- 动态主机配置协议
-
当计算机(主机)向服务器请求 IP 地址时,动态分配 IP 地址的协议。地址分配被称为“租约”。
E
- ECOFF 是一种可执行文件格式,用于表示可执行程序和共享库。它是早期 UNIX 系统中常用的格式之一,用于存储二进制代码和相关的符号信息。 ECOFF 文件包含了程序的指令、数据和符号表等信息,可以在操作系统中加载和执行。
-
请参阅《扩展 COFF ( Extended COFF )》。
- ELF ( Executable and Linkable Format )是一种可执行和可链接格式,用于在计算机系统中存储可执行文件、目标文件和共享库。它是一种通用的二进制文件格式,被广泛用于 UNIX 和类 UNIX 系统中。 ELF 文件包含了程序的机器代码、数据、符号表和其他与程序执行相关的信息。它提供了灵活的内存管理和动态链接的能力,使得程序的加载和执行更加高效和可靠。
-
参见 可执行和链接格式 。
- ESP 是指英语为第二语言( English as a Second Language )的缩写。
-
参见 封装安全载荷 。
- 封装安全载荷
- 可执行和链接格式
- 扩展 COFF
F
- FADT 是固件可用性和设备性能表( Firmware ACPI Description Table )的缩写。它是一种 ACPI (高级配置和电源接口)表格,用于描述计算机系统中的固件和硬件设备的特性和功能。 FADT 包含了系统的基本信息,如固件版本、电源管理特性和硬件配置等。它在操作系统启动时被 BIOS 或 UEFI 固件提供给操作系统,以便操作系统能够正确地管理和与硬件设备进行通信。
-
参见 固定 ACPI 描述表 。
- FAT 是一种文件系统,全称为 FAT ( File Allocation Table ),是一种用于在计算机存储设备上组织和管理文件的方法。 FAT 最早由微软公司开发,广泛应用于 DOS 和 Windows 操作系统中。 FAT 文件系统使用一种称为文件分配表的数据结构来跟踪文件的存储位置和状态。 FAT 文件系统具有简单、可靠和兼容性好的特点,但在处理大容量存储设备和大文件时性能较差。
-
请参阅 文件分配表 。
- FAT16 是一种文件系统,它是 FAT (文件分配表)系列中的一种。它最初在 1984 年由微软引入,用于 DOS 操作系统和早期的 Windows 版本。 FAT16 使用 16 位的文件分配表项来管理文件和目录的存储和访问。它支持最大容量为 2GB 的分区,并具有较低的存储效率和文件系统限制。尽管 FAT16 已经被更先进的文件系统所取代,但它仍然在某些嵌入式系统和旧版操作系统中使用。
-
参见 文件分配表( 16 位) 。
- FTP 是一种用于在计算机网络上传输文件的协议。它允许用户通过客户端和服务器之间的连接来上传和下载文件。 FTP 使用基于文本的命令和响应模式进行通信,并支持匿名访问和身份验证。它是互联网上最常用的文件传输协议之一。
-
参见 文件传输协议 。
- 文件分配表
- 文件分配表( 16 位)
- 文件传输协议
-
一种基于 TCP 实现的高级协议家族的成员,可用于在 TCP/IP 网络上传输文件。
- 固定 ACPI 描述表
G
- 图形用户界面( GUI )
-
参见 图形用户界面 。
- 巨人
-
一个互斥机制的名称(一个睡眠“互斥锁”),用于保护大量的内核资源。尽管在过去,一个简单的锁机制足以满足机器可能只有几十个进程、一个网络卡,当然只有一个处理器的需求,但在当前时代,它是一个无法接受的性能瓶颈。 FreeBSD 开发人员正在积极努力将其替换为保护单个资源的锁,这将为单处理器和多处理器机器提供更高程度的并行性。
- 图形用户界面
-
用户和计算机通过图形进行交互的系统。
你好!我是一个翻译引擎,我可以帮助你将英文翻译成中文。请告诉我你需要翻译的内容。
- 挂断电话
- 超文本标记语言
-
用于创建网页的标记语言。
I
- 输入 / 输出
-
请参阅 输入 / 输出 。
- IASL 是 Intel ACPI Source Language 的缩写,意为 Intel ACPI 源代码语言。
- IMAP ( Internet Mail Access Protocol )是一种用于电子邮件客户端与邮件服务器之间进行通信的协议。它允许用户在不下载邮件的情况下直接在邮件服务器上管理和查看邮件。 IMAP 提供了更多的功能和灵活性,例如可以在多个设备上同步邮件、管理文件夹和标签、搜索邮件等。 IMAP 是一种常用的电子邮件协议,被广泛用于个人和企业邮件系统中。
- IP 是 Internet Protocol (互联网协议)的缩写,它是一种用于在网络上传输数据的协议。 IP 地址是一个由数字和点组成的标识符,用于唯一标识网络上的设备。 IP 地址可以分为 IPv4 和 IPv6 两种格式。 IPv4 地址由 32 位二进制数表示,通常以点分十进制的形式呈现。 IPv6 地址由 128 位二进制数表示,通常以冒号分隔的八组十六进制数呈现。 IP 地址的作用是在网络上定位和识别设备,使得数据能够正确地传输和交换。
-
参见 Internet Protocol 。
- IPFW 是指 Internet 协议防火墙,是一种用于保护计算机网络安全的软件或硬件设备。它可以监控和控制网络流量,根据预设的规则来允许或阻止特定的网络连接。 IPFW 可以帮助防止未经授权的访问、网络攻击和数据泄露等安全威胁。
-
参见 IP 防火墙 。
- IPP 是 Internet Printing Protocol 的缩写,即互联网打印协议。它是一种用于在网络上进行打印操作的协议,允许用户通过互联网连接到远程打印机并发送打印任务。 IPP 提供了一种标准化的方式来管理打印作业,包括打印机的发现、状态查询、打印任务的提交和控制等功能。它是一种跨平台的协议,可以在不同操作系统和设备之间进行通信。
- IPv4 是 Internet Protocol version 4 的缩写,即互联网协议第四版。它是一种用于在互联网上进行数据传输的网络协议。 IPv4 使用 32 位地址来标识网络上的设备,这些地址由四个十进制数表示,每个数的取值范围是 0 到 255 。 IPv4 是目前广泛使用的互联网协议,但由于地址空间有限,已经逐渐被 IPv6 取代。
-
请参阅 IP 版本 4 。
- IPv6 是 Internet 协议第六版的缩写,它是一种用于互联网通信的网络协议。 IPv6 的主要目的是解决 IPv4 所面临的地址耗尽问题,并提供更好的安全性、可靠性和性能。与 IPv4 相比, IPv6 拥有更大的地址空间,能够支持更多的设备连接到互联网。此外, IPv6 还引入了一些新的特性,如流量优先级和安全性增强。随着互联网的发展, IPv6 正逐渐取代 IPv4 成为主流的网络协议。
-
请参阅《 IPv6 词汇表, IP 版本 6 》。
- ISP 是 Internet Service Provider 的缩写,意为互联网服务提供商。
-
参见 互联网服务提供商 。
- IP 防火墙
- IP 版本 4
-
IP 协议版本 4 使用 32 位进行寻址。这个版本仍然是最广泛使用的,但正在逐渐被 IPv6 取代。
请参阅《 IPv6 词汇表,同时也是 IP 版本 6 》。
- IP 版本 6
-
新的 IP 协议。由于 IPv4 中的地址空间即将耗尽而发明。使用 128 位进行寻址。
- 输入 / 输出
- 英特尔的 ASL 编译器
-
Intel 的编译器用于将 ASL 转换为 AML 。
- Internet Message Access Protocol ( IMAP )
-
一种用于访问邮件服务器上的电子邮件消息的协议,其特点是消息通常保存在服务器上,而不是下载到邮件阅读器客户端。
参见邮局协议版本 3 。
- Internet 打印协议
- 互联网协议
-
互联网上的基本协议,用于数据包传输。最初由美国国防部开发,是 TCP/IP 协议栈的一个极其重要的组成部分。没有互联网协议,互联网就不会成为今天的样子。更多信息,请参见链接: RFC 791 。
- 互联网服务提供商
-
一家提供互联网接入的公司。
K
KLD 是指 Kullback-Leibler 散度,是一种用于衡量两个概率分布之间差异的度量方法。它可以用来比较两个概率分布的相似性或者在机器学习中用于评估模型的性能。 KLD 的计算公式如下:
KLD(P || Q) = Σ (P(x) * log(P(x) / Q(x)))
- 其中, P 和 Q 分别表示两个概率分布, x 表示概率分布中的元素。 KLD 的值越小,表示两个概率分布越相似。
-
参见 Kernel ld(1) 。
- KSE
-
请参阅 内核调度实体 。
- 千伏安( KVA )
- 千比特每秒
-
参见 每秒千位比特数 。
- 内核手册: ld[1]
-
一种在不重新启动系统的情况下将功能动态加载到 FreeBSD 内核的方法。
- 内核调度实体
-
一个由内核支持的线程系统。详细信息请参见链接: 项目主页 。
- 内核虚拟地址
- 密钥分发中心
- 千比特每秒
-
用于测量带宽(在指定的时间内可以通过给定点的数据量)。除了 Kilo 前缀之外,还有 Mega 、 Giga 、 Tera 等替代选项。
L
- 行打印机守护程序
- 本地区域网络
-
局域网是指在局部范围内使用的网络,例如办公室、家庭等。
- 锁定顺序颠倒
-
FreeBSD 内核使用多个资源锁来调解对这些资源的争用。在 FreeBSD-CURRENT 内核中发现的一个运行时锁诊断系统(但在发布版本中已被删除),称为 witness(4) ,可以检测由于锁定错误而导致死锁的潜在可能性。( witness(4) 实际上稍微保守,因此可能会出现误报。)真正的阳性报告表示“如果你运气不好,死锁将会在这里发生”。
真正的正面 LOR (锁定对象关系)往往会很快得到修复,因此在向邮件列表发布之前,请在 https://lists.FreeBSD.org/subscription/freebsd-current 和链接: LORs Seen 页面上进行检查。
M
- MAC 是指"Media Access Control",中文意为媒体访问控制。在计算机网络中, MAC 地址是用于唯一标识网络设备的物理地址。每个网络设备都有一个唯一的 MAC 地址,它由 48 位二进制数表示。 MAC 地址通常以十六进制的形式表示,由 6 个字节组成,每个字节用冒号或连字符分隔。 MAC 地址在数据链路层起着重要的作用,用于在局域网中识别和定位设备。
-
参见 强制访问控制 。
- MADT
-
请参阅 多 APIC 描述表 。
- MFC ( Microsoft Foundation Class )是微软基于 C ++语言开发的一套应用程序框架。它提供了一系列的类和函数,用于简化 Windows 应用程序的开发过程。 MFC 包含了许多常用的功能,如窗口管理、消息处理、用户界面设计等,使开发者能够更快速、更方便地创建 Windows 应用程序。 MFC 已经成为 Windows 平台上最常用的应用程序开发框架之一。
-
请参阅 合并当前版本 。
- MFH 是指"Mainframe Host",即主机机架。
-
参见 从头合并 。
- MFS 是指分布式文件系统( Distributed File System ),它是一种用于存储和管理大规模数据的系统。 MFS 将数据分布在多个服务器上,通过网络进行访问和操作。它提供了高可用性、可扩展性和容错性,能够有效地处理大量数据的存储和访问需求。 MFS 在计算机领域被广泛应用于大数据处理、云计算和分布式存储等领域。
-
请参阅 从稳定分支合并 。
- MFV 是指最小可行化产品( Minimum Viable Product )的缩写。最小可行化产品是指在产品开发过程中,以最小的功能集合来满足用户需求的产品版本。它的目的是通过快速构建和发布最小可行化产品,来验证产品的可行性和市场需求,以便在后续开发中进行迭代和改进。最小可行化产品的特点是具有基本的核心功能,能够提供用户价值,并且能够在短时间内开发和发布。
-
请参阅 从供应商合并 。
- 麻省理工学院
-
参见《麻省理工学院词汇表》。
- 多级安全( MLS )
-
请参阅 多级安全 。
- MOTD ( Message of the Day )是一条每天显示在计算机终端或登录界面上的消息。
-
参见 每日消息 。
- MTA 是邮件传输代理( Mail Transfer Agent )的缩写,它是一种计算机程序或软件,用于在计算机网络中传输电子邮件。 MTA 负责接收、路由和传递电子邮件,以确保邮件能够准确、高效地发送到目标地址。常见的 MTA 软件包括 Sendmail 、 Postfix 和 Exim 等。
-
参见 邮件传输代理 。
- MUA
-
参见 邮件用户代理 。
- 邮件传输代理
-
MTA ( Mail Transfer Agent )是用于传输电子邮件的应用程序。传统上, MTA 一直是 BSD 基础系统的一部分。如今, Sendmail 已经包含在基础系统中,但还有许多其他的 MTA ,例如 postfix 、 qmail 和 Exim 。
- 邮件用户代理
-
用户使用的应用程序,用于显示和编写电子邮件。
- 强制访问控制
- 麻省理工学院
- 合并当前版本
-
要将功能或补丁从 -CURRENT 分支合并到另一个分支,通常是 -STABLE 分支。
- 合并自头部
-
将功能或补丁从存储库的 HEAD 合并到较早的分支。
- 从稳定分支合并
-
在 FreeBSD 的正常开发过程中,一个变更会先提交到 -CURRENT 分支进行测试,然后再合并到 -STABLE 分支。但在极少数情况下,一个变更会先进入 -STABLE 分支,然后再合并到 -CURRENT 分支。
当一个补丁从 -STABLE 分支合并到安全分支时,也会使用这个术语。
参见 同时合并当前内容 。
- 从供应商合并
- 每日消息
-
通常在登录时显示的消息,经常用于向系统用户分发信息。
- 多级安全
- 多个 APIC 描述表
N
- 网络地址转换( NAT )
-
参见 网络地址转换 。
- NDISulator 是一种网络驱动程序隔离技术。它允许在计算机系统中运行多个网络驱动程序实例,每个实例都在独立的隔离环境中运行。这种隔离技术可以提供更高的系统稳定性和安全性,同时还可以提供更好的网络性能和可扩展性。 NDISulator 广泛应用于计算机网络领域,特别是在虚拟化和云计算环境中。
-
请参阅《 Project Evil 》的 术语表 。
- NFS ( Network File System )是一种用于在计算机网络上共享文件的协议。它允许不同的计算机系统通过网络访问和共享文件和目录。 NFS 是一种分布式文件系统,它允许客户端计算机像访问本地文件一样访问远程文件。它提供了高性能和可靠性,并且被广泛用于许多计算机网络环境中。
-
参见《 NFS 词汇表,网络文件系统》。
- NTFS (新技术文件系统)是一种用于 Windows 操作系统的文件系统。它具有许多优点,包括对大容量硬盘驱动器的支持、文件和文件夹的安全性、高速读写能力以及对文件压缩和加密的支持。 NTFS 还支持许多高级功能,如文件权限和日志记录,以提供更可靠和稳定的文件系统。
-
请参阅《 NTFS 词汇表》。
- 网络时间协议( NTP )
-
参见《网络时间协议( Network Time Protocol )》的 网络时间协议术语表 。
- 网络地址转换
-
一种技术,通过网关对 IP 数据包进行重写,使得位于网关后面的多台机器能够有效地共享一个 IP 地址。
- 网络文件系统
- 新技术文件系统
-
一个由微软开发并在其“新技术”操作系统中可用的文件系统,如 Windows® 2000 , Windows NT® 和 Windows® XP 。
- 网络时间协议
-
一种通过网络同步时钟的方法。
嗨!我是一个翻译引擎,我可以帮助你将英文翻译成中文。请告诉我你需要翻译的内容。
- 按需邮件中继
- 操作系统
-
一组程序、库和工具,用于访问计算机的硬件资源。操作系统的范围从今天的简单设计,仅支持一次运行一个程序,仅访问一个设备,到完全支持多用户、多任务和多进程的系统,可以同时为数千个用户提供服务,每个用户同时运行数十个不同的应用程序。
- 被事件超越
-
指示一个建议的更改(例如问题报告或功能请求),由于 FreeBSD 的后续更改、网络标准的变化、受影响的硬件已经过时等原因,该更改不再相关或适用。
P
- PAE ( Physical Address Extension )是一种计算机技术,用于扩展 32 位操作系统的内存寻址能力。通过 PAE ,操作系统可以访问超过 4GB 的物理内存。 PAE 技术通过增加物理地址的位数来实现,从而扩展了内存寻址范围。
-
参见 物理地址扩展 。
- PAM ( Pluggable Authentication Modules )是一种用于实现灵活身份验证的系统框架。它允许系统管理员通过配置文件来选择和配置不同的身份验证方法,如密码、令牌、生物识别等。 PAM 提供了一种标准化的接口,使得开发者可以轻松地添加、修改或替换身份验证模块,而无需修改应用程序的源代码。 PAM 在计算机安全领域被广泛应用,特别是在 Linux 和 UNIX 系统中。
-
参见 可插拔认证模块 。
- PAP 是指人民行动党( People’s Action Party )的缩写,是新加坡的主要政党。该党成立于 1954 年,自 1965 年起一直执政至今。人民行动党在新加坡政治中起着重要的角色,致力于推动国家的发展和改革。
-
参见 密码认证协议 。
- 个人电脑
-
参见 个人电脑 。
- PCNSFD 是指"Power Control and Network Selection for Device-to-Device Communication in 5G Networks",即"5G 网络中用于设备对设备通信的功率控制和网络选择"。
-
请参阅《个人计算机网络文件系统守护进程》( pcnfsd-glossary )。
- PDF ( Portable Document Format )是一种用于显示和打印文档的文件格式。它是由 Adobe Systems 开发的,并且可以在各种操作系统和设备上使用。 PDF 文件可以包含文本、图像、链接和其他元素,并且可以保持文档的格式和布局不变。 PDF 已成为一种广泛使用的文件格式,特别适用于电子书、报告、合同和其他需要保持原始格式的文档。
-
参见 便携式文档格式 。
- 进程标识符( PID )
-
参见 进程 ID 。
- POLA 是一个缩写,代表着“ Plan , Organize , Lead , and Assess ”(计划、组织、领导和评估)这四个词。这个术语通常用于管理和领导方面,指的是一种管理方法或框架,用于指导和评估组织的活动和目标的实现。
-
参见《最小惊讶原则》( Principle Of Least Astonishment ),请参阅 [pola-glossary] 。
- POP 是一种用于接收电子邮件的协议,它代表邮局协议( Post Office Protocol )。它允许用户从邮件服务器上下载电子邮件到本地计算机上的邮件客户端。 POP 是一种常见的电子邮件协议,广泛用于个人和企业的电子邮件通信。
-
参见 邮局协议 。
- POP3 ( Post Office Protocol 3 )是一种用于接收电子邮件的 Internet 标准协议。它允许用户从远程服务器上下载电子邮件到本地计算机上的邮件客户端。 POP3 是一种简单的、无状态的协议,它使用 TCP 连接来传输邮件。它通常与 SMTP ( Simple Mail Transfer Protocol )一起使用,后者用于发送电子邮件。
-
请参阅《邮局协议版本 3 》的 术语表 。
- PPD 是指职业性皮肤病( Occupational Dermatitis ),是一种由工作环境中的化学物质或物理因素引起的皮肤炎症。这种疾病常见于需要与有害物质接触的工作岗位,如工业、农业、建筑和医疗等行业。 PPD 的症状包括皮肤红肿、瘙痒、疼痛和起泡等。及早诊断和采取适当的预防措施对于预防和管理 PPD 非常重要。
-
请参阅 PostScript 打印机描述 。
- PPP 是指点对点协议( Point-to-Point Protocol ),它是一种用于在计算机网络中建立和维护数据链路层通信的协议。 PPP 提供了一种可靠的、经过身份验证的连接方式,可以在两个节点之间传输数据。它通常用于建立拨号连接或者在局域网中连接两台计算机。 PPP 是一种通用的协议,可以在各种网络环境中使用。
-
参见《点对点协议( PPP )》。
- PPPoA 是一种广泛用于计算机网络中的协议,它代表点对点协议( Point-to-Point Protocol over ATM )。它允许在异步传输模式( Asynchronous Transfer Mode )网络上建立点对点连接,并提供了一种可靠的数据传输方式。 PPPoA 通常用于连接用户计算机与互联网服务提供商( ISP )之间的宽带连接。
-
请参阅 PPP over ATM 。
- PPPoE 是一种用于在以太网上建立点对点连接的网络协议。它允许用户通过宽带连接到互联网,并提供了一种认证和授权机制,以确保连接的安全性和可靠性。 PPPoE 通常用于家庭和办公室网络中,以便用户可以通过宽带连接访问互联网。
-
请参阅 以太网上的 PPP 。
- PPP over ATM ( Point-to-Point Protocol over Asynchronous Transfer Mode )
- 以太网上的 PPP
- PR 是公关的缩写,指的是公共关系。公关是一种管理组织与公众之间关系的活动,旨在建立和维护组织与公众之间的良好沟通和互动。公关的目标是提高组织的声誉和形象,增强公众对组织的认知和信任。公关活动包括媒体关系、社交媒体管理、危机管理、品牌推广等。
-
请参阅《问题报告》( Problem Report )。
- PXE ( Preboot Execution Environment )是一种计算机网络协议,用于在局域网中启动和安装操作系统。它允许计算机通过网络从远程服务器下载操作系统镜像,并在启动时执行。 PXE 通常用于大规模部署和管理计算机系统,特别是在无法使用光盘或 USB 驱动器进行安装的情况下。
- 密码认证协议
- 个人电脑
- 个人计算机网络文件系统守护程序
- 物理地址扩展
-
一种方法是在只有 32 位宽地址空间的系统上实现对最多 64GB RAM 的访问(否则将限制为 4GB ,没有 PAE )。
- 可插拔认证模块
- 点对点协议
- 尖顶帽
-
一种神秘的头饰,类似于愚人帽,授予任何破坏构建、使修订号逆行或在源代码中造成任何其他混乱的 FreeBSD 贡献者。任何值得一提的贡献者很快就会积累大量这样的头饰。使用方式(几乎总是)幽默。
- 便携式文档格式
- 邮局协议
-
参见邮局协议版本 3 。
- 邮局协议版本 3
-
一种用于访问邮件服务器上的电子邮件消息的协议,其特点是通常将消息从服务器下载到客户端,而不是保留在服务器上。
参见 互联网消息访问协议 。
- PostScript 打印机描述
- 预引导执行环境
- 最小惊讶原则
-
随着 FreeBSD 的发展,对用户可见的变化应尽量保持不令人惊讶。例如,在 [/etc/defaults/rc.conf] 中任意重新排列系统启动变量违反了 POLA 原则。开发人员在考虑用户可见的系统变化时会考虑 POLA 原则。
- 问题报告
-
这是对在 FreeBSD 源代码或文档中发现的某种问题的描述。请参阅 编写 FreeBSD 问题报告 。
- 进程 ID
-
一个数字,对于系统上的特定进程是唯一的,它可以标识该进程并允许对其进行操作。
- 邪恶项目
-
NDISulator 的工作标题是由 Bill Paul 撰写的,他给它取名是因为从哲学的角度来看,需要像这样的东西本身就很糟糕。 NDISulator 是一个特殊的兼容模块,允许在 FreeBSD/i386 上使用 Microsoft Windows™ NDIS miniport 网络驱动程序。这通常是使用驱动程序为闭源的卡片的唯一方法。请参阅 src/sys/compat/ndis/subr_ndis.c 。
R 是一种用于统计分析和数据可视化的编程语言和环境。它提供了丰富的统计和图形功能,可以进行数据处理、数据分析、模型建立和预测等任务。 R 语言具有开源的特点,拥有庞大的用户社区和丰富的扩展包,可以满足不同领域的数据分析需求。 R 语言的语法简洁易学,适合初学者入门,同时也支持高级编程和自定义函数。在计算机科学和数据科学领域, R 语言被广泛应用于学术研究、商业分析和数据挖掘等领域。
- RA 是指"逆向工程"( Reverse Engineering )的缩写。逆向工程是指通过分析已有的产品或系统,以了解其设计、功能和工作原理的过程。逆向工程通常用于研究竞争对手的产品、修复软件漏洞、提取硬件或软件的设计信息等。
-
请参阅《路由器通告》( Router Advertisement )。
- RAID (冗余磁盘阵列)是一种数据存储技术,通过将多个磁盘驱动器组合在一起,以提供更高的性能、容错能力和数据保护。 RAID 可以在硬件或软件级别实现,并且有不同的级别,如 RAID 0 、 RAID 1 、 RAID 5 等。每个级别都有不同的数据分布和冗余策略,以满足不同的需求。 RAID 技术广泛应用于服务器、存储系统和数据中心等领域,以提供可靠的数据存储和高效的数据访问。
-
请参阅《冗余磁盘阵列》( Redundant Array of Inexpensive Disks )一词的解释。
- RAM ( Random Access Memory )是一种计算机内存的类型,用于临时存储数据和指令。它是计算机中的主要存储器之一,与硬盘驱动器和固态驱动器等长期存储设备不同。 RAM 具有快速读写速度和易于访问的特点,可以提供计算机运行所需的临时存储空间。当计算机运行程序时,数据和指令被加载到 RAM 中,以便 CPU 可以快速访问和处理。然而, RAM 是一种易失性存储器,意味着在断电或重新启动计算机时,其中的数据将被清除。因此, RAM 通常用于存储临时数据和正在运行的程序,而不是长期存储数据。
-
请参阅 随机存取存储器 。
- 研发部门
-
参见 接收数据 。
- RFC ( Request for Comments )是一系列由互联网工程任务组( IETF )发布的文件,用于描述互联网协议、标准、方法和相关主题。 RFC 文件是互联网技术的重要参考资料,其中包含了许多关于网络通信、路由、安全、电子邮件、网页等方面的详细规范和建议。 RFC 文件通常以数字编号进行标识,每个 RFC 都经过了广泛的讨论和审查,以确保其质量和可靠性。
-
请参阅 请求评论 。
- 精简指令集计算机( RISC )
-
参见《精简指令集计算机》( Reduced Instruction Set Computer )的 术语表 。
- 远程过程调用( RPC )
-
参见《远程过程调用》( Remote Procedure Call ) Remote Procedure Call 。
- RS232C 是一种常见的串行通信接口标准,用于在计算机和外部设备之间传输数据。它定义了数据传输的电气特性、信号线的连接方式和通信协议。 RS232C 接口通常用于连接计算机与调制解调器、打印机、串口设备等外部设备。它已经被更先进的接口标准如 USB 所取代,但在某些特定应用中仍然广泛使用。
-
请参阅 推荐标准 232C 。
- 实时战略游戏( RTS )
-
请参阅《请求发送( Request To Send )》的内容。
- 随机存取存储器
- 版本控制系统
-
_版本控制系统( RCS )_是最早实现“版本控制”功能的软件套件之一,用于普通文件。它允许对每个文件存储、检索、归档、记录、标识和合并多个版本。 RCS 由许多小工具组成,它们共同工作。与更现代的版本控制系统(如 Git )相比, RCS 缺少一些功能,但对于一小组文件来说,安装、配置和开始使用非常简单。
参见 也可以参考 Subversion 。
- 接收到的数据
-
RS232C 引脚或线路,用于接收数据。
参见 传输的数据 。
- 推荐标准 232C
-
串行设备之间通信的标准。
- 精简指令集计算机
-
一种处理器设计方法,其中硬件可以执行的操作被简化,但尽可能通用。这可以导致更低的功耗、更少的晶体管,并且在某些情况下,可以获得更好的性能和增加的代码密度。 RISC 处理器的例子包括 Alpha 、 SPARC® 、 ARM® 和 PowerPC® 。
- 廉价磁盘冗余阵列
- 远程过程调用
- 请求评论
-
一组定义互联网标准、协议等的文档。请参阅 www.rfc-editor.org 。
当某人提出改变建议并希望得到反馈时,也可作为一个通用术语使用。
- 请求发送
-
一个 RS232C 信号,请求远程系统开始传输数据。
参见 也称为 Clear To Send 。
- 路由器通告
S
- SCI 是指科学引文索引( Science Citation Index ),是由美国科学信息研究所( Institute for Scientific Information )编制和发布的一种学术文献检索工具。它收录了全球范围内的科学、技术和医学领域的学术期刊文章,并提供了引用关系和引用分析功能,帮助研究人员追踪和评估学术论文的影响力和引用情况。 SCI 是科学研究和学术交流中重要的参考工具之一。
-
参见 << 系统控制中断 >> 。
- SCSI ( Small Computer System Interface )是一种计算机系统中常用的接口标准,用于连接计算机和外部设备,例如硬盘驱动器、光驱和打印机等。它提供了高速数据传输和并行通信的能力,使得计算机可以与多个设备同时进行数据交换。 SCSI 接口广泛应用于服务器、工作站和存储系统等领域。
-
参见《 SCSI 词汇表》中的《小型计算机系统接口》。
- 新加坡
-
参见 信号地 。
- SMB 是指 Server Message Block 的缩写,即服务器消息块。它是一种用于在计算机网络上共享文件、打印机和其他资源的通信协议。 SMB 协议最初由 IBM 开发,后来被微软广泛采用,并成为 Windows 操作系统中文件和打印机共享的主要协议。 SMB 协议使用 TCP/IP 协议进行通信,并提供了安全认证、文件访问控制和数据传输等功能。
-
请参阅《 SMB 词汇表, Server Message Block 》。
- 对称多处理( SMP )
-
参见《对称多处理器( Symmetric MultiProcessor )》。
- SMTP ( Simple Mail Transfer Protocol )是一种用于电子邮件传输的标准协议。它定义了电子邮件客户端和服务器之间的通信规则,以确保可靠地传递电子邮件。 SMTP 使用 TCP/IP 网络来传输邮件,并使用特定的端口号(默认为 25 )进行通信。通过 SMTP ,用户可以发送电子邮件到目标服务器,并且服务器可以将邮件传递给接收者的电子邮件客户端。 SMTP 还支持身份验证和加密机制,以确保邮件的安全性和私密性。
-
参见《 SMTP (简单邮件传输协议)术语表》。
- SMTP AUTH ( Simple Mail Transfer Protocol Authentication )是一种用于电子邮件传输的身份验证机制。它允许邮件服务器在发送或接收邮件时验证用户的身份。通过 SMTP AUTH ,用户可以使用用户名和密码进行身份验证,以便发送或接收邮件。这种身份验证机制可以提高邮件传输的安全性,并防止未经授权的访问和垃圾邮件的发送。
-
参见 SMTP 认证 。
- SSH ( Secure Shell )是一种网络协议,用于在不安全的网络中安全地进行远程登录和执行命令。它通过加密通信和身份验证来保护数据的安全性。 SSH 广泛用于管理远程服务器和计算机,提供了一种安全的方式来访问和控制远程设备。
-
请参阅《 SSH 词汇表》中的《 Secure Shell 》。
- STR 是英文单词"strength"的缩写,意为"力量"或"强度"。在计算机领域中, STR 也可以指代"字符串"( string )的意思。
-
参见 挂起到 RAM 。
- SVN 是一个版本控制系统,全称为 Subversion 。它被广泛用于管理和跟踪软件开发项目中的代码变更。 SVN 允许多个开发者同时工作,并提供了版本控制、分支管理、合并等功能,以便更好地协作和管理代码。
-
参见 Subversion 。
- SMTP 身份验证
- 服务器消息块
- 信号地线
-
RS232 引脚或线是信号的地线参考。
- 简单邮件传输协议
- 安全外壳协议
- 小型计算机系统接口
- Subversion 是一个版本控制系统,用于管理和跟踪文件和目录的变化。它允许多个用户协同工作,并提供了版本控制、分支和合并等功能。 Subversion 使用中央服务器存储文件的历史记录,并允许用户通过检出、提交和更新等操作来与服务器进行交互。它是一个开源软件,广泛用于软件开发和项目管理中。
-
Subversion 是一个版本控制系统,目前被 FreeBSD 项目使用。
- 挂起到 RAM
- 对称多处理器( Symmetric MultiProcessor ,简称 SMP )
- 系统控制中断
T
- 传输控制协议( TCP )
-
参见《传输控制协议》。
- TCP/IP 是一种网络协议套件,用于在计算机网络中进行通信。它由两个主要协议组成:传输控制协议( TCP )和 Internet 协议( IP )。 TCP 负责在网络上可靠地传输数据,而 IP 则负责将数据包从一个网络节点传输到另一个网络节点。 TCP/IP 是互联网的基础协议,也被广泛应用于局域网和广域网中。
-
参见《传输控制协议 / 互联网协议》( Transmission Control Protocol/Internet Protocol )的 术语表 。
- TD
-
参见 传输数据 。
- TFTP ( Trivial File Transfer Protocol )是一种简单的文件传输协议,用于在计算机网络中传输文件。它通常用于在本地网络中快速传输小型文件,如配置文件、固件等。 TFTP 使用 UDP 协议进行通信,并且没有身份验证或加密功能。它的设计目标是简单和高效,因此功能相对较少。 TFTP 常用于网络设备的配置和维护,以及在计算机之间传输引导程序和操作系统映像。
-
参见 Trivial FTP 。
- TGT
-
请参阅 票据授权票 。
- TSC 是指技术指导委员会( Technical Steering Committee ),它是一个由技术专家组成的团队,负责指导和监督项目的技术方向和决策。 TSC 的成员通常是项目的核心贡献者和领导者,他们负责评审和批准新功能、技术架构和项目发展计划。 TSC 的目标是确保项目的技术方向与项目的愿景和目标保持一致,并促进项目的技术创新和发展。
-
参见 时间戳计数器 。
- 票据授予票据
- 时间戳计数器
-
现代 Pentium® 处理器内部的性能分析计数器,用于计算核心频率时钟周期。
- 传输控制协议
-
一种位于(例如) IP 协议之上的协议,确保数据包以可靠、有序的方式传递。
- 传输控制协议 / 互联网协议
-
TCP/IP 是指运行在 IP 协议之上的 TCP 协议的组合术语。互联网的大部分运行都是基于 TCP/IP 。
- 传输的数据
-
RS232C 引脚或线是用于传输数据的。
请参阅 也收到的数据 。
- Trivial FTP (简称 TFTP )
U
- 用户数据报协议( UDP )
-
参见《用户数据报协议》( User Datagram Protocol )的 词汇表 。
- UFS1
-
请参阅《 Unix 文件系统版本 1 》的 Unix 文件系统版本 1 部分。
- UFS2
-
参见 Unix 文件系统版本 2 。
- 用户标识
-
参见 用户 ID 。
- URL ( Uniform Resource Locator )是统一资源定位符的缩写,用于标识和定位互联网上的资源。它是一个字符串,包含了资源的地址和访问方式。 URL 通常由协议、主机名、端口号、路径和查询参数等组成,可以用于访问网页、图片、视频等各种类型的资源。
-
参见 统一资源定位符 。
- 通用串行总线( Universal Serial Bus ),简称 USB ,是一种用于连接计算机与外部设备的通信接口标准。它可以用于连接各种设备,如打印机、键盘、鼠标、摄像头、移动存储设备等。 USB 接口具有热插拔、高速传输、简单易用等特点,已经成为计算机领域中最常用的接口之一。
-
参见《通用串行总线》。
- 统一资源定位符
-
一种定位资源的方法,例如在互联网上定位文档以及识别该资源的手段。
- Unix 文件系统版本 1
-
原始的 UNIX® 文件系统,有时被称为伯克利快速文件系统。
- Unix 文件系统版本 2
-
UFS2 是 UFS1 的扩展,引入于 FreeBSD 5-CURRENT 。 UFS2 增加了 64 位块指针(突破了 1T 的限制),支持扩展文件存储和其他功能。
- 通用串行总线
-
一种硬件标准,用于将各种计算机外设连接到通用接口。
- 用户 ID
-
计算机中为每个用户分配的唯一编号,通过该编号可以识别分配给该用户的资源和权限。
- 用户数据报协议
-
UDP 是一种简单而不可靠的数据报协议,用于在 TCP/IP 网络上交换数据。 UDP 不像 TCP 那样提供错误检查和纠正。
V
- 虚拟专用网络( VPN )
-
请参阅《虚拟私人网络》的 虚拟私人网络 部分。
- 虚拟专用网络
-
一种使用公共电信网络(如互联网)来提供对本地网络(如企业局域网)的远程访问的方法。
1. 有一些任务是无法中断的。例如,如果进程正在尝试从网络上的另一台计算机上读取文件,而该计算机不可用,那么该进程被称为不可中断。最终,该进程将超时,通常在两分钟后。一旦超时发生,该进程将被终止。
上次修改时间: September 18, 2024 by fiercex